Python容器类型
Python的容器类型包含:列表(list)、元组(tuple)、字典(dict)、集合(set)、字符串(str)
可迭代对象
可迭代对象 (Iterable)是实现了 __iter__() 方法,或能通过 __getitem__() 按索引访问元素的对象。简单来说就是可以被for循环遍历的对象。
-
列表
-
元组
-
字典
-
集合
-
字符串
列表
列表的定义( 注意: 不要以list作为变量名!)
python
# 用中括号定义
lst1 = []
# 用list关键字定义
lst2 = list()
print(lst1, lst2, type(lst1), type(lst2))列表的特点
- 可以存放任意数据类型
- 是有序项目集合
- 是可变数据类型
判断是不是list类型
python
lst = list()
print( isinstance(lst,list))可以存放任意数据类型
python
#可以存放任何类型对象
lst3 = [1,1.2,2+3j,'a',False,print]
print(lst3)有序项目集合
可以通过下标索引获取,也可以进行切片
python
#有序项目集合
print(lst3[3],lst3[-3])
print(lst3[-1:-4:-1])可变数据类型
- 可变数据类型:能够在原地址上对变量的值进行修改
- 不可变数据类型:一旦被定义就不能被改变,不能在原地址上进行修改
由于Python是 动态类型语言 (变量存放的都是地址),所以基本数据 类型(包含string)都是不可变数据类型。
python
a = 10
print(id(a)) # 140724537584344
a = 20
print(id(a)) # 140724537584664
# 可以发现,看似是一个值的变换,实际上是a存放的地址指向发生了改变
# 在原地址不能修改它的值,只能重新开辟一个新的空间指向它list,dict,set都是可变数据类型(可以在原地址上修改他的值)
python
lst = [1,2,3,4,5]
print(id(lst),lst[0]) # 2419404767168
lst[0] = 20
print(id(lst),lst[0]) # 2419404767168
# 可以发现修改它里面的值,列表本身的地址并未改变List的底层原理
lst 变量存放的实际上是一个地址,这个地址指向PyListObject 结构体,结构体中有一个变量存放的是元素的总数,有一个变量指向的是一个存着变量地址的数组。数组是内存中的一块连续的地址空间,每个数组元素中存放的是列表中的真实元素的地址。
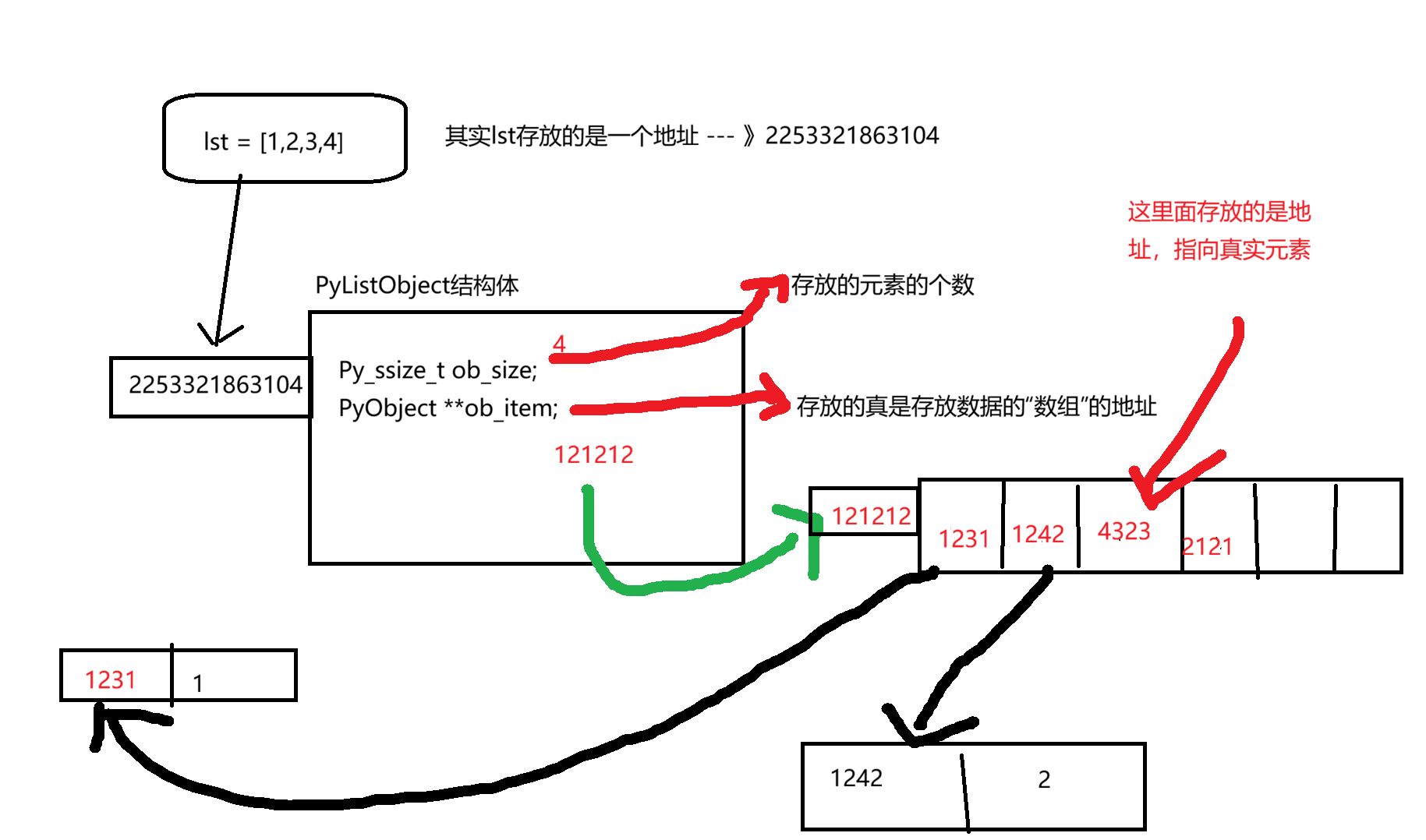
List的方法
list()函数可以把可迭代对象转换成列表
lst1 = list("abc")
lst1
# ['a', 'b', 'c']列表的增加
| Method | Comment |
|---|---|
| append(200) | 在末尾添加 |
| insert(1,200) | 在指定位置添加 |
| extend("abcd") | 将其他可迭代对象放入列表 |
列表的计算
| Method | Comment |
|---|---|
| lst3 = lst1 + lst2 | 两个列表拼接 |
| lst = lst * 3 | 里面的元素重复三次 |
列表的删除
| Method | Comment |
|---|---|
| result = pop(i) | 删除下标i元素并返回 |
| remove('x') | 删除出现的第一个x(没有会异常) |
列表的修改
| Method | Comment |
|---|---|
| lst2 = "abc" | 下标修改 |
| lst2:4 = "xy" | 将下标为2,3的元素替换为'x','y' |
列表的统计
| Method | Comment |
|---|---|
| lst.count("a") | 统计出现的次数 |
| lst.index("a") | 第一次出现的下标位置,若不存在则报错 |
| len(lst) | 求列表的长度 |
列表的复制
| Method | Comment |
|---|---|
| lst2 = lst1 | 引用复制(地址赋值) |
| lst2 = lst: | 截取lst的全部内容 |
| lst2 = lst.copy() | 内容复制 |
| lst2 = \[\] + lst | 合并赋值 |
列表的反转
| Method | Comment |
|---|---|
| lst.reverse() | 在原地址反转 |
| lst.sort() | 列表的排序 |
成员关系判断
in not in
lst = ['z','x','y']
for k,v in enumerate(lst): # k是下标索引,v是存放的值
print(k,v)元组
元组的特点
- 有序项目集合
- 可以存放任意数据类型
- 不可变数据类型(和列表的区别)
它的其他特点和列表一样,只是它是不可变数据类型
元组里面只有一个元素的时候要在末尾加一个逗号 (1,)
可以用tuple将可迭代对象转换为元组
lst = [1,2,'a']
t1 = tuple(lst)
print(t1)元组里面如果包含了可变数据类型(如列表),则可以对其进行修改
lst = [1,2,'a']
t2 = ('a',lst)
print(t2)
lst.append("tomdeng")
print(t2)字典
字典的特点
-
是一种
key-value键值存储的数据结构 -
无序项目集合 (不能通过下标索引和切片)
-
可变数据类型
字典的key
- 天生去重
key必须是不可变数据类型(可哈希对象)
字典的value 可以是任何数据类型
将列表转换为字典必须明确key - value 关系
lst = [('a',1),('b',2)]
d1 = dict(lst)
# {'a': 1, 'b': 2}字典取值
通过key取值时候,如果key不存在就会报错
>>> d1
{'a': 1, 'b': 2}
>>> d1['c']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'c'get取值
d1.get("name")这样不会报错
d1.get("name","tomdeng") 如果不存在,返回默认值Tomdeng
>>> a = d1.get('c')
>>> a
>>> a = d1.get('c','Tomdeng')
>>> a
'Tomdeng'd1"sex" = "男" key不存在就是新增 ,存在就是修改
字典的删除
pop删除
d1.pop("a")按key删除并返回删除的value
>>> result = d1.pop('a')
>>> result
1popitem删除
d1.popitem() 删除最后一个并且将删除的内容返回元组(key,value)
>>> result = d1.popitem()
>>> result
('sex', 'male')for循环取值
>>> for i in d1: # 取到的是values
... print(i)
...
b
sex
>>> for k,v in d1.items(): # 用d1.items()可以得到key 和 value
... print(f"key is {k},value is {v}")
...
key is b,value is 2
key is sex,value is male成员关系判断
key判断(默认)
>>> print('b' in d1)
Truevalue判断
>>> print("male" in d1.values())
True字典的合并
原地址合并
>>> d1 = {"a1":1,"b":2}
>>> d2 = {"c":1}
>>> d1.update(d2) # 在原地址上进行合并
>>> d1
{'a1': 1, 'b': 2, 'c': 1}合并成一个新的
使用dict函数合并两个字典,生成一个新的字典
d3 = dict(d1,**d2)字典的底层原理
hash算法
使用hash算法可以将明文变成密文,hash算法有md5 sha1 sha2 sha256 sha512等,这里用到的是Python 字典的 __hash__() 方法,特点是对于任意长度的输入都得到相同长度的输出,它是单向加密的,且对于相同的内容运算后得到的结果是相同的,不同的明文也可能得到相同的密文(概率极小)
常用在 身份校验 ,完整性检验 ,内容校验上,可以防止内容被篡改
bash
[root@TomDeng ~]# echo "tomdeng is handsome" | sha512sum
8678d0b89cf55acd7db308f8518e2fa725ea09bf0f522ceed5df3332d75b94a4ab92a323aa9bd12b72333f520656c461587dc250dee4d63e1bb0c99980aac7d7 -
[root@TomDeng ~]# echo "tomdeng a handsome boy" | sha512sum
12eecb0a2c3fe5ff02e6c330d477a2e0f8a4e042bb28ddd7007cd248136f62aefc024a0a3bd08aa20e9d492cd729838f874b3c82f01ee2707012ca692a20797d ->>> d1["username"].__hash__()
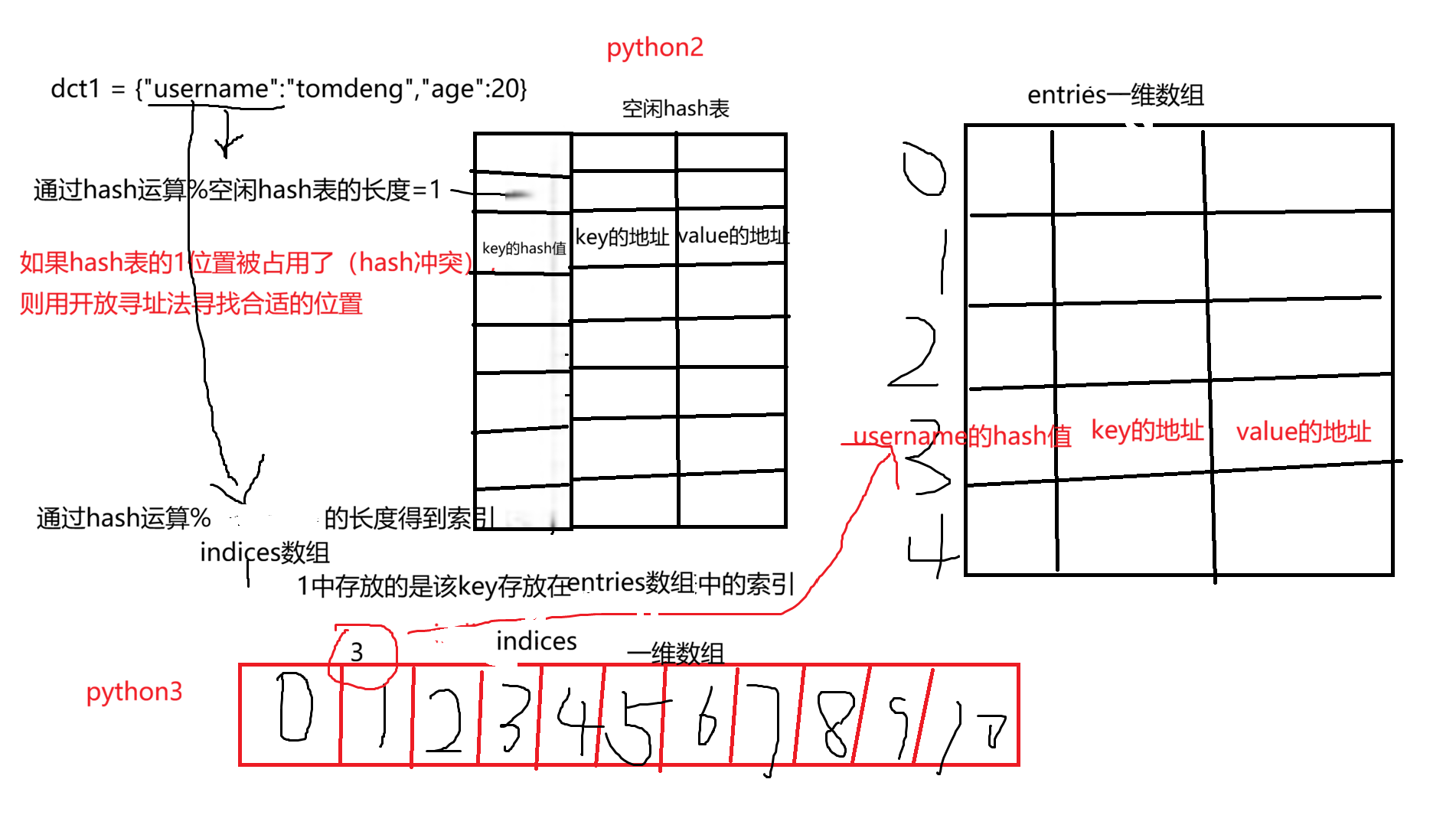
2015820907049098339Python2
通过对key进行取hash值,再将其与hash表取模运算得到索引,再将key对象和value对象存放到对应索引的位置
哈希表是一个数组(称为 table),每个槽位(slot)存储 (hash值, key, value) 三元组(或空)
Python字典默认的负载因子为2/3,(元素数 / 哈希表容量 ≥ 2/3 时触发扩容)用来平衡浪费空间和hash冲突
如果计算得到的索引位置上已经存放了数据,则使用开放寻址法找寻新的位置存放数据
Python3
python3 引入indices数组和entries`数组
indices 数组(索引数组):
- 长度等于哈希表的容量(如 8、16),每个元素是
entry数组的索引(整数),或NULL(空槽位);
entries 数组(条目数组):
- 按插入顺序 存储所有有效键值对,每个元素是
(hash值, key, value)三元组; - 数组长度等于字典的实际元素个数(无空闲槽位),不会浪费空间。
通过对key进行取hash值,再将其与indices表取模运算得到索引,索引的位置存放的是该键值对在entries表中的索引,entries表对应位置存放的是key的hash值、key对象和value对象。由于entries表是按顺序插入的,所以python3是有序的,只是不能通过下标进行访问,同时大大提升了利用率
集合
集合可以看作一个只有key的字典
集合的特点
- 无序项目集合
- 可以存放任何数据类型
- key必须唯一,天生去重,且必须为可哈希对象
集合的定义
s1 = {1,2,3} # 直接定义
s2 = set("123456711") # 可以转换可迭代对象并且天生去重
>>> s2
{'6', '2', '5', '7', '4', '1', '3'}集合的添加和删除
add添加
s1.add(4)update添加
s1.update("123") # 容器都是可迭代对象remove删除
s1.remove('1') #若不存在则会报错discard删除
s1.remove('tomdeng') # 若不存在也不会报错集合的运算
s1 = {1,2,3}
s2 = {2,3,4}
print("交",s1 & s2)
print("并",s1 | s2)
print("差",s1 - s2)
print("对称差",s1 ^ s2)