文章目录
- 前言
- [一、Go 基础](#一、Go 基础)
-
- [1 struct(类似 TypeScript interface + class)](#1 struct(类似 TypeScript interface + class))
- [2 interface(依赖抽象)](#2 interface(依赖抽象))
- [3 context(请求生命周期)](#3 context(请求生命周期))
- [4 goroutine(轻量线程)](#4 goroutine(轻量线程))
- [5 channel(并发通信)](#5 channel(并发通信))
- [二、HTTP + JSON(后端核心)](#二、HTTP + JSON(后端核心))
-
- [一个最简单 HTTP 服务](#一个最简单 HTTP 服务)
- [在 Kratos 中](#在 Kratos 中)
- 三、数据库(后端核心能力)
-
- [最重要的 SQL](#最重要的 SQL)
-
- SELECT
- JOIN
- [GROUP BY](#GROUP BY)
- INDEX(性能关键)
- [四、Go 数据库访问](#四、Go 数据库访问)
- 五、一个完整请求链路
前言
在 HOW - Kratos 入门实践(一) 我们简单介绍过 kratos 框架。
如果我们是前端工程师转 Go 后端,其实不需要把 Go 全部学完。
一般经验上只需要掌握 20% 的核心概念就能写 80% 的后端服务。
在第一篇文章里我们提到了:
Go基础
HTTP服务
数据库今天展开阐述。
一、Go 基础
核心其实只有:
struct
interface
context
goroutine
channel语言本身比 JS/TS 简单很多。
1 struct(类似 TypeScript interface + class)
在 Go 里 struct 是一切的基础。
前端:
ts
interface User {
id: number
name: string
}Go:
go
type User struct {
ID int
Name string
}使用:
go
user := User{
ID: 1,
Name: "Tom",
}JSON序列化:
go
type User struct {
ID int `json:"id"`
Name string `json:"name"`
}这和前端的:
axios -> JSON -> TS类型是一模一样的概念。
2 interface(依赖抽象)
很多前端第一次接触 Go 会被 interface 绕晕,其实很简单:
它就是 行为定义。
例如:
go
type UserRepo interface {
GetUser(id int) (*User, error)
}实现:
go
type userRepo struct{}
func (r *userRepo) GetUser(id int) (*User, error) {
return &User{ID: id, Name: "Tom"}, nil
}这其实和前端的 依赖注入思想一样。
比如:
Service -> Repository在 Kratos 中:
service
↓
biz
↓
repo(interface)
↓
data就是靠 interface 解耦。
3 context(请求生命周期)
Go 后端 所有请求都会带 context。
例如:
go
func GetUser(ctx context.Context, id int) (*User, error)context 用来控制:
超时
取消
trace
request scope例如:
go
ctx, cancel := context.WithTimeout(ctx, 3*time.Second)
defer cancel()如果数据库 3 秒没返回:
自动取消这在微服务非常重要。
4 goroutine(轻量线程)
Go 的并发核心。
开启一个并发任务只需要:
go
go func() {
fmt.Println("hello")
}()对比 JS:
Promise
async await
workergoroutine 非常轻量:
一个 Go 程序可以跑几十万 goroutine典型使用:
并发请求
批量处理
后台任务5 channel(并发通信)
Go 的理念:
Don't communicate by sharing memory;
share memory by communicating.用 channel 在 goroutine 之间传数据。
例子:
go
ch := make(chan int)
go func() {
ch <- 1
}()
value := <-ch
fmt.Println(value)这其实类似:
EventEmitter
message queue二、HTTP + JSON(后端核心)
大多数 Go Web 服务做的事情就是:
HTTP -> JSON -> DB最常见框架:
| 框架 | 特点 |
|---|---|
| Gin | 最流行 |
| Kratos | 微服务 |
| Fiber | 高性能 |
一个最简单 HTTP 服务
go
r := gin.Default()
r.GET("/user", func(c *gin.Context) {
user := User{
ID: 1,
Name: "Tom",
}
c.JSON(200, user)
})
r.Run()返回:
json
{
"id":1,
"name":"Tom"
}这和前端:
fetch -> JSON完全一致。
在 Kratos 中
请求链路:
HTTP
↓
server
↓
service
↓
biz
↓
data
↓
database优点:
结构清晰
可扩展
适合大型项目三、数据库(后端核心能力)
后端 80% 的逻辑其实是:
CRUD至少要熟悉:
| 数据库 |
|---|
| MySQL |
| PostgreSQL |
最重要的 SQL
SELECT
sql
SELECT id,name
FROM user
WHERE id = 1SELECT id, name → 只查询 user 表里的 id 和 name 两个列。
FROM user → 数据来源是 user 表。
WHERE id = 1 → 只获取满足条件 id = 1 的行。
JOIN
sql
SELECT u.name,o.price
FROM user u
JOIN order o
ON u.id = o.user_idu 和 o → 分别是 user 表和 order 表的别名。
JOIN → 内连接(默认 INNER JOIN),只返回两个表满足 ON 条件的行。
ON u.id = o.user_id → 两表通过 user.id 和 order.user_id 匹配。
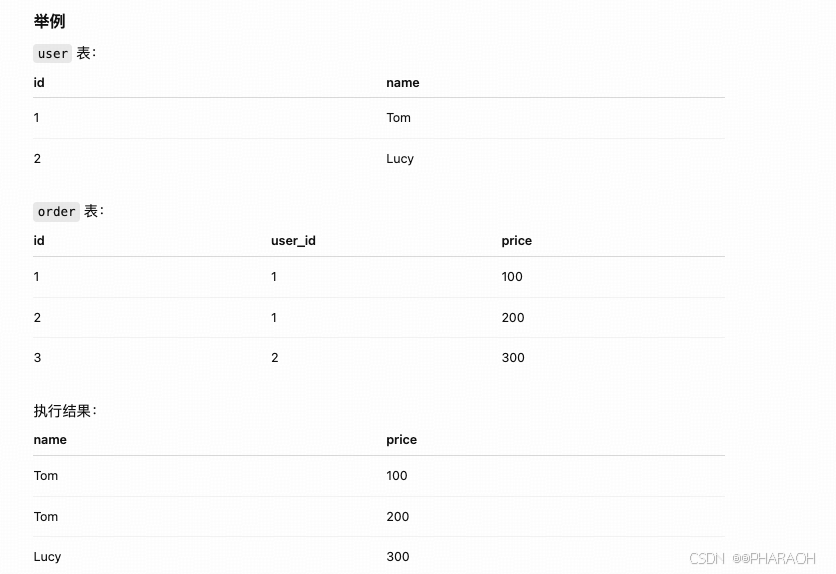
把两个表的数据按照某个关联条件组合在一起,用于查询关联数据。
GROUP BY
sql
SELECT user_id, COUNT(*)
FROM order
GROUP BY user_idGROUP BY user_id → 把 order 表按 user_id 分组。
COUNT(*) → 统计每组的行数。
SELECT user_id, COUNT(*) → 返回每个 user_id 的订单数量。
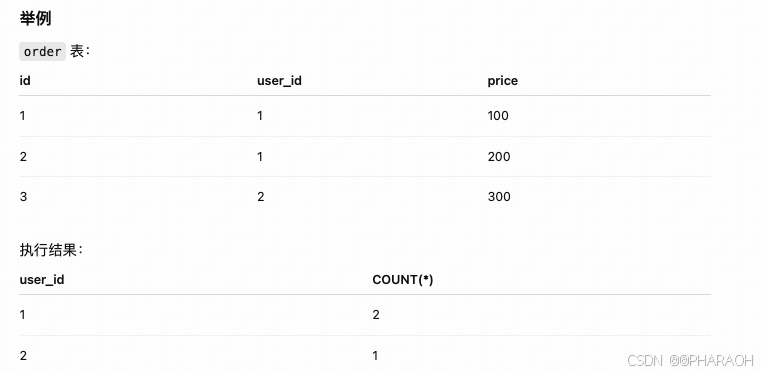
用于聚合统计,例如计算每个用户的订单数量、总金额等。
INDEX(性能关键)
sql
CREATE INDEX idx_user_name
ON user(name);在 user 表的 name 列上创建一个索引。
idx_user_name → 索引名称。
索引能加快查询速度,尤其是 WHERE、JOIN、ORDER BY 操作。

提高查询性能,是大数据量表必备的优化手段。
没有 index:
全表扫描有 index:
O(log n) 查询四、Go 数据库访问
常见 ORM:
| 工具 |
|---|
| GORM |
| sqlx |
| ent |
示例:
go
var users []User
db.Where("age > ?", 18).Find(&users)SQL:
SELECT * FROM users WHERE age > 18五、一个完整请求链路
真实请求流程:
前端 React
│
│ HTTP
▼
Kratos HTTP Server
│
▼
Service
│
▼
Biz
│
▼
Repository
│
▼
MySQL返回:
JSON