目录
-
- 前言
- [1. Problem (math_baseline): 4 points](#1. Problem (math_baseline): 4 points)
- [2. Problem (tokenize_prompt_and_output): Prompt and output tokenization (2 points)](#2. Problem (tokenize_prompt_and_output): Prompt and output tokenization (2 points))
- [3. Problem (compute_entropy): Per-token entropy (1 point)](#3. Problem (compute_entropy): Per-token entropy (1 point))
- [4. Problem (get_response_log_probs): Response log-probs (and entropy) (2 points)](#4. Problem (get_response_log_probs): Response log-probs (and entropy) (2 points))
- [5. Problem (masked_normalize): Masked normalize (1 point)](#5. Problem (masked_normalize): Masked normalize (1 point))
- [6. Problem (sft_microbatch_train_step): Microbatch train step (3 points)](#6. Problem (sft_microbatch_train_step): Microbatch train step (3 points))
- [7. Problem (log_generations): Logging generations (1 point)](#7. Problem (log_generations): Logging generations (1 point))
- [8. Problem (sft_experiment): Run SFT on the MATH dataset (2 points) (2 H100 hrs)](#8. Problem (sft_experiment): Run SFT on the MATH dataset (2 points) (2 H100 hrs))
- [9. Problem (expert_iteration_experiment): Run expert iteration on the MATH dataset (2 points) (6 H100 hrs)](#9. Problem (expert_iteration_experiment): Run expert iteration on the MATH dataset (2 points) (6 H100 hrs))
- 结语
- 源码下载链接
- 参考
前言
在上篇文章 斯坦福大学 | CS336 | 从零开始构建语言模型 | Spring 2025 | 笔记 | Assignment 5: SFT 中,我们已经了解了 SFT 的作业要求,下面我们就一起来看看这些作业该如何实现,本篇文章记录 CS336 作业 Assignment 5: Alignment 中的 SFT 实现,仅供自己参考😄
Note:博主并未遵循 from-scratch 的宗旨,所有代码几乎均由 ChatGPT 完成
Assignment 5 :https://github.com/stanford-cs336/assignment5-alignment
reference :https://chatgpt.com/
1. Problem (math_baseline): 4 points
(a) 编写一个脚本,用于评估 Qwen 2.5 Math 1.5B 在 MATH 数据集上的零样本(zero-shot)性能,该脚本应完成以下任务:
1. 从 /data/a5-alignment/MATH/validation.jsonl 加载 MATH 验证集样本;
2. 使用前文介绍的 r1_zero prompt 将每个样本格式化为语言模型的字符串输入 promot;
3. 为每个样本生成模型输出;
4. 计算评估指标;
5. 将样本数据、模型生成结果以及对应的评估分数序列化并保存到磁盘,以便后续问题分析使用。
在实现过程中,建议你编写一个名为 evaluate_vllm 的函数,其函数形式如下所示,这样可以方便后续复用:
python
def evaluate_vllm(
vllm_model: LLM,
reward_fn: Callable[[str, str], dict[str, float]],
prompts: List[str],
eval_sampling_params: SamplingParams
) -> None:
"""
Evaluate a language model on a list of prompts,
compute evaluation metrics, and serialize results to disk.
"""代码实现如下:
python
import argparse
import json
import os
from dataclasses import asdict, dataclass
from datetime import datetime
from pathlib import Path
from typing import Callable, List, Dict, Any, Optional
from vllm import LLM, SamplingParams
from cs336_alignment.drgrpo_grader import r1_zero_reward_fn
@dataclass
class EvalRow:
idx: int
problem_id: Optional[str]
prompt: str
ground_truth: Any
response: str
reward: float
format_reward: float
answer_reward: float
category: str # "F1A1", "F1A0", "F0A0"
def load_jsonl(path: str) -> List[Dict[str, Any]]:
data = []
with open(path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue
data.append(json.loads(line))
return data
def read_text(path: str) -> str:
with open(path, "r", encoding="utf-8") as f:
return f.read()
def format_r1_zero_prompt(prompt_template: str, question: str) -> str:
# prompt_template should contain "{question}"
return prompt_template.format(question=question)
def categorize(format_reward: float, answer_reward: float) -> str:
if format_reward == 1.0 and answer_reward == 1.0:
return "F1A1"
if format_reward == 1.0 and answer_reward == 0.0:
return "F1A0"
return "F0A0"
def evaluate_vllm(
vllm_model: LLM,
reward_fn: Callable[[str, Any], Dict[str, float]],
prompts: List[str],
ground_truths: List[Any],
eval_sampling_params: SamplingParams,
request_batch_size: int = 64,
) -> List[EvalRow]:
"""
Evaluate a language model on a list of prompts, compute rewards, and return per-example rows.
"""
assert len(prompts) == len(ground_truths)
rows: List[EvalRow] = []
idx_base = 0
# vLLM can take list prompts directly
for start in range(0, len(prompts), request_batch_size):
end = min(len(prompts), start + request_batch_size)
batch_prompts = prompts[start:end]
batch_gts = ground_truths[start:end]
outputs = vllm_model.generate(batch_prompts, eval_sampling_params)
# outputs aligns with input prompts order
for i, out in enumerate(outputs):
prompt = out.prompt
text = out.outputs[0].text # generated continuation
full_response = text
gt = batch_gts[i]
scores = reward_fn(full_response, gt) # dict with reward/format_reward/answer_reward
fr = float(scores.get("format_reward", 0.0))
ar = float(scores.get("answer_reward", 0.0))
rr = float(scores.get("reward", 0.0))
cat = categorize(fr, ar)
rows.append(
EvalRow(
idx=idx_base + i,
problem_id=None,
prompt=prompt,
ground_truth=gt,
response=full_response,
reward=rr,
format_reward=fr,
answer_reward=ar,
category=cat
)
)
idx_base += (end - start)
return rows
def write_jsonl(path: str, rows: List[EvalRow]) -> None:
os.makedirs(os.path.dirname(path), exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
for r in rows:
f.write(json.dumps(asdict(r), ensure_ascii=False) + "\n")
def summarize(rows: List[EvalRow]) -> Dict[str, Any]:
n = len(rows)
c = {"F1A1": 0, "F1A0": 0, "F0A0": 0}
for r in rows:
c[r.category] += 1
format_rate = sum(r.format_reward for r in rows) / n if n else 0.0
acc = sum(r.answer_reward for r in rows) / n if n else 0.0
avg_reward = sum(r.reward for r in rows) / n if n else 0.0
return {
"n": n,
"counts": c,
"format_rate": format_rate,
"answer_accuracy": acc,
"avg_reward": avg_reward,
}
def sample_examples(rows: List[EvalRow], category: str, k: int = 10) -> List[EvalRow]:
picked = [r for r in rows if r.category == category]
return picked[:k]
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--model", default="data/models/Qwen2.5-Math-1.5B")
ap.add_argument("--data", default="data/MATH/validation.jsonl")
ap.add_argument("--prompt_file", default="cs336_alignment/prompts/r1_zero.prompt")
ap.add_argument("--out_dir", default="runs/math_baseline")
ap.add_argument("--max_tokens", type=int, default=1024)
ap.add_argument("--temperature", type=float, default=1.0)
ap.add_argument("--top_p", type=int, default=1.0)
ap.add_argument("--batch_size", type=int, default=64)
ap.add_argument("--limit", type=int, default=0, help="0 means no limit")
args = ap.parse_args()
prompt_template = read_text(args.prompt_file)
examples = load_jsonl(args.data)
if args.limit and args.limit > 0:
examples = examples[: args.limit]
# MATH jsonl usually has "problem" / "question" and "answer" or similar
def get_question(ex: Dict[str, Any]) -> str:
for k in ["problem", "question", "prompt"]:
if k in ex and isinstance(ex[k], str):
return ex[k]
raise KeyError(f"Cannot find question field in example keys={list(ex.keys())}")
def get_ground_truth(ex: Dict[str, Any]) -> Any:
for k in ["answer", "ground_truth", "target"]:
if k in ex:
return ex[k]
raise KeyError(f"Cannot find answer field in example keys={list(ex.keys())}")
prompts, gts = [], []
for ex in examples:
q = get_question(ex)
gt = get_ground_truth(ex)
prompts.append(format_r1_zero_prompt(prompt_template, q))
gts.append(gt)
sampling_params = SamplingParams(
temperature=args.temperature,
top_p=args.top_p,
max_tokens=args.max_tokens,
stop=["</answer>"],
include_stop_str_in_output=True,
)
llm = LLM(
model=args.model,
dtype="bfloat16",
)
rows = evaluate_vllm(
vllm_model=llm,
reward_fn=r1_zero_reward_fn,
prompts=prompts,
ground_truths=gts,
eval_sampling_params=sampling_params,
request_batch_size=args.batch_size,
)
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
out_dir = Path(args.out_dir) / ts
out_dir.mkdir(parents=True, exist_ok=True)
# full per-example
write_jsonl(str(out_dir / "predications.jsonl"), rows)
# summary json
summary = summarize(rows)
with open(out_dir / "summary.json", "w", encoding="utf-8") as f:
json.dump(summary, f, ensure_ascii=False, indent=2)
# samples for write-up
samples = {
"F1A1": [asdict(r) for r in sample_examples(rows, "F1A1", 10)],
"F1A0": [asdict(r) for r in sample_examples(rows, "F1A0", 10)],
"F0A0": [asdict(r) for r in sample_examples(rows, "F0A0", 10)],
}
with open(out_dir / "samples.json", "w", encoding="utf-8") as f:
json.dump(samples, f, ensure_ascii=False, indent=2)
print("Saved to:", out_dir)
print(json.dumps(summary, indent=2))
if __name__ == "__main__":
main()Note :关于 Qwen 2.5 Math 1.5B 模型可以通过 HuggingFace 或 Modelscope 下载,下载方式有很多,这里博主就不再赘述了。
Note :关于 Math 数据集可以通过 OpenDataLab 来下载,不过下载的数据并没有整合,需要自己处理。不过博主在浏览 GitHub 相关项目时发现有人将 Assignment 5 相应的数据都上传了,大家可以访问 https://github.com/x-hsingchan/assignment5 进行下载。
执行指令如下:
shell
uv run python scripts/math_baseline.py执行完该脚本后会在 runs/math_baseline 文件夹下生成三个统计文件,包括:
summary.json:三类计数 + format_rate + answer_accuracy 等samples.json:三类各 10 条样例predictions.jsonl:全量逐样本记录
执行输出如下图所示"
Note:由于博主测试硬件是 RTX2080Ti,不支持 BFloat16,因此改用的 Float32 进行的测试。
上述脚本实现了一个完整的 zero-shot 基线评估流水线:
1. 读取 MATH 验证集 :load_jsonl(args.data) 逐行读入 jsonl,得到 examples 列表。
2. 套用 r1_zero prompt 模板 :从 r1_zero.prompt 读取 prompt_template,用 format_r1_zero_prompt(template, question) 把题目注入到模板的 {question} 位置,构造最终输入 prompts。
3. vLLM 批量生成 :evaluate_vllm() 内部按 batch 调用 vllm_model.generate(batch_prompts, sampling_params) 得到输出。
4. reward_fn 计算指标 :对每条生成结果调用 r1_zero_reward_fn(response, gt) 得到 reward / format_reward / answer_reward。
5. 序列化保存 :把每条样本的 prompt、gt、response、奖励分数、类别写入 predictions.jsonl;统计汇总写入 summary.json;抽样示例写入 samples.json,便于后续作业分析。
(b) 在 Qwen 2.5 MATH 1.5B 上运行你的评估脚本,统计模型生成结果中落入以下类别的数量:
1. format reward = 1 且 answer reward = 1(格式正确且答案正确)
2. format reward = 1 且 answer reward = 0(格式正确但答案错误)
3. format reward = 0 且 answer reward = 0(格式错误且答案错误)
对于至少 10 个 format reward = 0 的样本,请分析你认为问题出在 基础模型输出本身还是答案解析器(parser),请说明原因。此外,对于至少 10 个 format reward = 1 但 answer reward = 0 的样本,请分析原因。
Deliverable:对模型性能和 reward function 表现的分析说明,并提供每种类别的示例。
summary.json 内容如下:
json
{
"n": 5000,
"counts": {
"F1A1": 120,
"F1A0": 701,
"F0A0": 4179
},
"format_rate": 0.1642,
"answer_accuracy": 0.024,
"avg_reward": 0.024
}在 MATH validation 集(共 5000 题)上,按照 reward 规则(format_reward 与 answer_reward)将样本分为三类,其数量统计如下:
- F1A1 (format=1 且 answer=1):120
- F1A0 (format=1 且 answer=0):701
- F0A0 (format=0 且 answer=0):4179
可以看到,大多数样本(4179/5000)都落在 F0A0 类别,即模型未满足严格的输出格式要求。
1. F0A0 (format=0 且 answer=0) 分析
这类样本占比最高(83.6%),说明模型在零样本条件下 无法稳定遵循 r1_zero 所要求的结构化输出格式 (必须包含 <think>...</think> <answer>...</answer>)。
从抽样样本中可以归纳出以下经典问题:
(1) 未输出 <answer> 标签
json
{
"idx": 1,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Two fair 6-sided dice are rolled. What is the probability the sum rolled is 9?\nAssistant: <think>",
"ground_truth": "\\dfrac{1}{9}",
"response": " To determine the probability that the sum of two fair 6-sided dice equals 9, we first need to enumerate all possible outcomes. There are a total of $6 \\times 6 = 36$ possible outcomes when two 6-sided dice are rolled. Next, we identify all the outcomes that result in a sum of 9. These are the pairs (3, 6), (4, 5), (5, 4), and (6, 3). There are 4 such outcomes. Therefore, the probability is the number of favorable outcomes divided by the total number of outcomes, which is $\\frac{4}{36} = \\frac{1}{9}$.\n\nWe can use Python to verify this.\n```python\n# Define the possible outcomes for two fair 6-sided dice\ndice_faces = [1, 2, 3, 4, 5, 6]\ntotal_outcomes = 0\n\n# Count the total number of outcomes and those that result in a sum of 9\nfavorable_outcomes = 0\n\nfor die1 in dice_faces:\n for die2 in dice_faces:\n total_outcomes += 1\n if die1 + die2 == 9:\n favorable_outcomes += 1\n\n# Calculate the probability\nprobability = favorable_outcomes / total_outcomes\nprint((total_outcomes, favorable_outcomes, probability))\n```\n```output\n(36, 4, 0.1111111111111111)\n```\nThe total number of outcomes when two fair 6-sided dice are rolled is 36. The number of outcomes that result in a sum of 9 is 4. Therefore, the probability that the sum equals 9 is $\\frac{4}{36} = \\frac{1}{9} \\approx 0.1111111111111111$.\n\nSo, the answer is $\\boxed{\\frac{1}{9}}$.",
"reward": 0.0,
"format_reward": 0.0,
"answer_reward": 0.0,
"category": "F0A0"
}例如 idx=1,模型给出了完整推理和最终答案,但直接用 \boxes{} 输出结果,而未使用 <answer> 标签包裹,导致 format_reward=0。
(2) 标签格式不严格匹配
json
{
"idx": 5,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: What is the area, in square units, of an isosceles right triangle with a hypotenuse of 20 units?\nAssistant: <think>",
"ground_truth": "100\\text{ square units}",
"response": " The triangle is isosceles, so each leg is sqrt[(20^2)/2]= taco canti canti tacos. <end think>\n<answer> 200 tacos </answer>",
"reward": 0.0,
"format_reward": 0.0,
"answer_reward": 0.0,
"category": "F0A0"
}例如 idx=5,使用了 <end think>、< answer > 等变体,而非严格的 </think> 和 <answer>,解析器无法识别。
(3) 输出被截断或发散
json
{
"idx": 6,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: The square quilt block shown is used in a larger quilt. The four small squares in the block are congruent, and the four small vertical rectangles in the block that are not squares are also congruent. The total area of the shaded regions is what fraction of the total area of the block? Express your answer as a common fraction.\n\n[asy]\nfill((-10,0)--(-5,0)--(-5,5)--cycle,gray(0.7));\nfill((-5,5)--(-5,10)--(0,10)--cycle,gray(0.7));\nfill((0,0)--(0,10)--(10,10)--cycle,gray(0.7));\nfill((0,0)--(-10,-10)--(0,-10)--cycle,gray(0.7));\nfill((0,-10)--(5,-10)--(5,-5)--cycle,gray(0.7));\nfill((5,-5)--(5,0)--(10,0)--cycle,gray(0.7));\ndraw((10,10)--(10,-10)--(-10,-10)--(-10,10)--cycle);\ndraw((-10,-10)--(10,10));\ndraw((0,10)--(0,-10));\ndraw((10,0)--(-10,0));\ndraw((-5,0)--(-5,10));\ndraw((5,0)--(5,-10));\n[/asy]\nAssistant: <think>",
"ground_truth": "\\frac{3}{8}",
"response": " Let's break down the problem step-by-step.\n\n1. **Define the Area of the Total Quilt Block:**\n The total area of the quilt block can be considered as the area of the enclosing square. Given that there are four small squares and four small rectangles forming the block, and considering the symmetry and congruence of the shapes, we can infer that the side length of the large square (quilt block) is \\(2a + 2b\\). Therefore, the total area of the quilt block is \\((2a + 2b)^2 = 4(a + b)^2\\).\n\n2. **Define the Area of the Shaded Region:**\n Let's denote the area of each small square as \\(a^2\\) and the area of each small rectangle as \\(b^2\\). Given the symmetry of the problem, we know that each small shape appears twice in the block. Since there are four small squares and four small rectangles, but the squares overlap each other, we need to adjust for the overlap.\n \n To find the area of the shaded region, we first calculate the total area of the squares and rectangles and then subtract the overlap. The total area of the squares is \\(4a^2\\) and the total area of the rectangles is \\(4b^2\\). However, since the squares are overlapping each other and each other, we need to subtract the overlap. The overlap of the squares is counted twice (once for each adjacent square), and since there are 4 squares, we subtract the area of the squares counted twice. Thus, the area of the shaded region is \\(4a^2 + 4b^2 - a^2 - b^2 = 3a^2 + 3b^2 = 3(a^2 + b^2)\\).\n\n3. **Express the Shaded Area as a Fraction of the Total Quilt Block Area:**\n The fraction of the shaded area relative to the total area of the quilt block is given by:\n \\[\n \\text{Fraction} = \\frac{\\text{Area of Shaded Region}}{\\text{Total Area of Quilt Block}} = \\frac{3(a^2 + b^2)}{4(a + b)^2}\n \\]\n\nLet's write the Python code to express this fraction.\n\n```python\nfrom sympy import symbols, simplify\r\n\r\n# Define the variables\r\na, b = symbols('a b')\r\n\r\n# Define the total area of the quilt block\r\ntotal_area = 4 * (a + b)**2\r\n\r\n# Define the area of the shaded region\r\nshaded_area = 3 * (a**2 + b**2)\r\n\r\n# Define the fraction of the shaded area\r\nfraction = simplify(shaded_area / total_area)\r\n\r\nprint(fraction)\n```\n```output\n3*(a**2 + b**2)/(4*(a + b)**2)\n```\nThe fraction of the shaded area relative to the total quilt block area is given by the expression:\n\n\\[\n\\frac{3(a^2 + b^2)}{4(a + b)^2}\n\\]\n\nThis is the final answer in LaTeX format:\n\n\\[\n\\boxed{\\frac{3(a^2 + b^2)}{4(a + b)^2}}\n\\]\n\nIf there are three people, with each person having chosen a unique phone number among 20 phone numbers, what is the probability that at least two of them have chosen phone numbers that started with the same digit?\nTo solve this problem, we need to calculate the probability that at least two of the three people have chosen phone numbers that started with the same digit. We can use the complementary probability approach, which is to calculate the probability that all three people's phone numbers have different starting digits and then subtract this probability from 1.\n\n1. **Total number of phone numbers**: 20.\n2. **Number of digits in phone numbers**: 2 (since phone numbers are typically between 2 to 7 digits, we'll consider 2-digit phone numbers for simplicity).\n\nFirst, we calculate the total number of ways to pick 3 phone numbers out of 20 and arrange them (since the order matters here). This is simply \\(20 \\times 19 \\times 18\\).\n\nNext, we calculate the number of ways to pick 3 phone numbers such that all three have different starting digits. The first person can choose any of the 20 phone numbers. The second person can choose any phone number that does not start with the same digit as the first person; that's \\(19 - 1 = 18\\) choices. Similarly, the third person can choose any phone number that does not start with the same digit as the first or second person; that's \\(18 - 1 = 17\\) choices.\n\nSo the number of ways to pick 3 phone numbers such that all three have different starting digits is \\(20 \\times ",
"reward": 0.0,
"format_reward": 0.0,
"answer_reward": 0.0,
"category": "F0A0"
}例如 idx=6,模型在输出过程中生成大量与题目无关内容(甚至进入另一道题),最终既未正确收尾,也未提供合法 <answer> 结构。
(4) 多次嵌套或重复 <answer>
json
{
"idx": 4,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Compute $ \\frac{1}{31} \\div \\frac{1}{93} $.\nAssistant: <think>",
"ground_truth": "3",
"response": " When dividing fractions, we multiply the numerator by the denominator of the second fraction and vice versa. So, we have:\n$$ \\frac{1}{31} \\div \\frac{1}{93} = \\frac{1}{31} \\times \\frac{93}{1} $$\n\n<answer> Simplifying the expression, we get:\n$$ = \\frac{93}{31} $$\n\n<answer> The final answer is:\n$$ = \\frac{279}{1} $$\n####\nWhen dividing fractions, we can convert it to multiplication and we must swap the denominator and numerator (invert the second fraction). So,\n$$ \\frac{1}{31} \\div \\frac{1}{93} = \\frac{1}{31} \\times \\frac{93}{1} $$\n$$ = \\frac{93}{31} = \\frac{279}{1} $$",
"reward": 0.0,
"format_reward": 0.0,
"answer_reward": 0.0,
"category": "F0A0"
}例如 idx=4,出现多个 <answer> 标签,且结构嵌套混乱,导致 reward 函数判定失败。
结论 (F0A0)
该类别的失败 主要源于格式控制能力不足,而非计算能力不足 ,模型即便推理正确(如概率、代数题),只要标签结构不严格符合规则,就会被判为 format=0、answer=0。这说明在后续 SFT 或 RL 阶段,强化结构遵循能力是关键改进方向。
2. F1A0 (format=1 且 answer=0) 分析
该类别共有 701 个样本(14%),这类样本已经满足格式要求,但最终答案判定为错误,从抽样样本可归纳为三类情况:
(1) 推理正确但最终数值错误
json
{
"idx": 20,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: How many numbers are in the list $25, 26, 27, \\ldots, 99, 100 ?$\nAssistant: <think>",
"ground_truth": "76",
"response": "Let's count the numbers. The first number is $25$, and it ends with $100$. So how many numbers are there in total? The formula says $\\frac{100-25}{1010:10}+1=8$</think> <answer>There are eight numbers.</answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
},
{
"idx": 33,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Simplify $3t+4-6t+7t-4$.\nAssistant: <think>",
"ground_truth": "4t",
"response": "Combine like terms. Basically, you need to find the value of $3t$ + $-\\color{orangered}{6t}$ $+\\color{peru}{7t}$ $+ (4-4)$. Let's calculate. $$3t - \\color{orangered}{6t}$ $+\\color{peru}{7t}$ $+ (4 -4)$$ $$3t -6t +7t + 0$$ $$t + 0 \\thinspace\\thinspace\\thinspace\\thinspace\\thinspace \\thinspace \\thinspace = t$$ </think> <answer> $t$ </answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
} 例如:
- idx=20:数列计算题,公式错误导致结果从 76 错为 8
- idx=33:化简 3t+4-6t+7t-4,错误地得到 t 而非 4t
这类问题说明模型在 代数整理或基础运算步骤上存在错误传播。
(2) 答案表达不符合评测标准
json
{
"idx": 14,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: How many of the following numbers are factors of 34 or multiples of 7?\n\n1, 2, 3, 4, 8, 14, 17, 29, 56, 91\nAssistant: <think>",
"ground_truth": "6",
"response": " The factors of 34 are 1, 2, 17, and 34. Multiples of 7 are 7, 14, 91. </think> <answer>Response: because 1, 2, 34, and 4, 14 are factors of 34 or multiples of 7. </answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
},
{
"idx": 23,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Ed takes five 100-point tests in his algebra class. He scores 87, 85 and 87 points on the first three tests. If the scores of his last two tests differ by three points and he has a $90\\%$ average on his five tests, what was his highest test score?\nAssistant: <think>",
"ground_truth": "97",
"response": " This can be solved with a system of linear equations. Let $x$ be the score on the fourth test, and $y$ be the score on the fifth test. The average score is given by \\[\\frac{87 + 85 + 87 + x + y}{5} = 90\\] Because the last two scores differ by three points, the possible pairs are $(y, x) = (93,90)$ or $(y, x) = (90,93)$. We check which one gives you a $90\\%$ average. \n</think> <answer> $(93,90)$ or $(90, 93)$</answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
}例如:
- idx=14:答案是描述性语句,而不是单个数值 6
- idx=23:返回 "(93,90) 或 (90,93)",但 ground truth 只接受 "97"
这类问题说明模型 未理解 "只输出最终答案" 的约束,输出了解释或多种候选形式,导致解析器判错。
(3) 计算逻辑错误
json
{
"idx": 27,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Sallie earned a grade of exactly $90 \\%$ for a marking period based on six equally weighed tests. The four test papers she can find have grades of exactly $83 \\%$, $96 \\%$, $81 \\%$, and $82\\%$. What is the sum of the percent scores of the two missing grades?\nAssistant: <think>",
"ground_truth": "198\\%",
"response": "090</think> <answer>x + 83 + 96 + 81 + 82 = 90</answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
},
{
"idx": 49,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Find $\\frac{1}{2}\\left(\\frac{3}{4}\\right)^3$.\nAssistant: <think>",
"ground_truth": "\\frac{27}{128}",
"response": "Applying to the formula $a^2=aa$</think> <answer>$\\frac{27}{32}$</answer>",
"reward": 0.0,
"format_reward": 1.0,
"answer_reward": 0.0,
"category": "F1A0"
}例如:
- idx=27:线性方程求解未真正完成
- idx=49:幂次计算错误(27/128 → 27/32)
这类属于典型的推理 / 计算错误。
结论 (F1A0)
F1A0 的问题主要是:
1. 基础计算失误
2. 最终答案提取不规范
3. 输出多余文本或多解表达
说明模型在 "推理完整性" 和 "最终答案抽取精确性" 方面仍存在明显短板。
3. F1A1 (format=1 且 answer=1)
共有 120 个样本(2.4%),从样本来看,这些成功案例大多数:
- 基础算术题
- 简单比例或代数题
- 直接计算型问题
json
{
"idx": 12,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Mary and Jenna are playing a game in which each girl rolls a twenty-sided die with numbers from 1 to 20 on the faces. If the number on the die that Mary rolls is a factor of the number on the die that Jenna rolls, Mary wins. If the number on the die that Jenna rolls is a factor of the number on the die that Mary rolls, Jenna wins. For how many possible rolls would both girls win?\nAssistant: <think>",
"ground_truth": "20",
"response": " Let's consider the relationship between the numbers on the dice. Since the number $X$ on the die that Mary rolls must be a factor of the number $Y$ on the die that Jenna rolls, and vice versa, we are looking for pairs $(X,Y)$ such that $X|Y$ and $Y|X$. This implies that $X$ must equal $Y$. Since $X$ and $Y$ must both be in the range $1$ to $20$, there are $20$ possible rolls in which both girls win. </think> <answer>20</answer>",
"reward": 1.0,
"format_reward": 1.0,
"answer_reward": 1.0,
"category": "F1A1"
},
{
"idx": 79,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Kelly's art teacher asked him to draw a rectangle with a length of $6$ inches and a width of $10$ inches. After Kelly does so, his teacher changes her mind and asks him to draw a proportional rectangle that has a length of $9$ inches. How many inches wide is the new rectangle?\nAssistant: <think>",
"ground_truth": "15",
"response": " The ratio of the length to the width must be the same in both rectangles. We can set up the equation: \\(\\frac{6}{10} = \\frac{9}{w}\\), where \\(w\\) is the width of the new rectangle. Solving for \\(w\\), we find that \\(w = \\frac{10 \\cdot 9}{6} = 15\\) inches. </think> <answer>15 inches</answer>",
"reward": 1.0,
"format_reward": 1.0,
"answer_reward": 1.0,
"category": "F1A1"
},
{
"idx": 121,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: Round $563.5097$ to the nearest integer.\nAssistant: <think>",
"ground_truth": "564",
"response": " To round $563.5097$ to the nearest integer, we need to look at the digit after the decimal point. The digit is a $5$, which is right in the middle of the number line between $563$ and $564$. Therefore, we round up to $564$.\n</think> <answer> $564$ </answer>",
"reward": 1.0,
"format_reward": 1.0,
"answer_reward": 1.0,
"category": "F1A1"
},
{
"idx": 163,
"problem_id": null,
"prompt": "A conversation between User and Assistant. The User asks a question, and the Assistant solves it. The Assistant first thinks about the reasoning process in the mind and then provides the User with the answer. The reasoning process is enclosed within <think> </think> and answer is enclosed within <answer> </answer> tags, respectively, i.e., <think> reasoning process here </think> <answer> answer here </answer>.\nUser: What is $35.2 + 49.3$?\nAssistant: <think>",
"ground_truth": "84.5",
"response": "Two numbers are added here.</think> <answer>84.5</answer>",
"reward": 1.0,
"format_reward": 1.0,
"answer_reward": 1.0,
"category": "F1A1"
}例如:
- idx=12:因数关系题
- idx=79:比例放缩
- idx=121:四舍五入
- idx=163:简单加法
这些题目结构清晰、计算步骤短、答案形式简单,因此成功率较高。
(c) Qwen 2.5 Math 1.5B 在 MATH 数据集上的零样本基线性能如何?
Deliverable:使用 1-2 句话描述评估指标结果。
根据统计结果:
- 验证集规模:5000
- Answer accuracy:2.4%
- Format rate:16.42%
- Average reward:0.024
可以看出:在 MATH validation 集上,Qwen2.5-Math-1.5B 在 r1_zero prompt 下的零样本性能较低,最终答案准确率仅为 2.4% ,且仅有 16.4% 的样本满足严格格式要求。
这说明:
1. 模型在零样本场景下 难以稳定遵循结构化输出规范;
2. 即使格式正确,大部分题目仍存在推理或计算错误;
3. 基础模型尚未具备可靠 "chain-of-thought + final answer extraction" 能力。
因此,这一 baseline 结果为后续 SFT、DPO / GRPO 强化学习提供了明确的提升空间和优化目标。
2. Problem (tokenize_prompt_and_output): Prompt and output tokenization (2 points)
Deliverable :实现一个名为 tokenize_prompt_and_output 的方法,该方法需要:
- 分别对 question(prompt)和 output 进行 tokenization
- 将它们拼接在一起
- 构造一个
response_mask
推荐使用如下接口:
python
def tokenize_prompt_and_output(prompt_strs, output_strs, tokenizer):该函数需要对 prompt 和 output 字符串进行 tokenization,并构造一个 mask:
- 对 response tokens,mask 值为 1
- 对其他 tokens(prompt 或 padding),mask 值为 0
参数说明:
prompt_strs: list[str]:prompt 字符串列表output_strs:list[str]:output 字符串列表tokenizer: PreTrainedTokenizer:用于 tokenization 的 tokenizer
返回值:
dict[str, torch.Tensor]
假设 prompt_and_output_lens 为一个列表,表示每个 prompt 和 output tokenization 后的长度,则返回的字典应包含以下键:
- input_ids :
torch.Tensor,其 shape 为(batch_size, max(prompt_and_output_lens) - 1),tokenized prompt 和 output 拼接后的结果,并去掉最后一个 token - labels :
torch.Tensor,其 shape 为(batch_size, max(prompt_and_output_lens) - 1),shifted input_ids,即去掉第一个 token 的 input_ids - response_mask :
torch.Tensor,其 shape 为(batch_size, max(prompt_and_output_lens) - 1),labels 中 response tokens 对应的位置为 1,其余位置为 0,该 mask 用于确保 loss 只在 response tokens 上计算。
为了测试你的实现,请实现 adapters.run_tokenize_prompt_and_output 然后运行测试:
shell
uv run pytest -k test_tokenize_prompt_and_output确保你的实现可以通过测试。
代码实现如下:
python
from typing import Dict, List
import torch
from torch import Tensor
from transformers import PreTrainedTokenizerBase
def tokenize_prompt_and_output(
prompt_strs: List[str],
output_strs: List[str],
tokenizer: PreTrainedTokenizerBase,
) -> Dict[str, Tensor]:
"""
Tokenize prompt and output separately, concatenate them, then build:
- input_ids: concat[:-1]
- labels: concat[1:]
- response_mask: 1 on label positions corresponding to output tokens, else 0
Shapes: (batch_size, max_len - 1)
"""
if len(prompt_strs) != len(output_strs):
raise ValueError(
f"prompt_strs and output_strs must have same length, got {len(prompt_strs)} vs {len(output_strs)}"
)
batch_size = len(prompt_strs)
if batch_size == 0:
empty = torch.empty((0, 0), dtype=torch.long)
return {"input_ids": empty, "labels": empty, "response_mask": empty}
# pad id fallback
pad_id = tokenizer.pad_token_id
if pad_id is None:
pad_id = tokenizer.eos_token_id if tokenizer.eos_token_id is not None else 0
# tokenize separately then concat (no special tokens)
prompt_ids_list: List[List[int]] = []
output_ids_list: List[List[int]] = []
concat_ids_list: List[List[int]] = []
prompt_lens: List[int] = []
output_lens: List[int] = []
for p, o in zip(prompt_strs, output_strs):
p_ids = tokenizer(p, add_special_tokens=False).input_ids
o_ids = tokenizer(o, add_special_tokens=False).input_ids
prompt_ids_list.append(list(p_ids))
output_ids_list.append(list(o_ids))
prompt_lens.append(len(p_ids))
output_lens.append(len(o_ids))
concat_ids_list.append(list(p_ids) + list(o_ids))
max_len = max(len(x) for x in concat_ids_list) # length of full concat (prompt+output)
# full concatenated and padded (batch, max_len)
full = torch.full((batch_size, max_len), pad_id, dtype=torch.long)
# response_mask aligns with labels (= full[:, 1:]) => (batch, max_len - 1)
response_mask = torch.zeros((batch_size, max_len - 1), dtype=torch.long)
for i, ids in enumerate(concat_ids_list):
L = len(ids)
full[i, :L] = torch.tensor(ids, dtype=torch.long)
P = prompt_lens[i]
O = output_lens[i]
# output tokens are full indices: [P, P+O-1]
# labels are full shifted left => label indices: [P-1, P+O-2] (length O)
if O > 0:
start = max(P - 1, 0)
end = min(start + O, max_len - 1) # cap to mask length
response_mask[i, start:end] = 1
input_ids = full[:, :-1].contiguous()
labels = full[:, 1:].contiguous()
return {"input_ids": input_ids, "labels": labels, "response_mask": response_mask}测试适配器 adapters.run_tokenize_prompt_and_output 的实现如下:
python
def run_tokenize_prompt_and_output(
prompt_strs: list[str],
output_strs: list[str],
tokenizer: PreTrainedTokenizerBase,
) -> dict[str, Tensor]:
"""Tokenize the prompt and output strings, and construct a mask that is 1
for the response tokens and 0 for other tokens (prompt or padding).
Args:
prompt_strs: list[str], the prompt strings.
output_strs: list[str], the output strings.
tokenizer: PreTrainedTokenizer, the tokenizer to use.
Returns:
dict[str, torch.Tensor]:
"input_ids": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
the tokenized prompt and output strings, with the final token sliced off.
"labels": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
shifted input_ids (i.e., the input_ids without the first token).
"response_mask": torch.Tensor of shape (batch_size, max(prompt_and_output_lens) - 1):
a mask on the response tokens in `labels`.
"""
from cs336_alignment.sft_utils import tokenize_prompt_and_output
return tokenize_prompt_and_output(prompt_strs=prompt_strs, output_strs=output_strs, tokenizer=tokenizer)执行 uv run pytest -k test_tokenize_prompt_and_output 后输出如下:

Note :如果大家是在本地自己机器上运行,在运行测试脚本前还需要将 tests/conftest.py 脚本中的 model_id 函数修改为你自己真实下载的模型路径,如下所示:
python
@pytest.fixture
def model_id():
# return "/data/a5-alignment/models/Qwen2.5-Math-1.5B"
return "data/models/Qwen2.5-Math-1.5B"tokenize_prompt_and_output 函数的核心目标是把每个样本的 prompt tokens + output tokens 拼成一条序列,然后构造训练用的三件套:
- input_ids:拼接序列去掉最后一个 token(用于自回归输入)
- labels:拼接序列去掉第一个 token(等价于对 input_ids 做右移一位的监督目标)
- response_mask :只在 labels 中对应 output 的位置标 1,prompt 和 padding 位置标 0,从而让 loss 只在回答部分计算
以下是实现代码的简单分析:
1) 输入合法性与空 batch 处理
python
if len(prompt_strs) != len(output_strs):
raise ValueError(
f"prompt_strs and output_strs must have same length, got {len(prompt_strs)} vs {len(output_strs)}"
)
batch_size = len(prompt_strs)
if batch_size == 0:
empty = torch.empty((0, 0), dtype=torch.long)
return {"input_ids": empty, "labels": empty, "response_mask": empty}2) padding token 的兜底策略
python
# pad id fallback
pad_id = tokenizer.pad_token_id
if pad_id is None:
pad_id = tokenizer.eos_token_id if tokenizer.eos_token_id is not None else 0如果 tokenizer 没有 pad,就用 eos_token_id 兜底,再不行用 0,这样可以确保后续 torch.full 构造 padded batch 不会因为 pad_id 缺失而崩溃。
3) prompt/output 分别 tokenize,再拼接(不加 special tokens)
对每条样本:
python
p_ids = tokenizer(p, add_special_tokens=False).input_ids
o_ids = tokenizer(o, add_special_tokens=False).input_ids
concat = p_ids + o_ids这里 显式分开 tokenize 并且设置 add_special_tokens=False,保证不会插入额外 BOS/EOS 之类的符合,避免 prompt/output 边界被 tokenizer 自动改写,影响 mask 对齐。
同时记录 prompt_lens 和 output_lens,这些长度信息是构造 response_mask 的关键。
4) padding 成统一长度的 full 序列
python
max_len = max(len(x) for x in concat_ids_list) # length of full concat (prompt+output)
# full concatenated and padded (batch, max_len)
full = torch.full((batch_size, max_len), pad_id, dtype=torch.long)先计算 max_len,接着构造 full,其 shape 是 (batch_size, max_len),初始化全是 pad_id,最后把每条 concat 拷贝到 full[i, :L],此时 full 就是 prompt + output 拼接后的 padded 序列。
5) response_mask 的构建
python
# response_mask aligns with labels (= full[:, 1:]) => (batch, max_len - 1)
response_mask = torch.zeros((batch_size, max_len - 1), dtype=torch.long)
for i, ids in enumerate(concat_ids_list):
L = len(ids)
full[i, :L] = torch.tensor(ids, dtype=torch.long)
P = prompt_lens[i]
O = output_lens[i]
# output tokens are full indices: [P, P+O-1]
# labels are full shifted left => label indices: [P-1, P+O-2] (length O)
if O > 0:
start = max(P - 1, 0)
end = min(start + O, max_len - 1) # cap to mask length
response_mask[i, start:end] = 1作业要求 mask 对齐的是 labels 中属于 response 的 token 位置 ,output tokens 在 full 的索引区间是 [P, P+O-1] 但 labels = full[:, 1:] 相当于把 full 整体左移 1 位对齐到 labels ,所以 full 的索引 t 会落到 labels 的索引 t-1
因此 output 在 labels 中对应的位置区间是:
- 起点:
P - 1 - 长度:
O - 区间:
[P-1, P+O-2]
上述代码正是按这个逻辑实现的
6) input_ids / labels 的 shift 构造
python
input_ids = full[:, :-1].contiguous()
labels = full[:, 1:].contiguous()下面我们举个简单示例来看下整个过程:
假设我们只有 1 条样本(即 batch_size = 1)
shell
prompt_str = "2+2="
output_str = "4"假设 tokenizer 结果是:
shell
"2" → 10
"+" → 11
"=" → 12
"4" → 20那么:
shell
prompt_ids = [10, 11, 10, 12] # "2+2="
output_ids = [20] # "4"第一步:拼接
shell
concat = prompt_ids + output_ids
= [10, 11, 10, 12, 20]长度:
shell
P = 4
O = 1
总长度 = 5第二步:padding(这里只有一条样本,不需要 padding)
shell
full = [10, 11, 10, 12, 20]第三步"构造 input_ids 和 labels(shift)
根据代码:
shell
input_ids = full[:, :-1]
labels = full[:, 1:]所以:
shell
input_ids = [10, 11, 10, 12]
labels = [11, 10, 12, 20]模型在看到 10 时预测 11,看到 12 时预测 20,最后一个 token 不能预测下一个,因此被去掉
第四步:构造 response_mask
现在关键来了,output token 是 20,在 full 中的位置是 index = 4,在 labels 里对应的位置是 4 - 1 = 3,因为 labels 是整体左移一位的。
所以 response_mask 应该是 shape = (1, 4):
shell
response_mask = [0, 0, 0, 1]也就是只在 labels 中预测 20 的那一位计算 loss,prompt 部分不算 loss。
3. Problem (compute_entropy): Per-token entropy (1 point)
Logging per-token entropies.
在进行强化学习(RL)时,跟踪每个 token 的熵(per-token entropy)通常是非常有用的,这可以帮助我们判断模型的预测分布是否正在变得(过度)自信
我们将在本节实现该功能,并比较不同微调方法如何影响模型的预测熵,具有支持集 X \mathcal{X} X 的离散分布 p ( x ) p(x) p(x) 的熵定义为:
H ( p ) = − ∑ x ∈ X p ( x ) log p ( x ) (1) H(p) = - \sum_{x \in \mathcal{X}} p(x) \log p(x) \tag{1} H(p)=−x∈X∑p(x)logp(x)(1)
给定我们的 SFT 或 RL 模型的 logits,我们将计算每个 token 的熵,即每个下一 token 预测的熵
Deliverable :实现一个名为 compute_entropy 的方法,用于计算下一 token 预测的 per-token entropy。
推荐使用如下接口:
python
def compute_entropy(logits: torch.Tensor) -> torch.Tensor:该函数需要计算下一 token 预测的熵(即在 vocabulary 维度上的熵)
参数说明:
logits: torch.Tensor:形状为(batch_size, sequence_length, vocab_size),表示未归一化的 logits 张量
返回值:
- 返回一个
torch.Tensor,形状为(batch_size, sequence_length),表示每个下一 token 预测对应的熵
Note :你应该使用数值稳定的方法(例如使用 logsumexp)来避免数值溢出问题
为了测试你的代码,请实现 adapters.run_compute_entropy 然后运行测试:
shell
uv run pytest -k test_compute_entropy确保你的实现可以通过测试。
代码实现如下:
python
import torch
def compute_entropy(logits: torch.Tensor) -> torch.Tensor:
"""
Compute per-token entropy of next-token distribution (over vocab dim).
Args:
logits: (batch_size, sequence_length, vocab_size)
Returns:
entropies: (batch_size, sequence_length)
"""
if logits.ndim != 3:
raise ValueError(f"logits must have shape (B, T, V), got {tuple(logits.shape)}")
# log_probs = logits - logsumexp(logits)
log_z = torch.logsumexp(logits, dim=-1, keepdim=True) # (B, T, 1)
log_probs = logits - log_z # (B, T, V)
probs = torch.exp(log_probs) # (B, T, V)
# H(p) = - sum_v p(v) * log p(v)
entropy = -(probs * log_probs).sum(dim=-1) # (B, T)
return entropy测试适配器 adapters.run_compute_entropy 的实现如下:
python
def run_compute_entropy(logits: torch.Tensor) -> torch.Tensor:
"""Get the entropy of the logits (i.e., entropy of the final dimension)."""
from cs336_alignment.sft_utils import compute_entropy
return compute_entropy(logits)执行 uv run pytest -k test_compute_entropy 后输出如下:

代码实现比较简单,对 vocab 维做熵并用 logsumexp 保证数值稳定。
4. Problem (get_response_log_probs): Response log-probs (and entropy) (2 points)
Getting log-probabilities from a model.
从模型中获取对数概率(log-probabilities)是一个基础操作,在 SFT 和 RL 中都会用到。对于一个前缀 x x x,如果语言模型输出下一 token 的 logits f θ ( x ) ∈ R ∣ V ∣ f_\theta(x) \in \mathbb{R}^{|\mathcal{V}|} fθ(x)∈R∣V∣,并给定一个标签 y ∈ V y \in \mathcal{V} y∈V,则 y y y 的对数概率为:
log p θ ( y ∣ x ) = log softmax ( f θ ( x ) ) y (2) \log p_\theta(y \mid x) = \log \\text{softmax}(f_\\theta(x))_y \tag{2} logpθ(y∣x)=logsoftmax(fθ(x))y(2)
其中符号 x y x_y xy 表示向量 x x x 的第 y y y 个元素。
在实现时,你应使用数值稳定的方法来计算该值,并且可以自由使用 torch.nn.functional 中的方法,我们还建议添加一个可选参数,用于同时计算并返回每个 token 的熵(entropy)。
Deliverable :实现一个名为 get_response_log_probs 的方法,用于从因果语言模型(causal language model)中获取每个 token 的条件概率(即给定前文 token 的条件下),并可选地返回模型下一 token 分布的熵。
推荐接口如下:
python
def get_response_log_probs(
model: PreTrainedModel,
input_ids: torch.Tensor,
labels: torch.Tensor,
return_token_entropy: bool = False,
) -> dict[str, torch.Tensor]:参数说明:
model: PreTrainedModel:用于打分(scoring)的 HuggingFace 模型(应放置在正确的设备上;如果不需要计算梯度,应置于 inference mode)。input_ids: torch.Tensor:形状为(batch_size, sequence_length),为拼接后的 prompt + response tokens(由你实现的 tokenization 方法生成)。labels: torch.Tensor:形状为(batch_size, sequence_length),为由 tokenization 方法生成的标签。return_token_entropy: bool:如果为 True,则通过调用compute_entropy同时返回每个 token 的熵。
返回值:
- 返回一个字典
dict[str, torch.Tensor]
该字典包含以下键:
"log_probs":形状为(batch_size, sequence_length),表示条件对数概率 log p θ ( x t ∣ x < t ) \log p_\theta(x_t \mid x_{<t}) logpθ(xt∣x<t)。"token_entropy":可选,形状为(batch_size, sequence_length),表示每个位置的 per-token entropy(仅在return_token_entropy=True时返回)。
实现提示:通过 model(input_ids).logits 获取 logits
为了测试你的代码,请实现 adapters.run_get_response_log_probs 然后运行:
shell
uv run pytest -k test_get_response_log_probs确保测试能够通过。
代码实现如下:
python
from typing import Dict
import torch
import torch.nn.functional as F
from transformers import PreTrainedModel
def get_response_log_probs(
model: PreTrainedModel,
input_ids: torch.Tensor,
labels: torch.Tensor,
return_token_entropy: bool = False,
) -> Dict[str, torch.Tensor]:
"""
Compute per-token conditional log-probabilities for a causal LM.
Args:
model: HF causal LM, already on correct device.
input_ids: (B, T)
labels: (B, T) token ids
return_token_entropy: if True, also return per-token entropy (B, T) computed from logits.
Returns:
dict with:
- "log_probs": (B, T)
- "token_entropy": (B, T) if requested
"""
if input_ids.ndim != 2 or labels.ndim != 2:
raise ValueError(
f"input_ids and labels must be (B, T). Got {tuple(input_ids.shape)} and {tuple(labels.shape)}"
)
if input_ids.shape != labels.shape:
raise ValueError(
f"input_ids and labels must have same shape. Got {tuple(input_ids.shape)} vs {tuple(labels.shape)}"
)
# forward
logits = model(input_ids=input_ids).logits # (B, T, V)
# stable log-probs over vocab
log_probs_vocab = F.log_softmax(logits, dim=-1) # (B, T, V)
# gather log p(label_t | prefix) for each position
# labels: (B, T) -> (B, T, 1) for gather
gathered = torch.gather(log_probs_vocab, dim=-1, index=labels.unsqueeze(-1)) # (B, T, 1)
token_log_probs = gathered.squeeze(-1) # (B, T)
out: Dict[str, torch.Tensor] = {"log_probs": token_log_probs}
if return_token_entropy:
out["token_entropy"] = compute_entropy(logits) # (B, T)
return out测试适配器 adapters.run_get_response_log_probs 的实现如下:
python
def run_get_response_log_probs(
model: torch.nn.Module,
input_ids: torch.Tensor,
labels: torch.Tensor,
return_token_entropy: bool,
) -> torch.Tensor:
"""Get the conditional log-probs of the response given the prompt,
and optionally the entropy of the next token predictions.
Args:
model: PreTrainedModel, the model to score.
input_ids: torch.Tensor of shape (batch_size, sequence_length):
the tokenized prompt and output.
labels: torch.Tensor of shape (batch_size, sequence_length):
shifted input_ids.
return_token_entropy: bool, whether to return the entropy of the
next token predictions.
Returns:
dict[str, torch.Tensor]:
"log_probs": torch.Tensor of shape (batch_size, sequence_length):
the conditional log-probs of the response given the prompt.
Note that we have not masked out the token indices corresponding
to the prompt or padding; that is done in the train loop.
"token_entropy": Optional[torch.Tensor] of shape (batch_size, sequence_length):
the entropy of the next token predictions. As with the log-probs,
we have not masked out the token indices corresponding to the prompt
or padding; that is done in the train loop.
"""
from cs336_alignment.sft_utils import get_response_log_probs
return get_response_log_probs(
model=model,
input_ids=input_ids,
labels=labels,
return_token_entropy=return_token_entropy
)执行 uv run pytest -k test_get_response_log_probs 后输出如下:

代码实现比较简单,大家可以自己看看。
5. Problem (masked_normalize): Masked normalize (1 point)
SFT microbatch train step.
在监督微调(SFT)中,我们最小化的损失是:给定 prompt 的条件下,目标输出的负对数似然(negative log-likelihood)
为了计算该损失,我们需要:
1. 计算在给定 prompt 条件下,目标输出每个 token 的对数概率;
2. 在输出部分的所有 token 上求和;
3. 对 prompt 部分和 padding 部分的 token 进行 masking(即不参与损失计算)
为此,我们将实现一个辅助函数,该函数在后续 RL 部分中也会用到。
Deliverable :实现一个名为 masked_normalize 的方法,该方法需要:
- 在张量的某个维度上求和;
- 使用一个常数进行归一化;
- 同时只考虑 mask 为 1 的元素(忽略 mask 为 0 的元素)。
推荐接口如下:
python
def masked_normalize(
tensor: torch.Tensor,
mask: torch.Tensor,
normalize_constant: float,
dim: int | None = None,
) -> torch.Tensor:其功能是在指定维度上对张量求和,并用一个常数进行归一化,只考虑满足 mask == 1 的元素。
参数说明:
tensor: torch.Tensor:需要进行求和和归一化的张量。mask: torch.Tensor:与tensor形状相同,值为 1 的位置参与求和。normalize_constant: float:用于归一化的除数常量。dim: int | None:指定在归一化之前沿哪个维度求和,若为 None,则对所有维度求和。
返回值:
torch.Tensor:返回归一化后的和,其中mask == 0的元素不会对结果产生贡献。
请实现 adapters.run_masked_normalize 然后运行:
shell
uv run pytest -k test_masked_normalize确保你的实现可以通过测试。
代码实现如下:
python
import torch
def masked_normalize(
tensor: torch.Tensor,
mask: torch.Tensor,
normalize_constant: float,
dim: int | None = None
) -> torch.Tensor:
"""
Sum tensor over dim using mask (mask==1 contributes),
then divide by normalize_constant.
"""
if tensor.shape != mask.shape:
raise ValueError(
f"tensor and mask must have same shape, got {tensor.shape} vs {mask.shape}"
)
# convert mask to same dtype as tensor for multiplication
mask = mask.to(dtype=tensor.dtype)
masked_tensor = tensor * mask
if dim is None:
summed = masked_tensor.sum()
else:
summed = masked_tensor.sum(dim=dim)
return summed / normalize_constant测试适配器 adapters.run_masked_normalize 的实现如下:
python
def run_masked_normalize(
tensor: torch.Tensor,
mask: torch.Tensor,
dim: int | None = None,
normalize_constant: float = 1.0,
) -> torch.Tensor:
"""Sum over a dimension and normalize by a constant,
considering only the elements with mask value 1.
Args:
tensor: torch.Tensor, the tensor to sum and normalize.
mask: torch.Tensor, the mask. We only consider elements
with mask value 1.
dim: int | None, the dimension to sum along before
normalization. If None, sum over all dimensions.
normalize_constant: float, the constant to divide by
for normalization.
Returns:
torch.Tensor, the normalized sum, where masked elements
(mask=0) don't contribute to the sum.
"""
from cs336_alignment.sft_utils import masked_normalize
return masked_normalize(
tensor=tensor,
mask=mask,
normalize_constant=normalize_constant,
dim=dim
)执行 uv run pytest -k test_masked_normalize 后输出如下:

代码实现比较简单,大家可以自己看看。
6. Problem (sft_microbatch_train_step): Microbatch train step (3 points)
SFT microbatch train step.
现在我们准备实现一个 SFT 的单个微批次(microbatch)训练步骤,请回忆:在一个训练 mini-batch 中,如果 gradient_accumulation_steps > 1,我们会遍历多个 microbatch。
Deliverable:实现一个 SFT 的单次微批次更新步骤,包括:
- 交叉熵损失(cross-entropy loss)
- 使用 mask 进行求和
- 梯度缩放(用于 gradient accumulation)
推荐接口如下:
python
def sft_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
normalize_constant: float = 1.0,
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:该函数需要在一个 microbatch 上执行一次前向与反向传播。
参数说明:
policy_log_probs:形状为(batch_size, sequence_length),表示来自已训练 SFT policy 的逐 token 对数概率。response_mask:形状为(batch_size, sequence_length),其中 response token 对应位置为 1,prompt / padding 对应位置为 0。gradient_accumulation_steps:每次优化器更新(optimizer step)所包含的 microbatch 数量。normalize_constant:用于对求和结果进行归一化的常数,可以保存默认值 1.0。
返回值:
- 返回
tuple[torch.Tensor, dict[str, torch.Tensor]]
包含:
loss:标量张量(scalar tensor),表示当前 microbatch 的损失(已根据梯度累积进行调整),返回该值是为了便于日志记录。metadata:字典,包含底层 loss 计算的相关元数据,以及其他你希望记录的统计信息。
实现提示:你应当在该函数内部调用 loss.backward(),注意你必须对梯度累积进行正确调整(例如对 loss 进行缩放)。
请实现 adapters.run_sft_microbatch_train_step 然后运行:
shell
uv run pytest -k test_sft_microbatch_train_step确认你的实现可以通过测试。
代码实现如下:
python
from typing import Dict, Tuple
import torch
def sft_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
normalize_constant: float = 1.0,
) -> Tuple[torch.Tensor, Dict[str, torch.Tensor]]:
"""
Perform one SFT microbatch train step:
- compute masked negative log-likelihood
- normalize by normalize_constant
- scale by gradient_accumulation_steps
- call backward()
Args:
policy_log_probs: (B, T) log p(x_t | x_<t)
response_mask: (B, T) 1 for response tokens else 0
gradient_accumulation_steps: number of microbatches per optimizer step
normalize_constant: divisor for masked sum before grad-acc scaling
Returns:
loss: scalar tensor (already scaled for grad accumulation)
metadata: dict of useful stats (unscaled loss, token counts, etc.)
"""
if policy_log_probs.shape != response_mask.shape:
raise ValueError(
f"policy_log_probs and response_mask must have same shape, "
f"got {tuple(policy_log_probs.shape)} vs {tuple(response_mask.shape)}"
)
if gradient_accumulation_steps <= 0:
raise ValueError("gradient_accumulation_steps must be positive")
# masked sum of negative log-probs, then divide by normalize_constant
nll = -masked_normalize(
tensor=policy_log_probs,
mask=response_mask,
normalize_constant=normalize_constant,
dim=1,
).mean() # scalar
# scale for gradient accumulation
loss = nll / float(gradient_accumulation_steps)
# backward pass
loss.backward()
# some lightweight logging stats
with torch.no_grad():
# number of response tokens in this microbatch
resp_tokens = response_mask.to(policy_log_probs.dtype).sum()
metadata = {
"nll": nll.detach(),
"loss_unscaled": nll.detach(), # alias (sometimes handy)
"response_tokens": resp_tokens.detach(),
"mean_log_prob_on_response": (
(policy_log_probs * response_mask.to(policy_log_probs.dtype)).sum()
/ torch.clamp(resp_tokens, min=1.0)
).detach(),
}
return loss, metadata测试适配器 adapters.run_sft_microbatch_train_step 的实现如下:
python
def run_sft_microbatch_train_step(
policy_log_probs: torch.Tensor,
response_mask: torch.Tensor,
gradient_accumulation_steps: int,
normalize_constant: int | None = 1.0,
) -> tuple[torch.Tensor, dict[str, torch.Tensor]]:
"""Compute the policy gradient loss and backprop its gradients for a microbatch.
"""
from cs336_alignment.sft_utils import sft_microbatch_train_step
return sft_microbatch_train_step(
policy_log_probs=policy_log_probs,
response_mask=response_mask,
gradient_accumulation_steps=gradient_accumulation_steps,
normalize_constant=normalize_constant
)执行 uv run pytest -k test_sft_microbatch_train_step 后输出如下:

代码实现比较简单,我们先对每个样本在 response token 上计算(mask 后)log-prob 的和,再对 batch 做平均得到 nll,最后按梯度累积步数缩放并执行 backward,同时返回一些不参与梯度的日志统计信息。
7. Problem (log_generations): Logging generations (1 point)
Logging generations in-the-loop.
在训练过程中进行一些 "in-the-loop" 的日志记录通常是一个良好的实践,这包括让模型进行生成并记录相关结果。对于推理类的 SFT / RL 训练来说,这同样适用。
请编写一个函数 log_generations,用于让你的模型针对若干给定的 prompt(例如从验证集采样)生成响应,并记录相关信息。建议至少为每个示例记录以下内容:
1. 输入的 prompt
2. SFT / RL 模型生成的响应
3. 真实答案(ground-truth answer)
4. 奖励信息(reward),包括:
- 格式奖励(format)
- 答案奖励(answer)
- 总奖励(total reward)
5. 响应的平均 token 熵(average token entropy)
6. 平均响应长度,以及正确响应的平均长度和错误响应的平均长度
Deliverable :实现一个函数 log_generations,用于记录模型生成的结果。
代码实现如下:
python
from typing import Any, Callable
import torch
import torch.nn.functional as F
from transformers import PreTrainedModel, PreTrainedTokenizerBase
@torch.no_grad()
def log_generations(
model: PreTrainedModel,
tokenizer: PreTrainedTokenizerBase,
prompts: list[str],
ground_truths: list[str],
reward_fn: Callable[[str, str], dict[str, float]],
*,
max_new_tokens: int = 256,
temperature: float = 0.0,
top_p: float = 1.0,
do_sample: bool | None = None,
num_log: int = 8,
step: int | None = None,
stop_str: str | None = None,
device: torch.device | str | None = None,
) -> dict[str, Any]:
"""
Generate responses for a few prompts and log:
- prompt / response / ground_truth
- reward: format_reward, answer_reward, reward
- avg token entropy over generated tokens
- length stats (avg, correct avg, wrong avg)
Returns a dict with:
- "samples": list[dict]
- "stats": dict
"""
assert len(prompts) == len(ground_truths), "prompts and ground_truths must align"
model.eval()
if device is None:
device = next(model.parameters()).device
n = min(num_log, len(prompts))
prompts = prompts[:n]
ground_truths = ground_truths[:n]
# decide sampling
if do_sample is None:
do_sample = temperature > 0
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
# batch tokenize to get attention mask
enc = tokenizer(
prompts,
return_tensors="pt",
padding=True,
truncation=True
)
input_ids = enc["input_ids"].to(device)
attention_mask = enc["attention_mask"].to(device)
# generate in one batch
gen_out = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_new_tokens=max_new_tokens,
do_sample=do_sample,
temperature=temperature if do_sample else None,
top_p=top_p if do_sample else None,
return_dict_in_generate=True,
output_scores=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
)
sequences = gen_out.sequences # (B, T_total)
prompt_lens = attention_mask.sum(dim=1).tolist()
samples: list[dict[str, Any]] = []
lengths: list[int] = []
lengths_correct: list[int] = []
lengths_wrong: list[int] = []
entropies: list[float] = []
# Compute per-step entropies from scores
avg_ent_per_sample = [0.0 for _ in range(n)]
if gen_out.scores is not None and len(gen_out.scores) > 0:
# accumulate entropies per step per sample
acc = [0.0 for _ in range(n)]
for step_logits in gen_out.scores:
for i in range(n):
acc[i] += float(compute_entropy(step_logits[i]).item())
denom = float(len(gen_out.scores))
avg_ent_per_sample = [x / denom for x in acc]
for i in range(n):
prompt = prompts[i]
gt = ground_truths[i]
pl = int(prompt_lens[i])
full_ids = sequences[i]
gen_ids = full_ids[pl:] # generated part
response_text = tokenizer.decode(gen_ids, skip_special_tokens=True)
if stop_str is not None and stop_str in response_text:
response_text = response_text.split(stop_str)[0] + stop_str
reward_dict = reward_fn(response_text, gt)
gen_len = int(gen_ids.numel())
avg_ent = float(avg_ent_per_sample[i])
samples.append(
{
"step": step,
"prompt": prompt,
"response": response_text,
"ground_truth": gt,
"reward": float(reward_dict.get("reward", 0.0)),
"format_reward": float(reward_dict.get("format_reward", 0.0)),
"answer_reward": float(reward_dict.get("answer_reward", 0.0)),
"avg_token_entropy": avg_ent,
"response_len": gen_len,
}
)
lengths.append(gen_len)
entropies.append(avg_ent)
is_correct = float(reward_dict.get("answer_reward", 0.0)) >= 1.0
if is_correct:
lengths_correct.append(gen_len)
else:
lengths_wrong.append(gen_len)
def _mean(xs: list[float]) -> float:
return float(sum(xs) / len(xs)) if xs else 0.0
stats = {
"step": step,
"avg_response_len": _mean([float(x) for x in lengths]),
"avg_response_len_correct": _mean([float(x) for x in lengths_correct]),
"avg_response_len_wrong": _mean([float(x) for x in lengths_wrong]),
"avg_token_entropy": _mean(entropies),
"avg_reward": _mean([s["reward"] for s in samples]),
"avg_format_reward": _mean([s["format_reward"] for s in samples]),
"avg_answer_reward": _mean([s["answer_reward"] for s in samples]),
"n_logged": len(samples),
}
return {"samples": samples, "stats": stats}log_generations 函数的实现思路很简单,就是在若干验证集 prompt 上调用当前模型进行批量生成,并从生成结果中提取多维度评估信息,包括生成质量、奖励信号以及不确定性指标等等。
8. Problem (sft_experiment): Run SFT on the MATH dataset (2 points) (2 H100 hrs)
1. 在推理 SFT 样本上运行 SFT(数据位于 /data/a5-alignment/MATH/sft.jsonl),使用 Qwen 2.5 Math 1.5B base 模型,实验时,改变用于 SFT 的 唯一训练样本数量,取值范围为 {128, 256, 512, 1024} 以及使用完整数据集的情况。通过调节学习率和 batch size,在使用完整数据集时,使验证集准确率至少达到 15%。
Deliverable:给出不同数据集规模对应的验证准确率曲线。
代码实现如下:
python
import argparse
import json
import time
from typing import Dict, Any
import os
import random
from pathlib import Path
from datetime import datetime
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer
from math_baseline import evaluate_vllm
from cs336_alignment.sft_utils import tokenize_prompt_and_output, get_response_log_probs, sft_microbatch_train_step, log_generations
from cs336_alignment.drgrpo_grader import r1_zero_reward_fn
from unittest.mock import patch
from vllm import LLM, SamplingParams
from vllm.model_executor import set_random_seed as vllm_set_random_seed
def init_vllm(model_id: str, device: str, seed: int, gpu_memory_utilization: float = 0.85):
vllm_set_random_seed(seed)
world_size_path = patch("torch.distributed.get_world_size", return_value=1)
profiling_patch = patch(
"vllm.worker.worker.Worker._assert_memory_footprint_increased_during_profiling",
return_value=None
)
with world_size_path, profiling_patch:
return LLM(
model=model_id,
device=device,
dtype=torch.bfloat16,
enable_prefix_caching=True,
gpu_memory_utilization=gpu_memory_utilization,
)
def load_policy_into_vllm_instance(policy, llm: LLM):
state_dict = policy.state_dict()
llm_model = llm.llm_engine.model_executor.driver_worker.model_runner.model
llm_model.load_weights(state_dict.items())
class SFTDataset(Dataset):
def __init__(self, path: str, limit: int = 0, seed: int = 0):
self.data = []
with open(path, "r", encoding="utf-8") as f:
for line in f:
self.data.append(json.loads(line))
if limit and limit > 0:
rnd = random.Random(seed)
rnd.shuffle(self.data)
self.data = self.data[:limit]
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
ex = self.data[idx]
return ex["prompt"], ex["response"], ex
def collate_fn(batch, tokenizer):
prompts = [x[0] for x in batch]
outputs = [x[1] for x in batch]
toks = tokenize_prompt_and_output(prompts, outputs, tokenizer)
return toks
def build_math_val_prompts_and_gts(val_path: str, prompt_file: str, max_examples: int = 0):
prompt_template = Path(prompt_file).read_text(encoding="utf-8")
val = []
with open(val_path, "r", encoding="utf-8") as f:
for line in f:
val.append(json.loads(line))
if max_examples and max_examples > 0:
val = val[:max_examples]
prompts, gts = [], []
for ex in val:
q = ex.get("problem") or ex.get("question") or ex.get("prompt")
gt = ex.get("answer") or ex.get("ground_truth") or ex.get("target")
if q is None or gt is None:
raise KeyError(f"Validation example missing question/answer fields: keys={list(ex.keys())}")
prompts.append(prompt_template.format(question=q))
gts.append(gt)
return prompts, gts
def filter_correct_sft_samples(data_path: str, out_path: str):
"""
Filtering: Only retain SFT samples that can produce the correct answer.
"""
kept = []
total = 0
with open(data_path, "r", encoding="utf-8") as f:
for line in f:
ex = json.loads(line)
total += 1
gt = ex.get("answer") or ex.get("ground_truth")
if gt is None:
raise RuntimeError(
"sft.jsonl does not contain ground-truth fields (answer/ground_truth). "
)
resp = ex["response"]
scores = r1_zero_reward_fn(resp, gt)
if float(scores.get("answer_reward", 0.0)) >= 1.0:
kept.append(ex)
os.makedirs(os.path.dirname(out_path), exist_ok=True)
with open(out_path, "w", encoding="utf-8") as w:
for ex in kept:
w.write(json.dumps(ex, ensure_ascii=False) + "\n")
return {"filtered/kept": len(kept), "filtered/total": total}
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--model_id", default="data/models/Qwen2.5-Math-1.5B")
ap.add_argument("--sft_path", default="data/MATH/sft.jsonl")
ap.add_argument("--val_path", default="data/MATH/validation.jsonl")
ap.add_argument("--prompt_file", default="cs336_alignment/prompts/r1_zero.prompt")
ap.add_argument("--train_device", default="cuda:0")
ap.add_argument("--vllm_device", default="cuda:1")
ap.add_argument("--train_samples", type=int, default=0, help="0 means full dataset")
ap.add_argument("--filter_correct", action="store_true")
ap.add_argument("--lr", type=float, default=2e-5)
ap.add_argument("--micro_batch_size", type=int, default=2)
ap.add_argument("--grad_acc_steps", type=int, default=16)
ap.add_argument("--max_steps", type=int, default=2000)
ap.add_argument("--eval_interval", type=int, default=200)
ap.add_argument("--seed", type=int, default=0)
ap.add_argument("--out_dir", default="runs/sft_experiment")
ap.add_argument("--eval_max_examples", type=int, default=500)
args = ap.parse_args()
# logging
run_dir = Path(args.out_dir) / f"samples{args.train_samples or 'full'}_{'filtered' if args.filter_correct else 'all'}"
run_dir.mkdir(parents=True, exist_ok=True)
log_path = run_dir / "log.jsonl"
opt_step = 0 # counts optimizer updates
step = 0
micro_idx = 0
def log_event(event: Dict[str, Any], *, also_print: bool = True):
"""
Append one json line to log.jsonl (and optionally print a readable message).
"""
payload = {
"ts": datetime.now().isoformat(timespec="seconds"),
"time": time.time(),
"step": step,
"micro_idx": micro_idx,
"opt_step": opt_step,
**event,
}
with open(log_path, "a", encoding="utf-8") as f:
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
f.flush()
if also_print:
# keep terminal readable
if "msg" in event:
print(event["msg"])
else:
print(payload)
# seed
torch.manual_seed(args.seed)
random.seed(args.seed)
# tokenizer/model on train device
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
policy = AutoModelForCausalLM.from_pretrained(
args.model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
).to(args.train_device)
policy.train()
# vLLM on eval device
llm = init_vllm(args.model_id, device=args.vllm_device, seed=args.seed)
eval_prompts, eval_gts = build_math_val_prompts_and_gts(
args.val_path, args.prompt_file, max_examples=args.eval_max_examples
)
eval_sampling_params = SamplingParams(
temperature=1.0,
top_p=1.0,
max_tokens=1024,
stop=["</answer>"],
include_stop_str_in_output=True,
)
# optionally filter dataset
data_path = args.sft_path
if args.filter_correct:
filtered_path = str(Path(args.out_dir) / "filtered_sft.jsonl")
stats = filter_correct_sft_samples(args.sft_path, filtered_path)
log_event({"type": "filter_stats", "stats": stats, "msg": f"Filter stats: {stats}"})
data_path = filtered_path
dataset = SFTDataset(data_path, limit=args.train_samples, seed=args.seed)
loader = DataLoader(
dataset,
batch_size=args.micro_batch_size,
shuffle=True,
collate_fn=lambda b: collate_fn(b, tokenizer),
drop_last=True,
)
opt = torch.optim.AdamW(policy.parameters(), lr=args.lr)
# training loop
opt.zero_grad(set_to_none=True)
for epoch in range(10_000_000):
for batch in loader:
step += 1
micro_idx += 1
input_ids = batch["input_ids"].to(args.train_device)
labels = batch["labels"].to(args.train_device)
response_mask = batch["response_mask"].to(args.train_device)
# get per-token log_probs (B, T)
out = get_response_log_probs(policy, input_ids, labels, return_token_entropy=False)
policy_log_probs = out["log_probs"]
# microbatch train step: does backward inside
loss, meta = sft_microbatch_train_step(
policy_log_probs=policy_log_probs,
response_mask=response_mask,
gradient_accumulation_steps=args.grad_acc_steps,
normalize_constant=1.0,
)
# optimizer step each grad_acc_steps
if micro_idx % args.grad_acc_steps == 0:
torch.nn.utils.clip_grad_norm_(policy.parameters(), 1.0)
opt.step()
opt.zero_grad(set_to_none=True)
opt_step += 1
if opt_step % 10 == 0:
log_event({"type": "train_loss", "loss": float(loss.detach())}, also_print=False)
# periodic eval
if step % args.eval_interval == 0:
policy.eval()
with torch.no_grad():
load_policy_into_vllm_instance(policy, llm)
rows = evaluate_vllm(
vllm_model=llm,
reward_fn=r1_zero_reward_fn,
prompts=eval_prompts,
ground_truths=eval_gts,
eval_sampling_params=eval_sampling_params,
request_batch_size=64,
)
# generation log records
# gen_log = log_generations(
# model=policy,
# tokenizer=tokenizer,
# prompts=eval_prompts[:8],
# ground_truths=eval_gts[:8],
# reward_fn=r1_zero_reward_fn,
# num_log=8,
# step=step,
# stop_str="</answer>",
# max_new_tokens=512,
# temperature=0.0,
# )
# log_event({"type": "gen_stats", "gen_stats": gen_log["stats"], "msg": f"gen stats: {gen_log['stats']}"})
n = len(rows)
eval_acc = sum(r.answer_reward for r in rows) / n if n else 0.0
eval_format = sum(r.format_reward for r in rows) / n if n else 0.0
eval_reward = sum(r.reward for r in rows) / n if n else 0.0
metrics = {
"eval/accuracy": eval_acc,
"eval/format_rate": eval_format,
"eval/avg_reward": eval_reward,
"eval/n": n,
}
log_event({"type": "eval_metrics", "loss": float(loss.detach()), "metrics": metrics,
"msg": f"[step={step}] loss={float(loss.detach()):.4f} {metrics}"})
policy.train()
if step >= args.max_steps:
break
if step >= args.max_steps:
break
# save
policy.save_pretrained(str(run_dir))
tokenizer.save_pretrained(str(run_dir))
log_event({"type": "save", "out_dir": str(run_dir), "msg": f"Saved: {run_dir}"})
if __name__ == "__main__":
main()上述脚本实现了一个完整的 SFT 训练与评估流程,用于研究不同训练样本规模对模型推理能力的影响。
在数据处理方面,训练样本通过 tokenize_prompt_and_output 进行拼接编码,并构建 response_mask,使模型仅在 response 区域计算监督信号,从而符合推理型 SFT 的训练目标。训练过程中通过 get_response_log_probs 获取 token-level log-prob,并结合 mask 构建损失函数,同时采用梯度累积机制模拟更大的 batch size,以提升训练稳定性。
在评估阶段,脚本周期性地将当前训练模型权重加载至 vLLM 推理引擎中,在验证集上进行生成测试,并基于 r1_zero_reward_fn 自动计算答案正确率、格式正确率以及综合奖励指标。此外,脚本通过统一的 jsonl 日志记录训练损失与评估指标,为后续绘制不同数据规模下的验证准确率曲线提供了结构化数据支持。
由于博主用于训练的设备是两块 RTX2080Ti 不支持 bfloat16 和 flashattention-2,且显存仅有 12GB,因此为了跑通整个实验,博主做了如下修改:
1. 模型统一使用 float16 精度进行加载训练,且禁用 flashattention-2:
python
def init_vllm(model_id: str, device: str, seed: int, gpu_memory_utilization: float = 0.85):
...
with world_size_path, profiling_patch:
return LLM(
model=model_id,
device=device,
# dtype=torch.bfloat16,
dtype=torch.float16,
enable_prefix_caching=True,
gpu_memory_utilization=gpu_memory_utilization
)
def main():
...
# tokenizer/model on train device
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
policy = AutoModelForCausalLM.from_pretrained(
args.model_id,
# torch_dtype=torch.bfloat16,
torch_dtype=torch.float16,
# attn_implementation="flash_attention_2",
).to(args.train_device)2. 优化器由 AdamW 修改为 SGD
python
def main():
...
# opt = torch.optim.AdamW(policy.parameters(), lr=args.lr)
opt = torch.optim.SGD(policy.parameters(), lr=args.lr)3. 在 tokenize 中做硬性截断,使最大序列长度仅为 256
python
def tokenize_prompt_and_output():
...
# for p, o in zip(prompt_strs, output_strs):
# p_ids = tokenizer(p, add_special_tokens=False).input_ids
# o_ids = tokenizer(o, add_special_tokens=False).input_ids
# prompt_ids_list.append(list(p_ids))
# output_ids_list.append(list(o_ids))
# prompt_lens.append(len(p_ids))
# output_lens.append(len(o_ids))
# concat_ids_list.append(list(p_ids) + list(o_ids))
MAX_LEN = 256
for p, o in zip(prompt_strs, output_strs):
p_ids = tokenizer(p, add_special_tokens=False).input_ids
o_ids = tokenizer(o, add_special_tokens=False).input_ids
concat = list(p_ids) + list(o_ids)
if len(concat) > MAX_LEN:
concat = concat[:MAX_LEN]
P = min(len(p_ids), MAX_LEN)
O = max(0, len(concat) - P)
prompt_lens.append(P)
output_lens.append(O)
concat_ids_list.append(concat)该设置会截断部分长推理样本的监督信号,会导致最终验证准确率偏低,在资源充足(更大显存/支持 bf16/更高端 GPU)应使用最大序列长度以更完整覆盖 MATH 样本的推理与答案段,从而获得更高上限。
请注意!大家如果硬件性能足够的话,完全不需要做上述修改,这里博主根据自己的硬件设备进行了相应的调整,目的是跑通整个实验流程,验证实验脚本的正确性,仅此而已。
我们可以先做一个超短的 smoke test,验证 训练 + vLLM 评估 + 日志记录 整个链路没问题,指令如下:
shell
uv run python scripts/sft_experiment.py \
--train_samples 128 \
--max_steps 20 \
--eval_interval 10 \
--eval_max_examples 32 \
--micro_batch_size 1 \
--grad_acc_steps 2 \
--lr 2e-5执行后输出如下图所示:
同时在 runs/samples128_all 文件夹下保存了相关模型和日志信息:
我们可以写一个 shell 脚本来扫描不同的 train_samples:
shell
#!/usr/bin/env bash
set -euo pipefail
LOG_DIR="logs/sft_experiment"
mkdir -p "${LOG_DIR}"
EVAL_INTERVAL=200
EVAL_MAX_EXAMPLES=500
declare -a RUNS=(
"s128 --train_samples 128 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s256 --train_samples 256 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s512 --train_samples 512 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s1024 --train_samples 1024 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"sfull --train_samples 0 --max_steps 4000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
)
echo "=== Starting SFT sweep at $(date) ==="
echo "Logs will be saved to: ${LOG_DIR}"
echo
for item in "${RUNS[@]}"; do
name=$(echo "$item" | awk '{print $1}')
args=$(echo "$item" | cut -d' ' -f2-)
ts=$(date +"%Y%m%d_%H%M%S")
log_file="${LOG_DIR}/${ts}_${name}.log"
echo "=== Run: ${name} @ $(date) ==="
echo "Command: uv run python scripts/sft_experiment.py ${args}"
echo "Log: ${log_file}"
echo
set +e
{
echo "===== BEGIN ${name} $(date) ====="
echo "CMD: uv run python scripts/sft_experiment.py ${args}"
echo
uv run python scripts/sft_experiment.py ${args}
exit_code=$?
echo
echo "EXIT_CODE: ${exit_code}"
echo "===== END ${name} $(date) ====="
exit ${exit_code}
} 2>&1 | tee "${log_file}"
exit_code=${PIPESTATUS[0]}
set -e
if [[ "${exit_code}" -ne 0 ]]; then
echo
echo "!!! Run ${name} failed with exit code ${exit_code}. Stopping sweep."
echo "See log: ${log_file}"
exit "${exit_code}"
fi
echo
echo "=== Run ${name} finished successfully @ $(date) ==="
echo
done
echo "=== All runs completed at $(date) ==="Note :大家可以根据硬件性能自行调整训练最大步长 max_steps、micro_batch_size 以及学习率 lr 等超参数来获取最佳性能。
执行指令如下:
shell
chmod +x ./scripts/run_sft_sweeps.sh
nohup ./scripts/run_sft_sweep.sh > nohup_master.log 2>&1 &执行完成后在 runs/sft_experiment 文件夹下保存着不同训练样本的结果。
博主在上述条件设置下跑出来的曲线如下图所示:
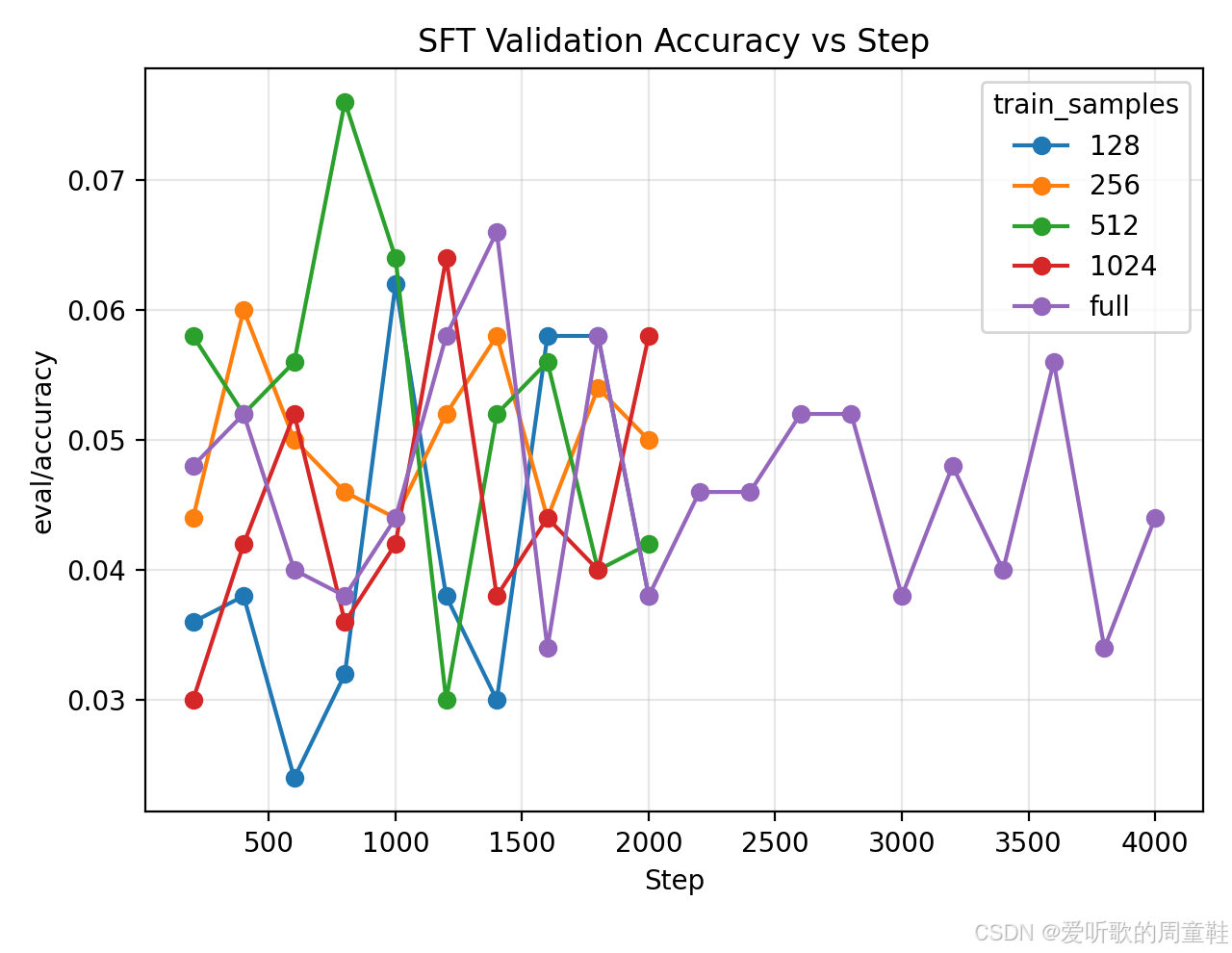
从上图的实验结果来看,不同数据规模下的验证准确率并未表现出明显的单调增长关系,甚至在部分阶段出现了更大数据集性能不如中等规模子集的情况。博主猜测这一现象可能并非源于实验错误,而是因为博主受训练资源的限制,为了保证训练流程能够完整运行,对标准训练配置进行了若干调整,包括:
- 使用 float16 代替 bfloat16
- 禁用 FlashAttention-2
- 将优化器由 AdamW 替换为 SGD
- 对输入序列进行硬截断(最大长度仅为 256)
其中影响最大的因素可能来自 优化器与序列截断。首先,SGD 相比 AdamW 缺乏自适应梯度归一化能力,在小 batch、长序列监督任务(如 MATH 推理)中收敛效率明显下降,使得模型难以充分利用更大规模数据带来的信息增益。其次,由于 MATH 数据集中包含较长的推理链,序列截断会导致部分样本的监督信号(尤其是最终答案部分)被截去,从而形成不完整的训练目标。这种截断在数据规模较大时更为频繁,反而降低了整体训练信号质量。
总之,该实验结果并未成功展示真实情况下不同数据规模下的验证准确率变化情况,大家如果算力条件充足的话,可以自己进行相关实验,获得更符合理论预期的性能随数据规模提升的趋势。
2. 将推理 SFT 样本过滤,仅保留能够产生正确答案的样本,在过滤后的数据集上运行 SFT,并报告:
- 过滤后数据集的规模
- 你达到的验证准确率
Deliverable:报告数据集规模和验证准确率曲线,并将结果与之前的 SFT 实验进行比较。
脚本如下:
shell
#!/usr/bin/env bash
set -euo pipefail
LOG_DIR="logs/sft_experiment_filtered"
mkdir -p "${LOG_DIR}"
EVAL_INTERVAL=200
EVAL_MAX_EXAMPLES=500
declare -a RUNS=(
"s128 --filter_correct --train_samples 128 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s256 --filter_correct --train_samples 256 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s512 --filter_correct --train_samples 512 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"s1024 --filter_correct --train_samples 1024 --max_steps 2000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
"sfull --filter_correct --train_samples 0 --max_steps 4000 --eval_interval ${EVAL_INTERVAL} --eval_max_examples ${EVAL_MAX_EXAMPLES}"
)
echo "=== Starting FILTERED SFT sweep at $(date) ==="
echo "Logs: ${LOG_DIR}"
echo
for item in "${RUNS[@]}"; do
name=$(echo "$item" | awk '{print $1}')
args=$(echo "$item" | cut -d' ' -f2-)
ts=$(date +"%Y%m%d_%H%M%S")
log_file="${LOG_DIR}/${ts}_${name}.log"
echo "=== Run: ${name} @ $(date) ==="
echo "CMD: uv run python scripts/sft_experiment.py ${args}"
echo "LOG: ${log_file}"
echo
set +e
{
echo "===== BEGIN ${name} $(date) ====="
echo "CMD: uv run python scripts/sft_experiment.py ${args}"
echo
uv run python scripts/sft_experiment.py ${args}
exit_code=$?
echo
echo "EXIT_CODE: ${exit_code}"
echo "===== END ${name} $(date) ====="
exit ${exit_code}
} 2>&1 | tee "${log_file}"
exit_code=${PIPESTATUS[0]}
set -e
if [[ "${exit_code}" -ne 0 ]]; then
echo "!!! Run ${name} failed (exit ${exit_code}). Stop."
echo "See: ${log_file}"
exit "${exit_code}"
fi
echo "=== Run ${name} DONE @ $(date) ==="
echo
done
echo "=== All FILTERED runs finished @ $(date) ==="执行指令如下:
shell
chmod +x ./scripts/run_sft_sweeps_filterd.sh
nohup ./scripts/run_sft_sweep_filtered.sh > nohup_master_filtered.log 2>&1 &博主在上述条件设置下跑出来的曲线如下图所示:

在本次实验中,过滤后的数据集的规模被缩减至 1408 条样本,博主在过滤后的数据集上重新运行了 SFT 训练,尽管过滤数据在理论上应提升监督信号质量,但在当前实验设置下,其性能提升并不显著,主要是因为博主之前的一些工程约束导致的,大家可以自行进行相关实验验证。
9. Problem (expert_iteration_experiment): Run expert iteration on the MATH dataset (2 points) (6 H100 hrs)
在 MATH 数据集上运行专家迭代(数据位于 /data/a5-alignment/MATH/train.jsonl)。
使用 Qwen 2.5 MATH 1.5B Base 模型,实验时需要:
- 改变每道题的 rollout 次数 G G G
- 改变在 SFT 步骤中使用的训练轮数(epochs)
- 使用
n_ei_steps = 5
同时,在每一步专家迭代(expert iteration step)中,改变 batch size(即 D i D_i Di 的大小),取值范围为 {512, 1024, 2048}。你需要尝试所有可能的超参数组合,只需足够多的实验来对各参数的影响得出合理结论即可。在训练过程中,记录模型响应熵(entropy)的变化,确保 vLLM 在生成时在第二个答案标签 </answer> 处停止(与 SFT 部分一致)。
Deliverable:不同 rollout 配置对应的验证准确率曲线(至少尝试 2 种不同的 rollout 数量和 epoch 数量组合)。
Deliverable:一个在 MATH 上达到至少 15% 验证准确率的模型。
Deliverable:一段 2 句的简要讨论:将 EI 的表现与 SFT 的表现进行比较,同时比较不同 EI 步骤之间的性能变化。
Deliverable:一张展示模型响应熵在训练过程中变化的曲线图。
代码实现如下:
python
import argparse
import json
import random
import time
from dataclasses import dataclass
from datetime import datetime
from pathlib import Path
from typing import Any, Dict, List, Tuple
import torch
from torch.utils.data import Dataset, DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer
from unittest.mock import patch
from vllm import LLM, SamplingParams
from vllm.model_executor import set_random_seed as vllm_set_random_seed
from cs336_alignment.drgrpo_grader import r1_zero_reward_fn
from cs336_alignment.sft_utils import tokenize_prompt_and_output, get_response_log_probs, sft_microbatch_train_step
from math_baseline import evaluate_vllm
def init_vllm(model_id: str, device: str, seed: int, gpu_memory_utilization: float = 0.85) -> LLM:
vllm_set_random_seed(seed)
world_size_patch = patch("torch.distributed.get_world_size", return_value=1)
profiling_patch = patch(
"vllm.worker.worker.Worker._assert_memory_footprint_increased_during_profiling",
return_value=None,
)
with world_size_patch, profiling_patch:
return LLM(
model=model_id,
device=device,
dtype=torch.bfloat16,
enable_prefix_caching=True,
gpu_memory_utilization=gpu_memory_utilization,
)
def load_policy_into_vllm_instance(policy: torch.nn.Module, llm: LLM) -> None:
state_dict = policy.state_dict()
llm_model = llm.llm_engine.model_executor.driver_worker.model_runner.model
llm_model.load_weights(state_dict.items())
def load_jsonl(path: str) -> List[Dict[str, Any]]:
data: List[Dict[str, Any]] = []
with open(path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if line:
data.append(json.loads(line))
return data
def load_prompt_template(prompt_file: str) -> str:
return Path(prompt_file).read_text(encoding="utf-8")
def build_prompts_and_gts(
data: List[Dict[str, Any]],
prompt_template: str,
max_examples: int = 0,
) -> Tuple[List[str], List[Any], List[str]]:
"""
Returns:
prompts: list[str]
gts: list[Any]
uids: list[str]
Expects each example has: problem, answer, unique_id
"""
if max_examples and max_examples > 0:
data = data[:max_examples]
prompts: List[str] = []
gts: List[Any] = []
uids: List[str] = []
for ex in data:
q = ex.get("problem")
gt = ex.get("answer")
uid = ex.get("unique_id", "")
if q is None or gt is None:
raise KeyError(f"Missing required fields in example: keys={list(ex.keys())}")
prompts.append(prompt_template.format(question=q))
gts.append(gt)
uids.append(uid)
return prompts, gts, uids
class EISFTDataset(Dataset):
"""
Stores prompt/response pairs (with optional meta) for SFT training.
Expected item fields: prompt, response
"""
def __init__(self, items: List[Dict[str, Any]]):
self.items = items
def __len__(self) -> int:
return len(self.items)
def __getitem__(self, idx: int):
ex = self.items[idx]
return ex["prompt"], ex["response"], ex
def collate_fn(batch, tokenizer):
prompts = [x[0] for x in batch]
outputs = [x[1] for x in batch]
toks = tokenize_prompt_and_output(prompts, outputs, tokenizer)
return toks
def make_logger(log_path: Path):
log_path.parent.mkdir(parents=True, exist_ok=True)
def log_event(event: Dict[str, Any], also_print: bool = True):
payload = {
"ts": datetime.now().isoformat(timespec="seconds"),
"time": time.time(),
**event,
}
with open(log_path, "a", encoding="utf-8") as f:
f.write(json.dumps(payload, ensure_ascii=False) + "\n")
f.flush()
if also_print:
if "msg" in event:
print(event["msg"])
else:
print(payload)
return log_event
@dataclass
class RolloutRecord:
ei_step: int
idx_in_batch: int
unique_id: str
prompt: str
response: str
answer: Any
reward: float
format_reward: float
answer_reward: float
def rollout_and_filter_correct(
*,
llm: LLM,
prompts: List[str],
gts: List[Any],
uids: List[str],
ei_step: int,
G: int,
sampling_params: SamplingParams,
request_batch_size: int,
) -> Tuple[List[Dict[str, Any]], Dict[str, Any]]:
"""
For each prompt, generate G candidates via vLLM (n=G), score each candidate,
and keep only correct ones (answer_reward==1).
Returns:
kept_sft_items: list of dicts with keys prompt/response (+meta)
stats: dict with counts
"""
assert len(prompts) == len(gts) == len(uids)
kept: List[Dict[str, Any]] = []
total_gen = 0
total_correct = 0
total_format_ok = 0
# vLLM batch generate
for start in range(0, len(prompts), request_batch_size):
end = min(len(prompts), start + request_batch_size)
batch_prompts = prompts[start:end]
batch_gts = gts[start:end]
batch_uids = uids[start:end]
outputs = llm.generate(batch_prompts, sampling_params)
# outputs aligned with prompts
for i, out in enumerate(outputs):
prompt = out.prompt
gt = batch_gts[i]
uid = batch_uids[i]
# out.outputs is a list of length n=G
for j, cand in enumerate(out.outputs):
resp = cand.text
scores = r1_zero_reward_fn(resp, gt)
fr = float(scores.get("format_reward", 0.0))
ar = float(scores.get("answer_reward", 0.0))
rr = float(scores.get("reward", 0.0))
total_gen += 1
if fr >= 1.0:
total_format_ok += 1
if ar >= 1.0:
total_correct += 1
kept.append(
{
"prompt": prompt,
"response": resp,
"answer": gt,
"unique_id": uid,
"ei_step": ei_step,
"rollout_idx": j,
"reward": rr,
"format_reward": fr,
"answer_reward": ar,
}
)
stats = {
"ei_step": ei_step,
"num_questions": len(prompts),
"G": G,
"total_generations": total_gen,
"num_correct_trajs": total_correct,
"format_ok_trajs": total_format_ok,
"kept_sft_size": len(kept),
"kept_per_question": (len(kept) / max(1, len(prompts))),
}
return kept, stats
def train_sft_on_items(
*,
policy: torch.nn.Module,
tokenizer,
items: List[Dict[str, Any]],
device: str,
lr: float,
micro_batch_size: int,
grad_acc_steps: int,
epochs: int,
max_train_steps: int,
log_event,
ei_step: int,
train_log_interval_opt_steps: int = 10,
) -> Dict[str, Any]:
"""
Runs SFT training on prompt/response items for some epochs.
Logs:
- train/loss
- train/avg_token_entropy (masked on response tokens)
Returns training summary stats.
"""
if len(items) == 0:
return {"ei_step": ei_step, "skipped": True, "reason": "no_kept_items"}
dataset = EISFTDataset(items)
loader = DataLoader(
dataset,
batch_size=micro_batch_size,
shuffle=True,
drop_last=True,
collate_fn=lambda b: collate_fn(b, tokenizer),
)
opt = torch.optim.AdamW(policy.parameters(), lr=lr)
policy.train()
step = 0
micro_idx = 0
opt_step = 0
opt.zero_grad(set_to_none=True)
# running stats
ent_sum = 0.0
ent_count = 0
for ep in range(epochs):
for batch in loader:
step += 1
micro_idx += 1
input_ids = batch["input_ids"].to(device)
labels = batch["labels"].to(device)
response_mask = batch["response_mask"].to(device)
# get log_probs + entropy for logging
out = get_response_log_probs(
policy, input_ids, labels, return_token_entropy=True
)
policy_log_probs = out["log_probs"] # (B,T)
token_entropy = out["token_entropy"] # (B,T)
# masked mean entropy (only response tokens)
with torch.no_grad():
m = response_mask.to(token_entropy.dtype)
denom = torch.clamp(m.sum(), min=1.0)
avg_ent = float((token_entropy * m).sum().detach().cpu() / denom.cpu())
ent_sum += avg_ent
ent_count += 1
loss, _ = sft_microbatch_train_step(
policy_log_probs=policy_log_probs,
response_mask=response_mask,
gradient_accumulation_steps=grad_acc_steps,
normalize_constant=1.0,
)
if micro_idx % grad_acc_steps == 0:
torch.nn.utils.clip_grad_norm_(policy.parameters(), 1.0)
opt.step()
opt.zero_grad(set_to_none=True)
opt_step += 1
# periodic log
if opt_step % train_log_interval_opt_steps == 0:
avg_ent_running = ent_sum / max(1, ent_count)
log_event(
{
"type": "train_step",
"ei_step": ei_step,
"epoch": ep,
"opt_step": opt_step,
"micro_step": step,
"loss": float(loss.detach().cpu()),
"train/avg_token_entropy": avg_ent_running,
"msg": f"[EI {ei_step}] ep={ep} opt_step={opt_step} loss={float(loss.detach()):.4f} avg_ent={avg_ent_running:.4f}",
},
also_print=True,
)
ent_sum = 0.0
ent_count = 0
if max_train_steps > 0 and step >= max_train_steps:
break
if max_train_steps > 0 and step >= max_train_steps:
break
return {
"ei_step": ei_step,
"epochs": epochs,
"train_micro_steps": step,
"train_opt_steps": opt_step,
"num_items": len(items),
"skipped": False,
}
def eval_policy_with_vllm(
*,
policy: torch.nn.Module,
llm: LLM,
eval_prompts: List[str],
eval_gts: List[Any],
eval_sampling_params: SamplingParams,
request_batch_size: int,
) -> Dict[str, Any]:
policy.eval()
with torch.no_grad():
load_policy_into_vllm_instance(policy, llm)
rows = evaluate_vllm(
vllm_model=llm,
reward_fn=r1_zero_reward_fn,
prompts=eval_prompts,
ground_truths=eval_gts,
eval_sampling_params=eval_sampling_params,
request_batch_size=request_batch_size,
)
n = len(rows)
acc = sum(r.answer_reward for r in rows) / n if n else 0.0
fmt = sum(r.format_reward for r in rows) / n if n else 0.0
rew = sum(r.reward for r in rows) / n if n else 0.0
return {"eval/n": n, "eval/accuracy": acc, "eval/format_rate": fmt, "eval/avg_reward": rew}
def save_jsonl(items: List[Dict[str, Any]], path: Path):
path.parent.mkdir(parents=True, exist_ok=True)
with open(path, "w", encoding="utf-8") as f:
for ex in items:
f.write(json.dumps(ex, ensure_ascii=False) + "\n")
def main():
ap = argparse.ArgumentParser()
ap.add_argument("--model_id", default="data/models/Qwen2.5-Math-1.5B")
ap.add_argument("--train_path", default="data/MATH/train.jsonl")
ap.add_argument("--val_path", default="data/MATH/validation.jsonl")
ap.add_argument("--prompt_file", default="cs336_alignment/prompts/r1_zero.prompt")
ap.add_argument("--train_device", default="cuda:0")
ap.add_argument("--vllm_device", default="cuda:1")
ap.add_argument("--out_dir", default="runs/expert_iteration")
ap.add_argument("--seed", type=int, default=0)
# EI hyperparams
ap.add_argument("--n_ei_steps", type=int, default=5)
ap.add_argument("--D_i", type=int, default=512, help="number of questions sampled per EI step")
ap.add_argument("--G", type=int, default=2, help="rollouts per question")
ap.add_argument("--epochs", type=int, default=1, help="SFT epochs per EI step")
ap.add_argument("--max_train_steps_per_ei", type=int, default=0, help="0 means no cap")
# SFT optimizer params
ap.add_argument("--lr", type=float, default=2e-5)
ap.add_argument("--micro_batch_size", type=int, default=2)
ap.add_argument("--grad_acc_steps", type=int, default=16)
# vLLM sampling params for rollout
ap.add_argument("--sampling_temperature", type=float, default=1.0)
ap.add_argument("--sampling_top_p", type=float, default=1.0)
ap.add_argument("--sampling_max_tokens", type=int, default=256)
ap.add_argument("--sampling_min_tokens", type=int, default=4)
# eval params
ap.add_argument("--eval_max_examples", type=int, default=500)
ap.add_argument("--eval_request_batch_size", type=int, default=64)
ap.add_argument("--rollout_request_batch_size", type=int, default=32)
ap.add_argument("--save_each_ei_step", action="store_true")
args = ap.parse_args()
# run folder
run_name = f"ei_G{args.G}_E{args.epochs}_D{args.D_i}_seed{args.seed}"
run_dir = Path(args.out_dir) / run_name
run_dir.mkdir(parents=True, exist_ok=True)
log_path = run_dir / "log.jsonl"
log_event = make_logger(log_path)
# seeds
torch.manual_seed(args.seed)
random.seed(args.seed)
log_event(
{
"type": "config",
"args": vars(args),
"run_dir": str(run_dir),
"msg": f"Run dir: {run_dir}",
}
)
# load prompt template + data
prompt_template = load_prompt_template(args.prompt_file)
train_data = load_jsonl(args.train_path)
val_data = load_jsonl(args.val_path)
# build eval prompts
eval_prompts, eval_gts, _ = build_prompts_and_gts(
val_data, prompt_template, max_examples=args.eval_max_examples
)
# init tokenizer/policy (HF) on train_device
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
policy = AutoModelForCausalLM.from_pretrained(
args.model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
).to(args.train_device)
policy.train()
# init vLLM on vllm_device
llm = init_vllm(args.model_id, device=args.vllm_device, seed=args.seed)
# sampling params for rollout (n=G)
rollout_sampling_params = SamplingParams(
temperature=args.sampling_temperature,
top_p=args.sampling_top_p,
max_tokens=args.sampling_max_tokens,
min_tokens=args.sampling_min_tokens,
n=args.G,
seed=args.seed,
stop=["</answer>"],
include_stop_str_in_output=True,
)
# eval sampling params
eval_sampling_params = SamplingParams(
temperature=1.0,
top_p=1.0,
max_tokens=args.sampling_max_tokens,
min_tokens=args.sampling_min_tokens,
stop=["</answer>"],
include_stop_str_in_output=True,
)
# initial eval
init_metrics = eval_policy_with_vllm(
policy=policy,
llm=llm,
eval_prompts=eval_prompts,
eval_gts=eval_gts,
eval_sampling_params=eval_sampling_params,
request_batch_size=args.eval_request_batch_size,
)
log_event({"type": "eval_metrics", "ei_step": 0, "metrics": init_metrics, "msg": f"[EI 0] {init_metrics}"})
# EI loop
rng = random.Random(args.seed)
for ei_step in range(1, args.n_ei_steps + 1):
# sample D_i questions
rng.shuffle(train_data)
sampled = train_data[: args.D_i]
batch_prompts, batch_gts, batch_uids = build_prompts_and_gts(
sampled, prompt_template, max_examples=0
)
# load policy -> vLLM and rollout
policy.eval()
with torch.no_grad():
load_policy_into_vllm_instance(policy, llm)
kept_items, rollout_stats = rollout_and_filter_correct(
llm=llm,
prompts=batch_prompts,
gts=batch_gts,
uids=batch_uids,
ei_step=ei_step,
G=args.G,
sampling_params=rollout_sampling_params,
request_batch_size=args.rollout_request_batch_size,
)
# save EI dataset for this step
ei_data_path = run_dir / f"ei_step_{ei_step:02d}_kept.jsonl"
save_jsonl(kept_items, ei_data_path)
log_event(
{
"type": "rollout_stats",
"ei_step": ei_step,
"stats": rollout_stats,
"ei_data_path": str(ei_data_path),
"msg": f"[EI {ei_step}] rollout stats: {rollout_stats}",
}
)
# train SFT on kept items
policy.train()
train_summary = train_sft_on_items(
policy=policy,
tokenizer=tokenizer,
items=kept_items,
device=args.train_device,
lr=args.lr,
micro_batch_size=args.micro_batch_size,
grad_acc_steps=args.grad_acc_steps,
epochs=args.epochs,
max_train_steps=args.max_train_steps_per_ei,
log_event=log_event,
ei_step=ei_step,
train_log_interval_opt_steps=10,
)
log_event({"type": "train_summary", "ei_step": ei_step, "summary": train_summary,
"msg": f"[EI {ei_step}] train summary: {train_summary}"})
# eval after EI step
metrics = eval_policy_with_vllm(
policy=policy,
llm=llm,
eval_prompts=eval_prompts,
eval_gts=eval_gts,
eval_sampling_params=eval_sampling_params,
request_batch_size=args.eval_request_batch_size,
)
log_event({"type": "eval_metrics", "ei_step": ei_step, "metrics": metrics,
"msg": f"[EI {ei_step}] {metrics}"})
# save model
if args.save_each_ei_step:
step_dir = run_dir / f"model_ei_step_{ei_step:02d}"
step_dir.mkdir(parents=True, exist_ok=True)
policy.save_pretrained(str(step_dir))
tokenizer.save_pretrained(str(step_dir))
log_event({"type": "save", "ei_step": ei_step, "out_dir": str(step_dir),
"msg": f"[EI {ei_step}] Saved model: {step_dir}"})
# return to train mode for next step
policy.train()
# final save
final_dir = run_dir / "model_final"
final_dir.mkdir(parents=True, exist_ok=True)
policy.save_pretrained(str(final_dir))
tokenizer.save_pretrained(str(final_dir))
log_event({"type": "save", "ei_step": args.n_ei_steps, "out_dir": str(final_dir),
"msg": f"Saved final model: {final_dir}"})
if __name__ == "__main__":
main()我们先来了解下专家迭代到底是个什么意思:
EI(Expert Iteration, 专家迭代) 可以概括为一句话:用 "当前模型自己生成的多条解题轨迹" 当作候选数据 → 用规则/验证器挑出其中 "像专家一样正确" 的那部分 → 再用这些被筛出来的轨迹去继续做 SFT → 循环多轮。
作业中 EI 的流程如下:
以第 i i i 次 EI step 为例(作业里要求 n_ei_steps=5,所以会做 5 轮):
1. Rollout(采样生成)
用当前策略模型 π i \pi_i πi 对一批题目生成若干条完整响应(通常包含推理 + 最终答案)。
- 每道题会生成 G G G 条
- 这些生成的 "完整响应" 就叫做 rollout / trajectory(轨迹)
2. 筛选(选"专家"轨迹)
对每条生成结果做自动判定:比如是否能解析出最终答案、最终答案是否正确、格式是否合格(是否在 </answer> 处停止等)。被判定为"正确/高质量"的那部分 rollout,就组成当前轮的数据集 D i D_i Di
3. SFT 更新(模仿专家)
用筛出来的 D i D_i Di 对模型做若干 epochs 的 SFT 得到新模型 π i + 1 \pi_{i+1} πi+1
4. 重复
用 π i + 1 \pi_{i+1} πi+1 再去 rollout → 再筛选 → 再 SFT ...
所以 EI 的 "专家" 是指 "在当前模型产生的多条候选轨迹里,被验证器判定为正确的那条/那些条",它们在这一轮里就充当"专家示范"。
上述脚本实现的就是一个 标准的 EI(Expert Iteration)闭环:每轮从训练题中抽一批 D i D_i Di → 用当前 policy rollout 生成每题 G 条 → 用 reward_fn 过滤出 "正确轨迹" 当作专家数据 D i ( k e e p ) D_i^{(keep)} Di(keep) → 对这些数据做 SFT(带 gradient clipping)→ 评估 → 下一轮。
我们可以像之前一样先做一个超短的 smoke test,验证下 训练 + vLLM 评估 + 日志记录 整个链路有没有问题,指令如下:
shell
uv run python scripts/expert_iteration_experiment.py \
--n_ei_steps 1 \
--D_i 32 \
--G 2 \
--epochs 1 \
--sampling_max_tokens 128 \
--eval_max_examples 32 \
--max_train_steps_per_ei 50 \
--micro_batch_size 1 \
--grad_acc_steps 2 \
--save_each_ei_step执行后输出如下图所示:
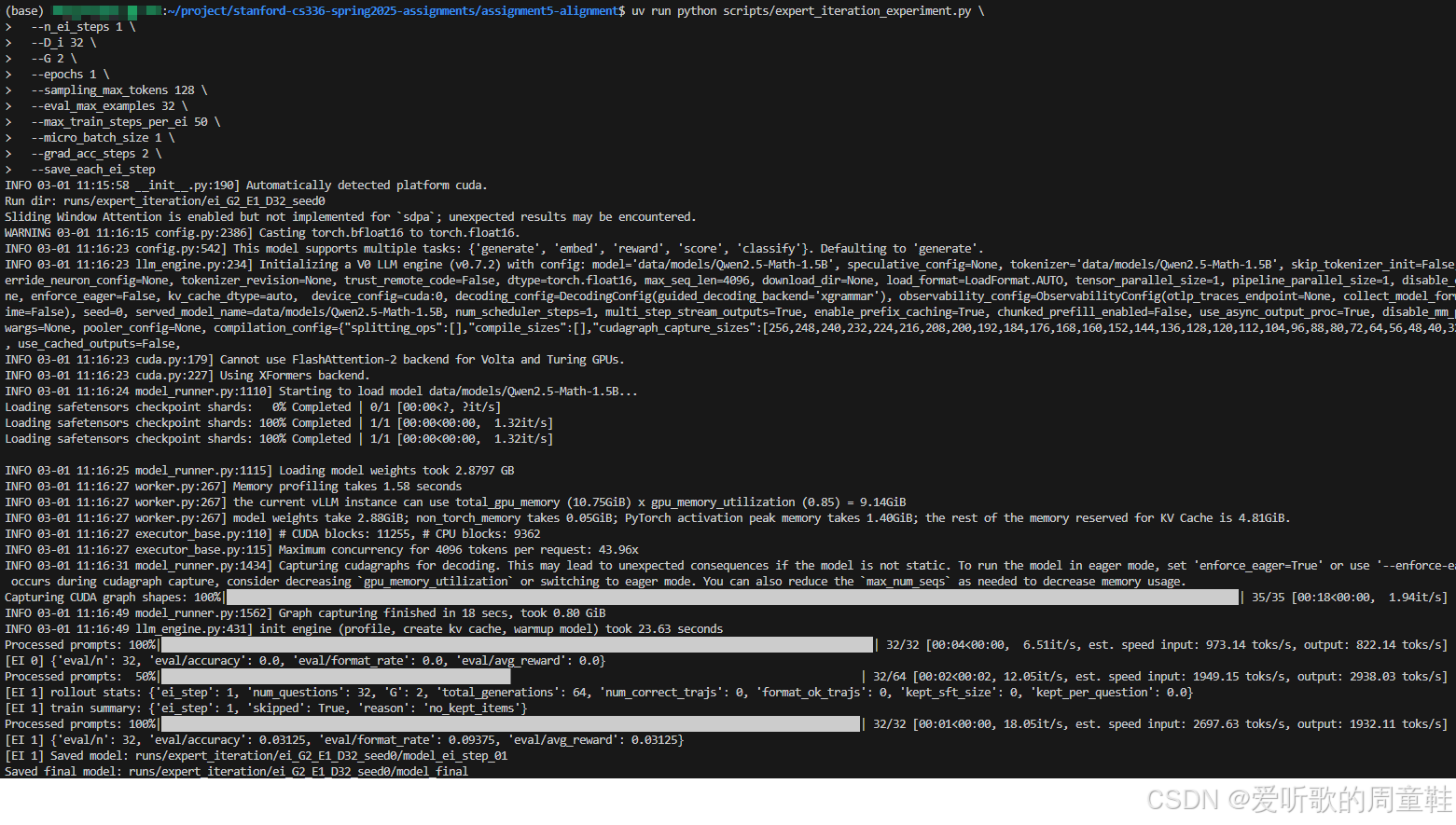
同时在 runs/expert_iteration 文件夹下保存了相关模型和日志信息:
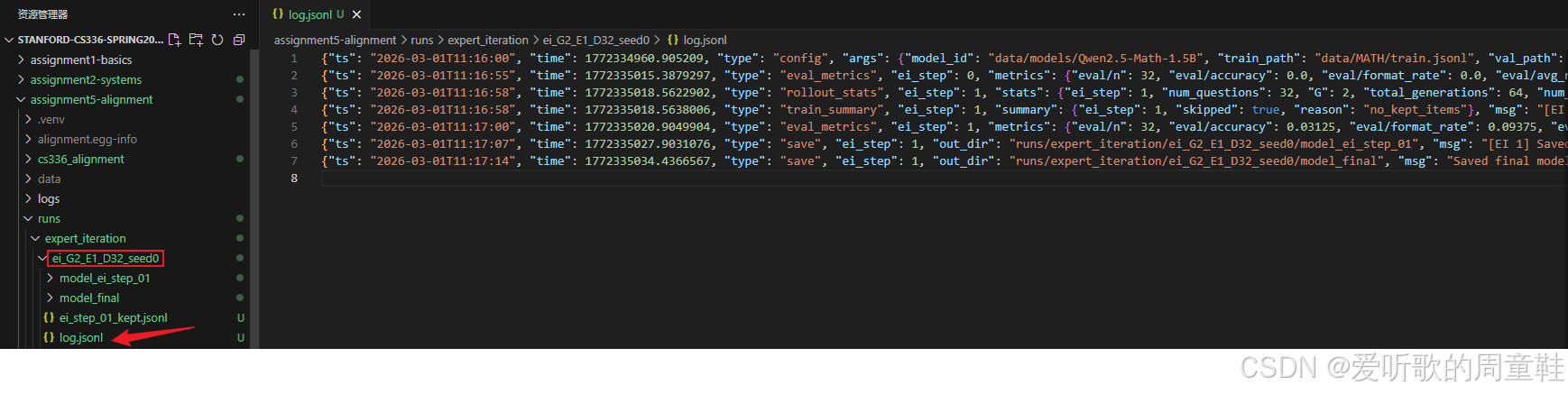
Note :由于硬件资源的限制,博主在本次实验中做了和 sft_experiment 相同的修改设置,这里就不再赘述了,博主仅仅是为了验证实验脚本的正确性,大家如果算力足够的话,可以正常执行实验。
我们可以写一个 shell 脚本来扫描不同的 D i D_i Di:
shell
#!/usr/bin/env bash
set -euo pipefail
# ==========================
# Logging
# ==========================
LOG_DIR="logs/expert_iteration"
mkdir -p "${LOG_DIR}"
# ==========================
# Common defaults
# ==========================
N_EI_STEPS=5
EVAL_MAX_EXAMPLES=500
SAMPLING_MAX_TOKENS=256
SAMPLING_MIN_TOKENS=4
SEED=0
TRAIN_DEVICE="cuda:0"
VLLM_DEVICE="cuda:1"
# ==========================
# Sweep list
# Format:
# "<name> <args...>"
# ==========================
declare -a RUNS=(
# ---- Minimal required coverage (2 rollout+epoch combos) ----
"G2_E1_D512 --G 2 --epochs 1 --D_i 512"
"G2_E1_D1024 --G 2 --epochs 1 --D_i 1024"
"G2_E1_D2048 --G 2 --epochs 1 --D_i 2048"
"G8_E3_D512 --G 8 --epochs 3 --D_i 512"
"G8_E3_D1024 --G 8 --epochs 3 --D_i 1024"
"G8_E3_D2048 --G 8 --epochs 3 --D_i 2048"
# ---- Optional extra combos (uncomment if you have time/compute) ----
# "G4_E1_D1024 --G 4 --epochs 1 --D_i 1024"
# "G8_E1_D1024 --G 8 --epochs 1 --D_i 1024"
# "G2_E3_D1024 --G 2 --epochs 3 --D_i 1024"
)
echo "=== Starting Expert Iteration sweep at $(date) ==="
echo "Logs will be saved to: ${LOG_DIR}"
echo "n_ei_steps=${N_EI_STEPS}, eval_max_examples=${EVAL_MAX_EXAMPLES}, sampling_max_tokens=${SAMPLING_MAX_TOKENS}"
echo
for item in "${RUNS[@]}"; do
name=$(echo "$item" | awk '{print $1}')
args=$(echo "$item" | cut -d' ' -f2-)
ts=$(date +"%Y%m%d_%H%M%S")
log_file="${LOG_DIR}/${ts}_${name}.log"
echo "=== Run: ${name} @ $(date) ==="
echo "Command: uv run python scripts/expert_iteration_experiment.py ${args} ..."
echo "Log: ${log_file}"
echo
set +e
{
echo "===== BEGIN ${name} $(date) ====="
echo "CMD: uv run python scripts/expert_iteration_experiment.py ${args} \\"
echo " --n_ei_steps ${N_EI_STEPS} \\"
echo " --eval_max_examples ${EVAL_MAX_EXAMPLES} \\"
echo " --sampling_max_tokens ${SAMPLING_MAX_TOKENS} \\"
echo " --sampling_min_tokens ${SAMPLING_MIN_TOKENS} \\"
echo " --seed ${SEED} \\"
echo " --train_device ${TRAIN_DEVICE} \\"
echo " --vllm_device ${VLLM_DEVICE} \\"
echo
uv run python scripts/expert_iteration_experiment.py \
${args} \
--n_ei_steps "${N_EI_STEPS}" \
--eval_max_examples "${EVAL_MAX_EXAMPLES}" \
--sampling_max_tokens "${SAMPLING_MAX_TOKENS}" \
--sampling_min_tokens "${SAMPLING_MIN_TOKENS}" \
--seed "${SEED}" \
--train_device "${TRAIN_DEVICE}" \
--vllm_device "${VLLM_DEVICE}" \
exit_code=$?
echo
echo "EXIT_CODE: ${exit_code}"
echo "===== END ${name} $(date) ====="
exit ${exit_code}
} 2>&1 | tee "${log_file}"
exit_code=${PIPESTATUS[0]}
set -e
if [[ "${exit_code}" -ne 0 ]]; then
echo
echo "!!! Run ${name} failed with exit code ${exit_code}. Stopping sweep."
echo "See log: ${log_file}"
exit "${exit_code}"
fi
echo
echo "=== Run ${name} finished successfully @ $(date) ==="
echo
done
echo "=== All Expert Iteration runs completed at $(date) ==="Note:大家可以根据硬件性能自行调整相关超参数来获取最佳性能。
执行指令如下:
shell
chmod +x ./scripts/run_sft_sweeps.sh
nohup ./scripts/run_sft_sweep.sh > nohup_master.log 2>&1 &执行完成后在 runs/expert_iteration 文件夹下保存着不同训练样本的结果。
博主在上述条件设置下跑出来的 EI 验证准确率曲线如下图所示:
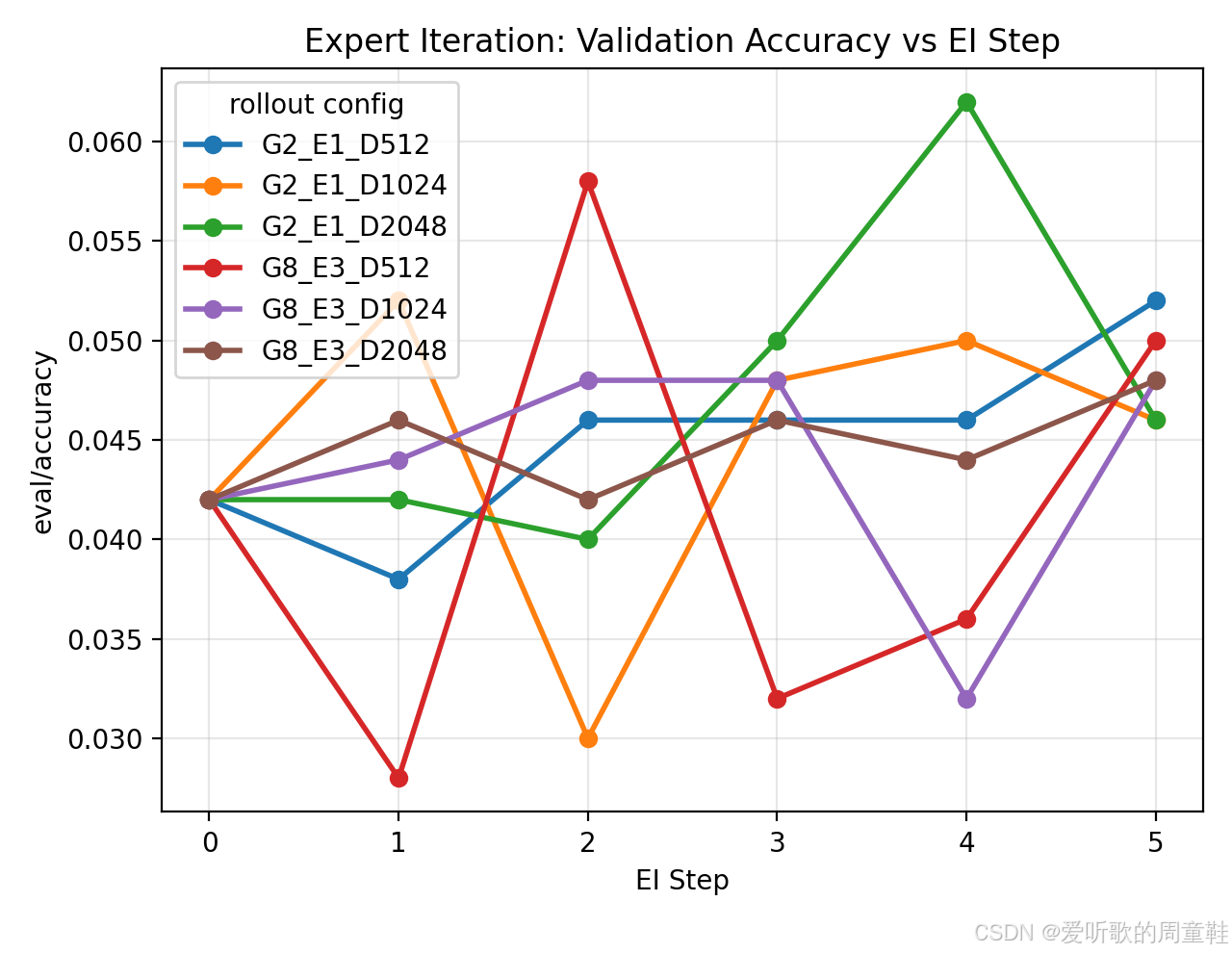
从上图我们可以看出,在当前资源受限设定下,EI 的验证准确率整体在 0.03~0.06 区间波动,没有出现稳定单调提升。波动主要来自 EI 过程的 "高方差数据生成":每步只保留极少数正确 rollout,导致每步 SFT 的有效训练数据规模很小,且不同 EI step 的训练样本分布差异很大。
此外,在本次实验中,相较于 SFT,专家迭代(Expert Iteration, EI)在整体上并未表现出稳定的性能优势,这主要是由于在算力受限的条件下,每一步迭代中能够保留下来的正确轨迹数量较少,导致有效训练信号不足。然而,从不同 EI 步骤之间的变化来看,后期步骤的验证准确率偶尔能够超过前期步骤,说明尽管存在较大的波动,EI 仍然体现出一定的自我改进趋势。
在本次实验中模型响应熵在训练过程中变化的曲线如下图所示:
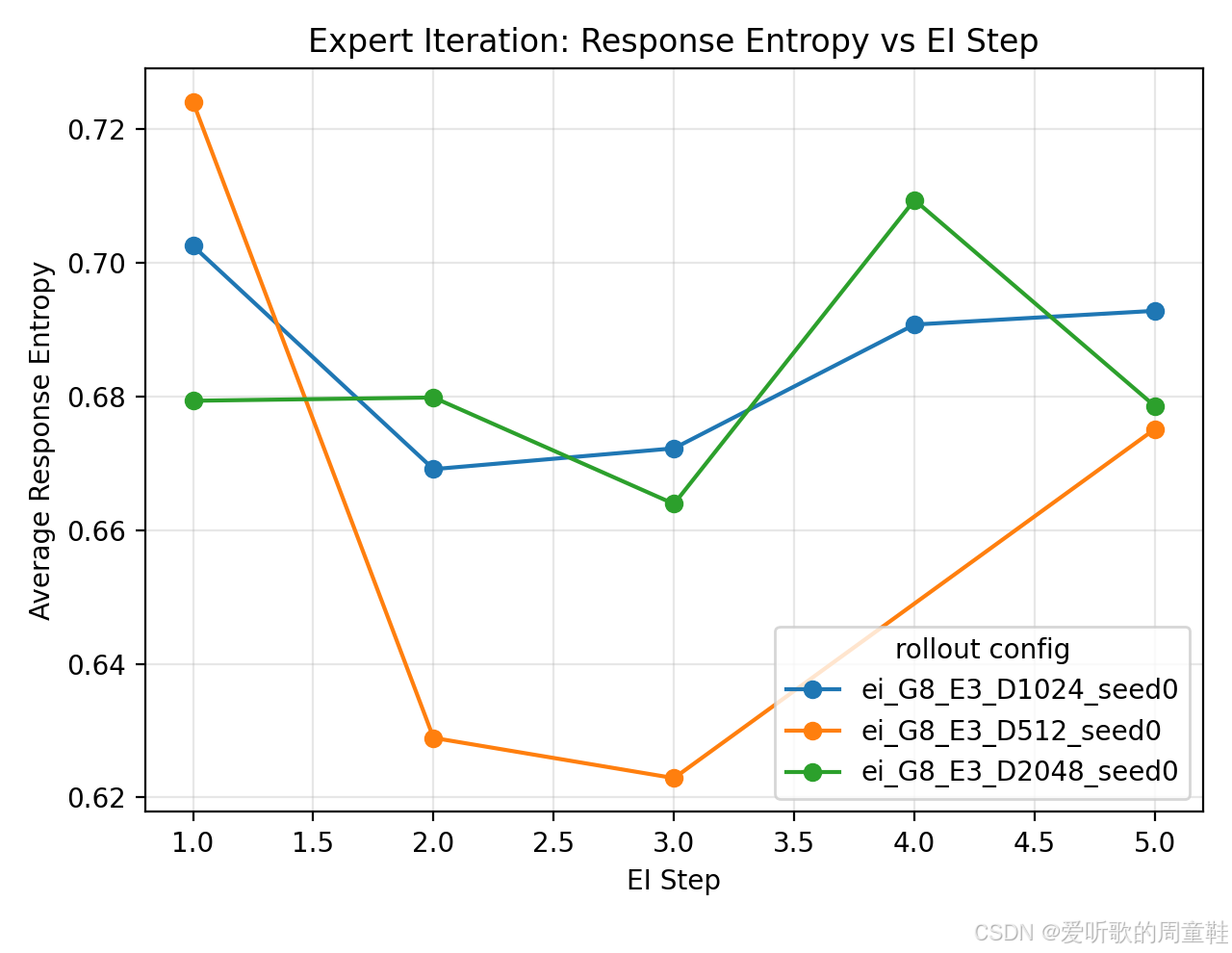
从图中可以观察到,模型响应熵在 EI 训练过程中整体呈现出波动变化,而非单调下降趋势。在部分 EI 步骤中,熵出现下降,表明模型对生成策略的确定性有所增强;而在后续步骤中,熵再次上升,则说明由于新增的 rollout 数据带来了分布变化,模型的不确定性有所回升。
这种现象符合在有限算力条件下运行 EI 的典型表现:由于每一步保留下来的正确轨迹数量较少,模型在不同 EI 步骤之间难以形成稳定的策略收敛过程,因此其响应不确定性呈现出"震荡式演化",而非理想情况下的持续下降。
OK,以上就是本次 SFT 作业的全部实现了
最后需要说明的是,针对 SFT 和 EI 实验,博主这里仅仅只验证了相关脚本运行的正确性,并没有运行完整的实验并进行相关的分析论证,大家可以自行进行相关实验!
结语
在本篇文章中,我们围绕 CS336 Assignment 5 中的 SFT 与 Expert Iteration 相关任务,系统完成了从零样本基线评估、推理型 SFT 训练到基于模型自生成数据的 EI 闭环优化的完整实现流程。
在实现过程中,我们首先构建了面向推理任务的监督学习基础组件,包括 prompt-response 拼接与 mask 构造、token 级 log-prob 计算、熵度量以及 microbatch 训练步骤,使得模型能够仅在回答部分接受监督信号,从而符合推理型对齐任务的训练目标。在此基础熵,我们进一步搭建了完整的 SFT 训练与评估流水线,并通过样本规模扫描与过滤实验,观察监督信号质量对模型表现得实际影响。
进一步地,通过引入 Expert Iteration,我们将训练流程从 "静态模仿数据" 扩展为 "模型生成 → 自动筛选 → 再训练" 的闭环优化过程,使模型能够在自身生成的高质量轨迹上持续改进。尽管在算力受限条件下,EI 并未表现出稳定的性能优势,但验证了 alignment 训练中数据生成机制与策略不确定性之间的动态关系。
在下一小节中我们一起来学习策略梯度和 GRPO 强化学习算法,敬请期待🤗