RAG 元数据的作用与管理:让知识库回答可追溯、可过滤、可维护
上一篇我们聊了 RAG 中的文本分块(Chunking):如何把长文档拆成适合检索的小块。分块解决的是"长文本如何变成可检索单元"的问题,但它没有回答另一个关键问题:这些文本块从哪里来、属于哪个业务范围、当前是否生效、谁可以查看、出了问题怎么回溯。
在真实业务里,RAG 系统不能只做到"能召回"。如果系统无法说明答案来源、无法按权限过滤、无法在错答后定位问题 chunk,那么知识库上线之后很快会进入难维护、难审计、难解释的状态。
本文会围绕在线教育场景,拆解 RAG 元数据(Metadata)的作用、字段设计、权限过滤、引用生成和后续运维方式。
你将看到:
- 为什么只保存文本 chunk 还不够;
- 一个带元数据的 chunk 应该包含哪些字段;
- 元数据如何支持引用、权限过滤、版本治理和错答回溯;
- 如何从最小可用字段集开始,逐步建设可维护的 RAG 知识库。
本篇讨论的核心,就是元数据管理(Metadata Management)。
元数据可以理解为贴在每个 chunk 上的标签。它不替代正文内容,但能告诉系统:这段内容来自哪份文档、位于哪个章节、什么时间生效、哪些角色可以访问、需要如何展示引用,以及后续如何定位和修复。
为什么只保存文本内容还不够?
1. 场景:在线教育平台的教务知识库
假设一个在线教育平台建设了面向学员、助教、教务老师和内部运营人员的 RAG 问答系统。平台知识库中包含多类文档:
- 学员端文档:课程介绍、预约规则、退课改期说明、学习路径、考试安排、证书申请说明。
- 教务端文档:排课流程、班级管理 SOP、学员投诉处理规范、服务工单处理规则。
- 教研端文档:课程大纲、知识点拆解、作业批改标准、测评题库说明。
- 内部运营文档:活动规则、优惠券配置说明、讲师结算口径、渠道投放复盘。
平台希望用户能直接提问,例如"课程开始前多久可以改期?"、"Python 进阶课的作业怎么提交?"、"证书什么时候发放?"。系统通过 RAG 从知识库中检索相关 chunk,再交给大模型生成答案。
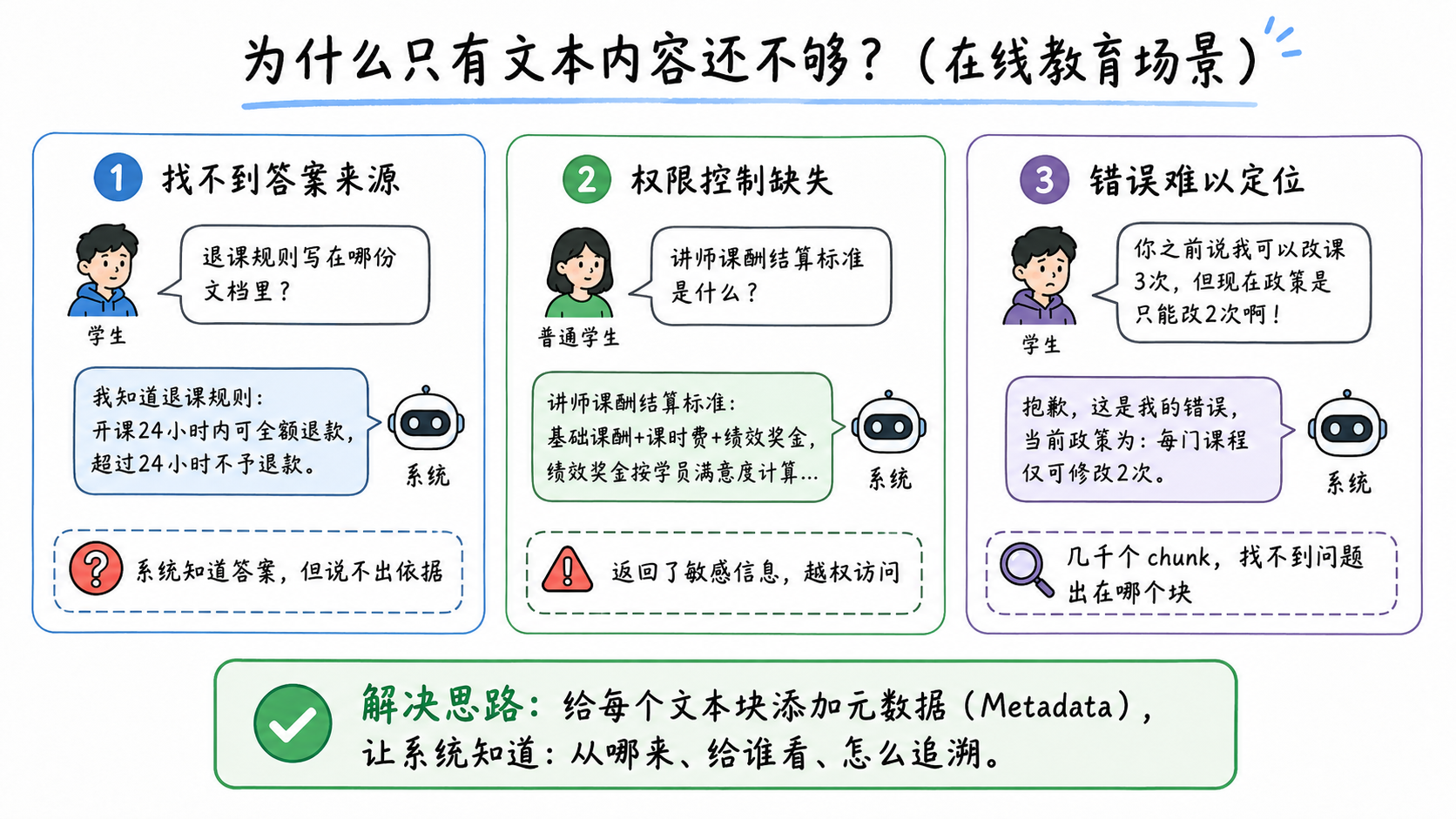
看上去流程已经完整,但真正落地后会出现三个典型问题。
2. 痛点一:系统能回答,但说不清依据
学员问:
课程开始前多久可以免费改期?
系统回答:
课程开始前 24 小时以上可以免费改期。
学员继续追问:
这个规则在哪份说明里?我想看完整政策。
如果被召回的 chunk 只有正文,没有记录它来自哪份文档、哪一页、哪个章节,系统就很难给出可靠出处。它知道答案,却说不清答案从哪里来。
在教育服务场景中,用户经常需要查看依据。退课、改期、考试、证书、费用等问题都带有规则属性。如果回答没有引用来源,用户很难判断它是否可信,客服和教务团队也难以对齐口径。
3. 痛点二:不同角色看到了不该看的内容
一名普通学员问:
讲师课酬是怎么计算的?
如果系统没有权限过滤,可能会召回内部运营文档中的讲师结算规则,并把敏感内容直接生成给学员。这显然不合适。
在线教育平台中,不同角色的知识可见范围不同:
- 学员可以查看公开课程规则、学习指南、考试说明。
- 助教可以查看班级服务 SOP、学员跟进记录模板。
- 教研老师可以查看课程大纲、作业批改标准、题库设计说明。
- 教务管理员可以查看排课规则、投诉处理流程、内部配置文档。
如果每个 chunk 没有角色、权限、敏感级别等元数据,系统就无法在检索时判断哪些内容可以返回,哪些内容必须过滤。
4. 痛点三:答案出错后,找不到问题 chunk
某位学员反馈:
系统告诉我开课前 2 小时还能免费改期,但客服说最新规则是开课前 24 小时内不能免费改期。
技术团队需要修复这个问题,但如果知识库中有几千个 chunk,而每个 chunk 只有一段文本,就很难快速定位问题来源。问题可能来自旧版课程预约规则,也可能来自某个活动页说明,还可能是旧 FAQ 没有下线。
如果 chunk 中记录了 doc_id、file_name、chunk_index、start_offset、effective_date、expiration_date 等元数据,就可以快速定位来源文档、原文位置和版本状态,从而完成修正。
这三个问题说明:文本内容负责"回答什么",元数据负责"能不能回答、依据在哪里、出了问题怎么改"。
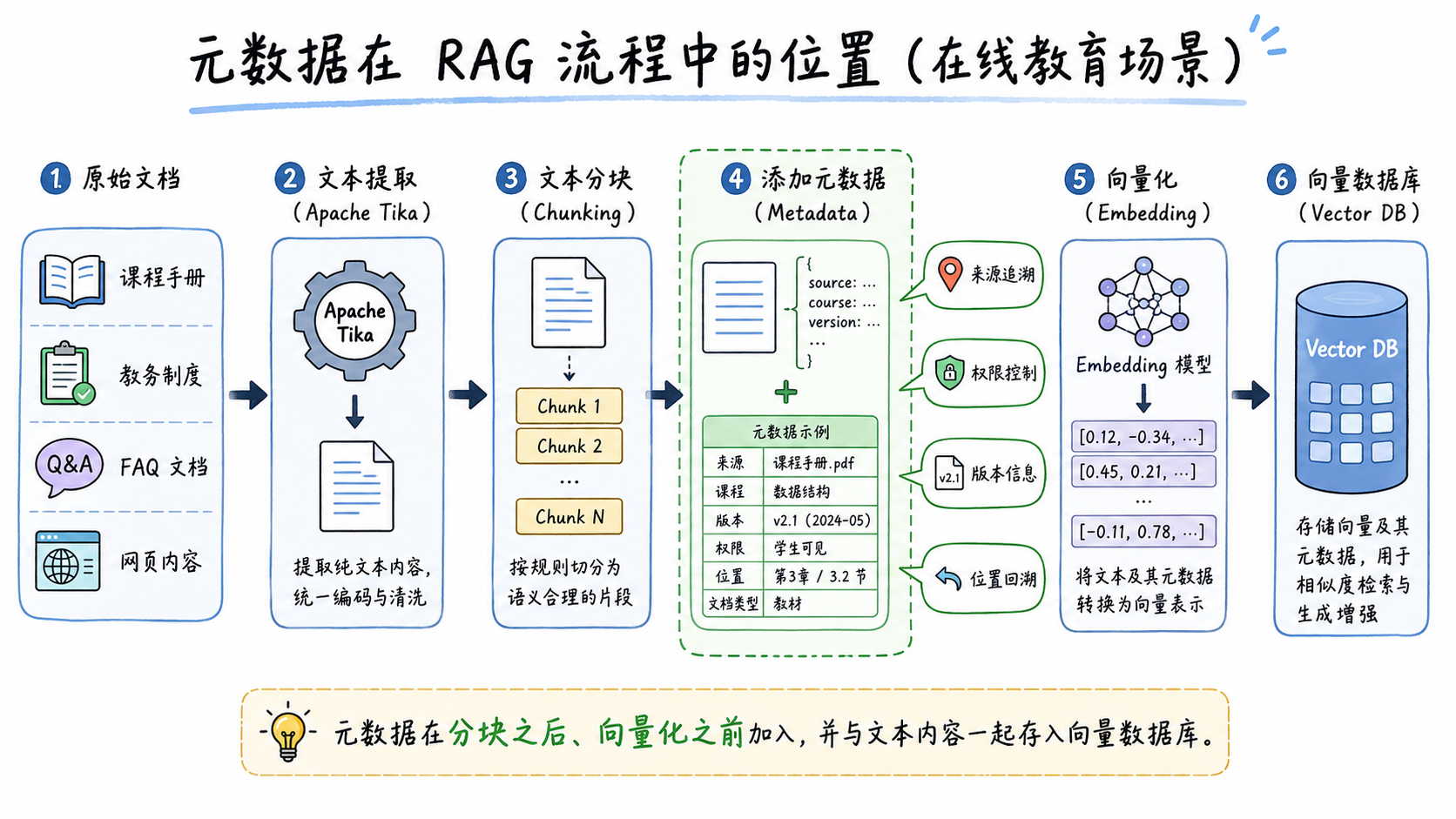
元数据在 RAG 流程中的位置
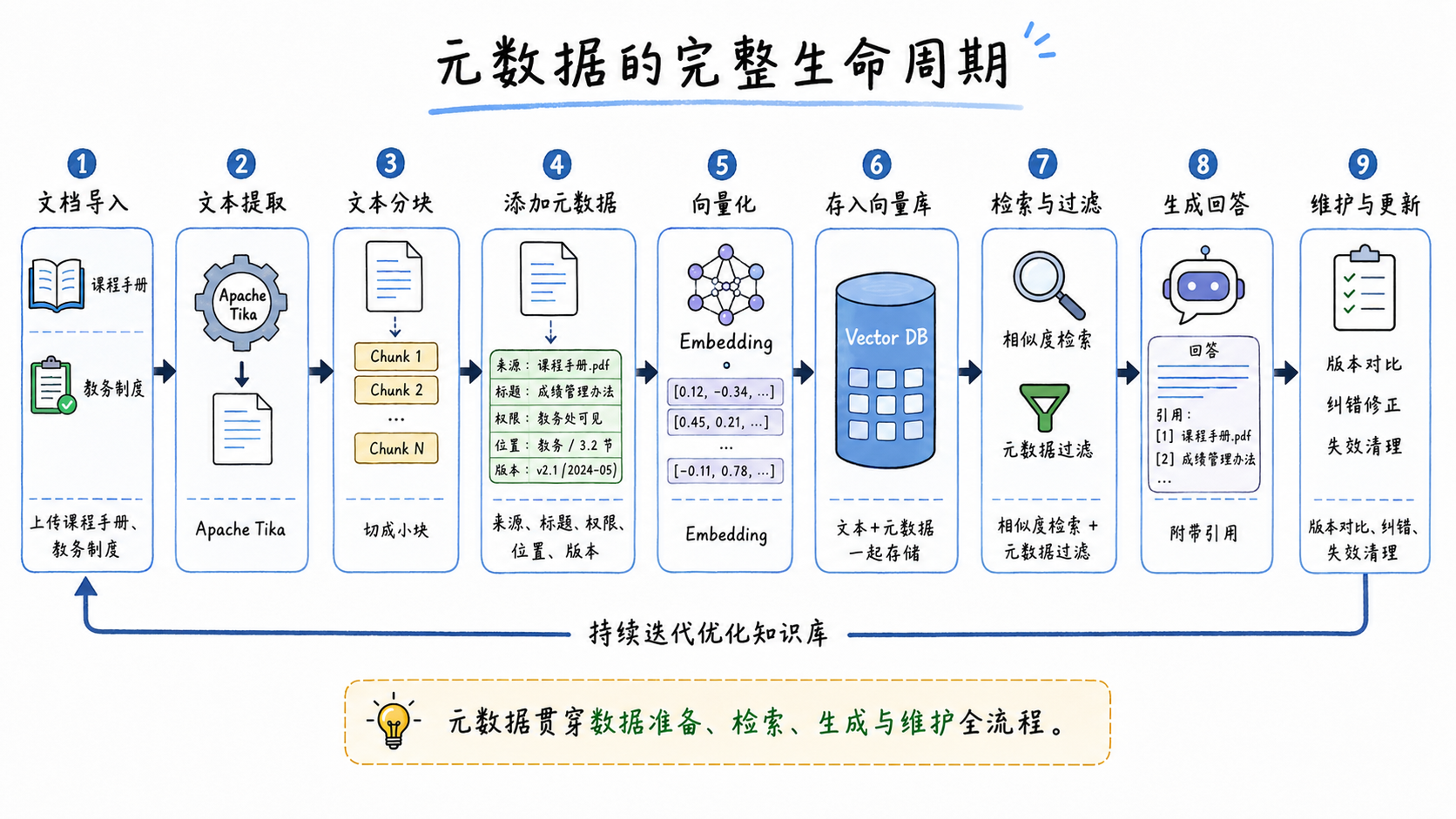
RAG 的数据准备流程可以简化为:
latex
原始文档
↓
文本提取(PDF / Word / HTML / Markdown 等)
↓
文本清洗与结构修复
↓
文本分块(Chunking)
↓
添加元数据(Metadata)
↓
向量化(Embedding)
↓
写入向量数据库(Vector Store)
↓
检索、过滤、增强生成元数据通常在分块之后、向量化之前补充。原因很简单:只有分块完成后,系统才知道每个 chunk 的具体内容、位置、序号和所属上下文。
在写入向量数据库时,文本内容会被 embedding 模型转成向量;元数据则作为结构化字段一起存储。后续查询时,系统不仅可以根据语义相似度召回相关 chunk,还可以基于元数据做过滤、排序、引用拼接和运维定位。
一个完整的 chunk 应该长什么样?
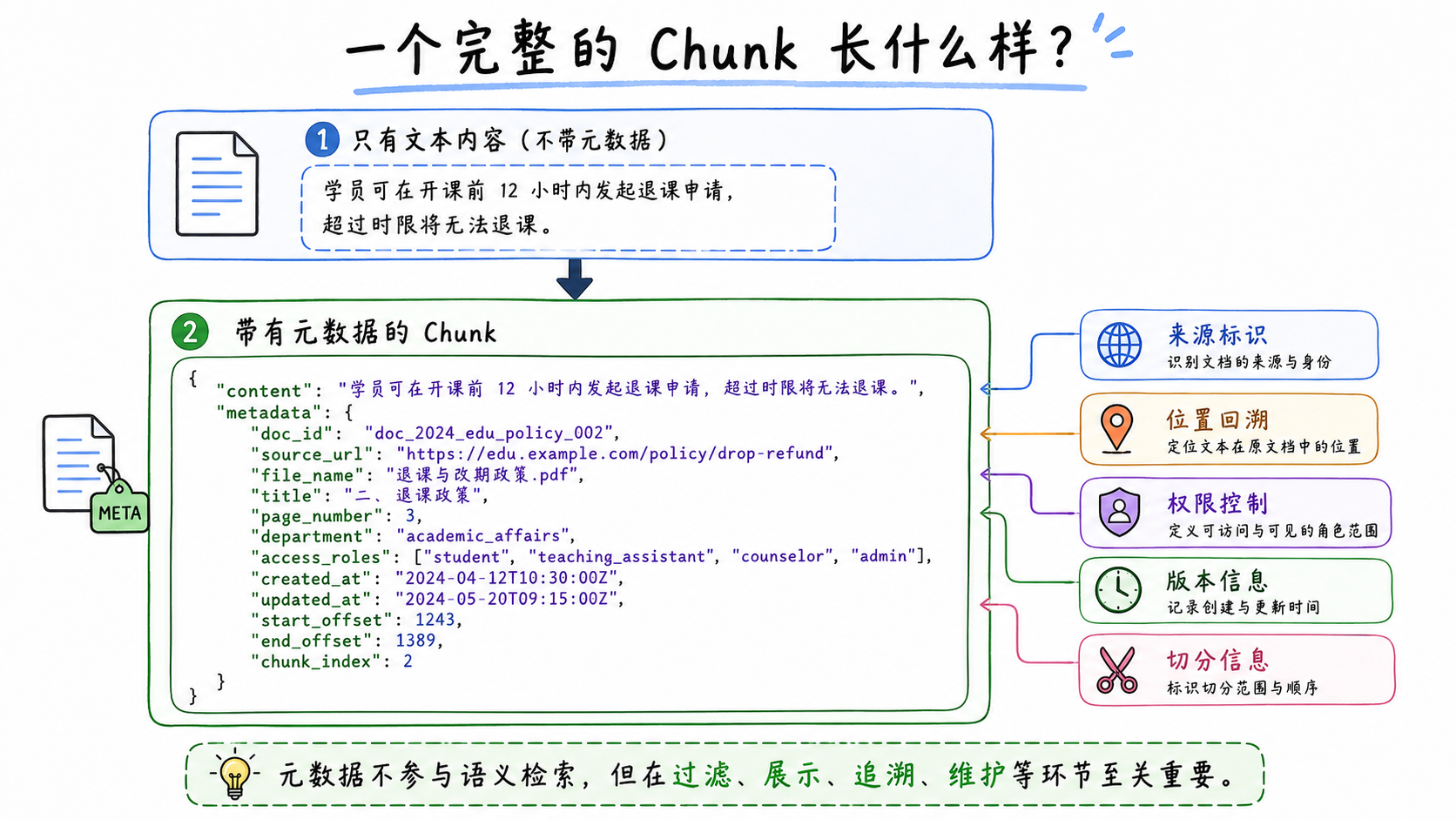
在没有元数据之前,一个 chunk 可能只是这样:
课程开始前 24 小时以上,学员可申请免费改期;课程开始前 2 小时至 24 小时之间改期,将扣除一次改期权益。
加入元数据后,它可以表示为:
json
{
"content": "课程开始前 24 小时以上,学员可申请免费改期;课程开始前 2 小时至 24 小时之间改期,将扣除一次改期权益。",
"metadata": {
"doc_id": "doc_edu_policy_20260401_001",
"source_url": "/knowledge/course/reschedule-policy",
"file_name": "课程预约与改期规则.md",
"title": "二、课程改期规则 > 2.1 免费改期条件",
"page_number": 2,
"created_at": "2026-04-01T09:00:00Z",
"updated_at": "2026-05-10T18:30:00Z",
"effective_date": "2026-04-01T00:00:00Z",
"expiration_date": null,
"course_category": "programming",
"service_stage": "before_class",
"access_roles": ["student", "teaching_assistant", "academic_admin"],
"sensitivity_level": "public",
"start_offset": 128,
"end_offset": 214,
"chunk_index": 3
}
}正文仍然是规则本身,但元数据提供了完整的上下文:来源、章节、时间、业务范围、权限、原文位置和 chunk 序号。
元数据一般不参与向量化。它的主要作用发生在检索前后:
- 检索前:根据角色、课程类型、生效时间等条件过滤候选范围。
- 检索中:结合向量相似度和元数据条件返回更精准的结果。
- 检索后:生成引用来源、展示文档链接、定位相邻 chunk。
- 运维阶段:根据文档 ID、版本和位置修复错误内容。
常见元数据字段设计

1. 文档标识类:doc_id、source_url、file_name
文档标识类字段解决的是"这个 chunk 从哪里来"的问题。
在在线教育知识库中,用户问完"课程怎么改期"后,可能希望打开完整规则说明。系统只有记录了 source_url,才能返回可点击的原文链接;只有记录了 doc_id,才能在文档更新时批量替换旧 chunk;只有记录了 file_name,才能在引用中用人类可读的方式展示来源。
三个字段的分工如下:
| 字段 | 作用 | 示例 |
|---|---|---|
doc_id |
文档唯一标识,用于更新、删除、追溯 | doc_edu_policy_20260401_001 |
source_url |
原始文档访问地址 | /knowledge/course/reschedule-policy |
file_name |
原始文件名或页面标题 | 课程预约与改期规则.md |
Java 示例:给 chunk 添加文档标识
java
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class DocumentMetadataExample {
public static Document create_chunk_with_doc_metadata(
String content,
String doc_id,
String source_url,
String file_name) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("doc_id", doc_id);
metadata.put("source_url", source_url);
metadata.put("file_name", file_name);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunk_content = "课程开始前 24 小时以上,学员可申请免费改期。";
Document chunk = create_chunk_with_doc_metadata(
chunk_content,
"doc_edu_policy_20260401_001",
"/knowledge/course/reschedule-policy",
"课程预约与改期规则.md"
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Metadata: " + chunk.getMetadata());
}
}这类字段几乎所有 RAG 系统都应该保留。即使文档内容都是公开的,也需要知道 chunk 来自哪份文档,方便引用和更新。
2. 结构信息类:标题层级、章节编号、页码
结构信息解决的是"这个 chunk 位于文档的哪个部分"。
一份课程服务文档通常有清晰结构,例如:
latex
一、课程预约说明
二、课程改期规则
2.1 免费改期条件
2.2 改期次数限制
三、退课与退款规则
四、考试与证书说明如果 chunk 记录了标题路径,系统就可以生成更精确的引用。例如:
依据:《课程预约与改期规则》二、课程改期规则 > 2.1 免费改期条件。
这比只说"来源:课程预约与改期规则"更清楚。
常见结构字段包括:
| 字段 | 说明 |
|---|---|
h1_title |
一级标题 |
h2_title |
二级标题 |
h3_title |
三级标题 |
title |
拼接后的完整标题路径 |
page_number |
PDF 或文档页码 |
section_number |
章节编号 |
如何提取结构信息
不同格式的文档提取方式不同:
- Markdown:根据
#、##、###提取标题层级。 - HTML:解析一级、二级、三级标题标签。
- Word:通过 Apache POI 读取段落样式,识别标题样式。
- PDF:需要结合字体大小、加粗、位置等信息推断标题,也可以依赖更专业的 PDF 解析工具。
工程上常见做法是在分块时维护"当前标题路径"。每切出一个 chunk,就把最近的标题层级写入元数据。
Java 示例:给 chunk 添加标题层级
java
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class StructureMetadataExample {
public static Document create_chunk_with_structure(
String content,
String h1_title,
String h2_title,
int page_number) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("h1_title", h1_title);
metadata.put("h2_title", h2_title);
metadata.put("page_number", page_number);
String title_path = h1_title + " > " + h2_title;
metadata.put("title", title_path);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunk_content = "课程开始前 24 小时以上,学员可申请免费改期。";
Document chunk = create_chunk_with_structure(
chunk_content,
"二、课程改期规则",
"2.1 免费改期条件",
2
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Title path: " + chunk.getMetadata().get("title"));
System.out.println("Page: " + chunk.getMetadata().get("page_number"));
}
}标题层级不需要无限深入。多数业务文档记录到 H1-H3 已经足够,过深的结构反而会增加展示复杂度。
3. 时间版本类:创建时间、更新时间、生效时间、失效时间
在线教育平台的规则经常变化:
- 课程改期规则可能从某一天开始调整。
- 促销活动有明确的开始和结束时间。
- 考试安排每期不同。
- 证书发放规则可能随课程版本变化。
如果不记录时间和版本,系统可能召回过期内容,造成错误回答。
常见字段包括:
| 字段 | 说明 |
|---|---|
created_at |
chunk 创建时间,通常由系统生成 |
updated_at |
chunk 最近更新时间 |
effective_date |
规则生效时间 |
expiration_date |
规则失效时间 |
version |
文档或规则版本 |
例如用户问"现在改期要收费吗?",系统可以在检索时过滤掉已经失效的 chunk,只保留当前有效规则。
Java 示例:给 chunk 添加时间版本
java
import org.springframework.ai.document.Document;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.HashMap;
import java.util.Map;
public class TimeMetadataExample {
public static Document create_chunk_with_time(
String content,
LocalDateTime created_at,
LocalDateTime effective_date,
LocalDateTime expiration_date,
String version) {
Map<String, Object> metadata = new HashMap<>();
DateTimeFormatter formatter = DateTimeFormatter.ISO_LOCAL_DATE_TIME;
metadata.put("created_at", created_at.format(formatter));
metadata.put("version", version);
if (effective_date != null) {
metadata.put("effective_date", effective_date.format(formatter));
}
if (expiration_date != null) {
metadata.put("expiration_date", expiration_date.format(formatter));
}
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunk_content = "课程开始前 24 小时内申请改期,将扣除一次改期权益。";
Document chunk = create_chunk_with_time(
chunk_content,
LocalDateTime.now(),
LocalDateTime.of(2026, 4, 1, 0, 0),
null,
"v2.0"
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Effective from: " + chunk.getMetadata().get("effective_date"));
System.out.println("Version: " + chunk.getMetadata().get("version"));
}
}时间字段建议使用 ISO 8601 格式,例如 2026-04-01T00:00:00。这样 Java、Python、数据库和向量存储系统都更容易解析。
4. 权限控制类:角色、部门、ACL、敏感级别
权限控制类元数据解决的是"当前用户能不能看到这个 chunk"。
ACL 是 Access Control List,即访问控制列表。它记录哪些角色、部门或用户可以访问某个资源。在 RAG 系统中,ACL 可以下沉到 chunk 级别,让检索结果天然符合权限要求。
例如:
latex
{
"content": "讲师课酬按课程类型、授课时长和满意度评分综合计算。",
"metadata": {
"access_roles": ["academic_admin", "finance_admin"],
"access_departments": ["academic_operations", "finance"],
"sensitivity_level": "confidential"
}
}这段内容不应返回给普通学员。即使它和查询语义高度相关,也应该在检索阶段被过滤掉。
常见权限字段包括:
| 字段 | 说明 |
|---|---|
access_roles |
可访问角色,如 student 、teaching_assistant 、academic_admin |
access_departments |
可访问部门或业务组 |
access_users |
可访问用户 ID 列表,适合精细控制 |
sensitivity_level |
敏感级别,如 public 、internal 、confidential 、restricted |
Java 示例:给 chunk 添加权限标签
java
import org.springframework.ai.document.Document;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class AccessControlExample {
public static Document create_chunk_with_acl(
String content,
List<String> access_roles,
List<String> access_departments,
String sensitivity_level) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("access_roles", access_roles);
metadata.put("access_departments", access_departments);
metadata.put("sensitivity_level", sensitivity_level);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunk_content = "讲师课酬按课程类型、授课时长和满意度评分综合计算。";
Document chunk = create_chunk_with_acl(
chunk_content,
Arrays.asList("academic_admin", "finance_admin"),
Arrays.asList("academic_operations", "finance"),
"confidential"
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Access roles: " + chunk.getMetadata().get("access_roles"));
System.out.println("Sensitivity: " + chunk.getMetadata().get("sensitivity_level"));
}
}检索时如何过滤权限
权限过滤应尽量发生在向量数据库检索阶段,而不是生成答案之后再过滤。原因是:如果敏感 chunk 已经被取回并进入 prompt,即使最终没有展示,也可能带来安全风险。
伪代码如下:
java
String user_role = "student";
String user_department = "learner_service";
Map<String, Object> filter = new HashMap<>();
filter.put("access_roles", user_role);
filter.put("sensitivity_level", "public");
List<Document> results = vector_store.search(
query,
top_k,
filter
);Milvus、Qdrant、Weaviate 等常见向量数据库都支持不同形式的元数据过滤,具体语法会有所差异,但核心思路一致:先用元数据约束候选集合,再做向量相似度召回或在召回过程中合并过滤条件。
5. 位置追溯类:start_offset、end_offset、chunk_index
位置追溯字段解决的是"出了问题如何回到原文"。
常见字段包括:
| 字段 | 说明 |
|---|---|
start_offset |
chunk 在原文中的起始字符位置 |
end_offset |
chunk 在原文中的结束字符位置 |
chunk_index |
chunk 在当前文档中的序号 |
total_chunks |
当前文档总 chunk 数 |
这些字段可以支持三类能力:
- 用户查看引用时,高亮原文中的相关片段。
- 运营或教务人员审核错误答案时,快速定位原文位置。
- 系统召回某个 chunk 后,可以按需加载相邻 chunk,补充上下文。
Java 示例:分块时记录位置
java
import org.springframework.ai.document.Document;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class PositionMetadataExample {
public static List<Document> chunk_with_position(
String full_text,
int chunk_size,
int overlap) {
if (overlap >= chunk_size) {
throw new IllegalArgumentException("overlap 必须小于 chunk_size");
}
List<Document> chunks = new ArrayList<>();
int step = chunk_size - overlap;
int start = 0;
int chunk_index = 0;
while (start < full_text.length()) {
int end = Math.min(start + chunk_size, full_text.length());
String chunk_content = full_text.substring(start, end);
Map<String, Object> metadata = new HashMap<>();
metadata.put("start_offset", start);
metadata.put("end_offset", end);
metadata.put("chunk_index", chunk_index);
metadata.put("total_length", full_text.length());
chunks.add(new Document(chunk_content, metadata));
start += step;
chunk_index++;
}
return chunks;
}
public static void main(String[] args) {
String full_text = "课程开始前 24 小时以上可以免费改期;课程开始前 24 小时内改期,将扣除一次改期权益。";
List<Document> chunks = chunk_with_position(full_text, 30, 5);
for (Document chunk : chunks) {
System.out.println("=== Chunk " + chunk.getMetadata().get("chunk_index") + " ===");
System.out.println("Content: " + chunk.getContent());
System.out.println("Position: " + chunk.getMetadata().get("start_offset")
+ " - " + chunk.getMetadata().get("end_offset"));
System.out.println();
}
}
}需要注意:offset 通常按字符计算,不等同于 UTF-8 字节位置。如果系统后续要根据字节流做定位,需要额外保存字节偏移。
6. 业务自定义类:课程类型、服务阶段、知识类型、优先级
通用字段无法覆盖所有业务需求。在线教育场景中,可以根据检索、过滤和排序需要增加自定义字段。
常见示例:
| 字段 | 说明 | 示例 |
|---|---|---|
course_category |
课程类别 | programming 、language 、exam_prep |
course_level |
课程难度 | beginner 、intermediate 、advanced |
service_stage |
服务阶段 | before_class 、in_class 、after_class |
knowledge_type |
知识类型 | policy 、faq 、sop 、tutorial |
priority |
排序优先级 | 1 、2 、3 |
例如用户问"Python 进阶课作业怎么交",系统可以优先检索 course_category = programming、course_level = intermediate、knowledge_type = faq 或 tutorial 的内容。
Java 示例:添加业务自定义元数据
java
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class CustomMetadataExample {
public static Document create_chunk_with_custom_metadata(
String content,
String course_category,
String course_level,
String service_stage,
String knowledge_type,
int priority) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("doc_id", "doc_course_service_001");
metadata.put("created_at", "2026-04-01T09:00:00Z");
metadata.put("course_category", course_category);
metadata.put("course_level", course_level);
metadata.put("service_stage", service_stage);
metadata.put("knowledge_type", knowledge_type);
metadata.put("priority", priority);
return new Document(content, metadata);
}
public static void main(String[] args) {
String chunk_content = "Python 进阶课作业需在课后 48 小时内提交,助教将在 3 个工作日内完成批改。";
Document chunk = create_chunk_with_custom_metadata(
chunk_content,
"programming",
"intermediate",
"after_class",
"faq",
1
);
System.out.println("Chunk content: " + chunk.getContent());
System.out.println("Course category: " + chunk.getMetadata().get("course_category"));
System.out.println("Priority: " + chunk.getMetadata().get("priority"));
}
}自定义元数据要克制。只添加能用于检索、过滤、排序、展示或运维的字段,不要把所有业务字段都塞进 metadata。
元数据的三大核心应用场景
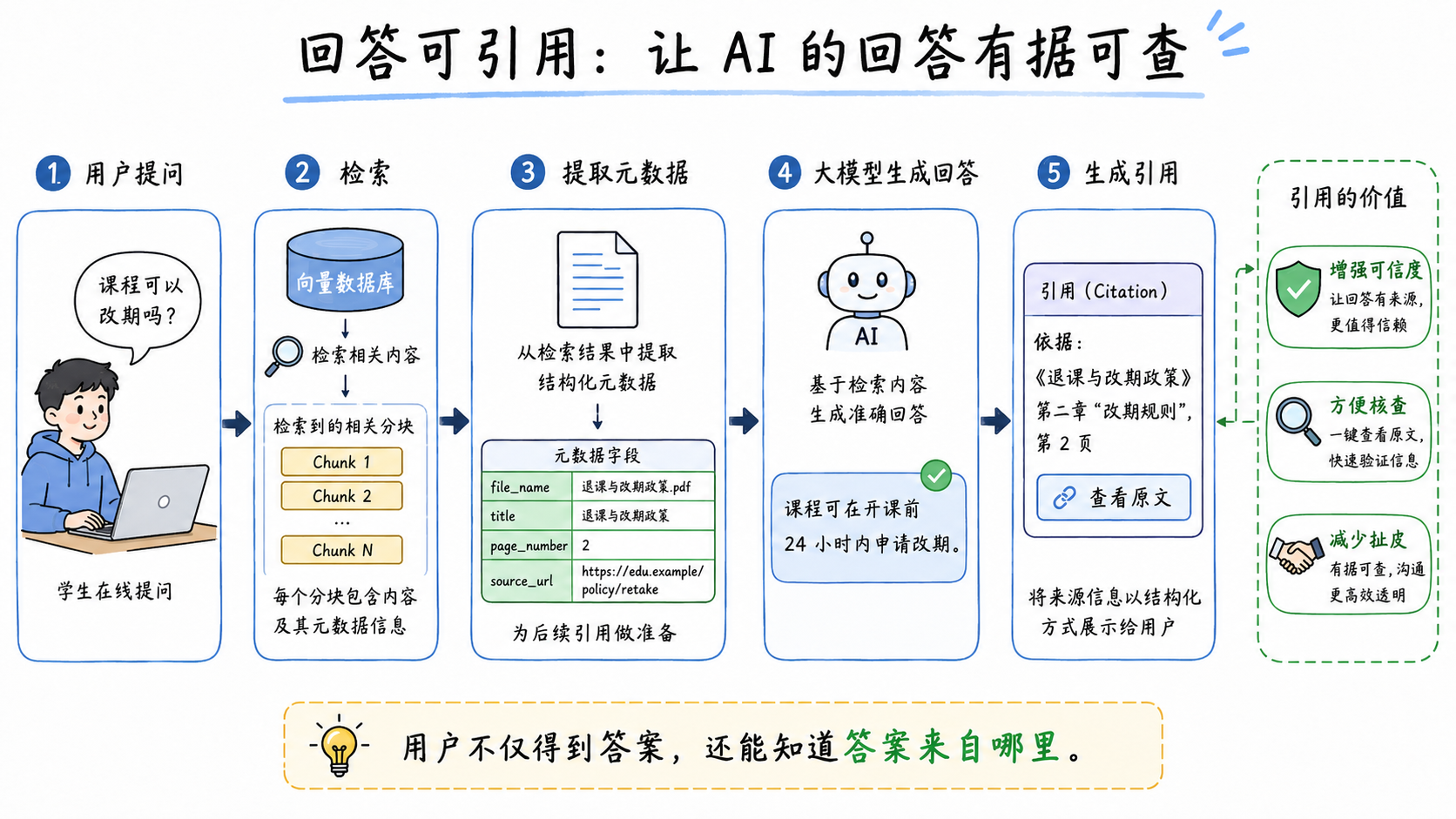
1. 回答可引用:让 AI 的答案有据可查
用户问:
课程开始前多久可以免费改期?
系统回答:
课程开始前 24 小时以上可以免费改期。
依据:《课程预约与改期规则》二、课程改期规则 > 2.1 免费改期条件,第 2 页。
这就是引用生成。检索到 chunk 后,系统从元数据中读取 file_name、title、page_number、source_url,拼接成可展示的依据。
流程可以概括为:
latex
用户问题
↓
向量检索召回相关 chunk
↓
读取 chunk 元数据
↓
构建引用信息
↓
将问题、chunk 内容、引用信息放入 prompt
↓
大模型生成答案
↓
返回答案 + 来源Java 示例:生成引用信息
java
import org.springframework.ai.document.Document;
import java.util.HashMap;
import java.util.Map;
public class CitationExample {
public static String generate_citation(Document chunk) {
Map<String, Object> metadata = chunk.getMetadata();
String file_name = (String) metadata.get("file_name");
String title = (String) metadata.get("title");
Integer page_number = (Integer) metadata.get("page_number");
String source_url = (String) metadata.get("source_url");
StringBuilder citation = new StringBuilder();
citation.append("**依据**:");
if (file_name != null) {
citation.append("《").append(file_name).append("》");
}
if (title != null) {
citation.append(" ").append(title);
}
if (page_number != null) {
citation.append(",第 ").append(page_number).append(" 页");
}
if (source_url != null) {
citation.append("\n\n[查看原文](").append(source_url).append(")");
}
return citation.toString();
}
public static void main(String[] args) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("file_name", "课程预约与改期规则.md");
metadata.put("title", "二、课程改期规则 > 2.1 免费改期条件");
metadata.put("page_number", 2);
metadata.put("source_url", "/knowledge/course/reschedule-policy#section-2-1");
Document chunk = new Document(
"课程开始前 24 小时以上,学员可申请免费改期。",
metadata
);
String citation = generate_citation(chunk);
System.out.println("Answer: " + chunk.getContent());
System.out.println("\n" + citation);
}
}引用信息可以增强答案可信度,也方便学员、客服和教务人员核查原文。
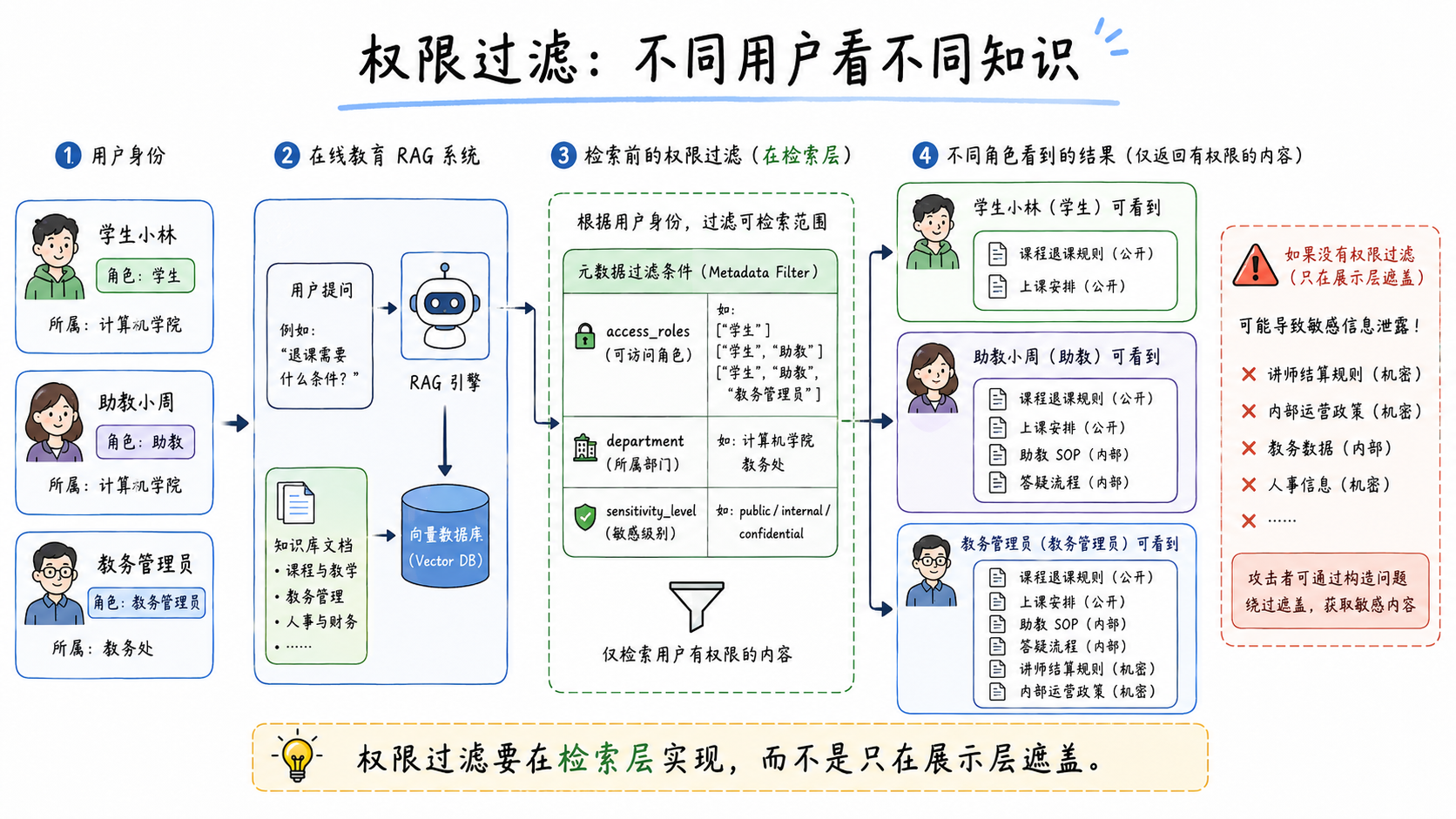
2. 权限过滤:不同角色看到不同知识
在同一个知识库中,学员、助教、教研、教务管理员看到的内容不同。
例如:
public:课程介绍、学习指南、退课改期规则,学员可见。internal:助教服务 SOP、班级管理流程,内部人员可见。confidential:讲师结算规则、渠道投放策略,限定角色可见。
检索时应先获取当前用户身份,再把权限条件传给向量数据库。只有通过权限判断的 chunk 才能进入后续生成阶段。
Java 示例:基于权限过滤 chunk
java
import org.springframework.ai.document.Document;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class PermissionFilterExample {
private static List<Document> mock_chunks() {
List<Document> chunks = new ArrayList<>();
Map<String, Object> metadata_1 = new HashMap<>();
metadata_1.put("sensitivity_level", "public");
metadata_1.put("access_roles", Arrays.asList("student", "teaching_assistant"));
chunks.add(new Document("课程开始前 24 小时以上可以免费改期。", metadata_1));
Map<String, Object> metadata_2 = new HashMap<>();
metadata_2.put("sensitivity_level", "confidential");
metadata_2.put("access_roles", Arrays.asList("academic_admin", "finance_admin"));
chunks.add(new Document("讲师课酬按课程类型、授课时长和满意度评分综合计算。", metadata_2));
Map<String, Object> metadata_3 = new HashMap<>();
metadata_3.put("sensitivity_level", "internal");
metadata_3.put("access_roles", Arrays.asList("teaching_assistant", "academic_admin"));
chunks.add(new Document("助教需在课后 3 个工作日内完成作业批改。", metadata_3));
return chunks;
}
public static List<Document> filter_by_permission(
List<Document> chunks,
String user_role) {
return chunks.stream()
.filter(chunk -> has_permission(chunk, user_role))
.collect(Collectors.toList());
}
private static boolean has_permission(
Document chunk,
String user_role) {
Map<String, Object> metadata = chunk.getMetadata();
String sensitivity_level = (String) metadata.get("sensitivity_level");
if ("public".equals(sensitivity_level)) {
return true;
}
List<String> access_roles = (List<String>) metadata.get("access_roles");
return access_roles != null && access_roles.contains(user_role);
}
public static void main(String[] args) {
List<Document> all_chunks = mock_chunks();
System.out.println("=== 学员可见内容 ===");
List<Document> student_results = filter_by_permission(all_chunks, "student");
student_results.forEach(chunk -> System.out.println("- " + chunk.getContent()));
System.out.println("\n=== 助教可见内容 ===");
List<Document> assistant_results = filter_by_permission(all_chunks, "teaching_assistant");
assistant_results.forEach(chunk -> System.out.println("- " + chunk.getContent()));
}
}权限过滤的底线是:不要只在展示层过滤。敏感 chunk 不应该进入生成 prompt。
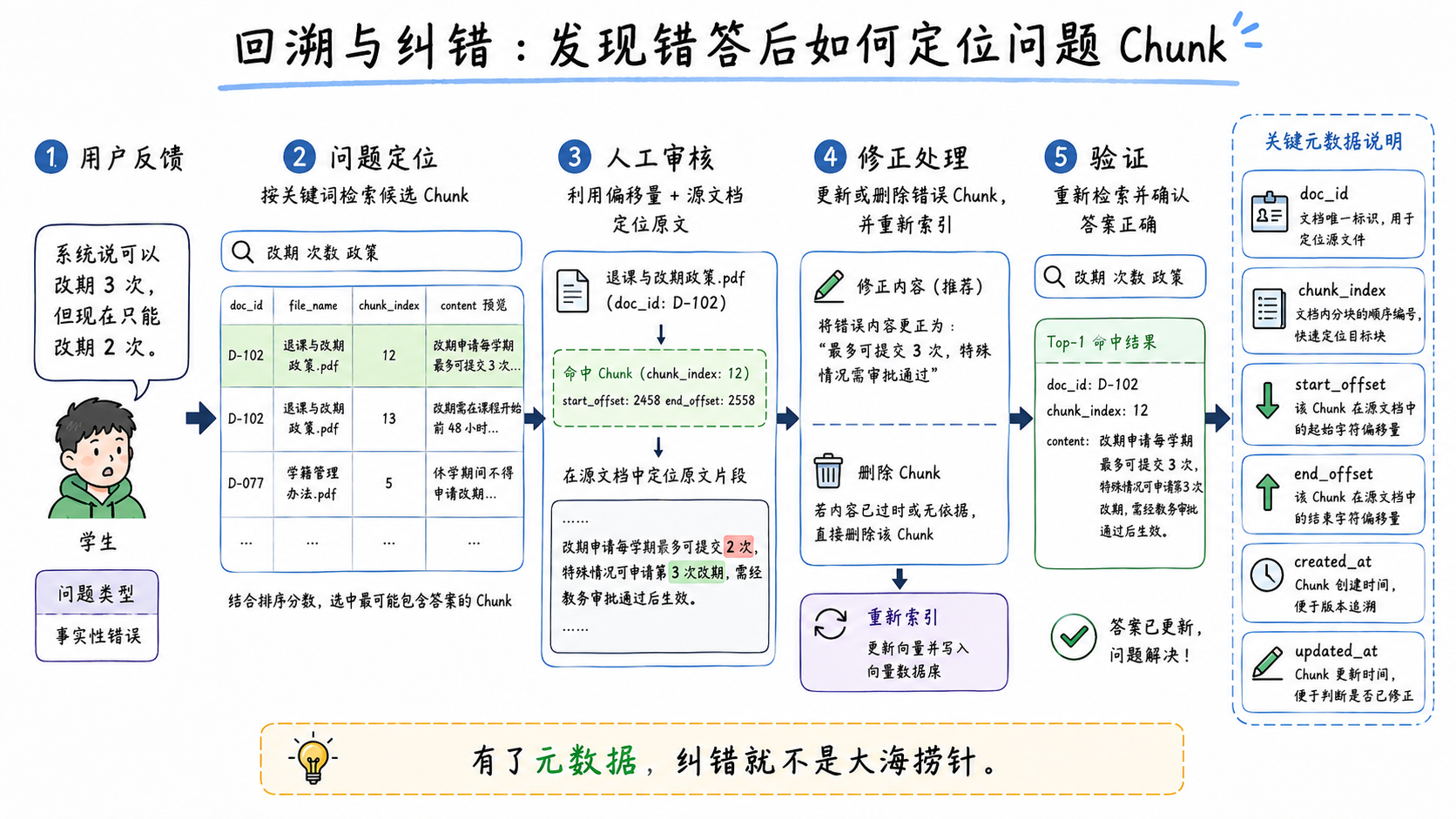
3. 回溯与纠错:发现错答后能定位源头
当用户反馈答案错误时,团队需要快速回答几个问题:
- 哪个 chunk 被召回了?
- 它来自哪份文档?
- 在原文的哪个位置?
- 这个文档是否已经过期?
- 是否有相邻 chunk 或同一文档的其他 chunk 也需要更新?
如果元数据设计完整,修复流程可以变成:
latex
用户反馈错误答案
↓
根据问题关键词或召回日志定位相关 chunk
↓
查看 doc_id、file_name、chunk_index、offset、version
↓
回到原始文档确认内容
↓
更新原文或删除过期 chunk
↓
重新分块、向量化、写入向量数据库
↓
回归测试典型问题Java 示例:定位并展示问题 chunk
java
import org.springframework.ai.document.Document;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class ErrorTrackingExample {
public static List<Document> find_chunks_by_keyword(
List<Document> all_chunks,
String keyword) {
List<Document> results = new ArrayList<>();
for (Document chunk : all_chunks) {
if (chunk.getContent().contains(keyword)) {
results.add(chunk);
}
}
return results;
}
public static void display_chunk_details(Document chunk) {
Map<String, Object> metadata = chunk.getMetadata();
System.out.println("=== Chunk 详情 ===");
System.out.println("内容: " + chunk.getContent());
System.out.println("文档 ID: " + metadata.get("doc_id"));
System.out.println("文件名: " + metadata.get("file_name"));
System.out.println("章节: " + metadata.get("title"));
System.out.println("Chunk 序号: " + metadata.get("chunk_index"));
System.out.println("原文位置: " + metadata.get("start_offset")
+ " - " + metadata.get("end_offset"));
System.out.println("版本: " + metadata.get("version"));
System.out.println("生效时间: " + metadata.get("effective_date"));
}
public static void main(String[] args) {
List<Document> all_chunks = new ArrayList<>();
Map<String, Object> metadata = new HashMap<>();
metadata.put("doc_id", "doc_edu_policy_20260101_legacy");
metadata.put("file_name", "旧版课程改期规则.md");
metadata.put("title", "二、课程改期规则 > 2.1 改期时限");
metadata.put("chunk_index", 4);
metadata.put("start_offset", 320);
metadata.put("end_offset", 386);
metadata.put("version", "v1.0");
metadata.put("effective_date", "2026-01-01T00:00:00");
all_chunks.add(new Document(
"课程开始前 2 小时以上,学员可申请免费改期。",
metadata
));
List<Document> problem_chunks = find_chunks_by_keyword(all_chunks, "免费改期");
problem_chunks.forEach(ErrorTrackingExample::display_chunk_details);
}
}有了这些信息,管理后台可以直接展示问题 chunk 的来源、版本和位置,教务人员可以快速判断是否需要下线旧规则或重新发布新版本。
元数据设计的最佳实践
1. 字段不是越多越好
元数据字段越多,维护成本越高。很多字段看起来"以后可能有用",但如果检索、过滤、排序、展示和运维都用不到,就会变成负担。
建议从最小可用集合开始:
latex
doc_id
file_name
source_url
title
chunk_index
created_at
updated_at
access_roles
sensitivity_level等系统跑起来后,再根据真实问题补充业务字段。
2. 粒度要和业务匹配
元数据可以在文档级、章节级、chunk 级维护。不同字段适合不同粒度:
| 粒度 | 适合字段 | 说明 |
|---|---|---|
| 文档级 | doc_id 、file_name 、source_url 、version |
整份文档一致 |
| 章节级 | title 、section_number 、course_category |
同一章节相同 |
| chunk 级 | chunk_index 、start_offset 、end_offset 、sensitivity_level |
每个 chunk 可能不同 |
不要为了省事只做文档级元数据。例如同一份内部手册中,前半部分可能是公开规则,后半部分可能是内部流程,权限字段就需要细化到章节或 chunk。
3. 权限过滤要前置
权限控制应当在检索阶段或向量数据库过滤阶段完成,而不是把所有结果拿回来再让大模型判断。
推荐流程:
latex
用户身份识别
↓
构造元数据过滤条件
↓
向量检索 + 元数据过滤
↓
只把有权限的 chunk 放入 prompt
↓
生成答案这能同时降低泄露风险和无效召回。
4. 时间版本要可治理
有生效时间和失效时间的规则,应该在检索时明确过滤。对于历史版本,可以保留但默认不参与普通用户查询。
常见策略:
- 普通问答只检索当前生效版本。
- 管理后台允许按版本检索历史规则。
- 文档更新时,通过
doc_id或version批量下线旧 chunk。 - 对高风险规则保留变更日志,方便审计。
5. 元数据字段命名要稳定
字段名一旦进入向量数据库、检索服务和后台管理系统,就会被多处依赖。命名要清晰、稳定、可读。
推荐使用统一的 snake_case,例如:
latex
doc_id
file_name
source_url
created_at
updated_at
effective_date
expiration_date
access_roles
sensitivity_level
course_category
knowledge_type避免使用 field1、tag_a、biz_type2 这类难以理解的名字。
元数据字段参考表
| 类别 | 字段 | 是否建议默认保留 | 用途 |
|---|---|---|---|
| 文档标识 | doc_id |
是 | 更新、删除、追溯 |
| 文档标识 | file_name |
是 | 引用展示 |
| 文档标识 | source_url |
是 | 查看原文 |
| 结构信息 | title |
是 | 引用、章节定位 |
| 结构信息 | h1_title / h2_title / h3_title |
视情况 | 结构化展示 |
| 结构信息 | page_number |
视情况 | PDF 引用与跳转 |
| 时间版本 | created_at |
是 | 数据治理 |
| 时间版本 | updated_at |
是 | 版本维护 |
| 时间版本 | effective_date |
视情况 | 规则生效过滤 |
| 时间版本 | expiration_date |
视情况 | 过期规则过滤 |
| 权限控制 | access_roles |
是 | 角色过滤 |
| 权限控制 | access_departments |
视情况 | 部门过滤 |
| 权限控制 | sensitivity_level |
是 | 敏感级别控制 |
| 位置追溯 | chunk_index |
是 | 定位 chunk |
| 位置追溯 | start_offset / end_offset |
视情况 | 原文高亮、纠错 |
| 业务自定义 | course_category |
视情况 | 课程类别过滤 |
| 业务自定义 | service_stage |
视情况 | 服务阶段过滤 |
| 业务自定义 | knowledge_type |
视情况 | FAQ、SOP、政策等类型过滤 |
| 业务自定义 | priority |
视情况 | 检索后排序 |
从 0 到 1 落地:推荐实施流程
如果团队第一次建设 RAG 元数据体系,不建议一开始就设计几十个字段。更稳妥的方式是先跑通最小闭环,再根据真实查询和运维问题逐步扩展。
可以按下面的顺序推进:
latex
明确知识库边界
↓
梳理用户角色和权限范围
↓
定义最小可用元数据字段
↓
在文档导入阶段生成 metadata
↓
在检索阶段加入 metadata filter
↓
在回答中展示引用来源
↓
记录召回日志和用户反馈
↓
根据错答案例迭代字段和过滤策略第一版建议先保留这些字段:
| 字段 | 用途 | 是否建议首版保留 |
|---|---|---|
doc_id |
文档唯一标识,支持更新、删除、追溯 | 是 |
file_name |
来源展示,便于用户理解引用 | 是 |
source_url |
跳转原文或后台详情页 | 是 |
title |
章节路径,提升引用可读性 | 是 |
chunk_index |
定位 chunk 顺序 | 是 |
access_roles |
角色过滤 | 是 |
sensitivity_level |
敏感级别控制 | 是 |
created_at / updated_at |
数据治理和问题排查 | 是 |
effective_date / expiration_date |
规则生效和过期过滤 | 规则类文档建议保留 |
等系统稳定后,再补充 course_category、service_stage、knowledge_type、priority 等业务字段。
完整落地示例:构造元数据并生成过滤条件
下面用一个更完整的 Java 示例,把"生成 chunk 元数据"和"构造检索过滤条件"放在一起。真实项目里,文档切分、Embedding 和向量库写入会由不同组件完成,但元数据字段最好在导入阶段一次性补齐。
java
import org.springframework.ai.document.Document;
import java.time.Instant;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class RagMetadataBuilder {
public static Document buildChunk(
String content,
String docId,
String fileName,
String title,
int chunkIndex,
int startOffset,
int endOffset,
List<String> accessRoles,
String sensitivityLevel) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("doc_id", docId);
metadata.put("file_name", fileName);
metadata.put("source_path", "/knowledge/course/reschedule-policy");
metadata.put("title", title);
metadata.put("chunk_index", chunkIndex);
metadata.put("start_offset", startOffset);
metadata.put("end_offset", endOffset);
metadata.put("access_roles", accessRoles);
metadata.put("sensitivity_level", sensitivityLevel);
metadata.put("effective_date", "2026-04-01T00:00:00Z");
metadata.put("expiration_date", null);
metadata.put("created_at", Instant.now().toString());
metadata.put("updated_at", Instant.now().toString());
return new Document(content, metadata);
}
public static Map<String, Object> buildSearchFilter(
String userRole,
Instant queryTime) {
Map<String, Object> filter = new HashMap<>();
filter.put("access_roles", userRole);
filter.put("sensitivity_level", "public");
filter.put("effective_date_lte", queryTime.toString());
filter.put("expiration_date_gt_or_null", queryTime.toString());
return filter;
}
public static void main(String[] args) {
Document chunk = buildChunk(
"课程开始前 24 小时以上,学员可申请免费改期。",
"doc_edu_policy_20260401_001",
"课程预约与改期规则.md",
"二、课程改期规则 > 2.1 免费改期条件",
3,
128,
214,
List.of("student", "teaching_assistant", "academic_admin"),
"public"
);
Map<String, Object> filter = buildSearchFilter("student", Instant.now());
System.out.println(chunk.getContent());
System.out.println(chunk.getMetadata());
System.out.println(filter);
}
}这个示例里用了 source_path 而不是外部 URL,是为了避免示例链接被误识别为不可访问链接。生产系统中可以根据情况使用真实 source_url、后台文档详情页地址,或者内部知识库路径。
主流向量数据库的元数据过滤对照
不同向量数据库对元数据字段的叫法不同,但本质都是"向量 + 结构化字段"一起存储,并在检索时用结构化字段缩小候选范围。
| 向量数据库 | 元数据常见叫法 | 过滤能力要点 | 示例场景 |
|---|---|---|---|
| Qdrant | Payload | 支持基于 payload 的条件过滤,适合按角色、时间、分类过滤 | access_roles 包含 student |
| Milvus | Scalar Field | 支持标量字段过滤,可在向量检索前缩小搜索范围 | status == "active" |
| Weaviate | Property / Metadata | 支持 filtered vector search,可组合结构化过滤和向量检索 | knowledge_type == "policy" |
| Elasticsearch | Field | 适合关键词、结构化过滤和向量检索混合场景 | course_category == "programming" |
| PGVector | Column | 通过 SQL 条件和向量距离组合检索 | tenant_id = ? AND expires_at > now() |
以 Qdrant 风格为例,权限和生效时间可以写成类似下面的过滤结构:
json
{
"must": [
{
"key": "access_roles",
"match": {
"value": "student"
}
},
{
"key": "sensitivity_level",
"match": {
"value": "public"
}
},
{
"key": "status",
"match": {
"value": "active"
}
}
]
}以 Milvus 风格为例,可以把过滤条件表达成标量过滤字符串:
latex
access_role == "student" and sensitivity_level == "public" and status == "active"以 SQL + PGVector 风格为例,可以把权限过滤和向量距离排序放在同一条查询里:
sql
SELECT content, metadata
FROM rag_chunks
WHERE access_roles @> ARRAY['student']
AND sensitivity_level = 'public'
AND status = 'active'
ORDER BY embedding <-> :query_embedding
LIMIT 5;真正上线时,不要只关注"能不能过滤",还要关注过滤字段是否建索引。高频过滤字段通常包括:
tenant_id:多租户隔离;access_roles:角色权限;sensitivity_level:敏感级别;status:是否生效;doc_id:按文档更新或删除;course_category:业务分类;updated_at:增量同步和审计。
元数据字段字典模板
为了避免字段名混乱,建议在项目早期维护一份元数据字段字典。下面是一份可以直接复用的模板。
| 字段 | 类型 | 必填 | 默认值 | 维护粒度 | 说明 |
|---|---|---|---|---|---|
doc_id |
string | 是 | 无 | 文档级 | 文档唯一 ID |
chunk_id |
string | 是 | 系统生成 | chunk 级 | chunk 唯一 ID |
file_name |
string | 是 | 无 | 文档级 | 原始文件名或页面标题 |
source_path |
string | 否 | 空 | 文档级 | 内部知识库路径或真实来源地址 |
title |
string | 是 | 空字符串 | 章节级 | 完整标题路径 |
chunk_index |
integer | 是 | 0 | chunk 级 | 当前 chunk 在文档中的序号 |
start_offset |
integer | 否 | null | chunk 级 | 原文起始字符位置 |
end_offset |
integer | 否 | null | chunk 级 | 原文结束字符位置 |
access_roles |
array | 是 | ["student"] |
章节级或 chunk 级 | 可访问角色 |
sensitivity_level |
string | 是 | public |
章节级或 chunk 级 | 敏感级别 |
status |
string | 是 | active |
文档级或 chunk 级 | 是否参与普通检索 |
effective_date |
datetime | 否 | null | 规则级 | 生效时间 |
expiration_date |
datetime | 否 | null | 规则级 | 失效时间 |
updated_at |
datetime | 是 | 系统生成 | chunk 级 | 最近更新时间 |
字段字典的价值不是"写得好看",而是让导入脚本、检索服务、后台管理和运营审核使用同一套语言。只要字段定义稳定,后续扩展和排查都会轻很多。
常见问题 FAQ
1. 元数据要不要参与向量化?
大多数情况下,doc_id、access_roles、sensitivity_level、chunk_index 这类字段不需要参与向量化。它们是过滤和治理字段,不是语义内容。
可以考虑参与向量化的字段包括 title、summary、tags。这些字段能补充正文语义,尤其适合正文很短、标题很关键的知识片段。
2. 元数据字段越多,检索效果会越好吗?
不会。字段越多,维护成本越高,过滤条件也越容易互相冲突。元数据字段要围绕检索、权限、引用、排序和运维来设计,不能为了"看起来完整"无限扩展。
3. 权限过滤放在生成答案之后可以吗?
不建议。敏感 chunk 一旦进入 prompt,就已经产生泄露风险。更安全的方式是在向量检索阶段就完成权限过滤,只让用户有权访问的 chunk 进入后续生成流程。
4. 旧版本文档要不要直接删除?
不一定。普通问答可以默认只检索当前生效版本;管理后台可以保留历史版本,用于审计、投诉处理和规则回溯。关键是要有 status、version、effective_date、expiration_date 这些字段来区分新旧内容。
5. 出现错答时,最先检查什么?
优先看召回日志:被召回的 doc_id、chunk_index、title、updated_at、status 是否正确。很多 RAG 错答并不是大模型"胡说",而是检索阶段召回了旧内容、无权限内容或上下文不完整的 chunk。
检索阶段的过滤示例
元数据真正发挥作用的地方,往往不是写入向量库时,而是用户发起查询时。
以"学员查询课程改期规则"为例,系统可以先根据用户身份构造过滤条件:
json
{
"access_roles": {
"$contains": "student"
},
"sensitivity_level": {
"$in": ["public"]
},
"effective_date": {
"$lte": "2026-06-08T00:00:00Z"
},
"expiration_date": {
"$or": [
{ "$is_null": true },
{ "$gt": "2026-06-08T00:00:00Z" }
]
}
}不同向量数据库的过滤语法不完全相同,Qdrant、Milvus、Weaviate、Elasticsearch、PGVector 都有自己的表达方式。但核心原则一致:
- 权限过滤要在召回前或召回过程中完成;
- 过期内容默认不参与普通问答;
- 高风险内容不能进入 prompt;
- 引用展示依赖
file_name、title、page_number、source_url等字段。
元数据治理中的常见坑
1. 只做文档级权限,不做 chunk 级权限
很多内部文档是混合内容:前几章可能是公开规则,后几章可能是内部操作流程。如果只在文档级设置权限,就容易出现"同一份文档要么全公开、要么全隐藏"的问题。
更好的做法是:文档级权限作为默认值,章节级或 chunk 级权限允许覆盖默认值。
2. 字段定义不统一
同一个概念不要出现多种字段名,例如 role、roles、access_role、access_roles 混用。字段名一旦进入向量库、检索服务和后台管理系统,后续修改成本会很高。
建议在项目早期维护一份元数据字段字典,至少包含字段名、类型、是否必填、默认值、用途和示例。
3. 过期内容没有下线策略
很多错答不是模型能力问题,而是知识库里同时存在新旧规则。只要旧规则还在参与检索,系统就可能召回错误内容。
对于规则类文档,建议同时使用:
effective_date:规则开始生效时间;expiration_date:规则失效时间;version:文档或规则版本;status:如active、deprecated、archived。
普通问答只检索 active 且当前生效的 chunk,管理后台再保留历史版本检索能力。
4. 把元数据当成正文一起向量化
元数据主要用于过滤、排序、展示和追溯,不一定适合直接拼进正文参与 embedding。尤其是 access_roles、sensitivity_level、doc_id 这类字段,通常不应该影响语义相似度。
更合理的做法是:正文用于生成向量,元数据作为结构化字段单独存储。对于 title、summary、tags 等会影响语义理解的字段,可以根据业务需要拼入待向量化文本,但要明确规则。
参考资料
CSDN 发布前检查清单
这篇文章已经按 CSDN 更友好的 Markdown 形式整理。正式发布前,可以再检查一次:
- 标题是否只有一个一级标题;
- 图片是否能正常加载,必要时上传到 CSDN 图床;
- 表格中是否没有字体样式标签、强制换行标签等残留 HTML;
- 代码块是否标注了语言,例如
java、json、text; - 行内代码是否只使用反引号,例如
doc_id; - 列表是否统一使用
-或数字列表; - 外链是否可以访问;
- 文章末尾是否有清晰总结,便于读者带走核心结论。
总结
元数据是 RAG 系统从"能检索"走向"可落地"的关键环节。
文本 chunk 解决的是内容召回问题,元数据解决的是上下文、权限、引用和运维问题。在在线教育平台中,课程预约、退课改期、考试安排、作业批改、证书发放等规则都需要清晰可追溯;助教 SOP、讲师结算、内部教研资料等内容也必须受到权限约束。
一个可靠的元数据体系至少应该回答四个问题:
- 这个 chunk 来自哪里?
- 当前用户能不能看?
- 这条规则现在是否有效?
- 出现错答后能不能定位并修复?
从工程实践看,建议先建立最小可用元数据集合,再随着业务复杂度逐步扩展。不要一开始就追求字段大而全,更不要忽略权限、版本和引用这些真正影响线上质量的关键字段。
当元数据设计合理时,RAG 系统的回答会更可信,检索结果会更安全,后续维护也会更可控。