目录
写在前面
learn-claude-code 项目目前有两条教程线,一条是之前的 s12 章节的,另一条是最近更新的 s20 章节的,大家如果刚学习这个项目的话推荐直接看最新的 s20 章节的教程即可,由于博主之前学习过 s12 章节的内容,因此打算把 s20 章节中新增章节的内容给补充学习,内容重复的章节博主这边就跳过了。
下面是旧版到新版的对应关系:
| Legacy 12-lesson track | Current 20-lesson track | Topic |
|---|---|---|
| old s01 | new s01 | Agent Loop |
| old s02 | new s02 | Tool Use |
| old s03 | new s05 | TodoWrite |
| old s04 | new s06 | Subagent |
| old s05 | new s07 | Skill Loading |
| old s06 | new s08 | Context Compact |
| old s07 | new s12 | Task System |
| old s08 | new s13 | Background Tasks |
| old s09 | new s15 | Agent Teams |
| old s10 | new s16 | Team Protocols |
| old s11 | new s17 | Autonomous Agents |
| old s12 | new s18 | Worktree Isolation |
| new only | s03, s04, s09, s10, s11, s14, s19, s20 | Permission, Hooks, Memory, System Prompt, Error Recovery, Cron, MCP, Comprehensive Agent |
从上表中我们可以看出我们需要补充的内容包括 s03(已补充) 、s04(已补充) 、s09(已补充) 、s10(已补充) 、s11(已补充) 、s14(已补充) 、s19(已补充) 以及 s20(已补充) 八个章节的内容。
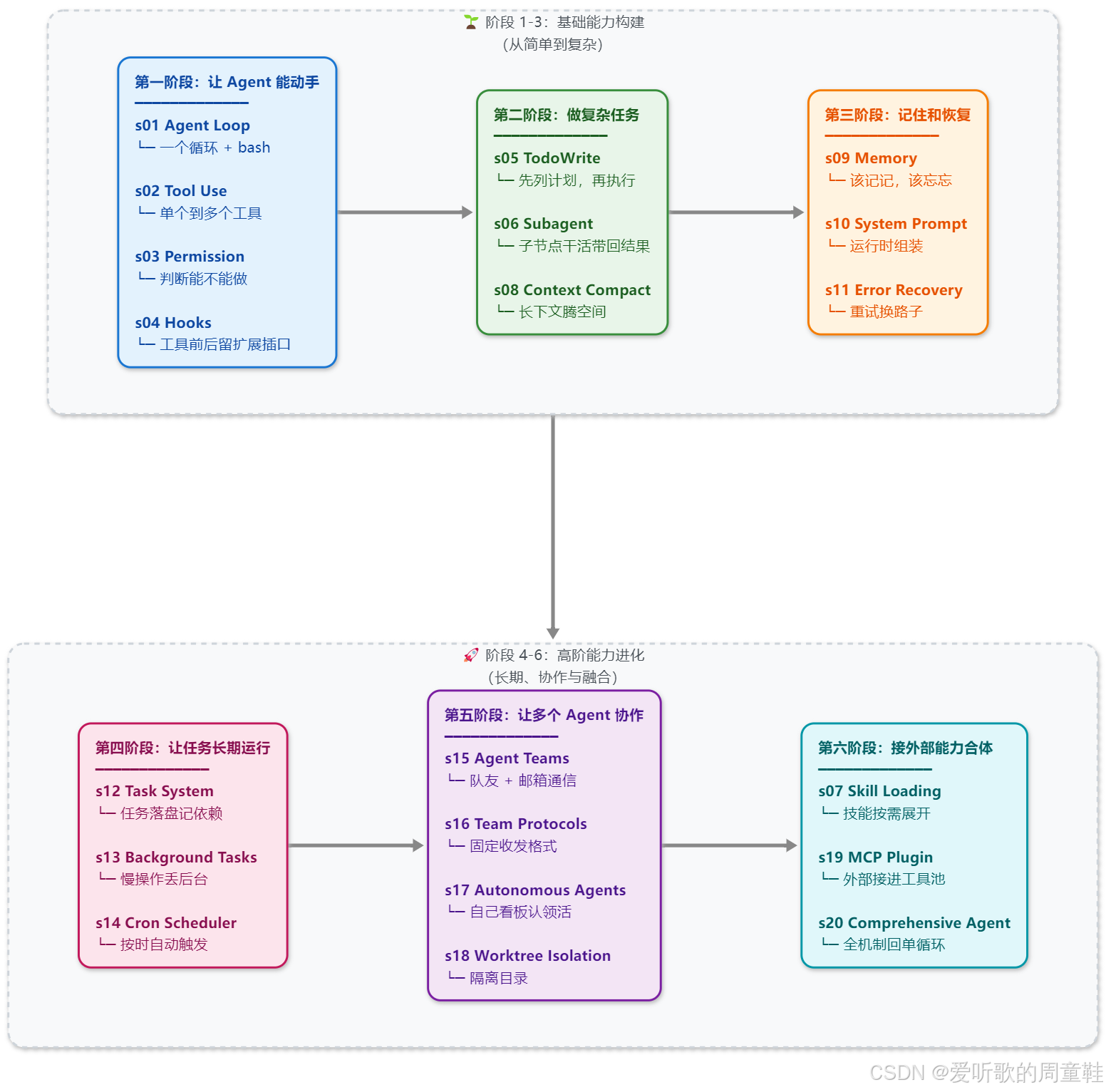
新版学习路径如下:
主线:能动手 → 能做复杂任务 → 能记住和恢复 → 能长期运行 → 能协作 → 能扩展并合体
前言
在上篇文章 Learn-Claude-Code | 笔记 | Multi-Agent Platform | s19_new MCP Plugin 中,我们介绍了开源项目 learn-claude-code 新版第十九个章节 s19_new: MCP Plugin 的内容,这篇文章我们继续跟着教程文档来学习多 Agent 相关内容,记录下个人学习笔记,和大家一起分享交流😄
Note:本篇文章主要学习记录 新版教程 第五部分 Multi-Agent Platform 中 s20: Comprehensive Agent 章节的内容。
github :https://github.com/shareAI-lab/learn-claude-code
reference :https://chatgpt.com/
1. s20: Comprehensive Agent
到了 s20,这个项目终于走到了最后一章:Comprehensive Agent。
如果说前面的章节是在一块一块地搭建 Agent Harness,那么 s20 做的事情就是把这些零散的机制重新收束到同一个系统里。它不再单独讲某一个机制,而是把前面已经学过的 Tool、Permission、Hooks、Todo、Subagent、Skill、Context Compact、Memory、System Prompt、Error Recovery、Task System、Background Tasks、Cron Scheduler、Agent Teams、Team Protocols、Autonomous Agents、Worktree Isolation 以及 MCP Plugin 全部整合到一个完整的 Agent Loop 中。
这也是本节标题中 "Comprehensive" 的含义:它不是再发明一个新的局部能力,而是把前 19 节已经出现过的机制统一放回同一个 while True 循环,让它们共同服务于一个真正可运行、可扩展、可长期执行任务的 Agent Harness。
回过头看整个系列,s01 和 s02 让模型具备了最基础的循环和工具调用能力;s03 和 s04 给工具执行增加了权限边界和 Hook 扩展点;s05 到 s08 解决的是复杂任务中的计划、子任务、技能和上下文压缩;s09 到 s11 进一步引入长期记忆、动态 System Prompt 和错误恢复;s12 到 s14 让 Agent 可以管理任务、后台执行和定时调度;s15 到 s18 则把单 Agent 扩展成团队协作、协议治理、自治认领和 worktree 隔离;s19 最后让工具系统突破本地边界,可以通过 MCP 接入外部服务。
但是,在真实的 Agent 系统中,这些机制不可能各自独立存在。模型不能一会儿在 Memory 系统里工作,一会儿在 Cron 系统里工作,一会儿又进入 MCP 系统。真正的工程问题是:所有机制最终都必须回到同一个模型调用循环中,并且以一致的方式进入 messages、system prompt、tool pool 和 tool_result。
所以 s20 的核心结论可以概括为一句话:
机制很多,但循环只有一个。工具、权限、记忆、任务、团队、worktree、MCP 和错误恢复,最终都要挂回同一个 Agent Loop。
2. 问题
在前 19 章中,每一章基本只引入一个新机制。这样做非常适合学习,因为每次只需要理解一个局部变化。例如 s03 只关注 Permission,s04 只关注 Hooks,s09 只关注 Memory,s14 只关注 Cron Scheduler,s19 只关注 MCP Plugin。每一节都可以把一个机制单独拿出来讲清楚。
但是这也带来一个问题:单独看每个机制时,它们都很清晰;一旦要把它们放到真实 Agent 中同时运行,系统就会变复杂。
一个真正能长期工作的 coding agent,不可能只会调用 bash 和 read_file。它至少需要同时具备下面这些能力:首先,它要有工具调用能力,能够读写文件、执行命令、编辑代码;其次,它要有权限边界,不能让模型直接执行危险命令;然后,它要有 Hook 扩展点,让日志、审计、权限检查、大输出监控等逻辑可以插入循环,而不是写死在每个工具里;接着,它还需要 Todo 和 Task System 来管理短期计划和长期任务;如果任务复杂,还需要 Subagent、Teammate 和 Team Protocols 来分工协作;如果代码修改有冲突风险,还需要 Worktree Isolation 来提供独立执行目录;如果任务耗时较长,还需要 Background Tasks;如果任务需要定时触发,还需要 Cron Scheduler;如果模型上下文越来越长,还需要 Context Compact;如果要跨会话记住用户偏好和项目状态,还需要 Memory;如果要把这些动态状态告诉模型,还需要 System Prompt Assembly;如果模型调用失败,还需要 Error Recovery;如果本地工具不够,还需要通过 MCP 接入外部工具。
这时真正困难的地方就不是 "有没有这些功能",而是 "这些功能应该挂在循环的哪个位置"。
如果随意堆叠这些功能,Agent Loop 很容易变成一团乱麻。例如,Cron 到点触发的任务到底应该直接执行,还是先进入 messages?后台任务完成后的结果是直接打印,还是交给模型继续推理?Memory 是每轮都加载,还是只在用户显式询问时加载?MCP 工具连接后,模型下一轮如何知道新增了工具?Permission 是写在 bash 里,还是写在所有工具前的统一门禁里?错误恢复是包住整个循环,还是只包住模型调用?
这些问题如果没有统一设计,Agent Harness 就会越来越难维护。每新增一个机制,都可能需要修改主循环;每新增一个工具,都可能需要改 System Prompt;每新增一种后台事件,都可能破坏 messages 的结构。
因此,s20 要解决的问题并不是再增加一个功能,而是要回答:
当 Agent 同时拥有工具、权限、Hooks、Memory、Skills、Prompt Assembly、Error Recovery、Task、Cron、Background、Team、Worktree 和 MCP 时,如何把它们统一挂在同一个 Agent Loop 上,并保持系统仍然可理解、可调试、可扩展?
这就是 s20 的核心问题。
它要把前面所有机制重新归位,让我们看清楚:哪些逻辑发生在 LLM 调用之前,哪些逻辑发生在工具执行之前,哪些逻辑发生在工具执行之后,哪些逻辑作为结果回到 messages,哪些逻辑只影响 system prompt,哪些逻辑需要后台线程,哪些逻辑需要跨会话持久化。
3. 解决方案
s20 的解决方案可以概括为一句话:
不改变 Agent Loop 的基本形状,而是在循环前、循环中、工具前、工具后和循环结束处挂载前面所有机制。
也就是说,s20 并没有推翻前面章节反复使用的结构。Agent 的核心循环仍然是:
python
while True:
response = client.messages.create(...)
messages.append({"role": "assistant", "content": response.content})
if not has_tool_use(response.content):
return
results = []
for block in response.content:
if block.type == "tool_use":
output = handler(**block.input)
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
messages.append({"role": "user", "content": results})这条主线从 s01 到 s20 一直没有变。模型负责根据 messages 和 system prompt 生成响应;如果响应中包含 tool_use,harness 就执行工具;工具结果被包装成 tool_result,再作为 user-side content 回到 messages;下一轮模型继续读取这些结果并做出决策。
s20 的变化在于:这个循环周围的 harness 变完整了。
在模型调用之前,系统会先消费 Cron Queue,把到点触发的定时任务注入 messages;然后收集 Background Tasks 的完成通知,把后台任务结果以 <task_notification> 的形式注入 messages;接着执行上下文压缩管线,避免上下文超过窗口;然后重新读取 Memory、MCP 状态、活跃队友等运行时状态,并组装新的 system prompt;最后动态组装工具池,把内置工具和已连接的 MCP 工具合并成一个模型可见的工具列表。
在模型调用阶段,s20 加入了完整的 Error Recovery。模型调用不是裸调用,而是通过 call_llm() 和 with_retry() 包裹起来。遇到 429 会指数退避重试;遇到 529 会重试,连续失败时可以切换 fallback model;遇到 prompt too long 会触发 reactive compact;遇到 max_tokens 会先提升输出 token 预算,再尝试 continuation。
在工具执行之前,s20 统一触发 PreToolUse hooks。这里会执行 permission 检查、日志记录等逻辑。也就是说,工具不是模型一申请就直接运行,而是要先经过 harness 的统一门禁。危险命令、越界写文件、破坏性 MCP 工具,都可以在这个阶段被拦截。
在工具执行阶段,s20 不再只有本地工具。它的工具池包含文件工具、shell 工具、Todo 工具、Task 工具、Skill 工具、Compact 工具、Cron 工具、Team 工具、Protocol 工具、Worktree 工具和 MCP 工具。所有工具都通过 assemble_tool_pool() 组装成统一工具池,然后通过 handlers 分发执行。
在工具执行之后,s20 会触发 PostToolUse hooks,例如大输出检查。然后把工具结果加入 results,最后通过 build_user_content(results) 把普通工具结果和后台任务通知一起回填到 messages 中。
如果模型本轮没有继续请求工具,s20 会触发 Stop hooks,进行本轮统计、审计或清理。
教程文档中提供了一张提供总架构图,我们来看下:
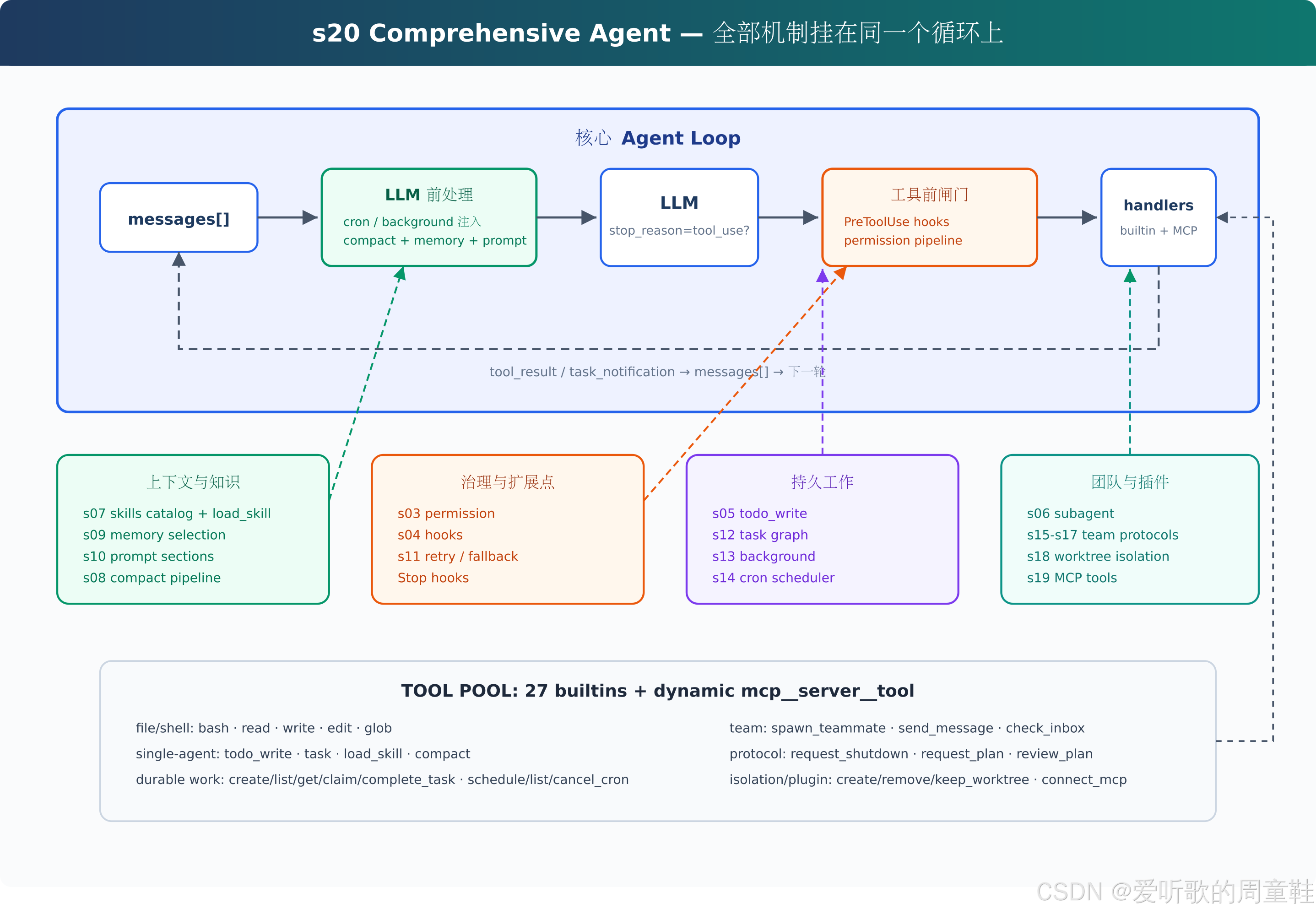
这张图是 s20 最关键的图。它把整个系统分成了一个核心 Agent Loop 和四类外挂能力。
最上方的大框是核心 Agent Loop。messages 进入循环后,先经过 LLM 前处理,包括 cron/background 注入、compact、memory 和 prompt 组装;然后进入 LLM;如果模型产生工具调用,就进入工具前门禁,也就是 PreToolUse hooks 和 permission pipeline;通过门禁之后,才会进入 handlers 执行工具;工具结果再沿着虚线回到 messages,进入下一轮循环。
左下角的绿色区域是 "上下文与知识",包括 s07 skill catalog、s09 memory selection、s10 prompt sections 和 s08 compact pipeline。这一组机制主要作用在 LLM 前,它们负责决定模型本轮应该看到什么上下文、哪些长期记忆、哪些技能目录,以及如何压缩旧内容。
中间偏左的橙色区域是 "治理与扩展点",包括 s03 permission、s04 hooks、s11 retry/fallback 和 Stop hooks。这一组机制主要保证执行安全和系统稳定。它们不会替代模型推理,也不会直接完成任务,而是围绕模型调用和工具执行提供边界、审计和恢复能力。
中间偏右的紫色区域是 "持久工作",包括 s05 todo_write、s12 task graph、s13 background 和 s14 cron scheduler。这一组机制解决的是 "任务如何跨轮次、跨时间推进" 的问题。Todo 让当前会话不漂移,Task Graph 让任务有持久状态,Background 让慢操作不阻塞主循环,Cron 让未来时间点也能主动触发 Agent。
右下角的绿色区域是 "团队与插件",包括 s06 subagent、s15-s17 team protocols、s18 worktree isolation 和 s19 MCP tools。这一组机制解决的是 "工作如何分出去、隔离开、接入外部能力" 的问题。Subagent 提供一次性上下文隔离,Teammate 提供长期并行协作,Worktree 提供代码执行隔离,MCP 提供外部工具接入。
最下面的 TOOL POOL 区域则说明,s20 最终把 27 个内置工具和动态 MCP 工具放在同一个工具池里。模型并不是分别进入不同子系统,而是在一个统一工具列表中选择工具。无论它选择 read_file、schedule_cron、spawn_teammate、create_worktree,还是 mcp__docs__search,对于 Agent Loop 来说,本质上都是同一种节奏:tool_use → handler → tool_result → messages。
所以 s20 的解决方案并不是"把所有功能混在一起",而是给每个机制找到一个明确的挂载点:
text
用户输入
→ UserPromptSubmit hooks
→ cron/background 通知注入
→ context compact
→ memory + skills + MCP 状态组装 system prompt
→ LLM
→ has tool_use block?
否 → Stop hooks → 返回
是 → PreToolUse hooks + permission
→ TOOL_HANDLERS / MCP handlers / background dispatch
→ PostToolUse hooks
→ tool_result / task_notification 回 messages
→ 下一轮这就是 s20 的核心设计:所有机制都围绕同一个循环展开,而不是把 Agent 拆成一堆互不相干的子系统。
4. Comprehensive Agent Turn 流程图分析
Web 教程提供的 Comprehensive Agent Turn 七张图,实际上是在用一个完整任务轮次说明:综合 Agent 在一次真实工作中,会如何把前面所有机制串起来。
这七张图不是在讲七个独立功能,而是在讲同一个 Agent Turn 的七个阶段:Intake、Guardrails、Route、Execute、External、Recover、Append。它们对应的是一个真实 Agent 在收到任务后,从接收输入到输出结果之间应该经历的完整链路。
1. Intake:把一次请求整理成可见的 Turn Packet
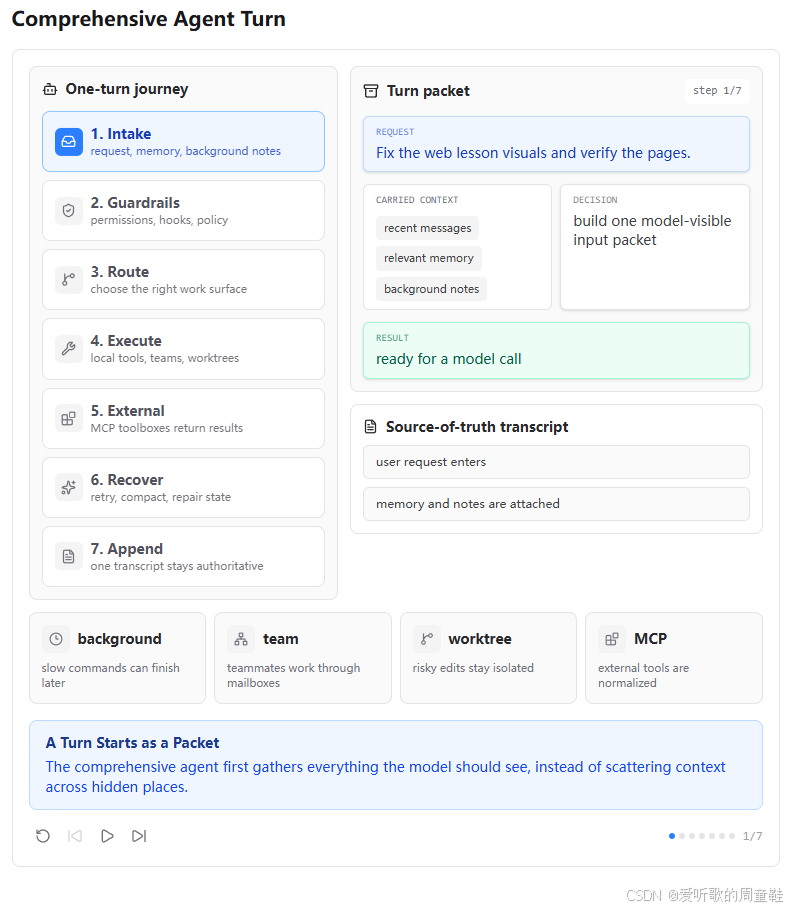
第一张图展示的是 Intake 阶段。用户请求是 "Fix the web lesson visuals and verify the pages.",也就是修复 Web 教程视觉效果并验证页面。
在一个简单 Agent 中,这个请求可能会直接丢给模型。但 s20 要表达的是,综合 Agent 不应该只把原始用户输入传给模型,而应该先构建一个 "Turn Packet"。这个 Turn Packet 里不仅有用户请求,还会携带 recent messages、relevant memory 和 background notes。
这和前面的 Memory、Background、Context Compact 有直接关系。用户当前这一句话并不是唯一上下文,Agent 还需要知道最近对话中发生了什么、是否有相关长期记忆、是否有后台任务已经完成、是否有之前的工具结果需要参考。
图中 "decision" 写的是 build one model-visible input packet,这句话非常关键。它说明 s20 的上下文设计不是把信息散落在各种隐藏状态里,而是尽量把模型需要看的内容整理成一个可见输入包。这样模型的决策才有依据,也方便调试。
这一阶段对应到代码里,就是进入 agent_loop() 后,在调用模型之前先处理各种注入源:
python
fired = consume_cron_queue()
for job in fired:
messages.append({"role": "user",
"content": f"[Scheduled] {job.prompt}"})
inject_background_notifications(messages)
prepare_context(messages)
context = update_context(context, messages)
tools, handlers = assemble_tool_pool()也就是说,用户请求只是 messages 的一部分,Cron、Background、Memory、MCP 状态都会在模型调用前被整理到当前回合的上下文中。
2. Guardrails:工具执行前先形成安全边界
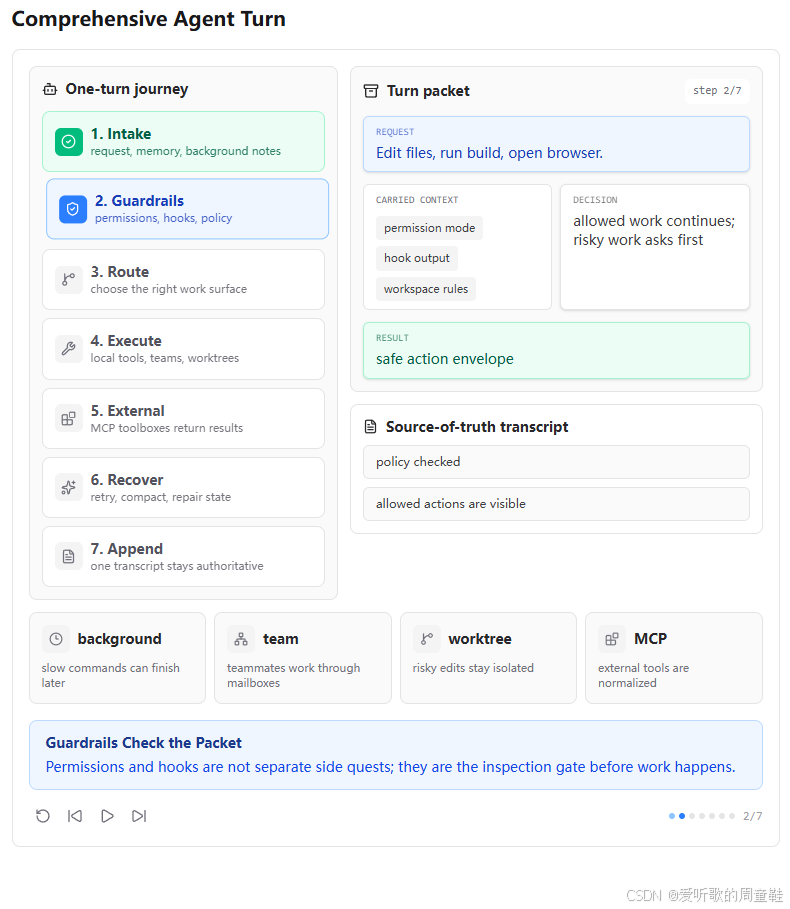
第二张图展示的是 Guardrails 阶段。用户请求变成了 "Edit files, run build, open browser.",这类任务显然会涉及文件修改、构建命令甚至外部检查,因此不能只依赖模型自觉安全。
图中 carried context 包括 permission mode、hook output 和 workspace rules,decision 是 allowed work continues; risky work asks first,result 是 safe action envelope。这说明综合 Agent 在执行任务之前,需要先建立一个安全执行信封:哪些动作允许直接做,哪些动作需要询问用户,哪些动作应该直接拒绝。
这对应 s03 Permission 和 s04 Hooks 的整合结果。到了 s20,权限检查不再是单独章节里的演示代码,而是作为 PreToolUse hook 挂在每次工具执行之前。
代码中可以看到:
python
blocked = trigger_hooks("PreToolUse", block)
if blocked:
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": str(blocked)})
continue只要模型请求工具,harness 就先触发 PreToolUse。而注册到这个 hook 点上的回调包括:
python
register_hook("PreToolUse", permission_hook)
register_hook("PreToolUse", log_hook)这意味着 permission 和 log 都不是工具内部逻辑,而是工具执行前的统一门禁。模型可以提出工具调用,但能不能执行,由 harness 决定。
所以这张图强调的是:综合 Agent 的安全性不是靠模型承诺,而是靠工具执行前的统一检查点。
3. Route:选择最小但足够的工作面
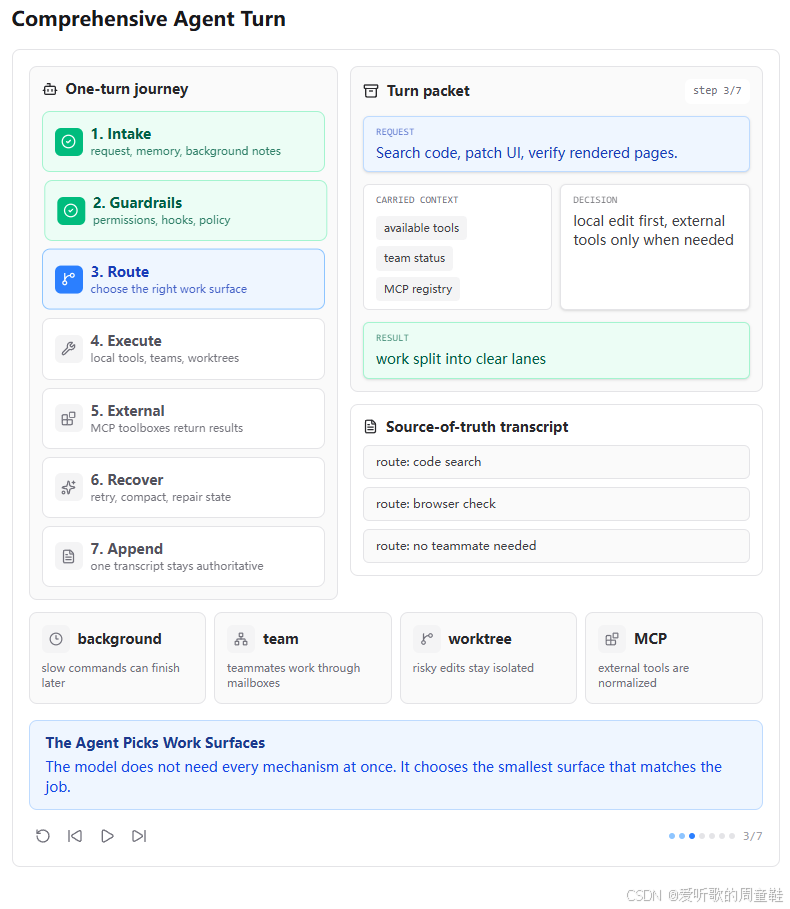
第三张图展示的是 Route 阶段。用户请求是 "Search code, patch UI, verify rendered pages."。这个任务可能涉及本地代码搜索、UI 修改、页面验证,甚至可能需要 MCP 或 worktree。
图中 carried context 包括 available tools、team status 和 MCP registry。decision 是 local edit first; external tools only when needed,result 是 work split into clear lanes。
这说明综合 Agent 不应该一上来就动用所有机制,而是要根据任务选择合适的工作面。能用本地工具解决的问题,就先用本地工具;如果需要外部文档或部署服务,再调用 MCP;如果需要并行修改或风险隔离,再创建 worktree;如果任务很大,再拆给 teammate。
这和 s20 的工具池设计对应。s20 的工具池很大,有 27 个内置工具加动态 MCP 工具,但大工具池不意味着每个任务都要用所有工具。模型看到的是统一工具池,具体使用哪个工具,取决于当前任务。
代码中的工具池定义非常完整:
python
BUILTIN_TOOLS = [
{"name": "bash", ...},
{"name": "read_file", ...},
{"name": "write_file", ...},
{"name": "edit_file", ...},
{"name": "glob", ...},
{"name": "todo_write", ...},
{"name": "task", ...},
{"name": "load_skill", ...},
{"name": "compact", ...},
{"name": "create_task", ...},
{"name": "list_tasks", ...},
{"name": "get_task", ...},
{"name": "claim_task", ...},
{"name": "complete_task", ...},
{"name": "schedule_cron", ...},
{"name": "list_crons", ...},
{"name": "cancel_cron", ...},
{"name": "spawn_teammate", ...},
{"name": "send_message", ...},
{"name": "check_inbox", ...},
{"name": "request_shutdown", ...},
{"name": "request_plan", ...},
{"name": "review_plan", ...},
{"name": "create_worktree", ...},
{"name": "remove_worktree", ...},
{"name": "keep_worktree", ...},
{"name": "connect_mcp", ...},
]然后通过 assemble_tool_pool() 把内置工具和 MCP 工具合并:
python
def assemble_tool_pool() -> tuple[list[dict], dict]:
tools = list(BUILTIN_TOOLS)
handlers = dict(BUILTIN_HANDLERS)
for server_name, mcp_client in mcp_clients.items():
...
prefixed = f"mcp__{safe_server}__{safe_tool}"
tools.append({...})
handlers[prefixed] = ...
return tools, handlers也就是说,Route 阶段的本质是:模型面对一个综合工具池,但应该选择最合适、最小、最直接的工具路径,而不是滥用复杂机制。
4. Execute:工具、队友和 worktree 都产生可回填的小结果
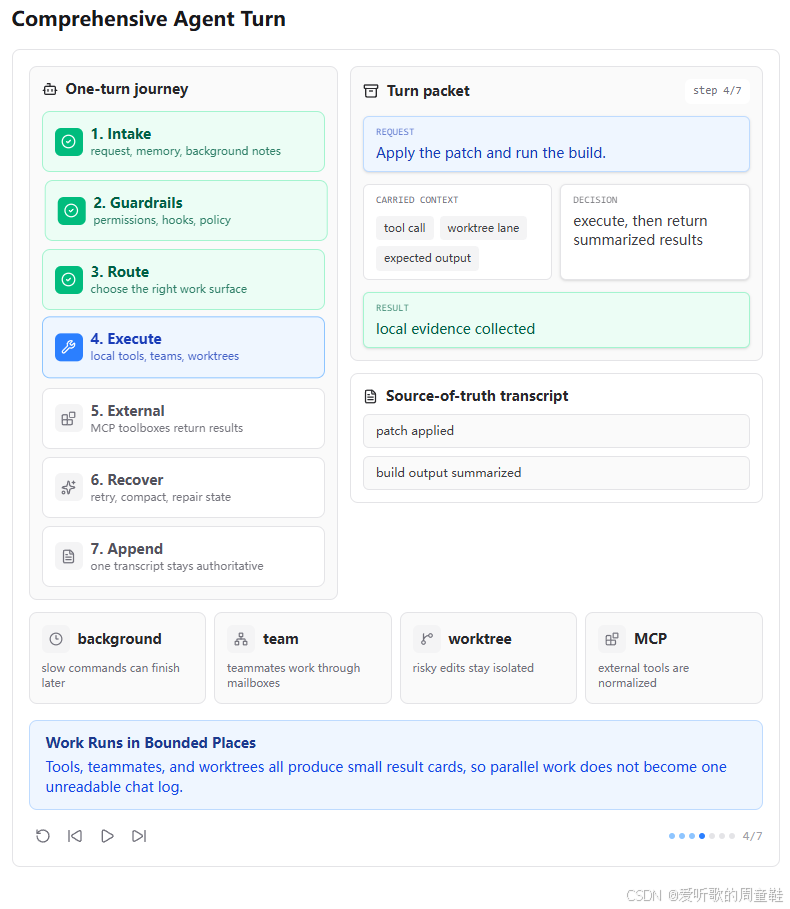
第四张图展示的是 Execute 阶段。用户请求是 "Apply the patch and run the build."。这类任务就进入了真正执行阶段。
图中 carried context 包括 tool call、worktree lane 和 expected output。decision 是 execute, then return summarized results,result 是 local evidence collected。这说明执行阶段的重点不是让工具无限输出,而是收集证据,并把执行结果以模型能继续理解的形式回到 messages。
这对应 s20 中工具执行和结果构造的逻辑。每个工具调用执行后,都会生成一个结构化的 tool_result:
python
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": output})如果是后台任务,则不是阻塞等待,而是先返回一个占位结果:
python
if should_run_background(block.name, block.input):
bg_id = start_background_task(block, handlers)
output = (f"[Background task {bg_id} started] "
"Result will arrive as a task_notification.")
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": output})
continue如果队友 claim 了带 worktree 的任务,则队友的工具会自动在 worktree 目录下执行:
python
def _wt_cwd():
p = wt_ctx["path"]
return Path(p) if p else None
def _run_bash(command: str) -> str:
return run_bash(command, cwd=_wt_cwd())
def _run_read(path: str) -> str:
return run_read(path, cwd=_wt_cwd())
def _run_write(path: str, content: str) -> str:
return run_write(path, content, cwd=_wt_cwd())这意味着 s20 的执行不是 "所有东西都在一个目录里乱跑",而是可以根据任务状态切换执行 lane。主 Agent、subagent、teammate、worktree、background task 都可以工作,但它们的结果最终都会被归一化为小块结果,回到 messages。
所以这张图强调的是:综合 Agent 的执行可以发生在不同地方,但结果必须回到同一个 transcript。
5. External:MCP 外部结果也回到同一条循环
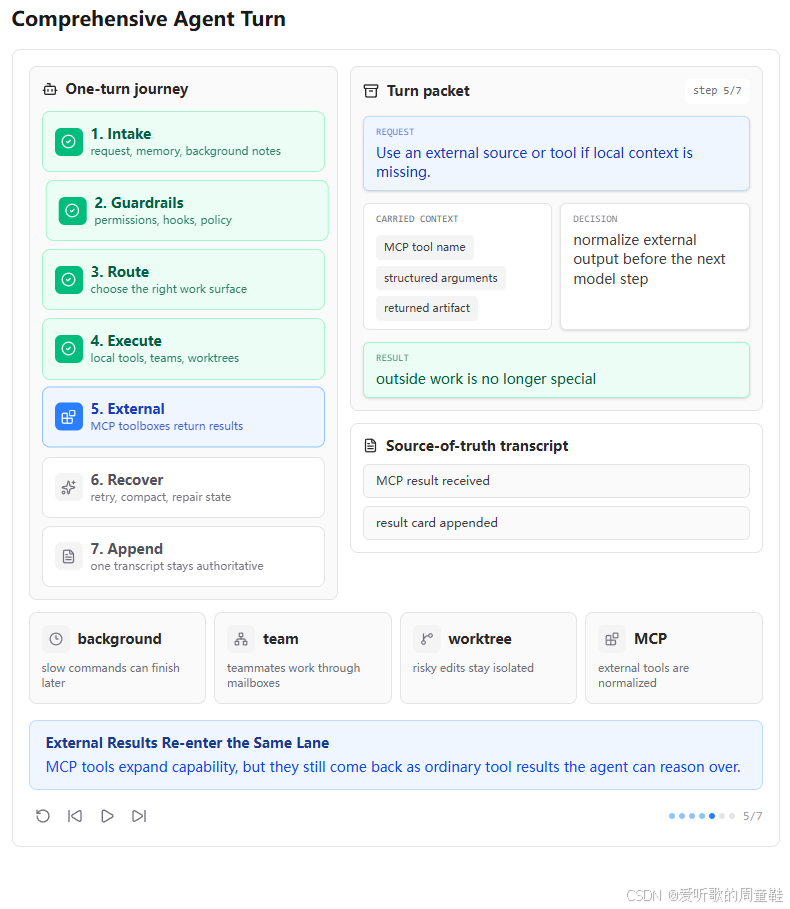
第五张图展示的是 External 阶段。用户请求是 "Use an external source or tool if local context is missing."。也就是说,当本地上下文不够时,Agent 可以调用外部工具。
图中 carried context 包括 MCP tool name、structured arguments 和 returned artifact。decision 是 normalize external output before the next model step,result 是 outside work is no longer special。
这正是 s19 MCP Plugin 在 s20 中的归位。MCP 工具虽然来自外部 server,但进入 Agent Loop 后,它和普通工具没有本质区别。模型看到的是 mcp__server__tool 形式的工具名,harness 通过 handler 转发给 MCPClient,返回结果后依旧包装成 tool_result。
相关代码仍然是:
python
class MCPClient:
def call_tool(self, tool_name: str, args: dict) -> str:
handler = self._handlers.get(tool_name)
if not handler:
return f"MCP error: unknown tool '{tool_name}'"
try:
return handler(**args)
except Exception as e:
return f"MCP error: {e}"工具池组装时,MCP 工具被加入普通工具列表:
python
prefixed = f"mcp__{safe_server}__{safe_tool}"
tools.append({
"name": prefixed,
"description": tool_def.get("description", ""),
"input_schema": tool_def.get("inputSchema", {}),
})
handlers[prefixed] = (
lambda *, c=mcp_client, t=tool_def["name"], **kw: c.call_tool(t, kw))所以 MCP 的外部性只存在于工具来源上,不存在于 Agent Loop 结构上。对于模型来说,MCP 结果也是下一轮 messages 中的一段工具结果;对于 harness 来说,MCP handler 也只是 handlers 字典里的一个函数。
这张图想强调的是:外部工具接入以后,不应该成为一条特殊旁路,而应该被标准化为普通工具调用结果。
6. Recover:错误恢复是显式状态,而不是神秘重试
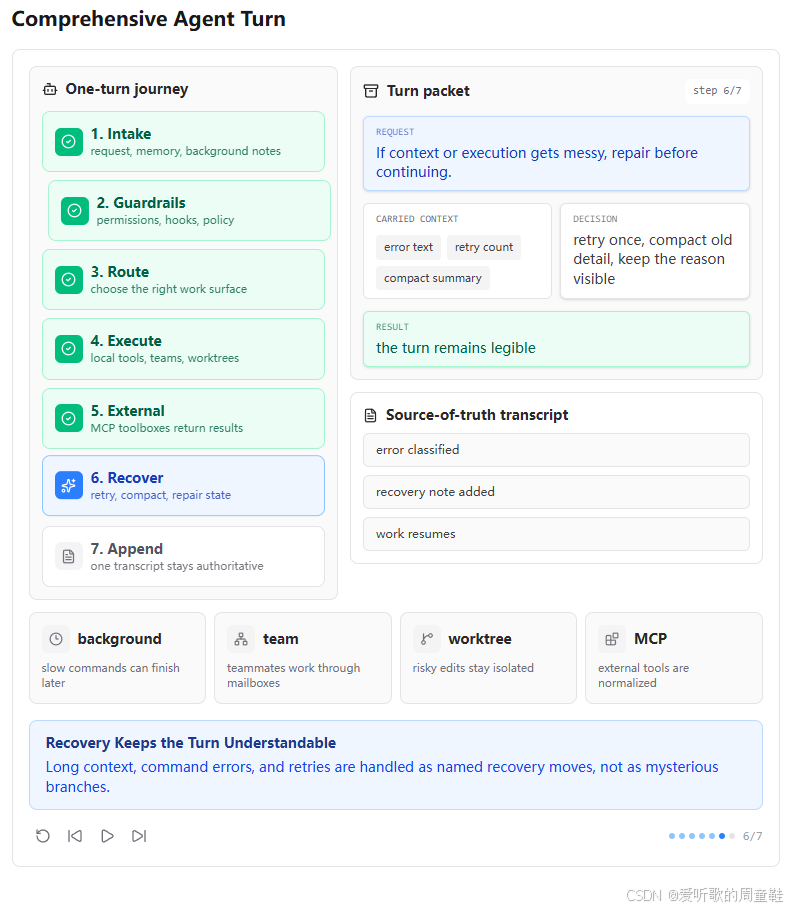
第六张图展示的是 Recover 阶段。用户请求是 "If context or execution gets messy, repair before continuing."。这对应 s11 Error Recovery 和 s08 Context Compact 的整合。
图中 carried context 包括 error text、retry count 和 compact summary。decision 是 retry once, compact old detail, keep the reason visible,result 是 the turn remains legible。
这说明 s20 不是遇到错误就无限重试,而是把错误恢复做成显式状态。429、529、max_tokens、prompt too long 都有不同恢复路径,每条路径都有上限,恢复后仍然回到正常循环。
代码里 RecoveryState 保存恢复状态:
python
class RecoveryState:
def __init__(self):
self.has_escalated = False
self.recovery_count = 0
self.consecutive_529 = 0
self.has_attempted_reactive_compact = False
self.current_model = PRIMARY_MODEL模型调用被 with_retry() 包起来:
python
def call_llm(messages: list, context: dict, tools: list,
state: RecoveryState, max_tokens: int):
system = assemble_system_prompt(context)
return with_retry(
lambda: client.messages.create(
model=state.current_model,
system=system,
messages=messages,
tools=tools,
max_tokens=max_tokens),
state)遇到 prompt too long 时,触发 reactive compact:
python
except Exception as e:
if is_prompt_too_long_error(e) and not state.has_attempted_reactive_compact:
messages[:] = reactive_compact(messages)
state.has_attempted_reactive_compact = True
continue遇到 max_tokens 时,先升级 token 预算,再尝试 continuation:
python
if response.stop_reason == "max_tokens":
if not state.has_escalated:
max_tokens = ESCALATED_MAX_TOKENS
state.has_escalated = True
print(f" \033[33m[max_tokens] retry with {max_tokens}\033[0m")
continue
messages.append({"role": "assistant", "content": response.content})
if state.recovery_count < MAX_RECOVERY_RETRIES:
messages.append({"role": "user", "content": CONTINUATION_PROMPT})
state.recovery_count += 1
continue
return这说明 s20 的恢复不是隐藏的魔法,而是明确写在循环里的控制流。恢复动作本身也会改变 messages 或 state,让后续模型调用能够继续进行。
所以这张图强调的是:综合 Agent 必须能从长上下文、输出截断、服务抖动和执行失败中恢复,而且恢复过程必须可理解、可限制、可继续。
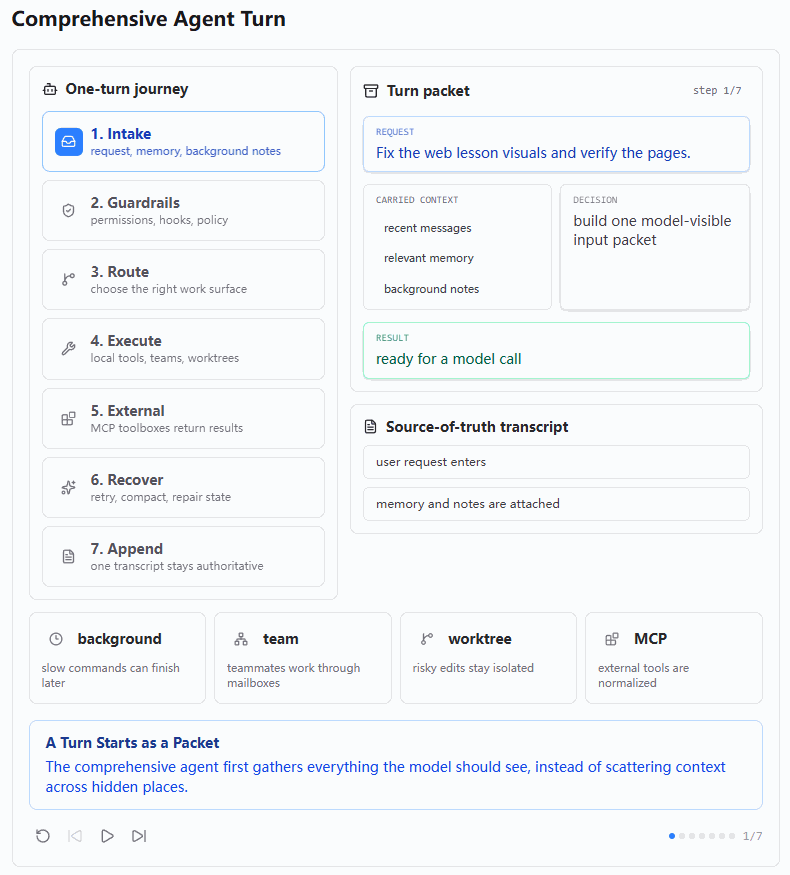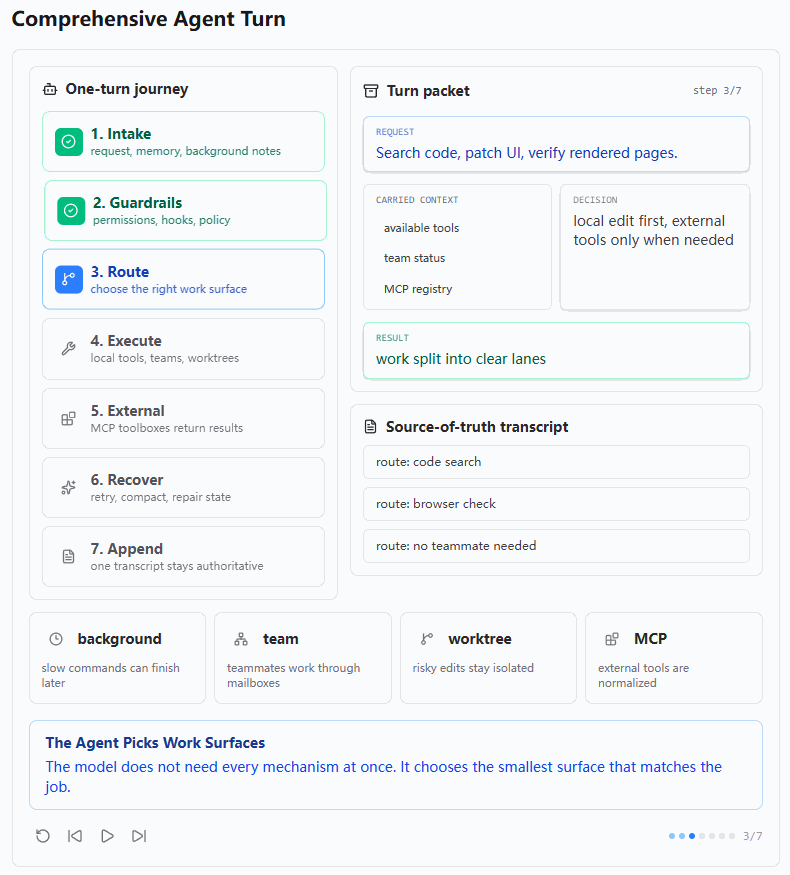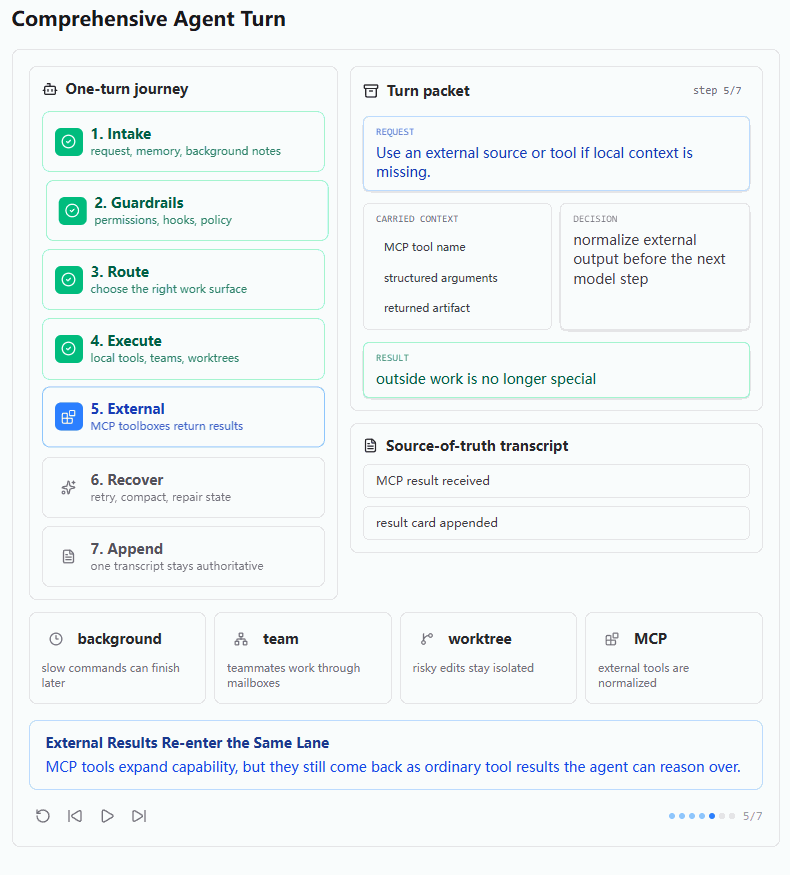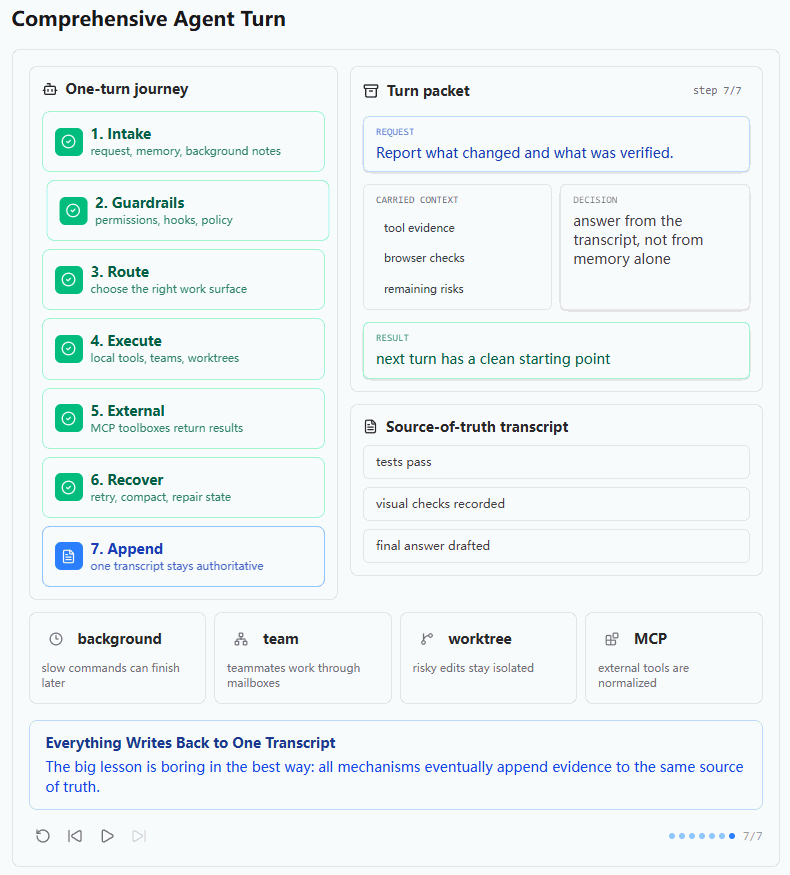
7. Append:所有证据回到同一个 Source-of-truth Transcript
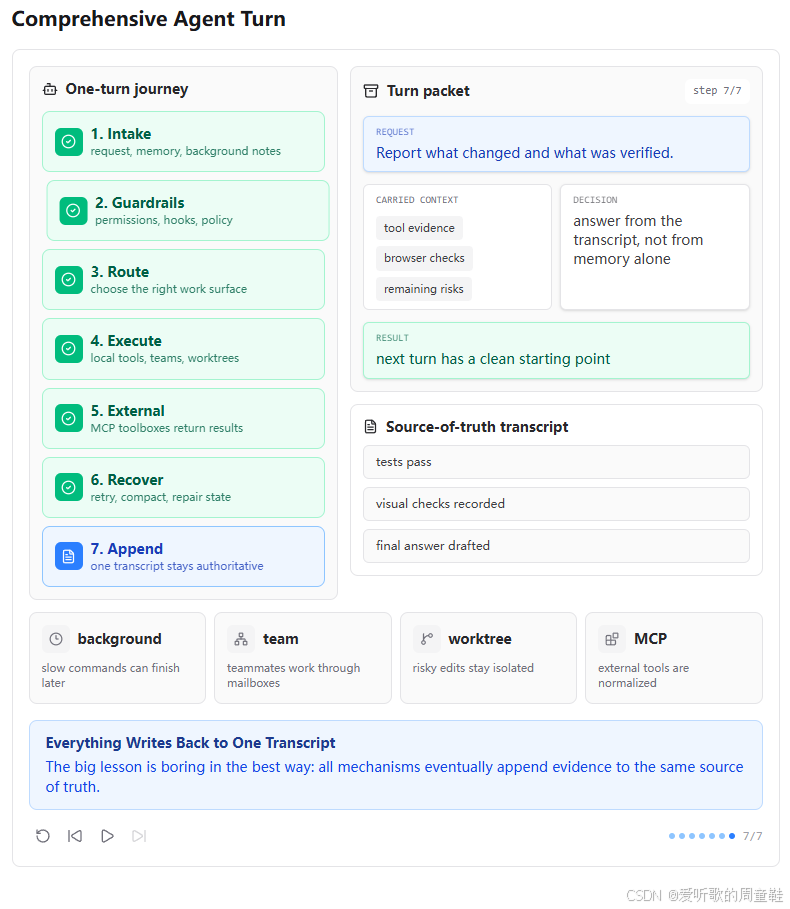
第七张图展示的是 Append 阶段。用户请求是 "Report what changed and what was verified."。这是一次任务结束时的输出阶段。
图中 carried context 包括 tool evidence、browser checks 和 remaining risks。decision 是 answer from the transcript, not from memory alone,result 是 next turn has a clean starting point。
这一点非常重要。综合 Agent 不是靠模型 "凭感觉" 回答,而是应该从 transcript 中已经回填的证据回答。工具结果、后台任务通知、MCP 结果、队友消息、测试结果、worktree 操作,都应该进入同一条 messages 轨道,成为最终回答的依据。
代码中工具结果通过下面这行回到 messages:
python
messages.append({"role": "user", "content": build_user_content(results)})其中 build_user_content() 不只加入当前工具结果,还会把后台任务完成通知也并入:
python
def build_user_content(results: list[dict]) -> list[dict]:
content = list(results)
for note in collect_background_results():
content.append({"type": "text", "text": note})
return content如果本轮没有工具调用,Stop hook 会运行:
python
if not has_tool_use(response.content):
trigger_hooks("Stop", messages)
returnCLI 最终打印本轮 assistant 输出:
python
def print_turn_assistants(messages: list, turn_start: int):
for msg in messages[turn_start:]:
if msg.get("role") != "assistant":
continue
for block in msg.get("content", []):
if getattr(block, "type", None) == "text":
terminal_print(block.text)这说明 s20 最终坚持一个原则:transcript 是事实来源。Memory 可以帮助跨会话保留偏好,Skill 可以提供能力说明,MCP 可以提供外部结果,Cron 可以注入未来任务,Background 可以异步返回结果,但最终模型回答时,应该尽量基于当前 messages 中已经出现的证据。
所以这张图是整个 s20 的收束:所有机制最终都不是为了制造更多隐藏状态,而是为了把有用信息整理进同一个可追踪的 Agent Turn。
完整动画演示如下图所示:
5. 工作原理(代码分析)
s20 的代码是整个教程中最完整的一份代码。它不是从零开始写一个新 Agent,而是把前面章节的关键机制全部合并到一个文件中。为了理解它,最好不要直接从 agent_loop() 开始,而是从上到下看每一组机制如何被定义,最后再看它们如何汇入主循环。
首先,代码开头定义了全局运行环境:
python
WORKDIR = Path.cwd()
client = Anthropic(base_url=os.getenv("ANTHROPIC_BASE_URL"))
MODEL = os.environ["MODEL_ID"]
PRIMARY_MODEL = MODEL
FALLBACK_MODEL = os.getenv("FALLBACK_MODEL_ID")
SKILLS_DIR = WORKDIR / "skills"
TRANSCRIPT_DIR = WORKDIR / ".transcripts"
TOOL_RESULTS_DIR = WORKDIR / ".task_outputs" / "tool-results"这里可以看到,s20 已经不只是一个简单脚本,而是一个带有多个持久化目录的 harness。WORKDIR 是整个工作空间根目录;SKILLS_DIR 存技能;TRANSCRIPT_DIR 存压缩前的对话记录;TOOL_RESULTS_DIR 存超大工具输出。也就是说,s20 从一开始就把长期运行、上下文压缩和工具输出持久化考虑进来了。
接着是 Task System。任务被定义为 dataclass,并持久化到 .tasks 目录:
python
TASKS_DIR = WORKDIR / ".tasks"
TASKS_DIR.mkdir(exist_ok=True)
@dataclass
class Task:
id: str
subject: str
description: str
status: str
owner: str | None
blockedBy: list[str]
worktree: str | None = None相比早期 task system,s20 的 Task 多了 worktree 字段。这说明任务不仅知道谁在做、状态是什么、依赖谁,还能知道自己绑定到哪个 worktree lane。这就是 s18 Worktree Isolation 被并入综合 Agent 后的体现。
任务创建、读取、保存仍然是文件驱动:
python
def create_task(subject: str, description: str = "",
blockedBy: list[str] | None = None) -> Task:
task = Task(
id=f"task_{int(time.time())}_{random.randint(0, 9999):04d}",
subject=subject, description=description,
status="pending", owner=None,
blockedBy=blockedBy or [],
)
save_task(task)
return task任务 claim 时会检查依赖:
python
def can_start(task_id: str) -> bool:
task = load_task(task_id)
for dep_id in task.blockedBy:
if not _task_path(dep_id).exists():
return False
if load_task(dep_id).status != "completed":
return False
return True这说明 s20 不是只保留了任务列表,而是保留了任务图的基本语义:pending → in_progress → completed,并且依赖任务完成前不能启动。
然后是 Worktree System。worktree 名称先经过严格校验:
python
VALID_WT_NAME = re.compile(r'^[A-Za-z0-9._-]{1,64}$')
def validate_worktree_name(name: str) -> str | None:
if not name:
return "Worktree name cannot be empty"
if name in (".", ".."):
return f"'{name}' is not a valid worktree name"
if not VALID_WT_NAME.match(name):
return (f"Invalid worktree name '{name}': "
"only letters, digits, dots, underscores, dashes (1-64 chars)")
return None这段代码体现了 s20 的一个重要特点:安全边界不只存在于 permission hook,也存在于具体子系统入口。worktree 名会变成文件路径和 git branch 名,如果不校验,就可能引入路径逃逸或非法 branch 名问题。
创建 worktree 时,会调用 git worktree,并可选地绑定 task:
python
def create_worktree(name: str, task_id: str = "") -> str:
err = validate_worktree_name(name)
if err:
return f"Error: {err}"
if task_id:
try:
load_task(task_id)
except FileNotFoundError:
return f"Error: task {task_id} not found"
path = WORKTREES_DIR / name
if path.exists():
return f"Worktree '{name}' already exists at {path}"
ok, result = run_git(["worktree", "add", str(path), "-b", f"wt/{name}", "HEAD"])
if not ok:
return f"Git error: {result}"
if task_id:
bind_task_to_worktree(task_id, name)
log_event("create", name, task_id)
return f"Worktree '{name}' created at {path}"这个函数把 s12 Task System 和 s18 Worktree Isolation 接到了一起。task 是控制平面,worktree 是执行平面;bind_task_to_worktree() 则是两者之间的桥。
python
def bind_task_to_worktree(task_id: str, worktree_name: str):
task = load_task(task_id)
task.worktree = worktree_name
save_task(task)接着是 Skill Loading。s20 会扫描 skills/ 目录,读取每个 skill 的 SKILL.md:
python
def scan_skills():
SKILL_REGISTRY.clear()
if not SKILLS_DIR.exists():
return
for directory in sorted(SKILLS_DIR.iterdir()):
if not directory.is_dir():
continue
manifest = directory / "SKILL.md"
if not manifest.exists():
continue
raw = manifest.read_text()
meta, _ = _parse_frontmatter(raw)
name = meta.get("name", directory.name)
desc = meta.get("description", raw.split("\n")[0].lstrip("#").strip())
SKILL_REGISTRY[name] = {
"name": name,
"description": desc,
"content": raw,
}这里延续了 s07 的思路:system prompt 里不直接塞完整技能内容,而是只放 catalog。当模型判断某个技能相关时,再调用 load_skill(name) 加载完整内容。
python
def list_skills() -> str:
if not SKILL_REGISTRY:
return "(no skills found)"
return "\n".join(
f"- {skill['name']}: {skill['description']}"
for skill in SKILL_REGISTRY.values())
def load_skill(name: str) -> str:
skill = SKILL_REGISTRY.get(name)
if not skill:
available = ", ".join(SKILL_REGISTRY.keys()) or "(none)"
return f"Skill not found: {name}. Available: {available}"
return skill["content"]然后是 System Prompt Assembly。s20 的 PROMPT_SECTIONS 比 s10 更完整,工具说明中列出了所有综合工具:
python
PROMPT_SECTIONS = {
"identity": "You are a coding agent. Act, don't explain.",
"tools": "Available tools: bash, read_file, write_file, edit_file, glob, "
"todo_write, task, load_skill, compact, "
"create_task, list_tasks, get_task, claim_task, complete_task, "
"schedule_cron, list_crons, cancel_cron, "
"spawn_teammate, send_message, check_inbox, "
"request_shutdown, request_plan, review_plan, "
"create_worktree, remove_worktree, keep_worktree, "
"connect_mcp. MCP tools are prefixed mcp__{server}__{tool}.",
"workspace": f"Working directory: {WORKDIR}",
"memory": "Relevant memories are injected below when available.",
}系统提示词每轮从 context 重新组装:
python
def assemble_system_prompt(context: dict) -> str:
sections = [PROMPT_SECTIONS["identity"],
PROMPT_SECTIONS["tools"],
PROMPT_SECTIONS["workspace"]]
sections.append(f"Current time: {datetime.now().isoformat(timespec='seconds')}")
sections.append("Skills catalog:\n" + list_skills() +
"\nUse load_skill(name) when a skill is relevant.")
if context.get("memories"):
sections.append(f"Relevant memories:\n{context['memories']}")
mcp_names = list(mcp_clients.keys())
if mcp_names:
sections.append(f"Connected MCP servers: {', '.join(mcp_names)}")
return "\n\n".join(sections)这段代码把 s09 Memory、s10 System Prompt、s07 Skill 和 s19 MCP 状态全部合并了。模型每轮看到的 system prompt 不是一个固定字符串,而是由当前时间、技能目录、记忆内容和已连接 MCP server 共同组装出来的。
接着是基本工具。文件工具通过 safe_path() 限制在 workspace 或 worktree 内:
python
def safe_path(p: str, cwd: Path = None) -> Path:
base = cwd or WORKDIR
path = (base / p).resolve()
if not path.is_relative_to(base):
raise ValueError(f"Path escapes workspace: {p}")
return pathrun_read()、run_write()、run_edit()、run_glob() 都基于这个路径安全函数:
python
def run_write(path: str, content: str, cwd: Path = None) -> str:
try:
fp = safe_path(path, cwd)
fp.parent.mkdir(parents=True, exist_ok=True)
fp.write_text(content)
return f"Wrote {len(content)} bytes to {path}"
except Exception as e:
return f"Error: {e}"这里需要注意,cwd 参数是 worktree 隔离的关键。主 Agent 默认在 WORKDIR 下执行,而 teammate 如果 claim 到绑定 worktree 的 task,就会把 cwd 切换到对应 worktree。
MessageBus 和 Protocol State 则保留了团队协作能力。消息通过 .mailboxes 目录下的 JSONL 文件传递:
python
class MessageBus:
def send(self, from_agent: str, to_agent: str, content: str,
msg_type: str = "message", metadata: dict = None):
msg = {"from": from_agent, "to": to_agent,
"content": content, "type": msg_type,
"ts": time.time(), "metadata": metadata or {}}
inbox = MAILBOX_DIR / f"{to_agent}.jsonl"
with open(inbox, "a") as f:
f.write(json.dumps(msg) + "\n")协议状态通过 request_id 匹配:
python
@dataclass
class ProtocolState:
request_id: str
type: str
sender: str
target: str
status: str
payload: str
created_at: float = field(default_factory=time.time)这让 shutdown、plan approval 等流程不会因为消息顺序混乱而误匹配。match_response() 会检查 request type 和 response type 是否对应:
python
def match_response(response_type: str, request_id: str, approve: bool):
state = pending_requests.get(request_id)
if not state:
return
if state.type == "shutdown" and response_type != "shutdown_response":
return
if state.type == "plan_approval" and response_type != "plan_approval_response":
return
state.status = "approved" if approve else "rejected"然后是 Teammate Thread。s20 的 teammate 不再只是简单子线程,而是带有 plan approval gate、inbox polling、task auto-claim 和 worktree context 的长期代理。
队友启动后,会维护自己的 wt_ctx:
python
wt_ctx = {"path": None}
def _wt_cwd():
p = wt_ctx["path"]
return Path(p) if p else None当队友 claim 到 task 后,如果 task 绑定了 worktree,就把工作目录切过去:
python
def _run_claim_task(task_id: str):
result = claim_task(task_id, owner=name)
if "Claimed" in result:
task = load_task(task_id)
wt_ctx["path"] = (str(WORKTREES_DIR / task.worktree)
if task.worktree else None)
return result队友提交 plan 后,不允许继续执行后续工具,而是等待 lead 审批:
python
if block.name == "submit_plan":
output = _teammate_submit_plan(
name, block.input.get("plan", ""))
match = re.search(r"\((req_\d+)\)", output)
protocol_ctx["waiting_plan"] = (
match.group(1) if match else output)
...
if protocol_ctx["waiting_plan"]:
break这说明 s20 的团队协作已经带有治理能力。队友不是随便 autonomously 修改代码,而是在协议要求下先提交计划,等待 lead 审批后再继续。
接着是 Hooks 和 Permission Pipeline。s20 的 hook 注册表如下:
python
HOOKS = {"UserPromptSubmit": [], "PreToolUse": [],
"PostToolUse": [], "Stop": []}
def register_hook(event: str, callback):
HOOKS[event].append(callback)
def trigger_hooks(event: str, *args):
for callback in HOOKS[event]:
result = callback(*args)
if result is not None:
return result
return Nonepermission 被实现为 PreToolUse hook:
python
def permission_hook(block):
if block.name == "bash":
command = block.input.get("command", "")
for pattern in DENY_LIST:
if pattern in command:
return f"Permission denied: '{pattern}' is on the deny list"
if any(token in command for token in DESTRUCTIVE):
print(f"\n\033[33m[permission] destructive command\033[0m")
print(f" {command}")
choice = input(" Allow? [y/N] ").strip().lower()
if choice not in ("y", "yes"):
return "Permission denied by user"
if block.name in ("write_file", "edit_file"):
path = block.input.get("path", "")
try:
safe_path(path)
except Exception:
return f"Permission denied: path escapes workspace: {path}"
if block.name.startswith("mcp__") and "deploy" in block.name:
print(f"\n\033[33m[permission] MCP destructive-looking tool: {block.name}\033[0m")
choice = input(" Allow? [y/N] ").strip().lower()
if choice not in ("y", "yes"):
return "Permission denied by user"
return None这段代码把 s03 Permission 和 s19 MCP 结合起来了。它不仅检查本地 bash 命令和文件写入,也会检查带有 destructive 风险的 MCP 工具。也就是说,外部工具接入后仍然必须经过同一个权限门禁。
Hooks 注册如下:
python
register_hook("UserPromptSubmit", user_prompt_hook)
register_hook("PreToolUse", permission_hook)
register_hook("PreToolUse", log_hook)
register_hook("PostToolUse", large_output_hook)
register_hook("Stop", stop_hook)这说明 s20 保留了 s04 的扩展点思想:主循环不需要知道每个扩展逻辑的细节,只需要在合适位置触发 hook。
Subagent 仍然是一次性上下文隔离工具:
python
def spawn_subagent(description: str) -> str:
messages = [{"role": "user", "content": description}]
for _ in range(30):
response = client.messages.create(
model=MODEL, system=SUB_SYSTEM, messages=messages,
tools=SUB_TOOLS, max_tokens=8000)
...它和 teammate 的区别在于,subagent 的中间过程不会长期保留,只返回最终摘要;teammate 则是长期线程,可以通过 MessageBus 与 lead 通信。
然后是 Context Compaction。s20 的压缩管线非常完整,包含大输出落盘、消息裁剪、旧工具结果压缩和模型摘要:
python
def prepare_context(messages: list) -> list:
messages[:] = tool_result_budget(messages)
messages[:] = snip_compact(messages)
messages[:] = micro_compact(messages)
if estimate_size(messages) > CONTEXT_LIMIT:
messages[:] = compact_history(messages)
return messages这段代码说明,压缩发生在每次模型调用之前。也就是说,不管 messages 是来自用户输入、工具结果、Cron 注入还是后台任务通知,最终都会先经过统一上下文预算管线。
Error Recovery 则负责模型调用失败时的恢复:
python
def with_retry(fn, state: RecoveryState):
for attempt in range(MAX_RETRIES):
try:
result = fn()
state.consecutive_529 = 0
return result
except Exception as e:
name = type(e).__name__.lower()
msg = str(e).lower()
if "ratelimit" in name or "429" in msg:
delay = retry_delay(attempt)
time.sleep(delay)
continue
if "overloaded" in name or "529" in msg or "overloaded" in msg:
state.consecutive_529 += 1
if state.consecutive_529 >= MAX_CONSECUTIVE_529 and FALLBACK_MODEL:
state.current_model = FALLBACK_MODEL
state.consecutive_529 = 0
delay = retry_delay(attempt)
time.sleep(delay)
continue
raise
raise RuntimeError(f"Max retries ({MAX_RETRIES}) exceeded")这延续了 s11 的三类恢复:429 退避,529 退避并可能切 fallback,prompt too long 触发 reactive compact,max_tokens 提升预算或 continuation。
Background Tasks 则通过线程执行慢工具:
python
def should_run_background(tool_name: str, tool_input: dict) -> bool:
if tool_name != "bash":
return False
return bool(tool_input.get("run_in_background")) or is_slow_operation(tool_name, tool_input)慢命令进入后台:
python
def start_background_task(block, handlers: dict) -> str:
global _bg_counter
_bg_counter += 1
bg_id = f"bg_{_bg_counter:04d}"
def worker():
handler = handlers.get(block.name)
result = call_tool_handler(handler, block.input, block.name)
trigger_hooks("PostToolUse", block, result)
with background_lock:
background_tasks[bg_id]["status"] = "completed"
background_results[bg_id] = str(result)
threading.Thread(target=worker, daemon=True).start()
return bg_id后台完成后,通过 collect_background_results() 生成 <task_notification>:
python
notifications.append(
f"<task_notification>\n"
f" <task_id>{bg_id}</task_id>\n"
f" <status>completed</status>\n"
f" <command>{task['command']}</command>\n"
f" <summary>{summary}</summary>\n"
f"</task_notification>")这说明后台任务不是旁路打印,而是最终仍然回到 messages,让模型能在下一轮继续处理。
Cron Scheduler 也被整合进来。定时任务保存为 CronJob:
python
@dataclass
class CronJob:
id: str
cron: str
prompt: str
recurring: bool
durable: bool调度线程每秒检查一次:
python
def cron_scheduler_loop():
while True:
time.sleep(1)
now = datetime.now()
marker = now.strftime("%Y-%m-%d %H:%M")
with cron_lock:
for job in list(scheduled_jobs.values()):
if cron_matches(job.cron, now) and _last_fired.get(job.id) != marker:
cron_queue.append(job)
_last_fired[job.id] = marker到点任务不会直接调用模型,而是先进入 cron_queue。主循环开始时会消费它:
python
fired = consume_cron_queue()
for job in fired:
messages.append({"role": "user",
"content": f"[Scheduled] {job.prompt}"})
print(f" \033[35m[cron inject] {job.prompt[:60]}\033[0m")CLI 还启动了一个自动消费线程:
python
def cron_autorun_loop(history: list, context: dict):
while True:
time.sleep(1)
fired = consume_cron_queue()
if not fired:
continue
with agent_lock:
turn_start = len(history)
for job in fired:
history.append({"role": "user",
"content": f"[Scheduled] {job.prompt}"})
agent_loop(history, context)
context.update(update_context(context, history))
print_turn_assistants(history, turn_start)这说明 s20 中 Cron 已经不只是一个工具,而是一个能够在用户不输入时主动触发 Agent Loop 的机制。
MCP System 仍然延续 s19。MCPClient 负责保存外部工具定义和 handler:
python
class MCPClient:
def __init__(self, name: str):
self.name = name
self.tools: list[dict] = []
self._handlers: dict[str, callable] = {}
def register(self, tool_defs: list[dict],
handlers: dict[str, callable]):
self.tools = tool_defs
self._handlers = handlers
def call_tool(self, tool_name: str, args: dict) -> str:
handler = self._handlers.get(tool_name)
if not handler:
return f"MCP error: unknown tool '{tool_name}'"
try:
return handler(**args)
except Exception as e:
return f"MCP error: {e}"connect_mcp() 连接 mock server:
python
def connect_mcp(name: str) -> str:
if name in mcp_clients:
return f"MCP server '{name}' already connected"
factory = MOCK_SERVERS.get(name)
if not factory:
available = ", ".join(MOCK_SERVERS.keys())
return f"Unknown server '{name}'. Available: {available}"
mcp_client = factory()
mcp_clients[name] = mcp_client
tool_names = [t["name"] for t in mcp_client.tools]
return (f"Connected to MCP server '{name}'. "
f"Discovered {len(mcp_client.tools)} tools: {', '.join(tool_names)}")动态工具池组装如下:
python
def assemble_tool_pool() -> tuple[list[dict], dict]:
tools = list(BUILTIN_TOOLS)
handlers = dict(BUILTIN_HANDLERS)
for server_name, mcp_client in mcp_clients.items():
safe_server = normalize_mcp_name(server_name)
for tool_def in mcp_client.tools:
safe_tool = normalize_mcp_name(tool_def["name"])
prefixed = f"mcp__{safe_server}__{safe_tool}"
tools.append({
"name": prefixed,
"description": tool_def.get("description", ""),
"input_schema": tool_def.get("inputSchema", {}),
})
handlers[prefixed] = (
lambda *, c=mcp_client, t=tool_def["name"], **kw: c.call_tool(t, kw))
return tools, handlers这就是 s19 的核心能力在 s20 中的保留:MCP 工具进入统一工具池,模型像调用普通工具一样调用它。
最后,我们来看最核心的 agent_loop():
python
def agent_loop(messages: list, context: dict):
global rounds_since_todo
tools, handlers = assemble_tool_pool()
state = RecoveryState()
max_tokens = DEFAULT_MAX_TOKENS
while True:
fired = consume_cron_queue()
for job in fired:
messages.append({"role": "user",
"content": f"[Scheduled] {job.prompt}"})
print(f" \033[35m[cron inject] {job.prompt[:60]}\033[0m")
inject_background_notifications(messages)
if rounds_since_todo >= 3:
messages.append({"role": "user",
"content": "<reminder>Update your todos.</reminder>"})
rounds_since_todo = 0
prepare_context(messages)
context = update_context(context, messages)
tools, handlers = assemble_tool_pool()这段是 LLM 前处理。它完成了四件事:消费 Cron Queue、注入后台任务通知、必要时提醒更新 Todo、压缩上下文并更新 context、重新组装工具池。
接着调用模型:
python
try:
response = call_llm(messages, context, tools, state, max_tokens)
except Exception as e:
if is_prompt_too_long_error(e) and not state.has_attempted_reactive_compact:
messages[:] = reactive_compact(messages)
state.has_attempted_reactive_compact = True
continue
messages.append({"role": "assistant", "content": [
{"type": "text", "text": f"[Error] {type(e).__name__}: {e}"}]})
return这里体现了 Error Recovery。模型调用失败并不会立刻崩溃,而是尝试根据错误类型恢复。
然后处理 max_tokens:
python
if response.stop_reason == "max_tokens":
if not state.has_escalated:
max_tokens = ESCALATED_MAX_TOKENS
state.has_escalated = True
print(f" \033[33m[max_tokens] retry with {max_tokens}\033[0m")
continue
messages.append({"role": "assistant", "content": response.content})
if state.recovery_count < MAX_RECOVERY_RETRIES:
messages.append({"role": "user", "content": CONTINUATION_PROMPT})
state.recovery_count += 1
continue
return如果模型没有请求工具,则触发 Stop hook:
python
messages.append({"role": "assistant", "content": response.content})
if not has_tool_use(response.content):
trigger_hooks("Stop", messages)
return如果有工具调用,就进入工具执行阶段:
python
results = []
compacted_now = False
for block in response.content:
if block.type != "tool_use":
continue
print(f"\033[36m> {block.name}\033[0m")如果模型请求 compact,则立即压缩历史并继续:
python
if block.name == "compact":
messages[:] = compact_history(messages)
messages.append({"role": "user",
"content": "[Compacted. Continue with summarized context.]"})
compacted_now = True
break否则先过 PreToolUse hooks:
python
blocked = trigger_hooks("PreToolUse", block)
if blocked:
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": str(blocked)})
continue如果是慢操作,进入后台:
python
if should_run_background(block.name, block.input):
bg_id = start_background_task(block, handlers)
output = (f"[Background task {bg_id} started] "
"Result will arrive as a task_notification.")
results.append({"type": "tool_result",
"tool_use_id": block.id,
"content": output})
continue否则正常执行 handler,并触发 PostToolUse:
python
handler = handlers.get(block.name)
output = call_tool_handler(handler, block.input, block.name)
trigger_hooks("PostToolUse", block, output)
print(str(output)[:300])最后,把所有工具结果回填 messages:
python
messages.append({"role": "user", "content": build_user_content(results)})这段 agent_loop() 是 s20 的核心。它把前面所有机制都放进了一个清晰的顺序中:
text
Cron / Background 注入
→ Todo reminder
→ Context Compact
→ update_context
→ assemble_tool_pool
→ call_llm with recovery
→ max_tokens recovery
→ Stop hooks
→ compact tool
→ PreToolUse hooks + permission
→ background dispatch
→ handler / MCP handler
→ PostToolUse hooks
→ tool_result 回 messages所以 s20 的代码并不是简单地把前面章节复制粘贴到一起,而是把每个机制都安排到了 Agent Loop 的一个明确位置。这样做的好处是:机制虽然很多,但执行路径仍然清楚。
OK,以上就是 s20 Comprehensive Agent 工作原理的完整分析了。
那大家感兴趣的话可以试试下面这些 prompt 感受下完整 Agent 的各个功能,这里博主就不一一调试展示了:
1. Create a todo list for inspecting this repo, then list Python files
2. Connect to the docs MCP server and search for agent loop
3. Create two tasks, create worktrees for them, then spawn alice and bob. Ask them to submit plans before claiming tasks.
4. remind me of the meeting in 3 minutes.
5. Run npm install in the background and continue reading README.md
观察重点:
- 工具调用前是否经过 hooks/permission
connect_mcp后下一轮是否出现 MCP 工具- 慢操作是否返回 background placeholder
- 到点是不是自动提醒开会
- 队友是否提交 plan,并在 approval 前暂停
- plan 批准后,队友是否能认领任务
- worktree 绑定后,队友是否切到对应目录
6. 相对于 s19 的变更
| 组件 | s19 | s20 |
|---|---|---|
| 工具池 | 内置 + MCP | 内置 + MCP,补齐 s01-s18 的工具 |
| 权限 | 教学主体省略 | PreToolUse hook 中执行 |
| hooks | 省略 | UserPromptSubmit / PreToolUse / PostToolUse / Stop |
| todo | 省略 | todo_write + reminder |
| skill | 省略 | catalog in system prompt + load_skill |
| compact | 省略 | LLM 前压缩 + compact 工具 + reactive compact |
| error recovery | 简化 try/except | retry / max_tokens / prompt too long |
| background | 省略 | 慢操作后台线程 + task notification |
| cron | 省略 | daemon scheduler + durable jobs |
| multi-agent | 保留 | 保留;队友使用隔离目录下的基础工具 |
| worktree | 保留 | 保留 |
| MCP | 新增 | 保留,作为最终工具池的一部分 |
7. 小结
本节我们学习了 s20: Comprehensive Agent,它是整个 learn-claude-code 系列的最终整合章节。
在这一章中,项目不再单独引入某一个新机制,而是把前面所有机制重新放回同一个 Agent Loop 中。这个 loop 仍然保持最基础的结构:模型读取 messages 和 system prompt,生成响应;如果有 tool_use,harness 执行工具;工具结果以 tool_result 的形式回到 messages;下一轮模型继续推理。
但是在这个简单循环周围,s20 挂载了完整的 harness 能力。LLM 调用前会注入 cron 和 background 任务通知,执行 context compact,加载 memory、skills 和 MCP 状态,并组装 system prompt;工具执行前会经过 PreToolUse hooks 和 permission pipeline;工具执行时可以分发到本地 handler、background thread、worktree lane 或 MCP server;工具执行后会触发 PostToolUse hooks;模型停止时会触发 Stop hook;模型调用失败时会进入 error recovery。
从代码上看,s20 的重点不在于某一个函数,而在于这些函数之间的位置关系。Task 和 Worktree 提供任务控制平面和执行隔离;SKILL_REGISTRY 和 load_skill 提供按需知识加载;assemble_system_prompt 把 workspace、time、skills、memory 和 MCP 状态变成模型可见上下文;HOOKS 和 permission_hook 提供统一执行门禁;prepare_context 控制上下文预算;with_retry 和 RecoveryState 处理模型调用失败;start_background_task 和 cron_scheduler_loop 让任务可以异步或定时进入循环;MCPClient 和 assemble_tool_pool 则让外部工具也进入同一个工具池。
从流程图上看,s20 的综合 Agent Turn 可以分成 Intake、Guardrails、Route、Execute、External、Recover、Append 七个阶段。它们分别对应输入整理、安全边界、工作面选择、工具执行、外部工具接入、错误恢复和结果回填。每个阶段都不是独立系统,而是同一个 Agent Turn 中的不同位置。
所以 s20 最大的价值在于:它让我们真正看清楚,一个完整 Agent Harness 并不是 "模型加很多工具" 这么简单,而是一套围绕模型循环构建的工程系统。工具只是其中一部分,真正重要的是如何管理上下文、权限、任务、团队、记忆、外部能力和错误恢复,并让所有结果回到同一个可追踪 transcript。
至此,learn-claude-code 的 20 个章节形成了一条完整主线:从最基础的 Agent Loop 出发,逐步加入工具、安全、扩展点、计划、子任务、技能、压缩、记忆、提示词、恢复、任务系统、后台任务、定时调度、团队协作、协议治理、自治执行、worktree 隔离和 MCP 外部工具,最后在 s20 中全部汇聚到一个 Comprehensive Agent 中。
这也说明了整个系列最重要的工程思想:
Agent 的智能来自模型,但 Agent 的可用性来自 Harness。
模型负责推理和决策,Harness 负责上下文、工具、安全、记忆、调度、协作、恢复和外部系统接入。
真正可工作的 Agent,不是把机制越堆越多,而是让所有机制都回到同一个清晰、稳定、可追踪的循环里。
OK,以上就是本期想要分享的全部内容了。
结语
本篇文章我们围绕 s20 Comprehensive Agent 这一节,完成了整个 learn-claude-code 系列的最终整合。
如果说前面每一章都是逐步构建 Agent 的局部能力:Loop 建立基础循环,Tool 提供执行接口,Permission 与 Hooks 管理边界和扩展点,Todo、Task、Subagent、Skill、Compact、Memory、System Prompt、Error Recovery、Background、Cron、Teams、Protocols、Autonomy、Worktree 和 MCP 分别解决规划、记忆、协作、隔离和外部工具接入等问题,那么 s20 的核心价值就在于:把这些能力汇聚到一个清晰、可追踪、可扩展的 Agent Loop 中。
在 s20 中,Agent 不再是零散的机制组合,而是一个完整的工程系统。无论是 Cron 定时任务、Background 异步任务、Memory 长期记忆、Skill 按需加载、MCP 外部工具、Worktree 隔离执行,还是 Teammate 协作和 Protocol 审批,所有机制都按照明确顺序挂载在主循环的不同阶段(Intake、Guardrails、Route、Execute、External、Recover、Append),最终回填同一条 messages 轨迹,形成事实来源。
从工程角度看,这一节实现了几个关键目标:
- 机制整合:所有前置、执行中、后置、异常恢复机制都在同一个循环内有序运行。
- 可追踪性:工具结果、任务状态、后台任务通知、MCP 调用输出、队友计划审批,都最终统一回到 messages,实现全程可审计。
- 可扩展性:新增工具或后台事件,只需挂载到对应阶段即可,无需破坏主循环。
- 长期可用性:Memory、Context Compact、Error Recovery、Worktree Isolation 等机制保证系统可长期稳定运行。
更高层次地看,s20 展示了一个核心思想:模型负责推理和决策,Harness 负责执行、上下文、工具、安全、记忆、调度、协作、恢复和外部系统接入。模型的智能是上限,但系统的可用性、可维护性和可扩展性来自于 Harness 的精心设计。
至此,整个 learn-claude-code 系列形成了一条完整的工程主线:从最基础的 Agent Loop 出发,逐步增加能力、管理边界、扩展协作、引入长期记忆和外部工具,最终在 s20 中汇聚成一个综合 Agent。
总结一句话:真正可工作的 Agent,不是把机制越堆越多,而是让所有机制都回到同一个清晰、稳定、可追踪的循环中,并围绕这个循环提供执行、协作、恢复和扩展能力。
至此,我们已经完成了从旧版教程到新版教程的所有补充章节。如果大家对 Agent 的内部机制感兴趣,不妨看看 learn-claude-code 这个项目,它对理解 Agent 的运行逻辑非常有帮助,值得推荐🤗。
OK,完结撒花🎉