日志配置、调试工具栏与 ORM 性能优化
在 Django 项目开发与运维过程中,日志是排查问题、分析系统运行状态的核心工具,而调试工具栏能直观暴露代码性能瓶颈,结合 ORM 优化手段可大幅提升项目运行效率。本文将从日志配置、调试工具部署、ORM 代码优化三个维度,详解 Django 项目的调试与性能优化方案。
一、Django 日志精细化配置
日志是项目的 "黑匣子":开发阶段,调试日志能快速定位代码 Bug;上线后,错误 / 警告日志可监控系统运行状态,同时日志数据也为流量分析、用户行为挖掘提供基础。
1. 核心配置示例
在 Django 的settings.py中添加如下配置,适配开发 / 生产双场景的日志需求:
LOGGING = { 'version': 1, # 是否禁用已经存在的日志器 'disable_existing_loggers': False, # 日志格式化器 'formatters': { 'simple': { 'format': '%(asctime)s %(module)s.%(funcName)s: %(message)s', 'datefmt': '%Y-%m-%d %H:%M:%S', }, 'verbose': { 'format': '%(asctime)s %(levelname)s [%(process)d-%(threadName)s] ' '%(module)s.%(funcName)s line %(lineno)d: %(message)s', 'datefmt': '%Y-%m-%d %H:%M:%S', } }, # 日志过滤器 'filters': { # 只有在Django配置文件中DEBUG值为True时才起作用 'require_debug_true': { '()': 'django.utils.log.RequireDebugTrue', }, }, # 日志处理器 'handlers': { # 输出到控制台 'console': { 'class': 'logging.StreamHandler', 'level': 'DEBUG', 'filters': ['require_debug_true'], 'formatter': 'simple', }, # 输出到文件(每周切割一次) 'file1': { 'class': 'logging.handlers.TimedRotatingFileHandler', 'filename': 'access.log', 'when': 'W0', 'backupCount': 12, 'formatter': 'simple', 'level': 'INFO', }, # 输出到文件(每天切割一次) 'file2': { 'class': 'logging.handlers.TimedRotatingFileHandler', 'filename': 'error.log', 'when': 'D', 'backupCount': 31, 'formatter': 'verbose', 'level': 'WARNING', }, }, # 日志器记录器 'loggers': { 'django': { # 需要使用的日志处理器 'handlers': ['console', 'file1', 'file2'], # 是否向上传播日志信息 'propagate': True, # 日志级别(不一定是最终的日志级别) 'level': 'DEBUG', }, }}2. 关键概念解析
(1)日志格式化占位符
| 占位符 | 说明 |
|---|---|
%(asctime)s |
日志生成时间(自定义格式) |
%(levelname)s |
日志级别(DEBUG/INFO 等) |
%(module)s |
触发日志的模块名 |
%(funcName)s |
触发日志的函数名 |
%(lineno)d |
触发日志的代码行号 |
%(process)d |
进程 ID |
%(threadName)s |
线程名称 |
(2)常用日志处理器
| 处理器类 | 适用场景 |
|---|---|
StreamHandler |
控制台输出(开发调试) |
TimedRotatingFileHandler |
按时间切割日志文件(生产环境) |
RotatingFileHandler |
按文件大小切割日志(大流量场景) |
SMTPHandler |
日志发送至邮箱(紧急错误告警) |
FileHandler |
普通文件输出(小型项目) |
(3)日志级别(从低到高)
NOTSET < DEBUG < INFO < WARNING < ERROR < CRITICAL
- DEBUG:开发调试信息(如 SQL 语句、变量值)
- INFO:常规运行信息(如接口访问记录)
- WARNING:非致命警告(如 4xx 请求、配置缺失)
- ERROR:致命错误(如 5xx 响应、数据库连接失败)
CRITICAL:系统级故障(如服务器宕机)最终日志级别 = 记录器级别 + 处理器级别(取较高者),例如记录器设为 DEBUG、处理器设为 INFO,则仅输出 INFO 及以上日志。
(4)Django 内置核心日志器
| 日志器名 | 用途 |
|---|---|
| django | 全局日志,覆盖项目所有模块 |
| django.request | 记录 HTTP 请求(4xx=WARNING,5xx=ERROR) |
| django.db.backends | 记录数据库交互(含 ORM 生成的 SQL) |
| django.template | 记录模板渲染相关日志 |
| django.server | 记录开发服务器(runserver)请求日志 |
日志记录器中配置的日志级别有可能不是最终的日志级别,因为还要参考日志处理器中配置的日志级别,取二者中级别较高者作为最终的日志级别。
二、Django-Debug-Toolbar 调试工具栏
Django-Debug-Toolbar 是开发阶段的 "调试神器",无需手动打印日志,即可直观查看项目运行的核心信息,是定位性能问题、优化代码的必备工具。
1. 核心功能
| 项目 | 说明 |
|---|---|
| Versions | Django的版本 |
| Time | 显示视图耗费的时间 |
| Settings | 配置文件中设置的值 |
| Headers | HTTP请求头和响应头的信息 |
| Request | 和请求相关的各种变量及其信息 |
| StaticFiles | 静态文件加载情况 |
| Templates | 模板的相关信息 |
| Cache | 缓存的使用情况 |
| Signals | Django内置的信号信息 |
| Logging | 被记录的日志信息 |
| SQL | 向数据库发送的SQL语句及其执行时间 |
2. 安装与配置
-
安装Django-Debug-Toolbar。
pip install django-debug-toolbar
-
配置 - 修改settings.py。
INSTALLED_APPS = [ 'debug_toolbar',]MIDDLEWARE = [ 'debug_toolbar.middleware.DebugToolbarMiddleware',]DEBUG_TOOLBAR_CONFIG = { # 引入jQuery库 'JQUERY_URL': 'https://cdn.bootcss.com/jquery/3.3.1/jquery.min.js', # 工具栏是否折叠 'SHOW_COLLAPSED': True, # 是否显示工具栏 'SHOW_TOOLBAR_CALLBACK': lambda x: True,}
-
配置 - 修改urls.py。
if settings.DEBUG: import debug_toolbar urlpatterns.insert(0, path('debug/', include(debug_toolbar.urls)))
-
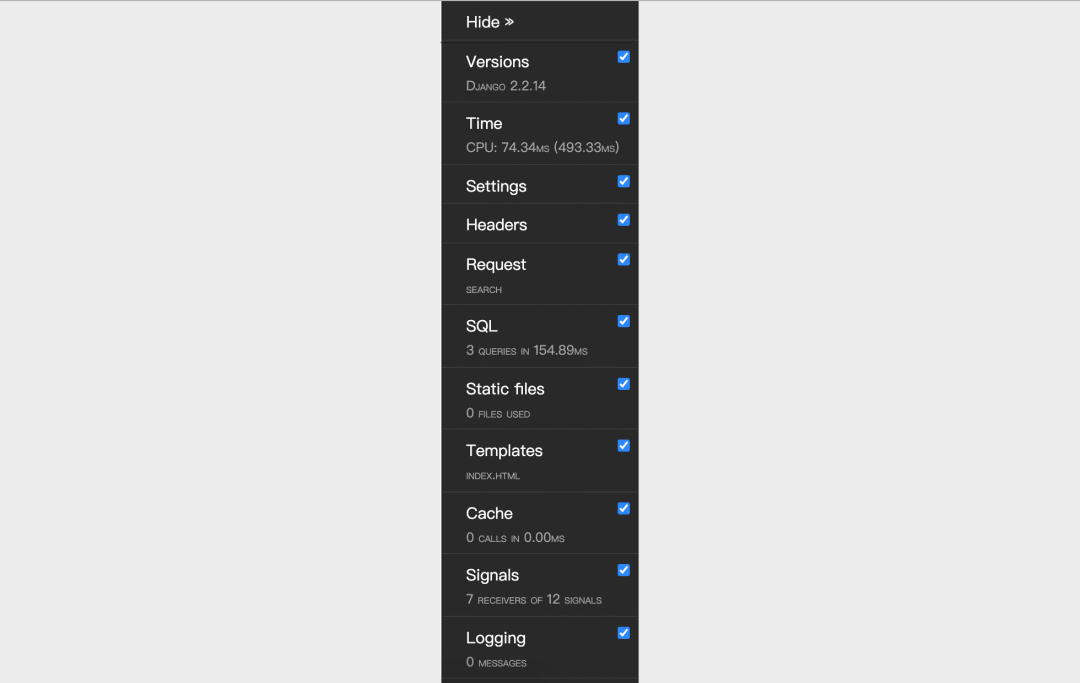
在配置好Django-Debug-Toolbar之后,页面右侧会看到一个调试工具栏,如下图所示,上面包括了如前所述的各种调试信息,包括执行时间、项目设置、请求头、SQL、静态资源、模板、缓存、信号等,查看起来非常的方便。
三、ORM 代码性能优化
在配置了日志或Django-Debug-Toolbar之后,我们可以查看一下之前将老师数据导出成Excel报表的视图函数执行情况,这里我们关注的是ORM框架生成的SQL查询到底是什么样子的,相信这里的结果会让你感到有一些意外。执行Teacher.objects.all()之后我们可以注意到,在控制台看到的或者通过Django-Debug-Toolbar输出的SQL是下面这样的:
SELECT `tb_teacher`.`no`, `tb_teacher`.`name`, `tb_teacher`.`detail`, `tb_teacher`.`photo`, `tb_teacher`.`good_count`, `tb_teacher`.`bad_count`, `tb_teacher`.`sno` FROM `tb_teacher`; args=()SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 101; args=(101,)SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 101; args=(101,)SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 101; args=(101,)SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 101; args=(101,)SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 103; args=(103,)SELECT `tb_subject`.`no`, `tb_subject`.`name`, `tb_subject`.`intro`, `tb_subject`.`create_date`, `tb_subject`.`is_hot` FROM `tb_subject` WHERE `tb_subject`.`no` = 103; args=(103,)这里的问题通常被称为"1+N查询"(有的地方也将其称之为"N+1查询"),原本获取老师的数据只需要一条SQL,但是由于老师关联了学科,当我们查询到N条老师的数据时,Django的ORM框架又向数据库发出了N条SQL去查询老师所属学科的信息。每条SQL执行都会有较大的开销而且会给数据库服务器带来压力,如果能够在一条SQL中完成老师和学科的查询肯定是更好的做法,这一点也很容易做到,相信大家已经想到怎么做了。是的,我们可以使用连接查询,但是在使用Django的ORM框架时如何做到这一点呢?对于多对一关联(如投票应用中的老师和学科),我们可以使用QuerySet的用select_related()方法来加载关联对象;而对于多对多关联(如电商网站中的订单和商品),我们可以使用prefetch_related()方法来加载关联对象。
在导出老师Excel报表的视图函数中,我们可以按照下面的方式优化代码。
queryset = Teacher.objects.all().select_related('subject')事实上,用ECharts生成前端报表的视图函数中,查询老师好评和差评数据的操作也能够优化,因为在这个例子中,我们只需要获取老师的姓名、好评数和差评数这三项数据,但是在默认的情况生成的SQL会查询老师表的所有字段。可以用QuerySet的only()方法来指定需要查询的属性,也可以用QuerySet的defer()方法来指定暂时不需要查询的属性,这样生成的SQL会通过投影操作来指定需要查询的列,从而改善查询性能,代码如下所示:
queryset = Teacher.objects.all().only('name', 'good_count', 'bad_count')当然,如果要统计出每个学科的老师好评和差评的平均数,利用Django的ORM框架也能够做到,代码如下所示:
queryset = Teacher.objects.values('subject').annotate(good=Avg('good_count'), bad=Avg('bad_count'))这里获得的QuerySet中的元素是字典对象,每个字典中有三组键值对,分别是代表学科编号的subject、代表好评数的good和代表差评数的bad。如果想要获得学科的名称而不是编号,可以按照如下所示的方式调整代码:
queryset = Teacher.objects.values('subject__name').annotate(good=Avg('good_count'), bad=Avg('bad_count'))可见,Django的ORM框架允许我们用面向对象的方式完成关系数据库中的分组和聚合查询。
AI工具,提高学习,工作效率,神器
国内直接使用顶级AI工具
谷歌浏览器访问:
https://www.nezhasoft.cloud/r/vMPJZr