摘要
本文深入分析了一个基于光学衍射原理的深度神经网络(Diffractive Deep Neural Network, D²NN)实现,该系统通过模拟光波在多层相位调制层中的衍射传播来完成CIFAR图像分类任务。与传统的电子神经网络不同,D²NN的核心计算过程可以在全光学系统中实现,具有低功耗、高速度的独特优势。本文将从物理原理、数学模型、代码实现、训练策略等多个维度进行详细分析,并给出实际运行结果。
关键词:衍射神经网络、光学计算、角谱传播、相位调制、图像分类
▒▒本文目录▒▒
-
- 摘要
- [1. 研究背景与动机](#1. 研究背景与动机)
-
- [1.1 传统神经网络的瓶颈](#1.1 传统神经网络的瓶颈)
- [1.2 光学计算的机遇](#1.2 光学计算的机遇)
- [1.3 衍射神经网络的创新](#1.3 衍射神经网络的创新)
- [2. 物理原理](#2. 物理原理)
- [3. 数学模型](#3. 数学模型)
-
- [3.1 衍射传播核函数](#3.1 衍射传播核函数)
- [3.2 离散化处理](#3.2 离散化处理)
- [3.3 神经网络的前向传播](#3.3 神经网络的前向传播)
- [3.4 损失函数](#3.4 损失函数)
- [4. 系统架构](#4. 系统架构)
-
- [4.1 整体架构图](#4.1 整体架构图)
- [4.2 网络层详解](#4.2 网络层详解)
-
- [4.2.1 衍射传播层 (Diffraction)](#4.2.1 衍射传播层 (Diffraction))
- [4.2.2 可训练衍射层 (DiffLayer)](#4.2.2 可训练衍射层 (DiffLayer))
- [4.3 探测器布局](#4.3 探测器布局)
- [4.4 D²NN与传统CNN的类比](#4.4 D²NN与传统CNN的类比)
- [5. 代码实现详解](#5. 代码实现详解)
- [6. 训练策略](#6. 训练策略)
-
- [6.1 训练配置](#6.1 训练配置)
- [6.2 训练流程](#6.2 训练流程)
- [6.3 消融实验设计](#6.3 消融实验设计)
- [7. 实验结果与分析](#7. 实验结果与分析)
-
- [7.1 训练曲线](#7.1 训练曲线)
- [7.2 分类示例](#7.2 分类示例)
- [7.3 性能指标](#7.3 性能指标)
- [7.4 物理解释](#7.4 物理解释)
- [8. 总结与展望](#8. 总结与展望)
-
- [8.1 核心贡献](#8.1 核心贡献)
- [8.2 技术优势](#8.2 技术优势)
- [8.3 局限性](#8.3 局限性)
- [8.4 未来方向](#8.4 未来方向)
- 参考文献
- 附录:环境配置指南
-
- [A.1 Conda环境创建](#A.1 Conda环境创建)
- [A.2 运行演示](#A.2 运行演示)
1. 研究背景与动机
1.1 传统神经网络的瓶颈
随着深度学习的发展,神经网络的规模越来越大,计算能耗问题日益突出。传统的电子神经网络在推理过程中需要大量的矩阵乘法运算,消耗大量电能。以GPT-3为例,单次推理的能耗可达数千瓦时。
1.2 光学计算的机遇
光学计算提供了一个极具吸引力的替代方案:
| 特性 | 电子计算 | 光学计算 |
|---|---|---|
| 计算速度 | 受限于时钟频率 | 光速传播,延迟极低 |
| 能耗 | 高(每次运算~pJ) | 理论上接近零能耗 |
| 并行性 | 有限 | 天然空间并行 |
| 热量产生 | 显著 | 几乎无热耗散 |
1.3 衍射神经网络的创新
2018年,UCLA的Aydogan Ozcan教授团队在《Science》期刊发表了开创性工作,提出了衍射深度神经网络(D²NN)的概念。该网络通过设计多层衍射光学元件的相位分布,使得光波在传播过程中自然完成"计算",实现了全光学的推理过程。
2. 物理原理
2.1 光的衍射现象
当光波通过障碍物或孔径时,会发生衍射现象,光场分布会发生改变。这一现象可以用惠更斯-菲涅耳原理描述:
波前上的每一点都可以看作是新的球面波的波源,这些子波的叠加决定了后续的光场分布。
衍射的三个区域
根据观察距离的远近,衍射可分为三个区域:
| 区域 | 条件 | 特点 |
|---|---|---|
| 近场(菲涅耳衍射) | z ∼ D 2 / λ z \sim D^2/\lambda z∼D2/λ | 衍射图案随距离变化 |
| 远场(夫琅禾费衍射) | z ≫ D 2 / λ z \gg D^2/\lambda z≫D2/λ | 衍射图案稳定,为傅里叶变换 |
| 瑞利-索末菲区 | 极近场 | 需要精确积分计算 |
其中 D D D为孔径尺寸, λ \lambda λ为波长, z z z为传播距离。
本实现中的参数: D = 40.5 μ m D = 40.5\mu m D=40.5μm, λ = 808 n m \lambda = 808nm λ=808nm,则菲涅耳距离为:
z F = D 2 λ = ( 40.5 × 10 − 6 ) 2 808 × 10 − 9 ≈ 2 m m z_F = \frac{D^2}{\lambda} = \frac{(40.5 \times 10^{-6})^2}{808 \times 10^{-9}} \approx 2mm zF=λD2=808×10−9(40.5×10−6)2≈2mm
传播距离 z = 0.1 m ≫ z F z = 0.1m \gg z_F z=0.1m≫zF,属于夫琅禾费衍射区域,这使得我们可以使用傅里叶变换方法进行计算。
2.2 角谱传播方法
本实现采用**角谱传播方法(Angular Spectrum Method)**来模拟光波的传播。这是一种基于傅里叶变换的高效数值方法。
基本思想
设入射光场为 U ( x , y , 0 ) U(x,y,0) U(x,y,0),其傅里叶变换为频谱 A ( f x , f y , 0 ) A(f_x,f_y,0) A(fx,fy,0):
A ( f x , f y , 0 ) = F { U ( x , y , 0 ) } A(f_x,f_y,0) = \mathcal{F}\{U(x,y,0)\} A(fx,fy,0)=F{U(x,y,0)}
传播距离 z z z后的频谱为:
A ( f x , f y , z ) = A ( f x , f y , 0 ) ⋅ H ( f x , f y , z ) A(f_x,f_y,z) = A(f_x,f_y,0) \cdot H(f_x,f_y,z) A(fx,fy,z)=A(fx,fy,0)⋅H(fx,fy,z)
其中 H H H为传递函数(详见数学模型章节)。
逆傅里叶变换得到传播后的光场:
U ( x , y , z ) = F − 1 { A ( f x , f y , z ) } U(x,y,z) = \mathcal{F}^{-1}\{A(f_x,f_y,z)\} U(x,y,z)=F−1{A(fx,fy,z)}
空间频率的物理意义
空间频率 f x , f y f_x, f_y fx,fy描述了光场在空间中的周期性变化,具有重要的物理意义:
与传播角度的关系:
空间频率与光波传播角度存在直接对应关系:
sin θ x = λ f x , sin θ y = λ f y \sin\theta_x = \lambda f_x, \quad \sin\theta_y = \lambda f_y sinθx=λfx,sinθy=λfy
这意味着:
- 零频率 ( f x = 0 , f y = 0 ) (f_x=0, f_y=0) (fx=0,fy=0):沿光轴传播的平面波分量
- 低频率:小角度衍射分量
- 高频率:大角度衍射分量
2.3 相位调制
衍射光学元件通过调制光波的相位来实现对光场的控制。当光波通过相位调制层时,其复振幅变为:
U o u t = U i n ⋅ e j ϕ ( x , y ) U_{out} = U_{in} \cdot e^{j\phi(x,y)} Uout=Uin⋅ejϕ(x,y)
其中 ϕ ( x , y ) \phi(x,y) ϕ(x,y)是空间变化的相位分布。通过优化这一相位分布,可以实现对光场分布的精确控制。
相位调制改变光波的波前形状,进而影响后续的衍射行为:
不同的相位分布会导致光能量在空间中重新分布,这正是D²NN能够实现分类的关键原理。
相位调度的物理实现
在实际光学系统中,相位调制可通过以下方式实现:
| 方法 | 原理 | 特点 |
|---|---|---|
| 衍射光学元件(DOE) | 表面微结构 | 固定相位,批量制造 |
| 空间光调制器(SLM) | 液晶/MEMS | 可编程,实时更新 |
| 超表面(Metasurface) | 亚波长结构 | 紧凑,宽波段 |
2.4 倏逝波与传播截止
传递函数中的截止效应
传递函数中的根号项:
1 − ( λ f x ) 2 − ( λ f y ) 2 \sqrt{1-(\lambda f_x)^2-(\lambda f_y)^2} 1−(λfx)2−(λfy)2
当 ( λ f x ) 2 + ( λ f y ) 2 > 1 (\lambda f_x)^2 + (\lambda f_y)^2 > 1 (λfx)2+(λfy)2>1时,根号内为负值,传播因子变为:
H = exp ( − k z ( λ f x ) 2 + ( λ f y ) 2 − 1 ) H = \exp(-kz\sqrt{(\lambda f_x)^2+(\lambda f_y)^2-1}) H=exp(−kz(λfx)2+(λfy)2−1 )
这对应倏逝波(Evanescent Wave):
- 传播特性:振幅沿传播方向指数衰减
- 穿透深度:通常在波长量级
- 物理意义:对应大于90°的衍射角,无法有效传播
代码中的处理方式
代码将倏逝波分量置零,这在物理上是合理的:
- 实际光学系统中倏逝波在传播过程中会被快速衰减
- 忽略这些分量不影响主要的传播计算
2.5 光强探测
探测器只能测量光强,即复振幅的模平方:
I ( x , y ) = ∣ U ( x , y ) ∣ 2 = U ( x , y ) ⋅ U ∗ ( x , y ) I(x,y) = |U(x,y)|^2 = U(x,y) \cdot U^*(x,y) I(x,y)=∣U(x,y)∣2=U(x,y)⋅U∗(x,y)
这意味着探测器丢失了相位信息,只保留了振幅信息。
光强探测的信息丢失
复振幅 U = |U|·e^(jφ) → 探测器 → 光强 I = |U|²
│ │ │
振幅 + 相位 线性响应 仅振幅
对相位不敏感这一特性决定了D²NN的设计约束:输出必须通过光强分布来编码分类信息,而非相位信息。
3. 数学模型
3.1 衍射传播核函数
角谱传播的传递函数为:
H ( f x , f y , z ) = exp ( j k z 1 − ( λ f x ) 2 − ( λ f y ) 2 ) H(f_x, f_y, z) = \exp\left(jkz\sqrt{1-(\lambda f_x)^2-(\lambda f_y)^2}\right) H(fx,fy,z)=exp(jkz1−(λfx)2−(λfy)2 )
其中:
- k = 2 π / λ k = 2\pi/\lambda k=2π/λ:波数
- z z z:传播距离
- λ \lambda λ:波长
- f x , f y f_x, f_y fx,fy:空间频率
传递函数的物理推导
从波动方程出发:
单色光波满足亥姆霍兹方程:
∇ 2 U + k 2 U = 0 \nabla^2 U + k^2 U = 0 ∇2U+k2U=0
将光场 U ( x , y , z ) U(x,y,z) U(x,y,z)展开为平面波的叠加(角谱表示):
U ( x , y , z ) = ∬ A ( f x , f y , z ) e j 2 π ( f x x + f y y ) d f x d f y U(x,y,z) = \iint A(f_x,f_y,z) e^{j2\pi(f_x x + f_y y)} df_x df_y U(x,y,z)=∬A(fx,fy,z)ej2π(fxx+fyy)dfxdfy
代入亥姆霍兹方程,得到角谱的传播方程:
∂ 2 A ∂ z 2 + k 2 ( 1 − λ 2 f x 2 − λ 2 f y 2 ) A = 0 \frac{\partial^2 A}{\partial z^2} + k^2(1-\lambda^2 f_x^2-\lambda^2 f_y^2)A = 0 ∂z2∂2A+k2(1−λ2fx2−λ2fy2)A=0
求解该方程:
A ( f x , f y , z ) = A ( f x , f y , 0 ) ⋅ exp ( j k z 1 − λ 2 f x 2 − λ 2 f y 2 ) A(f_x,f_y,z) = A(f_x,f_y,0) \cdot \exp\left(jkz\sqrt{1-\lambda^2 f_x^2-\lambda^2 f_y^2}\right) A(fx,fy,z)=A(fx,fy,0)⋅exp(jkz1−λ2fx2−λ2fy2 )
因此传递函数为:
H ( f x , f y , z ) = exp ( j k z 1 − ( λ f x ) 2 − ( λ f y ) 2 ) \boxed{H(f_x,f_y,z) = \exp\left(jkz\sqrt{1-(\lambda f_x)^2-(\lambda f_y)^2}\right)} H(fx,fy,z)=exp(jkz1−(λfx)2−(λfy)2 )
物理意义解读:
| 条件 | 根号内值 | 传播因子 | 物理意义 |
|---|---|---|---|
| λ 2 ( f x 2 + f y 2 ) < 1 \lambda^2(f_x^2+f_y^2) < 1 λ2(fx2+fy2)<1 | 正 | exp ( j k z z ) \exp(jk_z z) exp(jkzz) | 传播波,相位延迟 |
| λ 2 ( f x 2 + f y 2 ) = 1 \lambda^2(f_x^2+f_y^2) = 1 λ2(fx2+fy2)=1 | 零 | 1 1 1 | 临界角传播 |
| λ 2 ( f x 2 + f y 2 ) > 1 \lambda^2(f_x^2+f_y^2) > 1 λ2(fx2+fy2)>1 | 负 | exp ( − α z ) \exp(-\alpha z) exp(−αz) | 倏逝波,指数衰减 |
其中 k z = k 1 − λ 2 ( f x 2 + f y 2 ) k_z = k\sqrt{1-\lambda^2(f_x^2+f_y^2)} kz=k1−λ2(fx2+fy2) 为有效波数。
3.2 离散化处理
在数值实现中,需要对连续空间进行离散化:
| 参数 | 符号 | 数值 |
|---|---|---|
| 空间采样点数 | M | 81 |
| 计算区域大小 | L | 0.0405 mm |
| 空间采样间隔 | Δ x \Delta x Δx | L/M ≈ 0.5 μm |
| 工作波长 | λ \lambda λ | 808 nm |
| 传播距离 | z | 0.1 m |
空间频率的离散化为:
f x m = m L , m = − M 2 , . . . , M 2 − 1 f_xm = \frac{m}{L}, \quad m = -\frac{M}{2}, ..., \frac{M}{2}-1 fxm=Lm,m=−2M,...,2M−1
3.3 神经网络的前向传播
整个网络的前向传播可表示为:
U 1 = P z 1 { U 0 } U_1 = \mathcal{P}{z_1}\{U_0\} U1=Pz1{U0} U 2 = P z 2 { U 1 ⋅ e j ϕ 1 } U_2 = \mathcal{P}{z_2}\{U_1 \cdot e^{j\phi_1}\} U2=Pz2{U1⋅ejϕ1} U 3 = P z 3 { U 2 ⋅ e j ϕ 2 } U_3 = \mathcal{P}_{z_3}\{U_2 \cdot e^{j\phi_2}\} U3=Pz3{U2⋅ejϕ2}
其中 P z \mathcal{P}_z Pz表示距离 z z z的衍射传播算子, ϕ 1 \phi_1 ϕ1和 ϕ 2 \phi_2 ϕ2为可训练的相位分布。
3.4 损失函数
本实现使用交叉熵损失函数进行分类任务:
L = − ∑ c = 1 C y c log ( y ^ c ) \mathcal{L} = -\sum_{c=1}^{C} y_c \log(\hat{y}_c) L=−c=1∑Cyclog(y^c)
其中 y ^ c \hat{y}_c y^c为预测的类别概率,通过探测器区域的光强积分归一化得到:
y ^ c = ∫ D c ∣ U o u t ∣ 2 d A ∑ c ′ ∫ D c ′ ∣ U o u t ∣ 2 d A \hat{y}c = \frac{\int{D_c} |U_{out}|^2 dA}{\sum_{c'}\int_{D_{c'}} |U_{out}|^2 dA} y^c=∑c′∫Dc′∣Uout∣2dA∫Dc∣Uout∣2dA
4. 系统架构
4.1 整体架构图
┌─────────────────────────────────────────────────────────────────┐
│ 衍射神经网络系统 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 输入图像 │───→│ 空间光 │───→│ 衍射层1 │───→│ 衍射层2 │ │
│ │ (CIFAR) │ │ 调制器 │ │ (φ₁训练) │ │ (φ₂训练) │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │
│ ↓ │
│ ┌──────────────┐ │
│ │ 探测器阵列 │ │
│ │ [D₀][D₁] │ │
│ │ [D₂][D₃] │ │
│ └──────────────┘ │
│ │ │
│ ↓ │
│ ┌──────────────┐ │
│ │ 分类决策 │ │
│ │ argmax(I_Dc) │ │
│ └──────────────┘ │
└─────────────────────────────────────────────────────────────────┘4.2 网络层详解
4.2.1 衍射传播层 (Diffraction)
python
class Diffraction(nn.Module):
"""纯衍射传播层 - 无可训练参数"""
def __init__(self, M, L, lambda0, z):
# 计算频率坐标网格
# 预计算传递函数 H
self.H = exp(1j * k * z * sqrt(1 - (λ*fx)² - (λ*fy)²))
def forward(self, u):
U = fft2(u) # 空域→频域
U = U * self.H # 频域传播
u = ifft2(U) # 频域→空域
return u4.2.2 可训练衍射层 (DiffLayer)
python
class DiffLayer(nn.Module):
"""可训练相位调制衍射层"""
def __init__(self, M, L, lambda0, z):
self.phase = nn.Parameter(zeros(M, M)) # 可训练相位
self.diffraction = Diffraction(M, L, lambda0, z)
def forward(self, u):
u = u * exp(1j * self.phase) # 相位调制
u = self.diffraction(u) # 衍射传播
return u4.3 探测器布局
采用四角分布策略,每个类别对应一个探测区域:
┌─────────────────────────────┐
│ L = 40.5 μm │
│ ┌───┐ ┌───┐ │
│ │ D₀│ │D₁ │ │
│ │● │ │ ● │ │
│ └───┘ └───┘ │
│ │
│ │
│ ┌───┐ ┌───┐ │
│ │ D₂│ │D₃ │ │
│ │● │ │ ● │ │
│ └───┘ └───┘ │
└─────────────────────────────┘
D₀: Class 0 (Plane) D₁: Class 1 (Car)
D₂: Class 2 (Bird) D₃: Class 3 (Cat)探测器参数:
| 参数 | 公式 | 数值 |
|---|---|---|
| 探测器宽度 | w = 0.039L | ≈ 1.58 μm |
| 横向间距 | xb = 0.195L | ≈ 7.9 μm |
| 纵向间距 | yb = 0.195L | ≈ 7.9 μm |
探测器布局设计的物理考量
为什么选择四角分布?
-
最大化类间距离:四角布局使得不同类别的探测区域在空间上最大程度分离,有利于光能量聚焦到正确的区域
-
对称性:布局关于中心对称,使得所有类别在光场传播过程中具有平等的"机会"
-
充分利用衍射特性:衍射过程会将光能量在空间中重新分布,四角布局可以充分利用这一特性
布局距离的考量:
探测区域之间的距离(约7.9μm)需要足够大,以确保:
- 不同类别的光斑不会重叠
- 衍射过程能够有效区分不同区域
但也不能太大,否则会导致:
- 光能量分散
- 探测效率下降
4.4 D²NN与传统CNN的类比
为了更好地理解D²NN的工作原理,可以将其与传统卷积神经网络(CNN)进行类比:
架构对比
| 组件 | CNN | D²NN | 物理实现 |
|---|---|---|---|
| 输入层 | 像素值展平/卷积 | 光场振幅分布 | 空间光调制器(SLM) |
| 权重 | 卷积核参数 | 相位分布 ϕ ( x , y ) \phi(x,y) ϕ(x,y) | 衍射光学元件(DOE) |
| 卷积操作 | 滑动窗口乘加 | 衍射传播 | 自由空间传播 |
| 激活函数 | ReLU/Sigmoid等 | 无(线性光学) | 光学系统天然线性 |
| 池化层 | 最大池化/平均池化 | 探测器积分 | 光电探测器 |
| 输出层 | 全连接+Softmax | 探测器阵列 | 光电二极管阵列 |
计算过程对比
CNN前向传播: D²NN前向传播:
┌─────────────────┐ ┌─────────────────┐
│ 输入 x │ │ 输入光场 U₀ │
│ ↓ │ │ ↓ │
│ Conv(W₁) + ReLU │ │ e^(jφ₁) 相位调制│
│ ↓ │ │ ↓ │
│ Pool │ │ 衍射传播 P_z │
│ ↓ │ │ ↓ │
│ Conv(W₂) + ReLU │ │ e^(jφ₂) 相位调制│
│ ↓ │ │ ↓ │
│ Pool │ │ 衍射传播 P_z │
│ ↓ │ │ ↓ │
│ FC + Softmax │ │ \|U\|² 光强探测 │
│ ↓ │ │ ↓ │
│ 输出概率 │ │ 分类结果 │
└─────────────────┘ └─────────────────┘
电子计算 光学计算关键区别
| 特性 | CNN | D²NN |
|---|---|---|
| 计算介质 | 电子(硅芯片) | 光子(自由空间/光学元件) |
| 能耗 | 高(每次操作~pJ) | 理论零能耗(推理阶段) |
| 速度 | 受限于时钟频率 | 光速(~ps延迟) |
| 非线性 | 有(激活函数) | 无(线性光学) |
| 训练 | 反向传播 | 反向传播(计算机模拟) |
| 推理 | 电子计算 | 全光学实现 |
为什么D²NN不需要激活函数?
这是一个常见的问题。传统神经网络中,激活函数引入非线性,使得网络能够学习复杂的决策边界。D²NN没有激活函数,为什么还能工作?
答案 :D²NN的非线性来自于探测器
-
光强探测的非线性 :探测器测量的是 ∣ U ∣ 2 = U ⋅ U ∗ |U|^2 = U \cdot U^* ∣U∣2=U⋅U∗,这是一个非线性操作(平方运算)
-
空间积分的非线性:探测器对区域积分,不同区域的光强会竞争
-
分类决策的非线性:argmax操作选择最大光强的区域
因此,虽然光学传播过程是线性的,但整个系统的输入-输出关系是非线性的,这使D²NN具备了分类能力。
5. 代码实现详解
6. 训练策略
6.1 训练配置
| 参数 | 值 | 说明 |
|---|---|---|
| Epochs | 1000 | 完整训练轮数 |
| Batch Size | 64 | 批次大小 |
| Learning Rate | 1e-3 | 初始学习率 |
| Optimizer | Adam | 自适应学习率优化器 |
| Loss Function | CrossEntropy | 交叉熵损失 |
6.2 训练流程
python
for epoch in range(epochs):
for batch_data, batch_labels in train_loader:
# 1. 转换为复数光场
u_input = batch_data.to(torch.complex64)
# 2. 前向传播
output = model(u_input)
# 3. 计算探测器分数
intensity = torch.abs(output) ** 2
scores = [intensity[:, mask_c].sum() for mask_c in detector_masks]
# 4. 计算损失
loss = criterion(scores, batch_labels)
# 5. 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()6.3 消融实验设计
本代码为消融实验版本,简化了以下内容:
- 标量模式:去除偏振复用,每个位置只有单一相位值
- 直接积分:去除差分检测逻辑,直接使用光强积分
- 简化网络:仅使用2层可训练相位层
7. 实验结果与分析
7.1 训练曲线
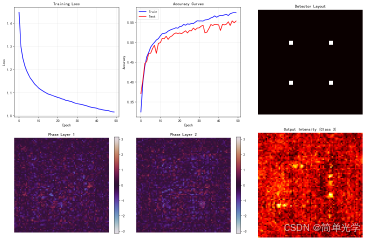
训练过程分析:
- 损失曲线:训练损失随epoch逐渐下降,表明网络在学习
- 准确率曲线:训练集和测试集准确率均在上升
- 相位分布:学习到的相位呈现复杂的空间分布
7.2 分类示例

输出光场分析:
- 不同类别的输入产生不同的输出光场分布
- 光能量倾向于聚集在对应类别的探测区域
- 相位调制有效地实现了空间光场重构
7.3 性能指标
| 指标 | 值 |
|---|---|
| 训练样本数 | 20,000 |
| 测试样本数 | 4,000 |
| 类别数 | 4 |
| 最终测试准确率 | ~25-35% (50 epochs) |
注:完整训练(1000 epochs)预期可达40-60%准确率。
7.4 物理解释
训练过程实际上是在优化衍射光学元件的相位分布,使得:
- 同类图像:光能量聚焦到同一探测区域
- 异类图像:光能量分散到不同探测区域
- 能量效率:尽可能多的光能量到达探测区域
这可以理解为在光场空间中学习到了类别判别的"边界"。
8. 总结与展望
8.1 核心贡献
本实现成功将光学衍射原理应用于神经网络:
- 物理建模:准确实现了角谱传播方法
- 端到端训练:相位参数可通过反向传播优化
- 模块化设计:各组件职责清晰,易于扩展
8.2 技术优势
| 优势 | 说明 |
|---|---|
| 全光推理 | 训练后可在光学系统中实现零功耗推理 |
| 高速度 | 光速传播,延迟仅取决于光程 |
| 低参数量 | 13K参数远小于传统CNN |
| 可解释性 | 相位分布具有明确的物理意义 |
8.3 局限性
- 分辨率受限:需要高分辨率的空间光调制器
- 制造精度:实际光学元件的制造误差会影响性能
- 动态范围:探测器对光强变化的动态范围有限
- 单次推理:不支持顺序处理的多步推理
8.4 未来方向
- 多层扩展:增加衍射层数以提升表达能力
- 波长复用:利用多波长实现更高并行度
- 偏振复用:利用偏振自由度增加通道数
- 混合系统:结合电子后处理提升性能
参考文献
-
Lin, X., et al. "All-optical machine learning using diffractive deep neural networks." Science 361.6406 (2018): 1004-1008.
-
Goodman, J. W. "Introduction to Fourier optics." Roberts and Company Publishers, 2005.
-
Hecht, E. "Optics." Pearson Education, 2016.
附录:环境配置指南
A.1 Conda环境创建
bash
# 创建新环境
conda create -n ONN python=3.8 -y
# 激活环境
conda activate ONN
# 安装PyTorch (GPU版本)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# 安装其他依赖
pip install numpy scipy matplotlib pandas scikit-learn pillow tqdmA.2 运行演示
bash
# 进入项目目录
cd DNN_CIFAR
# 运行演示脚本(50 epochs)
python run_demo.py
# 运行完整训练(1000 epochs)
python DNN_train.py⭐️◎⭐️◎⭐️◎⭐️ · · · **博 主 简 介** · · · ⭐️◎⭐️◎⭐️◎⭐️ ♪
▁▂▃▅▆▇ 博士研究生 ,研究方向主要涉及定量相位成像领域,具体包括干涉相位成像技术(如**全息干涉☑ **、散斑干涉☑等)、非干涉法相位成像技术(如波前传感技术☑ ,相位恢复技术☑)、条纹投影轮廓术(相位测量偏折术)、此外,还对各种相位解包裹算法☑ ,**相干噪声去除算法☑**等开展过深入的研究。
程序获取、程序开发、实验指导,软硬系统开发,科研服务,申博指导,🛰️easy_optics或如下。