在机器学习的模型训练中,损失函数是连接模型预测与真实标签的核心桥梁,它像一把"标尺",衡量着模型预测结果与实际情况的偏差,进而引导模型通过反向传播不断调整参数、优化性能。无论是初学者还是有一定经验的算法工程师,大概率都听过这样一句"金科玉律":回归任务用均方误差(MSE),分类任务用交叉熵(Cross-Entropy)。
这句话看似简洁好记,能快速帮我们完成损失函数的初步选择,但它并非绝对真理------在实际场景中,若机械套用这一规则,往往会导致模型收敛缓慢、泛化能力不足,甚至无法达到预期效果。事实上,损失函数的选择从来不是"一刀切"的流程,而是一门结合任务特性、模型结构、数据分布的艺术。
本文将从损失函数的核心本质出发,深入拆解MSE与交叉熵的底层逻辑,分析"回归用MSE,分类用交叉熵"的适用场景与局限性,再拓展到不同任务下的损失函数选择技巧,结合具体案例说明如何灵活选用损失函数,帮助大家跳出刻板认知,真正掌握损失函数的选择之道。全文约6000字,兼顾理论深度与实操性,适合机器学习初学者、算法工程师参考。
一、开篇思考:为什么会有"回归用MSE,分类用交叉熵"的说法?
在正式探讨之前,我们先明确两个基础概念:回归任务与分类任务的核心区别,以及损失函数的核心作用。
回归任务的核心是预测一个连续值,比如预测房屋价格、股票涨跌幅度、用户消费金额等,模型的输出是一个实数(或实数向量),目标是让预测值尽可能接近真实值的连续分布;分类任务的核心是预测一个离散标签,比如判断图片是猫还是狗、邮件是否为垃圾邮件、用户是否会流失等,模型的输出是类别概率(或类别索引),目标是让预测的类别概率尽可能匹配真实类别的分布。
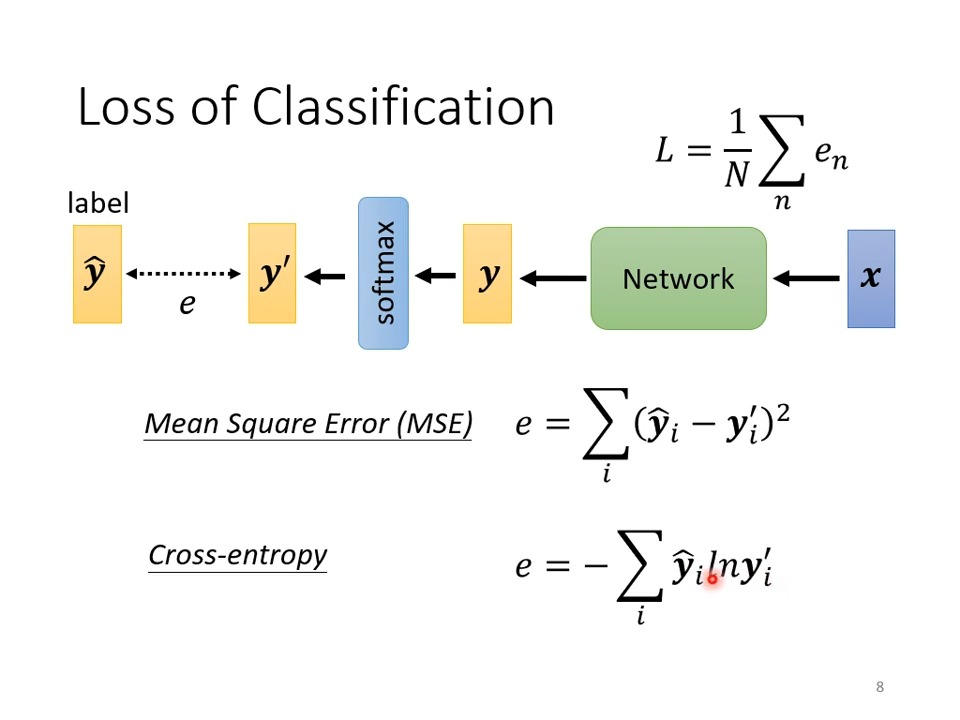
损失函数的核心作用,是将"预测偏差"量化为一个可优化的 scalar 值(标量),这个值越小,说明模型预测越接近真实情况。而MSE与交叉熵之所以被分别与回归、分类任务绑定,本质上是因为它们的"偏差量化逻辑",恰好与两类任务的目标特性相匹配------这也是那句"金科玉律"得以流传的核心原因。
1.1 回归任务与MSE:天生的"适配性"
均方误差(Mean Squared Error,MSE),也叫均方损失,其计算公式非常简单:对于单个样本,MSE = (y - ŷ)²,其中y是真实标签,ŷ是模型预测值;对于批量样本,MSE是所有样本误差的平均值,即MSE = (1/n)Σ(yᵢ - ŷᵢ)²(n为样本数量)。
MSE之所以适合回归任务,核心有三个原因,也是它与回归任务的"天生适配点":
第一,MSE的量化逻辑与回归任务目标高度一致。回归任务的目标是让预测值尽可能接近真实值,而MSE通过计算"预测值与真实值的差值的平方"来量化偏差------差值越大,平方后的值增长越快,对模型的惩罚力度越强,这能有效引导模型聚焦于减少大偏差,最终让预测值逼近真实值的连续分布。比如预测房屋价格时,若真实价格为100万,模型预测为150万(偏差50万),MSE为2500;若预测为110万(偏差10万),MSE为100,前者的惩罚力度是后者的25倍,能强力推动模型修正大误差。
第二,MSE具有良好的数学性质,便于优化。MSE是一个连续、可导(甚至二阶可导)的凸函数,而凸函数的优势在于存在唯一的全局最小值,不会出现局部最小值陷阱,这能让梯度下降等优化算法稳定收敛,快速找到最优参数。对于回归任务中常用的线性回归、多项式回归等模型,MSE的梯度计算简单,反向传播效率高,无需复杂的数学推导就能完成参数更新。
第三,MSE对"正态分布误差"的适配性。在实际回归场景中,样本的预测误差往往服从正态分布(这也是线性回归的基本假设之一),而MSE恰好是基于正态分布的极大似然估计推导得出的损失函数------从概率角度来说,使用MSE作为损失函数,等价于假设误差服从正态分布,能最大程度贴合数据的真实误差分布,提升模型的泛化能力。
1.2 分类任务与交叉熵:精准匹配"概率分布"
交叉熵(Cross-Entropy),本质上是衡量两个概率分布之间差异的指标,其核心逻辑是"通过惩罚预测概率与真实概率的偏差,让模型输出的概率分布尽可能接近真实标签的概率分布"。分类任务中,真实标签通常以"独热编码"(One-Hot Encoding)的形式存在,比如二分类任务中,正类标签为1,0,负类标签为0,1,这本质上是一种"确定性概率分布"(真实类别概率为1,其他类别为0);而模型的输出通常是经过Softmax(多分类)或Sigmoid(二分类)激活后的概率值,比如二分类中模型输出0.8, 0.2,表示预测为正类的概率是0.8,负类是0.2。
交叉熵的计算公式分两种场景:
-
二分类任务(Sigmoid + 交叉熵):损失 = -y·log(ŷ) + (1-y)·log(1-ŷ),其中y是真实标签(0或1),ŷ是模型预测的正类概率。
-
多分类任务(Softmax + 交叉熵):损失 = -Σyᵢ·log(ŷᵢ),其中yᵢ是真实标签的独热编码(只有真实类别为1,其余为0),ŷᵢ是模型预测的对应类别概率。
交叉熵之所以适合分类任务,核心原因也有三个,恰好匹配分类任务的"概率分布匹配"目标:
第一,交叉熵直接聚焦于"类别概率"的偏差,而非预测值本身。分类任务的核心不是预测一个具体的数值,而是预测每个类别的概率,最终选择概率最高的类别作为预测结果。交叉熵通过对数函数,将概率的偏差放大------当模型预测真实类别的概率接近1时,log(ŷ)接近0,损失接近0;当预测概率接近0时,log(ŷ)趋向负无穷,损失趋向正无穷,对模型的惩罚力度极强,能快速引导模型将真实类别的概率推向1,其他类别的概率推向0。
比如二分类任务中,真实标签为1(正类),若模型预测正类概率为0.9,交叉熵损失为 -1·log(0.9) + 0·log(0.1) ≈ 0.105;若预测概率为0.1,损失为 -1·log(0.1) + 0·log(0.9) ≈ 2.303,后者的损失是前者的22倍,能强力推动模型修正对真实类别的概率预测。
第二,交叉熵解决了MSE在分类任务中的"梯度消失"问题。如果在分类任务中强行使用MSE作为损失函数,结合Sigmoid/Softmax激活函数,会导致梯度下降过程中出现梯度消失,模型无法收敛。以Sigmoid激活函数为例,Sigmoid的导数在输出接近0或1时,会趋向于0;而MSE的梯度是2(ŷ - y)·Sigmoid'(x),当模型预测偏差较大(ŷ接近0或1)时,Sigmoid'(x)接近0,导致整体梯度接近0,参数更新停滞,模型无法继续优化。而交叉熵的梯度是(ŷ - y),无需乘以Sigmoid的导数,从根本上避免了梯度消失,让模型在分类任务中能快速收敛。
第三,交叉熵符合分类任务的"极大似然估计"逻辑。分类任务中,我们希望模型输出的类别概率,能最大程度贴合真实标签的分布,而交叉熵本质上是基于极大似然估计推导得出的------通过最小化交叉熵,等价于最大化模型预测的对数似然,即让模型对真实标签的预测概率最大化,这与分类任务的核心目标完全一致。
1.3 小结:"金科玉律"的本质是"适配性",而非"绝对性"
综上,"回归用MSE,分类用交叉熵"的说法,本质上是"损失函数的量化逻辑与任务目标的适配性"导致的------MSE适合量化连续值的偏差,交叉熵适合量化概率分布的偏差,而回归任务的核心是逼近连续值,分类任务的核心是匹配概率分布,因此二者形成了天然的对应关系。
但必须强调的是:这种对应关系是"适配",而非"绝对"。随着任务场景的复杂化(比如回归任务中存在异常值、分类任务中存在类别不平衡),或者模型结构的变化(比如深度学习中的复杂网络),单纯套用MSE或交叉熵,往往会出现问题。接下来,我们将深入分析这种"刻板套用"的局限性,打破认知误区。
二、认知误区:不是所有回归都能用MSE,也不是所有分类都能用交叉熵
很多初学者在学习过程中,会将"回归用MSE,分类用交叉熵"当作不可打破的规则,却忽略了实际场景中的复杂因素。事实上,MSE在回归任务中存在明显的局限性,交叉熵在分类任务中也并非万能,一旦场景不匹配,就会导致模型性能下降。
2.1 回归任务中MSE的局限性:这些场景下,MSE会"失效"
虽然MSE是回归任务的默认选择,但在以下4种场景中,MSE的表现会大打折扣,甚至无法满足需求,此时需要替换为更合适的损失函数。
场景1:数据中存在异常值(Outlier)
MSE的核心特性是"对大偏差进行平方惩罚",这在正常数据中是优势,但在存在异常值时,会变成劣势------异常值的偏差通常很大,平方后会产生极大的损失值,主导整个损失函数的优化方向,导致模型过度拟合异常值,偏离正常数据的分布,最终降低模型的泛化能力。
举个具体的例子:假设我们做"房屋价格预测",大部分房屋的价格在50万-200万之间,但有少量异常值(比如别墅价格1000万)。如果使用MSE作为损失函数,这些1000万的异常值会产生巨大的损失(比如真实价格1000万,模型预测200万,偏差800万,MSE为640000),远大于正常样本的损失(比如真实价格100万,预测120万,MSE为400)。模型为了最小化整体损失,会不断调整参数去拟合这些异常值,导致对正常房屋价格的预测偏差变大------比如原本能精准预测100万房屋的模型,为了贴合1000万的异常值,可能会将100万的房屋预测为150万,反而降低了整体预测精度。
这种场景下,MSE的局限性非常明显:对异常值过于敏感,容易导致模型"跑偏"。此时,我们需要选择对异常值更鲁棒(Robust)的损失函数,比如平均绝对误差(MAE)、Huber损失等。
场景2:回归任务的误差分布不是正态分布
前文提到,MSE的理论基础是"误差服从正态分布",如果实际回归任务中,样本误差的分布不是正态分布(比如服从拉普拉斯分布、柯西分布),那么使用MSE作为损失函数,会导致模型的泛化能力下降------因为MSE的优化目标与数据的真实误差分布不匹配。
比如,拉普拉斯分布的误差具有"重尾特性",即异常值出现的概率比正态分布高,但异常值的偏差不会像正态分布那样极端。此时,MAE(平均绝对误差)比MSE更合适,因为MAE是基于拉普拉斯分布的极大似然估计推导得出的,能更好地贴合误差分布,对异常值的敏感度也更低。
再比如,柯西分布的误差具有"极重尾特性",异常值的偏差极大且出现概率不低,此时MSE和MAE都会受到异常值的严重影响,需要使用对异常值更鲁棒的损失函数,比如Tukey损失(也叫bisquare损失),它会对大偏差进行"截断惩罚",避免异常值主导损失优化。
场景3:回归任务需要"侧重局部优化"
有些回归任务中,我们并不需要模型对所有样本的预测精度一致,而是需要侧重某一部分样本的预测效果------比如"医疗费用预测"中,我们更关注低收入人群的医疗费用预测精度(因为这部分人群对费用更敏感),而对高收入人群的预测偏差可以适当放宽。此时,MSE的"平等惩罚"特性就会显得不合理,因为它对所有样本的偏差都进行同等力度的惩罚,无法满足"局部侧重"的需求。
这种场景下,需要使用"加权损失函数",比如加权MSE(Weighted MSE),给需要侧重的样本分配更高的权重,给无需侧重的样本分配更低的权重,让模型在优化过程中更关注高权重样本的预测精度。例如,给低收入人群样本分配权重2,高收入人群样本分配权重0.5,那么低收入人群的预测偏差会被放大,模型会优先优化这部分样本的预测效果。
场景4:深度学习中的回归任务(需避免梯度爆炸)
在深度学习回归任务中(比如图像分割中的像素值回归、时序预测中的连续值预测),如果使用MSE作为损失函数,当模型输出与真实标签的偏差较大时,会产生较大的梯度,可能导致梯度爆炸,影响模型收敛。
比如,在图像分割任务中,像素值的范围是0-255,若模型预测的像素值为0,而真实像素值为255,偏差为255,MSE为65025,梯度为2*(0-255) = -510,这个梯度值过大,会导致参数更新幅度过大,模型震荡不收敛。此时,需要对MSE进行改进,比如使用归一化MSE(将预测值和真实值归一化到0-1之间),或者使用平滑L1损失(Huber损失的特例),既保留MSE的光滑性,又避免梯度爆炸。
2.2 分类任务中交叉熵的局限性:这些场景下,交叉熵会"失灵"
交叉熵是分类任务的默认选择,但在以下3种场景中,交叉熵的表现会不佳,需要替换为更合适的损失函数。
场景1:类别不平衡(Class Imbalance)
类别不平衡是分类任务中最常见的问题之一,指的是不同类别的样本数量差异极大------比如在"疾病诊断"任务中,患病样本(正类)占比仅1%,正常样本(负类)占比99%;在"欺诈检测"任务中,欺诈样本占比不足0.1%,正常样本占比99.9%。
此时,若使用普通交叉熵作为损失函数,模型会倾向于预测样本数量更多的类别(负类),因为这样能最小化整体损失------比如,模型只要全部预测为负类,就能达到99%的准确率,此时交叉熵损失会非常小,但模型完全无法识别正类(患病、欺诈样本),失去了实际意义。
普通交叉熵的问题在于:它对所有类别的样本都赋予了同等的权重,没有考虑类别数量的差异,导致少数类样本的损失被多数类样本的损失"淹没",模型无法学习到少数类的特征。此时,需要使用"加权交叉熵"(Weighted Cross-Entropy),给少数类样本分配更高的权重,给多数类样本分配更低的权重,让模型在优化过程中重视少数类的预测精度。
比如,在二分类任务中,正类样本占比1%,负类占比99%,可以给正类分配权重99,负类分配权重1,这样就能平衡两类样本的损失贡献,避免模型偏向多数类。除了加权交叉熵,还可以使用Focal Loss(焦点损失),它通过引入"调制系数",降低容易分类样本的权重,聚焦于难分类样本(通常是少数类样本),进一步提升少数类的识别精度。
场景2:分类任务需要"容错性"(允许轻微错误)
有些分类任务中,我们并不要求模型对所有样本都精准分类,而是允许轻微的分类错误------比如"商品分类"任务中,将"衬衫"误分为"T恤",虽然是错误,但影响不大;而将"衬衫"误分为"裤子",影响较大。此时,普通交叉熵的"同等惩罚"特性就会显得不合理,因为它对所有分类错误都进行同等力度的惩罚,无法区分错误的严重程度。
这种场景下,需要使用"有序交叉熵"(Ordinal Cross-Entropy)或"标签平滑"(Label Smoothing)技术。有序交叉熵适用于有序分类任务(比如"好评、中评、差评"的分类),它会根据类别之间的距离,调整惩罚力度------比如将"好评"误分为"中评"的惩罚,小于将"好评"误分为"差评"的惩罚;标签平滑则是将真实标签的独热编码进行轻微调整(比如将1改为0.9,0改为0.1),降低模型对"绝对正确"的追求,提升模型的容错性和泛化能力。
场景3:多标签分类任务(Multi-Label Classification)
普通交叉熵适用于"单标签分类"任务(即每个样本只有一个真实类别),但在多标签分类任务中(即每个样本可以有多个真实类别,比如一张图片中同时包含猫、狗、鸟),普通交叉熵就会失灵------因为多标签分类的真实标签不是独热编码(而是多维度的0-1向量,1表示存在该类别,0表示不存在),模型的输出也不是"概率之和为1"(而是每个类别独立输出概率)。
此时,若使用普通交叉熵(多分类Softmax+交叉熵),会强制模型输出的概率之和为1,导致类别之间相互抑制(比如模型预测"猫"的概率高,就会压低"狗"的概率),不符合多标签分类的需求。正确的选择是使用"二元交叉熵"(Binary Cross-Entropy,BCE),将多标签分类任务拆解为多个独立的二分类任务,每个类别单独计算交叉熵,再求和作为总损失------这样,每个类别的预测概率相互独立,不会相互抑制,能准确捕捉样本的多个类别特征。
2.3 小结:打破刻板认知,核心是"匹配场景"
通过以上分析,我们可以得出一个结论:损失函数的选择,核心不是"回归还是分类",而是"任务目标、数据分布、模型结构"三者的匹配。MSE和交叉熵只是"默认选项",而非"唯一选项"------当场景不匹配时,必须灵活替换为更合适的损失函数,否则会导致模型性能下降,甚至无法达到预期效果。
接下来,我们将系统梳理不同任务场景下的损失函数选择策略,结合具体案例,让大家能快速找到适合自己任务的损失函数。
三、损失函数选择指南:按场景分类,精准匹配需求
为了让大家更清晰地掌握损失函数的选择方法,我们将任务分为"回归任务"和"分类任务"两大类,每类任务下结合具体场景,给出对应的损失函数选择建议、公式、适用场景及注意事项,同时补充一些常用的改进型损失函数,帮助大家应对复杂场景。
3.1 回归任务:从"鲁棒性""误差分布""优化需求"出发
回归任务的核心需求是"预测连续值,最小化预测偏差",损失函数的选择主要围绕三个维度:对异常值的鲁棒性、与误差分布的匹配度、优化过程的稳定性(避免梯度爆炸/消失)。以下是常见场景及对应损失函数:
3.1.1 基础场景:无异常值、误差服从正态分布
适用场景:数据分布均匀,无明显异常值,误差服从正态分布(比如普通的房价预测、气温预测、销售额预测)。
推荐损失函数:均方误差(MSE)
公式:MSE = (1/n)Σ(yᵢ - ŷᵢ)²
优势:数学性质好,可导、凸函数,优化稳定,能有效最小化整体偏差。
注意事项:确保数据无异常值,否则会影响模型泛化能力;若数据范围过大(比如像素值0-255),可先归一化再使用。
3.1.2 场景2:存在异常值、误差服从拉普拉斯分布
适用场景:数据中存在少量异常值,误差服从拉普拉斯分布(比如用户消费金额预测,存在少量高消费异常值;工业数据预测,存在少量设备故障导致的异常值)。
推荐损失函数:平均绝对误差(MAE)、Huber损失
公式:
-
MAE = (1/n)Σ|yᵢ - ŷᵢ|
-
Huber损失 = (1/n)Σ若\|yᵢ - ŷᵢ\| ≤ δ,则 (1/2)(yᵢ - ŷᵢ)²;否则 δ(\|yᵢ - ŷᵢ\| - δ/2)(δ为超参数,通常取1.0)
优势:
MAE:对异常值鲁棒,不受极端偏差的影响,适合误差服从拉普拉斯分布的场景;
Huber损失:结合了MSE和MAE的优势,在偏差较小时(≤δ)使用MSE,保证优化的光滑性;在偏差较大时(>δ)使用MAE,避免异常值的影响,是回归任务中"鲁棒性+光滑性"的最优选择之一。
注意事项:MAE的缺点是在预测值等于真实值时不可导(梯度不连续),可能影响优化速度;Huber损失需要调优超参数δ,可通过交叉验证确定。
3.1.3 场景3:存在极端异常值、误差服从柯西分布
适用场景:数据中存在大量极端异常值,误差服从柯西分布(比如金融风险预测,存在少量极端风险事件导致的异常值;气象预测,存在极端天气导致的异常数据)。
推荐损失函数:Tukey损失(Bisquare损失)、L1-L2混合损失
公式:
-
Tukey损失 = (1/n)Σ若\|yᵢ - ŷᵢ\| ≤ δ,则 (1 - (1 - (\|yᵢ - ŷᵢ\|/δ)²)³);否则 1(δ为超参数)
-
L1-L2混合损失 = α·MSE + (1-α)·MAE(α为权重,0≤α≤1)
优势:
Tukey损失:对极端异常值进行"截断惩罚",当偏差超过δ时,损失不再增长,彻底避免异常值主导优化;
L1-L2混合损失:通过调节α,平衡MSE的光滑性和MAE的鲁棒性,灵活适配不同程度的异常值场景。
注意事项:Tukey损失的超参数δ需要结合数据分布调整;L1-L2混合损失的α需要通过交叉验证确定,α越大,越接近MSE;α越小,越接近MAE。
3.1.4 场景4:需要侧重局部样本(加权需求)
适用场景:回归任务中需要侧重某一部分样本的预测精度(比如医疗费用预测侧重低收入人群、学生成绩预测侧重学困生)。
推荐损失函数:加权MSE、加权MAE
公式:
-
加权MSE = (1/Σwᵢ)Σwᵢ·(yᵢ - ŷᵢ)²(wᵢ为第i个样本的权重)
-
加权MAE = (1/Σwᵢ)Σwᵢ·|yᵢ - ŷᵢ|(wᵢ为第i个样本的权重)
优势:通过权重分配,让模型优先优化高权重样本的预测精度,满足局部侧重需求。
注意事项:权重的分配需要结合业务需求确定,避免权重过高导致模型过拟合高权重样本;可通过业务经验或数据分布确定权重(比如少数重要样本分配高权重)。
3.1.5 场景5:深度学习回归任务(避免梯度爆炸/消失)
适用场景:深度学习中的回归任务(比如图像分割、时序预测、生成模型中的回归分支),需要保证梯度稳定,避免梯度爆炸或消失。
推荐损失函数:归一化MSE、平滑L1损失、Log-Cosh损失
公式:
-
归一化MSE = (1/n)Σ(yᵢ - ŷᵢ)/(max(y) - min(y))²(将真实值和预测值归一化到0-1之间)
-
平滑L1损失 = (1/n)Σ若\|yᵢ - ŷᵢ\| ≤ 1,则 (1/2)(yᵢ - ŷᵢ)²;否则 \|yᵢ - ŷᵢ\| - 1/2(Huber损失的特例,δ=1)
-
Log-Cosh损失 = (1/n)Σlog(cosh(yᵢ - ŷᵢ))
优势:
归一化MSE:缩小预测偏差的范围,避免梯度过大导致爆炸;
平滑L1损失:避免梯度爆炸,同时保证梯度的连续性,适合深度学习的优化;
Log-Cosh损失:具有MSE的光滑性,同时对异常值的鲁棒性优于MSE,梯度计算稳定,不会出现梯度爆炸。
注意事项:归一化MSE需要先对数据进行归一化处理;Log-Cosh损失在偏差较大时,损失增长速度接近MAE,鲁棒性较好。
3.2 分类任务:从"类别分布""任务类型""容错需求"出发
分类任务的核心需求是"预测类别概率,匹配真实类别分布",损失函数的选择主要围绕三个维度:类别分布(是否平衡)、任务类型(单标签/多标签)、容错需求(是否允许轻微错误)。以下是常见场景及对应损失函数:
3.2.1 基础场景:类别平衡、单标签分类
适用场景:各类别样本数量均衡,每个样本只有一个真实类别(比如MNIST手写数字分类、CIFAR-10图像分类)。
推荐损失函数:交叉熵(二分类用BCE,多分类用Softmax+交叉熵)
公式:
-
二分类(BCE):Loss = -y·log(ŷ) + (1-y)·log(1-ŷ)
-
多分类(Softmax+交叉熵):Loss = -Σyᵢ·log(ŷᵢ)
优势:直接量化概率分布的偏差,避免梯度消失,优化稳定,能快速引导模型学习类别特征。
注意事项:多分类任务中,模型输出需经过Softmax激活,确保概率之和为1;二分类任务中,模型输出需经过Sigmoid激活,输出范围在0-1之间。
3.2.2 场景2:类别不平衡、单标签分类
适用场景:各类别样本数量差异极大,每个样本只有一个真实类别(比如疾病诊断、欺诈检测、罕见事件识别)。
推荐损失函数:加权交叉熵、Focal Loss、平衡交叉熵(Balanced Cross-Entropy)
公式:
-
加权二分类交叉熵:Loss = -w₁·y·log(ŷ) + w₂·(1-y)·log(1-ŷ)(w₁为正类权重,w₂为负类权重,通常w₁ = 总样本数/正类样本数,w₂ = 总样本数/负类样本数)
-
Focal Loss(二分类):Loss = -α·(1-ŷ)^γ·y·log(ŷ) - (1-α)·ŷ^γ·(1-y)·log(1-ŷ)(α为类别权重,γ为调制系数,通常α=0.25,γ=2)
-
平衡交叉熵:Loss = -β·y·log(ŷ) + (1-β)·(1-y)·log(1-ŷ)(β = 负类样本数/(正类样本数+负类样本数),平衡两类样本的损失贡献)
优势:
加权交叉熵:通过权重平衡两类样本的损失,避免模型偏向多数类;
Focal Loss:不仅平衡类别权重,还通过(1-ŷ)^γ调制系数,降低容易分类样本的权重,聚焦于难分类样本(少数类),进一步提升少数类识别精度;
平衡交叉熵:自动根据类别数量计算权重,无需手动调参,适合类别不平衡程度动态变化的场景。
注意事项:Focal Loss的超参数α和γ需要通过交叉验证调优;加权交叉熵的权重需要根据类别数量合理分配,避免权重过高导致过拟合。
3.2.3 场景3:多标签分类(每个样本多个类别)
适用场景:每个样本可以有多个真实类别(比如图片多标签分类、文本多标签分类、用户兴趣标签预测)。
推荐损失函数:二元交叉熵(BCE)、多标签交叉熵、Dice Loss
公式:
-
多标签BCE:Loss = (1/n)ΣΣ-yᵢⱼ·log(ŷᵢⱼ) - (1-yᵢⱼ)·log(1-ŷᵢⱼ)(i为样本索引,j为类别索引,yᵢⱼ为第i个样本第j个类别的真实标签,ŷᵢⱼ为对应预测概率)
-
Dice Loss:Loss = 1 - (2·Σyᵢⱼ·ŷᵢⱼ + ε)/(Σyᵢⱼ + Σŷᵢⱼ + ε)(ε为平滑项,避免分母为0)
优势:
多标签BCE:将多标签任务拆解为多个独立二分类任务,每个类别独立预测,互不干扰,适合多标签场景;
Dice Loss:基于IoU(交并比)设计,能有效解决多标签分类中"类别不平衡"和"小目标漏检"问题,对小类别标签更敏感。
注意事项:多标签BCE中,模型输出无需经过Softmax激活,每个类别单独经过Sigmoid激活;Dice Loss适合小目标多标签场景,比如医学图像多病灶检测。
3.2.4 场景4:有序分类(类别具有顺序关系)
适用场景:类别之间具有明确的顺序关系(比如好评、中评、差评;轻度、中度、重度疾病;学生成绩等级A、B、C、D)。
推荐损失函数:有序交叉熵(Ordinal Cross-Entropy)、加权有序交叉熵
公式:
有序交叉熵(以3类别为例:类别0、1、2,顺序为0<1<2):Loss = -y₀·log(ŷ₀) + (y₀+y₁)·log(ŷ₀+ŷ₁) + (y₀+y₁+y₂)·log(ŷ₀+ŷ₁+ŷ₂)(y为独热编码,ŷ为模型预测概率)
优势:考虑了类别之间的顺序关系,对"相邻类别错误"的惩罚小于"非相邻类别错误",更贴合有序分类的实际需求。
注意事项:有序交叉熵需要保证类别顺序的正确性,模型输出需经过Softmax激活;若存在类别不平衡,可结合加权策略,提升少数有序类别的预测精度。
3.2.5 场景5:需要容错性、避免过拟合
适用场景:分类任务中允许轻微的分类错误,或模型存在过拟合风险(比如小样本分类、噪声数据分类)。
推荐损失函数:标签平滑交叉熵(Label Smoothing Cross-Entropy)、L2正则化交叉熵
公式:
-
标签平滑交叉熵:Loss = -Σ(1-ε)·yᵢ·log(ŷᵢ) + (ε/K)·log(ŷᵢ)(ε为平滑系数,通常取0.1;K为类别数量)
-
L2正则化交叉熵:Loss = 交叉熵 + λ·Σw²(λ为正则化系数,w为模型参数)
优势:
标签平滑交叉熵:将真实标签的独热编码进行轻微平滑(比如将1改为1-ε,0改为ε/K),降低模型对"绝对正确"的追求,避免过拟合,提升模型的容错性和泛化能力;
L2正则化交叉熵:在交叉熵的基础上增加参数正则化项,惩罚过大的参数,避免模型过度拟合训练数据。
注意事项:标签平滑的ε需要合理设置,ε过大会导致模型预测精度下降;L2正则化的λ需要通过交叉验证调优,避免λ过大导致模型欠拟合。
3.3 特殊场景:混合任务与自定义损失函数
除了纯回归、纯分类任务,实际场景中还存在"混合任务"(比如回归+分类结合),此时需要结合任务需求,设计自定义损失函数。以下是两个常见的混合任务案例,以及自定义损失函数的设计思路:
案例1:回归+分类混合任务(比如"用户留存预测")
任务需求:预测用户是否会留存(分类任务),同时预测用户的留存时长(回归任务)。
自定义损失函数:Loss = α·分类损失(交叉熵) + (1-α)·回归损失(MSE)(α为权重,0≤α≤1)
设计思路:通过α平衡分类任务和回归任务的重要性,若更关注留存与否(分类),则α取较大值(比如0.7);若更关注留存时长(回归),则α取较小值(比如0.3)。
案例2:带约束的回归任务(比如"预测商品销量,要求预测值不小于0")
任务需求:预测商品销量(连续值),但销量不能为负,若模型预测值为负,需要进行额外惩罚。
自定义损失函数:Loss = (1/n)Σ若ŷᵢ ≥ 0,则 (yᵢ - ŷᵢ)²;否则 (yᵢ - ŷᵢ)² + λ·\|ŷᵢ\|(λ为惩罚系数)
设计思路:在MSE的基础上,对预测值为负的样本增加额外惩罚,强制模型预测值不小于0,贴合业务约束。
自定义损失函数的核心原则:贴合业务需求、量化任务偏差、保证可优化性------即损失函数需能准确衡量模型预测与业务目标的偏差,同时具备可导性(便于梯度下降优化),避免出现梯度爆炸/消失等问题。
四、实操案例:损失函数选择对模型性能的影响
为了让大家更直观地感受"损失函数选择"的重要性,我们结合两个实际案例,对比不同损失函数的效果,验证"场景匹配"的核心原则。
案例1:回归任务(房屋价格预测)------ 异常值对损失函数的影响
数据集:某城市房屋价格数据集,共1000个样本,其中950个样本价格在50万-200万(正常数据),50个样本价格在800万-1000万(异常值),目标是预测房屋价格。
实验设置:使用线性回归模型,分别使用MSE、MAE、Huber损失(δ=1.0)作为损失函数,对比模型的预测精度(MAE值越小,精度越高)。
实验结果:
| 损失函数 | 训练集MAE(万) | 测试集MAE(万) | 是否拟合异常值 |
|---|---|---|---|
| MSE | 12.5 | 45.8 | 是,测试集精度大幅下降 |
| MAE | 15.2 | 18.6 | 否,精度稳定 |
| Huber损失 | 13.8 | 16.3 | 否,精度最优 |
结果分析:
-
使用MSE作为损失函数时,训练集MAE很小(模型拟合了训练数据),但测试集MAE很大------因为模型过度拟合了异常值,导致对正常数据的预测精度下降;
-
使用MAE作为损失函数时,训练集MAE略大,但测试集MAE较小------模型对异常值不敏感,能较好地拟合正常数据,泛化能力较强;
-
使用Huber损失时,训练集和测试集MAE都较小,精度最优------结合了MSE的光滑性和MAE的鲁棒性,既避免了异常值的影响,又保证了模型的优化效率。
结论:回归任务中存在异常值时,Huber损失是最优选择,MAE次之,MSE不适合。
案例2:分类任务(疾病诊断)------ 类别不平衡对损失函数的影响
数据集:某疾病诊断数据集,共10000个样本,其中正类(患病)样本100个(占比1%),负类(正常)样本9900个(占比99%),目标是判断用户是否患病。
实验设置:使用逻辑回归模型,分别使用普通交叉熵、加权交叉熵(正类权重99,负类权重1)、Focal Loss(α=0.25,γ=2)作为损失函数,对比模型的召回率(正类识别率,越高越好)和准确率。
实验结果:
| 损失函数 | 准确率(%) | 正类召回率(%) | 负类召回率(%) |
|---|---|---|---|
| 普通交叉熵 | 98.9 | 12.0 | 99.9 |
| 加权交叉熵 | 92.5 | 78.0 | 92.7 |
| Focal Loss | 93.2 | 85.0 | 93.3 |
结果分析:
-
使用普通交叉熵时,准确率很高(98.9%),但正类召回率极低(12%)------模型全部预测为负类,虽然准确率高,但无法识别患病样本,失去实际意义;
-
使用加权交叉熵时,准确率有所下降,但正类召回率大幅提升(78%)------模型开始关注正类样本,能有效识别患病样本,符合疾病诊断的业务需求;
-
使用Focal Loss时,准确率略高于加权交叉熵,正类召回率达到85%------不仅平衡了类别权重,还聚焦于难分类的正类样本,识别效果最优。
结论:分类任务中存在类别不平衡时,Focal Loss最优,加权交叉熵次之,普通交叉熵不适合。
五、总结:损失函数选择的"艺术",本质是"实事求是"
通过本文的深入分析,我们打破了"回归用MSE,分类用交叉熵"的刻板认知,明白了损失函数的选择从来不是一个"固定公式",而是一门结合任务特性、数据分布、模型结构的艺术。
回顾全文,我们可以总结出损失函数选择的核心原则,也是这门"艺术"的精髓:
-
贴合任务目标:回归任务聚焦"连续值偏差",分类任务聚焦"概率分布偏差",混合任务结合两类目标,自定义损失函数贴合业务约束;
-
匹配数据分布:误差服从正态分布用MSE,拉普拉斯分布用MAE,柯西分布用Tukey损失;类别平衡用普通交叉熵,类别不平衡用加权交叉熵或Focal Loss;
-
保证优化稳定:深度学习任务避免梯度爆炸/消失,优先选择平滑L1、Log-Cosh、归一化MSE等损失函数;确保损失函数可导,便于梯度下降优化;
-
结合业务需求:需要侧重局部样本用加权损失,需要容错性用标签平滑,需要识别小目标用Dice Loss,一切以"解决实际业务问题"为核心。
最后,需要强调的是:没有"最好"的损失函数,只有"最适合"的损失函数。在实际工作中,我们不能机械套用规则,而应先分析任务场景、数据分布和业务需求,再选择合适的损失函数;若效果不佳,可通过交叉验证、超参数调优、自定义损失函数等方式进一步优化,最终让模型达到最佳性能。