我正在开发 DocFlow,它是一个完整的 AI 全栈协同文档平台。该项目融合了多个技术栈,包括基于
Tiptap的富文本编辑器、NestJs后端服务、AI集成功能和实时协作。在开发过程中,我积累了丰富的实战经验,涵盖了Tiptap的深度定制、性能优化和协作功能的实现等核心难点。
如果你对 AI 全栈开发、Tiptap 富文本编辑器定制或 DocFlow 项目的完整技术方案感兴趣,欢迎加我微信 yunmz777 进行私聊咨询,获取详细的技术分享和最佳实践。
如果你对 OpenClaw 也感兴趣,也欢迎添加我微信,我拉你进交流群
Next.js 是最流行的 React 框架,被广泛用来构建现代 Web 应用,自带不少开发者未必会用到的能力。搜索形态正在从传统搜索转向"零点击搜索",背后是 Google AI Overview、ChatGPT 等 AI 搜索产品在推动。这些平台会持续抓取站点,用元数据和内容做索引,结构清晰、易于抓取的内容更容易被引用、出现在 AI 结果里。要想在这场变化里站稳,就需要同时为人和 AI 爬虫优化页面与内容。
下面按最佳实践,从页面和内容两方面说说如何做好 SEO 与 GEO。
1. 用 Metadata API 做 SEO
元数据一直负责告诉外界页面的标题和描述。Next.js 用新的 Metadata API 取代了过去的 Head 组件,可以在服务端组件里声明,由服务端渲染输出,爬虫和社交平台抓取时拿到的就是完整、准确的标题与描述,不会出现空白或占位文案。
在 app/layout.tsx 或单页的 layout.tsx 里导出 metadata 对象即可。下面这段示例覆盖了站点标题模板、默认描述、搜索引擎验证、Open Graph 与 Twitter 卡片、以及规范链接。
typescript
import type { Metadata } from "next";
export const metadata: Metadata = {
title: {
template: "%s",
default:
"Texavor - GEO & Content Optimization Platform for Writers, Marketers & Developers",
},
description:
"Build your AI content workflow. Discover topics across ChatGPT and Perplexity, and generate data-backed briefs.",
verification: {
google: "R53D-JHFSD93JDhjhds_ei99JFADSF", // 示例用占位,替换为你在 Search Console 获得的验证码
},
openGraph: {
title:
"Texavor - GEO & Content Optimization Platform for Writers, Marketers & Developers",
description:
"Build your AI content workflow. Discover topics across ChatGPT and Perplexity, and generate data-backed briefs.",
// images: "/easywriteOpenGraph.png",
},
twitter: {
card: "summary_large_image",
title:
"Texavor - GEO & Content Optimization Platform for Writers, Marketers & Developers",
description:
"Build your AI content workflow. Discover topics across ChatGPT and Perplexity, and generate data-backed briefs.",
// images: "/easywriteOpenGraph.png",
},
alternates: {
canonical: "/",
},
};可以配置的内容包括:title 与 description(当前页的标题和描述)、openGraph(在 Facebook、LinkedIn 等社交平台分享时的预览信息)、twitter(Twitter 卡片类型、图片、标题、描述等)、canonical(规范地址,用于转载或重复内容时指向原始出处,也可以把当前页设为自己的 canonical)、verification(向搜索引擎提交的站长验证标签,会变成 head 里的 meta,可用来在 Google Search Console、Bing Webmaster、Yandex 等平台验证站点)。需要按请求动态生成元数据时,可在同页导出异步函数 generateMetadata,接收 params、searchParams 等参数,返回结构相同的 Metadata 对象即可。
2. 使用服务端渲染(SSR)
爬虫更希望拿到"已经渲染好的"完整 HTML,而不是先看到加载态。用服务端渲染就不会先出一屏 loading,首屏 HTML 里已经包含主要内容,对收录和 AI 抓取都更友好。
Next.js App Router 下有三种常见用法,可按页面特性选一种。
- SSR:每次请求在服务端渲染页面,把带数据的 HTML 直接返回,适合内容经常变的页面(例如带实时数据的仪表盘、个性化推荐)。
- SSG:构建时生成 HTML,之后每次请求都直接返回这份静态页,适合几乎不变的页面,例如法律声明、关于我们、联系我们。
- ISR:在构建时生成并缓存页面,请求时先返回缓存,再通过
revalidate在指定时间后重新生成,适合博客这类更新有节奏的页面。
如下图所示。
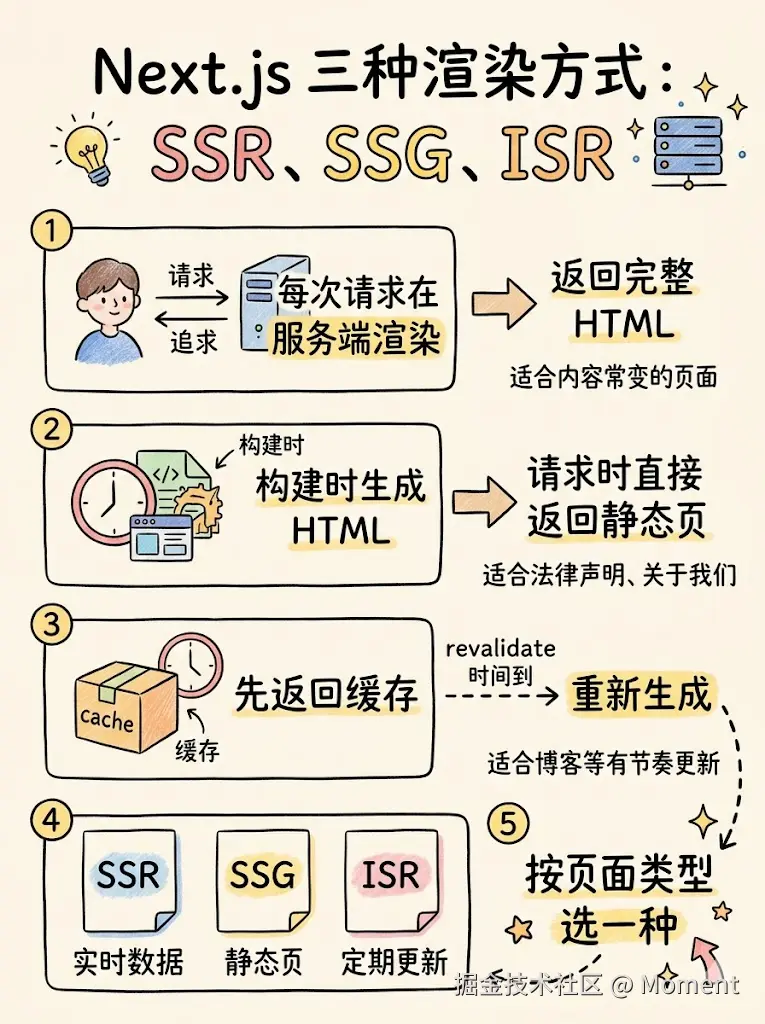
图里把 SSR 每次请求渲染、SSG 构建时生成、ISR 先缓存再按时间重建的差异和适用场景都画出来了。看完可按页面类型选一种。
在页面文件顶部导出 revalidate,即可为该路由开启 ISR。下面的 3600 表示该页最多缓存 1 小时,超过后下次请求会触发重新生成。
typescript
export const revalidate = 3600;除了 SEO,在 Vercel 等平台还能减轻服务器压力、控制成本。静态或 ISR 页面走 CDN,动态请求才回源。
3. 使用结构化数据(Schema 标记)
Schema 标记(结构化数据)是加在页面里的一段代码,用来帮助搜索引擎和问答引擎理解页面含义。它不仅能提升传统搜索表现,对 AI 搜索和 AI 回答的展示也很重要,因此是站点的重要一环。常见有两种形式:JSON-LD(用独立的 script type="application/ld+json" 注入,便于维护和扩展)、Microdata(用 itemscope、itemtype、itemprop 等属性写在 HTML 标签上,可读性和维护性较差)。当前更推荐 JSON-LD。
在页面组件里根据数据构建 JSON-LD 对象,用 dangerouslySetInnerHTML 写入 script 标签。注意把 < 转成 \u003c,避免被解析成 HTML 标签。
typescript
interface Product {
id: string;
name: string;
image: string;
description: string;
}
export default async function Page({ params }: { params: Promise<{ id: string }> }) {
const { id } = await params;
const product = await getProduct(id);
const jsonLd = {
"@context": "https://schema.org",
"@type": "Product",
name: product.name,
image: product.image,
description: product.description,
};
return (
<section>
<script
type="application/ld+json"
dangerouslySetInnerHTML={{
__html: JSON.stringify(jsonLd).replace(/</g, "\u003c"),
}}
/>
{/* 页面其余内容 */}
</section>
);
}Schema 类型可以有很多种。FAQ Schema 适合页面相关常见问题的问答结构。HowTo Schema 适合分步骤教程类页面。Article 与 Author Schema 把内容和作者关联起来,能强化 E-E-A-T(经验、专业、权威、可信)信号,对长文和博客尤其有用。延伸阅读可参考:How to Build Schema Markup for AEO、Common FAQ Schema Mistakes That Hurt Answer Engine Optimization、How to implement JSON-LD in your Next.js application。
4. 优化 Core Web Vitals
Core Web Vitals 是 Google 用来衡量页面体验的指标,主要看加载速度、视觉稳定性和可交互性。常见几个指标是:LCP(Largest Contentful Paint)即最大可见内容(卡片、图片或大段文字)加载完成的时间、CLS(Cumulative Layout Shift)即加载过程中布局发生意外偏移的程度、INP(Interaction to Next Paint)即用户操作(点击、触摸、按键)到页面给出反馈的时间。用 Next.js 的 Image 组件可以自动优化大图,有利于 LCP。
在需要展示图片的组件里引入 next/image,用 src、alt 和 fill(或 width/height)即可。alt 务必填写,对无障碍和图片搜索都有帮助。
tsx
import Image from "next/image";
export function ArticleCover({
image,
title,
}: {
image: string;
title: string;
}) {
return (
<div style={{ position: "relative", width: "100%", aspectRatio: "16/9" }}>
<Image src={image} alt={title} fill />
</div>
);
}使用 next/image 的好处包括:自动压缩图片、懒加载(不可见时不加载,减轻首屏压力)、配合 fill 等属性可适配父容器,方便做响应式布局。在 Vercel 上部署时,next/image 会走 Vercel 的图片优化服务,免费 Hobby 计划每月有 5,000 次优化额度,超出后可能需要升级付费计划。
5. 动态生成 Sitemap
Sitemap 帮助爬虫发现所有可抓取页面,Google Search Console、Bing Webmaster 等都会用它来识别公开页面。在 app 下放一个 sitemap.ts 或 sitemap.js,Next.js 会自动把它当作 sitemap 的路由。这是特殊的 Route Handler,默认会被缓存,除非用了动态 API 或动态配置。
下面示例从 getAllPosts 拉取博客列表,把静态首页、博客索引页和每篇文章的 URL 拼成 sitemap 数组。lastModified、changeFrequency、priority 可按实际更新频率调整。
tsx
import type { MetadataRoute } from "next";
import { getAllPosts } from "@/lib/posts";
interface Post {
slug: string;
updated_at: string;
}
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
const staticPages: MetadataRoute.Sitemap = [
{
url: "https://www.texavor.com",
lastModified: new Date(),
changeFrequency: "daily",
priority: 1.0,
},
{
url: "https://www.texavor.com/blog",
lastModified: new Date(),
changeFrequency: "daily",
priority: 0.8,
},
];
const posts = await getAllPosts();
const postPages: MetadataRoute.Sitemap = posts.map((post: Post) => ({
url: `https://www.texavor.com/blog/${post.slug}`,
lastModified: new Date(post.updated_at),
changeFrequency: "weekly",
priority: 0.8,
}));
return [...staticPages, ...postPages];
}可以把首页、关于我们等静态页和博客等动态页拼在一起,实现整站 sitemap 的动态生成。上线后可在 Search Console 中提交 sitemap URL,便于搜索引擎更快发现新页面。
常见问题
Next.js 对 SEO 的主要好处是什么?
通过 SSR、SSG、ISR 等渲染方式提升首屏 HTML 完整度和加载性能,并内置动态 sitemap、metadata、generateMetadata 等能力,减少手写 head 和 sitemap 的重复劳动。
如何在 Next.js 里做自定义 sitemap?
在 app 下新增 sitemap.ts 或 sitemap.js,默认导出一个返回 MetadataRoute.Sitemap 数组的异步函数即可。如需使用项目根路径以外的 base URL,可在返回的每条记录里写完整绝对 URL。
Next.js 的 Metadata API 对 SEO 有什么帮助?
可以集中配置 title、meta description、canonical、Open Graph、Twitter 卡片、验证标签等,全部由服务端输出,爬虫和社交爬虫拿到的都是最终 HTML,不会因为客户端才注入而漏抓。
为什么结构化数据对 SEO 和 AI 搜索很重要?
JSON-LD 等结构化数据能把"这是一篇教程、作者是谁、步骤有哪些"等信息显式告诉搜索引擎和 ChatGPT 等 AI 问答平台,它们更准确理解页面内容后,更容易在摘要或回答中引用你的页面。
Core Web Vitals 如何影响 Next.js 站点的 SEO?
它们衡量加载速度、视觉稳定性和交互响应。用 next/image、SSR 或 ISR、以及合理的资源加载策略把 Core Web Vitals 做好,既能提升体验,也有利于排名和 AI 抓取时的"可读性"评估。
小结
在 Next.js 里做好 SEO,需要技术实现和内容结构一起抓。Metadata API、SSR 与 SSG 及 ISR、JSON-LD 结构化数据以及基于 Core Web Vitals 的性能优化,都能让应用更容易被搜索到、体验更好,并适应下一代搜索与 AI 检索。建议从元数据与 sitemap 先做齐,再按页面类型选好渲染策略,最后补上结构化数据和图片优化,逐步迭代即可。