视频讲解:
stable diffusion代码:https://github.com/CompVis/stable-diffusion
参考代码:
https://github.com/hkproj/pytorch-stable-diffusion/tree/main
https://github.com/kjsman/stable-diffusion-pytorch
本文汇总了Stable Diffusion相关代码资源与参数说明,并整理了多篇文本生成图像(Text-to-Image)领域的核心论文。代码部分包含官方实现和PyTorch复现版本,重点解析了prompt、uncond_prompt、cfg_scale等关键参数的作用。论文部分系统梳理了GAN-based方法(如AttnGAN、MirrorGAN)、扩散模型(Stable Diffusion)、Transformer架构(VQ-GAN、MaskGIT)三大技术路线,涵盖基础模型(StackGAN)、优化方法(ControlGAN)到评估指标(视觉语义相似性)等研究方向,为文本生成图像领域提供了全面的技术参考。
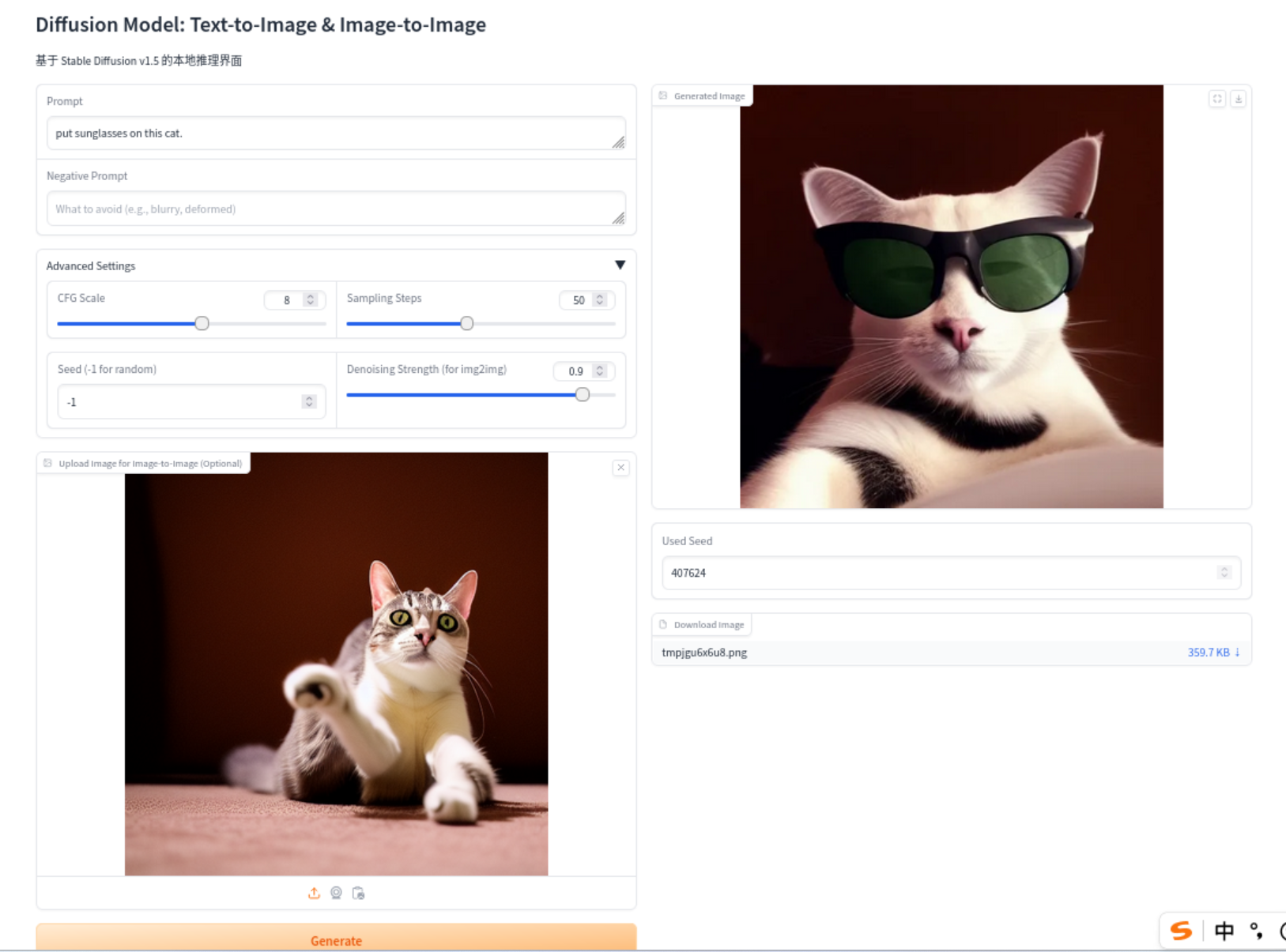
参数解释:理解好以下的参数前提是对文生图有一定的了解,同时对扩散模型以及stable diffusion有一定的了解最好。
prompt - 主文本提示
作用:描述希望生成图像的主要内容或主题
示例:"a beautiful sunset over mountains"
uncond_prompts (List[str], 可选, 默认为[""] * len(prompts))
作用:不用于引导图像生成的文本提示列表。当不启用引导时(即do_cfg为False时)会被忽略
使用场景:提供不希望出现在生成图像中的内容描述
do_cfg (bool, 可选, 默认为True)
作用:启用分类器自由引导
功能:通过对比条件提示和无条件提示来提升生成质量
cfg_scale (float, 可选, 默认为7.5)
作用:分类器自由引导的引导强度。当引导do_cfg被禁用时会被忽略
影响:较高的引导尺度鼓励生成与文本提示紧密相关的图像,但通常以降低图像质量为代价
input_image - 输入图像
类型:图像对象,默认值为None
作用:提供基础图像用于图像编辑、修复等任务
处理流程:图像会被缩放至512×512分辨率,并通过编码器转换为潜在表示
strength - 噪声添加强度
类型:浮点数,默认值为0.8
作用:控制对输入图像的修改程度,取值范围为(0, 1]
数值接近1:添加更多噪声,输出与输入图像差异较大
数值接近0:添加较少噪声,输出与输入图像较为相似
其实这个参数是通过控制去噪的起始位置来控制噪声程度的,
比如strength=1,表示从T位置开始去噪,那么生成的图像随机性也就越大
sampler_name - 采样器选择
类型:字符串,默认值为"ddpm"
作用:指定使用的扩散模型采样器
当前实现仅支持DDPM(Denoising Diffusion Probabilistic Models)
n_inference_steps - 推理步数
类型:整数,默认值为50
作用:控制去噪过程的精细程度
步数越多,生成质量通常越高,但计算时间也越长
seed - 随机种子
类型:整数,默认值为None
作用:控制随机数生成,确保结果可重现
当设置为特定值时,每次运行会生成相同结果
模型与设备参数
tokenizer - 分词器
类型:分词器对象
作用:将文本提示转换为模型可处理的token序列论文GALIP: Generative Adversarial CLIPs for Text-to-Image Synthesis详解(代码详解)
论文Generative Adversarial Text to Image Synthesis详解
论文DF-GAN: ASimple and Effective Baseline for Text-to-Image Synthesis详解
论文StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks详解
论文HDGAN(Photographic Text-to-Image Synthesis with a Hierarchically-nested Adversarial Network)详解
论文AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks详解
论文MirrorGAN: Learning Text-to-image Generation by Redescription详解
基于GAN的文生图(DM-GAN:Dynamic MemoryGenerative Adversarial Networks for Text-to-Image Synthesis)
基于监督对比学习的统一图像生成框架(A Framework For Image Synthesis Using Supervised Contrastive Learning)
基于GAN的文生图算法详解(Text to Image Generation with Semantic-Spatial Aware GAN)
基于GAN的文生图算法详解ControlGAN(Controllable Text-to-Image Generation)
StyleGAN-T文生图算法详解(Unlocking the Power of GANs forFast Large-Scale Text-to-Image Synthe)
论文VQ-GAN(Taming Transformers for High-Resolution Image Synthesis)高分辨图像生成讲解(PyTorch)
论文Neural Discrete Representation Learning(VQ-VAE)详解(PyTorch)
论文VQ-VAE-2(Generating Diverse High-Fidelity Images with VQ-VAE-2)详解(PyTorch)
MaskGIT掩码生成图算法详解(MaskGIT: Masked Generative Image Transformer)
SD-GAN文生图算法详解(Semantics Disentangling for Text-to-Image Generation)