千问(Qwen)视觉语言大模型,特别是最新的 Qwen2.5-VL 系列,提供了强大的零样本(zero-shot)文本提示检测能力,也就是视觉定位(Visual Grounding)。这意味着你无需微调模型,只需通过自然的文本指令,就能让模型识别并定位出图像中指定物体的位置,并以边界框的形式返回结果。以下是基于 Python 实现单张图像文本提示检测的具体方法,主要使用 Hugging Face 的 transformers 库。整个流程可以分为环境准备、加载模型、准备数据、执行推理和解析结果几个部分。
1、环境准备
首先,需要安装必要的 Python 库。
bash
# 安装核心库,建议使用源码安装最新版 transformers 以获得最佳支持
pip install git+https://github.com/huggingface/transformers accelerate
# 安装 Qwen 专用的视觉处理工具
pip install qwen-vl-utils
# 安装 torch (请根据你的 CUDA 版本选择合适的命令)
# pip install torch- 加载模型和处理器
选择你想使用的 Qwen2.5-VL 模型,例如 Qwen/Qwen2.5-VL-7B-Instruct。模型加载时会自动下载权重,请确保网络通畅。python代码如下
python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
# 加载模型,自动分配到可用设备(GPU)
# 可选模型: "Qwen/Qwen2.5-VL-7B-Instruct", "Qwen/Qwen2.5-VL-3B-Instruct" 等
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
torch_dtype=torch.bfloat16, # 使用 bfloat16 精度以节省显存
device_map="auto",
attn_implementation="flash_attention_2", # 如果GPU支持,可加速推理
)
# 加载处理器,并可以设置图像处理的像素范围,以平衡性能和成本 [citation:8]
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-7B-Instruct",
min_pixels=min_pixels,
max_pixels=max_pixels
)执行上面的python语句,提示:'WinError 10060 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。' thrown while requesting HEAD https://huggingface.co/Qwen/Qwen2.5-VL-7B-Instruct/resolve/main/config.json
问题原因:这个错误是因为你的网络环境(很可能在中国大陆)无法正常连接 Hugging Face 的服务器,导致模型文件下载失败。[WinError 10060] 错误是典型的网络连接超时问题。
解决方法:最推荐的方法,通过阿里云的ModelScope平台下载,速度快且稳定。
安装ModelScope:pip install modelscope
3.模型测试
编写python代码如下
python
from modelscope import snapshot_download
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
from qwen_vl_utils import process_vision_info
import torch
import json # 添加这一行
import cv2
import matplotlib.pyplot as plt
import matplotlib.patches as patches
# --- 第一步:设置模型下载目录并下载 ---
# 你可以自定义一个本地路径来存放模型
local_model_path = "D:/YOLO26/ultralytics/QwenVL/local_models/Qwen2.5-VL-7B-Instruct"
# 如果本地还没有模型,就下载;否则直接使用本地路径
import os
if not os.path.exists(local_model_path):
print("正在从ModelScope下载模型,这可能需要一些时间...")
# 注意:ModelScope上的模型名可能和HuggingFace略有不同,请确认
# 常用的Qwen2.5-VL模型在ModelScope上的ID可能是 'qwen/Qwen2.5-VL-7B-Instruct'
model_dir = snapshot_download('qwen/Qwen2.5-VL-7B-Instruct', cache_dir=local_model_path)
# snapshot_download 会下载到 cache_dir 下的特定目录,为了方便,我们直接指定一个最终的加载路径
# 更简单的做法是:直接设置 local_model_path = snapshot_download('qwen/Qwen2.5-VL-7B-Instruct')
# 这样 model_dir 就是模型实际所在的路径
local_model_path = snapshot_download('qwen/Qwen2.5-VL-7B-Instruct')
print(f"模型下载完成,保存在: {local_model_path}")
else:
print("模型已存在,直接从本地加载...")
# 如果之前已经下载过,需要找到确切的快照路径,或者确保 local_model_path 指向包含模型文件的目录
# 为了简化,我们每次都使用 snapshot_download,它会自动处理缓存和路径
local_model_path = "D:/YOLO26/ultralytics/QwenVL/local_models/Qwen2.5-VL-7B-Instruct/qwen/Qwen2.5-VL-7B-Instruct"#snapshot_download('qwen/Qwen2.5-VL-7B-Instruct')
#local_model_path = snapshot_download(local_model_path)# Revised By Lzy 20260309
# --- 第二步:从本地路径加载模型和处理器 ---
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
local_model_path, # 使用下载好的本地路径
torch_dtype=torch.bfloat16,
device_map="auto",
# attn_implementation="flash_attention_2", # 如果你的显卡不支持,可以先注释掉
)
processor = AutoProcessor.from_pretrained(local_model_path) # 同样使用本地路径
# --- 后续的推理代码保持不变 ---
# ... (你的图像路径和提示词)
image_path = "test.jpg"
detection_prompt = "Detect all red cars in the image. Return their locations as bounding box coordinates in JSON format."
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": image_path},
{"type": "text", "text": detection_prompt},
],
}
]
# 准备输入
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
).to(model.device)
# 生成
generated_ids = model.generate(**inputs, max_new_tokens=256)
generated_ids_trimmed = [out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
print("检测结果:", output_text)
# -------------------- 解析 JSON 结果 --------------------
detections = []
try:
# 尝试从输出中提取 JSON 数组(模型可能输出额外的文本,我们只取第一个 [ 到最后一个 ] 之间的内容)
import re
json_match = re.search(r'(\[.*\])', output_text, re.DOTALL)
if json_match:
json_str = json_match.group(1)
detections = json.loads(json_str)
print(f"解析到 {len(detections)} 个检测结果")
else:
print("未在输出中找到 JSON 数组")
except json.JSONDecodeError as e:
print(f"JSON 解析失败: {e}")
# -------------------- 可视化 --------------------
# 加载原始图像(使用 OpenCV 或 PIL)
img = cv2.imread(image_path)
if img is None:
raise FileNotFoundError(f"无法读取图像: {image_path}")
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转换为 RGB 供 matplotlib 使用
height, width, _ = img.shape
# 创建 matplotlib 图像
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.imshow(img_rgb)
# 遍历检测结果,绘制边界框
for det in detections:
bbox = det.get("bbox_2d")
label = det.get("label", "object")
if not bbox or len(bbox) != 4:
continue
# 坐标是从 0-1000 归一化的,需要映射回实际像素
x1 = bbox[0] / 1000.0 * width
y1 = bbox[1] / 1000.0 * height
x2 = bbox[2] / 1000.0 * width
y2 = bbox[3] / 1000.0 * height
w = x2 - x1
h = y2 - y1
# 绘制矩形
rect = patches.Rectangle(
(x1, y1), w, h,
linewidth=2, edgecolor='red', facecolor='none'
)
ax.add_patch(rect)
# 添加标签
ax.text(x1, y1 - 5, label, color='red', fontsize=12,
bbox=dict(facecolor='white', alpha=0.8, edgecolor='none'))
if not detections:
ax.text(0.5, 0.5, "No objects detected", color='blue', fontsize=20,
ha='center', va='center', transform=ax.transAxes)
plt.axis('off')
plt.tight_layout()
plt.show()执行命令如下:
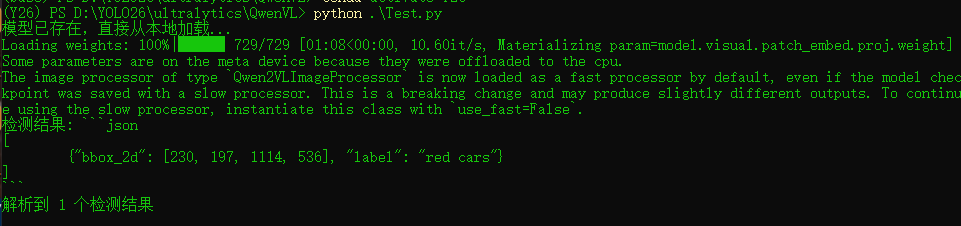
第一执行会自动下载模型下载。
因为检测的文本提示为red cars 所以检测效果如下图所示
