前面我们实现了大语言模型架构,进行了预训练。接下来,我们专注于将大语言模型微调到一个特定的分类任务上,即区分"垃圾消息"和"非垃圾消息"。现在,我们将实现微调大语言模型以遵循人类指令的过程。指令微调是开发用于聊天机器人应用程序、个人助理和其他对话任务的大语言模型的技术之一。
指令微调介绍
我们知道大语言模型的预训练是通过让模型学会逐个生成单词来实现的。预训练后的大语言模型能够进行文本补全 ,这意味着给定任意一个片段作为输入,模型能够生成一个句子或撰写一个段落。然而,预训练后的大语言模型在执行特定指令时往往表现不佳,比如无法完成像 "纠正这段文字的语法"或"将这段话变成被动语态"这样的指令。本章将通过一个具体的例子, 展示如何加载预训练后的大语言模型以进行指令微调 (也被称为有监督指令微调)。
在本章中,我们将专注于提高大语言模型遵循指令并生成合理回复的能力,如下图所示。
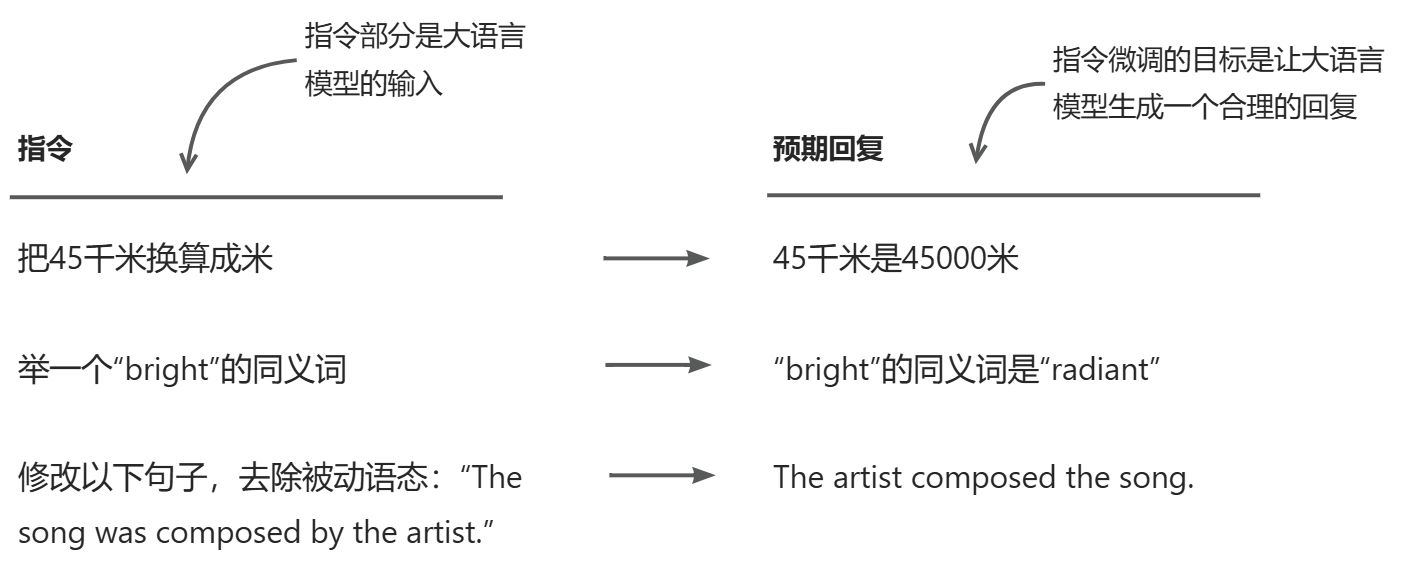
对大语言模型进行指令微调分三阶段。第一阶段涉及准备数据集,第二阶段是模型配置和微调,第三阶段包括模型性能的评估。
我们从第一阶段的第(1)步开始:下载和制作数据集。准备数据集是指令微调的一个关键部分。因此,接下来我们将从准备数据集开始,完成指令微调过程中3个阶段的所有步骤。
为有监督指令微调准备数据集
让我们下载并制作用于指令微调预训练的大语言模型的指令数据集。本章使用的指令数据集包含1100个指令-回复对,类似于上图中的示例。
样本例子:
python
Example entry:
{'instruction': 'Identify the correct spelling of the following word.',
'input': 'Ocassion', 'output': "The correct spelling is 'Occasion.'"}可以发现,示例样本是一个包含'instruction'、'input'和'output'3 个键的 Python 字典对象。
指令微调需要在一个明确提供输入-输出对(如同从 JSON 文件中提取的各个样本)的数据集上训练模型。在获得这些样本后,有多种方法可以将样本制作成适用于大语言模型的格式。
下图展示了两种样本格式,Alpaca 和 Phi-3,这通常也被称为提示词风格 。

大语言模型指令微调中不同提示词风格的比较。Alpaca 风格(左)为指令、输入和回复定义了不同的小节,其采用的是结构化的形式;Phi-3 风格(右)则使用了更简单的形式,主要借助的是特殊词元<|user|>和<|assistant|>。
Alpaca是最早公开详细说明其指令微调过程的大语言模型之一。我们提到微软开发的Phi-3是为了说明提示词风格的多样性。考虑到Alpaca提示词风格很大程度上奠定了指令微调的基础,是最流行的提示词风格之一,本章的其余部分将默认使用 Alpaca 提示词风格。
我们将列表中的样本转换成 Alpaca 风格的输入格式 。带格式的输入就像下面这样:
python
Below is an instruction that describes a task. Write a response that
appropriately completes the request.
### Instruction:
Identify the correct spelling of the following word.
### Input:
Ocassion
### Response:
The correct spelling is 'Occasion.' 在设置 PyTorch 数据集加载器之前,还需要将数据集分为训练集、验证集和测试集。 所用方法与我们在《分类微调大模型》 中处理垃圾消息分类数据集时相似。
在成功下载并划分数据集,且对数据集的提示词进行格式后,我们将专注于构建用于微调大语言模型的训练批次的方法。
将数据组织成训练批次
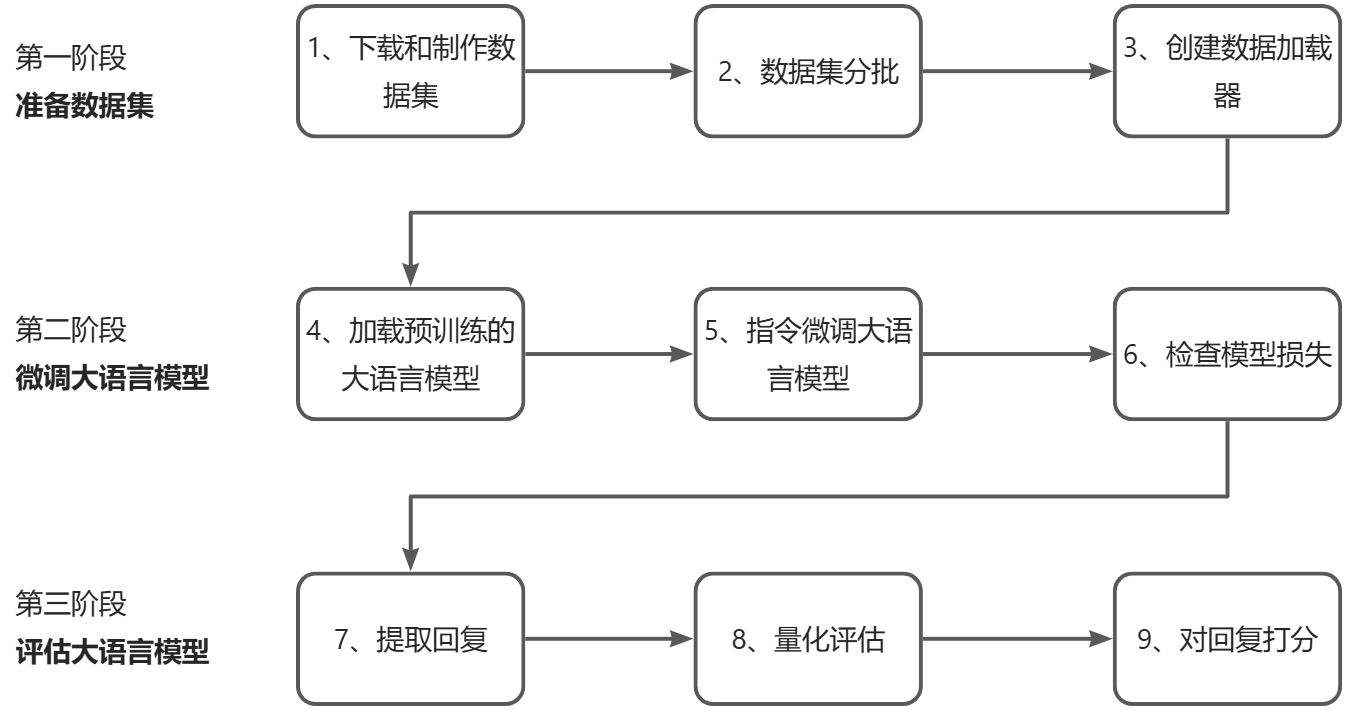
本章是指令微调过程的实现阶段,整体流程如下图所示。接下来,我们将专注于有效构建训练批次。该过程需要定义一种方法,以确保模型在微调期间正确接收经过格式化的训练数据。
在《分类微调大模型》章节中,训练批次是通过 PyTorch 的 DataLoader 类自动创建的,该类使用默认的聚合 (collate)函数将样本列表组合成训练批次。聚合函数的作用是将单个数据样本列表合并为一个批次,以便模型在训练时能够高效地处理。
然而,指令微调的批次处理稍微有些复杂,因为需要创建一个自定义的聚合函数,然后再将其集成到 DataLoader 中。我们将实现这个自定义聚合函数,以满足指令微调数据集的特定需求和格式。
实现批处理过程包括5个步骤:1、应用提示词模板;2、使用前几章提到的词元化方法;3、添加填充词元;4、创建目标词元 ID;5、在损失函数中用-100 占位符词元来掩码填充词元。
首先,完成第(1)步和第(2)步,我们对数据集中所有输入进行预词元化(pretokenize)。

实现批处理过程的前两个步骤:使用特定的提示词模板格式化数据集样本(1);将格式化样本词元化(2),从而生成模型能够处理的词元ID序列。如下图所示。
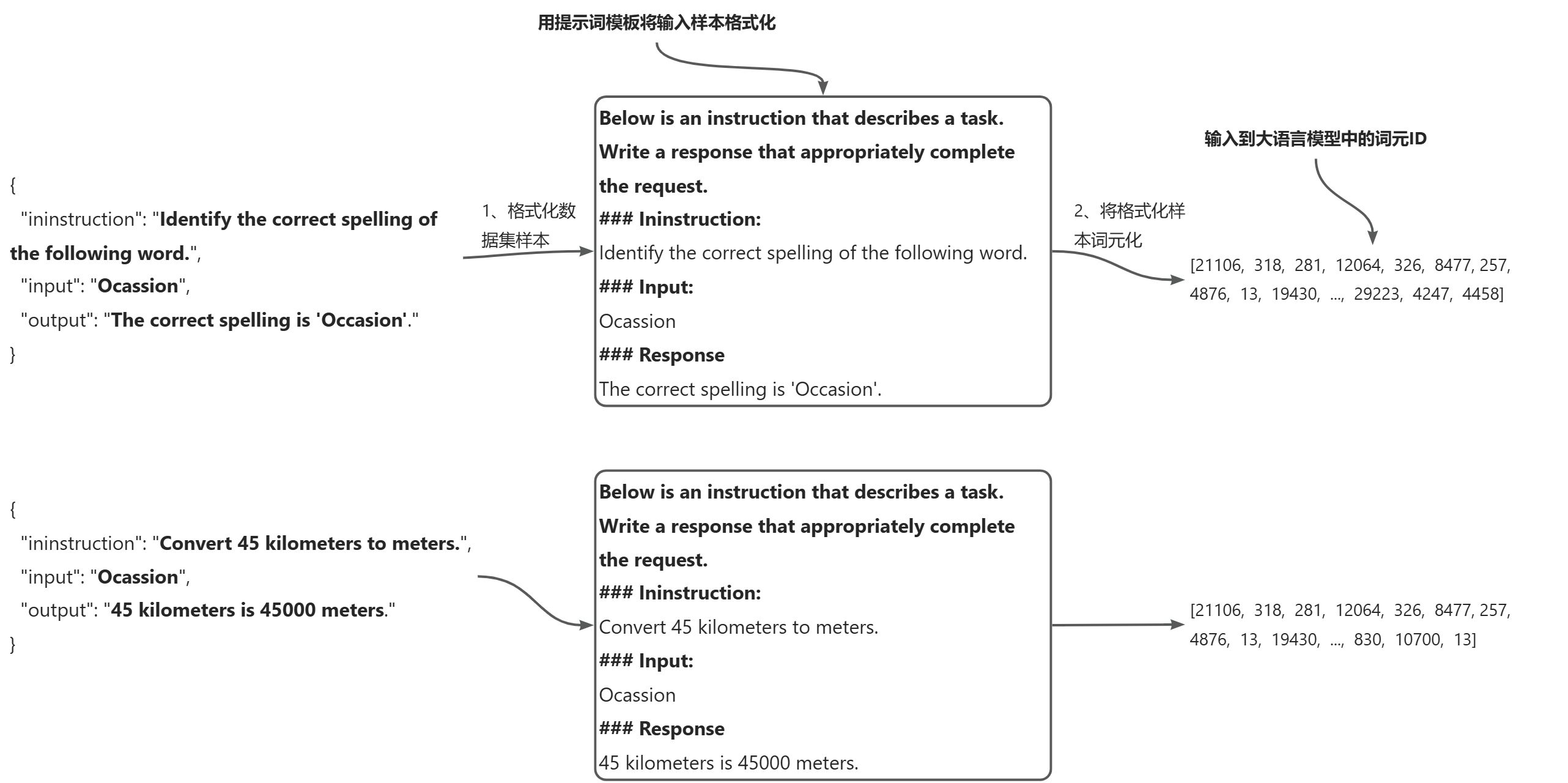
与文本分类微调的方法类似,我们希望通过将多个训练示例聚合到一个批次中来加速训练,这就需要将所有输入填充到相似的长度。同样,我们仍使用<|endoftext|>作为填充词元。
接下来,在第(3)步(参见图2)中,我们将采取更复杂的方法,开发一个自定义聚合函数来传递给数据加载器。该函数可以将每个批次中的训练示例填充到相同长度,同时允许不同批次具有不同长度,如图所示。这种方法通过仅扩展序列以匹配每个批次中最长的序列,从而减少了不必要的填充。

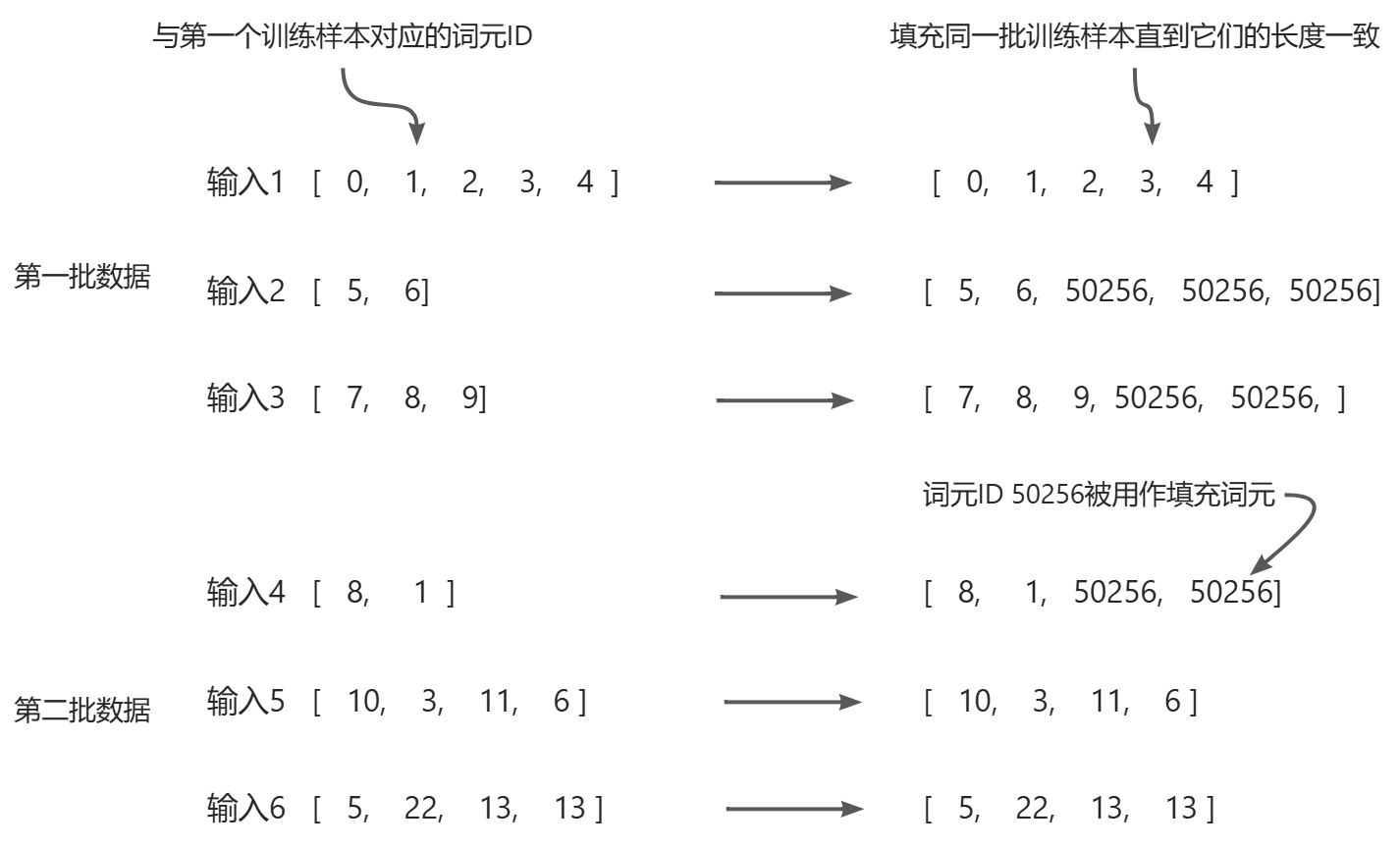
使用词元 ID 50256 对批次中的训练样本进行填充,以确保每个批次的长度一致。但每 个批次的长度可能不同,比如第一批数据就与第二批数据长度不同。
接着,我们还需要生成与输入词元 ID 批次对应的目标词元 ID。这些目标词元 ID非常重要,因为它们代表我们期望模型生成的内容,并且在训练中用来计算损失,以便进行权重更新。
与我们预训练大语言模型时的做法相似,目标词元 ID 与输入词元 ID 相对应,但向左移动了 一个位置。这样的设计(参见下图)使得大语言模型能够学习如何预测序列中的下一个词元。
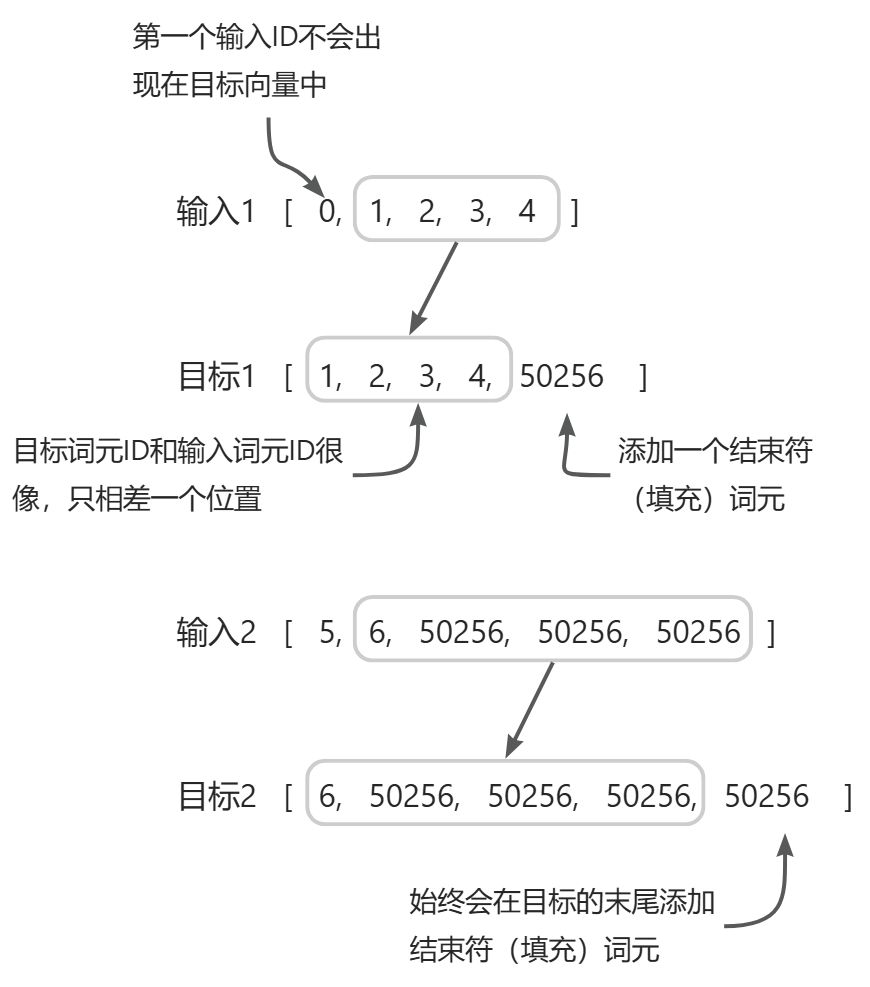
大语言模型指令微调过程中使用的输入词元和目标词元之间的对应关系。对每个输入序列而言,首先将其向左移动一个词元的位置,然后忽略输入序列的第一个词元,最后在尾部加入结束符词元即可得到其对应的目标序列。
在下一步中,我们会为所有填充词元都分配一个-100 占位符值。这个特殊值使我们能够在计算训练损失时排除填充词元的影响,从而确保只有有效的数据会影响模型的学习。(值得说明的是,分类微调时无须担心这个问题,因为我们只根据最后的输出词元对模型进行训练。)
不过,值得注意的是,我们在目标列表中保留了一个结束符词元,ID 为 50256。保留此词元有助于大语言模型学会何时根据指令生成结束符词元,一般我们将其作为生成的回复已经完成的指示符。

实现批处理过程的第(4)步说明了准备训练数据时目标批次的词元替换过程。在这一过程中,我们将每个目标序列中除第一个结束符(填充)词元外的所有结束符(填充) 词元替换为占位符值-100,同时保留第一个结束符(填充)词元。
-100 究竟有什么特别之处,使交叉熵损失能够忽略它呢?原来,在 PyTorch 中,交叉熵函数的默认设置为 cross_entropy(..., ignore_index=-100)。这意味着它会忽略标记 为-100 的目标。我们利用这个 ignore_index 来忽略那些用于填充训练示例以使每个批次具有相同长度的额外结束符(填充)词元。然而,我们需要在目标中保留结束符词元 ID 50256,因为它有助于大语言模型学习生成结束符词元,从而在适当的时候结束回复。
除了掩码填充词元,实践中我们通常还会掩码与指令相关的目标词元,如下图所示。通过掩码与指令对应的目标词元,交叉熵损失可以仅针对生成的回复目标词元进行计算。因此,模型的训练更专注于生成准确的回复,而非记住指令,这样可以帮助减少过拟合。

训练期间,格式化输入文本被词元化并送入大语言模型中(左);大语言模型准备的目标文本,我们可以选择掩码指令部分,即将相应的词元替换为损失的 ignore_index 值-100(右)
截至目前,研究人员对在指令微调过程中是否应掩码指令部分的损失仍存在分歧。
创建指令数据集的数据加载器
到目前为止,我们已经准备好数据集,并实现了一个自定义的聚合函数来对指令数据集进行分批处理。现在,我们可以开始创建训练集、验证集和测试集,并使用数据加载器加载它们来完成大语言模型的指令微 调与评估。
只需将 InstructionDataset 对象和 custom_collate_fn 函数传入 PyTorch 数据加载器即可。在大语言模型的指令微调过程中,这些加载器将自动聚合并随机打乱用于迭代训练的数据。
加载预训练的大语言模型
我们在准备用于指令微调的数据集上投入了大量时间,这是监督微调过程中的关键环节。指令微调的许多其他方面与预训练相似,因此我们可以重用之前章节中的大部分代码。 在开始指令微调之前,需要加载一个你希望进行微调的预训练 GPT 模型,加载过程与我们在前面章节中的操作一致。 需要注意, 较小的模型在学习高质量的指令遵循任务时,缺乏执行该任务所需的复杂模式和细微行为的能力。
未经微调的大语言模型主要用来做文本补全,而将文本补全的输入和输出连接在一起便会形成连贯易读的文本。然而,当评估模型在特定任务上的表现时,我们通常希望仅关注模型生成的回复。
在指令数据上微调大语言模型
是时候对大语言模型进行指令微调了(参见图2)。我们将利用前面加载的预训练模型,并进一步使用本章早期准备的指令数据集对其进行训练。接下来的微调过程可以复用《预训练大模型》章中介绍的损失计算和训练迭代函数。
在准备好模型和数据加载器后,现在可以开始训练模型了。下面代码清单中的代码设置了训练过程,包括初始化优化器、设定训练轮数、定义评估的频率和起始上下文(start_context)。 在这里,起始上下文是指在训练过程中,评估大语言模型在第一个验证集指令 (val_data0)上生成的回复。
python
import time
start_time = time.time()
torch.manual_seed(123)
optimizer = torch.optim.AdamW(
model.parameters(), lr=0.00005, weight_decay=0.1
)
num_epochs = 2
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context=format_input(val_data[0]), tokenizer=tokenizer
)
end_time = time.time()
execution_time_minutes = (end_time - start_time) / 60
print(f"Training completed in {execution_time_minutes:.2f} minutes.") 以下输出展示了模型在两轮内的训练进展,其中损失的持续下降表明其在遵循指令和生成恰当回复方面的能力正在不断提升:
shell
Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626
Ep 1 (Step 000005): Train loss 1.174, Val loss 1.103
Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944
Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906
...
Ep 1 (Step 000115): Train loss 0.520, Val loss 0.665
Below is an instruction that describes a task. Write a response that
appropriately completes the request. ### Instruction: Convert the
active sentence to passive: 'The chef cooks the meal every day.'
### Response: The meal is prepared every day by the chef.<|endoftext|>
The following is an instruction that describes a task.
Write a response that appropriately completes the request.
### Instruction: Convert the active sentence to passive:
Ep 2 (Step 000120): Train loss 0.438, Val loss 0.670
Ep 2 (Step 000125): Train loss 0.453, Val loss 0.685
Ep 2 (Step 000130): Train loss 0.448, Val loss 0.681
Ep 2 (Step 000135): Train loss 0.408, Val loss 0.677
...
Ep 2 (Step 000230): Train loss 0.300, Val loss 0.657
Below is an instruction that describes a task. Write a response
that appropriately completes the request. ### Instruction:
Convert the active sentence to passive: 'The chef cooks the meal
every day.' ### Response: The meal is cooked every day by the
chef.<|endoftext|>The following is an instruction that describes
a task. Write a response that appropriately completes the request.
### Instruction: What is the capital of the United Kingdom
Training completed in 0.87 minutes.训练输出日志表明模型正在快速学习,因为在两轮内训练集和验证集的损失值持续下降,这表明模型逐渐提高了理解和遵循所给指令的能力。(由于模型在两轮内的损失已经降到较低的水平,因此延长训练到第三轮或更多轮并无必要,甚至可能适得其反,导致过拟合加剧。)
此外,每一轮结束时生成的回复让我们能够检查模型在验证集示例中正确执行给定任务的进展。在这个例子中,模型成功地将主动句"The chef cooks the meal every day."转化为了被动句 "The meal is cooked every day by the chef."
从下图的损失图中可以看出,模型在训练集和验证集上的表现随着训练进行得到了显著改善。在初期阶段,损失的快速下降表明模型迅速从数据中捕捉到有意义的模式和特征。随着训练进入第二轮,损失虽然继续下降,但下降的速度有所放缓。这表明模型正在微调已经学习的特征,并逐渐收敛到一种稳定的解决方案。
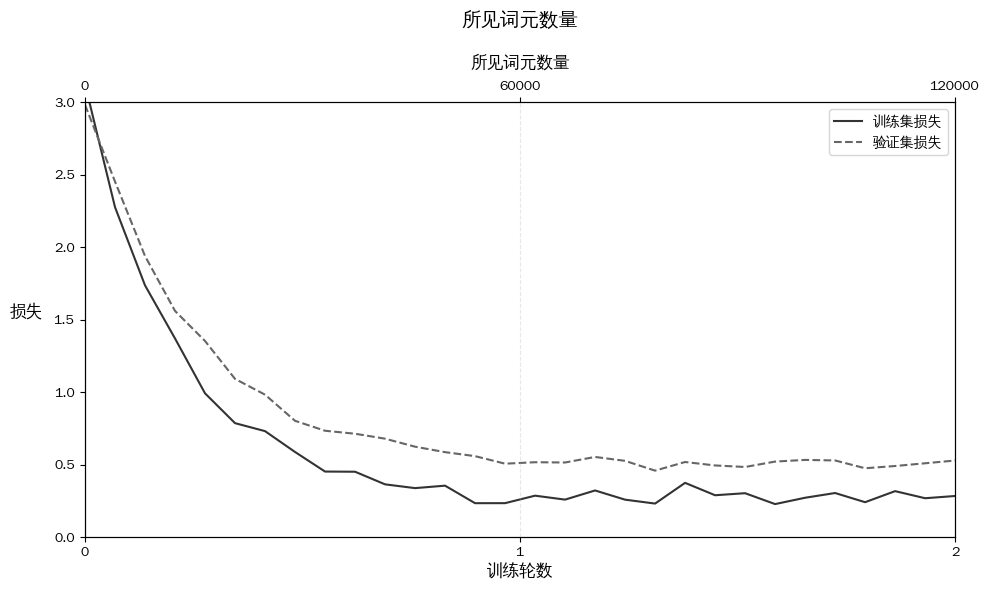
两轮内的训练集损失和验证集损失趋势。实线表示训练集损失呈现出明显的快速下降后趋于稳定的趋势,虚线表示验证集损失也呈现出相似的模式 。
虽然损失图显示出模型正在有效地进行训练,但对模型来说最关键的还是其在回复质量和准确性方面的表现。因此,接下来我们将提取回复,并以一种可以评估和量化质量的格式存储模型的回复。
抽取并保存模型回复
我们已经在指令数据集的训练集上完成了对大语言模型的微调,现在要在模型未见过的测试集上评估模型的性能。首先,提取测试集中每个输入对应的模型生成的回复,并将这些回复收集起来进行人工分析。然后,对大语言模型进行评估以量化模型回复的质量。
模型评估并不像指令微调那样简单。在文本分类时,我们只需通过计算正确的 垃圾消息与非垃圾消息分类标签的比例来获取准确性。然而,在实践中,对指令微调的大语言模型(如聊天机器人)的评估需要多种方法。
- 短答案和多项选择的基准测试,比如"Measuring Massive Multitask Language Understanding" (MMLU),主要考查模型的综合知识。
- 与其他大语言模型进行人类偏好比较,比如 LMSYS 聊天机器人竞技场。
- 使用其他大语言模型(如 GPT-4)来自动评估回复的对话基准,比如 AlpacaEval。
在实际操作中,同时考虑这 3 种评估方法(多项选择问答、人类评估,以及衡量对话性能的 自动化指标)是有必要的。
考虑到当前任务的规模,我们实施一种类似于自动化对话基准的方法,利用另一个 大语言模型来自动评估回复。通过这种方法,我们可以高效地评估生成的回复质量,而不需要大 量人力参与,从而节省时间和资源,同时仍能获得有意义的性能指标。
我们要采用的是一种受 AlpacaEval 启发的方法,使用另一个大语言模型来评估微调后的模型的回复。然而,与依赖公开的基准数据集不同,我们将使用自定义的测试集。这种定制化使我们 能够在预期的用例背景下对模型性能进行更有针对性和相关性的评估。这些用例在我们的指令数据集中有所体现。
评估微调后的大语言模型
之前,我们通过查看指令微调模型在测试集的 3 个样本上的回复来评估其性能。虽然这种方法能大致了解模型的表现,但在处理大量回复时并不适用。因此,我们利用另一个更强大的模型自动评估微调后的大语言模型的回复。
为实现自动化的测试集响应评估,我们使用由 Meta AI 开发的现有的经过指令微调后参数量为 80 亿的 Llama3 模型。
为了进一步提升模型的性能,也可以探索以下策略
- 在微调过程中调整超参数,比如学习率、批次大小或训练轮数;
- 增加训练数据集的规模 或多样化的示例,以涵盖更广泛的话题和风格;
- 尝试不同的提示词或指令格式,以更有效地引导模型的回复;
- 使用更大的预训练模型,以便更好地捕捉复杂模式并生成更准确的回复。
其他
对话性能
大语言模型的对话性能是指它们在理解上下文、细微差别和意图的基础上,进行类似人类沟通的能力。这种性能涵盖了多项技能,包括提供相关且连贯的回答、保持一致性,以及能够适应不同的主题和交流风格。
Ollama
Ollama 是一款高效的应用程序,专为在笔记本电脑上运行大语言模型而设计。作为开源 llama.cpp 库的包装器,它旨在用纯 C/C++实现大语言模型,以最大限度提高效率。不过,Ollama 仅用于生成文本(推理),不支持大语言模型的训练或微调。
参考
《从零构建大模型》