数据结构------trie(字典)树
- [字典 (trie) 树](#字典 (trie) 树)
-
- 字典树的实现
- [P8306 【模板】字典树 - 洛谷](#P8306 【模板】字典树 - 洛谷)
- [P2580 于是他错误的点名开始了 - 洛谷](#P2580 于是他错误的点名开始了 - 洛谷)
- [P10471 最大异或对 - 洛谷 01-Trie](#P10471 最大异或对 - 洛谷 01-Trie)
- OJ汇总
字典 (trie) 树
Trie 树又叫字典树或前缀树,是一种能够快速插入和查询字符串的数据结构。它利用字符串的公共前缀,将字符串组织成一棵树形结构,从而大大提高了存储以及查找效率。
各个编程语言都有提供红黑树和哈希表,都能做到字符串插入和查询。学习字典树肯定是学习红黑树和哈希表做不到的事。
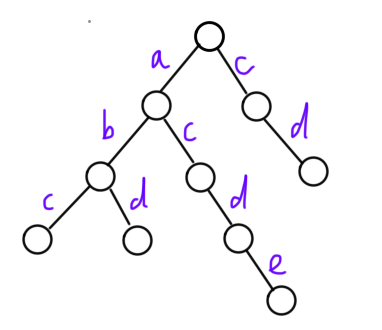
我们可以把字典树想象成一棵多叉树 ,每一条边代表一个字符 ,从根节点到某个节点的路径就代表了一个字符串 。通过字典树存储字符串可以节省存储字符串的空间。例如,要存储 "abc"、"abd"、"acde" 以及 "cd" 时,构建的字典树如下:
在字典树的每一个结点位置,额外维护一些信息时,就可以做到很多事情:
-
查询某个单词是否出现过,并且出现几次。
但若是查找前缀例如
"ac"的话,会出现可以查到,实际字符串并不存在的情况,存储"ac"同样麻烦。所以每个结点需要创建一个
pass和end变量,pass标记当前节点一共经过了多少次,end表示当前节点是多少个字符串的结尾。 -
查询有多少个单词是以某个字符串为前缀。
-
查询所有以某个前缀开头的单词。例如输入法中,输入拼音的时候,可以提示可能的单词。
字典树的功能有很多,这里列举了最常用的 3 种操作。
字典树的实现
实现一个能够查询单词出现次数 以及查询有多少个单词是以某个字符串为前缀的字典树,默认会是小写字母。
准备工作:
cpp
using vi = vector<int>;
struct DictTreeNode { // 描述字典树的边和结点信息
using cvi = const vi;
using ci = const int;
vi tree;
int pss; // 当前节点一共经过了多少次
int ed; // 当前节点是多少个字符串的结尾
DictTreeNode(cvi &_tree = vi(128, 0), int _pss = 0, int _ed = 0) {
tree = _tree;
pss = _pss;
ed = _ed;
}
int &operator[](ci &aim) { // 字典树支持下标访问
return tree[aim];
}
ci &operator[](ci &aim) const { // 字典树支持下标访问
return tree[aim];
}
};这里 tree[i] 表示 i 号结点的孩子信息, tree[i][1] 表示 b 的路径信息,tree[i].pss 表示 有多少个字符串经过 i 号结点, tree[i].ed 表示多少个字符串以 tree[i] 结尾。
其余模板见洛谷的 P8306 字典树模板题。
P8306 【模板】字典树 - 洛谷
字典树模板题,要求是能查找前缀。这是一个内存限制为 1 GB 的OJ,可以使用 128 个空位表示所有字符,然后利用整个字符的 ASCII 码进行查询。但字符串只包含大小写字母和数字,可以剔除前47个字符,节省内存。
这里为了字典树的完整性,就不节省内存了,只要内存足够,可适用绝大多数场景。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
struct DictTreeNode { // 描述字典树的边和结点信息
using cvi = const vi;
using ci = const int;
vi tree;
int pss; // 当前节点一共经过了多少次
int ed; // 当前节点是多少个字符串的结尾
DictTreeNode(cvi &_tree = vi(128, 0), int _pss = 0, int _ed = 0) {
tree = _tree;
pss = _pss;
ed = _ed;
}
int &operator[](ci &aim) { // 字典树支持下标访问
return tree[aim];
}
ci &operator[](ci &aim) const { // 字典树支持下标访问
return tree[aim];
}
};
struct dict_tree {
using Dtn = DictTreeNode;
using Vdtn = vector<Dtn>;
using cst = const string;
Vdtn dt; // 字典树本体
dict_tree(cst &st = "") {
insert(st);
}
void insert(cst &st) {
if (dt.empty())
dt.push_back(Dtn());
int cur = 0;
dt[cur].pss++;
for (size_t i = 0; i < st.size(); i++) {
int path = st[i] - '\0';
if (dt[cur][path] == 0) {
dt[cur][path] = dt.size();
dt.push_back(Dtn());
}
cur = dt[cur][path];
dt[cur].pss++;
}
dt[cur].ed++;
}
int find(cst &st) const {
int cur = 0;
for (size_t i = 0; i < st.size(); i++) {
if (dt[cur][st[i] - '\0'] == 0)
return 0;
cur = dt[cur][st[i] - '\0'];
if (cur >= dt.size())
return 0;
}
return dt[cur].ed;
}
int find_pre(cst &st) const {
int cur = 0;
for (size_t i = 0; i < st.size(); i++) {
if (dt[cur][st[i] - '\0'] == 0)
return 0;
cur = dt[cur][st[i] - '\0'];
if (cur >= dt.size())
return 0;
}
return dt[cur].pss;
}
};
void ac() {
int n, q;
dict_tree dt;
string st;
cin >> n >> q;
for (int i = 0; i < n; i++) {
cin >> st;
dt.insert(st);
}
for (int i = 0; i < q; i++) {
cin >> st;
cout << dt.find_pre(st) << '\n';
}
}
int main() {
int T = 1;
cin >> T;
while (T--)
ac();
return 0;
}P2580 于是他错误的点名开始了 - 洛谷
这里要求查询加查重。可以修改字典树的实现,让字典树在查询时也能做到顺便插入一个字符串进去,减少标记重复的成本。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
struct DictTreeNode { // 描述字典树的边和结点信息
using cvi = const vi;
using ci = const int;
vi tree;
int pss; // 当前节点一共经过了多少次
int ed; // 当前节点是多少个字符串的结尾
DictTreeNode(cvi &_tree = vi(26, 0), int _pss = 0, int _ed = 0) {
tree = _tree;
pss = _pss;
ed = _ed;
}
int &operator[](ci &aim) { // 字典树支持下标访问
return tree[aim];
}
};
struct dict_tree {
using Dtn = DictTreeNode;
using Vdtn = vector<Dtn>;
using cst = const string;
Vdtn dt; // 字典树本体
dict_tree(cst &st = "") {
insert(st);
}
void insert(cst &st) {
if (dt.empty())
dt.push_back(Dtn());
int cur = 0;
dt[cur].pss++;
for (size_t i = 0; i < st.size(); i++) {
int path = st[i] - 'a';
if (dt[cur][path] == 0) {
dt[cur][path] = dt.size();
dt.push_back(Dtn());
}
cur = dt[cur][path];
dt[cur].pss++;
}
dt[cur].ed++;
}
int find(cst &st) {
int cur = 0;
for (size_t i = 0; i < st.size(); i++) {
if (dt[cur][st[i] - 'a'] == 0)
return 0;
cur = dt[cur][st[i] - 'a'];
if (cur >= dt.size())
return 0;
}
return dt[cur].ed++; // 每查到一个字符串就插入一个
}
};
int main() {
int n, q;
dict_tree dt;
string st;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> st;
dt.insert(st);
}
cin >> q;
for (int i = 0; i < q; i++) {
cin >> st;
int ans = dt.find(st);
if (ans == 0)
cout << "WRONG\n";
else if (ans == 1) {
cout << "OK\n";
} else
cout << "REPEAT\n";
}
return 0;
}P10471 最大异或对 - 洛谷 01-Trie
P10471 最大异或对 The XOR Largest Pair - 洛谷
1472:【例题2】The XOR Largest Pair
有的资料对字典树分的特别细,例如这里的字典树叫 01-Trie 。
肯定不能两个循环去枚举,必定超时。
将每个数的二进制01序列存储在字典树中,然后进行贪心策略:从高到低找,对每个bit位,在所有存在的数中,尽可能去找和当前比特位不同的。然后根据查找的情况通过二进制操作将异或的结果更新 bit 位。这个算法的时间复杂度是 O ( n log n ) \text{O}(n\log n) O(nlogn) ,系数 32 可忽略。
P10471 最大异或对 The XOR Largest Pair - 洛谷 参考程序如下。1472:【例题2】The XOR Largest Pair 因为题目给的运行内存只有 64 MB ,而 vector 和结构体因为对齐等原因,浪费很多内存,使得这个代码无法过。
cpp
#include <bits/stdc++.h>
using namespace std;
using vi = vector<int>;
struct DictTreeNode { // 描述字典树的边和结点信息
using cvi = const vi;
using ci = const int;
vi tree;
int pss; // 当前节点一共经过了多少次
int ed; // 当前节点是多少个字符串的结尾
DictTreeNode(cvi &_tree = vi(2, 0), int _pss = 0, int _ed = 0) {
tree = _tree;
pss = _pss;
ed = _ed;
}
int &operator[](ci &aim) { // 字典树支持下标访问
return tree[aim];
}
ci &operator[](ci &aim) const { // 字典树支持下标访问
return tree[aim];
}
};
struct dict_tree {
using Dtn = DictTreeNode;
using Vdtn = vector<Dtn>;
using cst = const string;
Vdtn dt; // 字典树本体
dict_tree() {}
void insert(int num) {
if (dt.empty())
dt.push_back(Dtn());
int cur = 0;
dt[cur].pss++;
for (int i = 31; i >= 0; i--) {
int path = (num >> i) & 1;
if (dt[cur][path] == 0) {
dt[cur][path] = dt.size();
dt.push_back(Dtn());
}
cur = dt[cur][path];
dt[cur].pss++;
}
dt[cur].ed++;
}
int find(int num) const {
int cur = 0;
int ans = 0;
// 贪心策略:对每个bit位,在存在的数中,尽可能去找和当前比特位不同的
for (int i = 31; i >= 0; i--) { // 从第32位开始枚举
if (dt[cur][((num >> i) & 1) ^ 1] == 0) // 找不到就继续往下
cur = dt[cur][((num >> i) & 1)];
else {
ans |= (1 << i); // num的异或值
cur = dt[cur][((num >> i) & 1) ^ 1];
}
}
return ans;
}
};
string calc(int x) { // 转换成二进制01序列
string st;
for (int i = 31; i >= 0; i--) {
st += char(((x >> i) & 1) + '0');
}
return st;
}
int main() {
int n, ans = 0;
vi num;
dict_tree dt;
cin >> n;
num.resize(n + 1, 0);
for (int i = 1; i <= n; i++) {
cin >> num[i];
dt.insert(num[i]);
}
for (int i = 1; i <= n; i++) {
ans = max(ans, dt.find(num[i]));
}
cout << ans;
return 0;
}1472:【例题2】The XOR Largest Pair 建议是按照 C 语言的方式模拟实现,但字典树的核心插入、查找等逻辑保持不变。
cpp
#include <bits/stdc++.h>
using namespace std;
const int N = 1e7 + 1000;
int tree[N][2], pss[N], ed[N], num[N / 100];
int idx, n, ans;
void insert(int x) {
int cur = 0;
for (int i = 31; i >= 0; i--) {
int path = (x >> i) & 1;
if (tree[cur][path] == 0)
tree[cur][path] = ++idx;
cur = tree[cur][path];
}
}
int find(int x) {
int cur = 0;
int ans = 0;
for (int i = 31; i >= 0; i--) {
int path = (x >> i) & 1;
if (tree[cur][path ^ 1] == 0)
cur = tree[cur][path];
else {
ans |= (1 << i);
cur = tree[cur][path ^ 1];
}
}
return ans;
}
int main() {
cin >> n;
for (int i = 1; i <= n; i++) {
cin >> num[i];
insert(num[i]);
}
for (int i = 1; i <= n; i++)
ans = max(ans, find(num[i]));
cout << ans;
return 0;
}