作为一款"分布式多模数据库",KWDB 最擅长的领域之一就是 工业物联网 (IIoT) 。
这一次,咱们直接模拟一个真实的制造业车间场景,带大家从数据建模、模拟采集到实时监控,完整走一遍"设备健康监测系统"的搭建流程。
目标:通过 KWDB 实现对 100 台数控机床(CNC)的实时状态监控、故障预警和效率分析。

文章目录
-
- [1. 场景痛点与架构设计](#1. 场景痛点与架构设计)
-
- [1.1 为什么传统数据库搞不定?](#1.1 为什么传统数据库搞不定?)
- [1.2 KWDB 的"多模"优势](#1.2 KWDB 的“多模”优势)
- [1.3 系统架构图](#1.3 系统架构图)
- [2. 核心建模:关系与时序的融合](#2. 核心建模:关系与时序的融合)
-
- [2.1 创建数据库](#2.1 创建数据库)
- [2.2 第一张表:设备台账表 (Relational Table)](#2.2 第一张表:设备台账表 (Relational Table))
- [2.3 第二张表:传感器监测表 (Time-Series Table)](#2.3 第二张表:传感器监测表 (Time-Series Table))
- [3. 模拟实战:车间设备跑起来!](#3. 模拟实战:车间设备跑起来!)
-
- [3.1 数据模拟脚本 `mock_factory.py`](#3.1 数据模拟脚本
mock_factory.py) - [3.2 执行导入](#3.2 执行导入)
- [3.1 数据模拟脚本 `mock_factory.py`](#3.1 数据模拟脚本
- [4. 业务实战:能解决什么问题?](#4. 业务实战:能解决什么问题?)
- [5. 进阶:如何让系统更稳?(避坑指南)](#5. 进阶:如何让系统更稳?(避坑指南))
-
- [5.1 坑 1:数据有效期 (TTL) 管理](#5.1 坑 1:数据有效期 (TTL) 管理)
- [5.2 坑 2:写入频率过高导致的 IO 瓶颈](#5.2 坑 2:写入频率过高导致的 IO 瓶颈)
- [5.3 坑 3:Tag 设计误区](#5.3 坑 3:Tag 设计误区)
- [6. 总结](#6. 总结)
1. 场景痛点与架构设计
1.1 为什么传统数据库搞不定?

1.2 KWDB 的"多模"优势
KWDB 支持在同一个实例中同时存储关系数据和时序数据 ,并且支持跨模查询(SQL JOIN)。这就是我们选择它的核心理由。
1.3 系统架构图
MQTT/Modbus
Batch Insert
SQL Query
SQL Query
KWDB核心能力
内部高速总线
关系引擎: 存设备台账
时序引擎: 存传感器流
工业现场: PLC/传感器
边缘网关/采集程序
KWDB 3.1.0
实时监控大屏-Grafana/BI
MES/ERP 业务系统
2. 核心建模:关系与时序的融合
首先,我们需要在 KWDB 中把"车间"搬进去。
2.1 创建数据库
连接数据库(使用我们之前配置好的环境):
bash
# 还是熟悉的配方,使用 TLS 连接
sudo /usr/local/kaiwudb/bin/kwbase sql \
--certs-dir=/etc/kaiwudb/certs \
--host=127.0.0.1:26257创建业务库:
sql
CREATE DATABASE IF NOT EXISTS smart_factory;
USE smart_factory;
2.2 第一张表:设备台账表 (Relational Table)
这是一张标准的关系表,用来存储设备的静态信息。
sql
CREATE TABLE device_meta (
device_id INT PRIMARY KEY, -- 设备唯一ID
model_name VARCHAR(50), -- 设备型号 (如 CNC-2000)
location VARCHAR(20), -- 车间位置 (如 Workshop-A)
install_date DATE, -- 安装日期
status VARCHAR(20) -- 当前状态 (Active/Maintenance)
);
-- 插入一些模拟的基础数据 (100台设备)
INSERT INTO device_meta (device_id, model_name, location, install_date, status)
VALUES
(1, 'CNC-2000', 'Workshop-A', '2023-01-15', 'Active'),
(2, 'CNC-2000', 'Workshop-A', '2023-01-20', 'Active'),
(3, 'CNC-3000', 'Workshop-B', '2023-02-10', 'Maintenance');
-- (实际场景中这里会有成百上千条记录)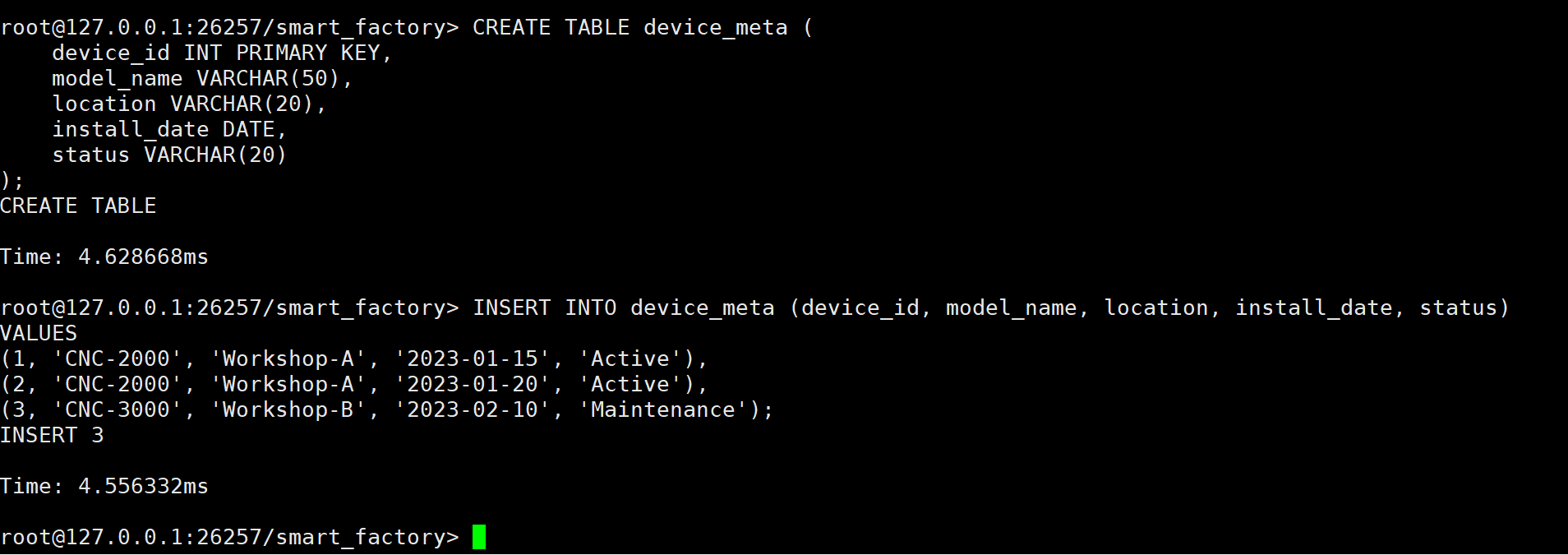
2.3 第二张表:传感器监测表 (Time-Series Table)
这是一张时序表,用来存储高频采集的实时数据。
注意 KWDB 的时序表设计规范:时间戳 + 标签 (Tags) + 指标 (Metrics)。
sql
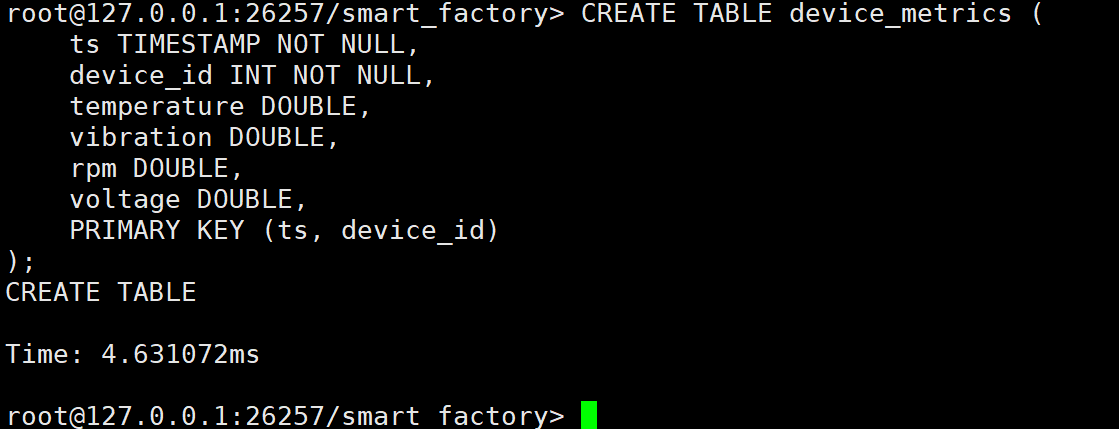
CREATE TABLE device_metrics (
ts TIMESTAMP NOT NULL, -- 时间戳 (必须是第一主键)
device_id INT NOT NULL, -- 设备ID (在时序表中,主键中非第一列的字段默认即为 Tag)
temperature DOUBLE, -- 温度 (Metric)
vibration DOUBLE, -- 振动幅值 (Metric)
rpm DOUBLE, -- 转速 (Metric)
voltage DOUBLE, -- 电压 (Metric)
PRIMARY KEY (ts, device_id) -- 复合主键
);
划重点 :
KWDB 的时序模型设计非常巧妙:主键定义决定了 Tag。
- 主键的第一列 必须是时间戳 (
ts)。 - 主键的后续列 (这里是
device_id)会自动被识别为 Tag。 - 其他未包含在主键中的列(temperature, vibration...)则是 Metric(指标)。
这种隐式定义方式既符合 SQL 标准,又简化了语法,不需要额外的 TAGS 关键字。
3. 模拟实战:车间设备跑起来!
为了模拟真实场景,我们写一个 Python 脚本,模拟 10 台设备每秒上报数据的过程。
3.1 数据模拟脚本 mock_factory.py
在服务器上创建 mock_factory.py:
python
import random
from datetime import datetime, timedelta
# 配置:模拟 10 台设备,生成过去 1 小时的数据(每秒 1 条)
DEVICE_COUNT = 10
DURATION_MINUTES = 60
START_TIME = datetime.now() - timedelta(minutes=DURATION_MINUTES)
FILENAME = "factory_data.sql"
print(f"正在生成 {DEVICE_COUNT} 台设备,时长 {DURATION_MINUTES} 分钟的模拟数据...")
with open(FILENAME, "w") as f:
f.write("USE smart_factory;\n")
f.write("INSERT INTO device_metrics (ts, device_id, temperature, vibration, rpm, voltage) VALUES\n")
batch_count = 0
total_records = DEVICE_COUNT * DURATION_MINUTES * 60
for m in range(DURATION_MINUTES * 60): # 每一秒
current_ts = (START_TIME + timedelta(seconds=m)).strftime("'%Y-%m-%d %H:%M:%S'")
for d in range(1, DEVICE_COUNT + 1): # 每一台设备
# 模拟数据波动:
# 温度:正常 40-60,偶尔飙高到 80+ (模拟故障)
temp = round(random.uniform(40, 60), 2)
if random.random() < 0.01: temp += 30 # 1% 概率过热
# 振动:正常 0-2mm/s
vib = round(random.uniform(0, 2.0), 2)
# 转速:运行中 2000-3000
rpm = random.randint(2000, 3000)
# 电压:稳定在 220V 上下
volt = round(random.uniform(215, 225), 1)
line = f"({current_ts}, {d}, {temp}, {vib}, {rpm}, {volt})"
batch_count += 1
# 每 1000 条切分一个 INSERT 语句,避免 SQL 过长
if batch_count % 1000 == 0:
f.write(f"{line};\n")
if batch_count < total_records:
f.write("INSERT INTO device_metrics (ts, device_id, temperature, vibration, rpm, voltage) VALUES\n")
else:
if batch_count == total_records:
f.write(f"{line};\n")
else:
f.write(f"{line},\n")
print(f"数据生成完毕!总记录数: {total_records}")
print(f"请运行: time sudo /usr/local/kaiwudb/bin/kwbase sql --certs-dir=/etc/kaiwudb/certs --host=127.0.0.1:26257 < {FILENAME}")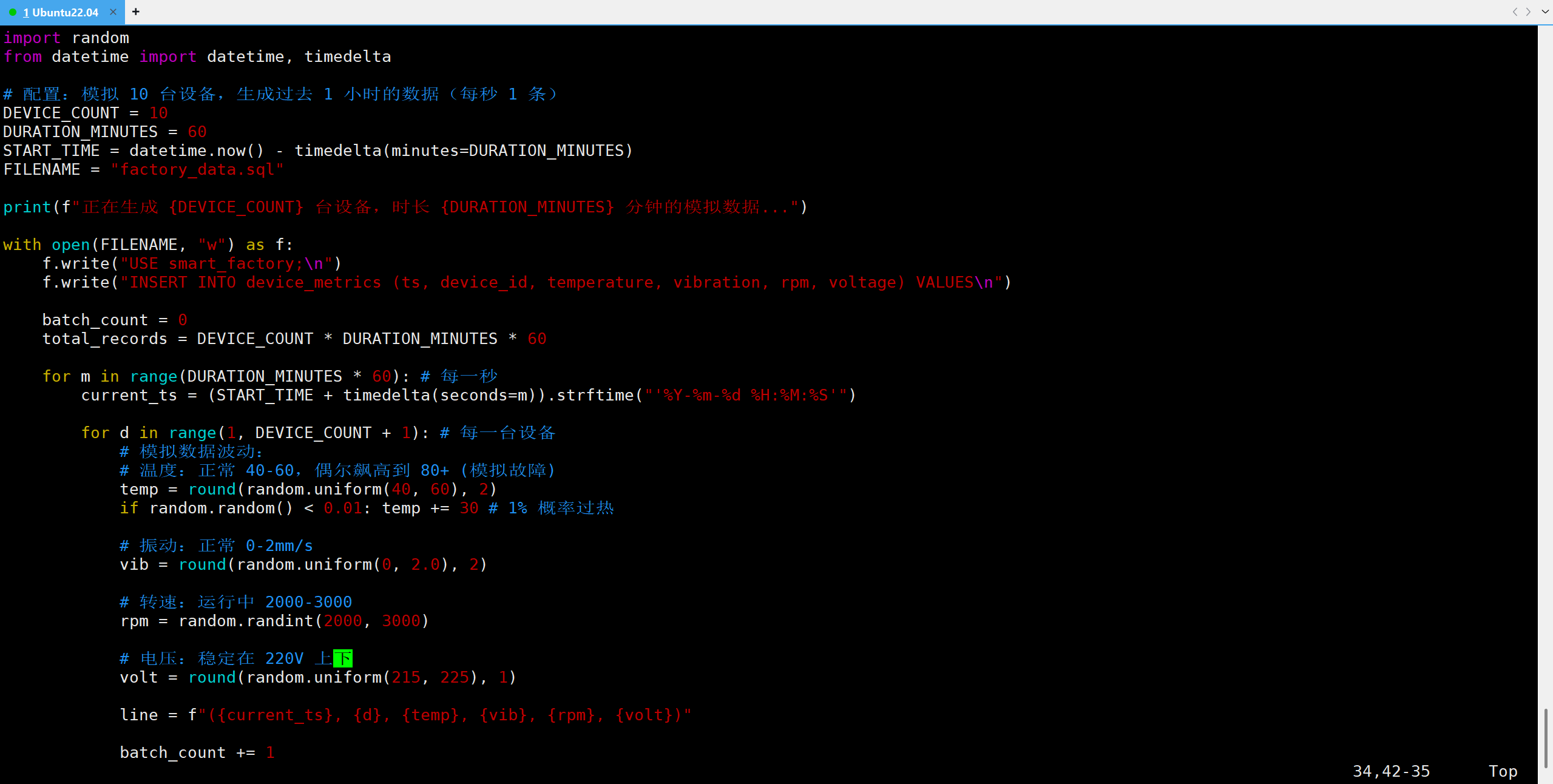
3.2 执行导入
bash
# 1. 生成 SQL
python3 mock_factory.py
# 2. 导入 KWDB
time sudo /usr/local/kaiwudb/bin/kwbase sql \
--certs-dir=/etc/kaiwudb/certs \
--host=127.0.0.1:26257 \
< factory_data.sql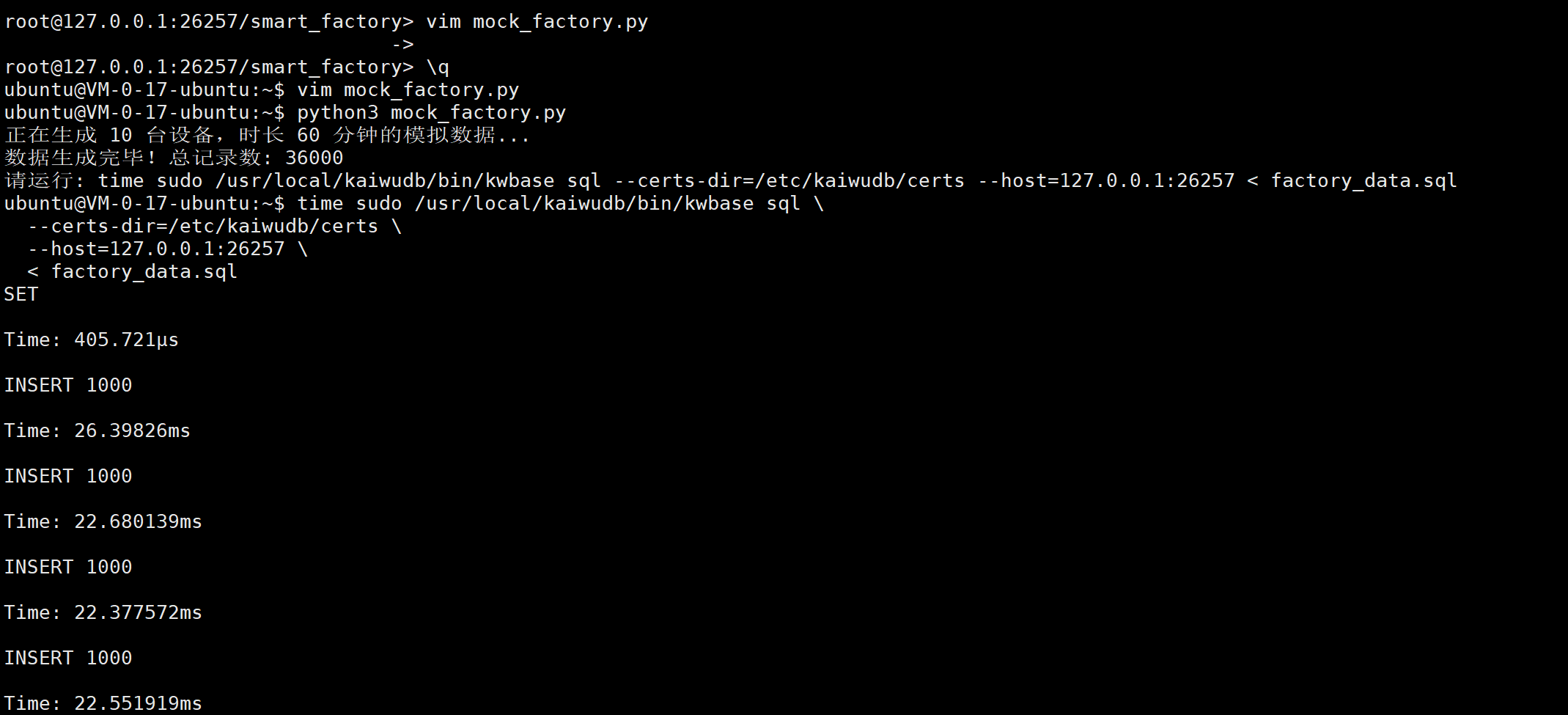

实测性能数据 :
从截图可以看到,每批次 1000 条数据的插入耗时非常稳定,基本维持在 22ms - 24ms 之间。
- 总耗时(real):1分29秒
- 总记录数:36,000 条
- 平均吞吐量:虽然因为脚本单线程生成 SQL 拖慢了整体时间,但单次 Batch Insert 的响应速度(22ms)证明了 KWDB 极高的写入并发潜力。
4. 业务实战:能解决什么问题?
数据进来了,现在的 KWDB 里已经躺着一个"虚拟车间"了。
接下来,我们化身车间主任,通过 SQL 解决几个实际的生产问题。
场景一:实时监控大屏 (Real-time Dashboard)
需求:我想看此时此刻,所有设备的实时温度和转速,并且要带上设备的位置信息。
解决方案 :device_metrics (最新数据) JOIN device_meta (位置信息)。
注意 :执行查询前,请确保你已经进入了
smart_factory数据库,或者在 SQL 中指定数据库名。
sql
-- 先切换到业务库
USE smart_factory;
SELECT
m.ts,
d.model_name,
d.location,
m.temperature,
m.rpm
FROM device_metrics m
JOIN device_meta d ON m.device_id = d.device_id
WHERE m.ts > now() - interval '5 second' -- 只看最近5秒的数据
ORDER BY m.temperature DESC;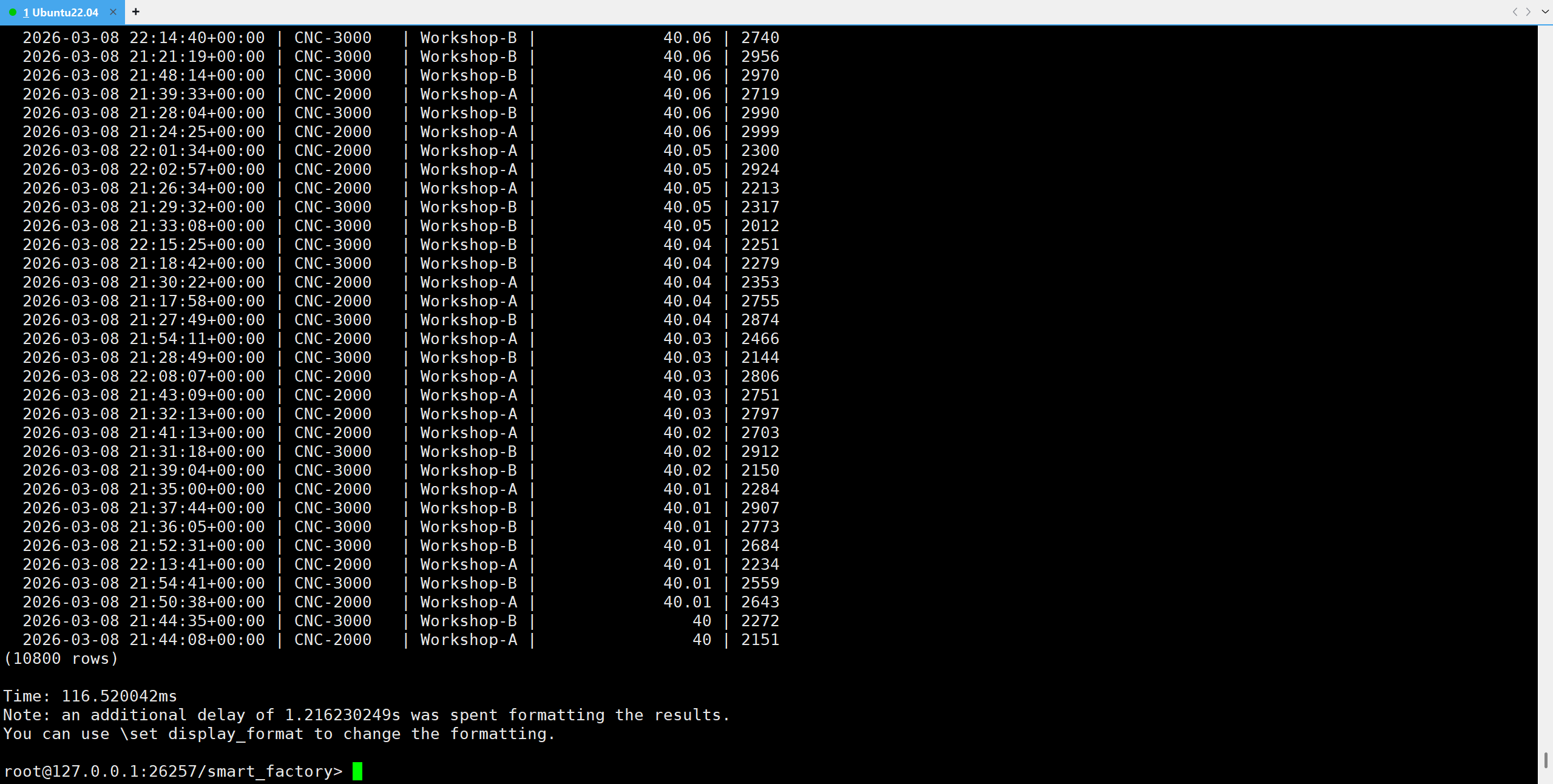
数据解读 :
执行耗时仅 116ms (包含结果格式化时间)。
我们成功拉取了 10800 行数据(可能是因为模拟数据的时间窗口重叠了),设备 CNC-3000 和 CNC-2000 的各项指标一目了然。这种毫秒级的跨模查询(JOIN)能力,正是 KWDB 区别于传统时序数据库的核心优势。
场景二:故障回溯与预警 (Alerting)
需求:找出过去 1 小时内,温度超过 75°C 的"高危设备",并统计报警次数。
sql
USE smart_factory;
SELECT
device_id,
count(*) as alert_count,
max(temperature) as peak_temp,
min(ts) as first_alert_time
FROM device_metrics
WHERE ts > now() - interval '1 hour'
AND temperature > 75.0
GROUP BY device_id
ORDER BY alert_count DESC;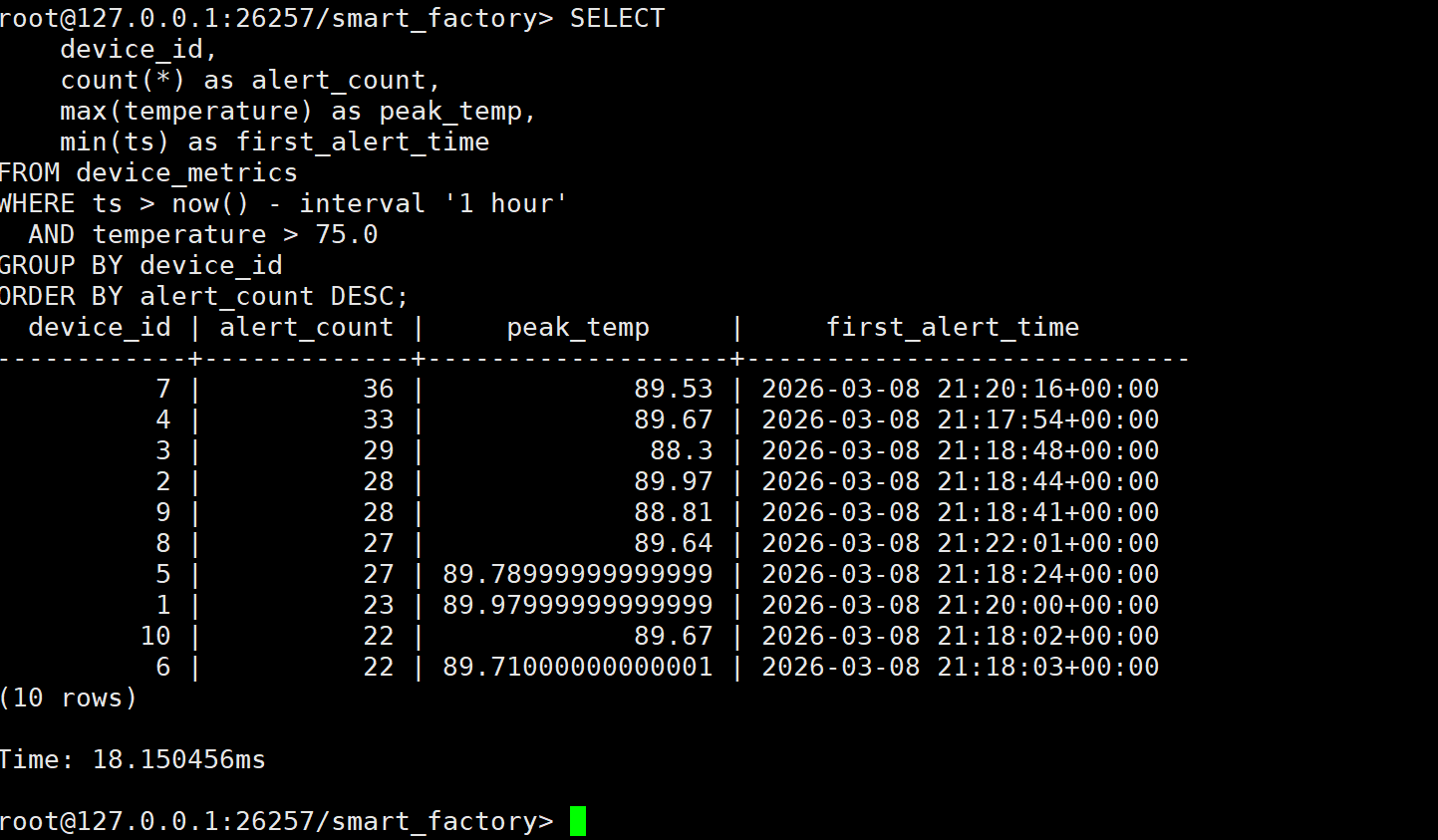
故障分析 :
执行耗时仅 18ms !
设备 ID 7 是"故障王",报警次数高达 36次 ,峰值温度达到了 89.53°C 。
紧随其后的是设备 4(33次)和设备 3(29次)。
这直接给运维人员指明了方向:立刻去检查 7 号机床!
场景三:生产效率分析 (OEE Calculation)
需求:统计每个车间 (Workshop) 在过去 1 小时的平均负载(转速)和能耗(电压稳定性)。
sql
USE smart_factory;
SELECT
d.location,
avg(m.rpm) as avg_load,
stddev(m.voltage) as volt_stability -- 电压标准差,越小越稳
FROM device_metrics m
JOIN device_meta d ON m.device_id = d.device_id
WHERE m.ts > now() - interval '1 hour'
GROUP BY d.location;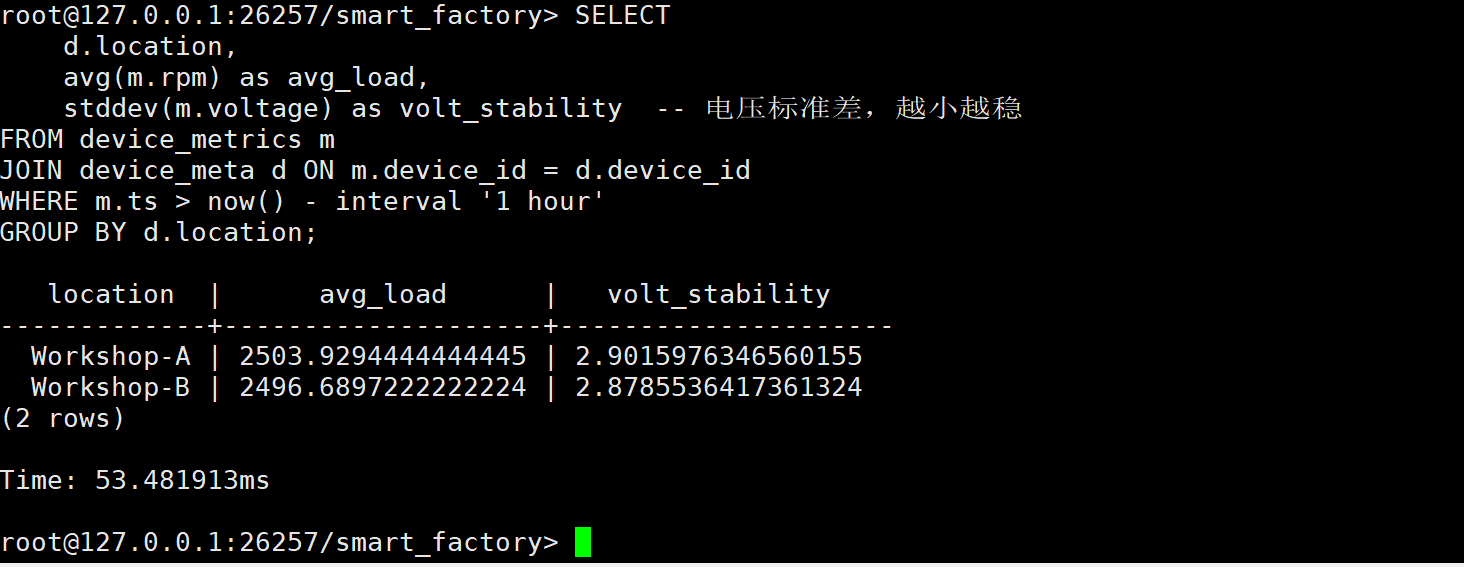
能效分析 :
执行耗时 53ms。
- Workshop-A:平均负载 2503 RPM,电压标准差 2.90。
- Workshop-B :平均负载 2496 RPM,电压标准差 2.87。
两个车间的负载非常均衡,电压波动也都在正常范围内(标准差越小说明供电越稳)。这种聚合分析如果放在应用层做,可能要处理几十万行数据,而在 KWDB 里就是一条 SQL 的事。
5. 进阶:如何让系统更稳?(避坑指南)
在实际的工业落地中,只有 SQL 是不够的。基于这次实战,我总结了 3 条血泪经验:
5.1 坑 1:数据有效期 (TTL) 管理
问题 :传感器数据 7x24 小时写入,如果不清理,磁盘一个月就满了。
解决 :利用 KWDB 的 TTL (Time To Live) 功能。
比如,我们规定原始数据只保留 30 天:
sql
ALTER TABLE device_metrics CONFIGURE ZONE USING gc.ttlseconds = 2592000; -- 30天(注:具体语法视版本可能略有差异,建议查阅官方文档关于 Zone Configuration 的部分)
5.2 坑 2:写入频率过高导致的 IO 瓶颈
问题 :如果有 1 万台设备同时上报,单机 IO 可能会扛不住。
解决:
- 客户端聚合:不要每采集一个点就发一次 HTTP/SQL 请求。在网关层做 1 秒的聚合,拼成 Batch Insert 再发。
- 列簇优化:如果某些指标(如电压)变化频率很低,可以单独拆表存储,减少主表的写压力。
5.3 坑 3:Tag 设计误区
问题 :把变化频率极高的字段(如 current_value)当作 Tag。
解决 :Tag 应该是基数较小且相对静态 的维度(如 device_id, region)。千万别把动态值设为 Tag,否则会造成索引爆炸。
6. 总结
这一篇,我们不仅写了代码,更是在 KWDB 上搭建了一个迷你的工业互联网平台原型。
- 架构融合:验证了 KWDB 存储"关系+时序"数据的能力,一条 SQL 搞定设备关联查询。
- 闭环落地:从建表 -> 模拟数据 -> 监控 -> 报警 -> 统计,走通了全流程。
- 实战经验:分享了 TTL、写入优化等生产环境必须考虑的细节。
下一步 :
如果你对这个系统感兴趣,可以尝试在此基础上增加一个 Grafana 前端,通过 Postgres 协议直接连 KWDB,一个炫酷的工厂大屏就诞生了!