作为后端开发,我们几乎每天都在和 Redis+MySQL 的组合打交道。Redis 用来做缓存,提升读性能;MySQL 用来做持久化存储,保证数据安全。但这个组合有一个永恒的痛点:如何保证 Redis 和 MySQL 的数据一致性?
相信很多人都遇到过这样的问题:更新了 MySQL 的数据,但 Redis 里还是旧数据;或者 Redis 里有数据,但 MySQL 里已经被删除了。数据不一致不仅会导致用户体验变差,严重时还会引发业务逻辑错误,造成经济损失。
面试时,这个问题更是 100% 会被问到:
- Redis 和 MySQL 怎么同步数据?
- 先更数据库还是先更缓存?为什么?
- 为什么要删除缓存而不是更新缓存?
- 怎么解决并发场景下的数据不一致问题?
- 大厂都是怎么保证缓存和数据库一致性的?
这篇文章,我们就从最基础的缓存读写模式出发,一步步拆解数据不一致的根本原因,然后从简单到复杂,讲解从基础方案到工业级解决方案的完整演进,最后给出线上最佳实践和避坑指南。看完这篇,你不仅能轻松应对面试,更能解决实际业务中的数据一致性问题。
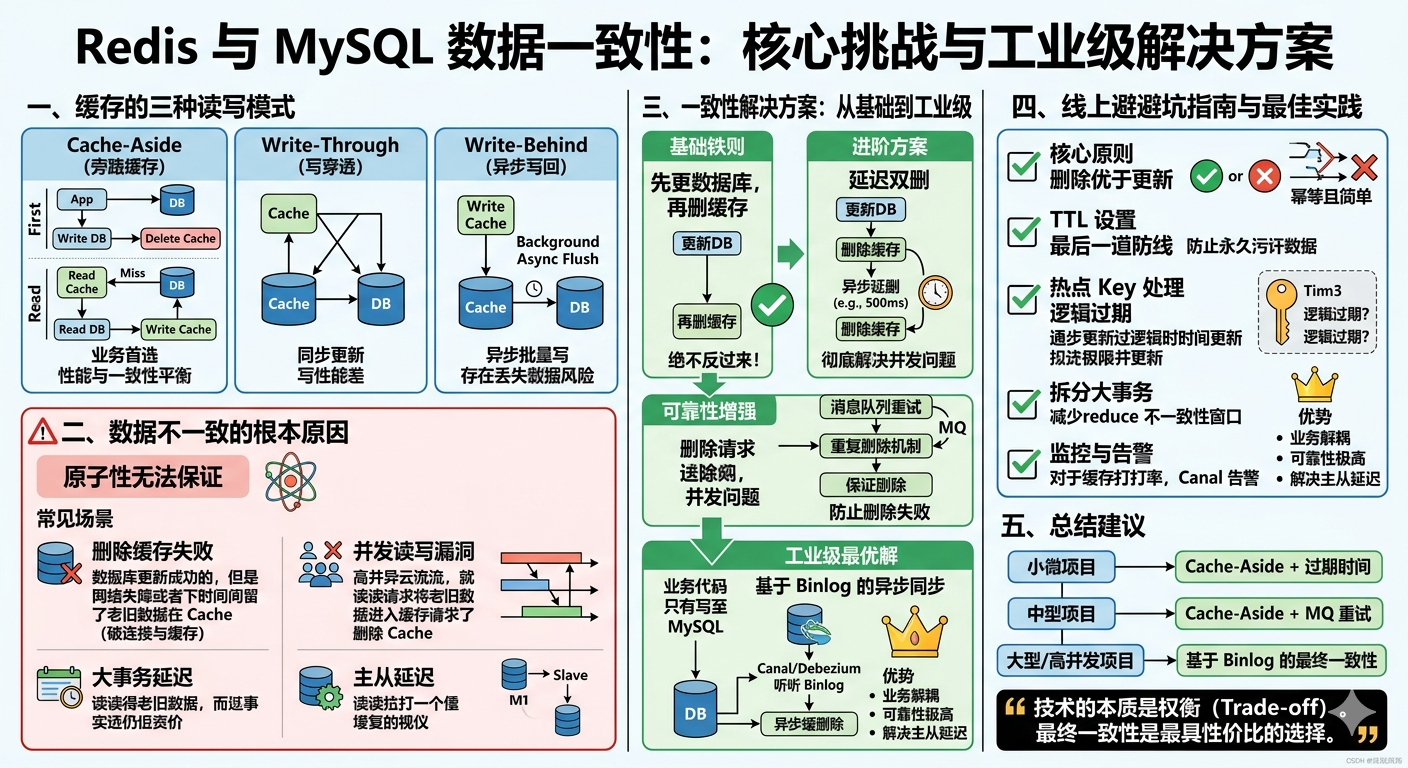
一、先搞懂:缓存的三种读写模式
在讲数据同步和一致性之前,我们必须先搞清楚缓存的三种基本读写模式。不同的读写模式,同步策略和一致性保证是完全不同的。
1. Cache-Aside(旁路缓存):99% 业务的首选
这是最通用、最成熟的缓存模式,也是所有互联网公司的标准配置。它的核心思想是:缓存只负责加速读,写操作永远直接走数据库,缓存只在需要时被动更新。
标准读流程
- 先查询 Redis,命中则直接返回数据
- Redis 未命中,查询 MySQL 数据库
- 将查询结果写入 Redis,设置过期时间
- 返回数据给客户端
标准写流程
- 先更新 MySQL 数据库
- 再删除 Redis 中的对应缓存(注意是删除,不是更新)
核心优势
- 实现简单,逻辑清晰,几乎没有学习成本
- 按需缓存,不会缓存冷数据,内存利用率高
- 一致性表现最好,是性能和一致性的最佳平衡点
局限性
- 第一次查询会缓存未命中,需要穿透到数据库
- 写操作会使缓存失效,可能导致短暂的读压力上升
2. Write-Through(写穿透):强一致性但性能差
写穿透的核心思想是:所有写操作必须同时更新数据库和缓存,两者要么都成功,要么都失败。
写流程
- 同时发起数据库更新和缓存更新请求
- 等待两个操作都完成
- 只有两者都成功,才返回客户端成功
- 任何一个失败,整个操作回滚
核心优势
- 理论上可以做到强一致性,缓存和数据库永远同步
- 读请求永远命中缓存,读性能极高
致命缺点
- 写性能极差,每次写都要操作两个存储系统
- 需要分布式事务支持,实现复杂度极高
- 会缓存大量冷数据,浪费宝贵的 Redis 内存
适用场景
仅适用于对一致性要求极致严格、且读多写少、数据量极小的场景(比如银行核心账户余额),绝大多数业务不会使用。
3. Write-Behind(写回 / 异步写):极致性能但一致性差
写回的核心思想是:写操作只写缓存,后台异步批量同步到数据库。
写流程
- 只更新 Redis 缓存
- 立即返回客户端成功
- 后台定时任务将缓存中的脏数据批量刷入 MySQL
核心优势
- 写性能极高,适合高并发写场景
- 批量写入数据库,大幅降低数据库压力
致命缺点
- 数据一致性最差,缓存和数据库可能有几分钟甚至几小时的不一致
- Redis 宕机会导致大量未刷盘的数据永久丢失
适用场景
仅适用于对数据一致性要求极低、允许数据丢失的非核心场景(比如文章浏览量、商品点击量统计)。
三种模式核心对比表
| 模式 | 写操作核心逻辑 | 一致性等级 | 写性能 | 读性能 | 实现复杂度 | 推荐指数 |
|---|---|---|---|---|---|---|
| Cache-Aside | 先更数据库,再删缓存 | 最终一致 | 较好 | 较好 | 简单 | ⭐⭐⭐⭐⭐ |
| Write-Through | 同时更数据库和缓存 | 强一致 | 差 | 极好 | 复杂 | ⭐ |
| Write-Behind | 只更缓存,异步更数据库 | 弱一致 | 极好 | 极好 | 中等 | ⭐⭐ |
核心结论 :除非有特殊需求,否则永远选择Cache-Aside 模式。下面所有的讨论,都基于这个模式展开。
二、为什么会出现数据不一致?
在理想情况下,只要严格遵循 "先更数据库,再删缓存" 的流程,就不会出现数据不一致。但在真实的分布式环境中,网络延迟、系统崩溃、并发请求、主从延迟等因素,都会导致数据不一致。
我们来看四个最常见、最容易踩坑的不一致场景:
场景 1:删除缓存失败(最常见)
这是线上最频繁出现的不一致原因,会导致永久不一致。
- 线程 A 更新 MySQL 数据库,将数据从 v1 改为 v2
- 线程 A 发起删除 Redis 缓存的请求
- 由于网络抖动、Redis 宕机或超时,删除操作失败
- 后续所有读请求都从 Redis 中读到旧数据 v1
除非缓存过期或被手动删除,否则这个不一致会一直存在。
场景 2:并发读写导致的脏数据(最隐蔽)
这是最容易被忽略的场景,发生概率不高,但在高并发下会被放大。
- 线程 A 查询 Redis,未命中,开始查询 MySQL,得到旧数据 v1
- 线程 B 更新 MySQL,将数据从 v1 改为 v2
- 线程 B 删除 Redis 缓存
- 线程 A 将查询到的旧数据 v1 写入 Redis
最终结果:Redis 中是 v1,MySQL 中是 v2,数据不一致。
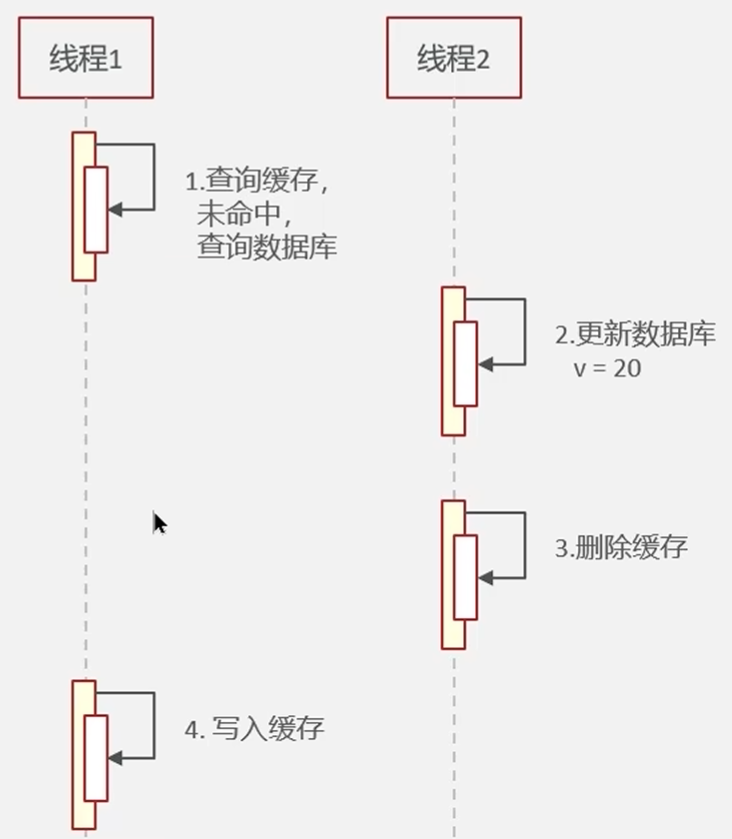
很多人以为 "先更数据库再删缓存" 就万无一失了,其实这个场景就是这个流程的漏洞。不过它的发生条件非常苛刻,需要同时满足:
- 缓存刚好在读写请求到达的瞬间过期
- 读请求的数据库查询时间 > 写请求的更新 + 删除缓存时间
- 读请求在写请求删除缓存之后才写入 Redis
场景 3:大事务导致的不一致
大事务会放大所有一致性问题,是线上的隐形杀手。
- 线程 A 开启大事务,更新 MySQL 数据为 v2,但未提交
- 线程 B 查询 Redis,未命中,查询 MySQL,读到未提交的旧数据 v1
- 线程 A 提交事务,MySQL 数据变为 v2
- 线程 A 删除 Redis 缓存
- 线程 B 将旧数据 v1 写入 Redis
最终结果:Redis 中是 v1,MySQL 中是 v2,数据不一致。
场景 4:主从延迟导致的不一致
如果使用了主从复制架构(读从库、写主库),主从延迟会成为一致性的重灾区。
- 线程 A 更新主库数据为 v2,删除 Redis 缓存
- 线程 B 查询 Redis,未命中,查询从库
- 由于主从延迟,从库还未同步到新数据,返回旧数据 v1
- 线程 B 将旧数据 v1 写入 Redis
最终结果:Redis 中是 v1,主库中是 v2,数据不一致。
根本原因
所有数据不一致的本质,都是Redis 和 MySQL 是两个独立的存储系统,无法做到原子更新。在分布式环境中,我们永远无法保证两个操作要么都成功,要么都失败。我们能做的,是通过各种方案,将不一致的时间窗口降到最低,最终达到数据一致。
三、数据一致性解决方案:从基础到工业级
我们将解决方案分为四个层级,你可以根据自己的业务规模、一致性要求和并发量,选择最合适的方案。
方案 1:基础方案 ------ 先更数据库,再删缓存
这是所有方案的基础,也是必须严格遵守的铁则。
很多人会问:为什么不能反过来,先删缓存再更数据库?我们用反证法来看:
- 先删缓存,再更数据库 :
- 线程 A 删除缓存
- 线程 B 查询缓存未命中,查询 MySQL 得到旧数据 v1
- 线程 B 将 v1 写入 Redis
- 线程 A 更新 MySQL 为 v2最终结果:缓存永久是 v1,数据库是 v2,永久不一致。
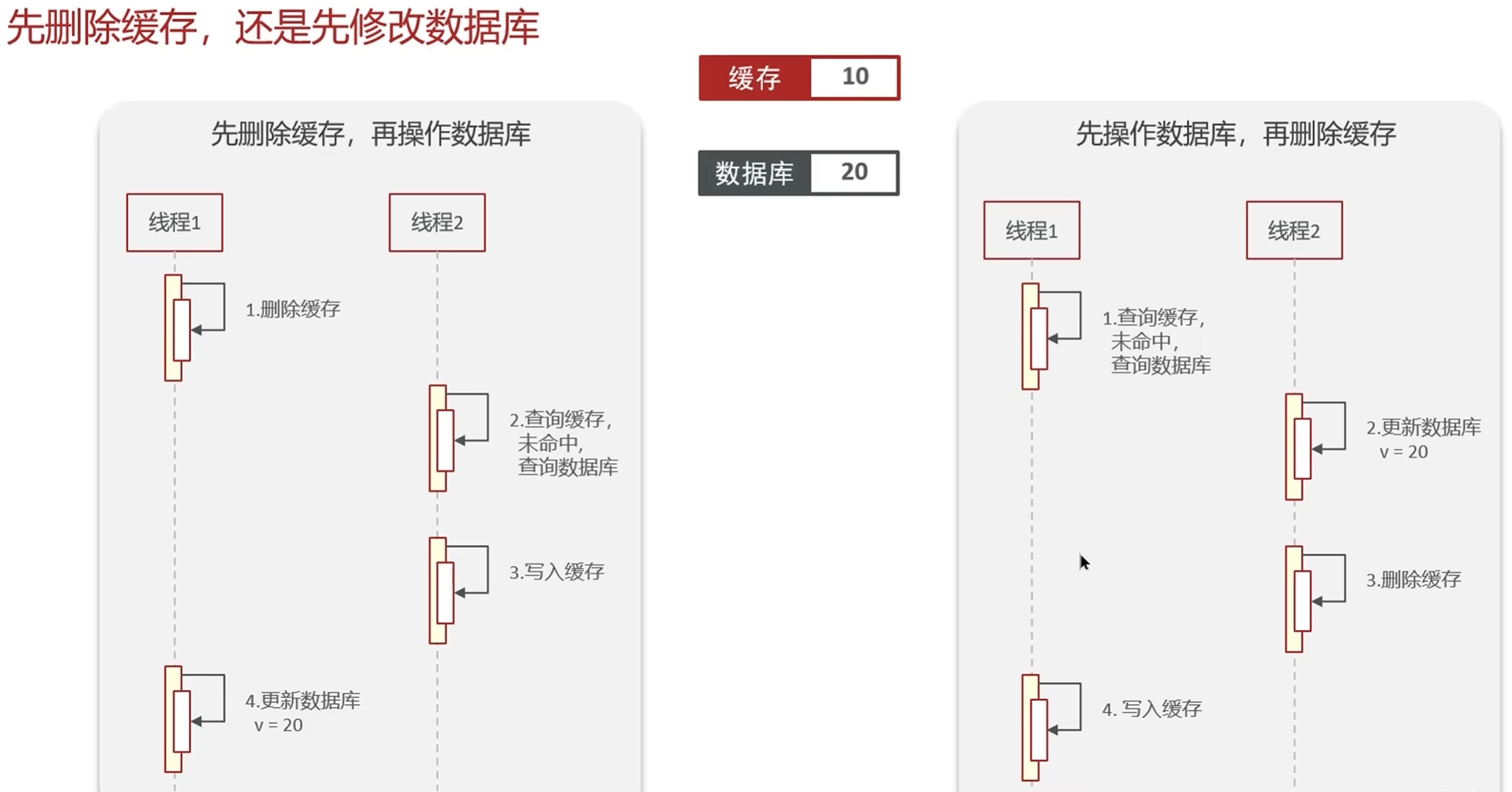
而 "先更数据库,再删缓存" 的不一致,只是短暂的,最多持续到缓存过期。而且发生概率极低,在绝大多数业务场景下是可以接受的。
铁则:永远使用 "先更新数据库,再删除缓存" 的顺序,不要反过来。
方案 2:延迟双删 ------ 解决并发读写问题
为了解决前面场景 2 的并发读写问题,我们可以在删除缓存之后,延迟一段时间,再删除一次缓存。这就是延迟双删。

核心原理
延迟的这段时间,就是为了等待那个慢查询的读线程把旧数据写入缓存,然后我们再把它删掉。这样即使出现了并发脏数据,第二次删除也会把它清理掉。
可落地代码实现
java
@Service
public class ProductService {
@Autowired
private ProductMapper productMapper;
@Autowired
private StringRedisTemplate redisTemplate;
// 专门用于异步延迟删除的线程池
private static final ExecutorService CACHE_DELETE_EXECUTOR =
Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
public void updateProduct(Product product) {
// 1. 第一步:先更新数据库
productMapper.updateById(product);
String cacheKey = "product:info:" + product.getId();
// 2. 第二步:第一次删除缓存
redisTemplate.delete(cacheKey);
// 3. 第三步:延迟500ms,第二次删除缓存
CACHE_DELETE_EXECUTOR.submit(() -> {
try {
// 延迟时间根据业务的平均数据库查询耗时设置,一般500ms-1s
Thread.sleep(500);
redisTemplate.delete(cacheKey);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("延迟删除缓存失败,key: {}", cacheKey, e);
}
});
}
}注意事项
- 延迟时间必须大于业务中最慢的数据库查询时间,否则第二次删除会先于脏数据写入
- 第二次删除必须异步执行,不能阻塞主线程
- 延迟双删只能降低不一致的概率,不能 100% 避免
方案 3:删除重试机制 ------ 解决删除失败问题
为了解决场景 1 的删除缓存失败问题,我们需要给删除操作增加重试机制。如果第一次删除失败,就重试几次,直到成功。
推荐实现:消息队列异步重试
同步重试会阻塞主线程,影响接口性能,因此推荐使用消息队列实现异步重试:
- 更新 MySQL 数据库
- 尝试删除 Redis 缓存
- 如果删除成功,流程结束
- 如果删除失败,将删除请求发送到消息队列
- 消费者监听消息队列,收到请求后重试删除
- 最多重试 3 次,还是失败则记录日志并报警,人工介入
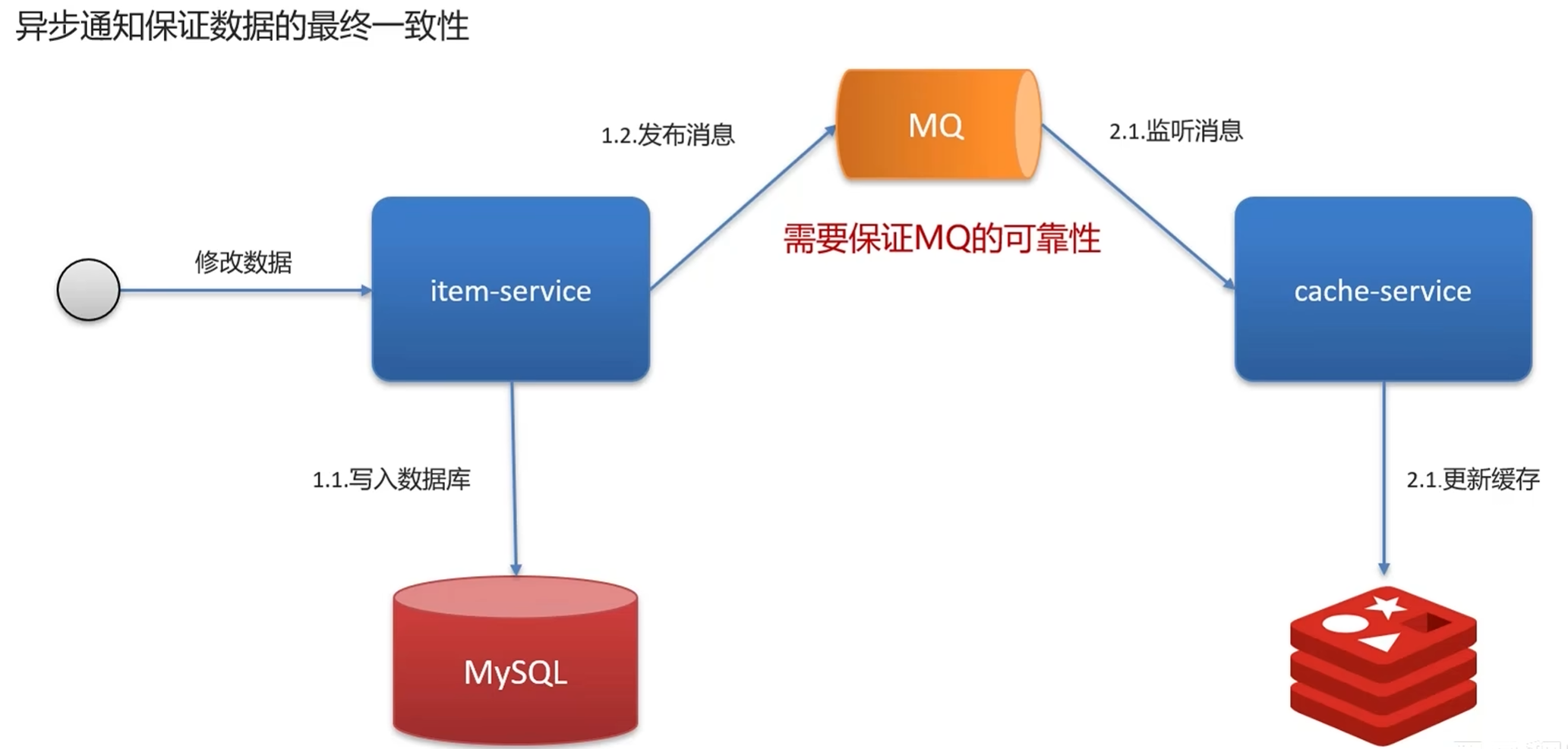
这种方式的优点是:不影响主线程性能,可靠性高,即使 Redis 暂时不可用,恢复后也能通过重试最终删除缓存。
方案 4:基于 binlog 的最终一致性(推荐,大厂首选)
前面的方案虽然能解决大部分问题,但都有局限性:
- 业务代码侵入性强,每个写操作都要写删除和重试逻辑
- 延迟双删的延迟时间难以精准控制
- 无法解决主从延迟、大事务等复杂场景的不一致
而基于 binlog 的异步缓存更新,是目前工业界最成熟、最可靠的方案,也是阿里、腾讯等大厂的标准做法。
核心原理
MySQL 的 binlog 记录了所有数据修改的完整操作。我们可以通过监听 binlog,获取数据的变更事件,然后异步删除对应的缓存。
这样做的最大好处是:业务代码只需要关心数据库更新,完全不需要关心缓存操作。缓存的更新逻辑和业务逻辑完全解耦,由统一的同步服务处理。
完整执行流程
- 业务代码只更新 MySQL 数据库,不做任何缓存操作
- MySQL 将数据修改操作记录到 binlog 中
- Canal/Debezium 等工具监听 binlog,解析出数据变更事件(增删改)
- 同步服务消费 binlog 事件,删除 Redis 中对应的缓存
- 如果删除失败,通过消息队列重试,直到成功
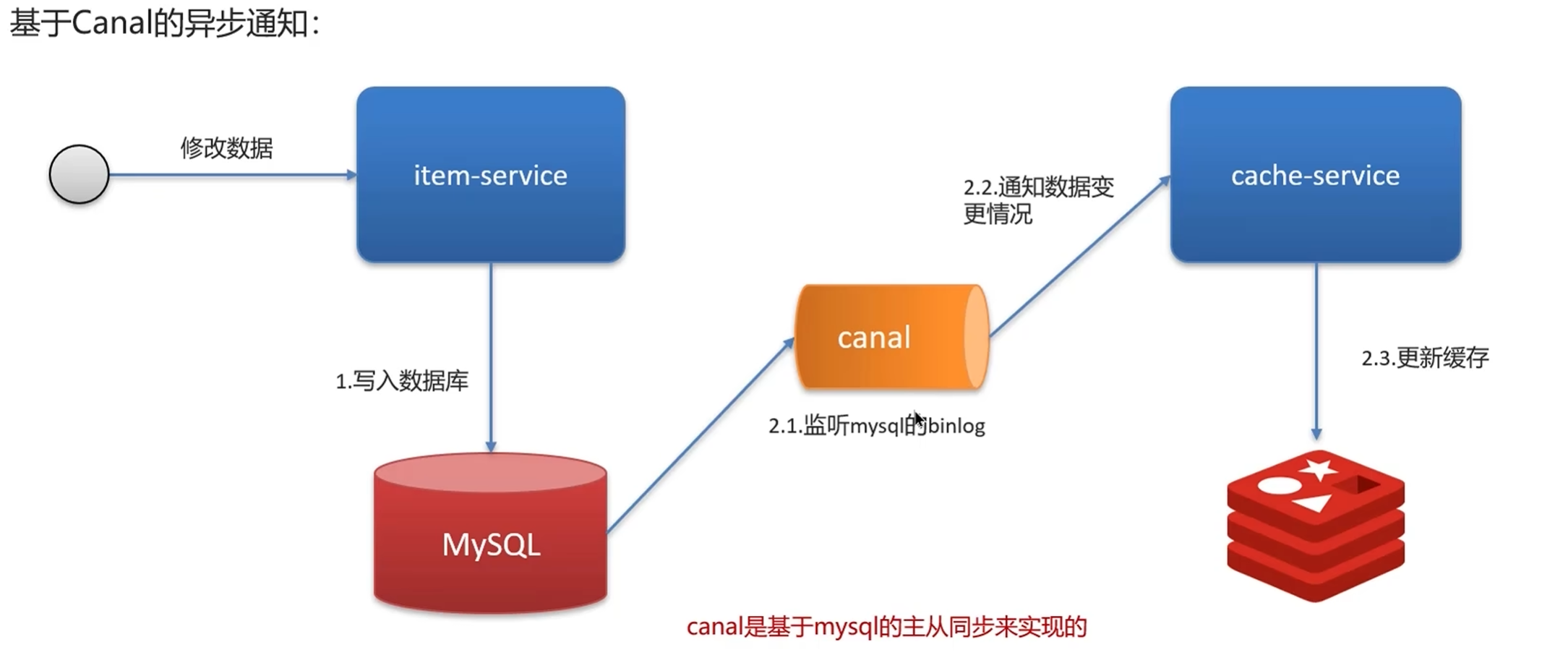
核心工具
- Canal:阿里开源的 MySQL binlog 订阅工具,国内使用最广泛,部署简单
- Debezium:RedHat 开源的分布式数据同步工具,支持多种数据库,适合云原生场景
为什么这是最优方案?
- 业务零侵入:业务代码不需要写任何缓存相关的逻辑,专注于业务本身
- 可靠性极高:只要数据库更新成功,binlog 一定会产生,缓存最终一定会被更新
- 一致性最好:不一致的时间窗口极短,通常只有几十毫秒
- 易于维护:所有缓存更新逻辑统一管理,不需要每个业务重复开发
局限性
- 需要额外部署和维护 Canal/Debezium 等中间件,增加了运维成本
- 是最终一致性,不是强一致性
方案 5:强一致性方案(不推荐)
如果你的业务必须要求强一致性(比如银行核心系统),可以考虑以下方案:
- 分布式事务:使用 Seata 等分布式事务框架,保证更新数据库和删除缓存的原子性
- 读写锁:读请求加共享锁,写请求加排他锁,保证同一时间只有一个操作执行
- 读写都走主库:避免主从延迟导致的不一致
但这些方案都有致命的缺点:性能极差、实现复杂、可扩展性差。互联网业务几乎都可以接受最终一致性,不要盲目追求强一致性,否则会付出巨大的代价。
四、线上最佳实践与避坑指南
1. 永远删除缓存,不要更新缓存
这是缓存使用的第一铁则。很多人会问:为什么不能更新缓存,而是要删除?
原因有三个:
- 更新缓存会导致脏数据:如果两个写请求同时更新同一个缓存,会出现覆盖问题,导致缓存数据错误
- 更新缓存浪费资源:很多缓存的数据可能永远不会被访问到,更新缓存会浪费 CPU 和内存
- 删除是幂等的:删除多次和删除一次效果一样,而更新不是
记住:缓存的唯一作用是加速读,数据的唯一可信来源是 MySQL。我们只需要在缓存失效时,从数据库重新加载最新的数据即可。
2. 给所有缓存设置过期时间
无论你的一致性方案多么完善,都一定要给所有缓存设置过期时间。
过期时间是数据一致性的最后一道防线。即使出现了数据不一致,最多也只会持续到缓存过期,不会出现永久不一致的情况。
过期时间设置原则:
- 一致性要求高、更新频繁的数据:5-30 分钟
- 一致性要求低、更新不频繁的数据:1-24 小时
- 绝对不要设置永久不过期的缓存
3. 热点 key 特殊处理
对于秒杀商品、热点新闻等极端热点 key,普通的删除缓存策略会导致缓存击穿,大量请求打到数据库。
对于热点 key,应该使用逻辑过期方案:
- 不设置 Redis 的物理过期时间
- 在缓存的 value 中维护一个逻辑过期时间戳
- 当查询到逻辑过期时,开启异步线程更新缓存,同步返回旧数据
这样既保证了性能,又避免了缓存击穿,同时最终数据也是一致的。
4. 避免大事务
大事务是所有数据库问题的万恶之源,也是数据不一致的重要诱因。
永远不要在事务中执行以下操作:
- 调用第三方 RPC 或 HTTP 接口
- 执行耗时的本地计算
- 批量处理大量数据
所有大事务都要拆分成小事务,分批提交。
5. 建立完善的监控和告警
最后,一定要建立完善的监控体系:
- 监控 Redis 的命中率、内存使用率、响应时间
- 监控缓存删除失败的次数,超过阈值立即报警
- 监控 Canal/Debezium 的同步状态,避免同步中断
- 定期对比 Redis 和 MySQL 的数据一致性,发现问题及时处理
五、常见误区纠正
-
误区 :先删缓存再更数据库更安全。纠正:先删缓存会导致严重的永久不一致问题,永远使用 "先更数据库,再删缓存" 的顺序。
-
误区 :更新缓存比删除缓存性能更好。纠正:更新缓存会导致脏数据和资源浪费,删除缓存是更简单、更可靠的方案。
-
误区 :延迟双删可以解决所有不一致问题。纠正:延迟双删只能降低并发不一致的概率,最终一致性还是要靠 binlog 同步。
-
误区 :强一致性比最终一致性更好。纠正:强一致性会带来巨大的性能和复杂度代价,互联网业务几乎都可以接受最终一致性。
-
误区 :只要用了 binlog 同步,就不会出现不一致。纠正:binlog 同步是最终一致性,还是会有几十毫秒的不一致时间窗口。
六、总结
Redis 和 MySQL 的数据一致性问题,本质上是分布式系统中多个独立存储系统的一致性问题。在分布式环境中,没有完美的强一致性方案,只有最适合业务的最终一致性方案。
回顾我们的方案演进路线:
- 基础方案:先更数据库,再删缓存,解决 80% 的场景
- 优化方案:延迟双删 + 删除重试,解决并发和删除失败问题
- 工业级方案:基于 binlog 的异步更新,业务零侵入,可靠性最高,大厂首选
- 强一致性方案:分布式事务 + 读写锁,性能差,仅适用于特殊场景
不同规模项目的推荐方案:
- 个人项目 / 小型项目:基础方案 + 过期时间
- 中型项目:基础方案 + 延迟双删 + 消息队列重试
- 大型项目 / 互联网公司:基于 binlog 的最终一致性方案
技术的选择永远是权衡的艺术。没有最好的方案,只有最适合业务的方案。我们需要根据自己的业务场景、一致性要求和团队能力,选择最合适的方案,在一致性、性能和复杂度之间取得最佳平衡。