本系列主要旨在帮助初学者学习和巩固Linux系统。也是笔者自己学习Linux的心得体会。

个人主页: 爱装代码的小瓶子
文章系列: Linux
2. C++
文章目录
- [1 前言:](#1 前言:)
- [2. 线程的概念:](#2. 线程的概念:)
-
- [2-1 Linux和windows平台的线程对比](#2-1 Linux和windows平台的线程对比)
- [2-2 Linux下的线程特点:](#2-2 Linux下的线程特点:)
- [2-3 初步认识Linux下的线程库:](#2-3 初步认识Linux下的线程库:)
- [3. 虚拟地址和页表:](#3. 虚拟地址和页表:)
-
- [3-1 引入页表:](#3-1 引入页表:)
- [3-2 引入多级页表:](#3-2 引入多级页表:)
- [3-3 引入快表:](#3-3 引入快表:)
- [4. `tid`和`pthread_t`的区别:](#4.
tid和pthread_t的区别:) - [5. 总结](#5. 总结)
1 前言:
在我们之前的文章中,我们一直在强调进程,那么线程是什么呢?应该怎么去理解呢,我们先来回顾什么是进程:进程是一个PCB(在Linux中叫做struct_task)+ 相关的数据 + 代码。
在我们之前的学习视角中,一直都是一个PCB(struct_task)里面有一个指针mm,指向一个叫 mm_struct 的结构体。这个结构体就是虚拟地址的代表。里面有一个页表 (翻译官): mm_struct 里面又包含了一个指针,指向这个进程专属的**页表(Page Table)**目录。 物理地址 (真实的土地): CPU 里的 MMU(内存管理单元)拿着这个页表,把你代码里的虚拟地址,翻译成内存条上真实的物理地址。
接下来,我们需要补充这个视角,我会给出线程的概念。为了更好的理解线程,我们还需要补充页表是怎么从物理地址找到虚拟地址的。
本文的知识点:
- 什么是线程,怎么理解Linux和windows的平台差异
- 理解页表的设计,怎么完成映射。
2. 线程的概念:
线程是一个进程内部的一个执行路线或控制序列 。
具体地说,线程的核心概念包括:
- 本质 :线程是进程的一个执行分支,它在进程的地址空间内运行,共享进程的大部分资源(如代码段、数据段、文件描述符表等)。
- 轻量级 :在Linux系统中,内核使用
task_struct结构体来管理线程,线程被视为轻量级进程。与创建和切换一个完整的进程相比,线程的创建和切换开销要小得多。 - 调度单位 :进程是资源分配的基本单位,而线程是CPU调度的基本单位。一个进程可以包含多个线程,这些线程并发执行。
- 以前我们说进程是 PCB。现在更准确地说,进程是指那个拥有独立虚拟地址空间(
mm_struct)的整体。进程是分配资源的基本单位。 - 线程就是那些底层具体干活的 PCB (
task_struct)。线程是 CPU 调度的基本单位。
我们可以这么理解,进程中至少包含一个线程(在Linux平台下看,也许这个进程只有一个PCB),而正是有了进程,才会拥有线程。
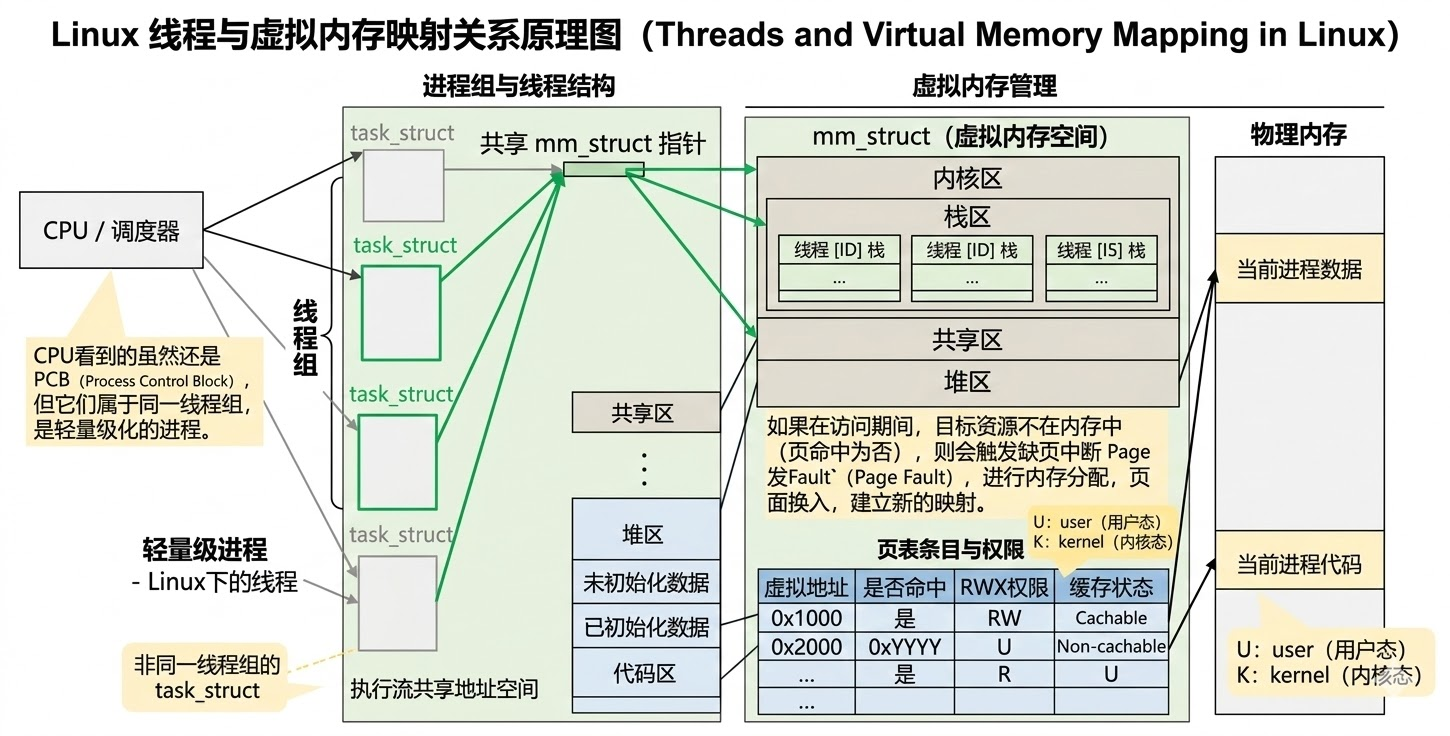
我们可以在这个图片,我们能清楚的知道Linux下,并没有单独的结构体去描述线程,而是复用了Linux下的进程描述结构体。
2-1 Linux和windows平台的线程对比
我们刚刚的介绍都是围绕着Linux下的线程来讲解的,但是线程的特性和概念都是相同的。可以说,windows和Linux下的设计方式不同,是两种设计理念。先来看看Linux线程的实现:
Linux 内核原生的字典里没有 "线程"这个词。它统一使用 task_struct 来管理。无论是进程还是线程,在 Linux 调度器眼里,统统都是一个"调度实体"(Lightweight Process,轻量级进程 LWP)。
而在Linux下的区别方式就是线程之间是共享虚拟内存的,它们之间是可以之间进行通讯的,而进程之间是独立的。一个进程中的线程之间相互共享资源的。他们可以很便捷的通讯。
这就是Linux下的设计哲学,复用以前的轮子,已经经历过很多次验证没有错误的轮子来完成线程的设计。Linux 的设计哲学是**"大道至简,万物皆任务"
而Windows 的设计哲学就是 "等级森严,分工明确"。windows单独设计一个TCB(线程描述结构体),Windows 的 TCB (Thread Control Block) 由两个位于内核空间的结构体组成,外加一个位于用户空间的结构体。我们在这里,不详细来讲解。但是在window的开发中,进程很像一个容器,而线程才是灵魂,windows平台为其提供了一个独立的创建接口,相关的函数都是独立的。
| 概念 | Windows 平台 | Linux 平台 |
|---|---|---|
| 内核线程结构 (TCB) | ETHREAD (包含 KTHREAD) |
task_struct |
| 内核进程结构 (PCB) | EPROCESS (包含 KPROCESS) |
task_struct |
| 用户态环境块 | TEB |
(通常通过线程栈的特定偏移模拟) |
| 设计哲学 | 分层解耦: 调度归调度,管理归管理 | 万物皆任务: 一个结构体打天下 |
| 对比维度 | Linux | Windows (NT 内核) |
|---|---|---|
| 内核数据结构 | 统一为 task_struct |
严格区分 EPROCESS 和 ETHREAD |
| 底层创建 API | 统一使用 clone() (通过标志位控制) |
CreateProcess 和 CreateThread 完全分开 |
| 进程创建开销 | 极小 (有写时拷贝 COW 优化) | 非常大 (重型初始化) |
| 主流开发模式 | 多进程、多线程百花齐放 | 几乎绝对依赖多线程 |
| 线程同步底层锁 | Futex (快速用户空间互斥体,极度优化) | 临界区 (Critical Section)、内核 Mutex |
| 哲学精髓 | 线程不过是共享了内存的进程 | 进程只是容器,线程才是灵魂 |
2-2 Linux下的线程特点:
由于Linux下没有设计复杂的结构体单独去描述线程,所以Linux下的线程是轻量的,我们又把线程称为LWP(轻量级进程)。
在Linux的设计下,进程和线程没有多大的区别,这样我们原来的调度进程的算法都是可以用在线程的。
但是也是这种特点,导致了线程的一个特点就是,一荣俱荣,一损俱损,由于共享了绝大部分资源,线程之间的关系非常紧密,但也非常危险。主要体现在下面的两个点:
- 一荣俱荣: 线程间通信极快,改个全局变量对方秒知。
- 一损俱损: 如果其中一个线程因为"除以 0"或者"非法访问内存(段错误)"崩溃了,内核会根据信号处理机制,把整个进程(包括所有兄弟线程)全部干掉。因为它们共享同一个地址空间,一个人把家拆了,大家都别住了。
2-3 初步认识Linux下的线程库:
先来认识两个函数,第一个就是:
这个就是用来创建线程,一共有四个参数:
*thread传入tid,由于会给出tid是什么,所以需要传入地址。- 第二个设置线程的权限,这里不用管,可以直接给
nullptr。 - 第三个就是线程需要执行的函数,是
void*作为返回值,同时还有一个void*的参数. arg就是需要传入的参数。
第二个函数就是 join函数,不然会造成内存泄露。类似于僵尸进程的那种感觉,这两个就是必须要配合的,除非设置线程是分离的(后面我们会讲)。
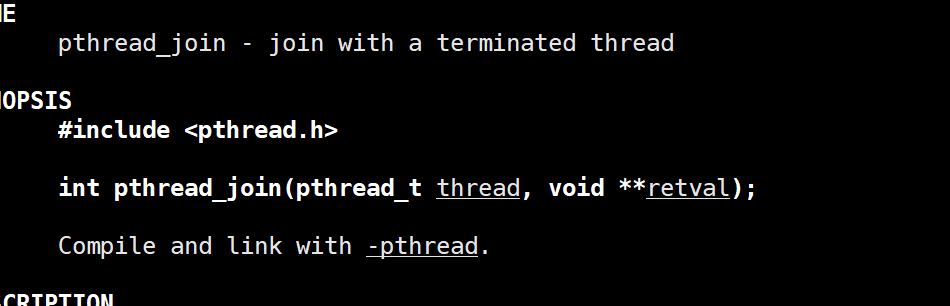
这里也是两个参数:
tid,告诉我需要等哪个线程。- 接受放回值,由于返回的是
void*,所以为了接受返回值,就必须void**,用来存放返回指针的地址。
好的,我们来看一段代码,来完成这个的操练,还是有很多小细节的:
cpp
#include <iostream>
#include <string>
#include <cstdio>
#include <pthread.h>
#define CHECK_ERR(expr) \
do \
{ \
int _err = expr; \
if (_err != 0) \
{ \
std::cerr << "在第" << __LINE__ << "行"; \
std::cerr << "错误码是" << _err << std::endl; \
exit(EXIT_FAILURE); \
} \
} while (0)
void *routine(void *arg)
{
std::string name = *(static_cast<std::string*>(arg));
pthread_t tid = pthread_self();
std::cout << name;
printf("%p\n",(void*)tid);
std::string* task = new std::string("i am a task");
return task;//放回void*,这个可以接受 string*
}
int main()
{
pthread_t tid;
std::string arg = "pthread-";
CHECK_ERR(pthread_create(&tid, nullptr, routine, &arg));
void * res = nullptr;
int n = pthread_join(tid,&res);
CHECK_ERR(n);
std:: cout << *(static_cast<std::string*> (res)) <<std::endl;
//这个是在堆上面开辟出来的res,记得销毁。
delete static_cast<std::string*> (res);
return 0;
}运行结果如下:

3. 虚拟地址和页表:
在早期没有出现虚拟地址和页表的时候,每个用户程序在物理内存上对应的空间必须是连续的:我们知道为了确保程序能够正常运行必须要有:作系统在加载程序(exec)时,需要将程序的各个部分(代码、数据等)完整地放入一段连续的物理内存空间中。只有这样,程序内部指令中预设的地址才能与实际存放内容的物理地址一一对应,CPU才能正确地取指、执行和访问数据。如果物理内存不连续,程序代码中相邻的两条指令可能会被放到毫不相干的两块物理内存上,导致CPU无法顺序执行。
但是这里又会造成一个问题就是会出现内存碎片化:一开始,内存是完全空闲的。程序 A(占 20MB)、程序 B(占 30MB)、程序 C(占 10MB)依次进入内存,挨着排列。 过了一会儿,程序 B 运行结束,退出了内存。此时,在 A 和 C 之间,就留下了一个 30MB 的"空洞(Hole)"。
甚至后面还会出现更加严重的内存碎片化:接着,一个占 15MB 的程序 D 需要运行。操作系统一看,刚好 B 留下的空洞有 30MB,就把 D 放了进去。此时,原来的大空洞被切分了,剩下一个 15MB 的更小的空洞。
3-1 引入页表:
在我们之前的课程中,其实我们已经讲述过了什么是页表,但是没有详细的讲述页表是怎么映射的,在我们之前的印象中,似乎是一个虚拟地址联系着一个物理地址,事实上并非如此。如果是这样,页表所占据的内存也是一个不小的开销。
我们以32位系统为例:
- 虚拟地址空间大小 :32 位系统,总空间是 2 32 2^{32} 232 字节 = 4GB。
- 而正常的页的大小(Page Size) :通常是 4KB(即 2 12 2^{12} 212 字节)。
- 那么如果按照我们假设的映射:4GB / 4KB = 1,048,576个页。
- 一个页里面的内容:每个页的映射关系(即页表项 PTE,里面存着物理页的地址和读写权限等)需要 4 个字节。
- 最后4B 乘上 1Mb = 4MB 。得出一个进程的页表就要占据4MB。
巨大的浪费 :绝大多数程序根本用不完 4GB 的虚拟空间!比如一个简单的 "Hello World" 程序可能只用了几百 KB 的内存。但是,由于单级页表的机制,只要程序运行,操作系统就必须老老实实地为它分配完整的、覆盖 4GB 空间的 4MB 页表。如果系统里跑了 100 个进程,光页表就要吃掉 400MB 内存!这绝对是不可接受的。
3-2 引入多级页表:
在我们之前讲的时候物理内存被切成了 4KB 的块,4KB = 4096B = 2 12 2^{12} 212。我们记住这个数字,这样我们只需12个比特就能查询每一个每一个块中的地址。
我们一般引入多级页表,一般情况如下:
10-10-12 的描述:前 10 位是页目录,中 10 位是二级页表,后 12 位是页内偏移。
在 32 位(32-bit)的计算机系统中,CPU 内部用来存放内存地址的寄存器(可以理解为指针)长度就是 32 个二进制位。这 32 个由 0 和 1 组成的位,能组合出多少种不同的地址呢? 答案就是 2 32 2^{32} 232 种。
那么我们就要合理分配这32个数字:
- 前10位表示页表的目录,可以表是1024个页表。决定了这 4GB 空间里的最高层级。 2 10 2^{10} 210 = 1024,对应页目录表里的 1024 个目录项。
- 中10位就是每个页表的对应物理内存块的地址。也就决定了中间层级。 2 10 2^{10} 210 = 1024,对应二级页表里的 1024 个页表项。
- 后12位,刚好是4KB,对应一个块的地址。找到了具体的物理页之后,用来在页内找具体的字节。 2 12 2^{12} 212 = 4096 字节(也就是 4KB)。通过偏移量来寻找。
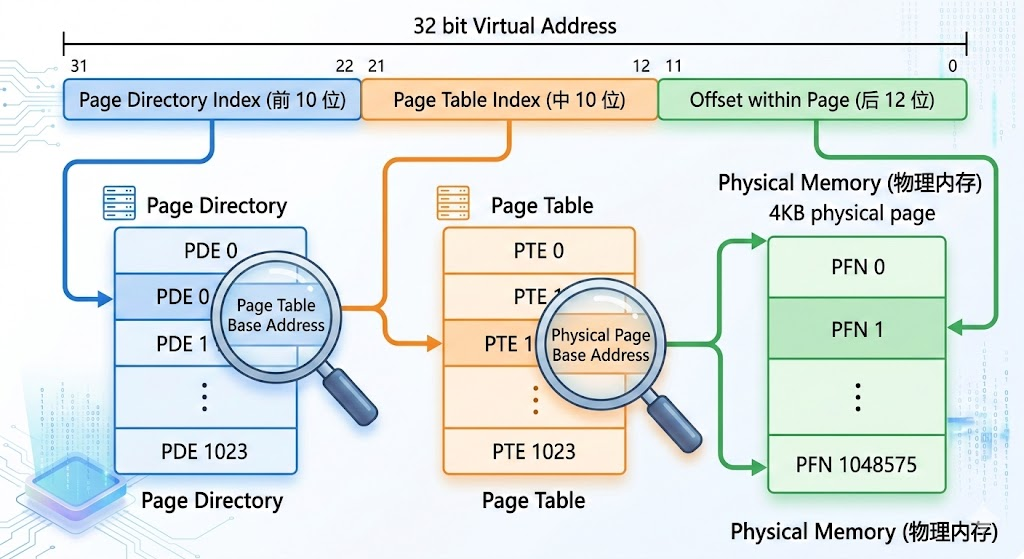
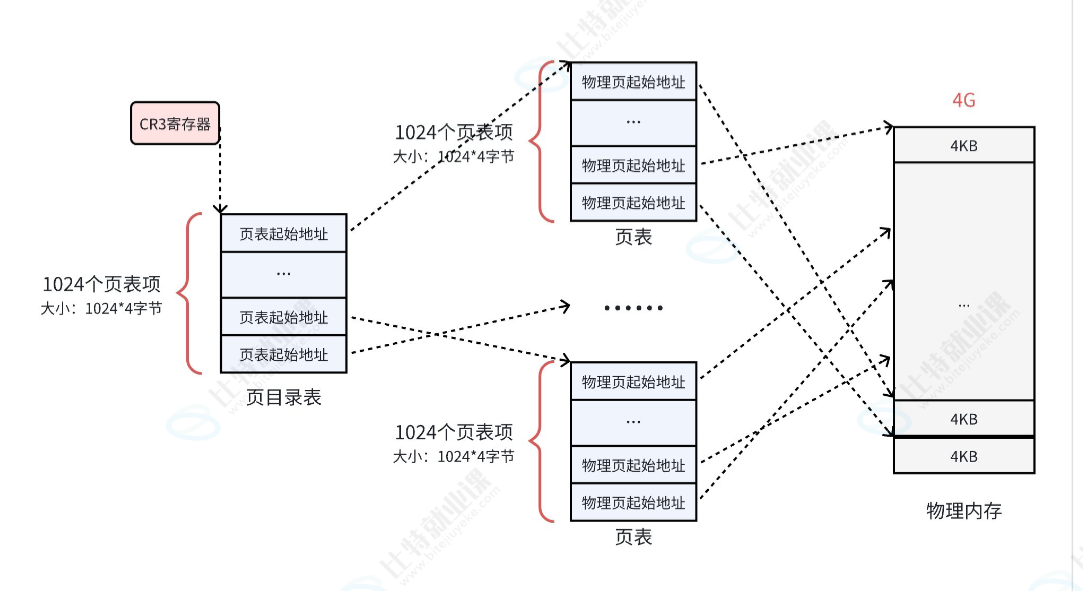
但是这种结构还是有一个问题,就是查询太消耗时间了。
3-3 引入快表:
为了填补多级页表带来的速度大坑,CPU 内部引入了一个极其昂贵、速度极快的小型存储器,叫做 TLB(Translation Lookaside Buffer,通常翻译为"快表"或"旁路转换缓冲") 。
TLB 里面直接缓存了最近使用过的 【虚拟页号 → \rightarrow → 物理页框号】 的映射关系。它把 10+10 的查找过程直接跳过了!
当 CPU 拿到一个虚拟地址时,它现在的标准动作是这样的:
- 先查 TLB(极速):CPU 拿着虚拟地址先去问 TLB。
- TLB 命中(Hit) :如果这张便签里记了这个地址,CPU 瞬间 就拿到了物理地址,直接去物理内存拿数据。中间那两次查页目录和二级页表的过程直接被省略了!
- TLB 未命中(Miss) :只有当 TLB 里没有记录时,CPU 才会叹口气,老老实实去内存里走那套"慢吞吞"的 10-10-12 多级查表流程。查到之后,不仅去拿数据,还会把这次查到的映射关系抄写到 TLB 这张便签上,方便下次使用。
因为局部性原理,现代 CPU 的 TLB 命中率通常高达 98% 甚至 99% 以上!
4. tid和pthread_t的区别:
为了讲清楚这个,我们必须要弄清楚:Linux下是没有线程这个概念的,我们对之前的代码可以进行稍微的进行调整:
cpp
void* threadRun(void* arg)
{
//arg 从void* 转换成为string*,再次解引用。
std::string name = *(static_cast<std::string*> (arg));
std::cout << name;
printf("%p\n",pthread_self());
//可以放回值,但是比如我要放回一个堆上的值才行:
std::string* message = new std::string("i am ok");
sleep(10);
return message;
}
int main()
{
pthread_t tid;
std::string arg = "pthread-";
int n = pthread_create(&tid,nullptr,threadRun,&arg);
void* res = nullptr;
pthread_join(tid,&res);
std::string ret = *(static_cast<std::string*>(res));
sleep(2);
std::cout << ret << std::endl;
delete static_cast<std::string*>(res);
return 0;
}当我们运行的时候,我们同时查询线程的LWP:
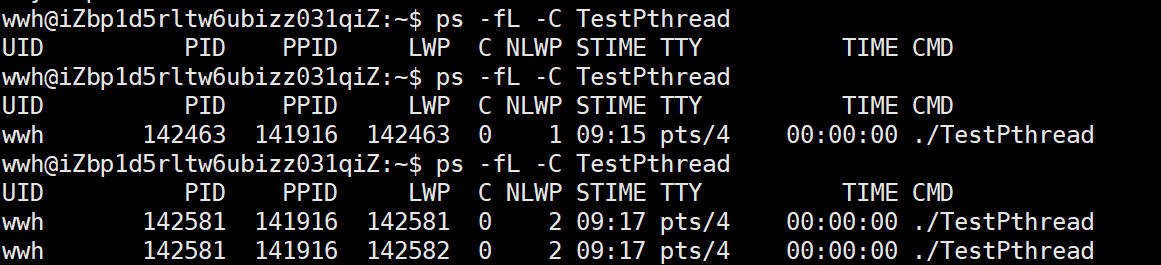

| 标识符 | 主线程 (LWP 142581) | 子线程 (LWP 142582) | 备注 |
|---|---|---|---|
| PID (内核叫法) | 142581 | 142582 | 内核看它们是两个独立的调度实体 |
| TGID (进程组 ID) | 142581 | 142581 | 它们对外宣称自己属于同一个进程 |
| 用户态 PID | 142581 | 142581 | getpid() 函数在两个线程里返回的值是一样的 |
那么这个pthread_t到底时什么呢? |
|||
结论先行:是的,在 Linux(基于 glibc 和 NPTL 线程库)的实现中,pthread_t 本质上就是一个内存地址(指针)! |
- POSIX 标准的障眼法 在 POSIX 标准中,
pthread_t被定义为一个"不透明的数据类型(Opaque Type)",用来作为线程的唯一标识符。标准并没有规定它必须是整数还是结构体,只是让开发者把它当成一个 ID 来看待。 - Linux glibc 的真实面目 但是,当你扒开 Linux 下 glibc(GNU C Library)的源码,你会发现
pthread_t通常被typedef为unsigned long int。 而这个长整型里存的值,正是一个指向名为struct pthread的结构体的内存地址 。 这个struct pthread就是大名鼎鼎的 线程控制块(TCB, Thread Control Block)。在这个结构体里,记录了属于这个用户态线程的各种私有信息:比如线程局部存储(TLS)的指针、取消状态、调度策略等。
那么这个地址到底指向那里,难道也是某个结构体的首位地址吗?
答案 - 是的,因为 Linux 内核太"糙"了,懒得去管复杂的线程同步和属性,所以 glibc 就在用户态封装了一套 NPTL (Native POSIX Thread Library)。pthread_t 就是 glibc 为了在用户态自己管理这些 LWP,而搞出来的一个指向用户态结构体(TCB)的内存地址。
5. 总结
这篇文章的核心在于从Linux的视角重新梳理"进程"与"线程"的概念,并深入剖析了支撑其运行的虚拟内存与页表机制。
首先,文章明确了线程是进程内部的执行分支 ,在Linux中,内核并未单独为线程设计数据结构,而是复用task_struct(进程控制块)来管理线程 ,因此线程被称为轻量级进程(LWP)。这导致了Linux线程"一荣俱荣,一损俱损"的特点,并与Windows平台(区分EPROCESS和ETHREAD)"进程是容器,线程是灵魂"的设计哲学形成鲜明对比。理解这种Linux与Windows线程模型的根本差异及其背后的设计哲学 是极为重要的知识点,也是面试高频考点。文章还初步介绍了POSIX线程库的使用,并通过ps -eLf命令揭示了Linux内核视角下,线程拥有独立的LWP,但共享同一个TGID(进程ID)的实质,进而解释了pthread_t实为用户态线程库(NPTL)管理的TCB地址。
其次,文章深入探讨了虚拟地址到物理地址的转换机制 ,这是支撑多线程/多进程内存隔离与共享的基础。为了解决早期连续内存分配导致的内存碎片和单级页表空间浪费问题,现代操作系统普遍采用多级页表 (如文中详述的32位系统10-10-12结构)进行地址映射。为了加速这一过程,CPU引入了TLB(快表) 缓存常用映射。理解多级页表如何工作、为何能节省空间,以及TLB如何利用局部性原理极大提升寻址效率,是操作系统和性能优化领域的核心知识,必然是面试重点考察内容。
谢谢大家的观看,能看到这里真的很厉害啊。
感谢各位对本篇文章的支持。谢谢各位点个三连吧!

