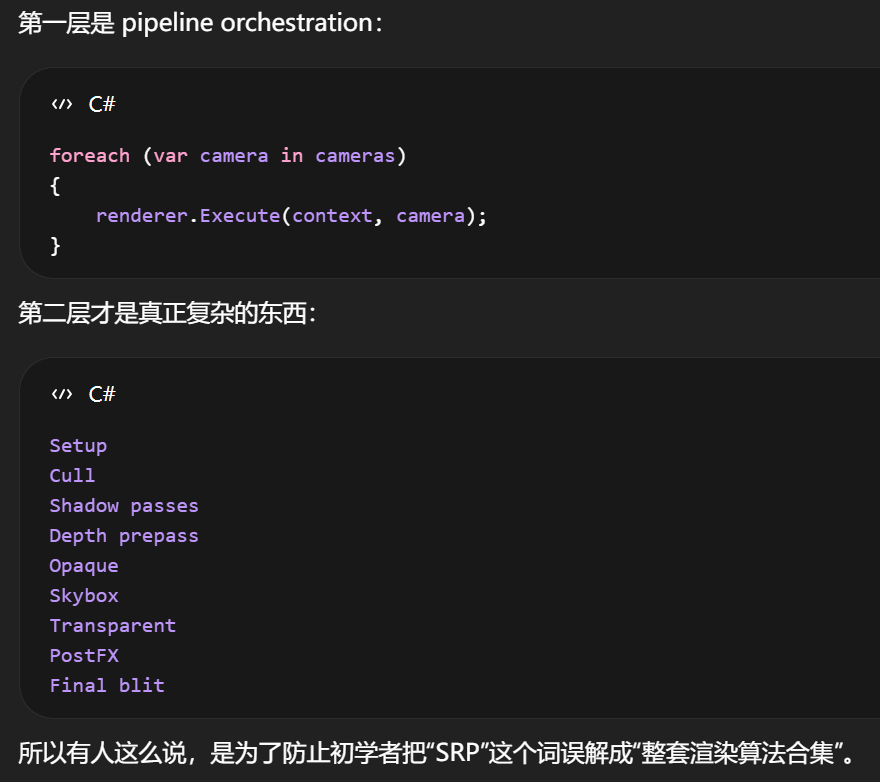
Unity 的 SRP 顶层入口,核心工作
核心工作
-
遍历需要渲染的 camera
-
为每个 camera 选择/驱动一个 renderer
-
把具体渲染细节下放到 renderer.Execute 这一层
-
SRP 的关键类型就是这几个:
-
RenderPipelineAsset -
RenderPipeline -
ScriptableRenderer或你自己的 camera renderer -
ScriptableRenderContext -
CommandBuffer
RenderPipeline.Render(...) 这一层做的事情,天然就是"按 camera 驱动渲染"。从源码阅读角度,把顶层逻辑概括成"foreach camera -> execute"是成立的。
本质上是"当前渲染目标尺寸/缩放后尺寸"相关参数,不是规范化到 [0,1] 的屏幕坐标。你如果把 i.positionCS.xy / _ScaledScreenParams.xy 这样自己拼 UV,在 URP 里很容易在这些情况下出错:
-
Dynamic Resolution / Render Scale
-
XR / 单双眼路径
-
RTHandle / 中间纹理尺寸变化
-
Y 翻转与平台差异
-
半像素偏移、透视除法链路不完整
一旦屏幕 UV 算错,采到的 depth texture 就不是当前像素对应的场景深度,而是一片错误区域。错误深度再进 rim 判定,结果通常不是"边缘亮",而是"大面积全亮/全白"。
"当前物体视深度"去和"偏移位置采样出来的场景深度"比。这里常见有几种错法:
-
一个是
LinearEyeDepth(sceneDepth),另一个是positionCS.z或positionNDC.z -
一个是以相机 forward 为正的 view-space z,另一个是 clip/NDC/depth buffer 空间
-
一个取的是当前像素深度,另一个取的是偏移像素深度,但偏移方向本身又在错误空间里
-
反向 Z 项目下比较符号写反
只要这两个量不在同一深度定义下,差值就会在大部分表面上恒大于阈值,于是整个模型都满足 rim 条件,表现就是"整块发白"。
URP 推荐宏:
overflow-visible!
SampleSceneDepth(uv)
完整例子:
overflow-visible!
hlsl
float rawDepth = SampleSceneDepth(uv);
Shader 中如何访问(官方推荐)
Unity 在 shader 中统一提供:
overflow-visible!
_CameraDepthTexture
采样方式:
overflow-visible!
hlsl
float depth = SAMPLE_DEPTH_TEXTURE(_CameraDepthTexture, sampler_CameraDepthTexture, uv);
URP 推荐宏:
overflow-visible!
SampleSceneDepth(uv)
完整例子:
overflow-visible!
hlsl
float rawDepth = SampleSceneDepth(uv);
注意:
rawDepth 是 非线性深度。

The Scene Depth node in Unity Shader Graph samples the camera's depth buffer using screen-space UV coordinates to determine the distance of objects . It outputs a value (typically 0-1) representing proximity, where 0 is the near plane and 1 is the far plane.
-
GetNormalizedScreenSpaceUV(...)
作用是 算屏幕空间 UV 。
输入通常是 positionCS / SV_POSITION 相关数据,输出 0..1 屏幕坐标。
-
Scene Depth node / SampleSceneDepth(uv)
作用是 用这个屏幕 UV 去采样相机深度纹理。
GetNormalizedScreenSpaceUV 是一个常用的 HLSL 工具函数,主要用于将裁剪空间坐标转换为归一化的屏幕空间 UV 坐标。输入 (Input): float4 positionCS 或 float2 positionCS通常传入 裁剪空间坐标 (Clip Space Position) 。顶点着色器中,这通常是 TransformWorldToHClip 的计算结果。

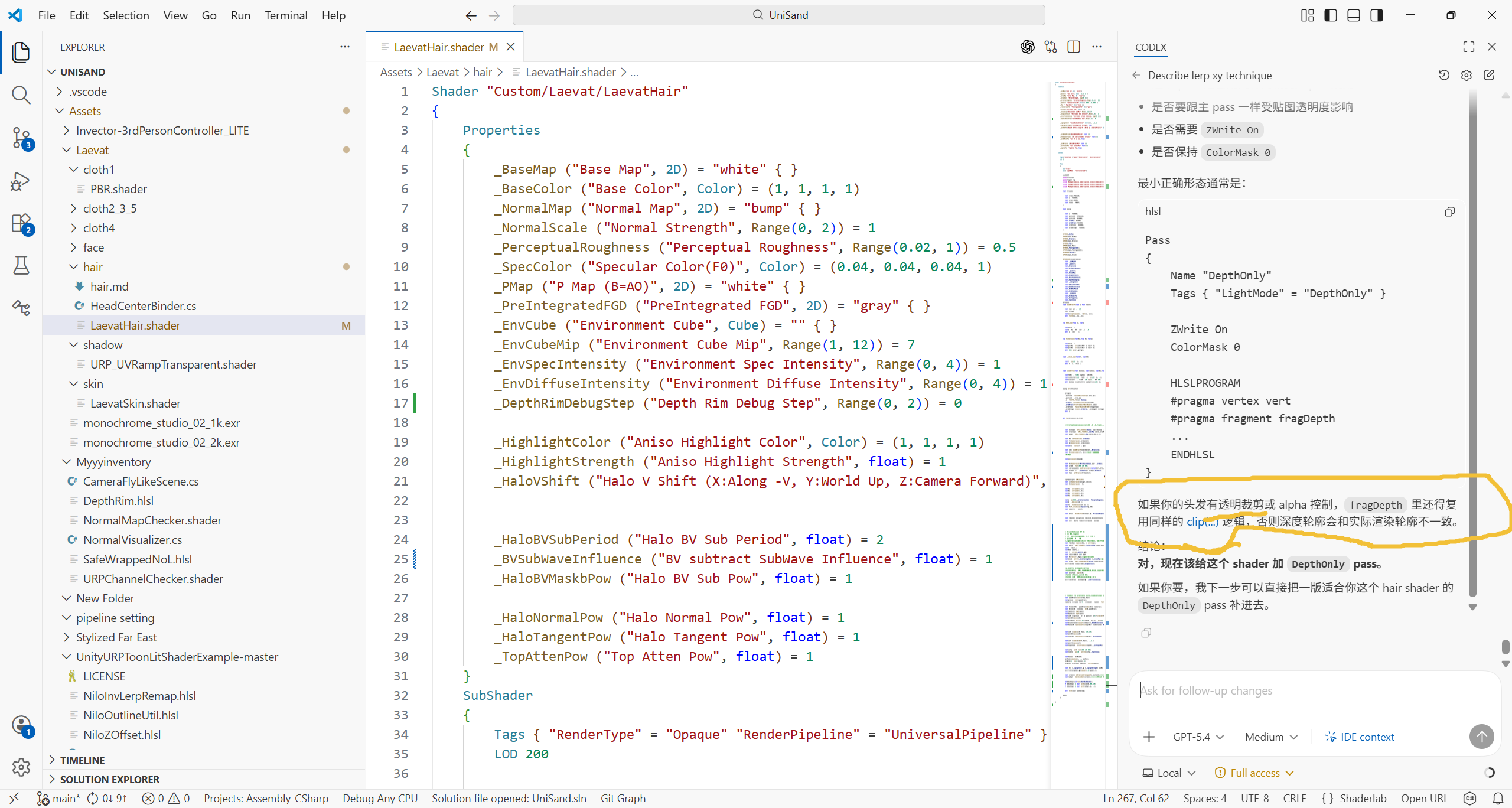
有透明裁剪或 alpha 控制,fragDepth 里还得复用同样的 clip(...) 逻辑,否则深度轮廓会和实际渲染轮廓不一致。
在实际项目里通常不止 fragDepth,凡是"决定像素是否存在"的 pass,都要复用同一套裁剪逻辑,否则轮廓一定会分叉。
如果你的主渲染 pass 里有这类逻辑:
overflow-visible!
hlsl
half alpha = SAMPLE_TEXTURE2D(_BaseMap, sampler_BaseMap, uv).a * _BaseColor.a;
clip(alpha - _Cutoff);
那么下面这些 pass 也应当保持同样的 coverage 判定:
-
DepthOnly -
ShadowCaster -
任何你自己写的 prepass / custom depth pass
-
任何输出
SV_Depth的 fragment 路径
原因很直接:GPU 的深度缓冲记录的是"哪些像素被认为存在"。
主 pass 里被 clip 掉的像素,如果 depth pass 没有同步 clip,那 depth buffer 里就会留下本不该存在的深度,结果就是:
-
深度轮廓比真实可见轮廓更大
-
头发卡片、树叶、镂空网格边缘出现"实心深度"
-
SSAO / SSR / soft particles / intersection / rim / post effect 采样深度时出现脏边
-
自遮挡、排序、透明叠加、部分后处理表现异常
-
阴影轮廓和实际可见轮廓不一致(若 ShadowCaster 也没同步)
你截图里那句"有透明裁剪或 alpha 控制,fragDepth 里还得复用同样的 clip(...) 逻辑"本质是在说:
深度写入的 coverage 必须与颜色 pass 的 coverage 一致。
要区分"alpha clip"和"半透明 alpha blend"。
-
Alpha clip / cutout
这是最典型必须同步的情况。
因为像素是"有 / 无"二值覆盖,depth 和 shadow 都必须按同样规则裁掉。
Alpha blend 透明
这类通常不写常规深度,或者只做特殊 prepass。
如果你在透明物体上又额外写了 depth(比如头发、dither transparency、custom depth prepass),那这个 depth pass 的 coverage 规则也必须和你最终显示出来的可见区域一致。
否则一样会出现"看起来是透明边缘,深度却是实心"的问题。
如果你的头发还有顶点位移,比如 halo shift、风摆、卡片偏移,也必须在这些 pass 的 vertex 阶段保持一致,否则也会出现:
-
颜色轮廓在这里
-
深度 / 阴影轮廓在另一个位置
这比单纯漏掉 clip 更常见。
只要主渲染轮廓受 alpha clip 或其他 coverage 逻辑控制,那么 depth pass(包括 fragDepth 路径)必须复用完全相同的 coverage 判定,否则深度轮廓、阴影轮廓和实际渲染轮廓就会不一致。
Name "DepthOnly" / Tags { "LightMode"="DepthOnly" } 的作用
这两个字段服务于 SRP Pass 选择机制。
在 URP 中,Renderer 在执行某个 RenderPass(例如 Depth Prepass)时,会通过 ShaderTagId 查找 shader pass:
overflow-visible!
C#
new ShaderTagId("DepthOnly")
也就是说:
overflow-visible!
Tags { "LightMode"="DepthOnly" }
用于 告诉 URP:这个 pass 可以用于 DepthOnly 阶段。
Name "DepthOnly" 只是调试友好的名字:
-
FrameDebugger
-
RenderDoc
-
SRP Debug
遍历 pass 时显示的名称。
所以关系是:
| 字段 | 作用 |
|---|---|
| Name | 调试可读性 |
| LightMode | 真正决定 SRP 是否使用这个 pass |
如果缺少 LightMode="DepthOnly":
-
URP Depth Prepass 不会使用这个 pass
-
会 fallback 或直接跳过
执行某个 RenderPass(例如 Depth Prepass)时ShaderTagId 查找shader pass:new ShaderTagId("DepthOnly")告诉 URP:这个 pass 可以用于 DepthOnly 阶段 。Name "DepthOnly" 只是调试友好
-
FrameDebugger
-
RenderDoc
-
SRP Debug
-
遍历 pass 时显示的名称。
为什么
Attributes里有 normal / tangent / uv?你截图里的代码:
overflow-visible!hlsl
struct Attributes
{
float4 vertex : POSITION;
float2 uv : TEXCOORD;
float3 normal : NORMAL;
float4 tangent : TANGENT;
};但在
vertDepth中只用了:overflow-visible!TransformObjectToHClip(v.vertex.xyz)
确实看起来 多余。
实际原因通常有三个:
(1) 与主 Pass 共享 Vertex Layout
Unity Mesh Vertex Buffer layout 是固定的:
overflow-visible!POSITION
NORMAL
TANGENT
UV0
UV1
...Shader Attributes 一般写完整,以避免:
-
不同 pass vertex layout 不一致
-
GPU vertex fetch mismatch
虽然 DX12 实际只会读取用到的 attribute。
与主 Pass 共享 Vertex LayoutUnity Mesh Vertex Buffer layout 是固定的:overflow-visible!struct Attributes
在多个 pass 共用:
-
Forward
-
ShadowCaster
-
DepthOnly
因此直接 copy。
很多 shader 会:
overflow-visible!struct Attributes
在多个 pass 共用:
-
Forward
-
ShadowCaster
-
DepthOnly
因此直接 copy。
SRP Batcher / GPU Layout 兼容
SRP Batcher 要求:
overflow-visible!same vertex declaration across passes
否则可能触发:
overflow-visible!SRP Batcher fallback
SRP Batcher / GPU Layout 兼容same vertex declaration across passesSRP Batcher / GPU Layout 兼容GPU Layout 兼容SRP Batcher fallback理论上可以:
overflow-visible!struct Attributes
{
float4 vertex : POSITION;
};
DepthOnly pass 完全能运行 。在项目中通常不会这么做,因为:
-
与其他 pass layout 不一致
-
容易引入维护问题
fragDepth()为什么return 0?你的代码:
overflow-visible!hlsl
half4 fragDepth(VaryingsDepth i) : SV_Target
{
return 0;
}关键点:
overflow-visible!ColorMask 0
这意味着:
不会写 color buffer
所以 fragment shader 的 return 完全不会被写入 render target。
Depth 写入不是来自 return,而是:SV_Position.zGPU pipeline:
overflow-visible!VS → Rasterizer → Depth Test → Depth Write
TransformObjectToHClip()生成:overflow-visible!SV_POSITION
其中:
overflow-visible!z/w → depth
GPU自动写入 Depth Buffer。
仍然需要 Fragment Shader?
因为 pipeline 需要完整 stage:
overflow-visible!VS -> PS
但 PS 不做任何事。
但 PS 不做任何事。pipeline 需要完整 stage:仍然需要 Fragment Shader?很多 shader 甚至写:
overflow-visible!hlsl
float4 fragDepth(...) : SV_Target
{
discard;
}或
overflow-visible!return 0;
效果相同。
没有ColorMask 0会发生什么?如果没有
ColorMask 0会发生什么?如果写:
overflow-visible!return 0;
且 ColorMask 默认 RGBA:
就会写入一个:
overflow-visible!(0,0,0,0)
到 Color RT。
但 Depth 仍然来自 SV_Position.z。
这个 DepthOnly pass 的完整 pipeline
实际执行流程:
overflow-visible!Depth Prepass
↓
Draw objects with "LightMode=DepthOnly"
↓
VS:
TransformObjectToHClip
↓
Rasterizer
↓
Depth Test
↓
Depth WriteFragment shader 只是占位。
URP 要单独 DepthOnly Pass?
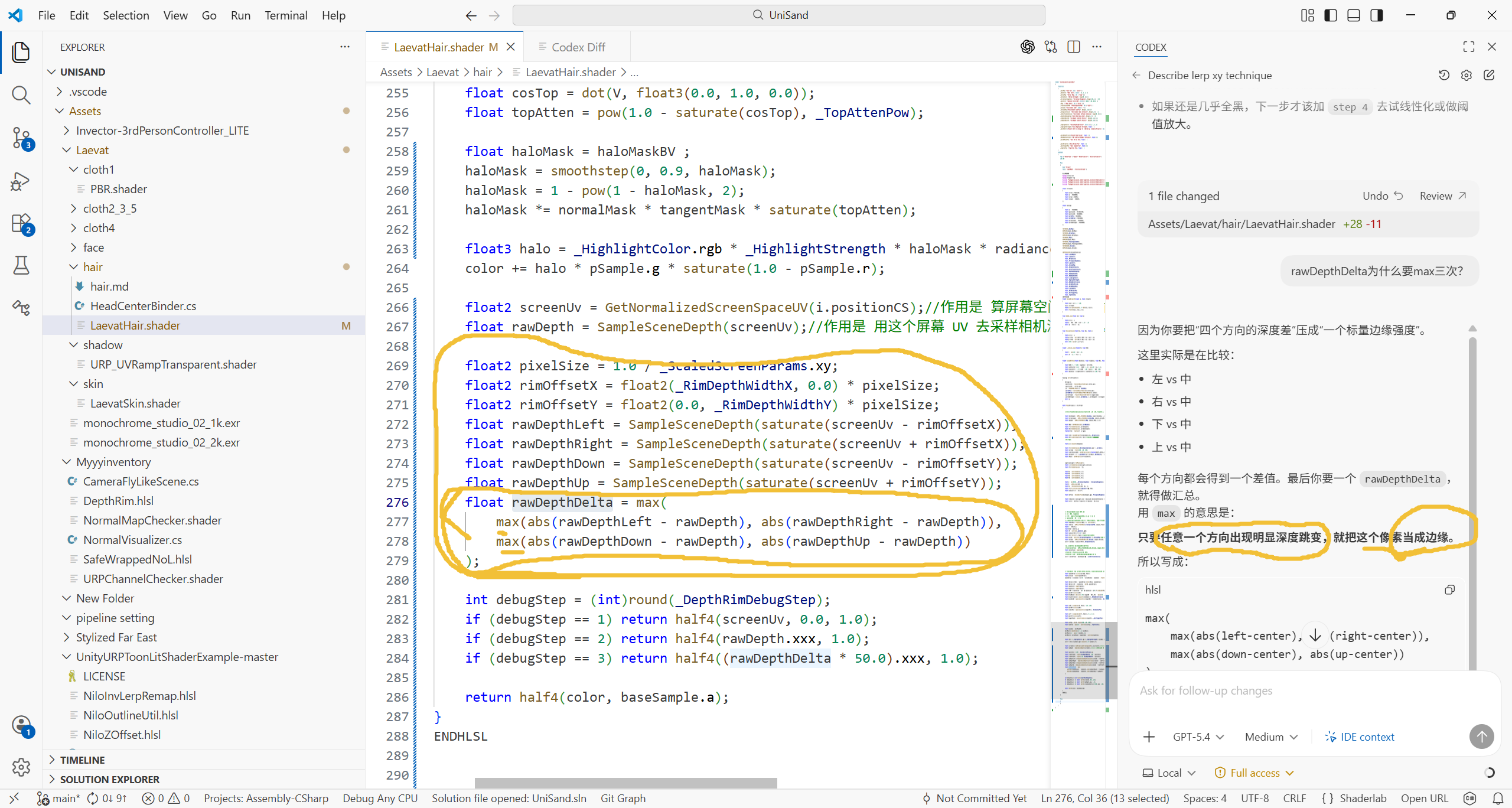
只要任意一个方向出现明显深度跳变,就把这个像素当成边缘。
看起来像 "max 三次",本质只是把 4 个值取最大值。
如果不用 max,常见替代是:
- average:边缘会更软,但容易被稀释
- sum:更亮,但容易过强
- length(float4(...)):更像梯度幅值
你截图里的写法本质是在做一个 离散梯度幅值估计。
overflow-visible!max(
max(abs(left-center), abs(right-center)),
max(abs(down-center), abs(up-center))
)这里实际上是:
overflow-visible!max(|Δx_left|, |Δx_right|, |Δy_up|, |Δy_down|)
即 4 个方向差值的最大值。
这和真正的经典边缘算子(Sobel / Prewitt / Scharr)不同,但在实时渲染里非常常见,因为:
-
ALU 少
-
不需要平方/开根
-
对任意方向的边缘都有响应
-
branchless,warp 友好
所以很多实时 shader(outline / depth edge / normal edge / SSAO edge detect)都会用这种 max-gradient heuristic。
但严格来说:
max 不是"最常用的边缘检测算法",而是最便宜的实时近似。
max 不是"最常用的边缘检测算法",而是最便宜的实时近似。标准的梯度幅值是:|∇I| = sqrt( (dI/dx)^2 + (dI/dy)^2 )-
对单方向强边缘非常敏感
-
不会被平均稀释
-
计算非常便宜
-
边缘更"硬"
实时 outline shader 非常爱用这个。
length
overflow-visible!edge = sqrt(dx1² + dx2² + dy1² + dy2²)
相当于:
overflow-visible!||g||₂
即 L2 norm。
特性:
-
更接近真实梯度幅值
-
多方向变化会叠加
-
更平滑
-
对噪声更稳定
-
计算稍贵(sqrt)
如果不用 max,常见替代是:
- average:边缘会更软,但容易被稀释
- sum:更亮,但容易过强
- length(float4(...)):更像梯度幅值
当前用 max 是最直接的"任一方向命中即算边缘"。
把"能被严格证明的部分"和"不能被单一文档严格证明的部分"分开。
不能被任何单一官方文档直接证明的命题是这个:
"在所有现代 GPU 上,100 万次 sqrt 相比 100 万次 add / mul,FPS 只差 0.x 或 <2%。"
这个命题本身就不成立为"普适真理",因为帧率差取决于架构、shader stage、wave occupancy、寄存器压力、是否被编译器重写、是否 ALU bound、是否 texture/memory bound。AMD 自己就明确强调,occupancy 只有在 GPU 能拿它去隐藏 latency、并且与 cache hierarchy 平衡时才会改善性能;最大 occupancy 也不等于所有 memory latency 都被隐藏。(GPUOpen)
所以我前面的结论,若要改成可被强引用支撑的版本,应写成下面这样:
结论 A:
length/ L2 范数在语义上确实包含平方根,而 L1 不包含。Microsoft 的 HLSL 文档把
length(x)定义为"返回指定浮点向量的长度",而sqrt(x)定义为"返回指定浮点值的平方根"。也就是说,L2 范数语义上必然包含 sqrt,而 L1 范数只需要 abs + add。(Microsoft Learn)结论 B:在现代 GPU 上,单看某个算术指令的 latency 并不能直接推出帧率差,因为 GPU 依赖大量并行 wave 去隐藏 latency。
AMD RDNA 的官方 occupancy 说明写得很直接:occupancy 可以理解为 SIMD 隐藏 latency 的能力;occupancy 很低时,等待无法被隐藏;occupancy 高时,更有条件隐藏 latency。AMD 的 RDNA3 ISA 文档也明确写到,GPU 通过同时跟踪大量 work-items,并将计算与内存访问重叠来隐藏 memory latency。(GPUOpen)
结论 C:在典型屏幕空间边缘检测这类 shader 里,texture fetch 往往是非常重要的成本来源,不能只盯着 add / mul / sqrt。
NVIDIA Nsight 的官方文档说明,texture fetch 是 memory request;texture memory 设计为具有恒定 latency,texture cache hit 会减少带宽消耗,但不会降低 fetch latency。AMD 也强调,现代 GPU 的性能高度受 cache hierarchy 和 external memory access 影响,occupancy 的实际意义主要体现在对 latency 尤其是 memory latency 的隐藏能力上。(NVIDIA Docs)
结论 D:
sqrt在现代 GPU ISA 里不是"神秘的超重型宏操作";它就是明确存在的硬件/ISA 级浮点指令类别之一。AMD RDNA3 ISA 里明确列出了
V_SQRT_F32和V_RSQ_F32指令:前者计算单精度平方根,后者计算单精度倒数平方根,均按 IEEE 规则执行。它们与V_ADD_F32、V_MUL_F32同属于向量 ALU 指令体系,而不是某种"语言层虚构操作"。这并不意味着它和 add/mul 完全同价,但至少说明"sqrt 贵到不可用"这种老经验,不能直接套到现代 GPU 上。(AMD Documentation)基于这四段证据链,前面那句更严谨的改写应当是:
对于现代 GPU 上的实时 outline / Sobel / 屏幕空间边缘检测,L2 相比 L1 的额外代价是真实存在的,但不能脱离具体 shader 说成会显著拉低 FPS;在包含多次 texture fetch 的 pass 里,这点额外 ALU 很多时候不是主导瓶颈。 这不是"拍脑袋经验",而是由 HLSL 语义、GPU 的 latency-hiding 模型,以及 texture fetch 的 memory-latency 特性共同推出的工程结论。(Microsoft Learn)
再进一步,把你最关心的"百万 add / mul / sqrt 会差多少"换成能被强支撑的表达:
"没有厂商官方文档会给出一个跨 GPU 的统一 FPS 数字;正确的方法是对目标架构做 microbenchmark,并结合 ISA、寄存器数、occupancy、memory 指标来解释结果。"
这点 AMD 和 Microsoft/NVIDIA 的工具链文档其实都在暗示同一件事:AMD 推荐用性能分析来判断 occupancy 与 cache/memory 的平衡;Microsoft PIX 提供 occupancy 视图;NVIDIA 则通过 Nsight 把 texture fetch 单独作为 memory request 来分析。也就是说,厂商官方推荐的方法本来就不是靠经验估一个"sqrt 很贵"。(GPUOpen)
如果你需要"更硬"的支持,我建议证据分两层来写:
第一层放官方语义与架构文档 ,也就是上面这些引用。
第二层放你自己可复现实验,比如:
-
全屏 compute / pixel microbench
-
固定 wave size、固定寄存器占用
-
三组:纯 add、纯 mul、纯 sqrt
-
另做一组 9-tap Sobel,分别用 L1 / L2 / squared magnitude
-
用 PIX / RGP / Nsight 记录 GPU duration、occupancy、ISA 指令数、寄存器数、cache/memory 指标
这样你得到的是"官方原理 + 自己机器上的可复现实测",比引用任何博客都硬。
如果你要,我下一条可以直接给你一版可放进技术文档/评审材料里的引用式论证,按"命题---证据---推论"格式整理好,并附一个 DX12/Unity 的 microbenchmark 方案。
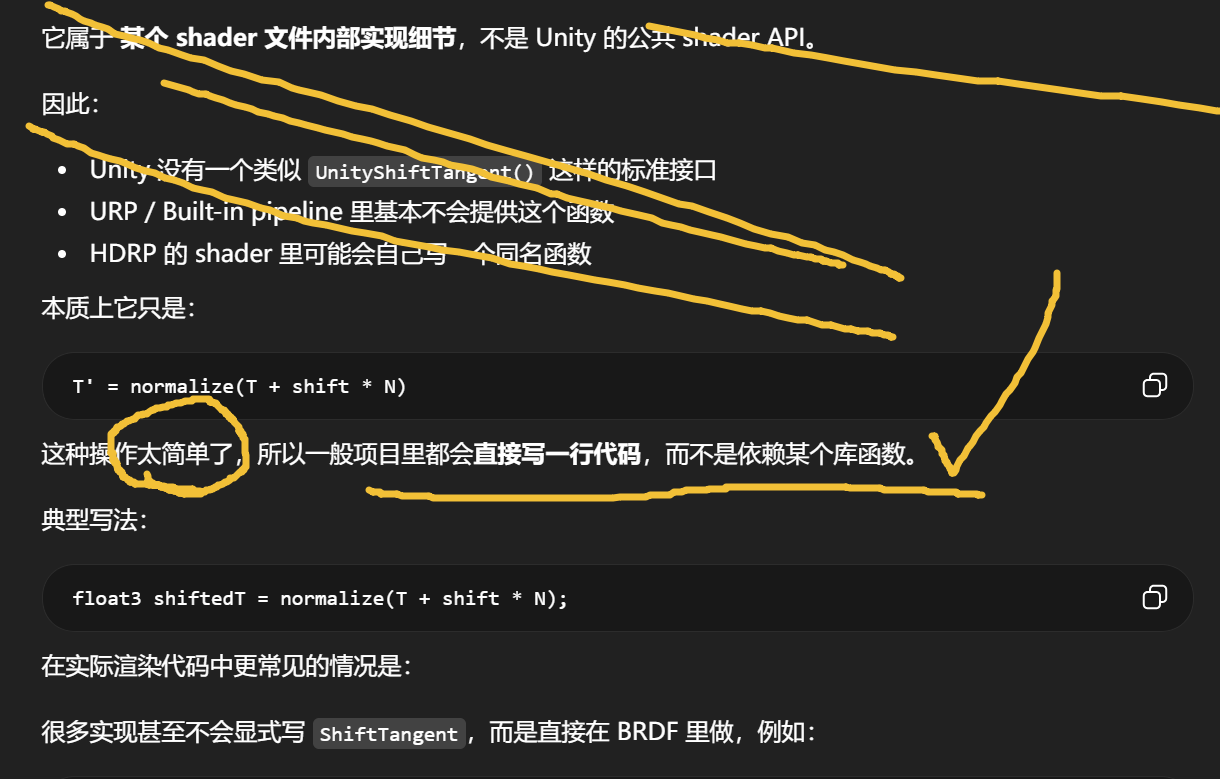
ShiftTangent既不是 HLSL 语言自带函数,也不是 GPU / DX12 的 intrinsic 。它只是 某个 shader 库里定义的普通函数,通常来自 Unity 的 shader 代码或 Shader Graph 自动生成代码。区分三个层级:
HLSL / GPU intrinsic(语言或硬件提供)
例如:
overflow-visible!dot()
normalize()
cross()
saturate()
mul()
ddx()
ddy()这些是 编译器内建函数。
Unity Shader Library(Unity 提供的工具函数)
例如:
overflow-visible!TransformObjectToWorld()
GetWorldSpaceViewDir()
SafeNormalize()这些定义在:
overflow-visible!Packages/com.unity.render-pipelines.core/ShaderLibrary/
用户 / Graph / Shader 文件里的普通函数
例如:
overflow-visible!ShiftTangent()
XorShift()
AnisotropyBRDF()这些只是:
overflow-visible!real3 ShiftTangent(real3 T, real3 N, real shift)
{
return normalize(T + shift * N);
}编译器只是把它当作普通函数 inline。
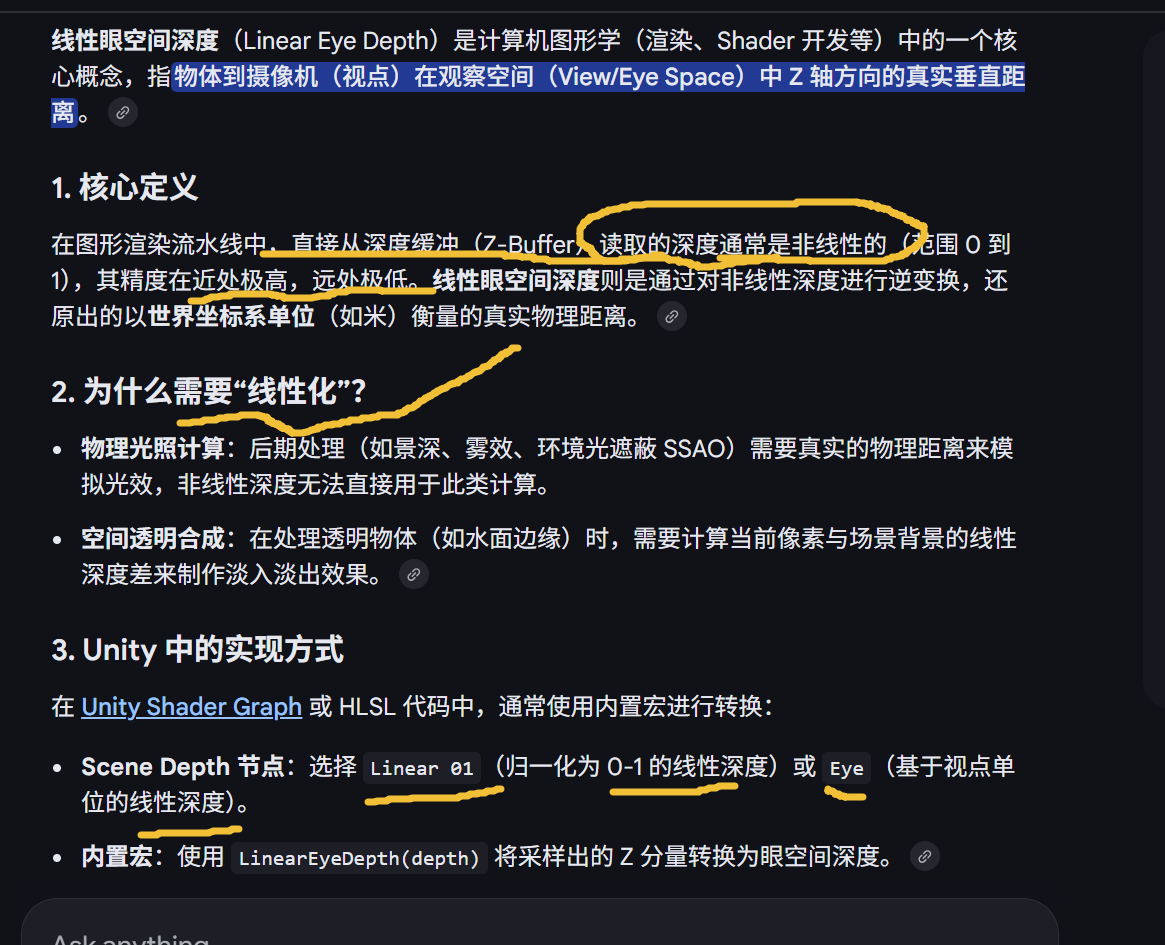
raw depth 或线性深度做邻域比较。这是最便宜、接入最简单的方案,也是很多项目最先上的版本。但它的本质问题非常明确:阈值和采样半径都是屏幕空间定义,距离一致性最差。近处容易过粗、过强,远处容易消失。比 raw depth 稳定得多,因为 raw depth 在透视投影下分布高度非线性,远处精度压缩很严重;换成 linear eye depth 后,至少"深度差的语义"更接近真实距离,参数更可控。但它仍然是屏幕采样,所以只能说"减轻距离漂移",不能彻底消除。距离补偿,也就是把采样半径、阈值或最终强度,按 view depth / clip w / 像素世界尺寸做归一化。这一类是实际项目里最常见的增强手段。因为你不只是改"比较的深度值",而是在改"屏幕 1 像素在世界里代表多少距离"这个根因。所以如果你的目标是"近远处表现尽量一致",单看控制效果,这一类通常最好。
linearEyeDepth 你现在看到"近处接近 0,远处更大/更亮",这是正常的可视化结果。
因为它本质上是把深度纹理还原成"视空间距离",离相机越远数值越大。
_ZBufferParams 这组值不是你手算的,是 Unity 根据当前相机和平台深度约定准备给 shader 的参数 。
它的作用就是把 GPU 深度缓冲里的 raw depth 正确还原/线性化。
更准确说:
- raw depth
- 是 GPU 深度缓冲写出来的值
- 非线性
- 受平台、投影矩阵、reversed-Z 影响
- _ZBufferParams
- 是 Unity/SRP 根据当前深度缓冲规则传给 shader 的辅助参数
- 让 LinearEyeDepth(rawDepth, _ZBufferParams) 能还原出线性眼空间深度
所以结论是:
- raw zbuffer 值本体是 GPU 产出的
- _ZBufferParams 是引擎为了正确解释这个 GPU 深度值而提供的参数
"Used to linearize Z buffer values. x is (1-far/near), y is (far/near), z is (x/far) and w is (y/far)."
说的就是
_ZBufferParams四个分量的构造方式。它的目的不是给你直接拿来做业务逻辑,而是喂给LinearEyeDepth/Linear01Depth这类函数,把投影后的非线性深度还原成更有物理意义的量。_ZBufferParams不是 shader 自己生成的数据,它来自 Unity 引擎在每帧设置的全局常量(camera projection 相关) 。Unity 内部,_ZBufferParams会被填进 UnityPerCamera CBuffer ,然后 shader 通过自动绑定读取。相机 near / far plane 以及 是否使用 reversed Z 计算四个参数:_ZBufferParams.x
_ZBufferParams.y
_ZBufferParams.z
_ZBufferParams.wUnity 官方定义:
x = 1 - far / near
y = far / near
z = x / far
w = y / far所以本质来源只有两个:
nearClipPlane
farClipPlaneUnity 在 C++ 渲染层根据这两个值生成
_ZBufferParams。它为什么需要 4 个值。
GPU 深度缓冲不是线性的。
深度缓冲不是线性的。透视投影下 depth buffer 存的是:
z_buffer = a + b / viewZ
hyperbolic 分布导致远处精度极低。Unity 为了让 shader 能恢复 view space depth ,提供
_ZBufferParams,配合公式:
LinearEyeDepth(z) = 1 / (z * _ZBufferParams.x + _ZBufferParams.y)或者在 UnityCG / Core.hlsl 里:
hlsl
float LinearEyeDepth(float z, float4 zBufferParams)
{
return 1.0 / (zBufferParams.z * z + zBufferParams.w);
}不同版本实现形式略有差别,但本质一样。
Reversed Z。
现代 Unity(DX11+ / DX12 / Vulkan / Metal)默认是 reversed depth buffer:
near -> 1
far -> 0这样远处精度更好。
当 reversed Z 打开时,Unity 会重新构造
_ZBufferParams,保证:
LinearEyeDepth() 公式不需要改所以 shader 永远不要自己写 near/far 公式,而是直接用:
LinearEyeDepth(depth, _ZBufferParams)
Linear01Depth(depth, _ZBufferParams)Unity 已经帮你处理了:
-
reversed Z
-
API 差异
-
clip space 差异
-
projection 细节
想在 CPU 侧验证
_ZBufferParams,可以直接打印:
C#
Shader.GetGlobalVector("_ZBufferParams")或在 FrameDebugger / RenderDoc constant buffer 里看到:
UnityPerCamera
_ZBufferParams它会随 Camera near/far 改变。
CPU 侧验证_ZBufferParams直接打印:Shader.GetGlobalVector("_ZBufferParams")FrameDebugger / RenderDoc constant buffer 里看到:UnityPerCamera
_ZBufferParams随 Camera near/far 改变。_ZBufferParams只和 projection 有关 ,和 depth texture 本身无关。SampleSceneDepth()- _ZBufferParams= 可恢复 view space depth可恢复可恢复可恢复可恢复可恢复view space depth=SampleSceneDepth()
- _ZBufferParams
custom projection(例如:
-
oblique projection
-
reversed infinite far
-
logarithmic depth
-
custom clip control
)
那
_ZBufferParams就不再正确,需要你自己提供。_ZBufferParams的数据来源:
Camera.nearClipPlane
Camera.farClipPlane- Unity projection mode (reversed Z)
→ Unity 渲染管线计算
→ UnityPerCamera CBuffer
→ shader 全局变量 _ZBufferParams
用途:
把 GPU depth buffer → 线性深度 / view space depth做的是 深度边缘 / depth rim / SSAO / SSR 这一类屏幕空间算法,其实还有一个更底层的问题很多项目会踩坑:LinearEyeDepth 并不是 world distance。
它是:view space Z
也就是 camera forward 方向的深度,而不是length(viewPos)
这在 大 FOV 或斜角观察时 会导致 rim 厚度变化。
-