本笔记仅为个人的理解,如果有误欢迎指出。
Per-Pixel Lists for Single Pass A-Buffer 单Pass生成基于逐像素列表的 A-Buffer 技术
这个标题的意思不是很好翻译。
在传统光栅化渲染半透明物体时,往往渲染的顺序十分重要,一般渲染半透明物体的时候都是从距离相机比较远的物体开始渲染,靠近相机的后渲染,从后往前叠加颜色来得到最终效果。主要是因为Alpha 混合公式的关系,限制了这个顺序。
因此,为了确定半透明物体的渲染顺序,就需要对物体进行排序,排序操作非常耗费性能,同时在物体层面上的排序往往对于某些自相交、循环遮挡的透明物体难以处理。因此产生了许多处理这种情况下渲染半透明物体的技术,这篇文章讲述的A-buffer就是其中一个解决方案。
A-buffer为每一个像素都存储着一个排序过的片元列表。因为涉及到对片元的排序,文章的方法依赖一个存储所有片元的缓冲区,称为主缓冲区(main buffer)。
整个渲染半透明物体的流程分为三个阶段:
CLEAR 阶段:初始化内存;
BUILD 阶段:为每个像素构建片元列表;
RENDER 阶段:累积片元的贡献并将颜色写入帧缓冲。
文章中给出了4种生成A-buffer的方法,这4种技术存在两个维度的差异:
第一个维度是排序调度策略:我们在何时对每个像素关联的片元进行深度排序?
第二个维度是用于逐步构建逐像素片元列表的内存分配策略。
各维度两个差异互相组合就是4种不同的实时构建和渲染A-buffer的技术,并且都只需要一个Pass。
排序策略:
排序策略分为两种:
第一种策略,POST-SORT(后排序) 在Build阶段中存储所有片元,然后再在Render阶段中积累颜色的时候再对所有当前像素的所有片元进行排序。
第二种策略,PRE-SORT(预排序) 在Build阶段中,就对A-Buffer进行插入排序。
在PRE-SORT 中,插入排序需要在全局内存中完成,这样的操作会比较慢,但这个排序方法支持对不可见的片元提前剔除。而在 POST-SORT中,排序会发生在本地内存中,这样速度更快,但是这限制了每个像素能关联的最大片元数量。
分配策略:
分配策略分为两种:
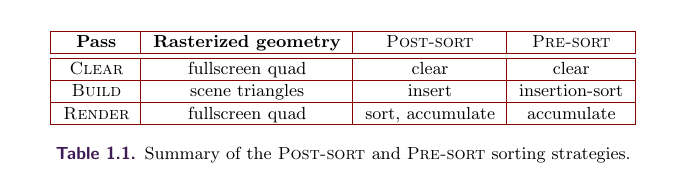
第一种策略,LIN-ALLOC 每个像素都分配一个链表,所有片元都保存在链表节点里并从头到尾排列在Main buffer 上并且有自己的地址ID,这个地址ID是通过递增的全局计数器获得的。因为每个像素都分配了一个链表,所以还需要额外的内存去保存每个像素的头节点。这种分配方式思路和用List实现链表结构类似,各个不同链表的节点保存在同一个List中,通过节点保存的下一个节点索引来实现链表结构。这种策略在GPU PRO 4 Real-Time Deep Shadow Maps中有类似的思路。
第二种策略,OPEN-ALLOC 这个方法复杂一些,但是思路是通过哈希函数***h(p,i)***计算下一个节点存储位置。其中参数p是像素,i是一个递增值,他会一直递增计算直到计算出来的一个可以保存片元的空地址。可以预想到这种计算方式很容易导致同像素或不同像素的片元之间地址的冲突,这个也是这种策略需要解决的问题之一。
两种分配策略(LIN-ALLOC 和 OPEN-ALLOC)与两种排序调度方式(后排序和前排序)的组合,为我们提供了构建 A-buffer的四种变体:POST-LIN、PRE-LIN、POST-OPEN 和 PRE-OPEN
POST-LIN(后排序线性链表分配):
最简单的给每个像素构建没排序的链表的代码如下:

可以看到链表节点保存着depth用来后面的排序,next用来指向下一个节点。
文章中提出了一种用一维数组合构建链表的方法,流程如下:
在渲染的时候需要对片元数据进行排序:
1,将片元数据保存到一个别的Buffer中,称为databuf。
2,将depth和next的数据打包到一起
3,将主缓冲区扩展,增加与屏幕像素数相同数量的单元。拓展出的的区域主要是为了作为临时交换数据时记录起点用。
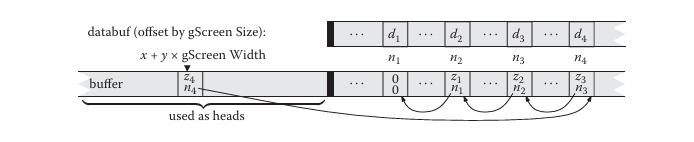
插入代码如下:

这个代码只是在说如何构建一个链表,但是并没有说明如何排序,文章后面也只是说会在渲染前将这个数据取出来然后进行简单的冒泡排序或者插入排序
PRE-LIN(预排序线性链表分配):
预排序就是在Build的时候就通过插入链表的形式构建A-Buffer。文章中讲解了一种支持多线程并行插入的排序方法,伪代码如下:
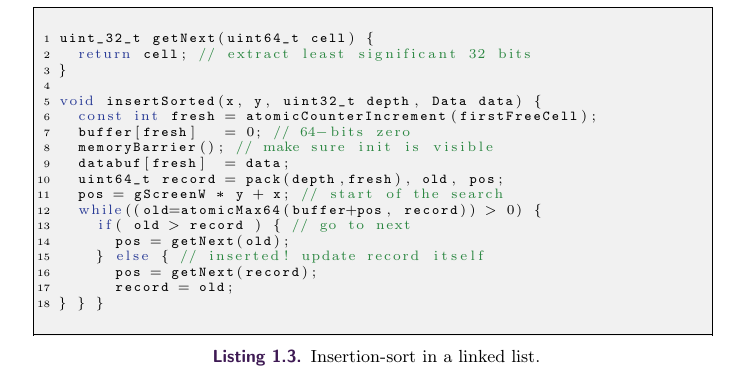
这个多线程插入实现的关键是atomicMax,所有线程的插入操作都被这个原子函数所限制。
atomicMax里会交换手上的record与缓冲区(buffer + pos)位置上的record,只有当手上的record的depth比缓冲区的record要大的时候才会进行交换。(atomicMax > 0 说明buffer + pos 的位置上是空的,可以直接插入当前的record,,否则old代表比较交换后的结果)
record表示当前要插入的节点数据,它包含当前节点的深度和指向下一个节点的位置。在单线程的情况下,插入排序就是取当前位置的节点数据与手上的节点数据比较,根据深度判断要交换位置还是去下一个节点位置再做比较,直到找到一个空节点位置把手上的节点数据放入进去。
而多线程的关键就在于**交换当前位置的节点数据上,**每次都只允许一个线程去取当前位置的节点数据,然后再执行while后面的内容获取下一个要比较的节点位置。
可以想象每个人手上有一个盒子去放在同一个队列里,每个盒子有一个大小值和下一个要比较的盒子的位置。当要把手上的盒子放到队列里的时候,我们先和队列里第一个盒子比较,如果位置上的盒子里的值比手上的盒子值小的时候,我将手上的盒子和当前位置的盒子交换,并且根据两个盒子的内容决定我下一次要去找哪个位置的盒子去比较。多线程的具象在于不同同时多个人去交换比较一个位置上的盒子。
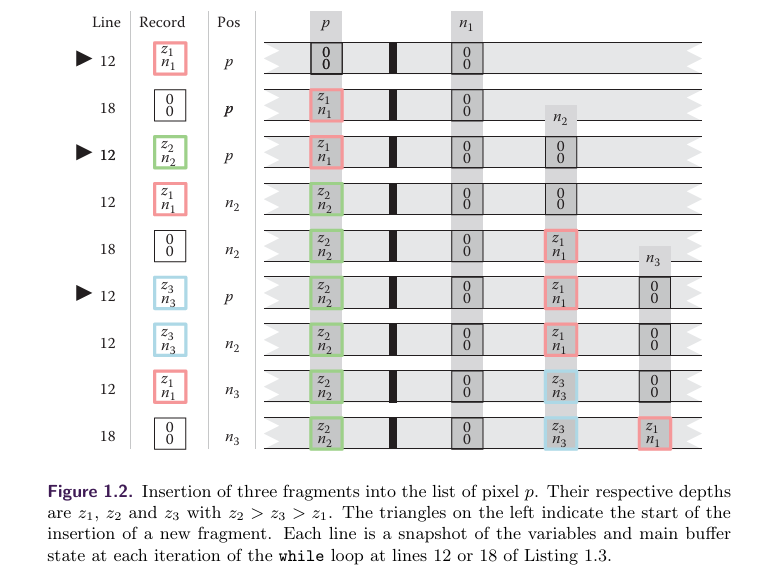
下图为三个线程的交换示例,可以看到Pos的更新在Record和n123交换之后。
POST-OPEN(后排序开放分配):
和前面的POST-LIN类似,这里只会将数据插入到缓存中,并不会对数据进行排序,片元数据和深度数据封装在一起,同时另外加一个age数据用于插入,用代码表示:
class
{
int age;
int depth;
FrameData data;
}内存上的结构为:
插入数据的时候遵循以下规则:
如果当前位置为空则放入数据。
否则则根据age把age最大的放入当前位置,age最小的重新通过哈希函数***h(p,i)***计算下一个位置,同时age加一。
代码如下:

这个插入方法还另外有个列表保存每个像素最大的age,他是用来表示每个像素上有多少个片元。
PRE-OPEN(预排序开放分配):
这个策略在插入数据到主缓存的时候与POST-OPEN类似,都是通过哈希函数***h(p,i)***计算下一个位置,而区别在于交换,
POST-OPEN在交换的时候一般只是简单的判断age大小不同,这里进行交换的时候还要同时考虑depth,具体的判断细节被atomicMax封装起来,但思路和PRE-LIN中的插入排序思路类似,插入过程中还会跳过不属于当前像素P的片元。
具体伪代码如下:
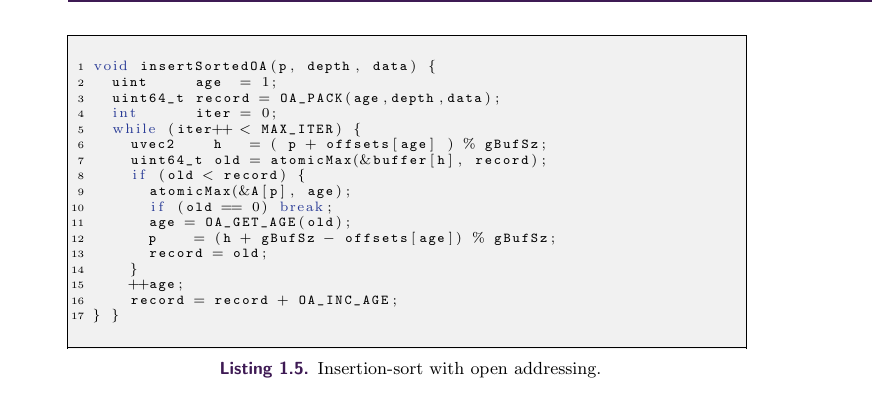
这段代码其实与POST-OPEN差别不大。
参考资料: