视觉推理(Visual Reasoning):从观察到逻辑的复杂认知链
1 什么是视觉推理
视觉推理是视觉-语言跨模态领域的高阶核心任务,建立在视觉问答、视觉定位、图像计数基础之上,要求模型基于图像与语言输入,完成多步逻辑推导、关联分析、常识判断,最终输出复杂决策或答案,是衡量多模态模型认知能力的关键指标。
与基础VQA的单步事实问答不同,视觉推理需要模型具备观察、分析、推导、总结的完整认知链,而非简单提取视觉信息。
2 视觉推理的核心:视觉版思维链
视觉推理的底层运行逻辑依托视觉版思维链(Chain of Thought,CoT),完整分为三个关键环节:
- 观察环节
通过文本编码器解析指令语义,结合视觉编码器、视觉定位、图像计数的基础能力,完成图像中目标、位置、数量、属性的精准感知,获取推理所需的基础视觉事实。 - 推理环节
依托大语言模型的世界知识与常识知识,对观察到的视觉信息进行多步逻辑加工,包括因果推导、关系判断、比较分析、分步推演等,这是视觉推理的核心。 - 结论环节
将推理过程的中间结果整合,按照指令要求完成答案格式化输出,保证结论与视觉事实、逻辑规则完全匹配。
3 视觉推理的两大前沿挑战
视觉推理是多模态任务中难度最高的任务之一,当前行业面临两大核心难题:
- 幻觉问题
模型生成看似合理、但与图像事实完全不符的描述或推理步骤,是制约视觉推理落地的关键问题。 - 因果推理缺失
模型擅长回答"是什么"的事实类问题,难以准确回应"为什么发生""如果......会怎样"等需要完整因果链的复杂问题。
4 视觉推理主流模型解析
4.1 ViLT
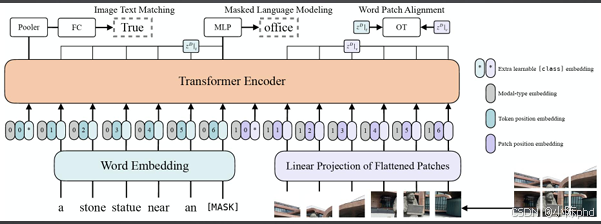
ViLT是首批将视觉-语言任务统一到Transformer结构的模型,采用双流嵌入、早期融合方案。
- 核心特点:计算成本低于复杂的跨模态注意力结构,轻量化优势明显。
- 固有局限:模态交互深度不足,早期融合会丢失部分模态专属的细粒度信息,复杂推理能力有限。
4.2 MMGPT

以大语言模型为核心的多模态推理模型,采用冻结图像编码器+适配器的方案。
- 核心逻辑:用CLIP/ViT等图像编码器提取视觉特征,通过适配器将特征对齐到GPT类LLM的输入空间,由LLM完成全部推理与输出。
- 优势:继承LLM的长文本理解与逻辑推理能力。
- 不足:视觉信息适配LLM时易丢失细节,复杂视觉场景推理精度受限。
4.3 DeepSeek-VL2
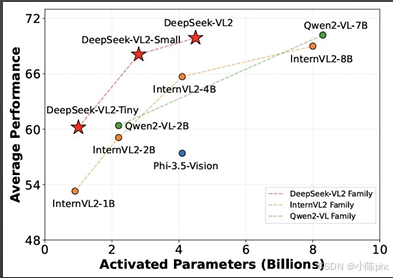
开源高性能多模态大模型代表,采用双流架构,在VQAv2、GQA、视觉定位等任务中接近SOTA水平,是视觉推理的主流开源基线模型。
5 视觉推理核心数据集与评估指标
5.1 核心数据集
- CLEVR
图像由球体、立方体、圆柱体等简单几何物体构成,搭配颜色、大小等属性,专门测试模型的空间关系、比较、计数等基础逻辑与组合推理能力。 - Visual CoT Dataset
包含约43.8万个问答对,每个样本均标注问题、答案、中间推理步骤与核心视觉区域,是专门用于训练和评估视觉思维链的核心数据集。 - GQA
基于真实世界场景构建,问题包含多跳推理、常识知识关联,用于测试模型在真实场景下的复杂视觉推理能力。 - VQAv2
作为基础数据集,用于验证模型的基础事实问答能力,是视觉推理的底层支撑。
5.2 核心评估指标
- 准确率
最终答案与真实标注完全一致的百分比,是最基础的推理效果指标。 - 多步推理准确率
严格要求所有中间推理步骤正确,且最终答案准确,才判定为完全正确,更贴合视觉推理的真实要求。 - 一致性/合理性
评估思维链推理步骤是否与图像事实一致、逻辑是否自洽,部分场景需人工或半自动评估。
6 总结
视觉推理是多模态感知从信息提取 走向认知理解的核心标志,以视觉思维链为核心运行机制,整合视觉定位、图像计数、常识知识完成多步逻辑推导。
当前模型已能完成基础几何推理、真实场景多跳推理,但仍面临幻觉、因果推理不足的核心挑战。随着大模型多模态能力的持续升级,视觉推理将逐步实现从简单逻辑到复杂因果、从人工场景到真实世界的突破,成为机器人决策、智能分析、自动驾驶等领域的核心认知能力。