摘要 :本文在 Decoder-only Transformer 的基础上,系统介绍 LLaMA 的架构设计及每一步的矩阵运算与维度。内容包括:LLaMA 的整体定位(Decoder-only + RMSNorm + Pre-Norm + SwiGLU + RoPE)、从输入到 Decoder 的数据流(Tokenization、Embedding、RoPE 位置编码)、单层 Decoder 的完整计算(RMSNorm、带掩码的自注意力/ GQA、SwiGLU 前馈网络)及其矩阵形状、输出层、以及与标准 Transformer 的对比表。旨在帮助读者建立对 LLaMA 的可计算、可对照的理解。
关键词:LLaMA;Decoder-only;RMSNorm;Pre-Norm;SwiGLU;RoPE;GQA;掩码自注意力;大语言模型
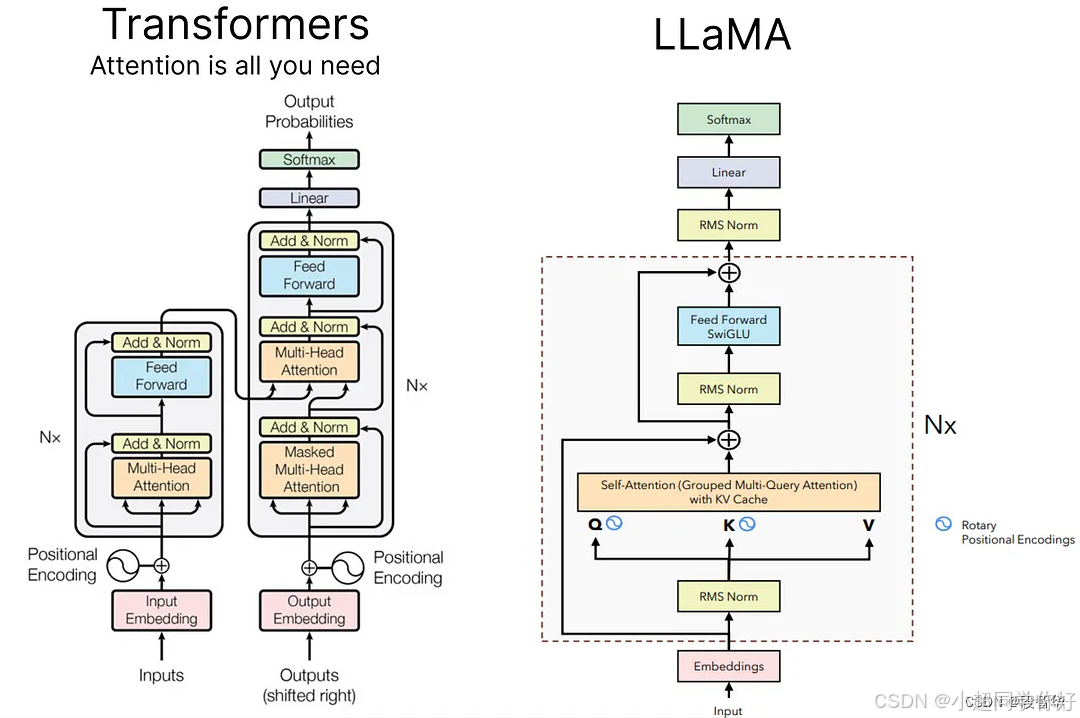
💡 理解要点 :LLaMA 是仅保留 Decoder 的 Transformer 变体,去掉 Encoder 与交叉注意力,并采用 RMSNorm 、Pre-Norm 、SwiGLU 、RoPE 等组件,形成现代大语言模型的常用基线。整体数据流与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 一致,差异在归一化、归一化顺序、FFN 激活与位置编码方式。
1. 概述:LLaMA 在 Transformer 家族中的位置
LLaMA(Large Language Model Meta AI)采用 Decoder-only 架构:只保留解码器中的带掩码多头自注意力 与前馈网络 ,去掉编码器与编码器-解码器交叉注意力,与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 中描述的整体数据流一致。与「标准」Decoder(如原版 Transformer 的 Decoder)相比,LLaMA 的主要变化为:
- 归一化 :用 RMSNorm 替代 LayerNorm。
- 归一化位置 :用 Pre-Norm(先归一化再进子层)替代 Post-Norm(先子层+残差再归一化)。
- 前馈网络 :用 SwiGLU 替代 ReLU。
- 位置编码 :用 RoPE(在注意力中对 Q、K 做旋转)替代在 Embedding 上相加的固定/可学习位置编码。
因此,单层 LLaMA Decoder 的流程为:RMSNorm → 掩码自注意力(或 GQA)→ 残差 → RMSNorm → SwiGLU FFN → 残差 ,且无交叉注意力。
🔍 实际例子 :若序列长度 L = 2048 L=2048 L=2048、模型维度 d model = 4096 d_{\text{model}}=4096 dmodel=4096(如 LLaMA-2 7B),则每层输入与输出均为 2048 × 4096 2048 \times 4096 2048×4096 的矩阵;最后一层取最后一位置的向量 h L ∈ R 4096 \mathbf{h}_L \in \mathbb{R}^{4096} hL∈R4096,经线性层与 Softmax 得到词表上的概率分布。
下文按数据流顺序 给出每一步的矩阵形状与运算 ,便于与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 逐项对照。
2. 从输入到 Decoder:数据如何进入
Decoder 不直接接收原始文本,而是接收 Tokenization → Embedding 后的表示;位置信息由 RoPE 在注意力层内注入,不在 Embedding 上再加一层位置向量。
2.1 Tokenization:从文本到 Token 序列
Tokenization 将文本切分为词表内的 Token ,每个 Token 对应一个整数 ID 。模型内部处理的是长度为 L L L 的 Token ID 序列。
矩阵视角 :得到的是长度为 L L L 的整数序列,后续由 Embedding 查表得到 L × d model L \times d_{\text{model}} L×dmodel 的矩阵。
LLaMA 词表 :常见为 V = 32000 V = 32000 V=32000(LLaMA-1)或 32000/128000 等,依版本而定。
2.2 Embedding:从 Token ID 到向量(矩阵运算)
数学 :Embedding 为可学习查找表 E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel。对每个 Token ID w i w_i wi:
Embedding ( w i ) = E w i ∈ R d model . \text{Embedding}(w_i) = Ew_i \in \mathbb{R}^{d_{\text{model}}}. Embedding(wi)=Ewi∈Rdmodel.
矩阵形状:
- 查表矩阵: E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel。
- 整段序列: L L L 个 token 查表后按位置堆叠,得到 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel。
数值示例 (LLaMA-2 7B): L = 2048 L=2048 L=2048, d model = 4096 d_{\text{model}}=4096 dmodel=4096,则 Embedding 输出为 2048 × 4096 2048 \times 4096 2048×4096。
💡 理解要点 :LLaMA 不在 此处加正弦/余弦或可学习位置编码;位置信息由 RoPE 在注意力层内注入,且注入方式与 Transformer 完全不同。
2.3 位置编码:LLaMA(RoPE)与 Transformer 有何不同?
原版 Transformer 的位置编码在 Transformer 4. Embedding层与位置编码技术 中有详细说明:在输入阶段 为每个位置生成一个与 Embedding 同形状的向量(正余弦或可学习),直接加在词嵌入上 ,再送入 Encoder/Decoder。LLaMA 则不在 Embedding 上加任何位置向量 ,而是用 RoPE 在每一层注意力内部 对 Q、K 做旋转变换。二者对比如下。
2.3.1 Transformer 的位置编码(复习)
- 注入时机与位置 :在 Embedding 之后、进入第一层之前 ,对整段序列做一次位置编码并与词嵌入相加。
- 数学形式 :对位置 p o s pos pos、维度 2 i / 2 i + 1 2i/2i+1 2i/2i+1,使用正余弦函数生成标量,组成向量 P E ( p o s ) ∈ R d model \mathrm{PE}(pos) \in \mathbb{R}^{d_{\text{model}}} PE(pos)∈Rdmodel:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) . PE_{(pos, 2i)} = \sin\Big(\frac{pos}{10000^{2i/d_{\text{model}}}}\Big), \quad PE_{(pos, 2i+1)} = \cos\Big(\frac{pos}{10000^{2i/d_{\text{model}}}}\Big). PE(pos,2i)=sin(100002i/dmodelpos),PE(pos,2i+1)=cos(100002i/dmodelpos). - 融合方式 : I n p u t i = E m b e d d i n g i + P E ( i ) \mathrm{Input}i = \mathrm{Embedding}i + \mathrm{PE}(i) Inputi=Embeddingi+PE(i),即逐位置、逐元素相加 ,形状仍为 L × d model L \times d_{\text{model}} L×dmodel。
- 特点 :每个位置得到一个唯一的绝对位置向量,与词嵌入混合后一起参与后续所有层的计算;位置信息只在这一步注入一次。
2.3.2 LLaMA 的 RoPE:在注意力里对 Q、K 做旋转
- 注入时机与位置 :不在 Embedding 上做任何加法 ;而是在每一层 的注意力中,在得到 Q、K 之后、计算注意力分数 Q K T Q K^T QKT 之前 ,对 Q、K 按位置做旋转变换。
- 数学形式 :对每个位置 p o s pos pos,使用与 p o s pos pos 和维度相关的旋转矩阵 R p o s R_{pos} Rpos,对该位置对应的 Q、K 行向量 做旋转(通常按 d k d_k dk 维分成若干二维子空间,每个子空间做平面旋转)。即 Q ′ p o s = R p o s Q p o s Q'pos = R_{pos}\, Qpos Q′pos=RposQpos, K ′ p o s = R p o s K p o s K'pos = R_{pos}\, Kpos K′pos=RposKpos,然后仍用 S = Q ′ ( K ′ ) T / d k S = Q' (K')^T / \sqrt{d_k} S=Q′(K′)T/dk 。
- 融合方式 :没有「位置向量 + 词嵌入」的加法 ;位置信息通过 Q、K 的旋转 编码进注意力分数里,使得 S i j S_{ij} Sij 依赖于位置 i i i 与 j j j 的相对关系 (如 i − j i-j i−j),而不是单独的绝对位置。
- 特点 :RoPE 不改变 Q、K 的矩阵形状 (仍为 L × d k L \times d_k L×dk),只改变数值;位置信息在每一层 都通过当前的 Q、K 重新参与计算,且天然是相对位置编码,对长序列外推往往更友好。
2.3.3 对比小结
| 维度 | Transformer(见 Transformer 4. Embedding层与位置编码技术) | LLaMA(RoPE) |
|---|---|---|
| 注入时机 | Embedding 之后、进入网络前,只做一次 | 每一层 注意力内,在算 Q K T QK^T QKT 之前 |
| 注入对象 | 整个输入序列(与 Embedding 相加) | 只对当前层的 Q、K 做旋转,V 不变 |
| 数学形式 | 位置向量 P E ( p o s ) \mathrm{PE}(pos) PE(pos) 加到词嵌入上 | 旋转矩阵 R p o s R_{pos} Rpos 乘在 Q、K 的对应行上 |
| 位置类型 | 以绝对位置为主(每个 pos 一个唯一向量) | 设计成相对位置 (注意力分数依赖 i − j i-j i−j) |
| 输入到第一层 | X = E m b e d d i n g + P E X = \mathrm{Embedding} + \mathrm{PE} X=Embedding+PE,形状 L × d model L \times d_{\text{model}} L×dmodel | X = E m b e d d i n g X = \mathrm{Embedding} X=Embedding(无 PE 相加),形状 L × d model L \times d_{\text{model}} L×dmodel |
因此,LLaMA 的位置编码方式与 Transformer 不同 :Transformer 是「在输入处加位置向量」,LLaMA 是「在注意力里对 Q、K 做旋转」,不改变 Q、K 的矩阵形状(仍为 L × d k L \times d_k L×dk),只改变数值,使注意力分数带上相对位置信息。进入第一层 Decoder 的输入在 LLaMA 中仍是 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel(仅 Embedding 输出)。
2.4 小结:进入第一层 Decoder 的矩阵
- Tokenization :文本 → 长度 L L L 的 Token ID 序列。
- Embedding : E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel,输出 X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel。
- RoPE :在注意力层内作用于 Q、K,不在此处改变 X X X 的形状。
故 Decoder 每层的输入/输出在形状上均为 L × d model L \times d_{\text{model}} L×dmodel ,与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 一致。
3. LLaMA Decoder 单层:每一步的矩阵计算
单层 LLaMA Decoder 由两个子层组成,且均为 Pre-Norm + 子层 + 残差:
- RMSNorm → 带掩码的多头自注意力(或 GQA)→ Add(残差)
- RMSNorm → 前馈网络(SwiGLU)→ Add(残差)
下面给出每一步的矩阵维度与运算。
3.1 RMSNorm(Root Mean Square Layer Normalization)
作用 :对每个样本(每行)做缩放归一化,只用到均方根,不做减均值。用于 Pre-Norm:先对输入归一化,再送入子层。
公式 :对输入向量 x ∈ R d model \mathbf{x} \in \mathbb{R}^{d_{\text{model}}} x∈Rdmodel(即 X X X 的某一行),
R M S ( x ) = ε + 1 d model ∑ j = 1 d model x j 2 , R M S N o r m ( x ) = x R M S ( x ) ⊙ γ , \mathrm{RMS}(\mathbf{x}) = \sqrt{\varepsilon + \frac{1}{d_{\text{model}}} \sum_{j=1}^{d_{\text{model}}} x_j^2}, \qquad \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\mathrm{RMS}(\mathbf{x})} \odot \boldsymbol{\gamma}, RMS(x)=ε+dmodel1j=1∑dmodelxj2 ,RMSNorm(x)=RMS(x)x⊙γ,
其中 γ ∈ R d model \boldsymbol{\gamma} \in \mathbb{R}^{d_{\text{model}}} γ∈Rdmodel 为可学习缩放参数, ε \varepsilon ε 为小数避免除零。
矩阵形状:
- 输入: X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel。
- 输出:逐行做 RMSNorm,形状仍为 L × d model L \times d_{\text{model}} L×dmodel。
- 可学习参数:每处 RMSNorm 一个 γ \boldsymbol{\gamma} γ,共 d model d_{\text{model}} dmodel 个标量。
3.1.1 与 Transformer 的 LayerNorm 有何不同?
是的,归一化方式不同 :Transformer 使用 LayerNorm ,LLaMA 使用 RMSNorm 。详见 Transformer 5. Transformer中的残差连接、归一化与前馈神经网络。
Transformer 的 LayerNorm (对每行 x \mathbf{x} x):
- 先算均值 μ = 1 d model ∑ j x j \mu = \frac{1}{d_{\text{model}}}\sum_j x_j μ=dmodel1∑jxj 和方差 σ 2 = 1 d model ∑ j ( x j − μ ) 2 \sigma^2 = \frac{1}{d_{\text{model}}}\sum_j (x_j - \mu)^2 σ2=dmodel1∑j(xj−μ)2(或标准差 σ \sigma σ)。
- 再做 减均值、除标准差 : x ^ = x − μ σ + ε \widehat{\mathbf{x}} = \frac{\mathbf{x} - \mu}{\sigma + \varepsilon} x =σ+εx−μ。
- 最后缩放与平移 : L a y e r N o r m ( x ) = γ ⊙ x ^ + β \mathrm{LayerNorm}(\mathbf{x}) = \boldsymbol{\gamma} \odot \widehat{\mathbf{x}} + \boldsymbol{\beta} LayerNorm(x)=γ⊙x +β。
- 可学习参数:两个 向量 γ \boldsymbol{\gamma} γ(scale)和 β \boldsymbol{\beta} β(shift),各 d model d_{\text{model}} dmodel 维。
LLaMA 的 RMSNorm:
- 不减均值 ,只算均方根 R M S ( x ) = ε + 1 d model ∑ j x j 2 \mathrm{RMS}(\mathbf{x}) = \sqrt{\varepsilon + \frac{1}{d_{\text{model}}}\sum_j x_j^2} RMS(x)=ε+dmodel1∑jxj2 (相当于在「二阶矩」意义下的缩放因子)。
- 再做 除 RMS、再缩放 : R M S N o r m ( x ) = x R M S ( x ) ⊙ γ \mathrm{RMSNorm}(\mathbf{x}) = \frac{\mathbf{x}}{\mathrm{RMS}(\mathbf{x})} \odot \boldsymbol{\gamma} RMSNorm(x)=RMS(x)x⊙γ。
- 可学习参数:仅一个 向量 γ \boldsymbol{\gamma} γ(scale),无 β \boldsymbol{\beta} β。
对比小结:
| 项目 | Transformer(LayerNorm) | LLaMA(RMSNorm) |
|---|---|---|
| 是否减均值 | 是,先减 μ \mu μ 再除 σ \sigma σ | 否,只除 RMS |
| 统计量 | 均值 μ \mu μ + 方差/标准差 σ \sigma σ | 仅均方根 RMS(无均值) |
| 可学习参数 | γ \boldsymbol{\gamma} γ(scale)+ β \boldsymbol{\beta} β(shift) | 仅 γ \boldsymbol{\gamma} γ(scale) |
| 计算 | 两次遍历(先求均值再求方差)或一次遍历求两者 | 一次遍历求平方和即可 |
💡 理解要点 :RMSNorm 是 LayerNorm 的简化版------去掉「减均值」和「shift 参数 β \boldsymbol{\beta} β」,只保留按尺度(RMS)的缩放,计算更省、参数更少;在许多大模型里效果与 LayerNorm 相当甚至更稳定,因此 LLaMA 等采用 RMSNorm。
3.2 带掩码的多头自注意力(含 RoPE)
输入 :本子层为 Pre-Norm,注意力层的输入为 X ~ = R M S N o r m ( X ) ∈ R L × d model \tilde{X} = \mathrm{RMSNorm}(X) \in \mathbb{R}^{L \times d_{\text{model}}} X~=RMSNorm(X)∈RL×dmodel。为书写简单,下面仍用 X X X 表示该层的输入(即已 RMSNorm 后的矩阵)。
约定 :头数 h h h,每头维度 d k = d model / h d_k = d_{\text{model}} / h dk=dmodel/h。LLaMA-2 7B: h = 32 h=32 h=32, d k = 128 d_k=128 dk=128。
3.2.1 每头的 Q、K、V 投影
对第 t t t 个头( t = 1 , ... , h t=1,\ldots,h t=1,...,h):
- Q ( t ) = X W Q ( t ) Q^{(t)} = X \, W_Q^{(t)} Q(t)=XWQ(t), K ( t ) = X W K ( t ) K^{(t)} = X \, W_K^{(t)} K(t)=XWK(t), V ( t ) = X W V ( t ) V^{(t)} = X \, W_V^{(t)} V(t)=XWV(t)
- W Q ( t ) , W K ( t ) , W V ( t ) ∈ R d model × d k W_Q^{(t)},\, W_K^{(t)},\, W_V^{(t)} \in \mathbb{R}^{d_{\text{model}} \times d_k} WQ(t),WK(t),WV(t)∈Rdmodel×dk
- Q ( t ) , K ( t ) , V ( t ) ∈ R L × d k Q^{(t)},\, K^{(t)},\, V^{(t)} \in \mathbb{R}^{L \times d_k} Q(t),K(t),V(t)∈RL×dk
3.2.2 RoPE 作用于 Q、K
对 Q ( t ) Q^{(t)} Q(t)、 K ( t ) K^{(t)} K(t) 按位置施加 RoPE 旋转,不改变形状,仍为 L × d k L \times d_k L×dk 。记旋转后为 Q ′ ( t ) , K ′ ( t ) Q'^{(t)},\, K'^{(t)} Q′(t),K′(t)(下文为简洁仍写 Q ( t ) , K ( t ) Q^{(t)}, K^{(t)} Q(t),K(t) 表示已旋转)。
3.2.3 注意力分数与掩码
- S ( t ) = Q ( t ) ( K ( t ) ) T / d k S^{(t)} = Q^{(t)} (K^{(t)})^T / \sqrt{d_k} S(t)=Q(t)(K(t))T/dk ,形状 L × L L \times L L×L。
- 因果掩码: S ( t ) ← S ( t ) + M S^{(t)} \leftarrow S^{(t)} + M S(t)←S(t)+M, M M M 为上三角为 − ∞ -\infty −∞、下三角为 0 的 L × L L \times L L×L 矩阵。
- h e a d ( t ) = s o f t m a x ( S ( t ) ) V ( t ) \mathrm{head}^{(t)} = \mathrm{softmax}(S^{(t)}) \, V^{(t)} head(t)=softmax(S(t))V(t),形状 L × d k L \times d_k L×dk。
3.2.4 多头拼接与输出投影
- C o n c a t ( h e a d ( 1 ) , ... , h e a d ( h ) ) ∈ R L × d model \mathrm{Concat}(\mathrm{head}^{(1)}, \ldots, \mathrm{head}^{(h)}) \in \mathbb{R}^{L \times d_{\text{model}}} Concat(head(1),...,head(h))∈RL×dmodel。
- A t t n O u t = C o n c a t ⋅ W O \mathrm{AttnOut} = \mathrm{Concat} \cdot W_O AttnOut=Concat⋅WO, W O ∈ R d model × d model W_O \in \mathbb{R}^{d_{\text{model}} \times d_{\text{model}}} WO∈Rdmodel×dmodel,输出形状 L × d model L \times d_{\text{model}} L×dmodel。
3.2.5 残差
X attn = X + A t t n O u t X_{\text{attn}} = X + \mathrm{AttnOut} Xattn=X+AttnOut(此处 X X X 为该子层原始 输入,即第一次 RMSNorm 前的矩阵),形状 L × d model L \times d_{\text{model}} L×dmodel。
小结(矩阵维度):
| 步骤 | 矩阵/运算 | 形状 |
|---|---|---|
| 输入(RMSNorm 后) | X X X | L × d model L \times d_{\text{model}} L×dmodel |
| 每头 Q,K,V | Q ( t ) , K ( t ) , V ( t ) Q^{(t)}, K^{(t)}, V^{(t)} Q(t),K(t),V(t) | L × d k L \times d_k L×dk |
| 注意力分数 | S ( t ) S^{(t)} S(t) | L × L L \times L L×L |
| 每头输出 | h e a d ( t ) \mathrm{head}^{(t)} head(t) | L × d k L \times d_k L×dk |
| 多头拼接 | Concat | L × d model L \times d_{\text{model}} L×dmodel |
| 输出投影 | A t t n O u t \mathrm{AttnOut} AttnOut | L × d model L \times d_{\text{model}} L×dmodel |
| 加残差后 | X attn X_{\text{attn}} Xattn | L × d model L \times d_{\text{model}} L×dmodel |
3.3 前馈网络:SwiGLU(矩阵运算)
作用 :对每个位置独立做非线性变换,采用 SwiGLU 门控形式,是 LLaMA 与标准 Transformer(ReLU FFN)的主要区别之一。
SwiGLU 形式(常见写法):
S w i G L U ( x ) = ( σ s w i s h ( x W 1 ) ⊙ ( x W 3 ) ) W 2 . \mathrm{SwiGLU}(x) = \big( \sigma_{\mathrm{swish}}(x W_1) \odot (x W_3) \big) W_2. SwiGLU(x)=(σswish(xW1)⊙(xW3))W2.
其中 σ s w i s h ( z ) = z ⋅ σ ( z ) \sigma_{\mathrm{swish}}(z) = z \cdot \sigma(z) σswish(z)=z⋅σ(z)(Swish 激活), ⊙ \odot ⊙ 为逐元素乘; W 1 , W 3 W_1,\, W_3 W1,W3 为「门」与「值」的两路投影, W 2 W_2 W2 为输出投影。也有实现将 W 1 W_1 W1 与 W 3 W_3 W3 合并为一个 d model × ( 2 ⋅ d f f ) d_{\text{model}} \times (2 \cdot d_{ff}) dmodel×(2⋅dff) 的矩阵再在特征维上拆成两半。
维度约定 (与 LLaMA 一致):中间维度 d f f = 4 ⋅ d model d_{ff} = 4 \cdot d_{\text{model}} dff=4⋅dmodel。
矩阵形状(逐位置等价为矩阵运算):
- 输入: X attn ∈ R L × d model X_{\text{attn}} \in \mathbb{R}^{L \times d_{\text{model}}} Xattn∈RL×dmodel(本子层输入为上一层输出,即注意力+残差后的结果;Pre-Norm 下先对该输入做 RMSNorm 再进 FFN,为书写简单下面用 X X X 表示 FFN 的输入,形状不变)。
- Z 1 = X W 1 Z_1 = X W_1 Z1=XW1, W 1 ∈ R d model × d f f W_1 \in \mathbb{R}^{d_{\text{model}} \times d_{ff}} W1∈Rdmodel×dff, Z 1 ∈ R L × d f f Z_1 \in \mathbb{R}^{L \times d_{ff}} Z1∈RL×dff。
- Z 3 = X W 3 Z_3 = X W_3 Z3=XW3, W 3 ∈ R d model × d f f W_3 \in \mathbb{R}^{d_{\text{model}} \times d_{ff}} W3∈Rdmodel×dff, Z 3 ∈ R L × d f f Z_3 \in \mathbb{R}^{L \times d_{ff}} Z3∈RL×dff。
- Z = σ s w i s h ( Z 1 ) ⊙ Z 3 Z = \sigma_{\mathrm{swish}}(Z_1) \odot Z_3 Z=σswish(Z1)⊙Z3,形状 L × d f f L \times d_{ff} L×dff。
- F F N O u t = Z W 2 \mathrm{FFNOut} = Z W_2 FFNOut=ZW2, W 2 ∈ R d f f × d model W_2 \in \mathbb{R}^{d_{ff} \times d_{\text{model}}} W2∈Rdff×dmodel, F F N O u t ∈ R L × d model \mathrm{FFNOut} \in \mathbb{R}^{L \times d_{\text{model}}} FFNOut∈RL×dmodel。
- 残差: X out = X + F F N O u t X_{\text{out}} = X + \mathrm{FFNOut} Xout=X+FFNOut,形状 L × d model L \times d_{\text{model}} L×dmodel。
数值示例 (LLaMA-2 7B): d model = 4096 d_{\text{model}}=4096 dmodel=4096, d f f = 16384 d_{ff}=16384 dff=16384。
- W 1 , W 3 ∈ R 4096 × 16384 W_1,\, W_3 \in \mathbb{R}^{4096 \times 16384} W1,W3∈R4096×16384, W 2 ∈ R 16384 × 4096 W_2 \in \mathbb{R}^{16384 \times 4096} W2∈R16384×4096。
- Z 1 , Z 3 ∈ R L × 16384 Z_1,\, Z_3 \in \mathbb{R}^{L \times 16384} Z1,Z3∈RL×16384, F F N O u t ∈ R L × 4096 \mathrm{FFNOut} \in \mathbb{R}^{L \times 4096} FFNOut∈RL×4096。
💡 理解要点 :SwiGLU 比 ReLU FFN 多一路投影( W 3 W_3 W3),参数量约为 3 ⋅ d model ⋅ d f f 3 \cdot d_{\text{model}} \cdot d_{ff} 3⋅dmodel⋅dff(若 W 1 , W 3 W_1,W_3 W1,W3 分开)或等价形式;输入与输出形状仍为 L × d model L \times d_{\text{model}} L×dmodel。
3.4 单层 LLaMA Decoder 的完整数据流与形状小结
设该层输入为 X i n ∈ R L × d model X_{\mathrm{in}} \in \mathbb{R}^{L \times d_{\text{model}}} Xin∈RL×dmodel:
- X ~ 1 = R M S N o r m ( X i n ) \tilde{X}1 = \mathrm{RMSNorm}(X{\mathrm{in}}) X~1=RMSNorm(Xin) → L × d model L \times d_{\text{model}} L×dmodel。
- A t t n O u t = M a s k e d M u l t i H e a d ( X ~ 1 ) \mathrm{AttnOut} = \mathrm{MaskedMultiHead}(\tilde{X}1) AttnOut=MaskedMultiHead(X~1)(内含 RoPE、掩码、多头、 W O W_O WO)→ L × d model L \times d{\text{model}} L×dmodel。
- X m i d = X i n + A t t n O u t X_{\mathrm{mid}} = X_{\mathrm{in}} + \mathrm{AttnOut} Xmid=Xin+AttnOut → L × d model L \times d_{\text{model}} L×dmodel。
- X ~ 2 = R M S N o r m ( X m i d ) \tilde{X}2 = \mathrm{RMSNorm}(X{\mathrm{mid}}) X~2=RMSNorm(Xmid) → L × d model L \times d_{\text{model}} L×dmodel。
- F F N O u t = S w i G L U ( X ~ 2 ) \mathrm{FFNOut} = \mathrm{SwiGLU}(\tilde{X}2) FFNOut=SwiGLU(X~2) → L × d model L \times d{\text{model}} L×dmodel。
- X o u t = X m i d + F F N O u t X_{\mathrm{out}} = X_{\mathrm{mid}} + \mathrm{FFNOut} Xout=Xmid+FFNOut → L × d model L \times d_{\text{model}} L×dmodel。
整层输入、输出形状均为 L × d model L \times d_{\text{model}} L×dmodel。
4. GQA(Grouped-Query Attention,大模型可选)
LLaMA-2 7B/13B 使用标准 MHA (每头一组 Q、K、V)。LLaMA-2 70B 使用 GQA:多组 Query 头共享同一组 Key/Value 头,以降低 KV 缓存与计算量。
约定 :Query 头数 h q h_q hq,KV 头数 h k v h_{kv} hkv, h k v < h q h_{kv} < h_q hkv<hq,每组 h q / h k v h_q/h_{kv} hq/hkv 个 Q 头共享 1 个 K、V 头。
矩阵形状 (以 70B 为例, h q = 64 h_q=64 hq=64, h k v = 8 h_{kv}=8 hkv=8):
- Q Q Q:仍为 h q h_q hq 个头,每头 L × d k L \times d_k L×dk,总体等价 L × ( h q ⋅ d k ) L \times (h_q \cdot d_k) L×(hq⋅dk)。
- K , V K,\, V K,V:仅 h k v h_{kv} hkv 组,每组 L × d k L \times d_k L×dk,故 K , V ∈ R L × ( h k v ⋅ d k ) K,\, V \in \mathbb{R}^{L \times (h_{kv} \cdot d_k)} K,V∈RL×(hkv⋅dk)。
- 注意力仍按「每 Q 头与对应共享的 K、V 头」计算,每头输出 L × d k L \times d_k L×dk,拼接后仍为 L × d model L \times d_{\text{model}} L×dmodel,再经 W O W_O WO。
GQA 不改变最终 输出形状(仍为 L × d model L \times d_{\text{model}} L×dmodel),只减少 K、V 的参数量与推理时 KV 缓存大小。
5. 输出层:线性层与 Softmax
最后一层 Decoder 输出为 H ∈ R L × d model H \in \mathbb{R}^{L \times d_{\text{model}}} H∈RL×dmodel。取最后一个位置的向量:
h L = H L − 1 , : ∈ R d model . \mathbf{h}L = HL-1,\\, : \in \mathbb{R}^{d{\text{model}}}. hL=HL−1,:∈Rdmodel.
线性层:
s = h L W out + b out , W out ∈ R d model × V , s ∈ R V . \mathbf{s} = \mathbf{h}L \, W{\text{out}} + b_{\text{out}}, \quad W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V}, \; \mathbf{s} \in \mathbb{R}^V. s=hLWout+bout,Wout∈Rdmodel×V,s∈RV.
Softmax : P ( next token ) = s o f t m a x ( s ) P(\text{next token}) = \mathrm{softmax}(\mathbf{s}) P(next token)=softmax(s)。
训练时用交叉熵与真实下一个 token 比较;推理时对 P P P 做 argmax 或采样得到下一个 token,并拼回输入继续自回归。与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 中输出层一致。
6. 与标准 Transformer 的架构对比
下面从「整体结构」与「组件」两方面对比 标准 Transformer(Encoder-Decoder) 与 LLaMA(Decoder-only)。
6.1 整体结构
| 项目 | 标准 Transformer | LLaMA |
|---|---|---|
| 架构 | Encoder-Decoder | Decoder-only(无 Encoder,无交叉注意力) |
| Decoder 子层 | 掩码自注意力 + 交叉注意力 + FFN | 掩码自注意力 + FFN |
| 输入到 Decoder | Embedding + 位置编码(相加) | Embedding(无在 Embedding 上相加的位置编码) |
6.2 组件级对比(含矩阵/公式差异)
| 组件 | 标准 Transformer | LLaMA |
|---|---|---|
| 归一化 | LayerNorm(减均值、除方差,再 scale & shift) | RMSNorm(只除 RMS,再 scale,无减均值) |
| 归一化位置 | Post-Norm: L N ( S u b ( X ) + X ) \mathrm{LN}(\mathrm{Sub}(X) + X) LN(Sub(X)+X) | Pre-Norm : S u b ( R M S N o r m ( X ) ) + X \mathrm{Sub}(\mathrm{RMSNorm}(X)) + X Sub(RMSNorm(X))+X |
| FFN 激活 | R e L U ( X W 1 ) W 2 \mathrm{ReLU}(X W_1) W_2 ReLU(XW1)W2,两矩阵 d → 4 d → d d \to 4d \to d d→4d→d | SwiGLU : ( σ s w i s h ( X W 1 ) ⊙ ( X W 3 ) ) W 2 (\sigma_{\mathrm{swish}}(X W_1) \odot (X W_3)) W_2 (σswish(XW1)⊙(XW3))W2,三矩阵/两路 d → 4 d → d d \to 4d \to d d→4d→d |
| 位置编码 | 正弦/余弦或可学习,与 Embedding 相加 | RoPE :在注意力内对 Q、K 旋转,不改变形状 |
| 注意力 | MHA | MHA(7B/13B);GQA(70B) |
6.3 单层 Decoder 公式对比
标准 Transformer Decoder 一层(Post-Norm + LayerNorm):
O u t = L N 2 ( F F N R e L U ( L N 1 ( A t t n ( X ) + X ) ) + L N 1 ( A t t n ( X ) + X ) ) . \mathrm{Out} = \mathrm{LN}2\Big( \mathrm{FFN}{\mathrm{ReLU}}\big( \mathrm{LN}_1( \mathrm{Attn}(X) + X ) \big) + \mathrm{LN}_1( \mathrm{Attn}(X) + X ) \Big). Out=LN2(FFNReLU(LN1(Attn(X)+X))+LN1(Attn(X)+X)).
LLaMA Decoder 一层(Pre-Norm + RMSNorm):
h = X + A t t n ( R M S N o r m ( X ) ) , O u t = h + S w i G L U ( R M S N o r m ( h ) ) . h = X + \mathrm{Attn}(\mathrm{RMSNorm}(X)), \qquad \mathrm{Out} = h + \mathrm{SwiGLU}(\mathrm{RMSNorm}(h)). h=X+Attn(RMSNorm(X)),Out=h+SwiGLU(RMSNorm(h)).
更直观的流程即:RMSNorm → Attn → Add → RMSNorm → SwiGLU → Add,且 Attn 内对 Q、K 使用 RoPE。
7. 小结:LLaMA 各环节矩阵与公式汇总
- 输入 :Tokenization → Embedding E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel → X ∈ R L × d model X \in \mathbb{R}^{L \times d_{\text{model}}} X∈RL×dmodel;无在 Embedding 上相加的位置编码。
- 位置 :RoPE 在注意力层内作用于 Q、K,不改变 L × d k L \times d_k L×dk 形状。
- 单层 :
- RMSNorm( X X X) → 掩码 MHA(或 GQA)+ 残差 → RMSNorm → SwiGLU FFN + 残差;
- 所有中间与输出形状均为 L × d model L \times d_{\text{model}} L×dmodel。
- 输出 : h L ∈ R d model \mathbf{h}L \in \mathbb{R}^{d{\text{model}}} hL∈Rdmodel → W out ∈ R d model × V W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} Wout∈Rdmodel×V → s ∈ R V \mathbf{s} \in \mathbb{R}^V s∈RV → Softmax。
结合 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 可对照查看:LLaMA 在「无交叉注意力、Decoder-only」这一点上与之一致,在归一化、归一化顺序、FFN 激活与位置编码方式上做了替换与优化。
8. 各环节参数量简要(LLaMA)
与 Transformer 10. Decoder Only Transformer 架构以及每一步骤的详细计算 对照,LLaMA 的差异主要在归一化与 FFN。
| 模块 | 形状/公式 | 参数量(权重) |
|---|---|---|
| Embedding | E ∈ R V × d model E \in \mathbb{R}^{V \times d_{\text{model}}} E∈RV×dmodel | V ⋅ d model V \cdot d_{\text{model}} V⋅dmodel |
| 位置编码 | RoPE 无额外参数 | 0 |
| 单层注意力 | W Q , W K , W V W_Q,W_K,W_V WQ,WK,WV 共 3 d model 2 3 d_{\text{model}}^2 3dmodel2, W O W_O WO 为 d model 2 d_{\text{model}}^2 dmodel2 | 4 d model 2 4 \, d_{\text{model}}^2 4dmodel2 |
| 单层 RMSNorm(2 个) | 每处仅 γ ∈ R d model \boldsymbol{\gamma} \in \mathbb{R}^{d_{\text{model}}} γ∈Rdmodel,无 β \beta β | 2 ⋅ d model 2 \cdot d_{\text{model}} 2⋅dmodel |
| 单层 SwiGLU FFN | W 1 , W 3 ∈ R d × 4 d W_1,\, W_3 \in \mathbb{R}^{d \times 4d} W1,W3∈Rd×4d, W 2 ∈ R 4 d × d W_2 \in \mathbb{R}^{4d \times d} W2∈R4d×d | 2 ⋅ d ⋅ 4 d + 4 d ⋅ d = 12 d model 2 2 \cdot d \cdot 4d + 4d \cdot d = 12 \, d_{\text{model}}^2 2⋅d⋅4d+4d⋅d=12dmodel2 |
| 输出层 | W out ∈ R d model × V W_{\text{out}} \in \mathbb{R}^{d_{\text{model}} \times V} Wout∈Rdmodel×V | d model ⋅ V d_{\text{model}} \cdot V dmodel⋅V |
单层 Decoder 合计(权重): 4 d model 2 + 12 d model 2 + 2 d model = 16 d model 2 + 2 d model 4 \, d_{\text{model}}^2 + 12 \, d_{\text{model}}^2 + 2 \, d_{\text{model}} = 16 \, d_{\text{model}}^2 + 2 \, d_{\text{model}} 4dmodel2+12dmodel2+2dmodel=16dmodel2+2dmodel。 N N N 层总参数量约为 N ⋅ ( 16 d model 2 + 2 d model ) + V ⋅ d model + d model ⋅ V N \cdot (16 \, d_{\text{model}}^2 + 2 \, d_{\text{model}}) + V \cdot d_{\text{model}} + d_{\text{model}} \cdot V N⋅(16dmodel2+2dmodel)+V⋅dmodel+dmodel⋅V。LLaMA 的 SwiGLU 比标准 ReLU FFN 多一组 d → 4 d d \to 4d d→4d 的投影,故 FFN 部分为 12 d 2 12 d^2 12d2 而非 8 d 2 8 d^2 8d2;RMSNorm 无 shift 参数 β \beta β,每处仅 d model d_{\text{model}} dmodel 个参数。