2026-1-15
tips:
gethub的download zip 之后,浏览器上下载卡住了:使用 fdm(free download Manager)
右键下载链接复制到fdm即可
anaconda常用指令
进入 Anaconda prompt
conda create -n 环境名称 python=3.6
ad: conda create -n tudui python=3.6
conda list 获取base环境中的所有包
conda env list 表示Anaconda里面所有的环境
conda activate tudui 激活"tudui"这个环境
当然也可以用Anaconda Navigator这种可视化页面来操作
在tudui环境中安装notebook的包
conda activate tudui
conda install nb_conda (注意这里最好别用pip)
jupyter notebook
主要是要看conda list里面有没有ipkernel,没有就需要安装这个包
然后用浏览器进入
新建对应conda环境tudui的notebook
验证:import torch
torch.cuda.is_available()
正确输出:true
help()与dir()
help(torch.cuda.is_available)
dir(torch.cuda.is_available())
Dataset与Dataloader
Dataset和 DataLoader是 PyTorch 中数据加载的两个核心组件,它们分工明确,一起协作完成高效的数据加载和处理。
1. Dataset
-
定义 :数据集的定义者和描述者
-
职责 :负责定义数据如何组织、存储和读取
-
关键方法:
-
__len__():返回数据集的大小 -
__getitem__():根据索引返回单个数据样本
-
-
特点:被动组件,不管理批次、打乱等
python
from torch.utils.data import Dataset
import torch
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx] # 返回单个样本
# 创建数据集
dataset = MyDataset(torch.randn(100, 3, 32, 32)) # 100个样本
print(f"数据集大小: {len(dataset)}") # 100
sample = dataset[0] # 获取第一个样本
print(f"样本形状: {sample.shape}") # torch.Size([3, 32, 32])2. DataLoader
-
定义 :数据加载的管理者和执行者
-
职责 :负责批量加载、打乱、并行处理等
-
关键功能:
-
批量处理
-
数据打乱
-
多进程并行加载
-
数据预处理
-
-
特点:主动组件,管理加载流程
python
from torch.utils.data import DataLoader
# 创建数据加载器
dataloader = DataLoader(
dataset, # 传入 Dataset
batch_size=16, # 批次大小
shuffle=True, # 打乱数据
num_workers=2, # 并行进程数
drop_last=True # 丢弃最后一个不完整的批次
)
# 遍历批次
for batch in dataloader:
print(f"批次形状: {batch.shape}") # torch.Size([16, 3, 32, 32])
breakP6_Dataset类代码实战

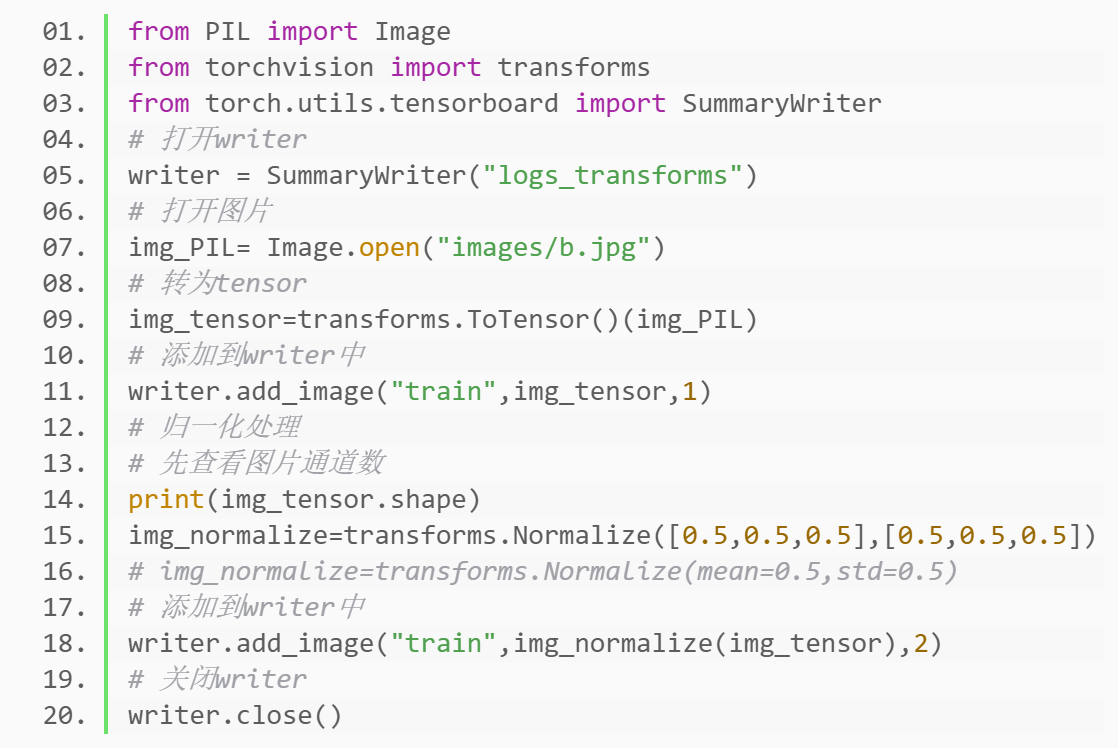
P7_TenSorBoard的使用(一)

P8_TenSorBoard的使用(二)
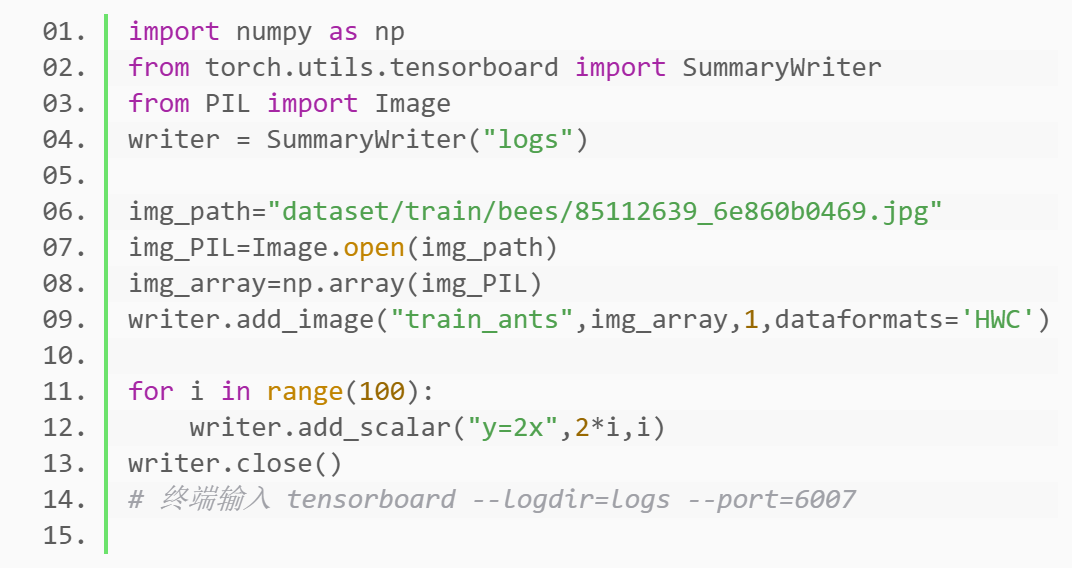
P9_Transforms的使用(一)