MLMs之Agent之Qwen:Qwen3.5的简介、安装和使用方法、案例应用之详细攻略
目录
[第三方工具联动:OpenClaw 集成](#第三方工具联动:OpenClaw 集成)
[视觉智能体与自动化(多示例):GUI 智能体、视觉编程、空间智能](#视觉智能体与自动化(多示例):GUI 智能体、视觉编程、空间智能)
[视觉推理与解题(教育 / STEM 场景)](#视觉推理与解题(教育 / STEM 场景))
Qwen3.5 的 简介

Qwen3.5-397B-A17B 是Qwen3.5系列的第一款模型,于2026年2月14日正式发布开放权重版本。它是一个原生视觉-语言模型,旨在通过统一的架构处理和理解多种模态的信息。该模型在推理、编程、智能体能力与多模态理解等多个维度的基准评估中表现优异,其设计目标是助力开发者和企业显著提升生产力。
Qwen3.5 是一次面向 原生多模态智能体 的系统性升级:在架构(混合注意力 + MoE)、预训练数据、RL 环境扩展、系统与硬件协同优化方面同时发力。智能体长期发展方向,指出下一阶段重点是从模型规模转向系统整合:包括跨会话持久记忆、具身接口(embodied interfaces)与自我改进机制,目标是打造能够长期自主运行且逻辑一致的智能体------从"按任务边界的助手"升级为"可持续、可信赖的伙伴"。
官网地址 :https://qwen.ai/blog?id=qwen3.5
1、 特点
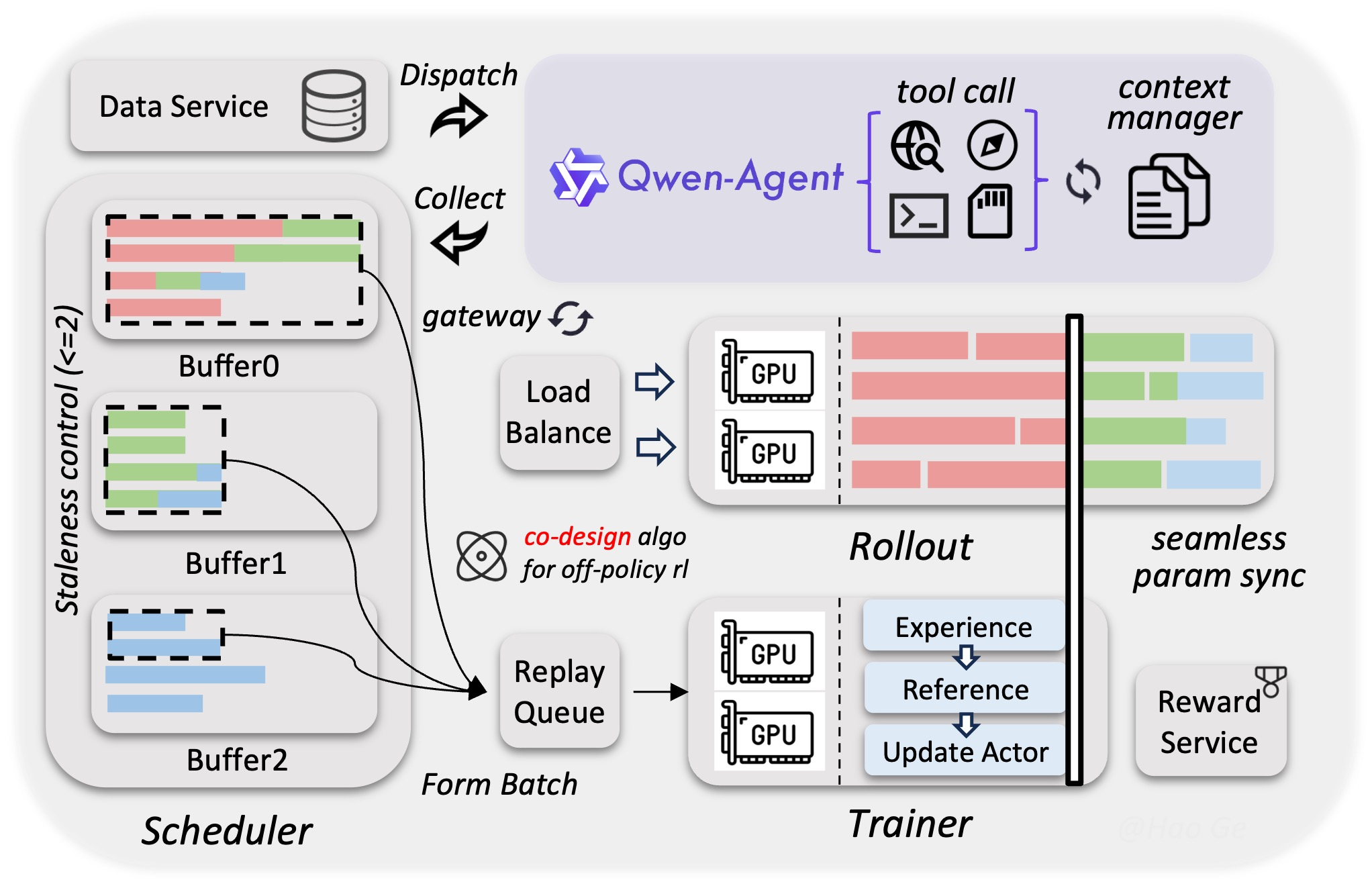
>> 创新的混合架构: 模型采用了一种将线性注意力(Gated Delta Networks) 与稀疏混合专家(MoE) 相结合的新型架构。这种设计在保持强大模型能力的同时,优化了推理速度与成本。采用混合架构,将线性注意力(Gated Delta Networks / Gated Attention)与稀疏混合专家(MoE)结合,达到高效推理与能力保留的折中。每次前向传播仅激活约 170 亿 参数以降低成本与延迟。将 Gated DeltaNet(线性/混合注意力变体)与高稀疏度的 MoE 结合,既保证模型能力又显著提升计算/推理效率。
>> 高效的激活参数: 模型总参数量达到3970亿,但在每次前向传播中,仅激活其中的170亿参数。这种稀疏激活的方式是其实现高效推理的关键。
>> ****原生多模态能力:****作为原生视觉-语言模型,它天生具备处理图像和文本混合输入的能力,能够执行复杂的视觉理解和推理任务。在预训练阶段就采用文本-视觉早期融合策略,增强视觉 + STEM + 视频能力,使得在同规模下优于之前的 Qwen3-VL。支持像素级空间理解(物体计数、相对位置、空间关系),对遮挡和视角变化鲁棒性更好。
>> 超长上下文窗口(API版本): 通过阿里云百炼平台提供的API版本 Qwen3.5-Plus,支持高达 1M token 的上下文窗口,能够一次性处理如三体三部曲体量的长篇内容。在 32k/256k 长上下文场景下,Qwen3.5-397B-A17B 的解码吞吐量远超前代(文中给出与 Qwen3-Max 与 Qwen3-235B 的倍数对比),在保持性能的同时大幅提高速度。
****>> 能力倾向:****文中强调 Qwen3.5 在自然语言理解、视觉问答、STEM(数学)、编程代理与通用 Agent 能力等多项基准上有显著表现。作者同时指出 Qwen3.5 的提升很大程度上来自更广泛、更难、可泛化的强化学习(RL)训练集与环境扩展。
>> 广泛的多语言支持: 模型支持的语言和方言数量从之前的119种大幅扩展至201种,为全球更多地区的用户提供了可用性。词表从 15 万扩到 25 万,提升编码/解码效率。词表扩充至 250k,带来 10--60% 的编码/解码效率提升(视语言而定)。
>> 训练与系统工程优化:异构基础设施(视觉/语言组件解耦并行)、原生 FP8 流水线、激活显存降低、动态路由与 MoE 优化,使训练吞吐率接近或达到纯文本基线的近 100%。可扩展的异步强化学习框架(训推分离、Rollout 路由回放、投机采样、多轮 Rollout 锁定等)提升硬件利用率、训练稳定性与端到端加速(文中提到 3×--5× 加速范围)。
工具与代理能力(agent):模型内建对链式思考 / 推理模式的支持,能边思考、边搜索、边调用工具(search、Code Interpreter 等)。官方提供三种交互模式:自动(auto,带自适应思考与工具调用)、思考(thinking,深度推理链)、快速(fast,直接回答且不消耗思考 token)。
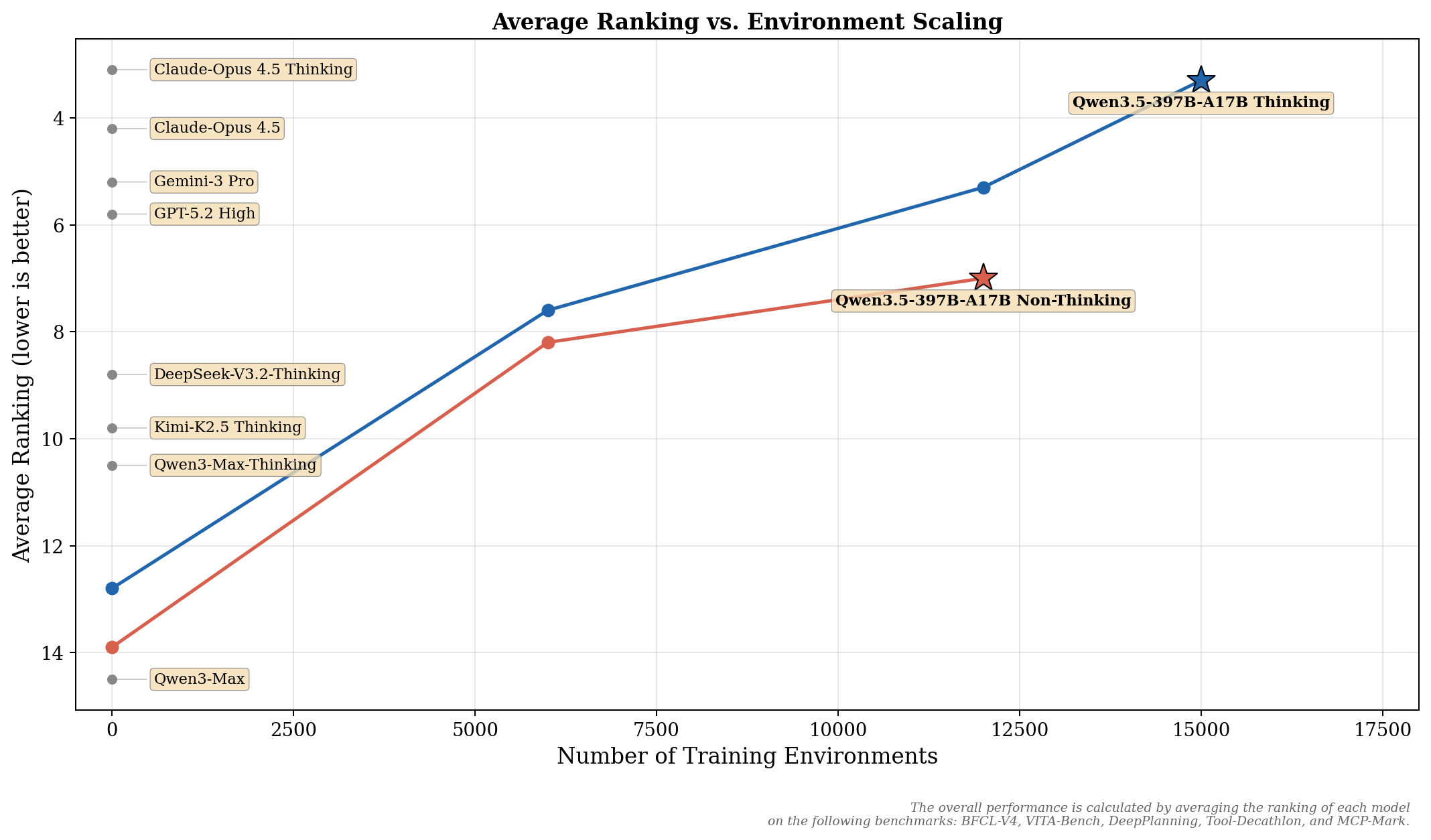
2、 模型性能
根据官网文章中公布的评估数据,Qwen3.5-397B-A17B在与GPT-5.2、Claude 4.5 Opus等前沿模型的对比中,展现了全面且具有竞争力的性能:
>> 自然语言处理:在知识类(MMLU-Pro 87.8分)、指令遵循(IFBench 76.5分、MultiChallenge 67.6分)和多语言任务(NOVA-63 59.1分、MAXIFE 88.2分)上表现突出。
>> 视觉语言理解:在数学推理(MathVision 88.6分、Mathvista 90.3分)、文档理解(OmniDocBench1.5 90.8分、OCRBench 93.1分)和空间智能(RefCOCO 92.3分、V*基准 95.8分)等多个视觉任务上取得了领先或顶尖的分数。
>> 智能体能力:在通用智能体(BFCL-V4 72.9分、TAU2-Bench 86.7分)、搜索智能体(BrowseComp 78.6分)和编程智能体(SecCodeBench 68.3分)等任务上也展现出强大的工具使用和任务执行潜力。
Qwen3.5 的 安装与使用方法
1、安装
官网文章主要介绍了模型的开放权重版本和API服务版本:
- 开放权重版本:文章提到发布了 Qwen3.5-397B-A17B 的开放权重版本,开发者可以获取模型权重进行本地部署和研究。
- API服务版本:对于希望通过API直接调用的用户,可以通过阿里云百炼平台使用该模型的API版本 Qwen3.5-Plus。该版本不仅拥有1M的超长上下文,还集成了官方工具及自适应调用功能。
在 Qwen Chat 上可直接使用三种交互模式(auto / thinking / fast)。
若通过云 API 使用(原文以阿里云百炼为例),需要获得百炼的 API Key 并配置相应环境变量,调用 qwen3.5-plus(或按需覆盖模型名)。
可通过 extra_body 参数开启思考(链式思考)或联网搜索 / Code Interpreter 等能力(示例参数:enable_thinking, enable_search)。
2、使用方法
用户可通过阿里云百炼调用我们的旗舰模型 Qwen3.5-Plus 进行体验。若要开启推理、联网搜索与 Code Interpreter 等高级能力,只需传入以下参数:
enable_thinking:开启推理模式(链式思考)enable_search:开启联网搜索与 Code Interpreter
python
"""
Environment variables (per official docs):
DASHSCOPE_API_KEY: Your API Key from https://bailian.console.aliyun.com
DASHSCOPE_BASE_URL: (optional) Base URL for compatible-mode API.
DASHSCOPE_MODEL: (optional) Model name; override for different models.
DASHSCOPE_BASE_URL:
- Beijing: https://dashscope.aliyuncs.com/compatible-mode/v1
- Singapore: https://dashscope-intl.aliyuncs.com/compatible-mode/v1
- US (Virginia): https://dashscope-us.aliyuncs.com/compatible-mode/v1
"""
from openai import OpenAI
import os
api_key = os.environ.get("DASHSCOPE_API_KEY")
if not api_key:
raise ValueError(
"DASHSCOPE_API_KEY is required. "
"Set it via: export DASHSCOPE_API_KEY='your-api-key'"
)
client = OpenAI(
api_key=api_key,
base_url=os.environ.get(
"DASHSCOPE_BASE_URL",
"https://dashscope-intl.aliyuncs.com/compatible-mode/v1",
),
)
messages = [{"role": "user", "content": "Introduce Qwen3.5."}]
model = os.environ.get(
"DASHSCOPE_MODEL",
"qwen3.5-plus",
)
completion = client.chat.completions.create(
model=model,
messages=messages,
extra_body={
"enable_thinking": True,
"enable_search": False
},
stream=True
)
reasoning_content = "" # Full reasoning trace
answer_content = "" # Full response
is_answering = False # Whether we have entered the answer phase
print("\n" + "=" * 20 + "Reasoning" + "=" * 20 + "\n")
for chunk in completion:
if not chunk.choices:
print("\nUsage:")
print(chunk.usage)
continue
delta = chunk.choices[0].delta
# Collect reasoning content only
if hasattr(delta, "reasoning_content") and delta.reasoning_content is not None:
if not is_answering:
print(delta.reasoning_content, end="", flush=True)
reasoning_content += delta.reasoning_content
# Received content, start answer phase
if hasattr(delta, "content") and delta.content:
if not is_answering:
print("\n" + "=" * 20 + "Answer" + "=" * 20 + "\n")
is_answering = True
print(delta.content, end="", flush=True)
answer_content += delta.contentQwen3.5 的 案例应用
1、基础用法
根据其强大的多模态理解和智能体能力,可以推断出丰富的应用方向。文章特别强调了在"搜索智能体"和"视觉智能体"方面的潜力,例如:
复杂的搜索智能体
模型在BrowseComp、WideSearch等需要结合工具进行信息查找和整合的基准上表现优异,可用于构建能够理解复杂查询、自主浏览网页并整合信息的下一代搜索引擎或研究助手。
视觉交互智能体
在ScreenSpot Pro、OSWorld-Verified等视觉智能体基准上的表现,预示着模型可以作为"眼睛"和"大脑",驱动能够理解和操作图形用户界面(GUI)的自动化程序,例如自动化测试、跨应用工作流执行等。
高级文档分析
在OmniDocBench、CC-OCR等文档理解基准上的高分,表明模型能够精确地从复杂的扫描文档、图表、截图中提取并推理信息,适用于金融、法律、科研等领域的深度文档分析。
2、进阶用法
集成与编程辅助
网页开发 / 前端生成:Qwen3.5 能将自然语言指令转为可运行的前端代码,擅长 UI 构建与网页开发任务,能把简单指令转为可直接运行的代码片段(文中演示"网页开发")。
Qwen Code(编码体验):以 Qwen3.5 为底层,Qwen Code 提供所谓的 "vibe coding" 体验:把自然语言实时迭代为代码、支持富创意任务(如生成视频等)。(在本文档中的演示项里有相关示例。)
第三方工具联动 : OpenClaw 集成
OpenClaw 集成:文中展示 Qwen3.5 与 OpenClaw 集成的演示:通过 OpenClaw 作为第三方智能体环境,模型能进行网页搜索、信息收集与结构化报告生成 ------ 体现模型与外部工具/接口联动的能力("Search and Report" 演示)。
Code Interpreter / 搜索工具:在 API 中可通过 enable_search、enable_thinking 等参数开启联网搜索与 Code Interpreter,从而实现边思考边检索并执行代码的工作流。
视觉智能体与自动化(多示例) : GUI 智能体 、 视觉编程 、 空间智能
GUI 智能体:在移动端与 PC 端分别演示,移动端适配主流应用并支持自然语言驱动操作;PC 端可以跨应用执行数据整理与多步骤流程自动化(示例:Excel 的"填补缺失行/列并求总值"场景)。
视觉编程:将手绘界面草图转换为结构清晰的前端代码;把简单游戏视频还原为逻辑并生成前端实现(文中有"Video Game to Code"示例)。
空间智能 / 自动驾驶场景:基于像素级位置建模,模型可进行物体计数、相对位置判断和空间关系描述,示例中包含驾驶场景的帧序列分析(分析为何车辆在某时刻没有停车的判定示例)。
视觉推理与解题(教育 / STEM 场景)
迷宫最短路径:文中展示了如何解析迷宫图像、网格化(21×21,单元格 28 像素)、定位起终点并用 BFS 找到最短路径(示例实现与绘制流程与代码都在文中)。
找不同 / 视觉辨识题:演示模型对小差异图像的细粒度定位能力(文中示例定位到第一行第 4 个为不同项并给出判定依据)。
数学/推理结合视觉:在 MathVision、We-Math 等多模态 STEM 基准上,模型在图文混合题型也有专门表现(文中列出该类基准及成绩摘要)。