前言
在 LLM 落地应用的过程中,推理效率和部署门槛是开发者面临的两大痛点。llama.cpp 以其卓越的跨平台兼容性和惊人的推理速度,成为了当前本地推理事实上的工业标准。本系列文章将构建一条从"应用使用"到"源码解析"的学习曲线,包含入门与概览、模型加载与初始化、推理循环核心、计算后端与性能调优、总结与展望五个部分。第一章"初识 llama.cpp-轻量级推理引擎"作为入门与概览的首篇文章,将从简介、编译、本地运行三个方面,快速建立对llamacpp的认识。
目录
- 1 简介
- 2 编译
- 3 本地运行
1 简介
llama.cpp 的核心目标是:在本地及云端的各类硬件平台上,以极简的配置实现业界顶尖的大语言模型(LLM)推理性能。 该项目采用纯 C/C++ 开发,完全脱离了对外部库的依赖,通过针对 Apple Silicon、x86 及 RISC-V 架构的深度指令集优化,以及对 1.5-bit 到 8-bit 整数量化技术的支持,在显著降低显存占用的同时实现了飞跃式的推理速度。凭借对 CUDA、Metal、Vulkan 等多样化计算后端的高效兼容,以及独具特色的 CPU+GPU 混合推理模式,它不仅确保了模型在各类主流及国产硬件上的极致表现,更成为了 ggml 库探索前沿功能、驱动生态创新的核心阵地。
2 编译
llama.cpp 具备卓越的跨平台兼容性,支持在 Windows、Linux、macOS、Android 及各类嵌入式设备上,针对 CPU、CUDA、Metal 或 Vulkan 等多样化硬件后端进行高效编译与部署。接下来,我们将以 Windows 11 环境为例,详细说明开启 CUDA 加速(适用于 NVIDIA 显卡)或仅采用 CPU 推理模式下的具体编译流程与操作细节。
在开始编译前,请确保系统中已正确安装以下开发工具链:
1) Visual Studio 2022:核心编译器,安装时务必勾选"使用 C++ 的桌面开发"组件。
2) CUDA Toolkit 11.8(可选):NVIDIA 显卡驱动加速工具包,用于开启 GPU 推理能力。若您的显卡非 NVIDIA 或仅计划使用 CPU 进行推理,可跳过此项安装,后续编译时将默认采用 CPU 后端。
3) CMake:跨平台项目构建工具,建议版本 3.20 或以上。
其中CUDA Toolkit 11.8的环境配置,首先前往官网CUDA Toolkit 11.8 Downloads | NVIDIA Developer,接着选择Windows、x86_64、11、exe(local),将安装包(约3GB)下载到本地,同时安装前请务必提前安装VS 2022,安装完成后,CUDA会自动向系统注入环境变量,可手动检查进行确认,可在Path变量中找到如下两条记录:

在cmd命令窗口中,运行nvcc --version命令,得到如下输出,表明CUDA Toolkit安装和环境配置成功。

接着编译并安装llama.cpp,运行如下命令,将源码下载到本地:
git clone https://github.com/ggml-org/llama.cpp.git采用CMake-gui构建解决方案,在Where is the source code中选择源码根目录,在 Where to build the binaries 中选择或新建一个 build 文件夹,点击Configure按钮,在弹窗中选择Visual Studio 17 2022和x64。

在 CMake-gui 的配置过程中,针对需要开启 GPU 加速的用户,可勾选GGML_CUDA选项,取消勾选GGML_NATIVE选项,再次点击Configure按钮,CMake-gui界面会出现与CUDA相关选项,如下图所示,具体的依赖CUDA环境的构建方法可详见[++++llama.cpp/docs/build.md at master · ggml-org/llama.cpp++++](#llama.cpp/docs/build.md at master · ggml-org/llama.cpp)。

接着分别点击Generate、Open Project按钮, Visual Studio 顶部工具栏中,将编译配置由Debug切换为Release,在右侧"解决方案资源管理器"中,右键点击解决方案 'llama.cpp',选择"生成解决方案",编译完成后点击Install项目,将编译完成的llama-server.exe等拷贝到安装目录,而安装目录为CMake-gui界面中CMAKE_INSTALL_PREFIX对应的路径,用户可在点击Configure按钮前进行修改。一个包含llama-server.exe的打包文件夹,可从此链接下载,用于读者本地体验。
3 本地运行
在顺利完成 llama.cpp 的编译构建后,高性能推理框架已准备就绪。接下来的核心任务是为其配置支撑智能推理的关键组件------大语言模型权重文件。llama.cpp 使用的是经过优化的 GGUF 格式。GGUF可在Hugging Face(Hugging Face -- The AI community building the future.)或其镜像网站(HF-Mirror)上下载,可搜索gemma-3-1b-it-GGUF并点击gemma-3-1b-it-Q4_K_M.gguf模型进行下载,其中gemma-3为模型所属的家族,由Google开发的开源大模型系列Gemma的第三代(version 3),1b表示参数规模,具体表示模型包含10亿参数。it表示模型类型/变体,具体为Instruction Tuned(指令微调),Q4_K_M表示模型量化等级,表示对原始模型(FP16)权重进行了多大程度的压缩(量化),Q4代表4-bit量化,K表示使用了K-Quants算法,M代表Medium,在同意量化位数下,通常有S(Small)、M(Medium)、L(large)之分。GGUF命名规范详细见ggml/docs/gguf.md at master · ggml-org/ggml中GGUF Naming Convention部分。
在准备好推理引擎与模型文件后,接下来我们将通过运行llama-server.exe并配置关键参数(如-m指定模型路径与-ngl 99开启全量 GPU 加速)来激活本地 AI 服务。在建立起一个兼容 OpenAI API 规范的高性能推理接口的同时,可在浏览器中通过http://127.0.0.1:8080访问可视化交互界面,正式开启与本地大模型的零延迟对话体验,如下图所示:
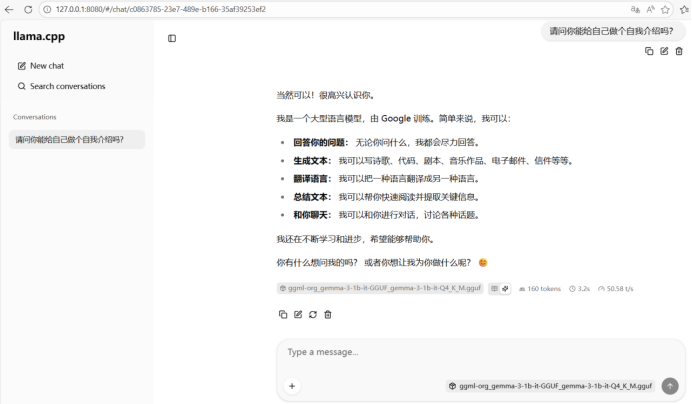
此问答过程为GPU推理,可通过llama-server.exe启动时相关日志看出:

文末:作为本系列的开篇,本文从简介、编译、本地运行三个方面,为读者快速建立了对llamacpp的认识。在本文的最后运行了本地大模型服务,下一章将进一步深入从命令行到HTTP Server的过程,包括应用实战(启动大模型服务),并进一步深入代码,探索基于 cpp-httplib 的大模型服务运行机制。