引言
RAG在今天已经不是什么稀奇玩意了,懂或不懂的多多少少都会讲出点门道。小马之前也介绍过相关的文章链接: 《RAG检索增强生成:通过重排序提升AI信息检索精准度》。至于RAG的具体原理小马再次就不做赘述了。然而在实际的真实场景中,往往会面临着真实效果的上限问题,通用的RAG似乎都无法满足特定化的业务场。于是,我们往往需要针对其做特定业务的召回优化(专属)。
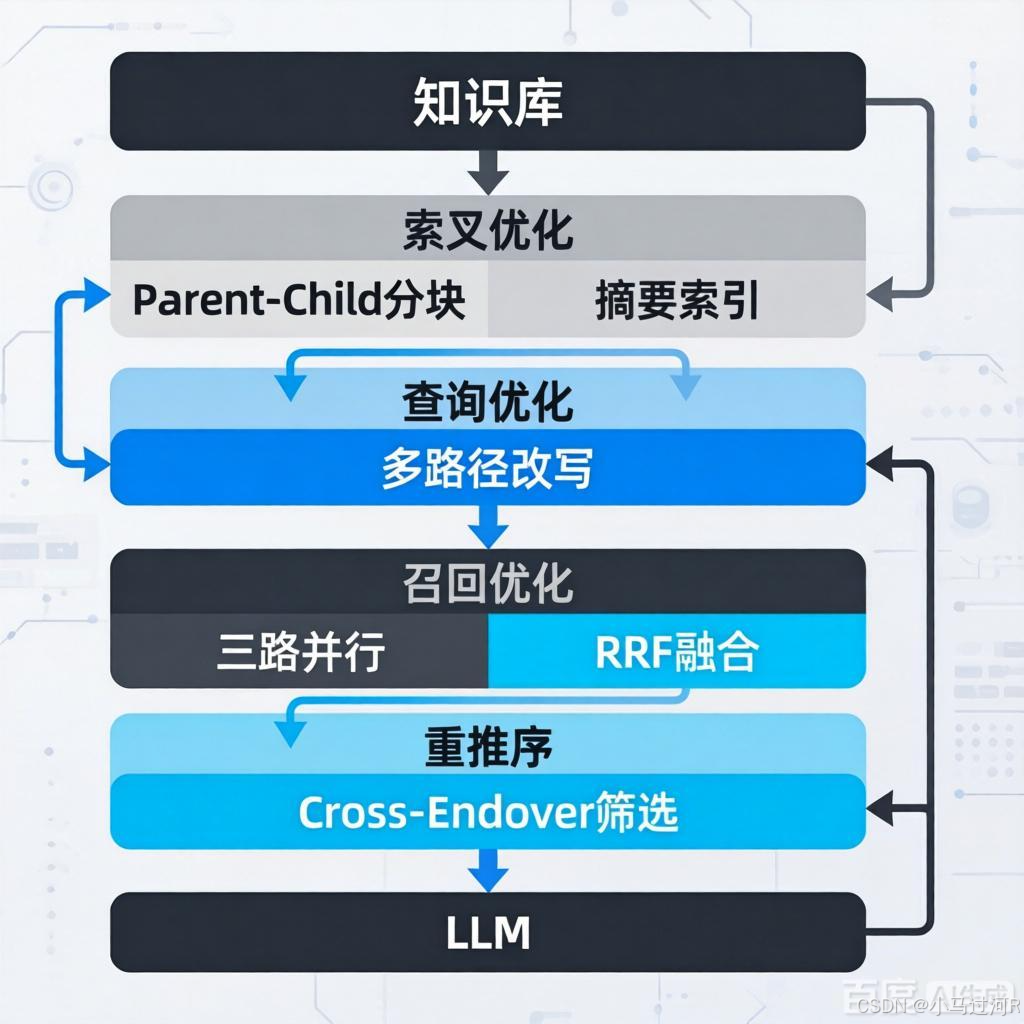
检索增强生成(RAG)系统的效果瓶颈往往在于检索环节,优化生成层(如调整提示词、更换模型)是"锦上添花",而检索优化则是"雪中送炭" ,直接决定了系统性能的上限 。以下是基于索引层、查询层、召回层、重排序层 的系统性优化策略,逻辑严密,可组合使用。

第一层:索引优化 -- 解决"检索粒度"与"上下文完整性"的矛盾
检索任务需要语义聚焦的小粒度文档块,而大语言模型(LLM)推理需要上下文完整的大粒度文本。若直接采用单一粒度划分,会出现小粒度内容在检索中表现精准但LLM理解碎片化,或大粒度内容在检索中语义被稀释的困境。
解决方案:采用"小块检索,大块使用"策略
1. 父子分块(Parent-Child Chunking)
创建两种粒度 的文档块:
子块:粒度较小(如150 Token),单独建立向量索引用于检索。
父块:粒度较大(如500 Token),与子块建立关联(如通过parent_id字段)。
流程:检索→按子块匹配→命中后将关联的父块送入LLM。这样既能精准召回 ,又能让LLM获得完整上下文。
2. 摘要索引(Summary Index)
对每段文本生成摘要,用摘要文本建立向量索引。由于摘要更凝练,语义更聚焦,检索命中率更高;命中后则将原文内容送入LLM。
优势:提升了索引质量,弥补了原文表达散乱可能导致的检索偏差。
3. 多粒度分层索引
同时建立章节、段落、句子等多个粒度的索引。
根据问题的宽泛程度自动选择不同索引粒度:概念性问题用章节级,细节查询用句子级。
**总结索引优化思路:**保证"存入的知识"格式既能有效检索(靠小粒度聚焦),又便于LLM阅读(靠大粒度完整)。
第二层:查询优化 -- 弥合用户提问与知识库表达间的鸿沟
当用户的查询表述口语化、指代不明或问题角度与文档视角不同时,向量距离被拉远,直接检索命中率可能降低。
核心方法:对查询进行加工、转换
1. 查询改写(Query Rewriting)
利用LLM将口语化、有歧义的查询转为规范的书面表达。
例如:"它为什么贵?" → "iPhone 15 Pro Max的定价策略和成本构成分析?"
2. 多查询扩展(Multi-Query)
将一个问题扩展为3~5个不同角度的表述(同时保留原查询),每种子查询分别进行向量检索,最终合并结果。
作用:增加从不同视角"触达"文档的可能性,提高召回率。
3. 假设文档嵌入(HyDE -- Hypothetical Document Embeddings)
不直接用原始查询向量检索。而是让LLM生成一个"假设的答案"示例,用该假设答案的向量(而不是原问题向量)做检索。
逻辑:答案与文档是同类文体(都是陈述句),向量距离可能更近。但要注意知识边界明确的领域使用更安全,避免因生成错误假设而偏离检索。
4. 后退提问(Step-Back Prompting)
遇到高度具体的问题但知识库只有普适背景时:先提炼出一个"抽象版"或更通用的背景问题,用它去检索,获取背景信息后再用来解答具体问题。
例如:"Transformer里sqrt(d_k)是干嘛的?" → 抽象为:"Attention机制中的缩放因子有哪些数学原理?"
第三层:召回优化 -- 采用多路检索,覆盖更广泛语义空间
任何单一检索路径都有盲区。例如:
向量检索 能捕捉语义相似(如同义词),但可能忽略精确术语匹配。
关键词检索(如BM25)基于精确词汇,但无法理解不同表述的同一语义。
方案:多路并行 + 融合排序(RRF算法)
1. 典型三路召回路径:
向量检索 :捕捉语义相近内容。
关键词检索 :精确词汇匹配。
混合检索/其他检索器:补充基于元数据或图结构的检索。
2. 融合排序:倒数排名融合(RRF -- Reciprocal Rank Fusion)
思路:忽略不同路径的原始分数差异,只看各路径返回的排名顺序 。
公式:每个候选块的得分 = Σ 1 / (k + rank)。通常k=60(平滑参数)。
优点:简单、无模型训练、兼容不同分数体系(各路径不需要归一化)。
3. 作用:
利用多条路径补全彼此的检索盲点,实现候选集最大化,提高召回覆盖度。
RRF公平地聚合各类排名,获得综合质量排序,是多路召回的标准融合手段。
第四层:重排序(Rerank) -- 保证送入LLM的内容精而准
从召回优化得到的20-30个候选文档虽然覆盖率提高了,但仍包含杂质,需进行精排,选出最相关的3-5个交付给LLM。其原因:
Token开销 :太多候选会推高成本和响应延迟。
"迷失在中段"(Lost in the Middle)现象:LLM对长篇幅上下文的中段内容可能"忽略"或关注不足,造成重要信息被淹没。
为什么不用原始向量检索替代Rerank?
向量检索常采用双编码器(Bi-encoder):查询 + 文本分别编码→向量比较。速度快、适合实时召回,但查询-文本间的具体词义交互信息丢失,精度受限。
Rerank采用交叉编码器(Cross-encoder):查询;文本拼接成一条文本输入,模型从整体判断相关性。
核心区别:Bi-encoder只比较摘要向量,Cross-encoder看两者之间的直接互动,精确性更高,但运行速度慢,适合在小候选集上做精排。
实现流程:
- 多路召回得到20-30个候选。
- 用交叉编码器对每个query, chunk对计算相关性分数。
- 按分数降序取Top3~5送入LLM。
常用模型 :BGE-Reranker-v2、BCE-Reranker,或云服务(如Cohere Rerank API、Jina Reranker API)。该层成本效益高,常显著提升最终答案质量。
四层组合策略(生产级推荐)
| 层级 | 解决的核心问题 | 推荐方法 | 何时应用 |
|---|---|---|---|
| 索引层 | 文档划分粒度不适配 | Parent-Child分块 / 多粒度索引 | 多数场景,提高检索粒度与上下文的兼容性 |
| 查询层 | 提问方式与存储内容不匹配 | Query改写、Multi-Query、HyDE等 | 用户提问含糊、口语化或指代不明时必用 |
| 召回层 | 单一路径检索的盲区 | 向量+BM25多路召回,RRF融合 | 低成本、显著减少漏召,适用于绝大多数系统 |
| 重排层 | 召回结果杂,送入LLM无效 | Cross-encoder Rerank | 精提升、降低冗余输入,提高LLM使用效率 |
典型生产级组合:
Parent-Child索引 → (如有需要,加上查询层改写或多查询) → 向量+BM25多路召回 → 交叉编码器Rerank。
这种组合涵盖了存储、提问理解、多路径检索、最终精排的系统思路,能稳定应对绝大多数业务检索场景。
通过分层次的检索优化,系统能从根本上提升RAG的上限和稳定可靠性。在实际面试或工程项目中,强调这一框架和层级协作的逻辑性,通常能体现出系统性思维和实际的工程经验积累。