一、前言
Elasticsearch是一个搜索引擎中间件,可以通过自动分出的中文词条来替代以往在dao层使用的like关键字,其实我们完全可以把Elasticsearch看作一个新的数据库,不过这个数据库的搜索性能非常好,并且底层使用的算法和mysql大不相同。
二、Elasticsearch简介
在正式学习es之前,我们将在docker中添加es和kibana的容器:
bash
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
bash
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1这个kibana是es的一个图形化界面,就类似于网页版的Datagrip,当然,由于是网页版,所以我们会把服务器部署在虚拟机中(和之前的所有中间件一样)。
1.倒排索引
这个概念是相对于正向索引的,以往的mysql就是采用的正向索引,在模糊查询某个字段时,其实底层是先遍历索引然后再筛选出符合要求的多条数据。
而倒排索引就是先查询字段,然后倒推出对应的索引的。
这个查询字段看上去很抽象,其实原理也很简单:使用一定的算法让一句中文拆分成很多词(分词 ),比如:我是Java程序员,就可以分成:我、是、Java、程序、程序员,像这样分出来的每一个词我们叫做词条 ,自然的,每个词条都可以对应一条数据(这里的这条数据就是:我是Java程序员,我们把这条数据称为文档)。
于是词条和文档直接就会有联系了,比如这里有两个文档:1.苹果手机、2.安卓手机,分词后苹果词条对应的文档索引就是1,而安卓词条对应的就是2,手机词条对应的就是1、2 ,所以当我们搜索 "手机"时,es会查询出1和2的索引,也就是苹果手机和安卓手机这两个文档。
那么再回到查询字段的概念上面,这个查询字段就是查询对应词条,而倒推索引就是找到那个词条对应的文档索引。
2.IK分词器
刚刚提到了,分词是通过一定的算法来实现的,这里的这个算法就是分词器,分词器有很多种类,我们可以根据需要自行选择,我们在这里选择使用IK分词器,这是一个可以分中文词的分词器,所以非常复合我们使用中文搜索的需求。
首先我们需要安装这个分词器,安装在es挂载的目录中,相当于就是安装了es的一个插件:
bash
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip接下来我们就可以尝试使用分词器了,我们打开kibana图形化界面,在里面的Dev tool中使用,(注意,这里都需要使用JSON格式来使用分词器),接下来我们尝试分词(ik_smart 是智能分词模式,还有一个最细粒度ik_max_word模式我们一会儿演示):
bash
POST /_analyze
{
"analyzer": "ik_smart",
"text": "印东升程序员Java学得特牛逼"
}得到的结果就是:
bash
{
"tokens" : [
{
"token" : "印东升",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "程序员",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "java",
"start_offset" : 6,
"end_offset" : 10,
"type" : "ENGLISH",
"position" : 2
},
{
"token" : "学得",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "特",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "牛",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 5
},
{
"token" : "逼",
"start_offset" : 14,
"end_offset" : 15,
"type" : "CN_CHAR",
"position" : 6
}
]
}现在再试试最细粒度分词:
bash
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "印东升程序员Java学得特牛逼"
}
bash
{
"tokens" : [
{
"token" : "印东升",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "东升",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "程序员",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "程序",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "员",
"start_offset" : 5,
"end_offset" : 6,
"type" : "CN_CHAR",
"position" : 4
},
{
"token" : "java",
"start_offset" : 6,
"end_offset" : 10,
"type" : "ENGLISH",
"position" : 5
},
{
"token" : "学得",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "特",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "牛",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "逼",
"start_offset" : 14,
"end_offset" : 15,
"type" : "CN_CHAR",
"position" : 9
}
]
}可以看到最细粒度分得是最详细的,但是在实际搜索中,我们很少会要求分到那么细,分成这么细也会导致性能下降,所以一般情况下还是使用智能分词。
值得注意的是,刚刚我们分词后,"牛逼"这个词竟然没有被分作一个词,由于这个是网络用语,所以分词器不会那么及时的更新出这个分词,这个时候就需要我们自己去将这个词添加进词典中去了。
首先先在插件配置文件中指定一个词典ext.dic。
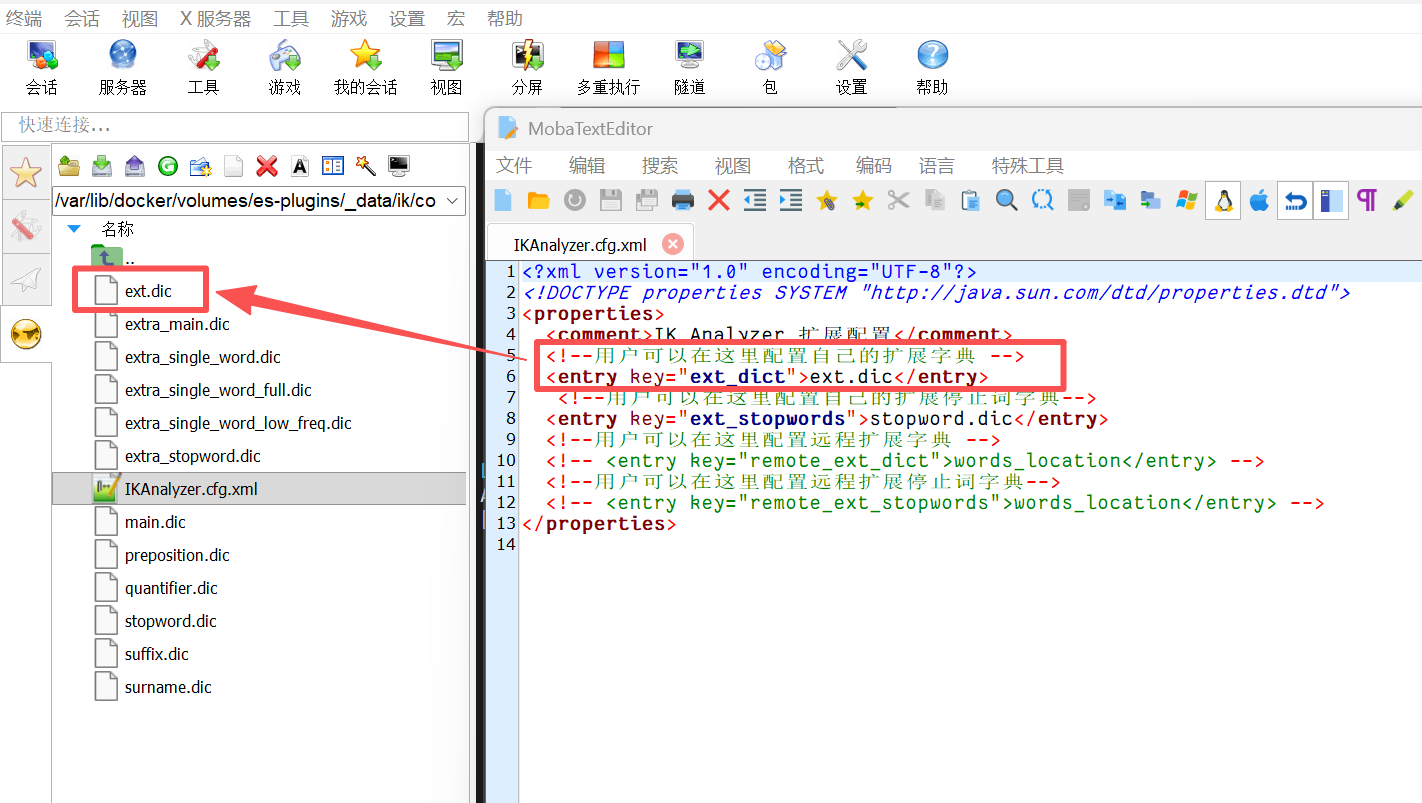
然后在词典中写出我们希望分出的词:
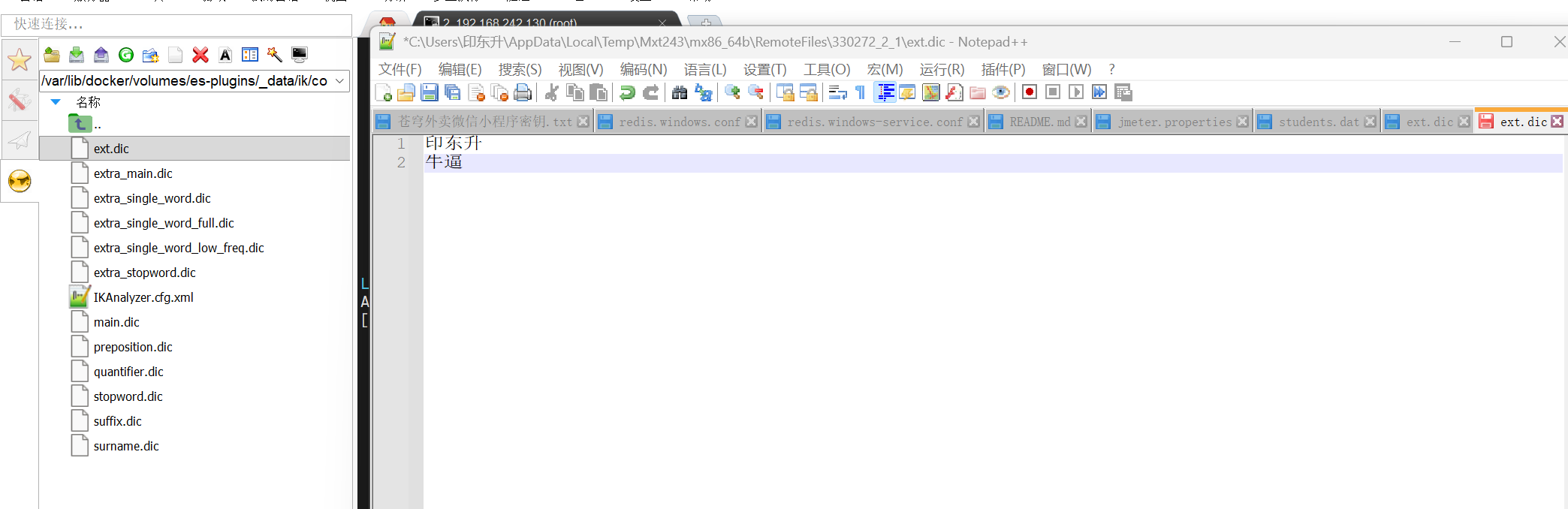
保存后再次尝试分词:(记得重启es容器)
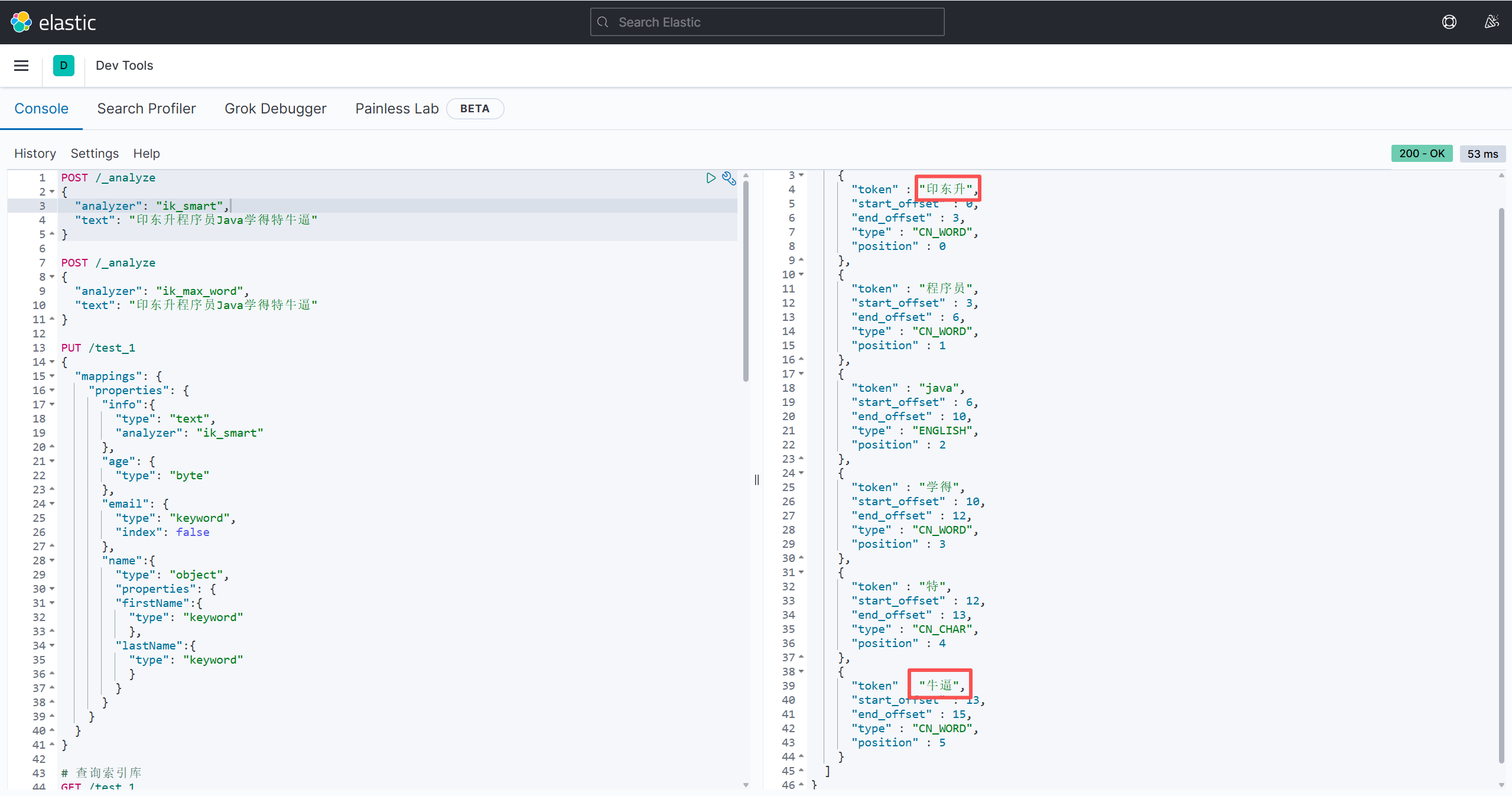
这样就分出来了。
3.索引库操作
这里引入两个新概念:索引库 和映射Mapping。
索引库就相当于mysql中的表,
映射就相当于mysql中对每个字段的约束,
文档就相当于mysql中的每条数据。
而索引库的操作就类似于我们在DataGrip中操作表,但是这里我们需要采用JSON格式。
例如我们想创建一个索引库test_1,其中包含了四个字段:info、age、email、name,我们需要约束每个字段,比如info的类型就是text ,age是byte ,email是keyword ,name是object。
其中只有text类型的字段可以被分词 ,所以我们还需要选择分词器ik_smart。
而object类型表示对象,所以在name字段中还可以嵌套字段,我们还可以在name字段中再分出两个字段:firstName和lastName。
至于email字段,我们不希望它参与搜索,所以需要把索引关闭(默认是打开的)。
bash
PUT /test_1
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"age": {
"type": "byte"
},
"email": {
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type": "keyword"
},
"lastName":{
"type": "keyword"
}
}
}
}
}
}运行后我们尝试查询这个索引库:
bash
# 查询索引库
GET /test_1结果如下:
bash
{
"test_1" : {
"aliases" : { },
"mappings" : {
"properties" : {
"age" : {
"type" : "byte"
},
"doc" : {
"properties" : {
"email" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"email" : {
"type" : "keyword",
"index" : false
},
"info" : {
"type" : "text",
"analyzer" : "ik_smart"
},
"name" : {
"properties" : {
"firstName" : {
"type" : "keyword"
},
"lastName" : {
"type" : "keyword"
}
}
}
}
},
"settings" : {
"index" : {
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "test_1",
"creation_date" : "1770270194699",
"number_of_replicas" : "1",
"uuid" : "32aDOd-lQeu5cRj_gbueJQ",
"version" : {
"created" : "7120199"
}
}
}
}
}至于删除和修改,这里就不演示了,可以自行尝试:
bash
# 删除索引库
DELETE /test_1
# 修改索引库
PUT /test_1/_mapping
{
"properties": {
"age": {
"type": "byte"
}
}
}4.文档操作
这个就比索引库操作更重要一些了,毕竟在使用mysql中我们也知道,对数据的处操作比对表结构的操作更频繁。但是由于后面我们还是主要在Java客户端中操作文档,所以这里了解就好了。
新增文档:
bash
# 新增文档
POST /test_1/_doc/1
{
"info": "个人信息",
"email": "1923046593@qq.com",
"name": {
"firstName": "东升",
"lastName": "印"
}
}查询文档:
bash
# 查询文档
GET /test_1/_doc/1
GET /test_1/_doc/2
GET /test_1/_doc/3
GET /test_1/_doc/4删除文档:
bash
# 删除文档
DELETE /test_1/_doc/1全量修改:底层原理就是把原有的文档全部删除,然后重新添加一个相同id的新文档:
bash
# 全量修改
PUT /test_1/_doc/2
{
"info": "个人信息",
"email": "1923046593@qq2.com",
"name": {
"firstName": "东升",
"lastName": "印"
}
}增量修改:就是局部的修改文档中的信息
bash
# 增量修改
POST /test_1/_update/2
{
"doc": {
"email": "yds@qq.com"
}
}批量新增:注意,这里对格式要求很严格,新增的内容需要全部写在一行中:
bash
# 批量新增
POST /_bulk
{"index": {"_index": "test_1","_id": 3}}
{"info": "个人信息","email": "1923046593@qq2.com","name": {"firstName": "帅","lastName": "王"}}
{"index": {"_index": "test_1","_id": 4}}
{"info": "个人信息","email": "1923046593@qq.com","name": {"firstName": "宇","lastName": "张"}}批量删除:这里就只用写出删除的文档索引即可了。
bash
# 批量删除
POST /_bulk
{"delete": {"_index": "test_1","_id": 3}}
{"delete": {"_index": "test_1","_id": 4}}三、Java客户端操作
刚刚所有对es的操作都是在kibana图形化界面上面进行的,这显然是不符合正常Java开发的,所以最终我们还是将在客户端中进行这些操作。
1.客户端初始化
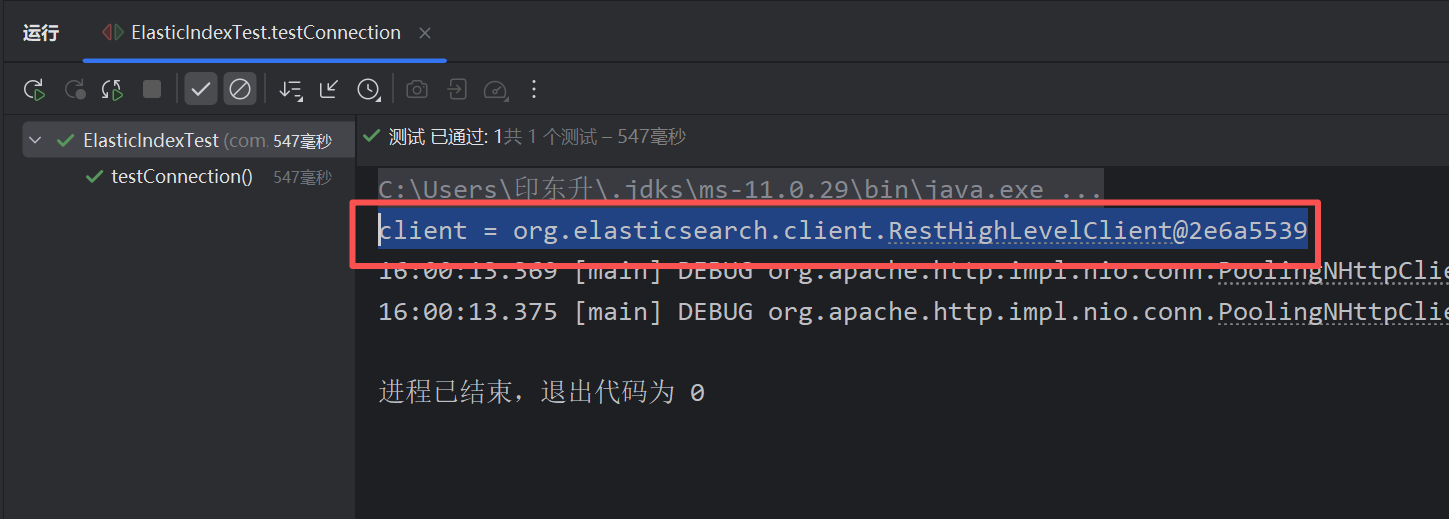
我们这里使用AOP在每次运行测试用例前初始化es客户端,同时在结束时关闭客户端。
java
public class ElasticIndexTest {
private RestHighLevelClient client;
@Test
void testConnection() {
System.out.println("client = " + client);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.111.111:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if (client != null) {
client.close();
}
}
}测试连接:
2.客户端中的索引库操作
对索引库的操作大体分为三步:1.准备一个请求对象 2.准备请求参数 3.发送请求。
在第二步准备请求参数时,我们本质上其实还是以传入JSON格式字符串的形式来创建索引库的,而Java客户端提供了很多易读的API供我们使用,create、delete、get、update等等......
并且这些api使用的顺序基本上都是固定的,所以其实并没有想象那么难记。
java
public class ElasticIndexTest {
private RestHighLevelClient client;
@Test
void testConnection() {
System.out.println("client = " + client);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.242.130:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if (client != null) {
client.close();
}
}
@Test
void testCreateIndex() throws IOException {
//1.准备Request对象
CreateIndexRequest request = new CreateIndexRequest("items");
//2.准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
//3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
@Test
void testGetIndex() throws IOException {
//1.准备Request对象
GetIndexRequest request = new GetIndexRequest("items");
//2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("exists = " + exists);
}
@Test
void testDeleteIndex() throws IOException {
//1.准备Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
//2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}
private static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_smart\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"stock\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"image\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"category\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sold\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"commentCount\":{\n" +
" \"type\": \"integer\",\n" +
" \"index\": false\n" +
" },\n" +
" \"isAD\":{\n" +
" \"type\": \"boolean\"\n" +
" },\n" +
" \"updateTime\":{\n" +
" \"type\": \"date\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}3.客户端中对文档的操作
(1)CRUD
首先我们要准备一个实体类来作为操作索引库的媒介,虽然后续操作本质上还是以JSON格式进行处理的,但是有了实体类作为媒介就可以通过使用工具类将JSON和JavaBean类型互相转换,这样代码中就不会出现JSON格式了,实际操作也就由直接修改JSON变成了修改实体类然后转化为JSON传递了。
实体类:
java
@Data
@ApiModel(description = "索引库实体")
public class ItemDoc{
@ApiModelProperty("商品id")
private String id;
@ApiModelProperty("商品名称")
private String name;
@ApiModelProperty("价格(分)")
private Integer price;
@ApiModelProperty("商品图片")
private String image;
@ApiModelProperty("类目名称")
private String category;
@ApiModelProperty("品牌名称")
private String brand;
@ApiModelProperty("销量")
private Integer sold;
@ApiModelProperty("评论数")
private Integer commentCount;
@ApiModelProperty("是否是推广广告,true/false")
private Boolean isAD;
@ApiModelProperty("更新时间")
private LocalDateTime updateTime;
}CRUD:
增:这里我们通过service层获取mysql中真实的商品信息,然后转换为索引库实体,最后通过工具类转化为JSON格式然后发送请求。
删:直接删除指定索引的文档。
改 :直接改指定索引的文档,请求参数是局部更新的字段键值对。
查:直接查询指定索引的文档,获得一个响应,我们只需要响应中的_source部分,在最后还需要把source部分的格式转换一下。
java
@SpringBootTest(properties = "spring.profiles.active=local")
public class ElasticDocumentTest {
private RestHighLevelClient client;
@Autowired
private IItemService itemService;
@Test
void testIndexDoc() throws IOException {
//0.准备文档数据
//0.1.根据id查询数据库数据
Item item = itemService.getById(317578L);
//0.2.把数据库数据转化为文档数据
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
//1.准备Request
IndexRequest request = new IndexRequest("items").id(item.getId().toString());
//2.准备请求参数
request.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON);
//3.发送请求
client.index(request, RequestOptions.DEFAULT);
}
@Test
void testGetDocument() throws IOException {
//1.准备Request
GetRequest request = new GetRequest("items", "317578");
//2.发送请求
GetResponse response = client.get(request, RequestOptions.DEFAULT);
//3.解析响应结果
String json = response.getSourceAsString();
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("doc = " + doc);
}
@Test
void testDeleteDocument() throws IOException {
//1.准备Request
DeleteRequest request = new DeleteRequest("items", "317578");
//2.发送请求
DeleteResponse response = client.delete(request, RequestOptions.DEFAULT);
}
@Test
void testUpdateDocument() throws IOException {
//1.准备Request
UpdateRequest request = new UpdateRequest("items", "317578");
//2.准备请求参数
request.doc(
"price", "25600"
);
//3.发送请求
client.update(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp() {
client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.111.111:9200")
));
}
@AfterEach
void tearDown() throws IOException {
if (client != null) {
client.close();
}
}
}(2)批量操作
刚刚的所有操作都是单次的,实际开发中我们希望批量操作,比如我们mysql数据库中有上万条商品信息,我们想全部导入到es中,肯定就不能一条一条去插入了,我们会选择批量插入,其实批量插入的原理很简单,就是一次性发送多个请求,这里的 **"批量请求"**其实就是很多请求的集合,所以其实就分为两步:
1.向批量请求中添加一条一条的请求(这个请求可以是增删改查的任意一种请求)。
2.发送请求。
做到第一条看上去很简单,直接循环就行了,但是实际上我们不能一次直接循环几万条,这样内存会爆的,所以就可以想到可以几百条几百条地去添加,直到所有数据被添加完,那么就又能想到使用分页查询了,一页装500条数据,每次循环页码+1,最后查询为空了就停止查询。
于是这里使用mp的分页查询,每500条一页分出一个结果集,然后遍历该结果集中的所有商品信息,全部添加到批量请求中,最后发送,然后开始下一页的循环。
java
@Test
void testBulkDocument() throws IOException {
int pageNo = 1, pageSize = 500;
while(true){
//0.准备文档数据
//0.1.根据id查询数据库数据
Page<Item> page = itemService.lambdaQuery()
.eq(Item::getStatus, 1)
.page(Page.of(pageNo, pageSize));
List<Item> records = page.getRecords();
if (records == null || records.isEmpty()) {
return;
}
//1.准备Request
BulkRequest request = new BulkRequest();
//2.准备请求参数
for (Item item : records) {
request.add(new IndexRequest("items")
.id(item.getId().toString())
.source(JSONUtil.toJsonStr(BeanUtil.copyProperties(item, ItemDoc.class)),XContentType.JSON));
}
//3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
//翻页
pageNo++;
}
}最后我们在控制台查询一下有多少条数据:
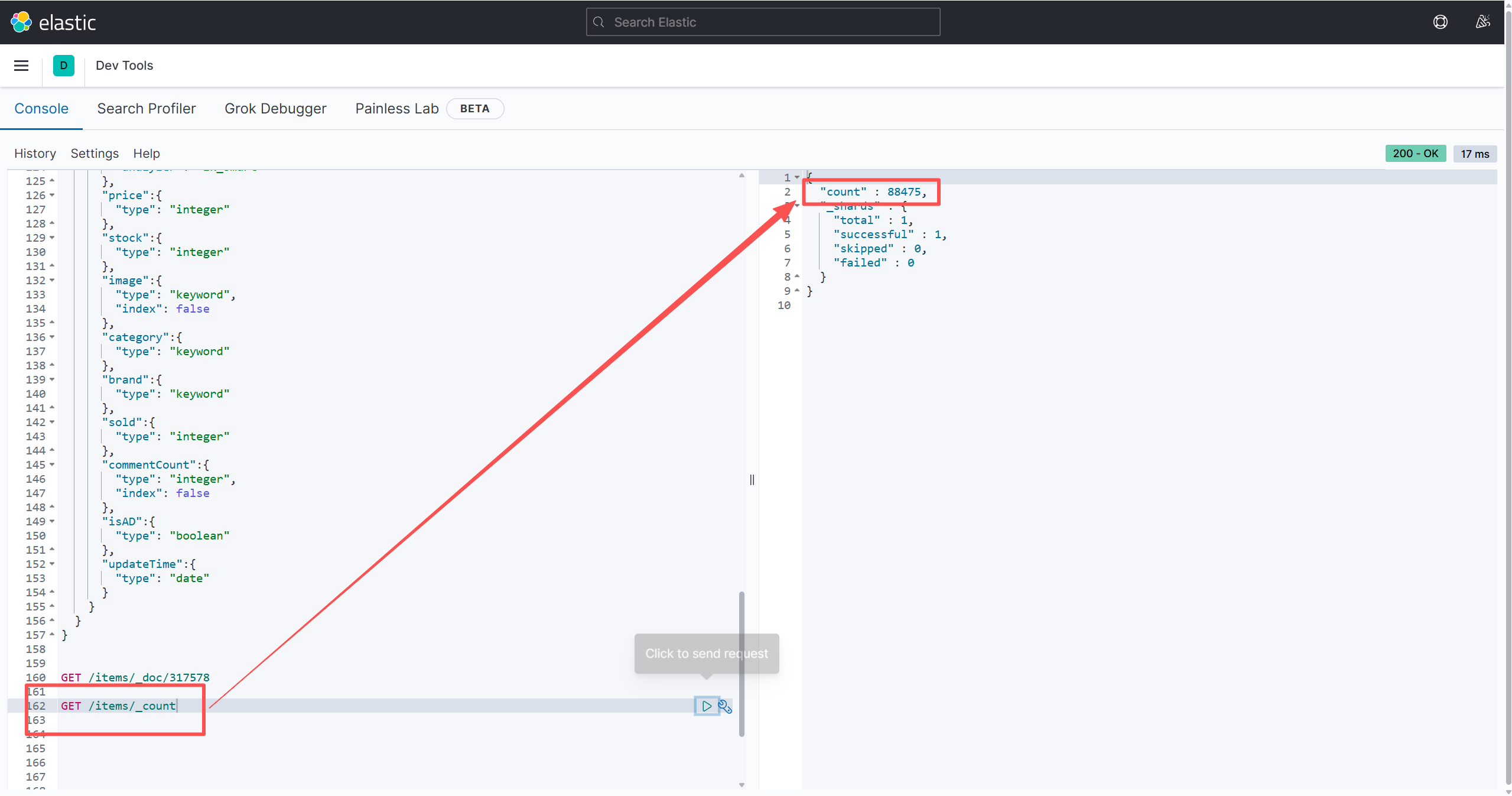
bash
{
"count" : 88475,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}有88475条,这个数字也和mysql中的商品数据(上架的)条数相等,所以批量操作成功。