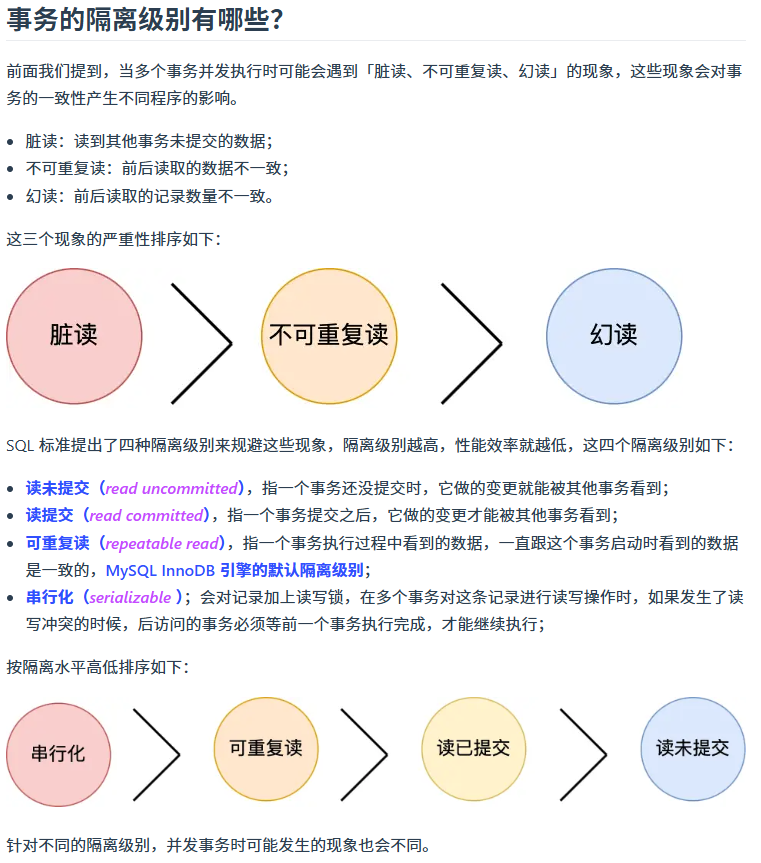
为了实现不同的隔离级别,需要MVCC机制
简单来说,MVCC 就像是给数据库拍"快照"。它的核心原理由三部分组成:隐藏字段 、Undo Log 版本链 和 ReadView(一致性视图)。
1. 核心基石:版本链与隐藏字段
在 InnoDB 中,每一行记录的聚簇索引背后,其实都偷偷藏了两个关键的隐藏字段:
trx_id:最近一次修改这条记录的事务 ID。roll_pointer:指向 Undo Log 的指针。
每当一条记录被修改时,InnoDB 不会直接覆盖旧数据,而是把旧版本写入 Undo Log,并让新记录的 roll_pointer 指向这个旧版本。这样就形成了一条版本链,记录了这行数据的所有前世今生。
2. 什么是 ReadView(一致性视图)?
ReadView 是事务执行 SELECT 时产生的一个"内存快照"。它并不拷贝真实数据,而是记录了当前系统中 "哪些事务还没提交"。ReadView并不是全局的而是事务/SELECT私有的。
一个 ReadView 包含四个核心要素:
m_ids:生成 ReadView 时,系统中所有正在活跃(未提交)的事务 ID 列表。min_trx_id:活跃事务中最小的 ID。max_trx_id:系统即将分配给下一个事务的 ID(即当前最大 ID + 1)。creator_trx_id:创建这个 ReadView 的事务 ID。
3. 判别逻辑:我能看到哪一个版本?
当事务读取一行数据时,它会沿着 Undo Log 版本链 从新往旧找,拿每一版的 trx_id 去跟自己的 ReadView 规则比对:
- 可见 :如果
trx_id < min_trx_id(说明该版本在快照前已提交)。 - 不可见 :如果
trx_id >= max_trx_id(说明该版本在快照后才开启)。 - 复杂区 :如果在
min和max之间,则看trx_id是否在m_ids列表中。- 在列表中:说明快照时还没提交,不可见。
- 不在列表中:说明快照时已经提交,可见。
- 特例 :如果
trx_id == creator_trx_id,那是自己改的,永远可见。
判别逻辑场景
场景一:绝对历史快照(满足 trx_id < min_trx_id)
这是最常见的可见情况:数据在当前事务开启并生成快照之前就已经提交。
-
T1时刻 :系统全局事务 ID 计数器为
100。记录 RRR 的age = 18,其隐藏列trx_id = 50(旧事务已提交)。 -
T2时刻 :事务 B (ID=100) 开启并修改记录 RRR,将
age改为20。此时记录 RRR 的trx_id = 100。 -
T3时刻 :事务 B 提交。
-
T4时刻 :事务 A 开启并执行
SELECT,生成 ReadView。- 由于此时系统中没有活跃事务,
m_ids为空。 min_trx_id = 101(即将分配的 ID)。max_trx_id = 101。
- 由于此时系统中没有活跃事务,
-
T5时刻 :事务 A 读取记录 RRR,发现
trx_id = 100。
判断逻辑:
- 判定路径 :
trx_id < min_trx_id。 - 具体比对 :100<101100 < 101100<101。
- 结果 :可见。
- 物理本质:事务 B 在事务 A 拍快照之前就已经完成了提交,属于 A 视角下的"历史既定事实"。
场景二:活跃间隙中的已提交数据(满足 min_trx_id <= trx_id < max_trx_id 且不在 m_ids 中)
这个场景展示了当多个事务交错执行时,ReadView 如何精准识别哪些是已提交的。
- T1时刻 :系统全局事务 ID 计数器为
100。 - T2时刻:事务 B (ID=100) 开启。
- T3时刻 :事务 C (ID=101) 开启。此时全局计数器变为
102。 - T4时刻 :事务 B (ID=100) 修改数据并提交。此时事务 C (101) 依然活跃。
- T5时刻 :事务 A 开启并执行
SELECT,生成 ReadView 。- 此时活跃事务只有 C,所以
m_ids = {101}。 min_trx_id = 101(活跃列表中最小的)。max_trx_id = 102(即将分配的下一个)。
- 此时活跃事务只有 C,所以
- T6时刻 :事务 A 读取事务 B 修改的那行数据,发现
trx_id = 100。
判断逻辑:
- 判定路径 :
trx_id < min_trx_id。 - 具体比对 :100<101100 < 101100<101。
- 结果 :可见。
- 物理本质:虽然事务 B 的 ID 很大,但它在 A 开启的那一刻已经提交,不属于"活跃事务"了。
场景3:跨越两次更新的回溯(可重复读 RR 级别)
- T1 时刻(初始状态) :
- 系统全局下一个待分配事务 ID 为
100。 - 聚簇索引中有一行记录 RRR:
age = 18,其隐藏列trx_id = 50(历史已提交事务),roll_ptr = NULL。
- 系统全局下一个待分配事务 ID 为
- T2 时刻(事务 A 开启并查询) :
- 事务 A 开启,系统分配事务 ID 为
100。全局待分配 ID 变为101。 - 事务 A 执行
SELECT,生成 ReadView :m_ids = {100}(只有它自己活跃)。min_trx_id = 100。max_trx_id = 101。
- 此时 A 读到记录 RRR 的
trx_id = 50。因为 50<10050 < 10050<100(min_trx_id),判定可见 ,得到age = 18。
- 事务 A 开启,系统分配事务 ID 为
- T3 时刻(事务 B 开启并修改) :
- 事务 B 开启,系统分配事务 ID 为
101。全局待分配 ID 变为102。 - 事务 B 将记录 RRR 的
age改为20。 - 物理动作 :
- 拷贝旧行到 Undo Log:生成节点
[age=18, trx_id=50]。 - 更新当前行:
age = 20,trx_id = 101。 - 当前行的
roll_ptr指向刚生成的 Undo Log 节点。
- 拷贝旧行到 Undo Log:生成节点
- 事务 B 开启,系统分配事务 ID 为
- T4 时刻(事务 B 提交) :
- 事务 B (ID=101) 提交。
- T5 时刻(事务 C 开启并修改) :
- 事务 C 开启,系统分配事务 ID 为
102。全局待分配 ID 变为103。 - 事务 C 将记录 RRR 的
age改为22。 - 物理动作 :
- 拷贝旧行到 Undo Log:生成节点
[age=20, trx_id=101]。 - 更新当前行:
age = 22,trx_id = 102。 - 当前行的
roll_ptr指向刚生成的这个 Undo Log 节点。
- 拷贝旧行到 Undo Log:生成节点
- 事务 C 开启,系统分配事务 ID 为
- T6 时刻(事务 C 提交) :
- 事务 C (ID=102) 提交。
- T7 时刻(事务 A 再次查询) :
- 事务 A (ID=100) 再次执行
SELECT。 - 在 RR 级别下,它严格复用 T2 时刻的 ReadView (
min_trx_id = 100,max_trx_id = 101)。
- 事务 A (ID=100) 再次执行
事务 A 在 T7 时刻的判定与回溯逻辑
当事务 A 在 T7 试图读取这行记录时,执行器会在内存中进行以下严格的链表遍历:
-
第一步:检查当前聚簇索引记录
- 读取当前最新行:
age = 22,trx_id = 102。- 判定 :102≥101102 \ge 101102≥101(
max_trx_id)。 - 结论 :这是在我拍快照之后才开启的事务修改的,不可见。
- 动作 :提取当前行的
roll_ptr,顺着指针去 Undo Log 找上一个版本。
- 判定 :102≥101102 \ge 101102≥101(
- 读取当前最新行:
-
第二步:回溯到 Undo Log 的第一个历史版本
- 读取 Undo Log 节点:
age = 20,trx_id = 101。- 判定 :101≥101101 \ge 101101≥101(
max_trx_id)。 - 结论 :这也是在我拍快照之后(或同一瞬间)产生的新事务,不可见。
- 动作 :继续提取该节点的
roll_ptr,顺藤摸瓜找更老的版本。
- 判定 :101≥101101 \ge 101101≥101(
- 读取 Undo Log 节点:
-
第三步:回溯到 Undo Log 的第二个历史版本
- 读取 Undo Log 节点:
age = 18,trx_id = 50。- 判定 :50<10050 < 10050<100(
min_trx_id)。 - 结论 :这是在我拍快照之前就已经确定的历史数据,可见!
- 最终动作 :停止遍历,将
age = 18组装好返回给事务 A。
- 判定 :50<10050 < 10050<100(
- 读取 Undo Log 节点:
理解
总的来说,就是:事务A在开启的时候创建了一个ReadView存储创建时事务快照。当A要读某记录时,判断记录当前trxid<mintrxid则说明记录最后被修改是在A之前因此可以读;trxid>=maxtrxid说明记录最后被修改是在A创建之后因此不能读;trxid在mintrxid和maxtrzid之间说明A创建时所存在的某事务修改的该记录,此时判断trxid是否在mids中:如果不在则说明该事务在A创建时已提交因此可以读,如果在则说明该事务在A创建时未提交,则不能读;在上述不能读的情况下,会去回溯roll_pointer直到找到第一个能读的历史记录
总的逻辑其实是:在A创建时存一个快照,之后读取记录时判断该记录在A创建时是否被修改完毕了,如果被修改完毕则安全,若是A创建之后被修改的则不安全
四种隔离级别在 MVCC 上的底层实现机制
InnoDB 存储引擎主要通过控制 ReadView 的生成时机 以及是否引入锁机制,来实现 SQL 标准定义的四种隔离级别。以下是具体的物理实现逻辑:
-
读未提交 (Read Uncommitted, RU)
- 实现逻辑 :完全不使用 MVCC 机制。查询操作直接读取聚簇索引叶子节点上最新的物理数据行,不进行任何
DB_TRX_ID的比对,也不回溯 Undo Log 版本链。
- 实现逻辑 :完全不使用 MVCC 机制。查询操作直接读取聚簇索引叶子节点上最新的物理数据行,不进行任何
-
读已提交 (Read Committed, RC)
- 实现逻辑 :严格依赖 MVCC。事务在每一次执行 SELECT 语句前 ,都会重新生成一个新的 ReadView。由于每次查询的
m_ids和max_trx_id都在实时更新,执行器在遍历 Undo Log 版本链时,能够读取到其他事务刚刚提交的最新版本。
- 实现逻辑 :严格依赖 MVCC。事务在每一次执行 SELECT 语句前 ,都会重新生成一个新的 ReadView。由于每次查询的
-
可重复读 (Repeatable Read, RR)
- 实现逻辑 :严格依赖 MVCC。事务仅在第一次执行 SELECT 语句前 生成一个 ReadView。该事务后续生命周期内的所有普通查询,均严格复用这首个 ReadView。由于判定基准(
m_ids,min_trx_id,max_trx_id)被彻底固化,执行器在 Undo Log 版本链中永远只能匹配到固定的历史版本数据。
- 实现逻辑 :严格依赖 MVCC。事务仅在第一次执行 SELECT 语句前 生成一个 ReadView。该事务后续生命周期内的所有普通查询,均严格复用这首个 ReadView。由于判定基准(
-
串行化 (Serializable)
- 实现逻辑 :主动放弃 MVCC 的无锁并发优势。InnoDB 会将事务中所有的普通
SELECT查询隐式转换为加锁的"当前读"(等效于执行SELECT ... FOR SHARE)。通过共享锁(S锁)和排他锁(X锁)的互斥,以及 Next-Key Lock 对索引间隙的封锁,在物理层面强制所有并发事务排队执行。
- 实现逻辑 :主动放弃 MVCC 的无锁并发优势。InnoDB 会将事务中所有的普通