深度学习基础
深度学习是指基于"深度"(⾄少具有两个隐藏层)神经⽹络的机器学习⽅法。在本模块将学习神经⽹络的基本原理,了解深度学习的计算环境,掌握深度学习框架PyTorch的编程技能,最后基于全连接结构的神经⽹络完成MNIST数字⼿写体识别任务。
深度学习发展史




神经网络的基本原理
神经⽹络是⼀种模仿⽣物神经系统的计算模型,它由⼤量互相连接的节点(⼜被称为"神经元")组成,它们之间存在复杂的连接关系,通过连接权重来传递信息。神经元节点在收到其它节点传递过来的信息之后,⾸先通过线性模型的⽅式集成信息,再通过节点上定义的激活函数有选择性地透出信息,继续传递给其它神经元。
神经⽹络模型在上世纪50年代就已经出现,但由于算⼒的限制,只能训练简单结构的⽹络,因⽽⼀直没有做出突破性的成果。直到2011年,在GPU算⼒的⽀持下,Geoffrey Hinton和邓⼒⾸次成功地将深度神经⽹络应⽤在语⾳识别上,将识别错误率相对降低了20〜30%,深度学习时代正式到来。
1.神经元
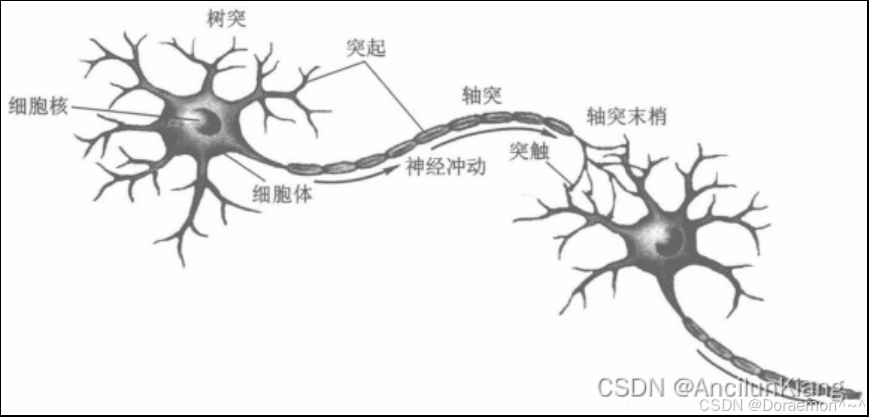
神经元是构成神经⽹络的基本单元。下图所示的是⼀个⽣物神经元的结构,由细胞体、树突和轴突等结构组成。其中,细胞体是神经元的代谢中⼼,负责维持神经元的⽣存和功能。树突是神经元的输⼊部分,接收来⾃其它神经元的信号。细胞体对接收到的信号进⾏整合,当整合之后的信号强度超过某个阈值,就会将其通过轴突输出,传递给其它的神经元。
上述⽣物神经元之间信息传递的机制,被早期的神经科学家抽象为线性感知机:
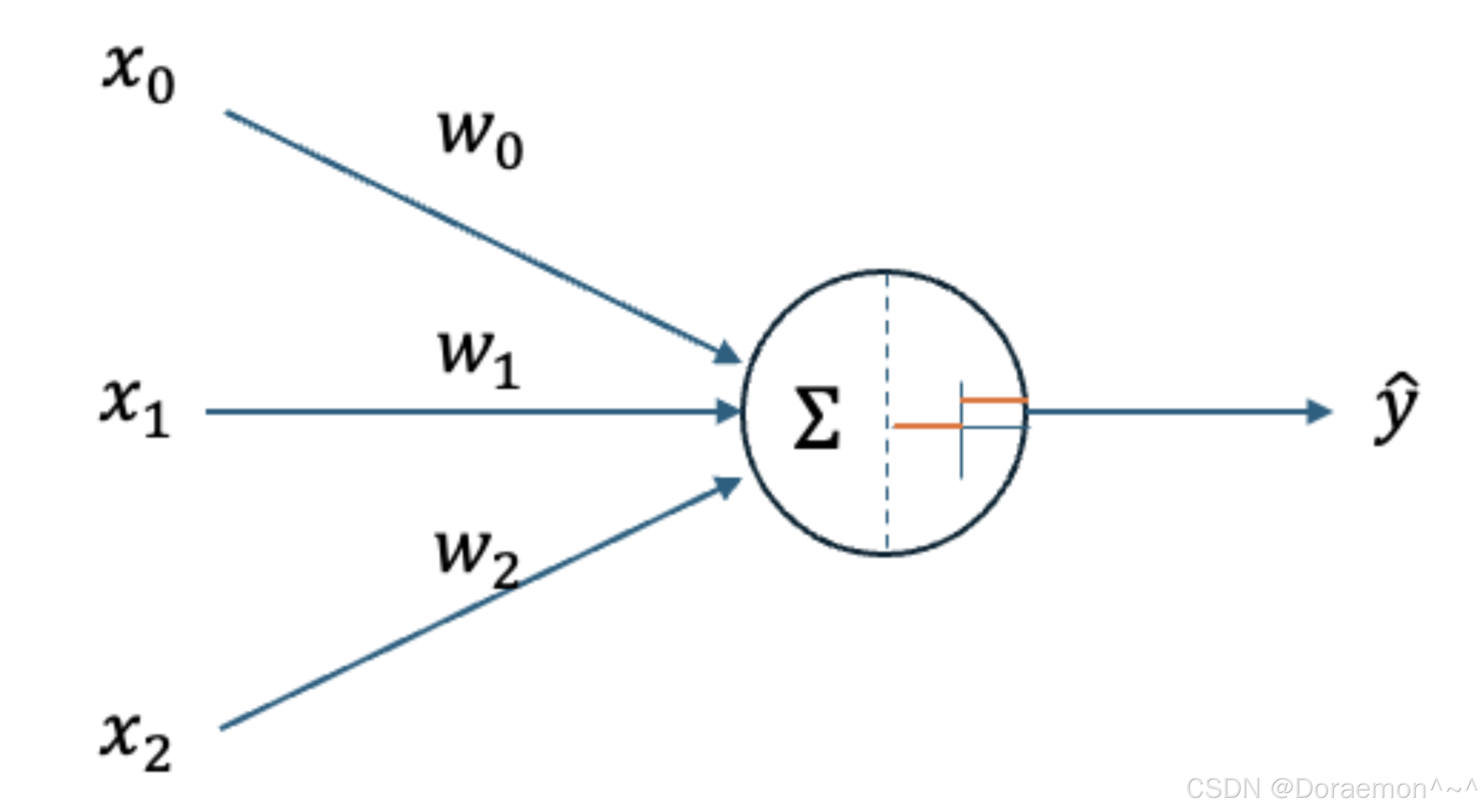
在上图所示的计算模型中:
-
x0 , x1 , x2为神经元所接收到的数据
-
w0 , w1 , w2 为对应连接上的权重
神经元在接收到数据之后,⾸先按照线性模型的⽅式进⾏集成,再通过阶跃函数进⾏输出。
上图所示线性感知机的计算公式为:
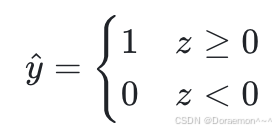
其中, z= w0x0 + w1x1 + w2x2
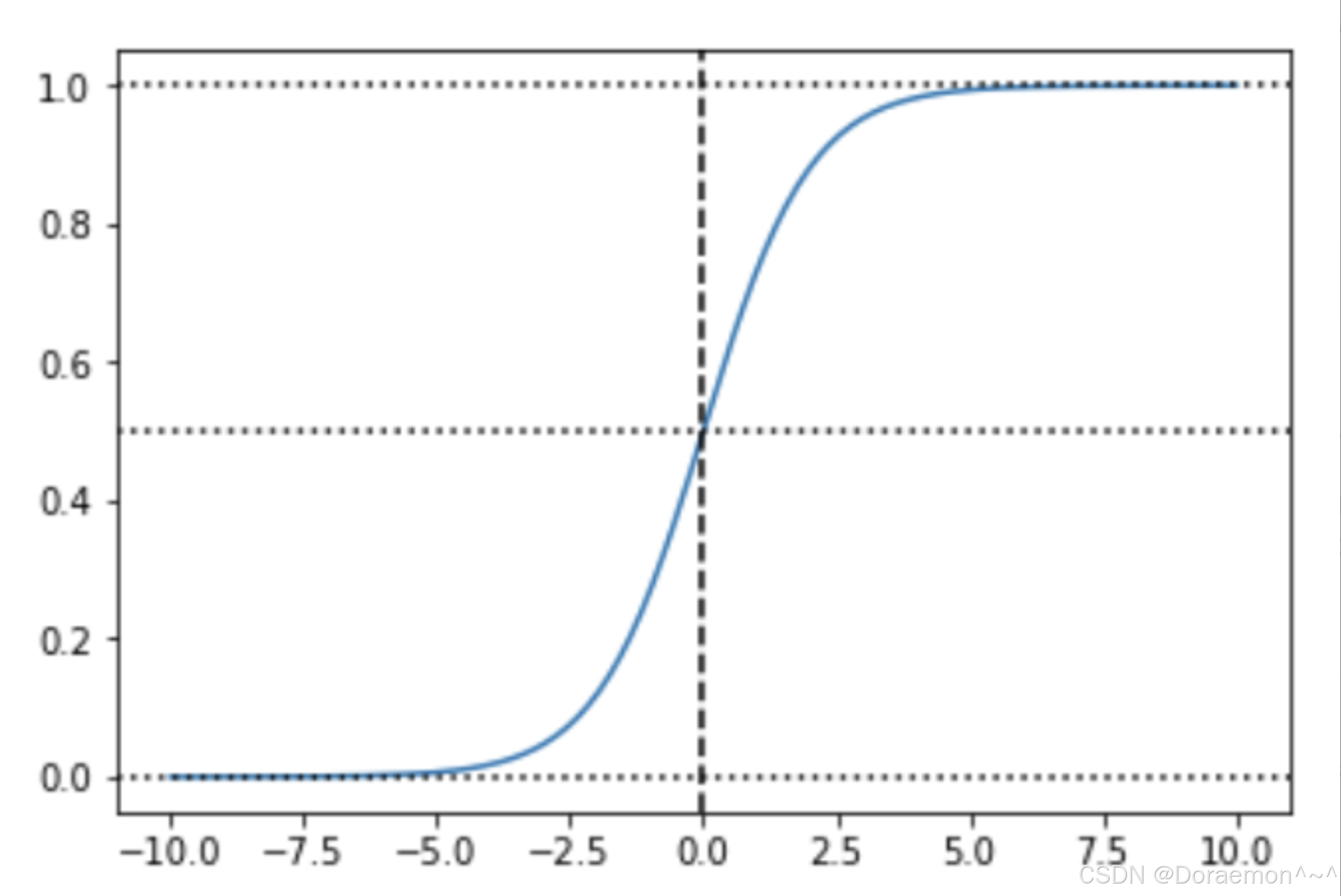
由于阶跃函数不连续,不利于优化,因此经常将阶跃函数替换为 Sigmoid函数,此时神经元的输出为:

可以看出,此时神经元的输出符合逻辑回归模型,因此,逻辑回归模型可以看作是最简单的神经⽹络(只有⼀个神经元构成)。它实质上是⼀个线性的分类模型,当 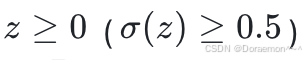 时,预测的类别为1;当
时,预测的类别为1;当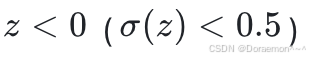 时,预测的类别为0。两类数据之间的分类边界为
时,预测的类别为0。两类数据之间的分类边界为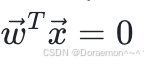 ,是⼀条直线或超平⾯。
,是⼀条直线或超平⾯。
sigmoid函数的性质:

2.逻辑回归
逻辑回归是⼀个⼆分类模型, 函数的输出是样本属于⽬标类(y=1)的概率,即:
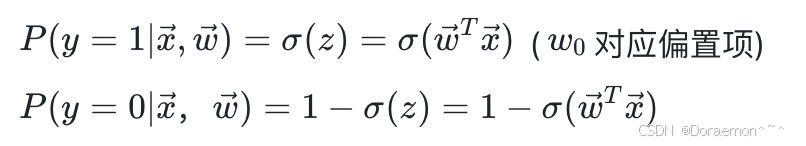
如果收集了⼀个训练数据集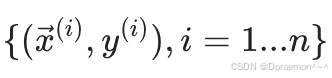 ,那么对于其中的每⼀个训练样
,那么对于其中的每⼀个训练样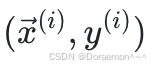 本,
本,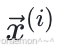 通过模型预测其类别为
通过模型预测其类别为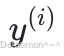 的概率为:
的概率为:
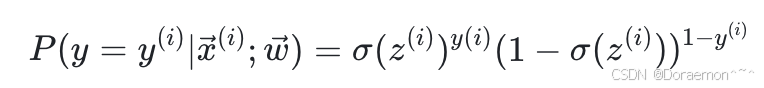
其中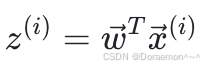 ,
,
显然希望极⼤化这个概率。为了计算⽅便,取对数概率,得到:
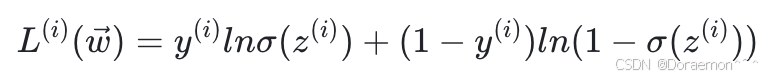
再对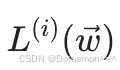 取负数,就得到样本
取负数,就得到样本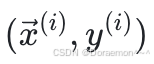 相关的损失函数:
相关的损失函数:
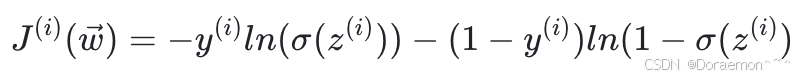
训练集上总体的损失函数为:
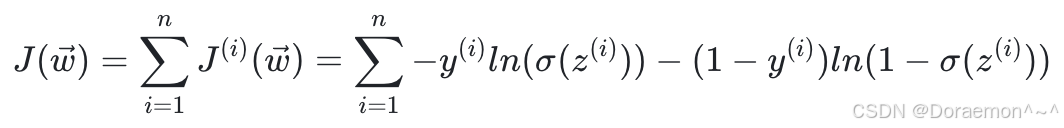
模型参数 (即权重) 通过梯度下降进⾏优化。为了平衡训练速度和效果,⼀般采⽤⼩批量梯度下降。对于每个训练epoch,⾸先打乱训练集中的样本顺序,然后在乱序之后的数据列表中,依次取B个样本 (微批) 进⾏权重更新。如果在epoch开始的时候,模型权重为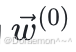 ,那么在进⾏了第1次更新之后变为
,那么在进⾏了第1次更新之后变为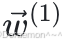 ,之后是
,之后是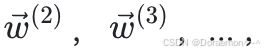 以此类推。下图说明了⼩批量梯度下降的权重更新过程,注意:在每次更新权重时,⽤于计算梯度的数据是不同的。
以此类推。下图说明了⼩批量梯度下降的权重更新过程,注意:在每次更新权重时,⽤于计算梯度的数据是不同的。
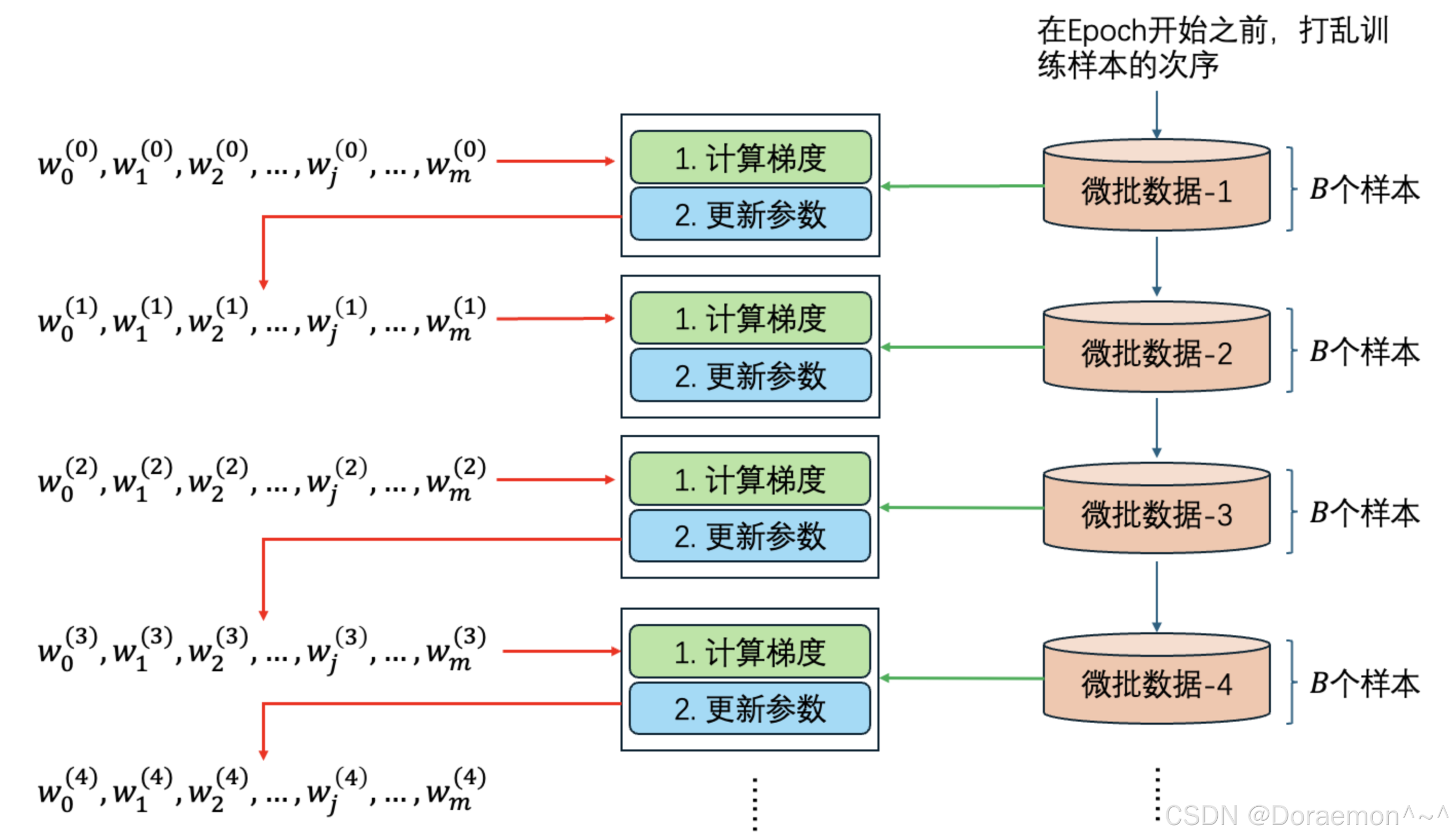
梯度下降算法依赖梯度 (偏导向量) 的计算。
基于链式法则,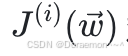 对于权重
对于权重 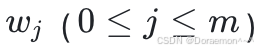 的偏导函数为:
的偏导函数为:
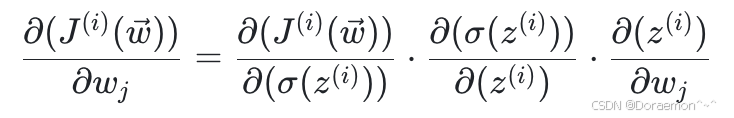 (1)
(1)
其中,第⼀个因式为损失函数对于逻辑回归输出的偏导:
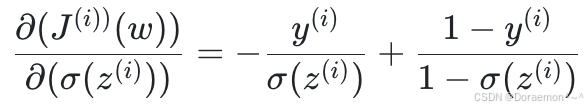 (2)
(2)
(2)式实际上与模型的函数表达式⽆关,它只与损失函数如何度量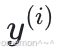 与
与 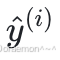 的差异有关。
的差异有关。
第⼆个因式为逻辑回归模型中 Sigmoid 函数的输出对其输⼊的偏导:
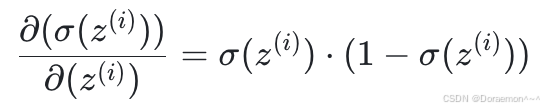 (3)
(3)
第三个因式为线性模型输出对权重的偏导:
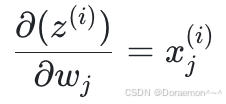 (4)
(4)
(3)、(4)两式只与模型的函数表达式有关。
将(2)-(4)式带⼊(1)式,即可得到完整的偏导函数:
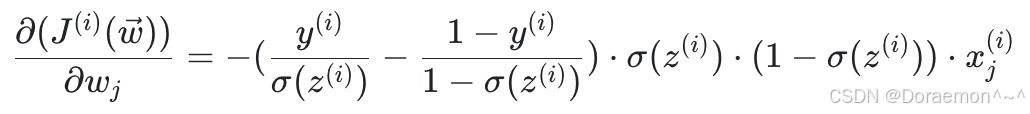 (5)
(5)
化简(5),可得:
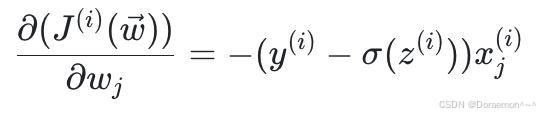 (6)
(6)
公式需不需要记住?
- 常⽤的公式应该记住,例如sigmoid 函数,softmax函数,回归问题和分类问题的损失函数等。
- 梯度下降中的求导公式可以不⽤记忆,着重理解因变量、中间变量和⾃变量之间的依赖关系,以及通过链式法则偏导传递的过程。
- 有些公式虽然可以不记忆,但掌握它们的性质很重要。例如sigmoid 函数的导函数,虽然不⼀定需要背下来具体的公式形式,但掌握"当⾃变量⾜够⼩或⾜够⼤时,sigmoid的导数趋近于0"这⼀性质⾮常有必要!
梯度即为偏导向量:
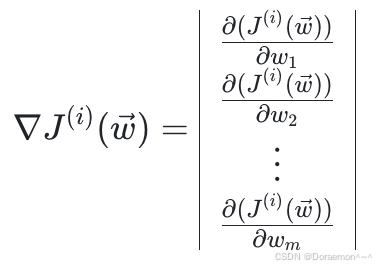
⼩批量梯度下降中使⽤的梯度,为微批中所有样本对权重的平均梯度:
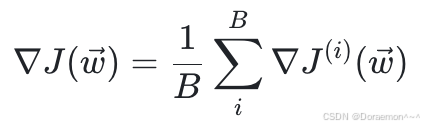
在计算出梯度之后,权重按照下列公式进⾏更新:
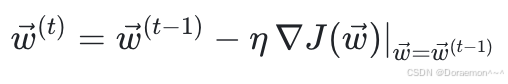
其中 t表示权重迭代次数。 η是学习率,是⼀个训练超参数。
由于⼩批量梯度下降的梯度估计也带有随机性,因此通常也被称为"随机梯度下降",即SGD (Stochastic Gradient Descent)。
⾯试点:神经⽹络为什么采⽤随机梯度下降(⽽不是批量梯度下降)进⾏优化?
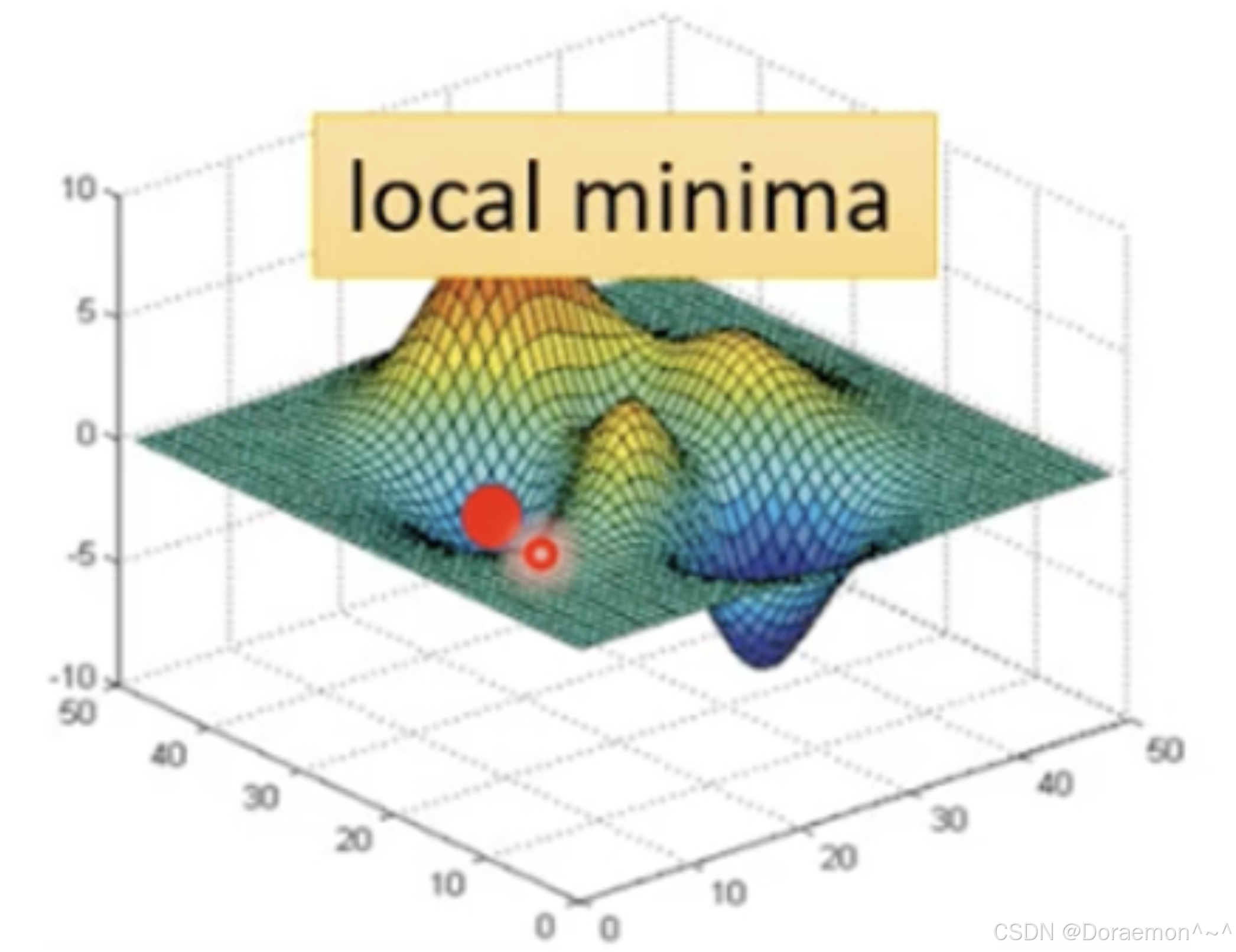
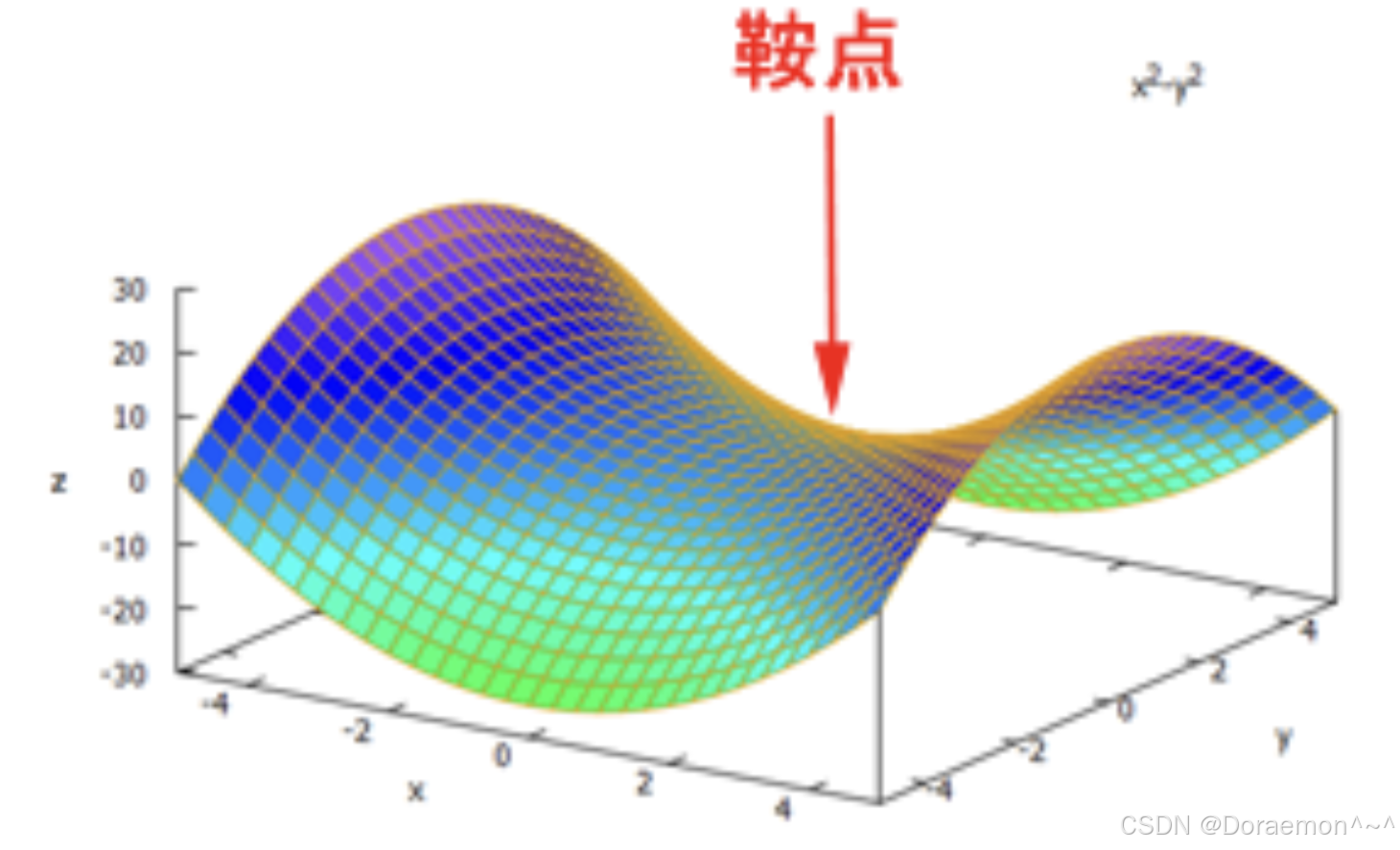
对于绝⼤部分的神经⽹络模型,其损失函数没有全局极⼩值,但在参数空间(权重空间)中存在多个梯度为0的点,称为稳定点。稳定点不⼀定是⼀个可接受的优化结果,它可能是⼀个损失值较⼤的局部极⼩点、⼀个局部极⼤点或者是⼀个鞍点 (对于某个权重⽅向是局部极⼤点,⽽对于另外⼀个权重⽅向是局部极⼩点 )。
如果采⽤批量梯度下降进⾏权重的优化,那么如果优化过程中的权重刚好落⼊某个不理想的稳定点,由于此时梯度为0,权重的数值不会发⽣任何变化。⽽到了下⼀次权重更新时,由于梯度是基于全体训练样本估计的,偏导函数在每⼀轮参数更新中都是相同的,因此梯度仍然是0,权重仍然不会得到更新......这样,训练就被"卡"住了,权重⼀直得不到更新,训练loss⼀直不会下降。
再来看基于随机梯度下降的情况 (⼩批量梯度下降也可以被称为随机梯度下降,因为梯度计算同样具有随机性)。如果在优化过程中权重落⼊了稳定点,由于梯度为0,权重的数值不会发⽣任何变化,本次更新结束,程序进⼊下⼀次参数更新的流程。由于每次权重更新时基于的训练数据不同,下⼀次参数更新时的损失函数和前⼀次会有所差异,因此即使权重相同,梯度也可能会有所不同,因此参数会得到更新,可能就会跳出当前这个不理想的稳定点。
因此,除了参数更新的速度快,随机梯度下降还具有⼀定的逃逸不理想稳定点(包括局部极⼩点)的能⼒,这⼀点对于神经⽹络的训练⾄关重要。
接下来,从神经⽹络的⻆度,⽤代码实现逻辑回归。在这个代码实现中,可以着重关注:
- 对神经⽹络"LogisticNetwork"类和数据集"Dataset"类的抽象。
- 随机梯度下降的流程。
- Numpy ndarray的运算。
python
import numpy as np
class LogisticNetwork:
'''
将逻辑回归模型从神经网络的角度重新实现
对于神经网络,我们只关注模型的前向计算和反向计算过程
前向计算:从输入的特征计算出模型的输出,即预测值
反向计算:根据损失函数对于模型输出的导数,计算模型权重和偏置的梯度
'''
def __init__(self, input_dim, weight=None, bias=None):
self.input_dim = input_dim
self.weight = np.random.randn(input_dim, 1) # 对象内部保存的模型权重,基于正态分布进行了初始化
self.bias = np.random.randn(1, 1) # 对象内部保存的模型权重偏置,基于正态分布进行了初始化
if weight is not None:
self.weight[:] = weight
if bias is not None:
self.bias[:] = bias
# 其他更新参数所需要的变量
self.weight_grad = np.zeros([input_dim, 1]) # 对象内部保存的权重梯度,是经过样本之间平均处理的,因此一个权重对应一个梯度值
self.bias_grad = 0.0 # 对象内部保存的偏置梯度,是经过样本之间平均处理的,因此一个偏置对应一个梯度值
self.inputs_buff = None
self.outputs_buff = None
def forward(self, inputs):
'''
forward method: compute the output of the network
inputs: 输入的特征,shape:(sample_num, input_dim)
return: 经过逻辑回归计算出的预测值,shape: (sample_num, 1)
'''
z = np.matmul(inputs, self.weight) + self.bias
outputs = 1 / (1 + np.exp(-z))
self.inputs_buff = np.copy(inputs)
self.outputs_buff = np.copy(outputs)
return outputs
def backward(self, out_grads):
'''
backward method: compute the gradient of the loss with respect to the weight and bias
out_grads: 损失函数对于逻辑回归输出的导数,每条训练样本对应一个导数值,shape: (sample_num, 1)
inputs: 与out_grads相对应的输入特征,shape: (sample_num, input_dim)
preds: 将inputs通过forward()方法计算得到的预测值,shape: (sample_num, 1)
return: None (计算出的梯度保存在对象内部)
'''
sample_num = self.inputs_buff.shape[0]
# 首先计算损失函数对于线性模型输出的梯度z_grads
# z_grads = out_grads * preds * (1 - preds)
z_grads = out_grads * self.outputs_buff * (1 - self.outputs_buff)
# 然后计算损失函数对于权重梯度
# z_grads shape: (sample_num, 1)
# inputs shape: (sample_num, input_dim)
# 输出的weight_grads shape: (sample_num, input_dim)
# 需要将z_grads进行广播,扩展到(sample_num, input_dim), 再与inputs进行对应元素相乘的运算
weight_grads = z_grads * self.inputs_buff
# 同样的方式计算损失函数对于偏置的梯度,可视为输入特征为1.0的情况
bias_grads = z_grads
# 对梯度进行平均
self.weight_grad = weight_grads.mean(axis=0).reshape(-1, 1) # 在样本之间取平均
self.bias_grad = bias_grads.mean().reshape(-1, 1) # 在样本之间取平均
def update(self, lr, weight_decay):
self.weight = (1 - lr * weight_decay) * self.weight - lr * self.weight_grad
self.bias = (1 - lr * weight_decay) * self.bias - lr * self.bias_grad
self.weight_grad[:] = 0.0
self.bias_grad[:] = 0.0
class Dataset:
'''
数据集
'''
def __init__(self, sample_num, seed):
'''
sample_num: 生成随机样本的个数
seed: 随机种子
'''
self.sample_num = sample_num
# 生成特征
np.random.seed(seed=seed)
self.x = np.random.rand(sample_num, 2) # 服从[0, 1]之间均匀分布的随机数
# 生成标签:如果 x2 >= x1,则y=1, 否则y=0
self.y = np.ones((sample_num, 1)) * (self.x[:, 1] >= self.x[:, 0]).reshape(-1, 1)
def __len__(self):
return self.sample_num
def __getitem__(self, index):
return self.x[index], self.y[index]
def shuffle(self):
# 打乱数据集
index = np.arange(self.sample_num)
np.random.shuffle(index)
self.x = self.x[index]
self.y = self.y[index]
def plot(self):
import matplotlib.pyplot as plt
plt.scatter(self.x[self.y[:, 0] == 1][:, 0], self.x[self.y[:, 0] == 1][:, 1], marker='+', color='blue')
plt.scatter(self.x[self.y[:, 0] == 0][:, 0], self.x[self.y[:, 0] == 0][:, 1], marker='o', color='green')
plt.show()
def calc_loss(preds, labels):
# 计算损失函数
return -labels * np.log(preds+1e-10) - (1 - labels) * np.log(1-preds+1e-10)
def calc_loss_grad(preds, labels):
return -labels / (preds+1e-10) + (1 - labels) / (1 - preds+1e-10)
def test_model(model, dataset):
# 测试模型
preds = model.forward(dataset.x)
pred_labels = (preds >= 0.5).astype(np.int32)
accuracy = (pred_labels == dataset.y)
loss = calc_loss(preds, dataset.y)
return loss.mean(), accuracy.mean()
if __name__ == '__main__':
# 生成数据集
train_dataset = Dataset(500, 0)
valid_dataset = Dataset(100, 1)
test_dataset = Dataset(100, 2)
#train_dataset.plot()
#test_dataset.plot()
# 训练超参数设置
config = {
"lr": 0.5,
"epoch": 1000000,
"weight_decay": 0.001,
"batch_size": 256,
"max_no_improve_epoch": 100
}
# 创建模型对象
model = LogisticNetwork(2)
# 开始模型训练
valid_loss = []
best_valid_loss = 1e10
best_model = {
"weight": None,
"bias": None
}
no_improve_epoch = 0
for epoch in range(config['epoch']):
# 打乱训练集中的样本顺序
train_dataset.shuffle()
iter = 0
while (iter + config['batch_size']) < len(train_dataset):
# 获取一个batch的数据
batch_x = train_dataset.x[iter: iter + config['batch_size']]
batch_y = train_dataset.y[iter: iter + config['batch_size']]
# 前向计算
preds = model.forward(batch_x)
# 计算loss
loss = calc_loss(preds, batch_y)
# 计算损失函数对于模型输出的导数, shape: (batch_size, 1)
out_grads = calc_loss_grad(preds, batch_y)
# 反向计算
model.backward(out_grads)
# 更新权重和偏置
model.update(config['lr'], config['weight_decay'])
iter += config['batch_size']
# 在验证集上测试模型
valid_loss, valid_accuracy = test_model(model, valid_dataset)
print(f"epoch: {epoch}, valid_loss: {valid_loss}, valid_accuracy: {valid_accuracy}, no_improve_epoch: {no_improve_epoch}")
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
best_model['weight'] = model.weight.copy()
best_model['bias'] = model.bias.copy()
no_improve_epoch = 0
else:
no_improve_epoch += 1
if no_improve_epoch >= config['max_no_improve_epoch']:
break
# 测试模型
print(f"best model:\n{best_model}")
best_model = LogisticNetwork(2, best_model['weight'], best_model['bias'])
test_loss, test_accuracy = test_model(best_model, test_dataset)
print(f"test_loss: {test_loss}, test_accuracy: {test_accuracy}")3.异或问题
异或 (XOR) 是⼀种⼆值逻辑运算,对于两个输⼊ x1 与 x2,异或运算的输出值如下表所示。

如果将异或运算的结果作为类别标签,样本的分布如图所⽰。显然,不存在任何⼀条直线能够将样本正确分类,因此简单神经⽹络是⽆法解决异或问题的,需要更多的神经元。
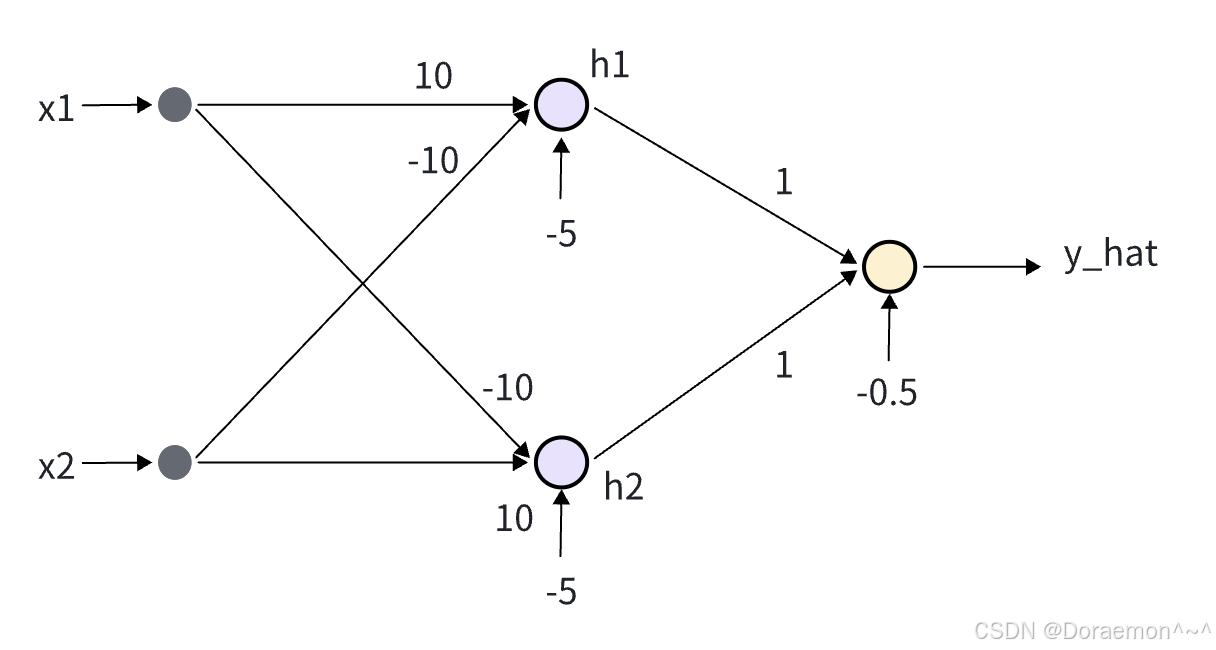
图示为⼀个由三个神经元构成的神经⽹络,紫⾊的神经元负责将原始的特征(x1,x2) 变换为(h1,h2),⻩⾊的神经元则以(h1,h2)作为特征,作出最后的预测。每个神经元同样包含了线性模型和sigmoid函数变换。
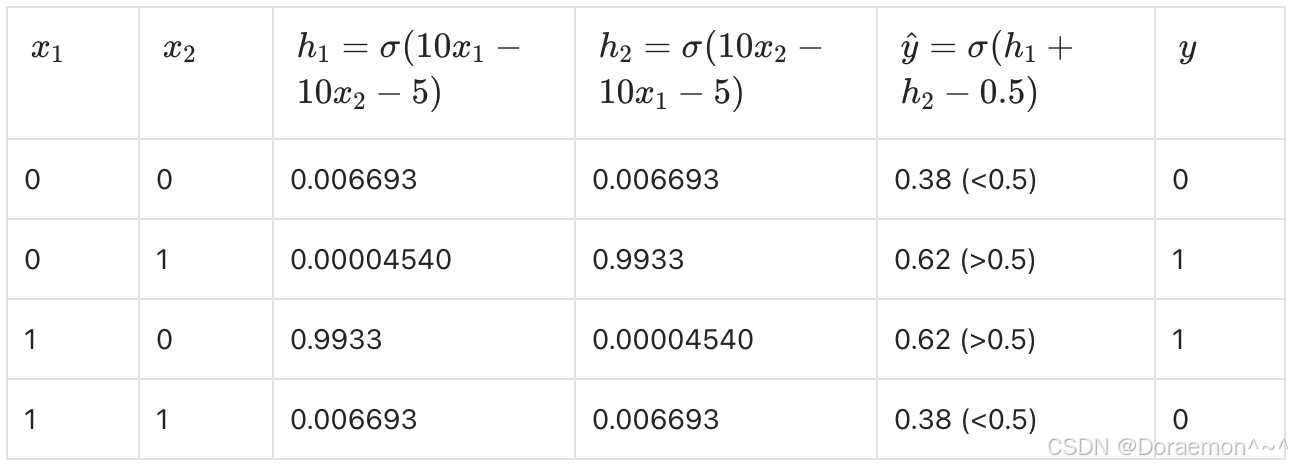
在通过紫⾊神经元之后,原始特征空间中的点(1,1)被映射到了原点附近,⽽其他三个点还在原有位置附近,因此很容易能够被线性分类器给区分开。紫⾊神经元构成了"隐藏层",它们的作⽤是提取更有效的特征。⻩⾊神经元构成了"输出层",作⽤是利⽤隐藏层提取的特征进⾏预测。表示原始特征输⼊的⿊⾊节点,在逻辑上也被看作神经⽹络的⼀层,叫作"输⼊层"。
4.多层感知机
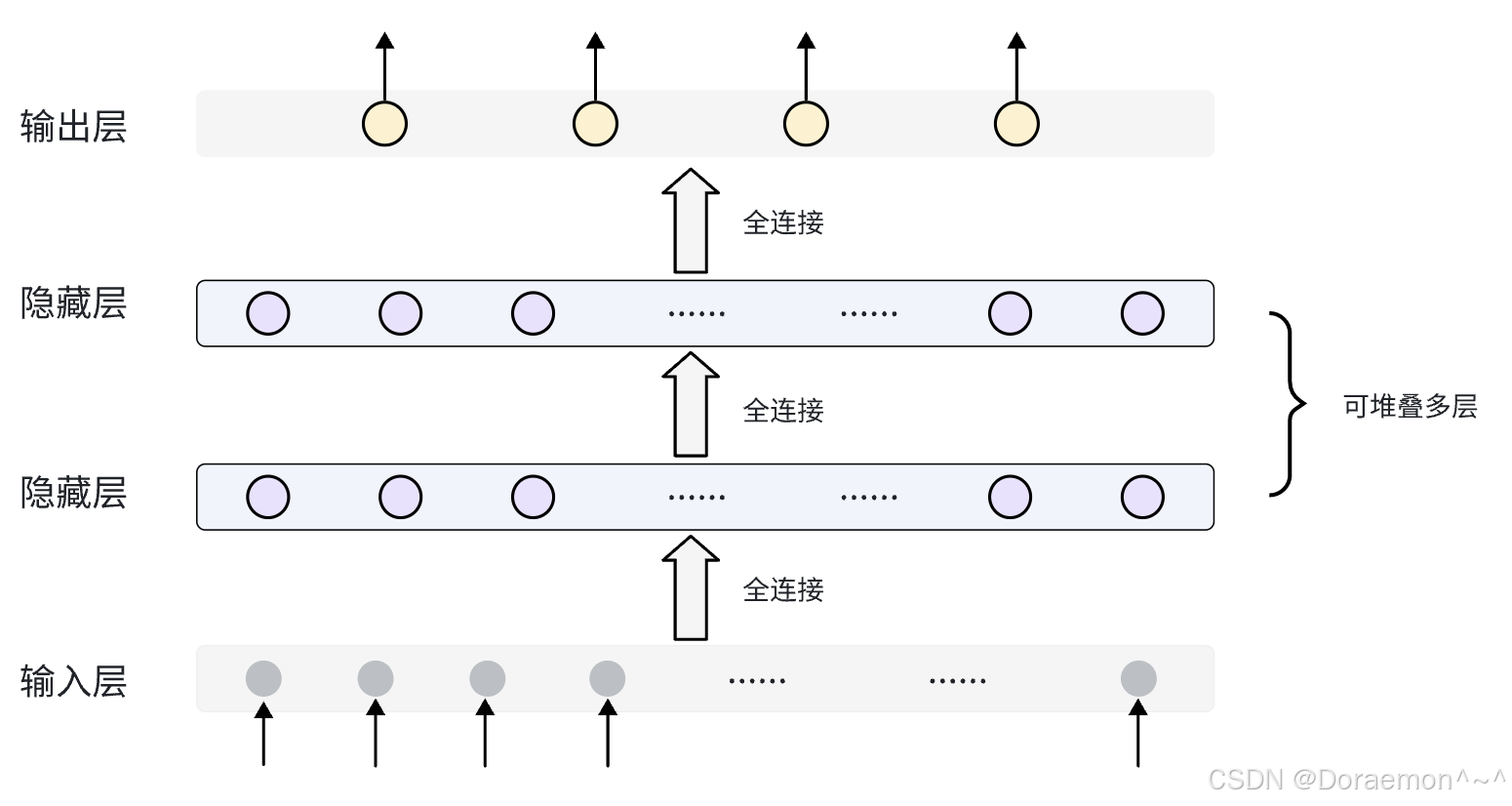
我们在异或问题上证明了多层神经⽹络可以解决线性不可分的问题。这种相邻两层节点之间是全连接结构的神经⽹络叫做多层感知机 (Multi-Layer Perceptron),缩写为MLP。多层感知机由输⼊层、隐藏层和输出层组成,其中隐藏层的作⽤是提取⾮线性特征,输出层的作⽤是进⾏预测。
4.1.隐藏层
隐藏层的作⽤是提取特征,可以有多层,每层的神经元数量可以不相同。越靠近输出层,所提取特征的语义层级 (或抽象层级)越⾼。具有两个及两个以上隐藏层的神经⽹络被称为"深度神经⽹络"。
隐藏层神经元的激活函数有多种选择,除了Sigmoid 之外,还可以采⽤Tanh (双曲正切函数)、ReLu 和LeakyReLu等。但需要注意的是,神经⽹络依靠激活函数带来⾮线性输出,因此,隐藏层的激活函数⼀定是⾮线性的。
主要的激活函数:
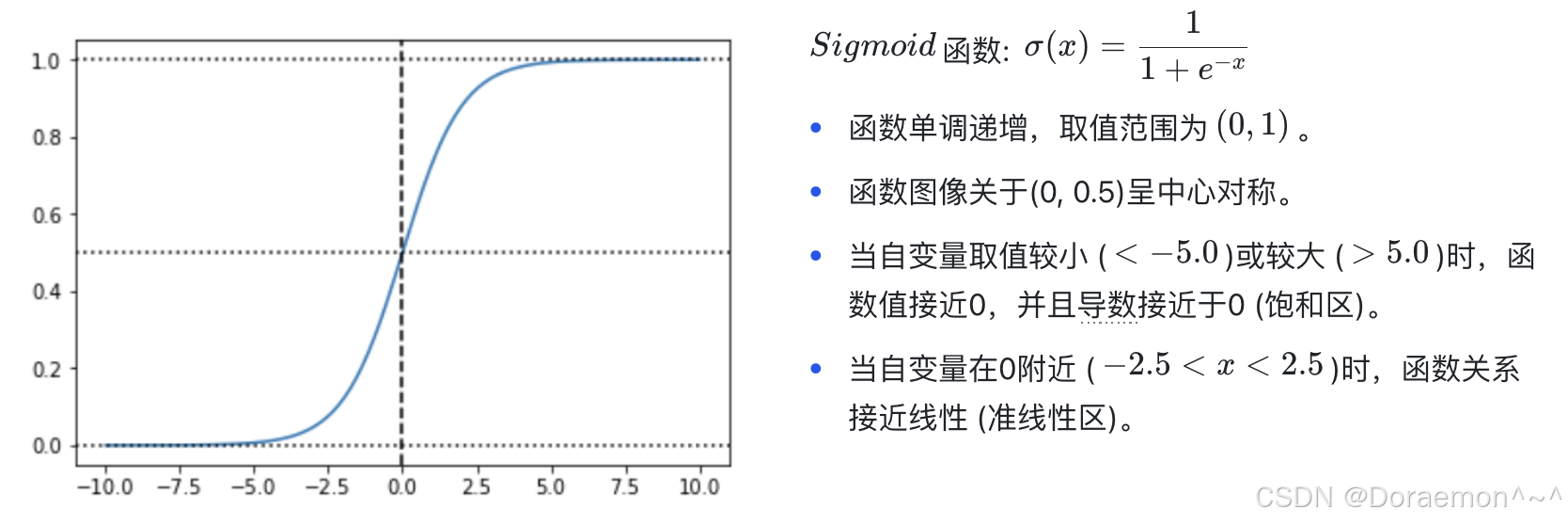
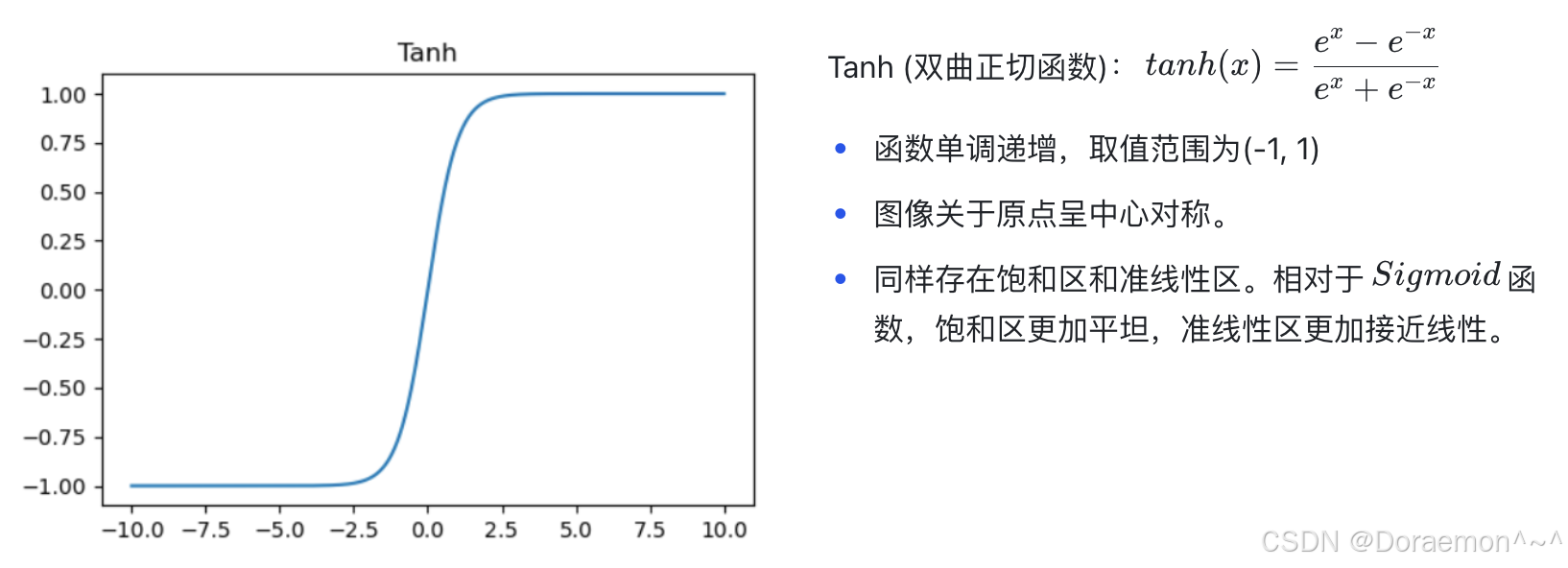
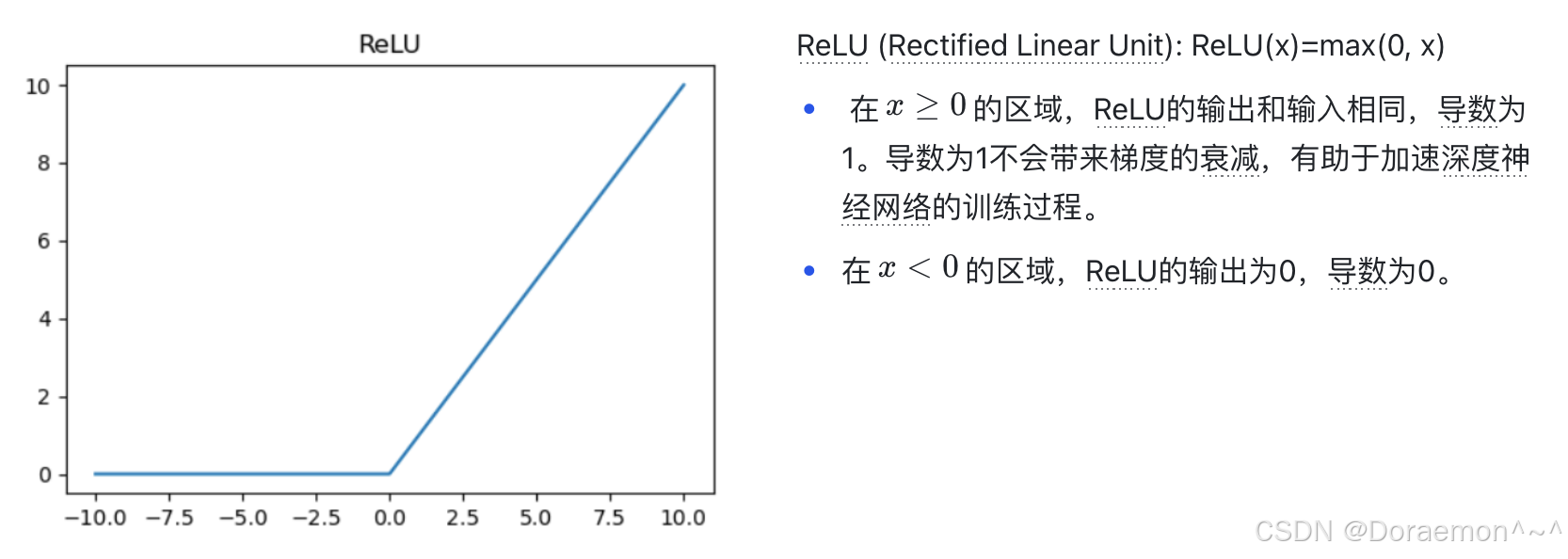
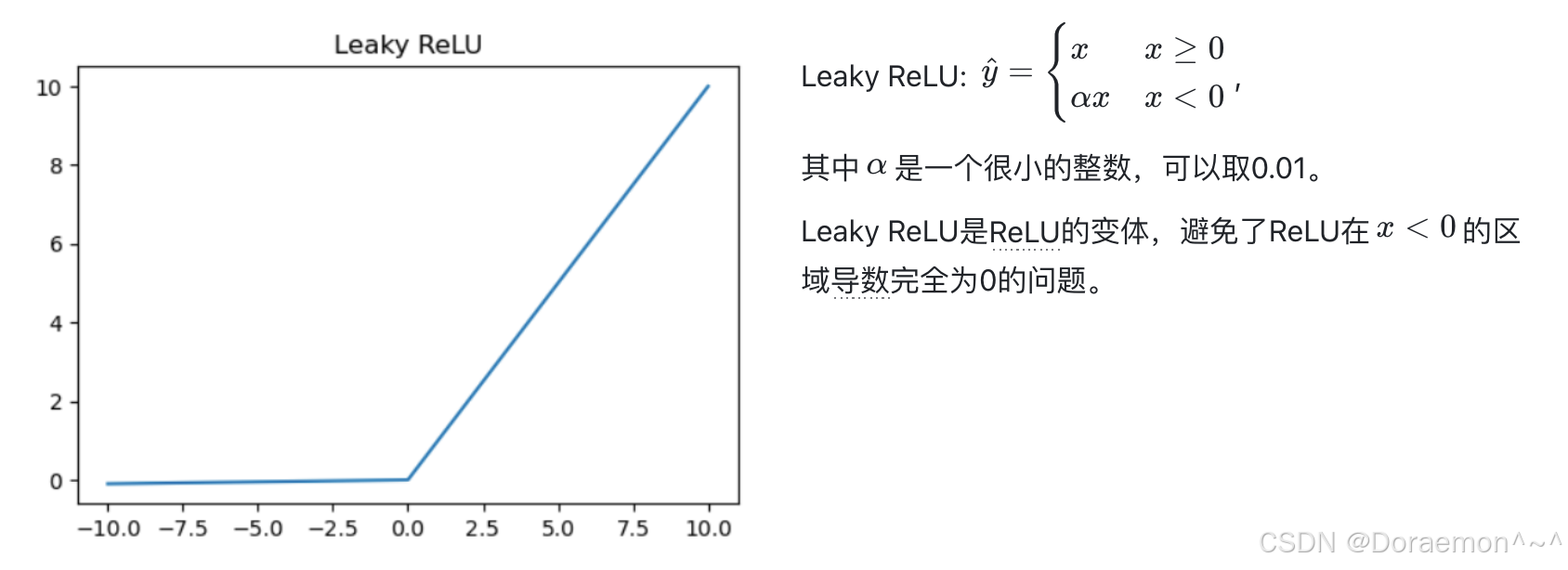
4.2.输出层
输出层的作⽤是完成预测,因此输出层的结构取决于预测任务的类型。
对于回归问题,输出层的节点数量为1,并且没有⾮线性函数:
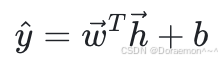
其中, 为输出层的权重向量,
为输出层的权重向量,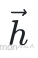 为最后⼀个隐藏层的输出, b为偏置项。
为最后⼀个隐藏层的输出, b为偏置项。
对于**⼆分类问题**,输出层的节点数量为1,节点上的激活函数为Sigmoid,所预测的是样本属于正类的概率:
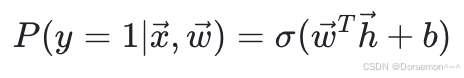
对于多分类问题,输出层节点的数量等于类别数,输出层的激活函数为Softmax,每个节点所预测的是样本属于相应类别的概率。具体公式在MNIST数字⼿写体实验的部分进⾏讲解。
⽹络结构的设计问题
隐藏层和输出层具有不同的作⽤,因此隐藏层和输出层在结构设计⽅⾯是解耦的。
- 隐藏层的作⽤是提取特征,因此隐藏层的结构设计和数据特点有关。例如:结构化数据⼀般采⽤全连接的⽹络结构;图像数据⼀般先经过卷积神经⽹络提取局部特征,再通过全连接⽹络进⾏整体特征的抽象和变换;⽂本数据⼀般通过Transformer提取语义特征。
- 输出层的作⽤是进⾏预测,因此输出层的结构只与预测问题的类型有关,⽽与数据特点⽆关。
5.正向传播和反向传播
神经⽹络有两个计算问题:
- 正(前)向传播 (Forward Propagation):从特征输⼊开始,从下到上逐层计算神经⽹络的输出,直到计算出最终的预测结果。每⼀层的输出都是下⼀层的输⼊。
- 反(后)向传播 (Backward Propagation):从损失函数对于神经⽹络预测结果的偏导开始,从上到下逐层计算损失函数对于每⼀层⽹络输出的偏导,⽤于计算每⼀层权重的梯度。
下边,结合⼀个例⼦,说明正向传播和反向传播的计算过程。
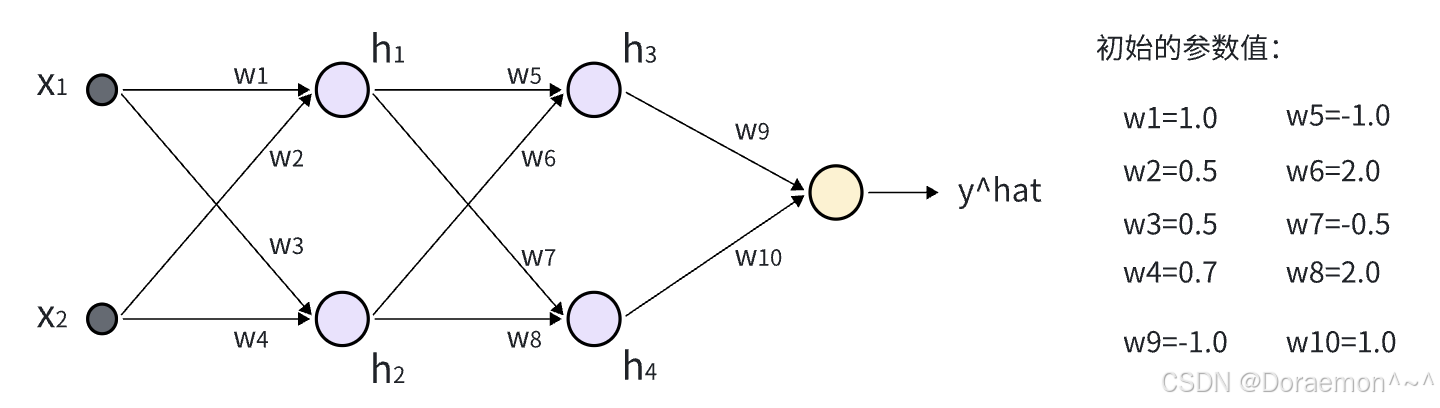
图⽰的神经⽹络包含两个隐藏层,隐藏层节点的激活函数为ReLU。输出层节点只包含线性模型,⽤于解决数值预测的问题,即回归问题。假设我们输⼊的样本x1=0.5,x2=1.0,y=0.8。
正向传播的过程如下:
1、以 x1 、 x2 为输⼊,计算 h1 、 h2 :
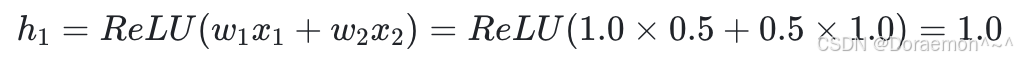
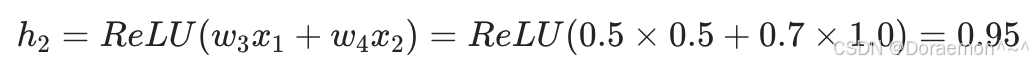
2、以 h1 、 h2 为输⼊,计算 h3 、 h4 :
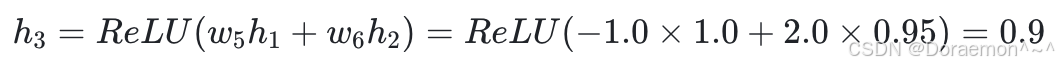
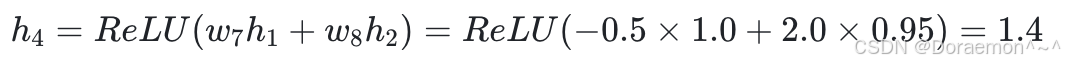
3、以 h3 、 h4 为输⼊,计算 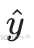 :
:
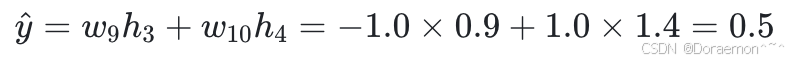
4、将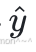 与 y相⽐对,计算损失函数值:
与 y相⽐对,计算损失函数值:
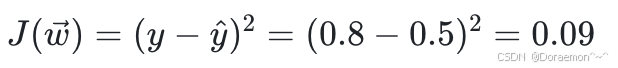
正向传播的过程结束,之后开始反向传播:
1、计算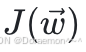 对于
对于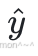 的导数:
的导数:
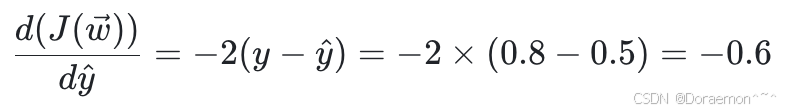
2、已知损失函数对于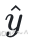 的导数,计算损失函数对于 *w*9 , *w*10 的梯度,同时将梯度传播到 *h*3 , *h*4 :
的导数,计算损失函数对于 *w*9 , *w*10 的梯度,同时将梯度传播到 *h*3 , *h*4 :
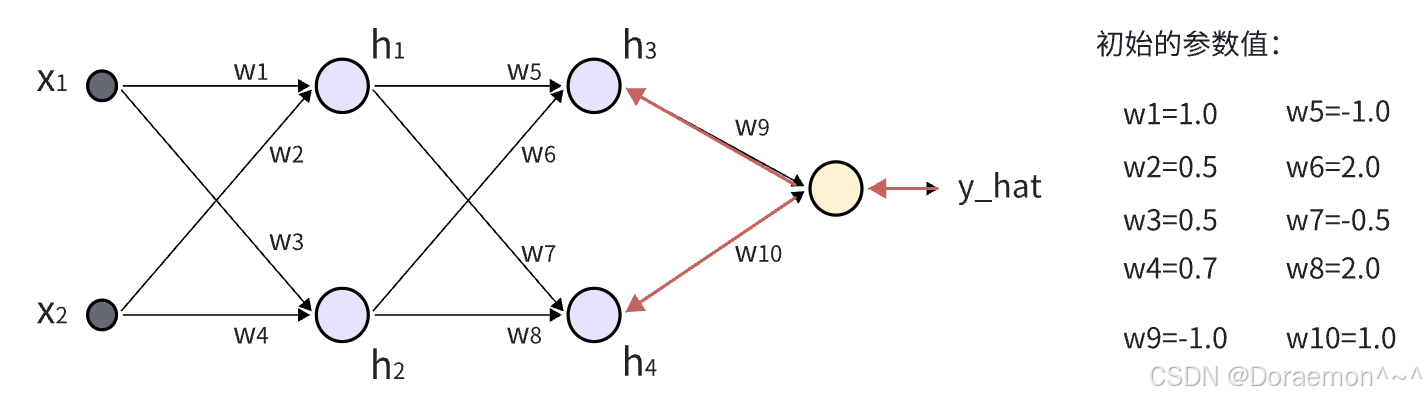
(1)计算损失函数对于 w9 、 w10 的偏导:
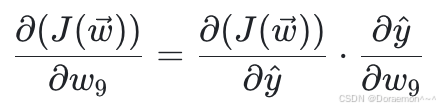
其中第⼀个因式在上⼀步已算出,因此只需要计算第⼆个因式即可:
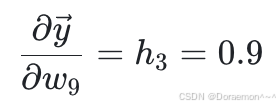
将两个因式相乘:
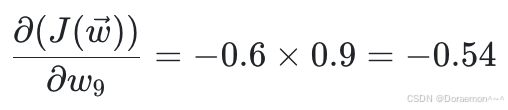
同理,损失函数对于 w10的偏导:
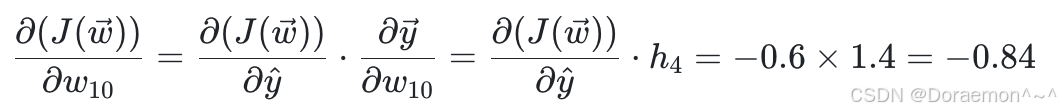
(2) 计算损失函数对于 h3 、 h4 的偏导:
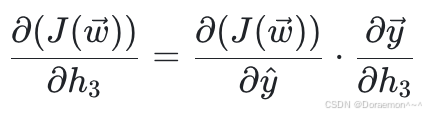
其中第⼀个因式已知,第⼆个因式:
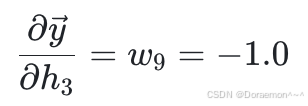
将两个因式相乘:
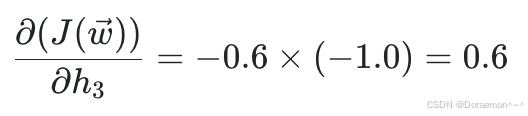
同理可得:
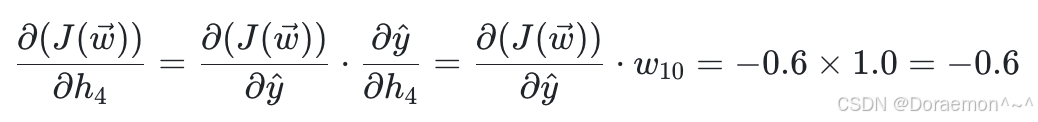
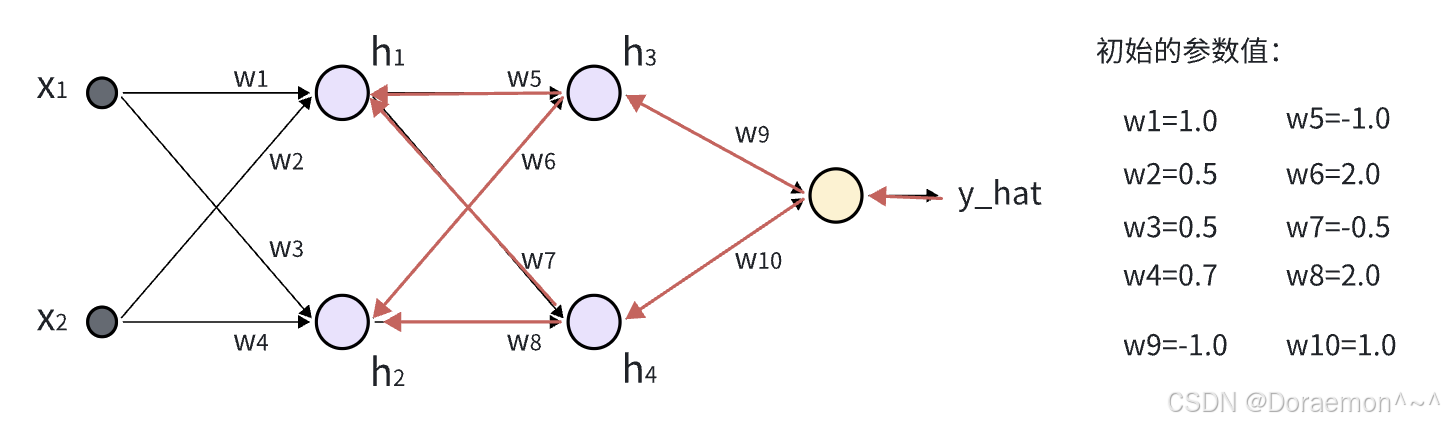
3、已知损失函数对于*h*3,*h*4 的梯度,计算损失函数对于*w5* , *w6* ,*w7* , *w8* 的梯度,同时将梯度传播到 *h1,**h2* 。
(1)计算损失函数对于 w5、 w6、 w7、 w8 的偏导:
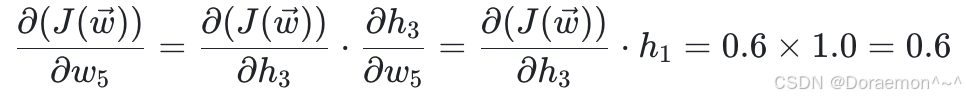
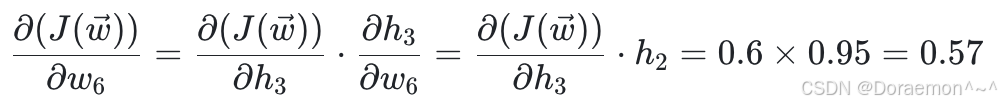
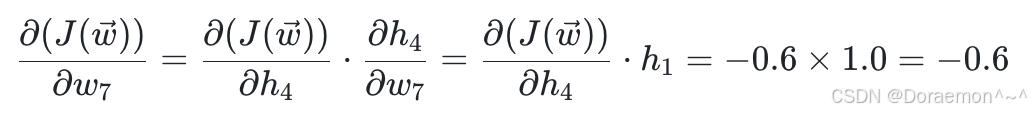
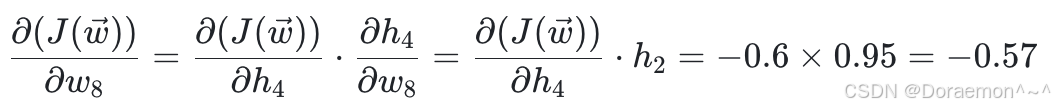
(2)计算损失函数对于 h1、 h2 的偏导:
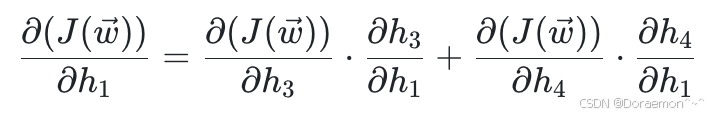
由于:
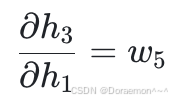 ,
,
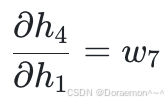 ,
,
因此:
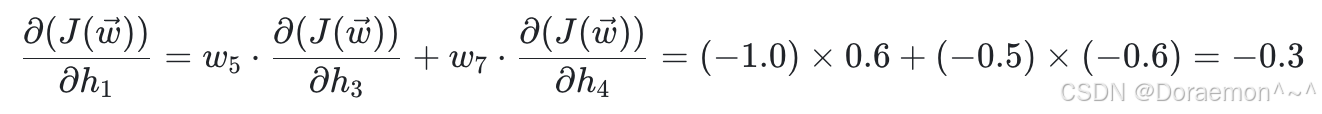
同理可得:
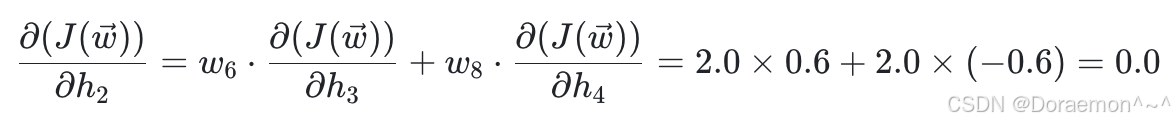
4、已知损失函数对于 *h*1 , *h*2 的梯度,计算损失函数对于 *w*1 , *w*2 , *w*3 , *w*4 的梯度:
已知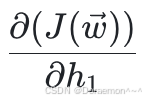 、
、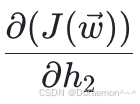 ,显然可得:
,显然可得:
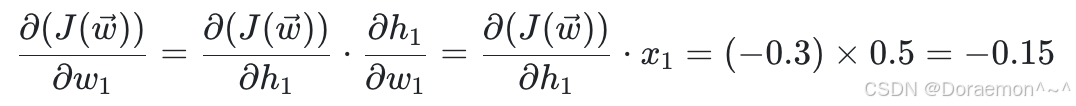
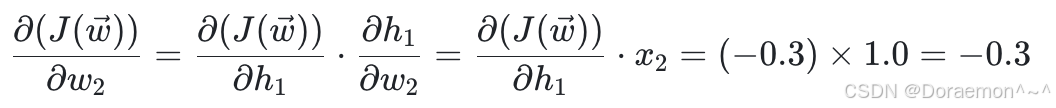
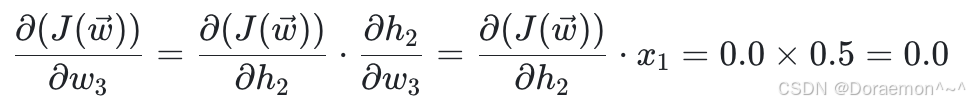
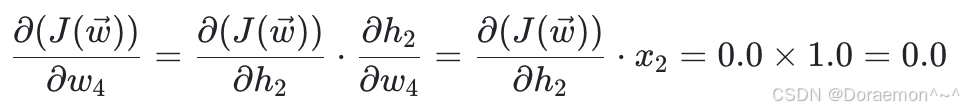
在求出损失函数对所有权重的梯度之后,就可以进⾏权重更新,设学习率 η= 0.1 :

可以验证⼀下,在进⾏了⼀次参数更新之后,预测值是否更加接近真实值。重新进⾏⼀次正向传播:
1、以 x 1 、 x 2 为输⼊,计算 h 1 、 h2 :
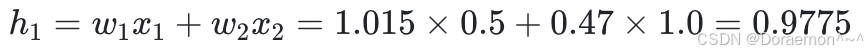
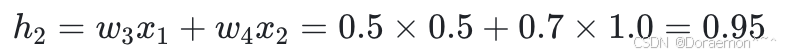
2、以 h 1 、 h 2 为输⼊,计算 h 3 、 h4 :

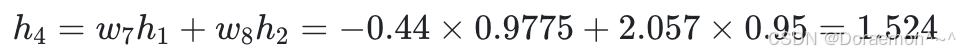
3、以 h3 、 h4 为输⼊,计算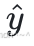 :
:
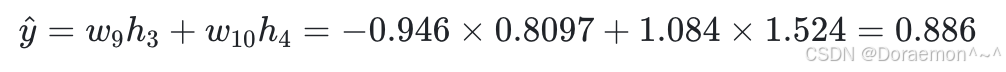
4、将 与 y相⽐对,计算损失函数值:
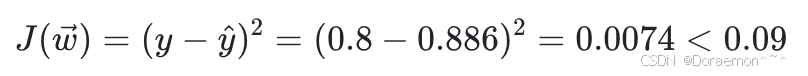
可⻅权重更新之后,预测值的确更加接近真实值了。
6.全连接层的向量化计算
现在来梳理⼀下全连接⽹络的计算。
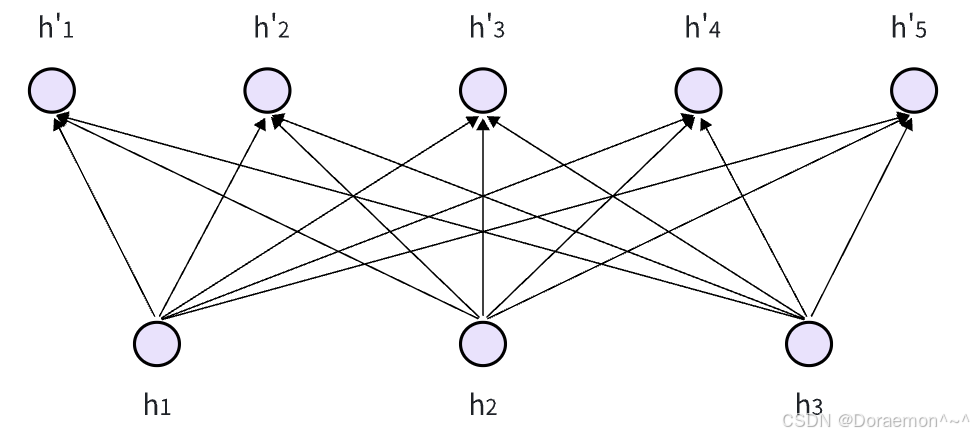
对于图示的全连接⽹络,输⼊节点数为3,输出节点数为5,设神经元上的激活函数为Sigmoid函数,即 。这样每个输出节点实际上分别对应一个逻辑回归模型,每个逻辑回归的权重(w)和偏置(b)是独立的。
。这样每个输出节点实际上分别对应一个逻辑回归模型,每个逻辑回归的权重(w)和偏置(b)是独立的。
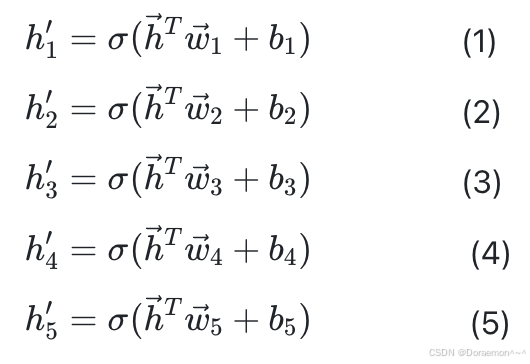
其中 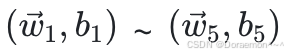 分别为每个逻辑回归模型的参数,
分别为每个逻辑回归模型的参数,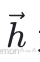 为输入向量:
为输入向量:
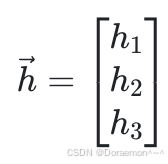
如果将(1)~(5)式合并为一个矩阵运算:
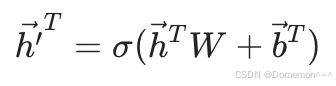
其中W是一个3x5的矩阵,每一列对应于一个输出节点的权重:
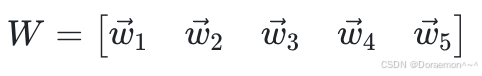
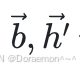 分别是一个向量:
分别是一个向量:
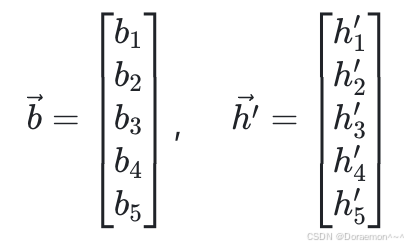
上述计算也可以拆分为两个步骤:
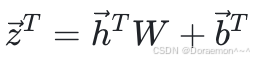 ,
,
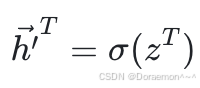
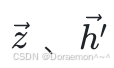 均为长度为5的向量。
均为长度为5的向量。
6.1.正向传播
在正向传播的过程中,设输⼊数据包含B个样本,分别为 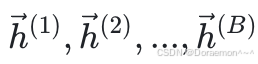 ,同样排列为⼀个矩阵,其中的每⾏表⽰⼀个样本:
,同样排列为⼀个矩阵,其中的每⾏表⽰⼀个样本:

H的尺寸为(B, 3),每行表示一个样本。线性模型的输出为:
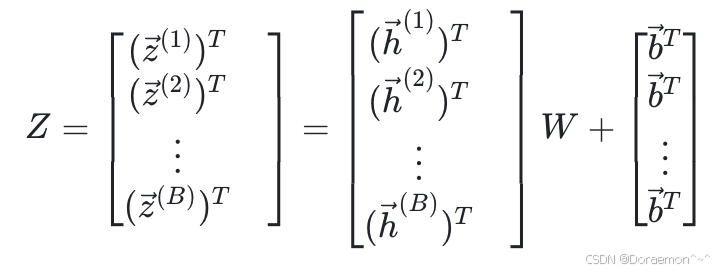
即: (需要利用广播机制)
(需要利用广播机制)
其中 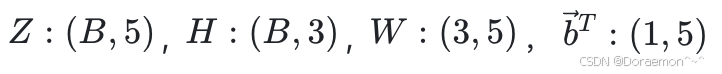
之后再经过激活函数(按元素计算),即可得到输出:
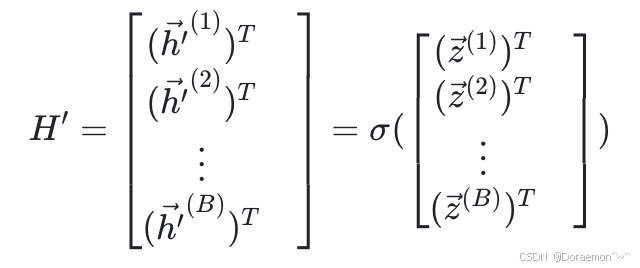
6.2.反向传播
在反向传播过程中,我们已知损失函数对于 H′ 的梯度矩阵:
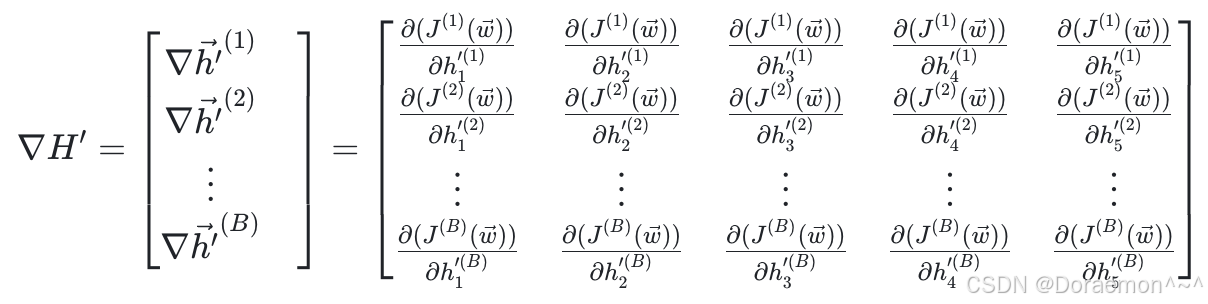
1、⾸先来求损失函数对于线性模型输出Z的梯度,这一步需要乘以Sigmoid函数的导数:
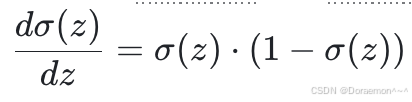
只需要在 矩阵的每个元素乘以对应的
矩阵的每个元素乘以对应的
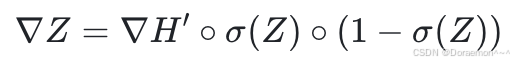
其中 o 表示对应元素相乘的运算。 也是一个尺寸为(B, 5)的矩阵,其中每一行对应于一个样本。
也是一个尺寸为(B, 5)的矩阵,其中每一行对应于一个样本。
2、接下来求权重矩阵的梯度,先看通过第 k个样本的损失函数计算的梯度 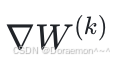 ,是一个3x5的矩阵,与W的元素一一对应。
,是一个3x5的矩阵,与W的元素一一对应。
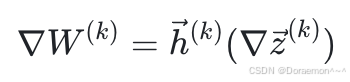
其中,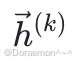 是第k个样本的输入向量,尺寸为(3,1);
是第k个样本的输入向量,尺寸为(3,1);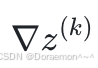 是
是  的第k行,尺寸为(1,5)。
的第k行,尺寸为(1,5)。
微批中所有样本对 W的总梯度 为:
为:
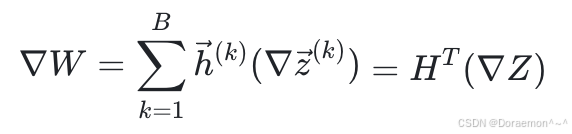
3、最后求输入H 的梯度:
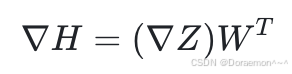
7.神经网络的代码实现(基于numpy)
- 构建通用的全连接层类
- 基于全连接层类构建MLP类
- 解决非线性回归问题
python
import numpy as np
class NeuralNetworkBase():
'''
神经网络的基类
'''
def __init__(self):
self.params = {}
pass
def forward(self, inputs):
pass
def backward(self, out_grads):
pass
def update(self):
pass
def print_params(self):
for key, value in self.params.items():
print(key, value)
@staticmethod
def sigmoid(inputs):
return 1 / (1 + np.exp(-inputs))
@staticmethod
def sigmoid_grad(outputs):
return outputs * (1 - outputs)
@staticmethod
def linear(inputs):
return inputs
@staticmethod
def linear_grad(outputs):
return np.ones_like(outputs).astype(np.float32)
@staticmethod
def relu(inputs):
return (inputs > 0).astype(np.float32) * inputs
@staticmethod
def relu_grad(outputs):
return (outputs > 0).astype(np.float32)
class FCLayer(NeuralNetworkBase):
'''
全连接层网络 (一层)
'''
def __init__(self, input_dim, output_dim, activation="linear", weight=None, bias=None):
super().__init__()
# 输入和输出节点数
self.input_dim = input_dim
self.output_dim = output_dim
# 配置激活函数
self.activation_fn = self.linear
self.activation_grad_fn = self.linear_grad
if activation == "sigmoid":
self.activation_fn = self.sigmoid
self.activation_grad_fn = self.sigmoid_grad
if activation == "relu":
self.activation_fn = self.relu
self.activation_grad_fn = self.relu_grad
# 初始化参数
self.weight = np.random.randn(input_dim, output_dim) # (input_dim, output_dim)
self.bias = np.random.randn(1, output_dim) # (1, output_dim)
self.params['weight'] = self.weight
self.params['bias'] = self.bias
if weight is not None:
self.weight[:] = weight
if bias is not None:
self.bias[:] = bias
# data buffer
self.inputs_buff = None
self.outputs_buff = None
# gradients buff
self.weight_grad = np.zeros(self.weight.shape)
self.bias_grad = np.zeros(self.bias.shape)
def forward(self, inputs):
# 计算z
z = np.matmul(inputs, self.weight) + self.bias
# 计算经过激活函数的outputs
outputs = self.activation_fn(z)
# buffering data
self.inputs_buff = np.copy(inputs)
self.outputs_buff = np.copy(outputs)
return outputs
def backward(self, out_grads):
# 计算z的梯度
zgrads = out_grads * self.activation_grad_fn(self.outputs_buff)
# 计算权重和偏置的梯度
self.weight_grad[:] = np.matmul(self.inputs_buff.T, zgrads) / zgrads.shape[0]
self.bias_grad[:] = np.matmul(np.ones((1, zgrads.shape[0])).astype(np.float32), zgrads) / zgrads.shape[0]
# 返回input_grads
return np.matmul(zgrads, self.weight.T)
def update(self, lr, weight_decay=0.0):
self.weight[:] = self.weight * (1- lr * weight_decay) - lr * self.weight_grad
self.bias[:] = self.bias * (1- lr * weight_decay) - lr * self.bias_grad
# 清空中间变量的缓存
self.inputs_buff = None
self.outputs_buff = None
self.weight_grad[:] = 0
self.bias_grad[:] = 0
class MLP(NeuralNetworkBase):
'''
多层感知机
'''
def __init__(self, dims, hidden_activation="linear", output_activation="linear", params=None):
super().__init__()
# 创建隐藏层
self.hidden_layers = []
self.hidden_layer_num = len(dims)-2
for i in range(self.hidden_layer_num):
layer_name = "hidden_layer_" + str(i)
weight = None
bias = None
if params is not None:
weight_name = layer_name + "_weight"
bias_name = layer_name + "_bias"
weight = params.get(weight_name, None)
bias = params.get(bias_name, None)
self.hidden_layers.append(FCLayer(dims[i], dims[i+1], hidden_activation, weight, bias))
# 把当前隐藏层的参数放到self.params中
self.params[layer_name + "_weight"] = self.hidden_layers[-1].weight
self.params[layer_name + "_bias"] = self.hidden_layers[-1].bias
# 创建输出层
layer_name = "output_layer"
weight = None
bias = None
if params is not None:
weight_name = layer_name + "_weight"
bias_name = layer_name + "_bias"
weight = params.get(weight_name, None)
bias = params.get(bias_name, None)
self.output_layer = FCLayer(dims[-2], dims[-1], output_activation, weight, bias)
self.params[layer_name + "_weight"] = self.output_layer.weight
self.params[layer_name + "_bias"] = self.output_layer.bias
def forward(self, inputs):
for layer in self.hidden_layers:
inputs = layer.forward(inputs)
return self.output_layer.forward(inputs)
def backward(self, out_grads):
out_grads = self.output_layer.backward(out_grads)
for layer in reversed(self.hidden_layers):
out_grads = layer.backward(out_grads)
def update(self, lr, weight_decay=0.0):
for layer in self.hidden_layers:
layer.update(lr, weight_decay)
self.output_layer.update(lr, weight_decay)
python
import numpy as np
from model import *
import copy
class Dataset:
def __init__(self, sample_num, seed):
self.sample_num = sample_num
# 生成x
np.random.seed(seed)
# 基于正态分布生成x
self.x = np.random.randn(sample_num, 2)
# 基于x计算y
self.y = (self.x[:, 0] ** 2 + 2 * self.x[:, 0] * self.x[:, 1] + self.x[:, 0] - self.x[:, 1] +0.5).reshape(-1, 1)
def __len__(self):
return self.sample_num
def __getitem__(self, index):
return self.x[index], self.y[index]
def shuffle(self):
# 打乱数据集
index = np.arange(self.sample_num)
np.random.shuffle(index)
self.x = self.x[index]
self.y = self.y[index]
def calc_loss(preds, labels):
return (preds-labels) ** 2
def calc_loss_grad(preds, labels):
return 2 * (preds - labels)
# main
if __name__ == '__main__':
train_dataset = Dataset(sample_num=1000, seed=0)
valid_dataset = Dataset(sample_num=1000, seed=1)
test_dataset = Dataset(sample_num=1000, seed=2)
# config
config = {
"mlp_structure": [2, 20, 10, 1],
"hidden_activation": "relu",
"lr": 0.001,
"epochs": 100000,
"weight_decay": 0.0,
"batch_size": 64,
"max_no_prove_epochs": 1000
}
# 创建模型对象
model = MLP(config["mlp_structure"], config["hidden_activation"])
best_valid_loss = 1e10
no_improve_epochs = 0
best_model = None
for epoch in range(config['epochs']):
# shuffle traing dataset
train_dataset.shuffle()
iter = 0
while (iter + config['batch_size'] < len(train_dataset)):
# 获取一个微批的数据
batch_x, batch_y = train_dataset[iter: iter+config['batch_size']]
# 正向传播
preds = model.forward(batch_x)
# 计算loss
loss = calc_loss(preds, batch_y)
# 反向传播
out_grads = calc_loss_grad(preds, batch_y)
model.backward(out_grads)
# 更新参数
model.update(config['lr'], config['weight_decay'])
iter += config['batch_size']
# 验证集上验证
valid_preds = model.forward(valid_dataset.x)
valid_mean_loss = calc_loss(valid_preds, valid_dataset.y).mean()
# 比较当前的best_valid_loss
if valid_mean_loss < best_valid_loss:
best_valid_loss = valid_mean_loss
no_improve_epochs = 0
#best_model = model.params.copy()
#best_model = {}
#for key in model.params:
# best_model[key] = model.params[key].copy()
best_model = copy.deepcopy(model.params)
else:
no_improve_epochs += 1
score = 1 - valid_mean_loss / valid_dataset.y.var()
print(f'epoch: {epoch}, valid_loss: {valid_mean_loss:.5f}, valid_loss_score: {score:.5f}, no_improve_epochs: {no_improve_epochs}')
if no_improve_epochs > config['max_no_prove_epochs']:
break
best_valid_score = 1 - best_valid_loss / valid_dataset.y.var()
print(f'------- Now training has been finished. -------')
print(f'best_valid_loss: {best_valid_loss}, best_valid_score: {best_valid_score:.5f}')
# 测试集上测试
best_model = MLP(config['mlp_structure'], config['hidden_activation'], params=best_model)
test_mean_loss = calc_loss(best_model.forward(test_dataset.x), test_dataset.y).mean()
print(f'test_loss: {test_mean_loss}, test_loss_score: {1 - test_mean_loss / test_dataset.y.var()}')
⾯试点:早停机制 (Early Stopping)
深度神经⽹络的参数量⼤,因此很容易发⽣过拟合。早停机制是防⽌神经⽹络训练发⽣过拟合的重要⼿段。
在⼀般情况下,训练过程中会观察训练Loss (即在训练数据上估计的损失函数值) 的变化情况,直到训练Loss下降到最低点时,才会终⽌训练。⽽在神经⽹络的训练中,如果这样操作,就很容易导致过拟合。
为了防⽌过拟合,⼀般会从神经⽹络的训练集中随机采样⼀部分数据 (占训练集总量的10~20%) 作为验证集,余下的数据才作为真正的训练集。在训练过程中,需要观察验证集上的Loss,只要验证集上的Loss停⽌下降了,就要终⽌训练。由于此时训练Loss往往还没有降到最低,因此称为"早停"。
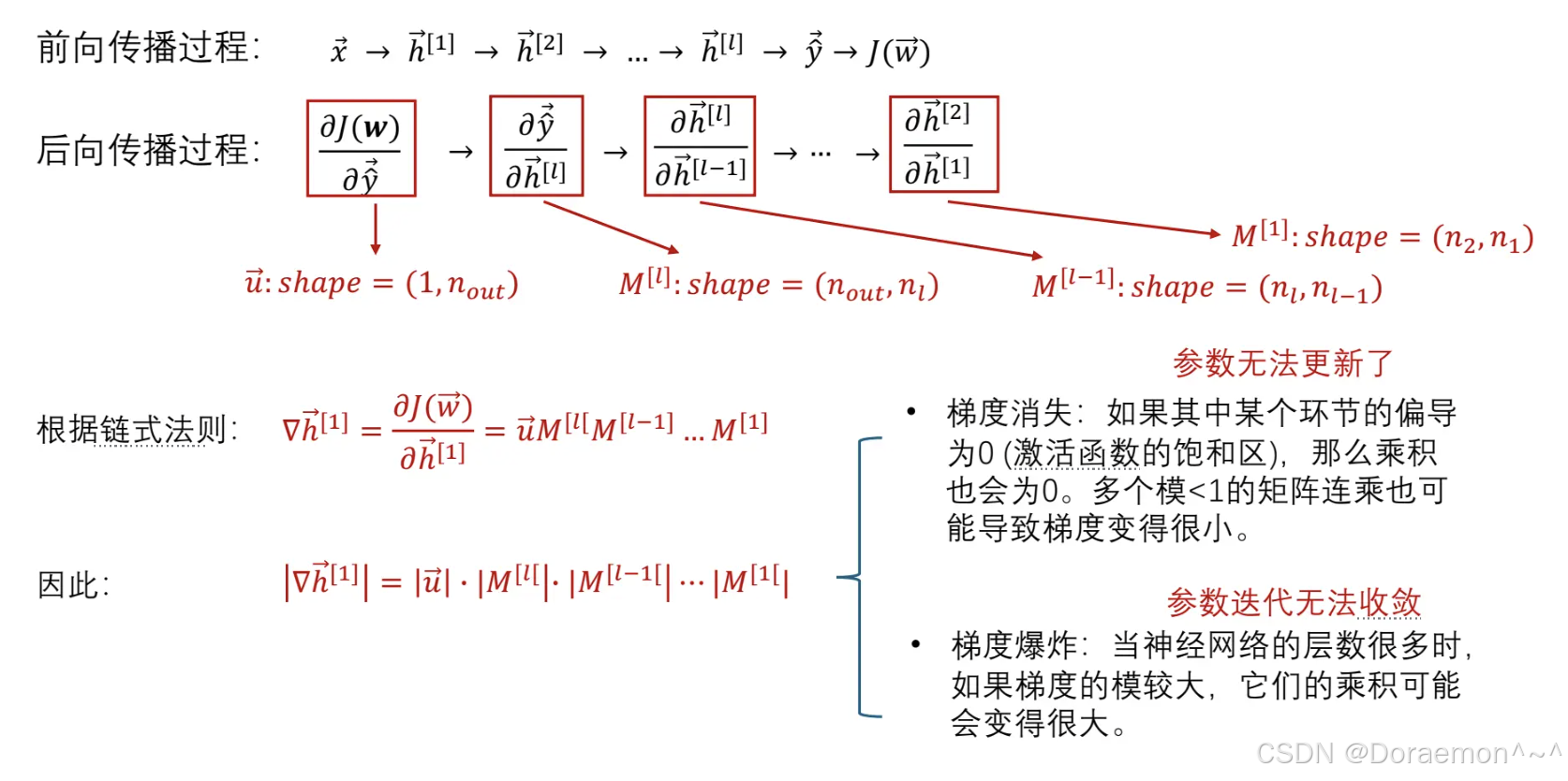
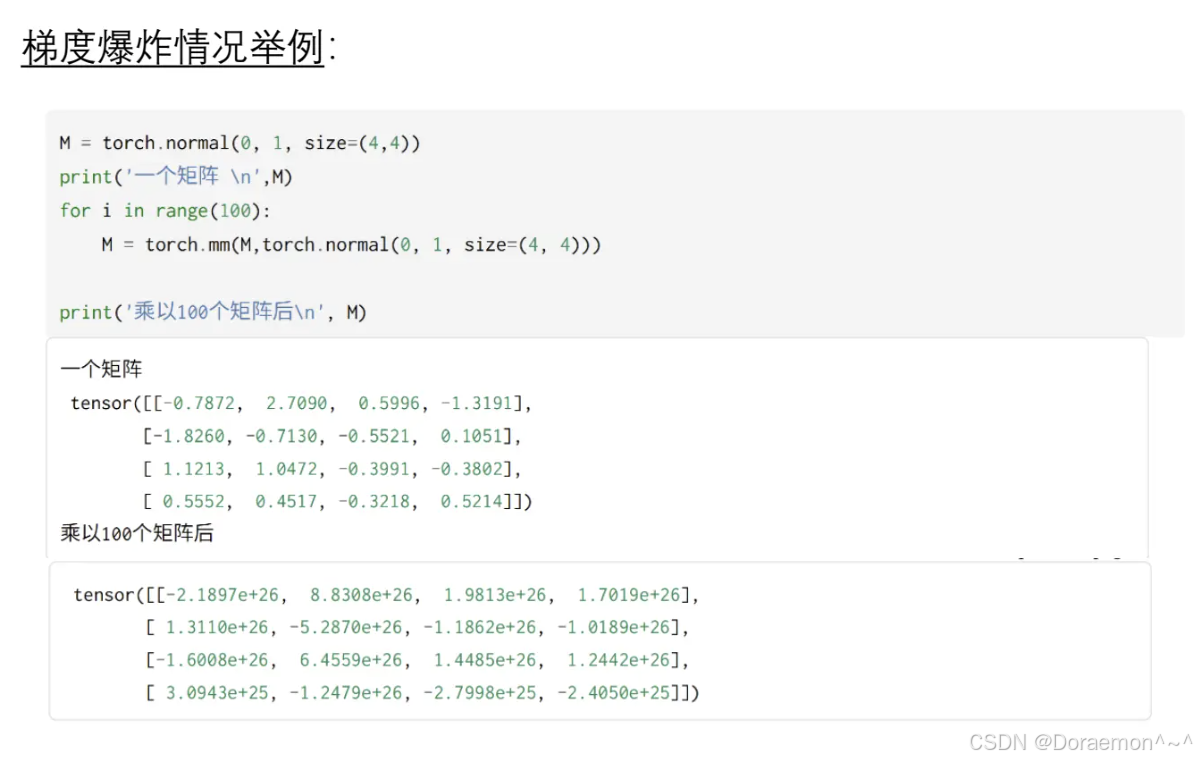
⾯试点:梯度消失和梯度爆炸