MySQL与Redis数据一致性保障策略全解析
Redis作为高性能缓存,与MySQL配合时核心挑战是保证缓存数据与数据库数据的一致性(避免缓存脏数据、数据丢失)。根据业务对「一致性强度」(强一致/最终一致)、「开发成本」、「性能损耗」的不同诉求,业界有多种成熟策略,本文从核心逻辑、适用场景、优缺点等维度全面解析。
一、基础策略:Cache Aside(旁路缓存)
这是最常用、最易落地的「最终一致性」策略,也是上一轮我们重点聊的方案,核心由业务代码直接管控缓存和数据库。
1. 核心流程
- 读操作:查缓存 → 命中则返回 → 未命中则查MySQL → 回填Redis → 返回结果;
- 写操作:更新MySQL → 删除Redis缓存(而非直接更新)→ 返回成功。
2. 关键设计
- 写操作「删缓存」而非「更缓存」:避免并发更新导致的缓存与数据库数据冲突;
- 兜底机制:给缓存设置过期时间,即使删缓存失败,也能自动淘汰脏数据。
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 实现简单、无额外中间件依赖 | 仅保证「最终一致」,并发场景可能出现短暂不一致; 删缓存失败会导致脏数据(需重试兜底) |
| 性能损耗低,适配读多写少场景 | 不适合强一致性业务 |
4. 适用场景
绝大多数互联网业务(商品详情、用户信息、订单列表),对一致性要求为「最终一致」即可。
二、进阶策略:Read/Write Through(读写穿透)
核心思想是将缓存作为数据操作的唯一入口,业务代码只操作缓存,由缓存层统一负责与MySQL的同步,彻底解耦业务与数据库。
1. 核心流程
- Read Through(读穿透) :业务查缓存 → 缓存未命中 → 缓存层主动查MySQL → 回填缓存 → 返回结果(与Cache Aside读流程类似,但逻辑封装在缓存层);
- Write Through(写穿透) :业务更新缓存 → 缓存层先更新MySQL → 再更新缓存(同步写)→ 返回成功。
2. 关键设计
- 缓存层封装所有数据库交互逻辑,业务无需感知MySQL;
- 写操作是「同步双写」,缓存与数据库更新原子性更强(但性能略低)。
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 业务逻辑简化,一致性比Cache Aside更强 | 写操作需同步等待数据库更新,性能损耗高于Cache Aside; 缓存层需自定义开发,复杂度提升 |
| 避免业务代码重复编写缓存逻辑 | 缓存层故障会直接影响所有读写操作 |
4. 适用场景
对代码整洁性要求高、写操作频率不高、可接受轻微性能损耗的场景(如内部管理系统)。
三、高性能策略:Write Back(写回/延迟写)
极致追求写性能的策略,核心是「先写缓存,延迟写数据库」,类似操作系统的「页缓存」机制。
1. 核心流程
- 写操作 :业务更新缓存 → 缓存标记为「脏数据」→ 立即返回成功;
缓存层在「特定时机」(如缓存满、定时任务、数据被淘汰)批量将脏数据同步到MySQL; - 读操作:与Read Through一致(优先查缓存,未命中则查库回填)。
2. 关键设计
- 核心是「异步批量写库」,减少数据库IO次数;
- 需设计「脏数据持久化」机制,避免缓存宕机导致数据丢失。
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 写性能极致(无需等待数据库),适合高并发写场景 | 数据一致性最弱(缓存宕机会丢失未同步的脏数据); 实现复杂,需处理数据丢失、并发覆盖问题 |
| 减少MySQL的写压力 | 仅适合「非核心数据」(如访问量统计、临时计数) |
4. 适用场景
高并发写、允许少量数据丢失、对一致性要求极低的场景(如点赞数、浏览量统计)。
四、强一致策略:基于binlog的同步(Canal/MaxWell)
通过监听MySQL的binlog(二进制日志)实现缓存与数据库的「自动同步」,是企业级高一致性方案,核心解决「业务代码侵入性」和「并发不一致」问题。
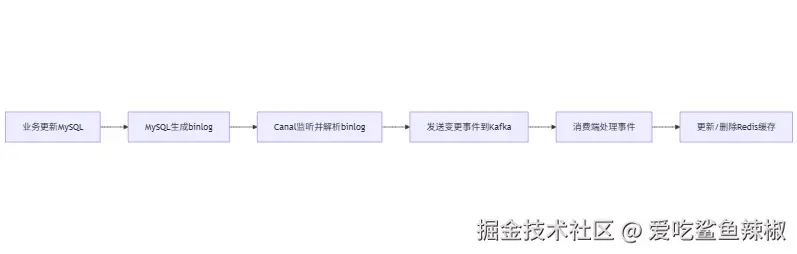
1. 核心原理
- 部署Canal/MaxWell组件,伪装成MySQL的从库,实时监听MySQL的binlog;
- 解析binlog中的增删改操作,获取数据变更内容;
- 通过消息队列(Kafka/RabbitMQ)将变更事件推送给消费端;
- 消费端根据事件更新/删除Redis缓存。
2. 核心流程
3. 优缺点
| 优点 | 缺点 |
|---|---|
| 一致性高(最终一致,延迟毫秒级); 业务代码无侵入,无需关注缓存操作; 解决并发更新不一致问题 | 引入Canal、消息队列等中间件,部署和维护成本高; 需处理binlog解析、消息重试等异常场景 |
| 适配所有读写场景,扩展性强 | 对运维能力有要求 |
4. 适用场景
中大型系统、核心业务数据(如交易、支付)、对一致性要求高且希望解耦业务与缓存逻辑的场景。
五、极致强一致:分布式事务(2PC/TCC)
如果业务要求「缓存与数据库必须实时强一致」(如金融核心系统),需通过分布式事务保证两者更新的原子性,但性能损耗大,极少推荐。
1. 核心思路
- 2PC(两阶段提交) :引入事务协调器,先预提交MySQL和Redis更新,确认两者都可执行后,再正式提交;任一环节失败则回滚;
- TCC(补偿事务) :将更新拆分为「Try(尝试)- Confirm(确认)- Cancel(取消)」三步,先尝试锁定资源,确认两者都成功后完成更新,失败则执行补偿操作。
2. 优缺点
| 优点 | 缺点 |
|---|---|
| 保证强一致性,数据零不一致风险 | 性能极低(事务阻塞、网络开销大); 实现极其复杂,易出现死锁、超时问题; Redis本身不原生支持2PC,需自定义开发 |
3. 适用场景
金融级核心业务(如资金交易),对数据一致性要求为「实时强一致」,可接受性能损耗的场景(极少使用)。
六、各策略对比与选型建议
| 策略 | 一致性级别 | 性能 | 开发/运维成本 | 适用场景 |
|---|---|---|---|---|
| Cache Aside | 最终一致 | 高 | 极低 | 绝大多数互联网业务(读多写少、最终一致) |
| Read/Write Through | 最终一致(强于Cache Aside) | 中 | 中 | 代码解耦需求高、写频率低的场景 |
| Write Back | 弱最终一致 | 极高 | 高 | 高并发写、允许少量数据丢失的非核心场景 |
| Canal+binlog | 最终一致(延迟毫秒级) | 中高 | 中高 | 中大型系统、核心业务、解耦诉求高 |
| 分布式事务 | 强一致 | 低 | 极高 | 金融核心、实时强一致场景(极少用) |
选型核心原则
- 优先选Cache Aside:90%的业务场景无需过度设计,简单落地即可满足需求;
- 核心业务升级为Canal+binlog:在一致性和性能间取平衡,同时解耦业务;
- 避免滥用分布式事务:强一致需求优先通过业务设计规避(如分阶段确认),而非技术硬扛。
总结
- MySQL与Redis数据一致性的核心是「权衡」:一致性越强,性能和开发成本越高,需匹配业务诉求;
- 主流方案是「最终一致性」:Cache Aside(基础)和Canal+binlog(进阶)是企业首选;
- 关键兜底手段:所有策略都应给缓存设置过期时间,即使同步失败,也能自动淘汰脏数据,保证最终一致。