9.4 如何对集群的容量进行规划

主要要知道单条文档的大小,预计未来3年会有多少数据量.
要确定数据是否需要过期删除,这个会影响索引设计方案;
要确定数据写入的吞吐量有没有要求. 查询的吞吐量;单条查询可接受的最大耗时;
如果是日志类型的,要考虑基于日期区分.

 创建timed-base索引
创建timed-base索引
基于别名查询,控制查询日期范围(定时任务定期变更别名范围)
这种的要注意每个新索引都会创建新分片,时间长了ES管理的分片太多.
 当分片数>节点数时,增加节点能优化读写性能.
当分片数>节点数时,增加节点能优化读写性能.

10.1 分片路由详解
ES底层读写工作原理分析
分片路由:
3节点集群,一个文档会存到哪个节点呢?会有hash(默认ID,可以自定义字段)取模的过程,这就是为什么主分片创建后不能再修改.
10.2 ES写入数据的过程
ES客户端配置3个节点ip;
①写入的时候会选择一个es节点作为协调节点,然后开始计算选择坐落的分片;
②通过集群元数据知道所需分片在哪个节点上,如果是别的机器上就把路由转发过去到对应节点上,存入主节点.再写入从节点;
③主从都写入完成后协调节点将结果返回给客户端.
10.3 根据id查询数据的过程
一种是根据ID查询:
①先轮询随机连上一个es节点;
②再根据ID进行hash再对分片数取模.定位到分片,
③再通过集群元数据找到主从节点所在node.再通过轮询的方式选择读取主从哪个node.
④拿到数据后返回给所连节点并由它返回数据给客户端
一种是根据关键词查询:
search的时候数据会比较分散,它会查所有的分片.
①还是先随机连到一个协调节点上;
②再请求其它节点上的分片,直到一个索引完整的分片都查完了;
③再到协调节点汇总结果进行合并,排序,分页;
④fetch阶段,就是根据前面获取到的ID再去各个节点查一下拉取文档;
⑤最后才是返回给客户端
10.5 写数据底层原理
每秒都会生成一个segment_file,没有数据也会生成,当文件过多的时候会自动合并.同时将已标记为删除的文档删除.
还有个提交点的概念,记录当前所有可用的segment,每个commit_point都会维护一个.del文件.当es在做删改操作的时候会先到.del文件中声明某个document已经被删除.这些文档在查询的时候是能搜多到的,但是在返回阶段会被过滤掉.
为了防止es宕机造成数据丢失保证可靠性,es会将每次写入数据同时写入translog日志中(类似MySQL,预写日志).
①写入的时候先hash再取模确定落在哪个节点,先写入Buffer,此时的数据不被搜索;同时再写入translog;
②Buffer快慢了或者每隔1秒就会将Buffer数据更新到segment_file(先写入系统缓存再写到磁盘),同时更新commit point.再清空Buffer;
③translog默认每隔30分钟或者足够大了就会触发flush操作,将segment文件写入磁盘,然后清空translog.
10.6 提升集群读取性能的方法
数据建模:
①不要在查询过程中使用script做特殊处理;
②尽量使用filter_Context利用缓存机制,减少不必要的算分;
③结合profile,explain API分析慢查询的问题;
④避免使用*开头的通配符查询
优化分片:
①分片不要过多.20G以内不要加分片;
10.7 提升写入性能的方法
 一般不要随便动es的配置
一般不要随便动es的配置
①客户端,多线程批量写;
②不需要搜索的字段其Index设为false;
③写入时将副本设为0,写完再调整回去;增加refresh interval的时间等;

④一次写入数据量大概在5-15M;
⑤写入端尽量轮询将数据写入不同节点;
11.3.3 利用Logstash同步mysql数据到ES


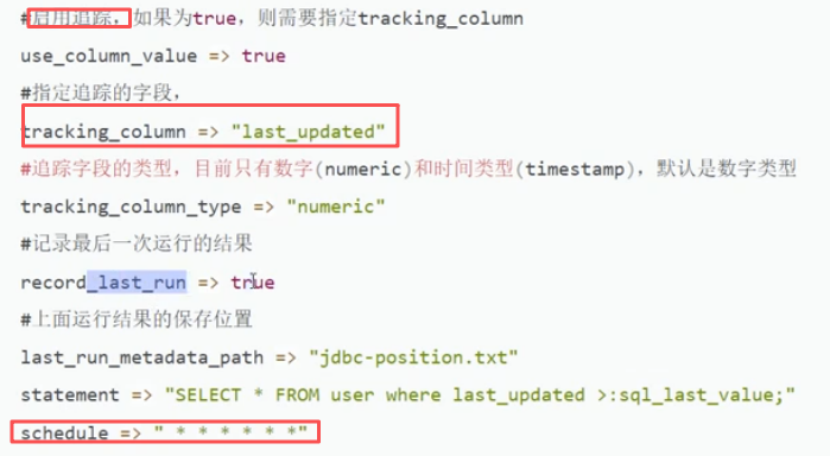
11.3.4 拓展:如何保证Mysql数据库到ES的数据一致性
需求背景是将现有的酒店数据同步到ES中.
1000左右QPS;
搜索响应在500ms以内.
将MySQL数据实时同步到ES;

常用方案分析:
①同步双写:
存在性能瓶颈和数据不一致的风险;
②MQ异步双写方案:
提升了性能,但可能存在消息延迟和增加系统复杂度的问题;
③扫表定时同步:
实时性差;
④监听Binlog同步:
对业务代码没有侵入性,需要额外框架介入,有一定延迟

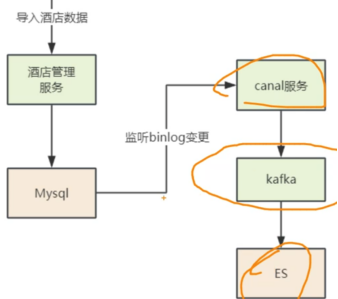
问:
有一个正在运行的项目,数据主要存在MySQL,现在需要引入es来优化查询.要求不能停止服务,如何来同步数据?
答:把MySQL数据分为存量+增量两部分.
选择一个时间点作为同步点,在此之前的数据为存量数据,使用Logstash的JDBC插件同步,
或者新增脚本来批量查询插入;
同步点之后的数据通过MySQL的Binlog同步.比如使用Canal