这篇文章的主题主要解释:NLP 中的 Transformer,为何优于 RNN,以及注意力机制如何提升效果。
我们最近经常听到 Transformer 的相关讨论,这是有充分理由的。在过去几年里,它彻底席卷了自然语言处理(NLP)领域 。Transformer 是一种利用注意力机制(Attention)的架构,能显著提升深度学习机器翻译模型的性能。它最初在论文《Attention Is All You Need》中被提出,并迅速成为大多数文本数据任务的主流领先架构。
此后,包括谷歌的 BERT、OpenAI 的 GPT 系列在内的众多项目都基于这一基础展开,并发布了轻松超越当时最优水平(SOTA)的实验结果。
在本系列文章中,我会讲解 Transformer 的基础知识、整体架构及其内部工作原理。我们将自上而下 地梳理 Transformer 的功能。在后续文章中,我们会深入底层,详细理解系统的运行机制,并深度剖析 Transformer 的核心 ------多头注意力机制(Multi-Head Attention)。
这里是本系列文章的快速概览。我的目标始终是:不仅理解怎么做 ,更要理解为什么要这么做。
-
功能概述 ------ 即本文(Transformer 的用途、为何优于 RNN、架构组成,以及训练与推理过程)
-
工作原理(端到端内部运行机制、数据流向与具体计算,包括矩阵表示)
-
多头注意力(Transformer 中注意力模块的内部原理)
-
注意力为何能提升性能(不只看注意力做了什么,而是它为何效果如此好;如何捕捉句子中单词间的关系)
什么是 Transformer
Transformer 架构非常擅长处理天然具有序列特性的文本数据。它接收一个文本序列作为输入,并输出另一个文本序列,例如:将输入的英文句子翻译成西班牙语。
其核心部分包含编码器层栈 与解码器层栈 。为避免混淆,我们将单独的一层称为编码器(Encoder) 或解码器(Decoder) ,而将多层编码器组成的整体称为编码器栈 ,多层解码器组成的整体称为解码器栈。
编码器栈和解码器栈各自拥有对应的嵌入层 ,用于处理各自的输入。最后,通过一个输出层生成最终结果。
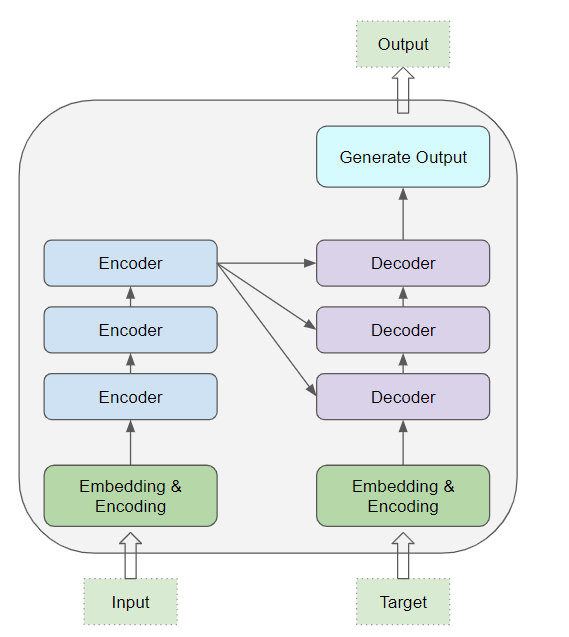
所有编码器彼此完全相同。同样,所有解码器也彼此完全相同。
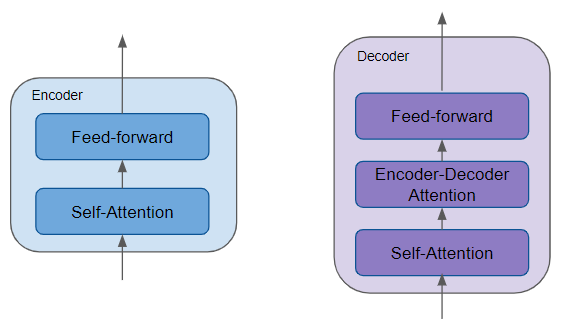
编码器中包含至关重要的自注意力层 ,用于计算序列中不同单词之间的关联关系,同时还包含一个前馈层。
解码器中包含自注意力层、前馈层,以及第二层编码器‑解码器注意力层。
每个编码器和解码器都拥有各自独立的参数权重。
编码器是一个可复用模块,也是所有 Transformer 架构的核心组件。除上述两层之外,它在两层周围还设有残差跳跃连接 ,并搭配两个层归一化层。
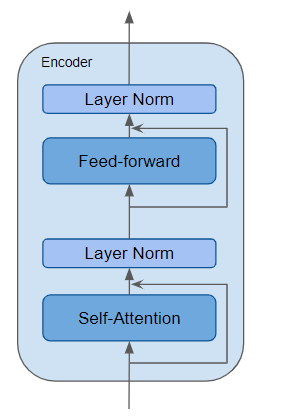
Transformer 架构有很多变体。有些 Transformer 架构完全不含解码器,只使用编码器。
注意力机制的作用是什么?
Transformer 能取得突破性性能,关键在于它使用了注意力机制。
在处理一个单词时,注意力机制能让模型重点关注输入中与该单词密切相关的其他单词。
例如:"Ball"(球)与 "blue"(蓝色的)和 "holding"(拿着)密切相关。而 "blue"(蓝色的)与 "boy"(男孩)则没有关联。

Transformer 架构通过自注意力机制 ,将输入序列中的每个单词与其他所有单词建立关联。
例如,来看两个句子:
The cat drank the milk because it was hungry.
The cat drank the milk because it was sweet.
在第一句中,单词 it 指代 cat ;而在第二句中,it 指代 milk。
当模型处理单词 it 时,自注意力机制会为模型提供更多关于其含义的信息,从而让模型能将 it 与正确的单词关联起来。

为了让模型能够捕捉句子意图和语义中更细微的差别,Transformer 会为每个单词计算多个注意力分数。
例如:在处理单词 it 时,第一个注意力分数会重点关联 cat ,第二个分数则重点关联 hungry 。因此,当模型对 it 进行解码(例如翻译成另一种语言)时,会把 cat 和 hungry 两者的语义信息都融入到译文中。

训练 Transformer
Transformer 在训练阶段 和推理阶段的运行方式略有不同。
我们先来看训练过程中的数据流向。训练数据包含两部分:
-
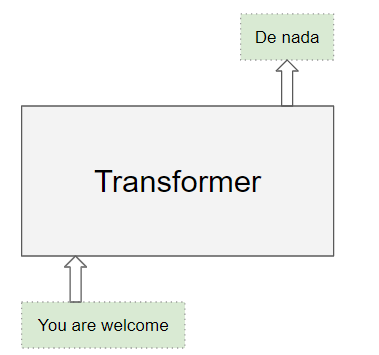
**源序列(输入序列)**例如:翻译任务中的英文句子 "You are welcome"。
-
**目标序列(输出序列)**例如:对应的西班牙语句子 "De nada"。
Transformer 的目标是:同时利用输入序列和目标序列,学习如何输出正确的目标序列。
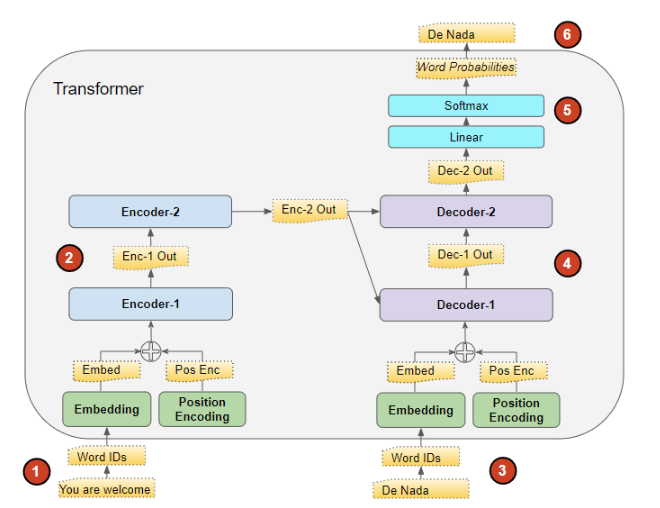
Transformer 按以下方式处理数据:
-
输入序列被转换为嵌入向量 (并加入位置编码),然后送入编码器。
-
编码器栈对其进行处理,生成输入序列的编码表示。
-
目标序列开头添加一个句子起始标记,再转换为嵌入向量(并加入位置编码),然后送入解码器。
-
解码器栈结合编码器栈输出的编码表示进行处理,生成目标序列的编码表示。
-
输出层将其转换为单词概率分布,并得到最终的输出序列。
- Transformer 的损失函数 会将这个输出序列与训练数据中的目标序列进行对比。该损失用于计算梯度,并在反向传播过程中训练 Transformer。
推理阶段
在推理阶段,我们只有输入序列,没有目标序列 可以作为解码器的输入。Transformer 的目标是仅通过输入序列直接生成目标序列。
因此,和序列到序列(Seq2Seq)模型类似,我们通过循环生成输出:将上一个时间步得到的输出序列,作为下一个时间步的输入送入解码器,直到生成句子结束标记。
与传统 Seq2Seq 模型的区别在于:在每个时间步,我们都会将迄今为止生成的整个输出序列重新送入模型,而不仅仅是上一个单词。
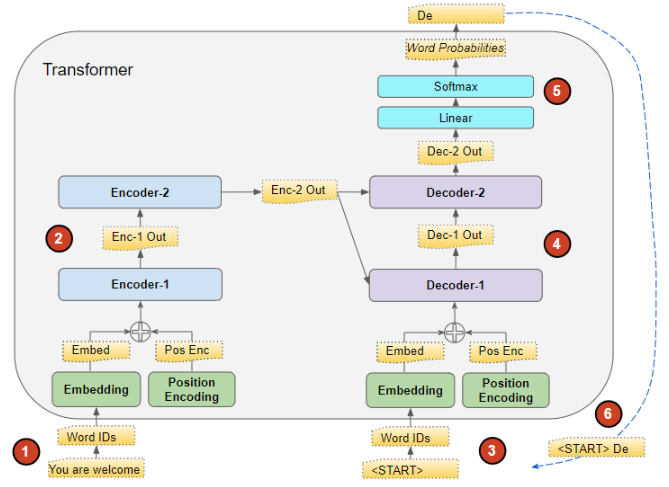
推理过程中的数据流向:
-
输入序列被转换为嵌入向量 (并加入位置编码),然后送入编码器。
-
编码器栈对其进行处理,生成输入序列的编码表示。
-
我们不再使用目标序列,而是使用只包含句子起始标记的空序列。将其转换为嵌入向量(并加入位置编码),然后送入解码器。
-
解码器栈结合编码器栈输出的编码表示进行处理,生成目标序列的编码表示。
-
输出层将其转换为单词概率分布,并生成输出序列。
-
我们取输出序列的最后一个单词作为预测单词。将该单词填入解码器输入序列的第二个位置,此时解码器输入包含句子起始标记和第一个预测单词。
-
回到第 3 步。和之前一样,将新的解码器序列送入模型,然后取输出的第二个单词,追加到解码器序列中。重复这一过程,直到模型预测出句子结束标记。注意:由于编码器序列在每次迭代中都保持不变,因此无需每次都重复执行第 1、2 步。
教师强制(Teacher Forcing)
在训练期间,将目标序列直接送入解码器 的方法被称为教师强制。我们为什么要这么做?这个术语又是什么意思?
在训练时,我们本可以采用和推理时一样的方式:也就是循环运行 Transformer,从输出序列取出最后一个单词,追加到解码器输入中,再送入解码器进行下一轮迭代。最后,当预测出句子结束标记时,用损失函数将生成的输出序列与目标序列对比,以此训练网络。
但这种循环方式不仅会让训练慢得多 ,还会让模型更难训练。模型必须基于可能错误的第一个预测词去预测第二个词,误差会不断累积。
相反,把目标序列直接送入解码器,相当于给模型提供正确提示 ,就像老师在一旁指导。即便模型第一个词预测错了,它依然可以使用正确的第一个词去预测第二个词,避免误差不断叠加放大。
此外,Transformer 可以并行输出所有单词,不需要循环,这极大地加快了训练速度。
Transformer 用来做什么?
Transformer 通用性极强,被用于绝大多数 NLP 任务,例如语言模型、文本分类等。它常被用在序列到序列模型中,应用包括:机器翻译、文本摘要、问答系统、命名实体识别、语音识别等。
针对不同任务有不同变体的 Transformer 架构 ,但基本的编码器层是通用基础模块,再根据具体任务搭配不同的专用 "头"。
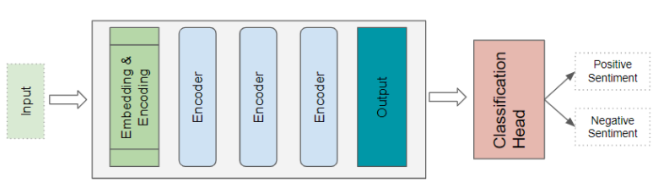
Transformer 分类架构
以情感分析为例:输入一段文本,分类头接收 Transformer 的输出,生成类别标签预测,比如积极情感或消极情感。
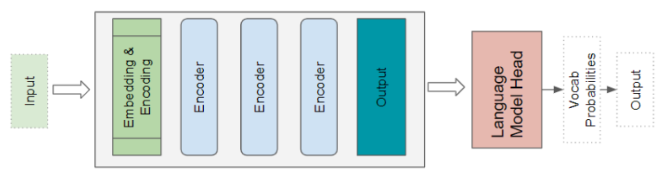
Transformer 语言模型架构
语言模型架构以输入序列(如文本句子)的前半部分 作为输入,通过预测后续可能出现的句子来生成新文本 。语言模型头接收 Transformer 的输出,并为词表中的每个单词计算一个概率。概率最高的单词会被作为句子中下一个单词的预测结果输出。
Transformer为何比 RNN 更优秀?
在 Transformer 出现并取而代之 之前,RNN 及其同类模型 LSTM、GRU 是所有 NLP 任务的事实标准架构。
基于 RNN 的序列到序列模型表现出色,而注意力机制刚被提出时,也是用来提升这类模型的性能。
但它们存在两个局限性:
-
处理长距离依赖非常困难 ------ 对于长句中距离相隔很远的单词之间的关系,模型很难捕捉。
-
它们按顺序逐词处理输入序列,意味着必须完成第 t-1 个时间步的计算,才能开始第 t 个时间步的计算。这会拖慢训练与推理速度。
顺便一提:CNN 可以并行计算所有输出,速度快得多。但它在处理长距离依赖时同样存在局限:在卷积层中,只有处于卷积核大小范围内的邻近区域(图像区域或文本中的单词)才能相互作用。对于距离更远的元素,需要堆叠极深的网络才行。
Transformer 架构同时解决了这两个问题 。它完全抛弃了 RNN,只依靠注意力机制 实现优势:它能并行处理序列中的所有单词,从而大幅提升计算速度。
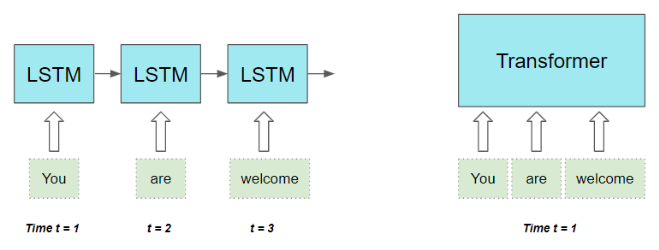
输入序列中单词之间的距离无关紧要。无论是相邻单词,还是相距很远的单词,它在计算依赖关系时效果同样出色。
现在我们已经对 Transformer 有了宏观上的认识,在下一篇文章中,我们将深入其内部功能,理解它的原理细节。