文章目录
最小生成树概念
通过前文的学习知道,一个具有 n 个顶点的连通图,其生成树为包含 n−1 条边和所有顶点的极小连通子图。
对于生成树来说,若砍去一条边就会使图不连通图;若增加一条边就会形成回路。
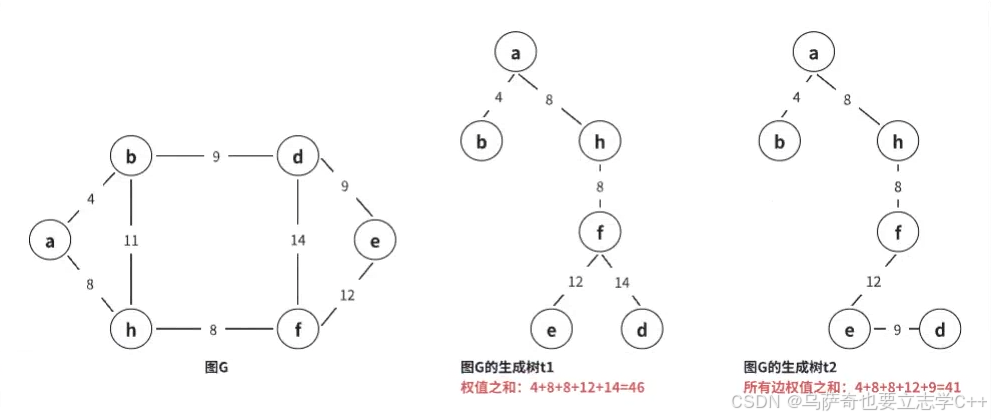
一个图的生成树可能有多个,将所有生成树中权值之和最小的树称为最小生成树。(对于一个图来说,它的最小生成树可能不唯一,但权值一定是最小)
构造最小生成树有多种算法,典型的有普利姆 (Prim) 算法和克鲁斯卡尔 (Kruskal) 算法两种,它们都是基于贪心的策略。下面讲解算法的具体流程。
Prim算法
核⼼:不断加点。
Prim 算法构造最⼩⽣成树的基本思想:
- 从任意⼀个点开始构造最⼩⽣成树;
- 将距离该树权值最⼩且不在树中的顶点,加⼊到⽣成树中。然后更新与该点相连的点到⽣成树的最短距离(到⽣成树的最短距离:该点到当前生成树中任意一点的最小边权值);
- 重复 2 操作 n 次,直到所有顶点都加⼊为⽌。
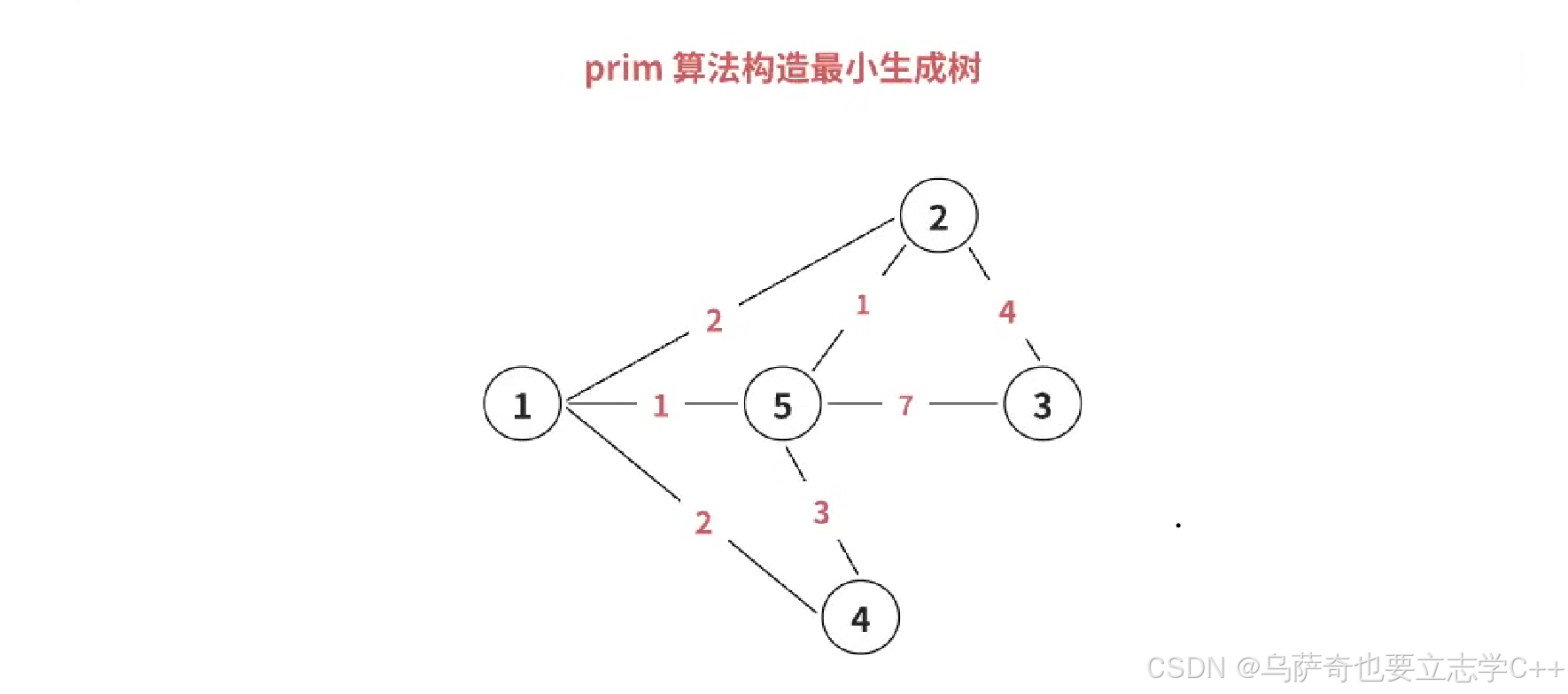
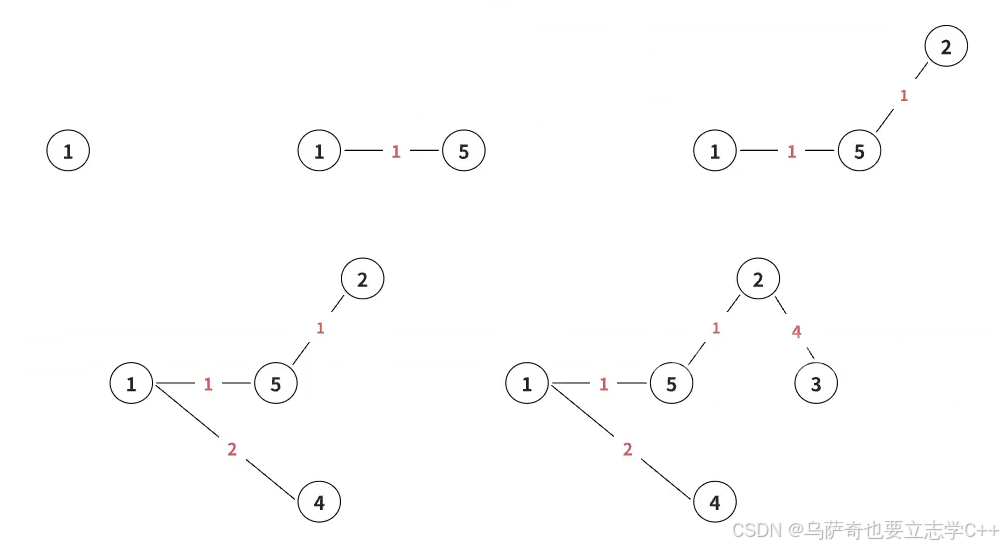
Prim算法的代码实现我们需要两个数组dist和st,int类型的dist数组标记某一个结点到生成树的最短距离,bool类型的st数组标记哪些点已经加入到生成树中。
一开始要先对数组初始化,dist数组所有元素初始化为无穷,表示所有点都不考虑加入最小生成树,st数组所有元素初始化为false,表示一开始没有点加入到生成树中。
代码实现-邻接矩阵存图
下面我们以一道模板题来讲解一下如何用代码实现Prim算法:
【模板】最小生成树

接下来我们先用邻接矩阵来实现。
对于本题小编先说明一点注意事项,对于没有说明输入数据是否会有重边的题目,我们一律认为存在重边,如下图所示。
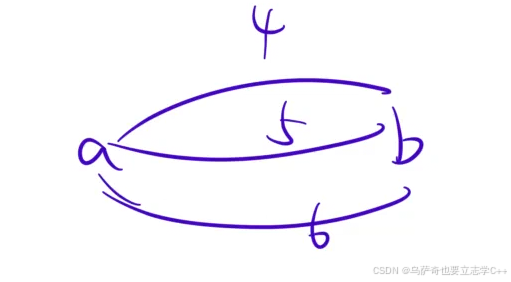
因为我们用邻接矩阵来存储图,那么edges 只能存储一条边的一个权值,那么对于本题来说,因为是求最小生成树,所以我们只存储所有重边中的最小值,实现方法就是对一条边的所有权值取min,那么edges数组就不能初试化为0,这样取min后所有边的权值都是0了,所以本题需要把edges数组初始化为正无穷。
处理完输入后就开始写prim算法内部逻辑:
1、首先把dist数组全部初始化为INF(无穷大),表示没有点加入生成树中,然后把dist1置为0,表示把1结点加入生成树中,从结点1开始构建最小生成树。
注意:此时先不要把st1更新为true,Prim 算法的标准流程就是在每次循环中找到并加入一个新节点,包括起始节点。
接下来循环加入n个点,每次循环需要做下面三个操作:
2、找出所有没加入生成树的结点中距离当前生成树最短的结点
因为距离当前生成树的距离信息都在dist数组中,所以遍历一次dist数组,找出dist数组中的最小值,该值对应的结点就是距离当前生成树最短的结点,用t标记该结点,因为还需要保证该节点没加入生成树,所以还需要判断stt是否是false。
3、因为题目输入的图结构没有说明一定是联通的,所以需要判断t是否和其余结点联通,判断方法是看distt是否是INF,因为t 初始为 0 是因为数组下标从 1 开始,dist0 是无效值;若遍历后 t 仍为 0(即 distt==INF),说明剩余未加入的节点都无法连通到生成树。
4、更新dist数组,方法很简单,枚举除了结点以外的其他结点,将枚举到的结点记为j,分别给j结点的两个值:(distj,edgestj)取min,将取到的min值重新赋给distj。
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 5010, INF = 0x3f3f3f3f;
int n, m;
int x, y, z;
int edges[N][N];
int dist[N]; //标记某个点距离生成树是最短距离
int st[N]; //标记某个点是否被选为生成树
int prim()
{
//初始化
//全部初始化为无穷大,方便
memset(dist, INF, sizeof(dist));
//从第一个点开始构造最小生成树
dist[1] = 0;
int ret = 0; //最小生成树长度之和
//循环加入n个点
for (int i = 1; i <= n; i++)
{
//标记距离结点i(生成树)最短的结点对应的下标
int t = 0;
//1、找出距离生成树最短的结点
for (int j = 1; j <= n; j++)
{
//遍历st数组
if (!st[j] && dist[j] < dist[t])
t = j;
}
//2、判断是否联通,不联通则直接返回INF
if (dist[t] == INF)
return INF;
ret += dist[t];
st[t] = true;
//3、更新最短距离
for (int j = 1; j <= n; j++)
{
dist[j] = min(edges[t][j], dist[j]);
}
}
return ret;
}
int main()
{
//处理输入
cin >> n >> m;
//初始化邻接矩阵全为正无穷,为了后续处理重边
memset(edges, INF, sizeof(edges));
for (int i = 1; i <= m; i++)
{
cin >> x >> y >> z;
//min处理重边
edges[x][y] = min(edges[x][y], z);
edges[y][x] = min(edges[y][x], z);
}
int ret = prim();
if (ret != INF)
cout << ret << endl;
else
cout << "orz" << endl;
return 0;
}代码实现-vector数组存图
实现方式基本和临界矩阵存图一样,唯一需要注意一点,用vector数组存图时不用处理重边,因为用vector数组存图输入重边时会把重边的信息都存入,但用临界矩阵存图输入重边时只会存储重边中最短的边。
因为用vector数组存图有所有重边的信息,所以在prim逻辑更新dist数组时,取min后就会找到最小的重边,自动过滤较大的重边。
cpp
#include <iostream>
#include <algorithm>
#include <cstring>
#include <vector>
using namespace std;
const int N = 5010, INF = 0x3f3f3f3f;
int n, m;
int x, y, z;
vector<pair<int, int>> v[N];
int dist[N]; //标记某个点距离生成树是最短距离
int st[N]; //标记某个点是否被选为生成树
int prim()
{
memset(dist, INF, sizeof(dist));
dist[1] = 0;
//循环加入n个点
int ret = 0;
for (int i = 1; i <= n; i++)
{
//1、找出距离生成树最短的点
int t = 0; //标记距离生成树最短的点
for (int j = 1; j <= n; j++)
{
//遍历st数组
if (!st[j] && dist[j] < dist[t])
{
t = j;
}
}
//2、判断联通性 + 更新ret + 修改st数组
if (dist[t] == INF)
return INF;
ret += dist[t];
st[t] = true;
//3、更新dist
for (auto &p : v[t])
{
int a = p.first; //和结点t相连的结点
int b = p.second;//t->a的边权值
dist[a] = min(dist[a], b);
}
}
return ret;
}
int main()
{
//处理输入
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> x >> y >> z;
v[x].push_back({ y, z });
v[y].push_back({ x, z });
}
int ret = prim();
if (ret != INF)
cout << ret << endl;
else
cout << "orz" << endl;
return 0;
}Kruskal算法
核⼼:不断加边。
Kruskal 算法构造最⼩⽣成树的基本思想:
- 所有边按照权值排序;
- 每次选出权值最⼩且两端顶点不连通的⼀条边(两端顶点不在一个集合中),直到所有顶点都联通。
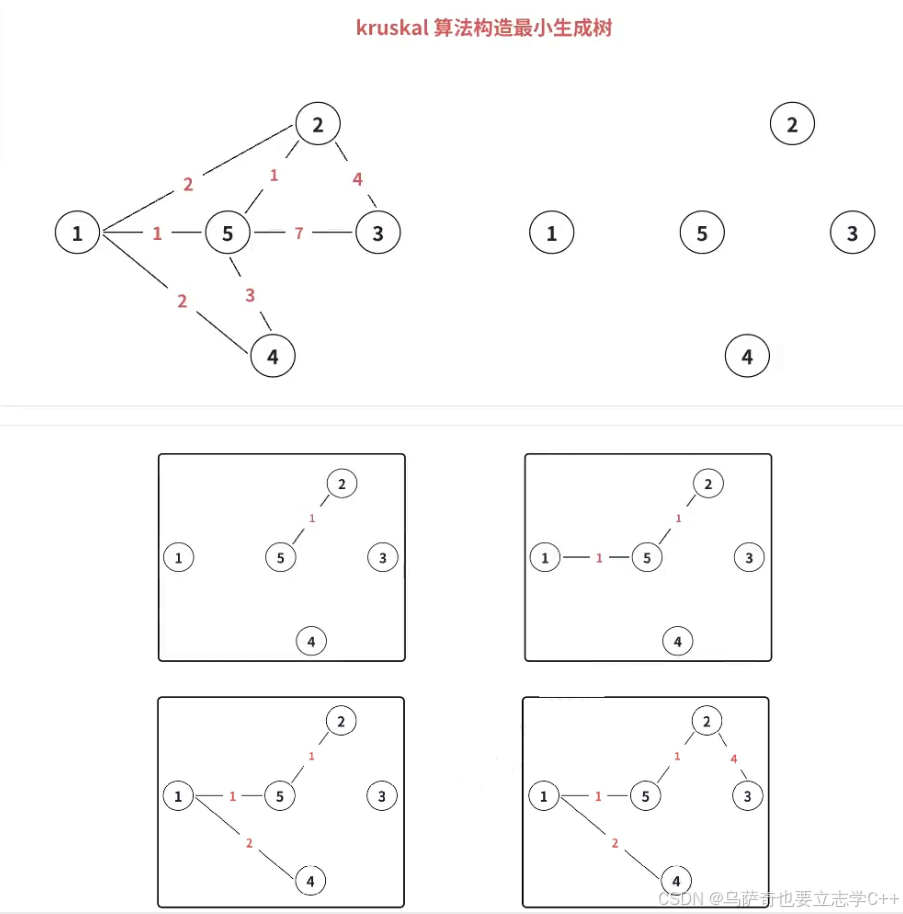
代码实现
因为Kruskal算法只关注边的信息,所以外面不需要存储整个图结构。
因为外面要判断结点是否在同一个集合,所以需要用到并查集。
整体思路很简单,因为本题不用存储图结构,所以用一个结构体数组来存储输入数据即可。
然后初始化并查集:自己是自己的父节点。
接着实现Kruskal算法内部逻辑,第一步先将所有边按从小到大排序,第二步遍历排好序的所有边,若边的两个结点不在同一个集合,则把改边加入最小生成树,并把该边对应的两个结点放入同一个集合。
注意:并查集合并是合并两颗树,而不是合并两个单独的结点,所以合并时要:fafind(a\[i.x)] = find(ai.y); ,而不是 faa\[i.x] = ai.y; !!!
cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5010, M = 2e5 + 10, INF = 0x3f3f3f3f;
struct node
{
int x, y, z;
}a[M];
int n, m;
int fa[N]; //并查集
bool cmp(node &a, node &b)
{
return a.z < b.z;
}
int find(int x)
{
if (fa[x] == x)
return x;
return fa[x] = find(fa[x]);
}
//Kruskal
int kk()
{
//对所有边排升序
sort(a + 1, a + 1 + m, cmp);
//sort(a[1], a[m + 1], cmp);
//遍历所有边,构建最小生成树
int cnt = 0; //标记选择的边数
int ret = 0; //最小生成树各边的长度之和
for (int i = 1; i <= m; i++)
{
if (find(a[i].x) == find(a[i].y))
continue;
fa[find(a[i].x)] = find(a[i].y);
cnt++;
ret += a[i].z;
}
//最后边数合法,返回ret,不合法返回INF
if (cnt == n - 1)
return ret;
else
return INF;
}
int main()
{
//处理输入
cin >> n >> m;
for (int i = 1; i <= m; i++)
{
cin >> a[i].x >> a[i].y >> a[i].z;
}
//初始化并查集
for (int i = 1; i <= n; i++)
{
fa[i] = i; //自己是自己的父节点
}
//输出结果
int ret = kk();
if (ret != INF)
{
cout << ret << endl;
}
else
{
cout << "orz" << endl;
}
return 0;
}以上就是小编分享的全部内容了,如果觉得不错还请留下免费的关注和收藏
如果有建议欢迎通过评论区或私信留言,感谢您的大力支持。
一键三连好运连连哦~~
