目录
- 前言
- 一、二分算法
-
- [1.1 二分查找](#1.1 二分查找)
-
- [1.1.1 牛可乐和魔法封印](#1.1.1 牛可乐和魔法封印)
- [1.1.2 A - B 数对](#1.1.2 A - B 数对)
- [1.1.3 烦恼的高考志愿](#1.1.3 烦恼的高考志愿)
- 结语


🎬 云泽Q :个人主页
🔥 专栏传送入口 : 《C语言》《数据结构》《C++》《Linux》《蓝桥杯系列》
⛺️遇见安然遇见你,不负代码不负卿~
前言
大家好啊,我是云泽Q,欢迎阅读我的文章,一名热爱计算机技术的在校大学生,喜欢在课余时间做一些计算机技术的总结性文章,希望我的文章能为你解答困惑~
一、二分算法
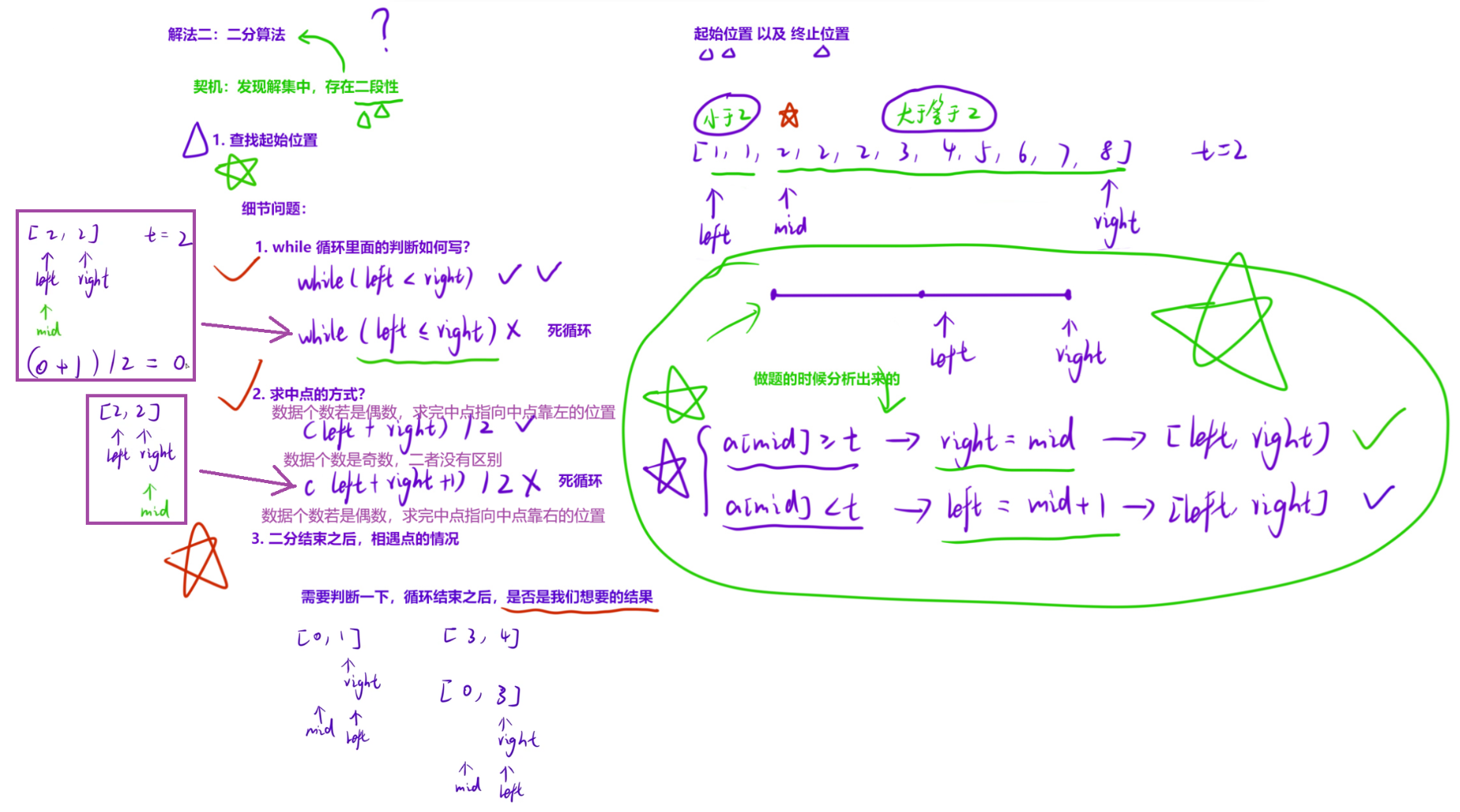
二分算法是我觉得在基础算法篇章中最难的算法,二分算法的原理以及模板其实是很简单的,主要的难点在于问题中的各种各样的细节问题。因此,大多数情况下,只是背会二分模板并不能解决题目,还要去处理各种乱七八糟的边界问题
1.1 二分查找
在排序数组中查找元素的第一个和最后一个位置


算法原理 :
当我们的解具有二段性时,就可以使用二分算法找出答案:
- 根据待查找区间的中点位置,分析答案会出现在哪一侧
- 接下来舍弃一半的待查找区间,转而在有答案的区间内继续使用二分算法查找结果
模板 :
二分的模板在网上至少能搜出来三个以上。但是,我们仅需掌握一个,并且一直使用下去即可

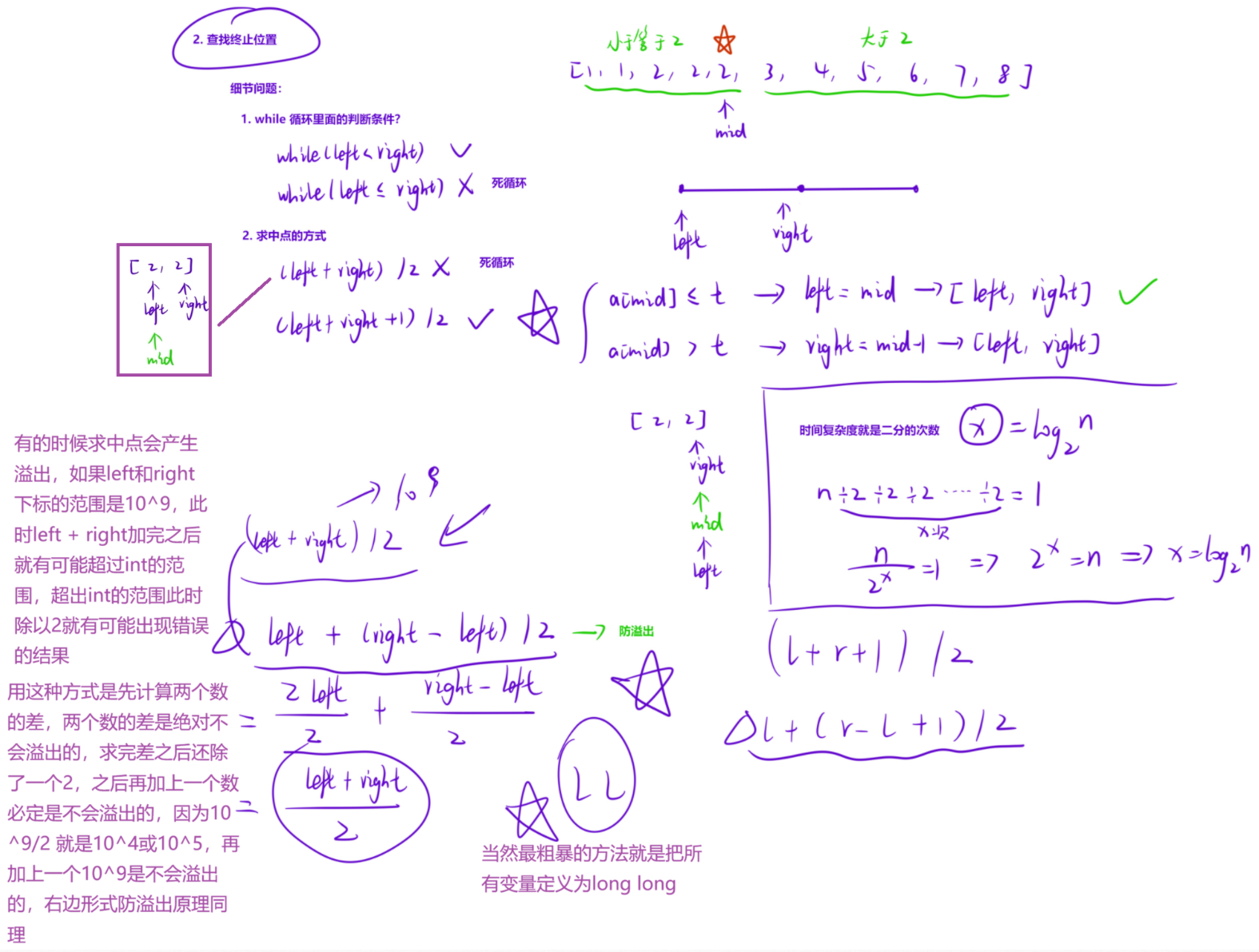
为了防止溢出,求中点时可以下面的方式
- mid = l + (r - l) / 2;
时间复杂度 :
每次二分都会去掉一半的查找区域,因此时间复杂度为logN
模板记忆方式
- 不用死记硬背,算法原理搞清楚之后,在分析题目的时候自然而然就知道要怎么写二分的代码
- 仅需记住一点,if/else 中出现 -1 的时候,求 mid 就 +1 就够了
二分问题解决流程
- 先画图分析,确定使用左端点模板还是右端点模板,还是二者配合一起使用
- 二分出结果之后,不要忘记判断结果是否存在,二分问题众多,一定要分析全面
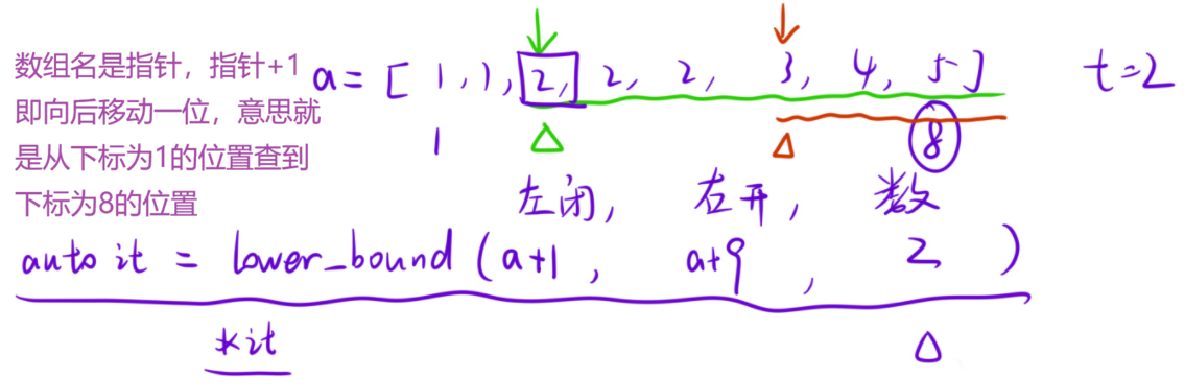
STL中的二分查找
bash
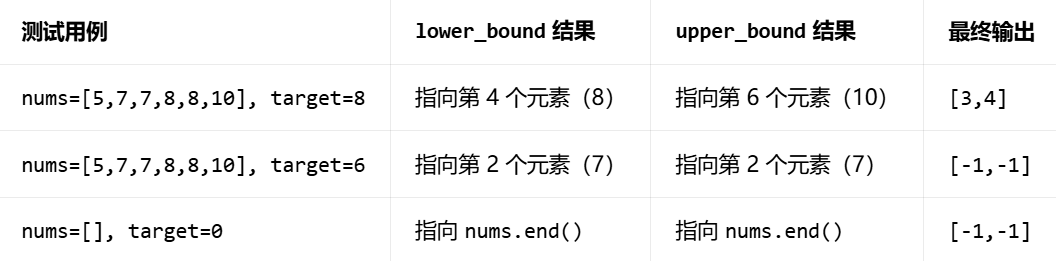
< algorithm >- lower_bound:在 [first, last) 区间内,返回第一个大于等于 target 的元素的迭代器;若所有元素都小于 target,返回 last。时间复杂度:O(logN)
- upper_bound:在 [first, last) 区间内,返回第一个大于 target 的元素的迭代器;若所有元素都小于等于 target,返回 last。时间复杂度:O(logN)
二者均采用二分实现。但是STL中的二分查找只能适用于"在有序的数组中查找",如果是二分答案就不能使用,因此还是需要记忆二分模板
解法一:二分查找模板
cpp
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
int n = nums.size();
//若整个数组没有数,后面会发生越界访问
if(n == 0) return {-1, -1};
//初始化
int left = 0, right = n - 1;
//起始位置
while(left < right)
{
int mid = (left + right) / 2;
if(nums[mid] >= target) right = mid;
else left = mid + 1;
}
//left 或 right所指的位置就有可能是最终结果
if(nums[left] != target) return {-1, -1};
int retleft = left;
//终止位置
left = 0, right = n - 1;
while(left < right)
{
int mid = (left + right + 1) / 2;
if(nums[mid] <= target) left = mid;
else right = mid - 1;
}
//若有起始位置,一定有终止位置
return {retleft, right};
}
};解法二:STL中的二分查找
cpp
class Solution {
public:
vector<int> searchRange(vector<int>& nums, int target) {
//找到第一个 >= target 的迭代器
auto left = lower_bound(nums.begin(), nums.end(), target);
//迭代器越界或指向的元素不是target
if(left == nums.end() || (*left) != target) return {-1, -1};
//找到第一个 > target 的迭代器
auto right = upper_bound(nums.begin(), nums.end(), target);
return {
//转化为下标
(int)(left - nums.begin()), (int)(right - nums.begin() - 1)
};
}
};一、解题思路
结合两个函数的特性,可直接推导目标位置:
- 起始位置:lower_bound 返回的迭代器,若该迭代器指向的元素等于 target,则为起始位置;否则说明数组中无 target,直接返回 -1, -1。
- 结束位置:upper_bound 返回的迭代器减 1,即为最后一个等于 target 的元素位置(前提是起始位置有效)。
二、代码详细解析
起始位置查找:
left_it = lower_bound(nums.begin(), nums.end(), target):在整个数组中二分查找第一个 >= target 的元素。- 判空逻辑:如果 left_it 等于 nums.end()(所有元素都小于 target),或
*left_it != target(找到的是大于 target 的元素),直接返回 -1, -1。
结束位置查找:
right_it = upper_bound(nums.begin(), nums.end(), target):找到第一个 > target 的元素。- 结束位置下标
= right_it - nums.begin() - 1(因为 right_it 是第一个大于 target 的位置,前一个就是最后一个等于 target 的位置)。
迭代器转下标 :通过 迭代器 - 容器.begin() 得到元素的下标,强制转换为 int 以匹配返回值类型。
1.1.1 牛可乐和魔法封印
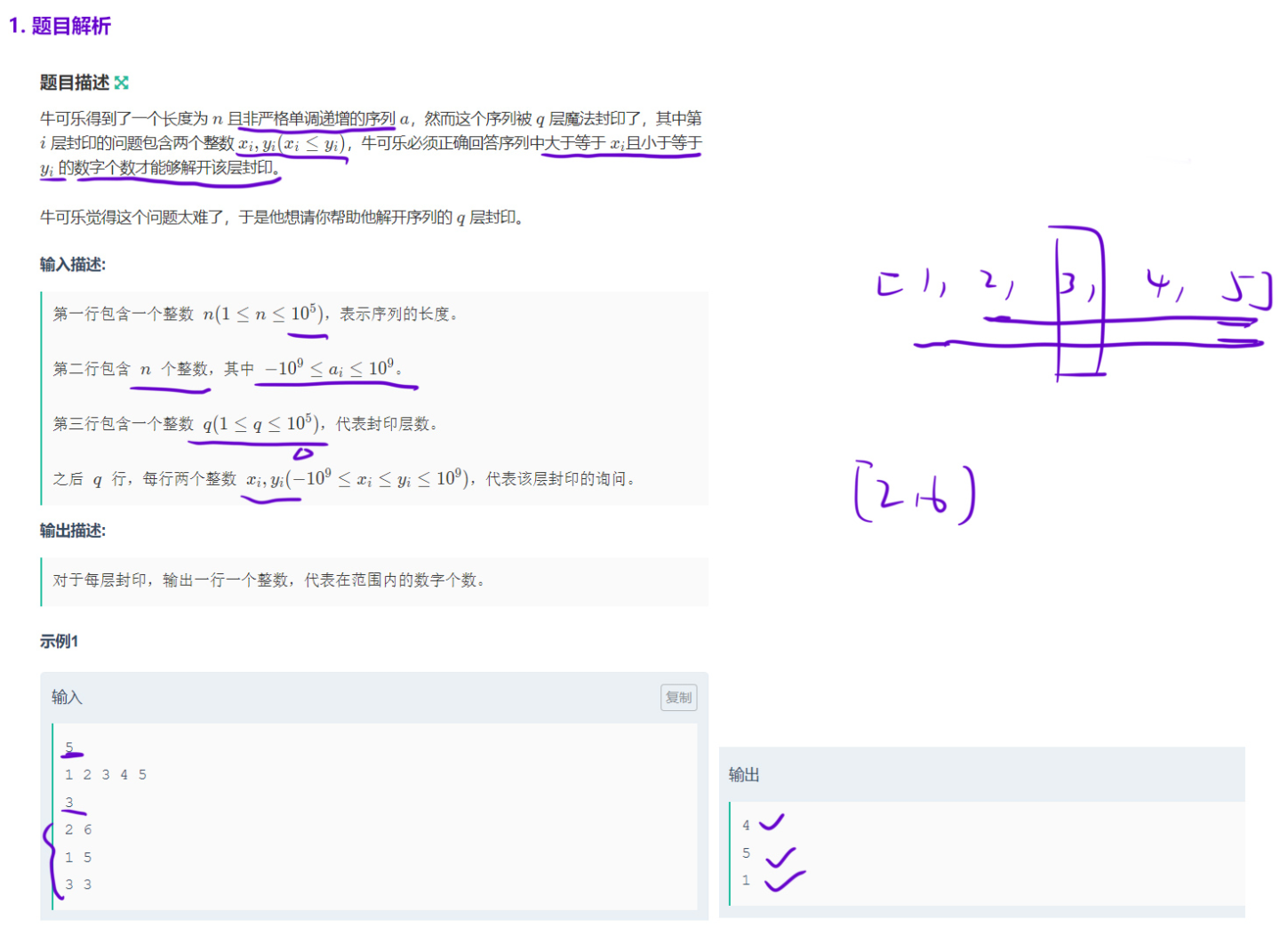

没啥好说的,直接分析上模板
cpp
#include<iostream>
using namespace std;
const int N = 1e5 + 10;
int a[N];
int n;
int binary_search(int x, int y)
{
//初始化
int left = 1, right = n;
// 大于等于 x 的最小元素
while(left < right)
{
int mid = (left + right) / 2;
if(a[mid] >= x) right = mid;
else left = mid + 1;
}
if(a[left] < x) return 0;
int tmp = left;
//小于等于 y 的最大元素
left = 1, right = n;
while(left < right)
{
int mid = (left + right + 1) / 2;
if(a[mid] <= y) left = mid;
else right = mid - 1;
}
if(a[left] > y) return 0;
return left - tmp + 1;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i];
int q; cin >> q;
while(q--)
{
int x, y; cin >> x >> y;
cout << binary_search(x, y) << endl;
}
return 0;
}补充两点:
一:if(a[left] < x) return 0;与if(a[left] > y) return 0;的作用
1. if(aleft < x) return 0;
- 执行时机:第一个二分循环(找≥x 的最小元素)结束后。
- 二分循环的特性 :循环条件是left < right,退出时
left == right,此时left是我们 "认为" 的「≥x 的最小位置」。 - 判断的意义 :如果此时aleft < x,说明整个数组的所有元素都小于 x(比如数组是1,2,3,4,5,x=6),不存在≥x 的元素,自然也不存在 "≥x 且≤y" 的元素,因此直接返回 0。
- 反例验证 (结合题目示例 1):
若输入查询x=6, y=10,数组是1,2,3,4,5:
第一个二分结束后left=5,a5=5 < 6,触发该判断,返回 0(正确,因为没有元素≥6)。
2. if(aleft > y) return 0;
- 执行时机:第二个二分循环(找≤y 的最大元素)结束后。
- 二分循环的特性 :循环条件是left < right,退出时
left == right,此时left是我们 "认为" 的「≤y 的最大位置」。 - 判断的意义 :如果此时aleft > y,说明整个数组的所有元素都大于 y(比如数组是1,2,3,4,5,y=0),不存在≤y 的元素,因此直接返回 0。
- 反例验证 (结合题目示例 1):
若输入查询x=0, y=0,数组是1,2,3,4,5:
第二个二分结束后left=1,a1=1 > 0,触发该判断,返回 0(正确,因为没有元素≤0)。
如果去掉这两行,会出现逻辑错误 :
比如数组1,2,3,4,5,查询x=6, y=10:
- 第一个二分后tmp=5(a5=5 <6);
- 第二个二分后left=5(a5=5 ≤10);
- 计算
left - tmp +1 =5-5+1=1,但实际结果应该是 0,明显错误。
这两行判断正是为了堵住这类 "二分找到的位置不满足条件" 的漏洞,确保只有当「存在≥x 的元素」且「存在≤y 的元素」时,才会计算最终的个数。
二:日常开发中(32 位 int):取值范围在 109 量级(约 ±21 亿);
1.1.2 A - B 数对
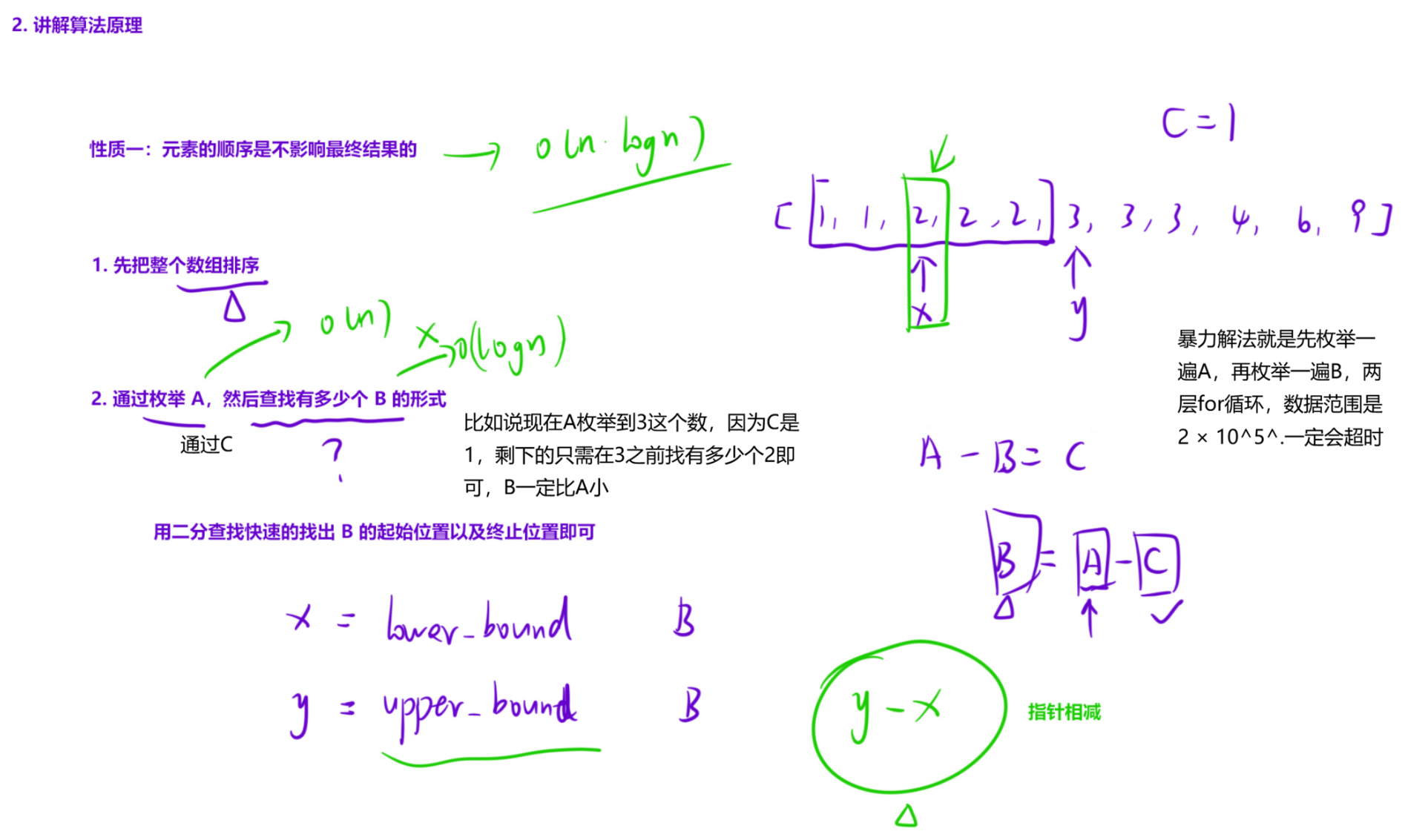
数据范围ai是0到230,加加减减有可能超过int的范围,所以可以用long long
由于顺序不影响最终结果,所以可以先把整个数组排序。
由A-B=C得:B=A-C,由于C是已知的数,我们可以从前往后枚举所有的A,然后去
前面找有多少个符合要求的B,正好可以用二分快速查找出区间的长度。
【STL的使用】
- lower_bound:传入要查询区间的左右迭代器(注意是左闭右开的区间,如果是数组就是左右指
针)以及要查询的值k,然后返回该数组中≥k的第一个位置; - upper_bound:传入要查询区间的左右迭代器(注意是左闭右开的区间,如果是数组就是左右指
针)以及要查询的值k,然后返回该数组中>k的第一个位置;
要点补充:
sort(first, last) 会对 [first, last) 区间内的元素排序,包含 first 指向的元素,不包含 last 指向的元素 。
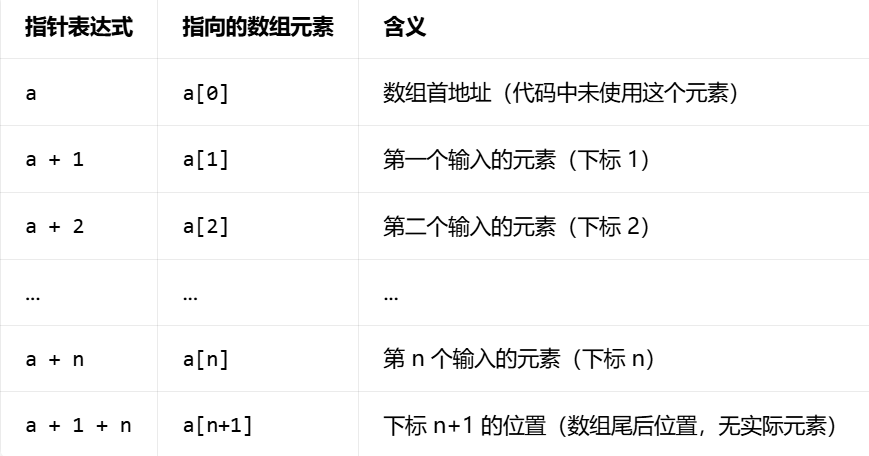
sort(a + 1, a + 1 + n) → 排序范围是 a+1, a+1+n),对应数组元素 a\[1, a2, ..., an,正好是输入的 n 个元素。
i 从 2 开始的核心原因:i=1 时没有可匹配的 B 元素,无法形成数对,遍历无意义。避免一次无效循环,让代码更高效
STL二分算法解法
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 2e5 + 10;
typedef long long LL;
int n;
LL a[N];
LL c;
int main()
{
cin >> n >> c;
for(int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + 1 + n);
LL ret = 0;
for(int i = 2; i <= n; i++)
{
LL b = a[i] - c;
ret += upper_bound(a + 1, a + i, b) - lower_bound(a + 1, a + i, b);
}
cout << ret << endl;
return 0;
}

二分模板解法(不建议)
cpp
#include<iostream>
#include<algorithm>
using namespace std;
const int N = 2e5 + 10;
typedef long long LL;
int n;
LL a[N];
LL c;
int main()
{
cin >> n >> c;
for (int i = 1; i <= n; i++) cin >> a[i];
sort(a + 1, a + 1 + n);
LL ret = 0;
for (int i = 2; i <= n; i++)
{
LL b = a[i] - c;
// 1. 找第一个 ≥ b 的位置(左端点模板),区间 [1, i-1]
LL left = 1, right = i - 1; // 改用LL避免mid溢出
while (left < right) {
LL mid = (left + right) / 2;
if (a[mid] >= b) {
right = mid;
}
else {
left = mid + 1;
}
}
LL first_ge = left; // 第一个≥b的位置
// 2. 找最后一个 ≤ b 的位置(右端点模板),区间 [1, i-1]
left = 1, right = i - 1;
while (left < right) {
LL mid = (left + right + 1) / 2; // 右端点模板必须+1
if (a[mid] <= b) {
left = mid;
}
else {
right = mid - 1;
}
}
LL last_le = left; // 最后一个≤b的位置
// 3. 严谨的匹配判断:区间有效 + 第一个≥b的元素就是b
LL cnt = 0;
if (first_ge <= last_le && a[first_ge] == b) {
cnt = last_le - first_ge + 1;
}
ret += cnt;
}
cout << ret << endl;
return 0;
}说一下最后的if判断作用:
一、前置前提:两个二分的核心结果
在这段代码执行前,我们通过两个模板得到了两个关键位置:
- first_ge:数组 a1\~i-1 中第一个 ≥ b 的元素下标(左端点模板结果)。
- last_le:数组 a1\~i-1 中最后一个 ≤ b 的元素下标(右端点模板结果)。
因为数组是升序排序 的,如果存在等于 b 的元素,这些元素必然是一个连续的区间,且这个区间的左边界就是 first_ge,右边界就是 last_le。
二、代码逐部分拆解
1. 初始化计数:LL cnt = 0;
先默认当前 ai 作为 A 时,没有找到符合条件的 B,计数为 0,避免后续无匹配时出现垃圾值。
2. 核心条件:if (first_ge <= last_le && afirst_ge == b)
这是双重校验 ,缺一不可,目的是排除所有 "假匹配" 情况,只保留真正存在 b 的场景。

3. 计数逻辑:cnt = last_le - first_ge + 1;
当双重校验通过后,说明 afirst_ge \~ last_le 这个连续区间内的所有元素都等于 b(因为数组升序,且左边界≥b、右边界≤b)。
- 公式意义:连续区间的元素个数 = 右边界 - 左边界 + 1(比如下标 1 到 2,是 2 个元素,2-1+1=2)。
- 示例:样例中 i=3,b=1,first_ge=1,last_le=2,则 2-1+1=2,正好是 2 个 1,统计正确。
4. 累加计数:ret += cnt;
将当前 ai 作为 A 时找到的有效 B 的个数,累加到最终结果中。
1.1.3 烦恼的高考志愿
烦恼的高考志愿
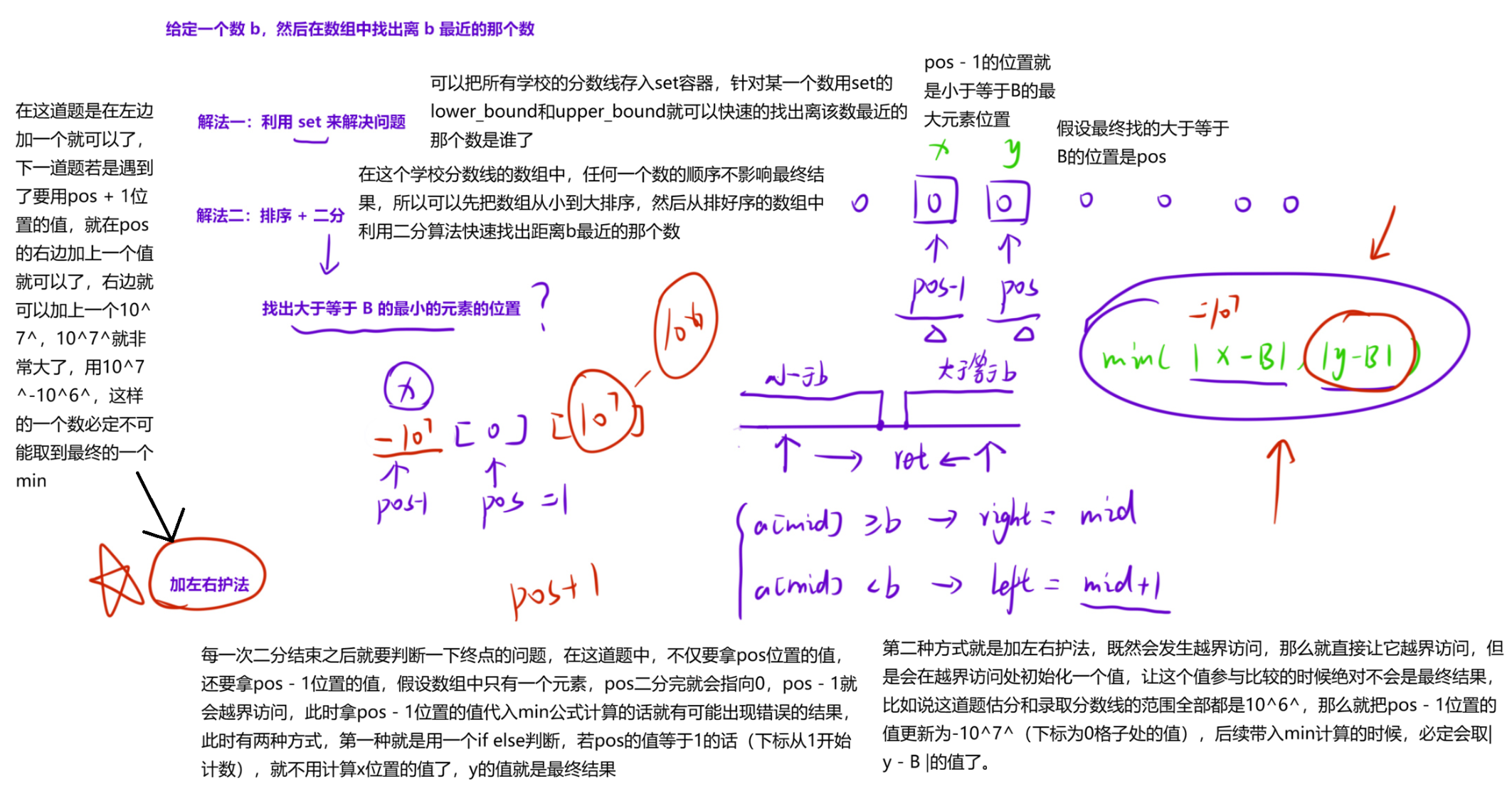
【解法】
先把学校的录取分数「排序」,然后针对每一个学生的成绩,在「录取分数」中二分出≥b的「第一个」位置pos,那么差值最小的结果要么在pos位置,要么在pos一1位置。
取 abs(apos一b)与abs(apos一1一b)两者的「最小值」即可。
细节问题:
- 如果所有元素都大于b的时候,pos一1会在0下标的位置,有可能结果出错;
- 如果所有元素都小于b的时候,pos会在n的位置,此时结果倒不会出错,但是我们要想到这
个细节问题,这道题不出错不代表下一道题不出错。
加上两个左右护法,结果就不会出错了。
cpp
#include <iostream>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 1e5 + 10;
int n, m;
LL a[N];
int find(LL x)
{
int left = 1, right = m;
while(left < right)
{
int mid = (left + right) / 2;
if(a[mid] >= x) right = mid;
else left = mid + 1;
}
return left;
}
int main()
{
cin >> m >> n;
for(int i = 1; i <= m; i++) cin >> a[i];
sort(a + 1, a + 1 + m);
// 加上左右护法
a[0] = -1e7 + 10;
LL ret = 0;
for(int i = 1; i <= n; i++)
{
LL b; cin >> b;
int pos = find(b);
ret += min(abs(a[pos] - b), abs(a[pos - 1] - b));
}
cout << ret << endl;
return 0;
}代码中数据类型用long long的原因:
题目中明确给出了数据范围:
学生数 n 和学校数 m 最大可达 105,学校分数线 ai 和学生估分 bj 最大可达 106,这意味着单个学生的 "不满意度"(即分数线与估分的绝对差)最大可达 106,所有学生的不满意度之和最大可达 105×106=1011
而在 C++ 中,int 类型通常是 32 位,其最大值约为 2.1×109,远小于 1011。如果用 int 存储总和 ret,必然会发生整数溢出,导致结果错误。因此,必须使用 64 位的 long long 类型来存储总和。
ret 变量:用于累加所有学生的不满意度,必须是 long long 类型,否则会溢出。
a 数组和 b 变量:虽然 ai 和 bj 的值(最大 106)用 int 也能存,但将它们定义为 long long 有以下好处:
- 统一数据类型,避免在计算 abs(apos - b) 时出现类型不匹配的问题。
- 提高代码的兼容性,即使未来题目数据范围扩大,也无需修改类型定义。
- 防止在极端情况下(如 ai 和 bj 接近 106),差值计算时出现溢出。
结语
