精炼回答
第一步照着 npm 抄作业------文件托管、版本管理、安全下架、下载统计,这套东西 npm 已经跑了十几年,直接复用就好。 ClawHub 本质上是"AI Agent 的 npm",没有它用户只能手动管理 Skill 文件夹,有了它一条 clawhub install 就能完成发现、安装、更新。
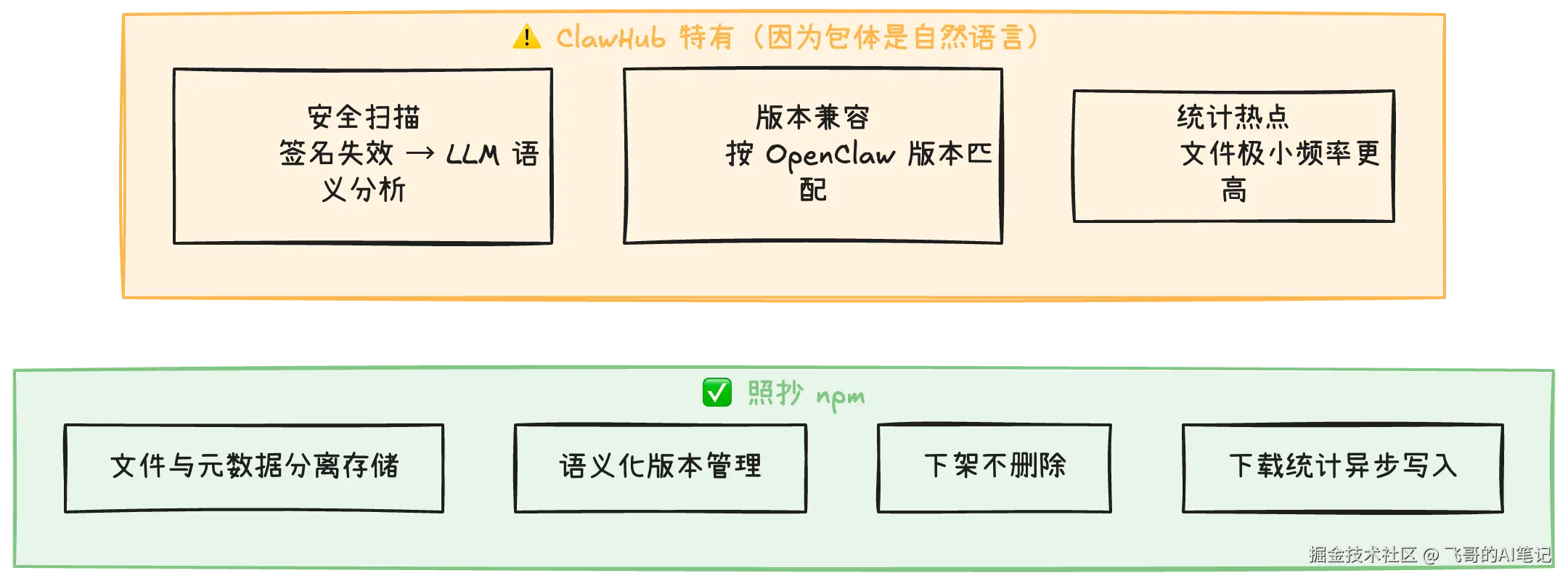
第二步才是真正要动脑子的地方:Skill 的包体不是二进制代码,而是写给 LLM 读的自然语言文件。这一点让四处设计不能照抄 npm------搜索不能只靠关键词,要用向量语义搜索;安全扫描不能靠病毒签名,必须用 LLM 读懂文字判断意图;版本兼容不能直接返回最新版,要按客户端的 OpenClaw 版本匹配;Skill 文件极小所以下载极频繁,统计写入是必选的异步处理而非可选优化。
扩展分析
第一步:先把 npm 能复用的搬过来
ClawHub 和 npm 的通用骨架是一样的,五张核心表直接照抄:
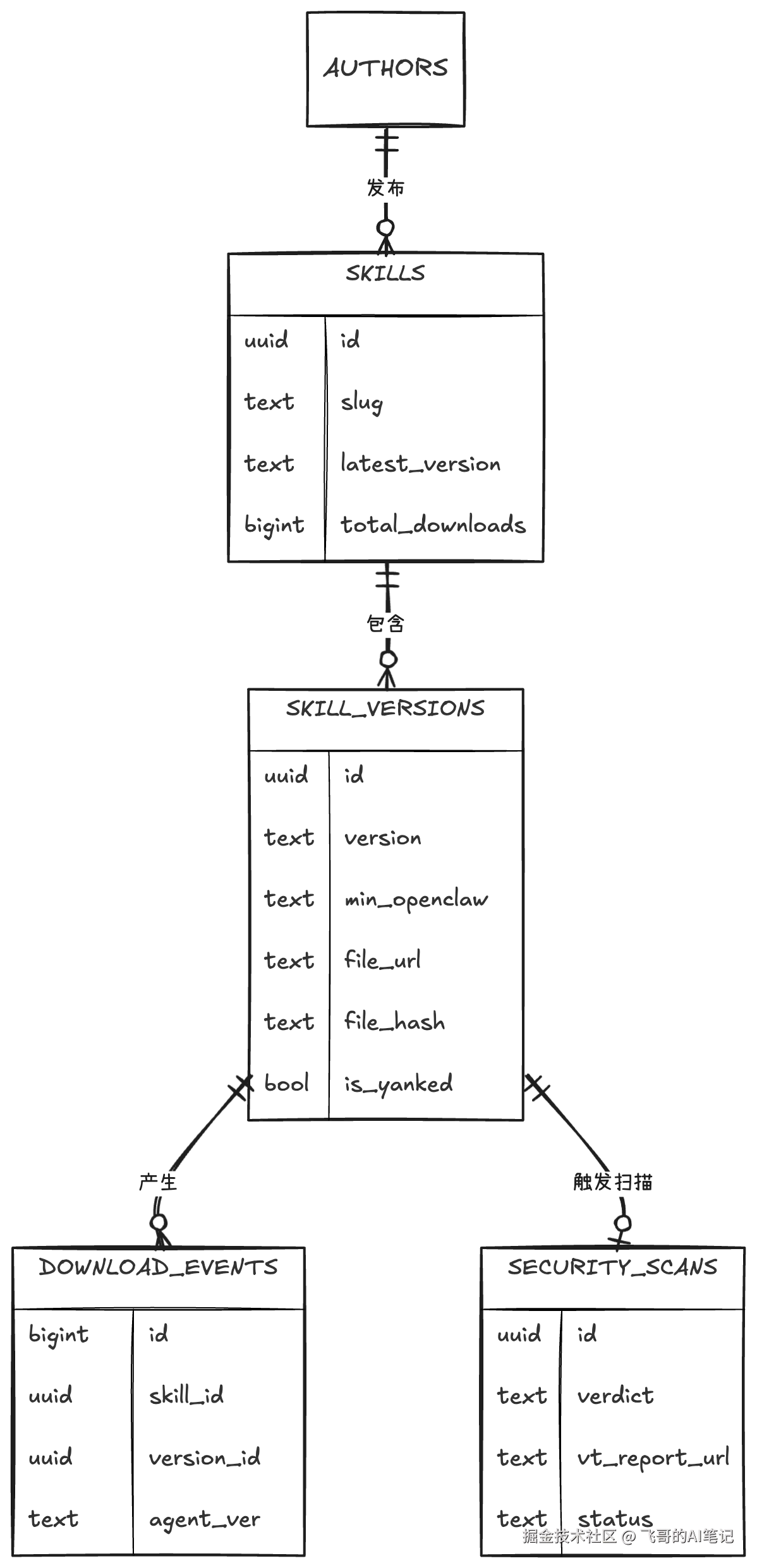
latest_version 是冗余字段:列表页高频查询,每次 JOIN 版本表太慢,发布新版时同步更新------npm 的 dist-tags.latest 是同样的思路。
is_yanked 撤回而非删除------npm 在 left-pad 事件后确立的政策:直接删包会破坏已安装用户的完整性校验,标记撤回、保留文件,已安装用户收到警告但不崩溃。ClawHub 还有一个对应的客户端机制:安装的 Skill 记录在本地的 .clawhub/lock.json(对应 npm 的 package-lock.json),更新时用 file_hash 做内容比对,本地文件和注册表哈希不一致才提示覆盖,而不是无脑覆盖。
ClawHub 特有的字段只有两处:版本表里的 min_openclaw,以及单独抽出来的 SECURITY_SCANS 表。加上搜索层的向量索引,这四处是设计里真正需要想清楚的地方。
第二步:包体是自然语言,四处设计必须重来
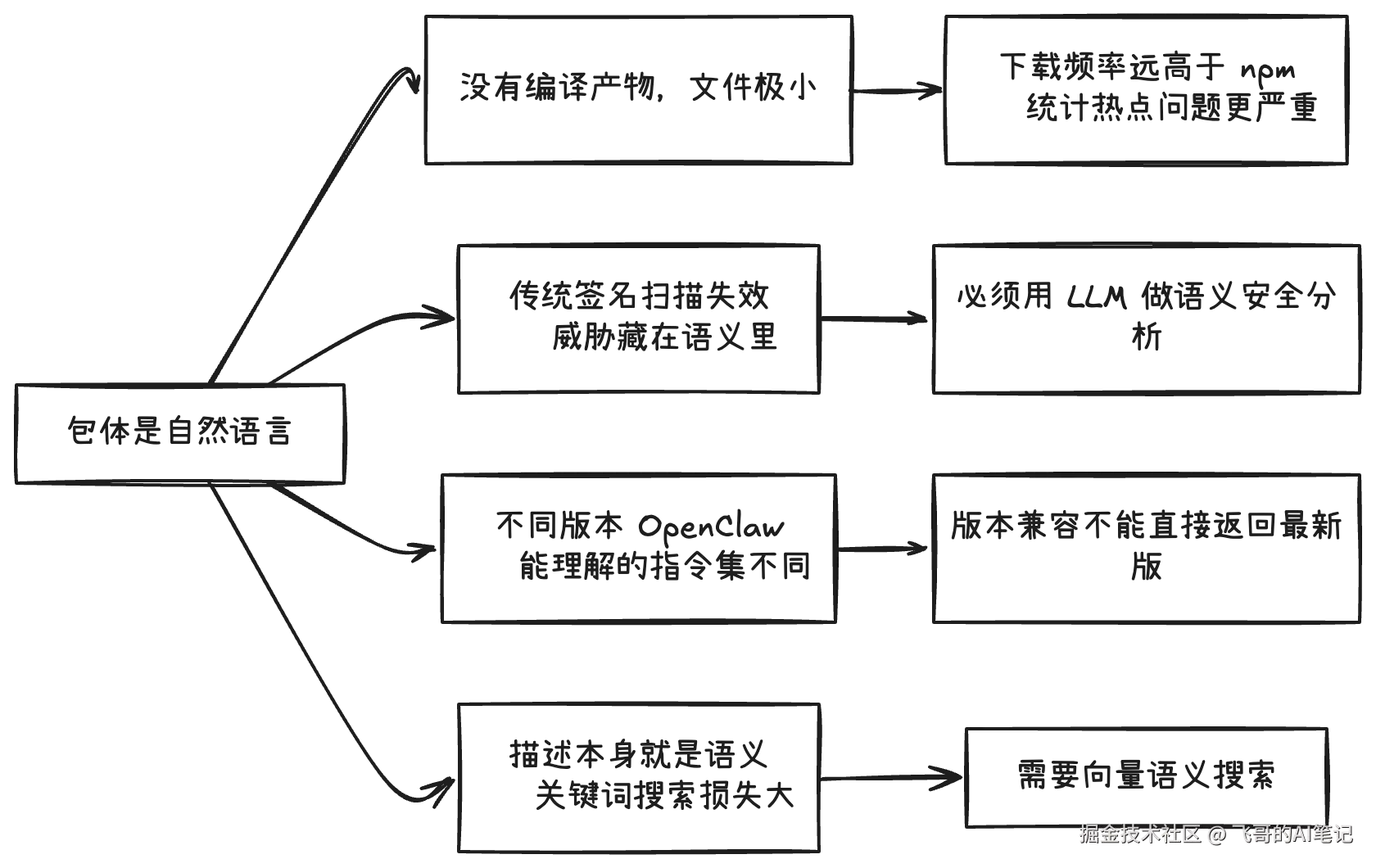
这四条线,对应下面四节。
向量搜索:关键词匹配不了自然语言描述
npm 搜索靠包名和关键词,因为包名通常就是功能的精确描述(lodash、express)。Skill 不一样------它的"功能"写在 SKILL.md 的自然语言描述里,用户搜索时说的是"帮我自动化 shopify 退款流程",而不是包名。
ClawHub 的做法是用 OpenAI embeddings 把每个 Skill 的 description 向量化,存入向量索引;搜索时把查询词同样向量化,做余弦相似度匹配,再用关键词搜索做兜底。这意味着数据库除了关系型表,还需要一个向量索引层。
版本兼容:按客户端版本匹配,不是直接给最新
min_openclaw 对应 VS Code 的 engines.vscode 字段------声明这个版本的 Skill 最低需要哪个 OpenClaw 才能正确理解其中的指令。
客户端安装时带上自己的 OpenClaw 版本号,服务端从新到旧遍历所有未撤回版本,返回第一个 min_openclaw ≤ 客户端版本 的。新版 OpenClaw 拿到最新 Skill,旧版拿到它能跑的最高版本,两边都不出错。
安全扫描:签名不够,要让 LLM 读懂文字
ClawHavoc 事件(2026 年 2 月)是最直接的案例:ClawHub 出现 341 个恶意 Skill,分发 Atomic Stealer 恶意软件。这些包藏的不是病毒代码,而是伪装成正常操作指令的提示词注入------传统杀毒工具完全检测不出来。OpenClaw 随后下架 2419 个可疑包,与 VirusTotal 合作引入 Code Insight 才建立起有效防线。
SECURITY_SCANS 独立成表而不是字段加在版本表上,是因为扫描是异步的、结果有延迟,verdict 和版本的 is_yanked 需要独立更新,混在一起会互相阻塞。
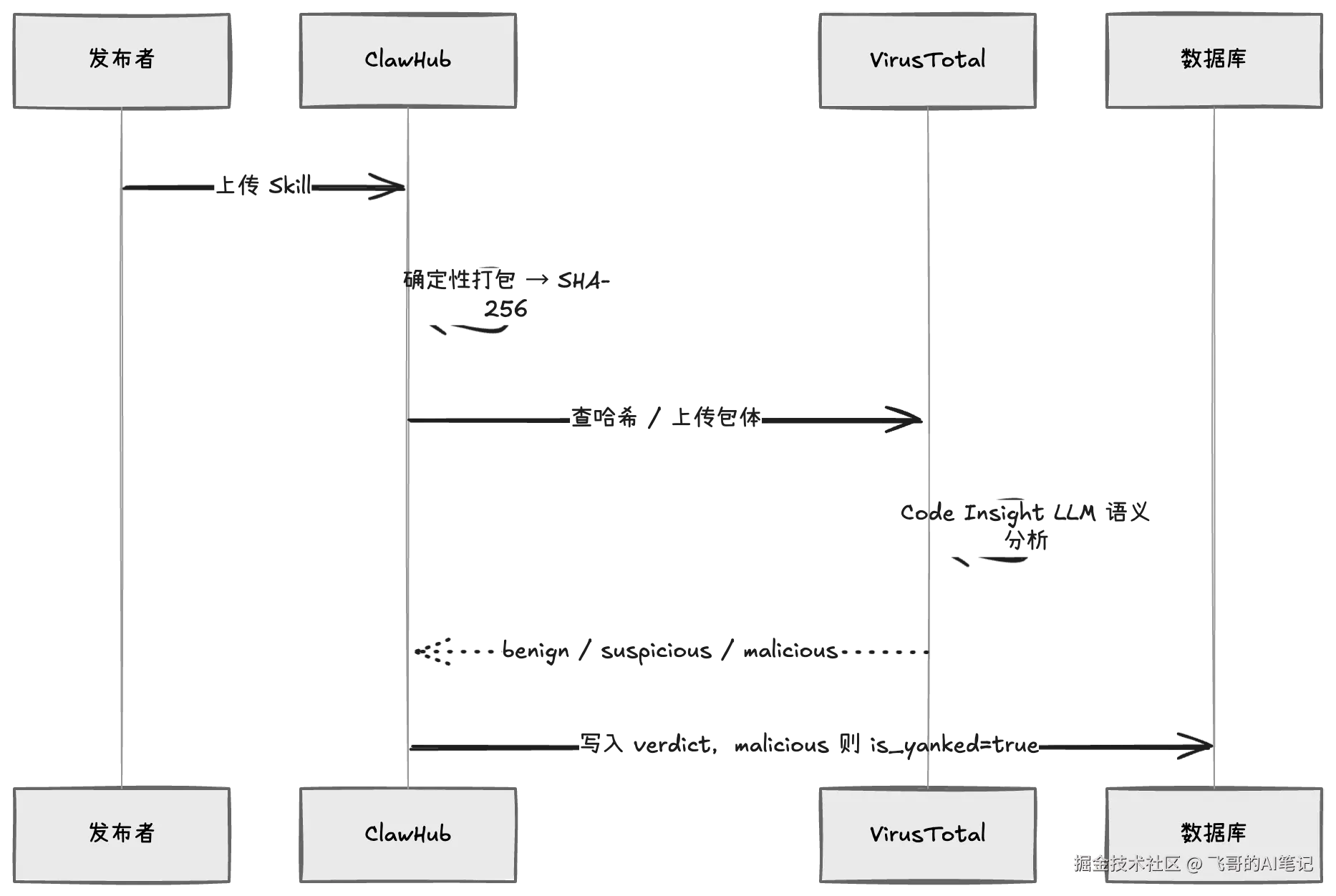
确定性打包(文件排序和时间戳固定)是工程细节:同一份 Skill 每次打包哈希值一致,才能命中 VirusTotal 的哈希缓存,避免重复上传触发重新分析。
下载统计:文件越小频率越高,行锁问题越严重
Skill 只是一个 Markdown 文件,下载成本几乎为零,所以下载频率远高于 npm 包。如果每次下载都同步 UPDATE total_downloads + 1,热门 Skill 的并发请求会争同一行的行锁,把下载接口拖慢。
解法是把统计写入从请求链路里解耦出去:

客户端拿到下载地址的延迟只取决于生成预签名 URL(< 50ms),统计延迟秒级,用户感知不到。DOWNLOAD_EVENTS 不加外键约束、用自增 ID,都是为了最大化这张高频写入表的吞吐。