小T导读:当天文观测进入 PB 级时代,问题不再是"有没有数据",而是"数据该怎么用"。面对高基数、高频次的时域观测数据,传统的数据处理范式已经逼近极限。国家天文科学数据中心(NADC)围绕新一代科研需求,探索"计算向数据靠拢"的存储与分析架构,并在多时标光变曲线生成、高能光子数据库等关键场景中引入 TDengine 时序数据库,构建支撑海量时序数据就地分析的技术体系。本文将系统介绍这一架构的设计思路、核心能力及其在真实科学发现中的实际价值。
合作背景
随着天文观测技术的快速发展,天文数据规模正呈指数级增长。预计到 2030 年底,来自空间与地面的天文观测数据总量将达到约 500 PB,远超人类历史上累计获取的数据规模。面对如此海量的数据,传统的"检索---下载---分析"科研模式已难以为继,受限于网络带宽和计算资源,海量的原始数据无法被高效地传输至客户端进行集中处理。
在此背景下,亟需构建一种支持"计算向数据靠拢"的新型存储与计算架构,即在数据存储层直接完成重采样、聚合等分析操作,仅向用户返回处理后的结果,从而支撑新一代数据密集型科研范式。
时域天文作为未来天文学的重要分支之一,正在产生持续、高频、大规模的时间序列数据。国际上的 LSST、ZTF 以及国内的司天、EP 等望远镜,均属于典型的时域天文观测设施。传统关系型数据库在存储和管理此类时域数据时暴露出明显不足,包括压缩效率低、存储成本高、查询延迟大,以及难以支持降采样、时序分析算符和多维聚合等分析需求。
基于上述挑战,国家天文科学数据中心(NADC)在时域天文数据领域,开展了面向新科研范式的计算与存储架构研究,探索能够支撑海量时序数据高效管理与就地分析的新型技术路径。
为什么选择 TDengine TSDB?
支持高基数、高频次数据的高效管理
时域天文观测对数据管理系统提出了"高基数 + 高频次"的双重挑战,而传统关系型数据库在这一场景下难以满足需求。关系数据库最初面向事务处理(OLTP)场景设计,采用以"行"为单位的存储结构。当用于存储高频时域观测数据时,这种设计暴露出明显瓶颈:由于同一时间段内的不同观测量分散存储在大量行中,在查询某一时间区间内的特定数据列(例如单个天体的光变曲线)时,系统需要频繁进行跨行、跨磁盘位置的随机访问,导致 I/O 开销显著增加,查询效率大幅下降。
而在时域天文数据分析中,典型的访问模式恰恰是针对同一时间区间的一列或多列连续数据进行分析。随着 TESS、EP 等时域天文望远镜引入超大视场设计,每个天体被高频、多次重复观测,高频写入与批量时序查询并存,使关系数据库在存储效率和查询延迟上的问题进一步放大,想要解决这一问题,就需要应用更为专业的时序数据库。
进一步地,将大视场的 TESS 图像与高分辨率的 Gaia 星表进行联合测光,生成 Tess--Gaia 联合光变曲线后,数据同时具备了"高基数"、"高频次"特征。这使时域天文成为一个典型的高基数时序数据场景。所谓高基数,是指时序数据中标签(如天体编号、坐标等)的取值数量极大,会导致标签索引膨胀、元数据规模迅速增长,进而引发表定位困难和查询性能下降等问题。
根据已有行业测试结果,在低基数、高频次的时序场景中,InfluxDB 表现良好;但当基数显著上升时,其性能受限于底层的 LSM-Tree 数据结构而急剧下降。相比之下,TDengineTSDB通过引入 VNode 等分布式存储与调度机制,并定义了一种被称为"超级表"的创新数据模型,从架构上将高基数问题进行拆解和隔离,有效避免了标签爆炸对单表性能的影响,更适合支撑大规模、高基数的时域天文数据管理需求。
支持近数据计算,减少网络传输
在时域天文研究中,科学家经常需要围绕不同的科学目标(如搜索短时标的快速射电暴或长时标的变星周期),对同一组原始观测数据进行不同时间窗口(Time-bin)的重采样分析。
如果沿用传统的"存储---查询---传输---计算"模式,将海量原始时序数据完整传输至应用端再进行分析,不仅会对网络带宽造成持续压力,还会显著增加客户端的内存占用与计算负担,在 PB 级数据规模下几乎不可行。
TDengine TSDB 提供了面向时序数据的强大窗口计算能力,支持在数据库服务端直接完成时间窗口划分(window)、降采样(downsampling)以及多维聚合分析等操作。基于这一能力,可以将光变曲线生成算法中最核心、最耗时的聚合与重采样逻辑下沉至数据库层执行,仅将处理后的轻量级结果数据返回给应用端。
支持大规模表间的多维度聚合分析
为保证数据的高压缩率与高写入吞吐能力,我们采用了 TDengine TSDB 推荐的"一个数据采集点一张表"的建模策略,即一个天体或一个天区一张表。这种设计能够最大化发挥时序数据在时间维度上的连续性优势,但在 NADC 的业务场景下,也意味着需要同时管理上千万甚至上亿张子表,传统数据库在表管理、跨表查询和聚合分析方面难以承受如此规模。
针对这一问题,TDengine TSDB 在数据模型层面引入了"超级表(Super Table)"机制,将具有相同 Schema 的子表在逻辑上归为一个超级表,并允许通过标签(Tag)对子表进行多维度的分类和过滤。
基于超级表模型,我们能够轻松实现跨天体、跨天区的多维度聚合分析,例如"查询误差半径内不同时间范围的光子数"。通过该机制,系统在保持子表物理独立存储所带来的高并发写入与高压缩效率优势的同时,有效解决了海量小表场景下的管理困难和跨表分析性能瓶颈,为大规模时域天文数据的统一分析提供了可行路径。
TDengine TSDB 业务应用
多时标光变曲线生成工具 LCGCT
多时标光变曲线生成工具用于从望远镜原始观测数据出发,采用不同时间间隔进行分箱处理,生成多时间尺度的光变曲线,以满足暂现源搜寻、变源周期提取等不同科学目标的需求。在该系统中,包含三类实体:Source、Instrument 和 Detection。Source 表示一个实际天体,如 Crab、M87 等;Instrument 表示能够产生独立时序观测数据的望远镜或仪器,当同一望远镜配置有多个滤光片时,不同滤光片在系统中分别作为独立的 Instrument 存在;Detection 表示一次具体的观测行为,即某一 Instrument 对某一 Source 的观测记录,包含时间、流量、曝光时间等观测信息。从数据关系角度来看,Source 与 Instrument 之间为多对多关系,二者通过 Detection 进行关联。
Tess--Gaia 联合光变曲线是一类典型的高基数、高频次数据,覆盖上千万个天体。为获得更高的数据压缩率与检索效率,我们选用 TDengine TSDB 作为底层存储引擎,并采用"一个仪器对一个源的观测存储一张表"的方案,将 Detection 数据统一存储于同一超级表中,并以 SourceId 和 InstrumentId 作为标签进行子表划分,最终分布式存储于 TDengine TSDB 集群中。
这种设计不仅极大地降低了标签数据的冗余存储,还保证了同一天体数据的物理连续性,从而实现了高达 75% 的数据压缩率。同时,借助 TDengine TSDB 强大的集群支持能力,我们能够轻松实现数据的横向扩展,高效应对千万级天体表的并发写入与查询需求。
在查询性能方面,TDengine TSDB 的 Vnode(虚拟数据节点)机制在该场景中发挥了关键作用。每个子表的数据被映射到特定的 Vnode 中进行管理,使得查询请求可以被拆分并由多个 Vnode 并行处理,充分利用多核计算资源,显著缩短查询响应时间。借助"一个数据采集点一张表"的数据模型,单个子表(光变曲线)的数据在同一 Vnode 内顺序存储,时间范围查询主要以顺序读为主,相比随机读可获得数量级上的性能提升。
此外,TDengine TSDB 针对时序数据构建了高效的时间索引结构。在定位具体子表(光变曲线)时,系统可在索引文件中快速锁定可能包含目标数据的数据块,避免全表扫描,尤其适合以时间戳为核心条件的过滤查询。对于降采样等常见聚合分析场景,TDengine TSDB 还支持使用预计算结果直接完成聚合计算,无需反复读取和解压原始数据,进一步降低 I/O 开销并提升查询效率。
在天文数据分析过程中,天文学家经常需要使用不同时标(Time-bin)的光变曲线,如果采用传统方式,将海量原始数据全部通过网络传输到应用端再进行重采样,无疑是对带宽和计算资源的巨大浪费。为此,我们基于泊松统计模型,利用原始观测的流量、误差与曝光时间,推导并实现了反推有效面积以及并道光变曲线流量与误差的计算方法。
在此基础上,依托 TDengine TSDB 在存储端提供的窗口计算与聚合分析能力,将光变曲线生成过程中的核心处理逻辑(如时间重采样与降采样)直接转移至数据库层执行。通过 LCGCT 工具,用户无需查询完整原始数据集,即可在数据端按需生成任意时标的光变曲线,仅将处理后的结果数据返回至应用端。这种方式显著减轻了网络传输负担,极大地提升了科学发现的效率。

数据库端降采样以减少网络传输
高能光子数据库 XPhotonBank
传统的X射线天文数据往往以预处理后的图像或固定时标的光变曲线形式存在,但这限制了科学家对瞬变天体的精细化研究。从数据科学视角来看,这些数据都是光子事例数据的"派生"数据,或者说,光子事例数据是更高维的数据,因而也蕴含着更丰富的特征。为了支持在任意观测时段和天区位置灵活生成可定制时间窗口的图像、光变曲线和能谱,以及从更高维度研究各类天体的特征,我们需要直接存储最原始的光子事例(Photon Events)数据。
光子事例数据同样是一个典型的高基数、高频次场景 。EP 卫星每年观测到的光子数接近 200 亿个,为了实现对全天球光子数据的高效空间索引,我们采用了"一个天区一张表"的存储策略,将天空按照 HEALPix 网格划分为数千万的细粒度网格,每个网格对应 TDengine TSDB 中的一张子表。
在光子级多时标光变曲线生成场景中,多维度数据聚多维度的数据聚合操作尤为普遍。在实际科学分析中,单个天体的观测往往受到仪器点扩散函数(PSF)和定位误差的影响,其对应的光子事例数据通常分布在相邻的多个天区网格中。依托 TDengine TSDB 的超级表数据模型和强大的多维度聚合能力,系统能够根据源的中心坐标和误差半径,自动定位并筛选出覆盖该区域的多个天区子表,并在服务端对这些子表中的光子数据进行实时聚合,从而直接在数据库层完成跨子表计算,生成任意时标的光子级别的光变曲线,实现长期光子级光变曲线的秒级响应。
科学发现
EP251020a
EP251020a 是使用以上系统发现的重要成果之一。该源在 EP 宽视场 X 射线望远镜(WXT)中的定位坐标为赤经 74.292 度、赤纬 -11.746 度(J2000 历元),半径方向不确定度为 3.1 角分(90% 置信度,含统计与系统误差),与星系 LEDA 962438 位置一致。
研究团队利用 FXT 和 Swift/XRT 进行的后续观测,进一步将 X 射线源精确定位到宿主星系的核区;同时,UVOT 观测到其亮度较历史记录显著增强,这些证据共同支持该事件属于潮汐瓦解事件。在 2025 年 9 月底,该源即通过光子数据库探测到信号,从而引起科研人员的注意。20 多天后,该天体接近本次爆发峰值,才被单次观测处理流水线正式探测到并被命名为 EP251020a。
XPhotonBank 的预警能力成功捕获了原本可能遗漏的早期辐射阶段,显著延长了观测的时间基线并提前引起科研人员注意,为该源证认为为罕见的潮汐瓦解事件候选体争取了宝贵的观测数据和后随观测支持。
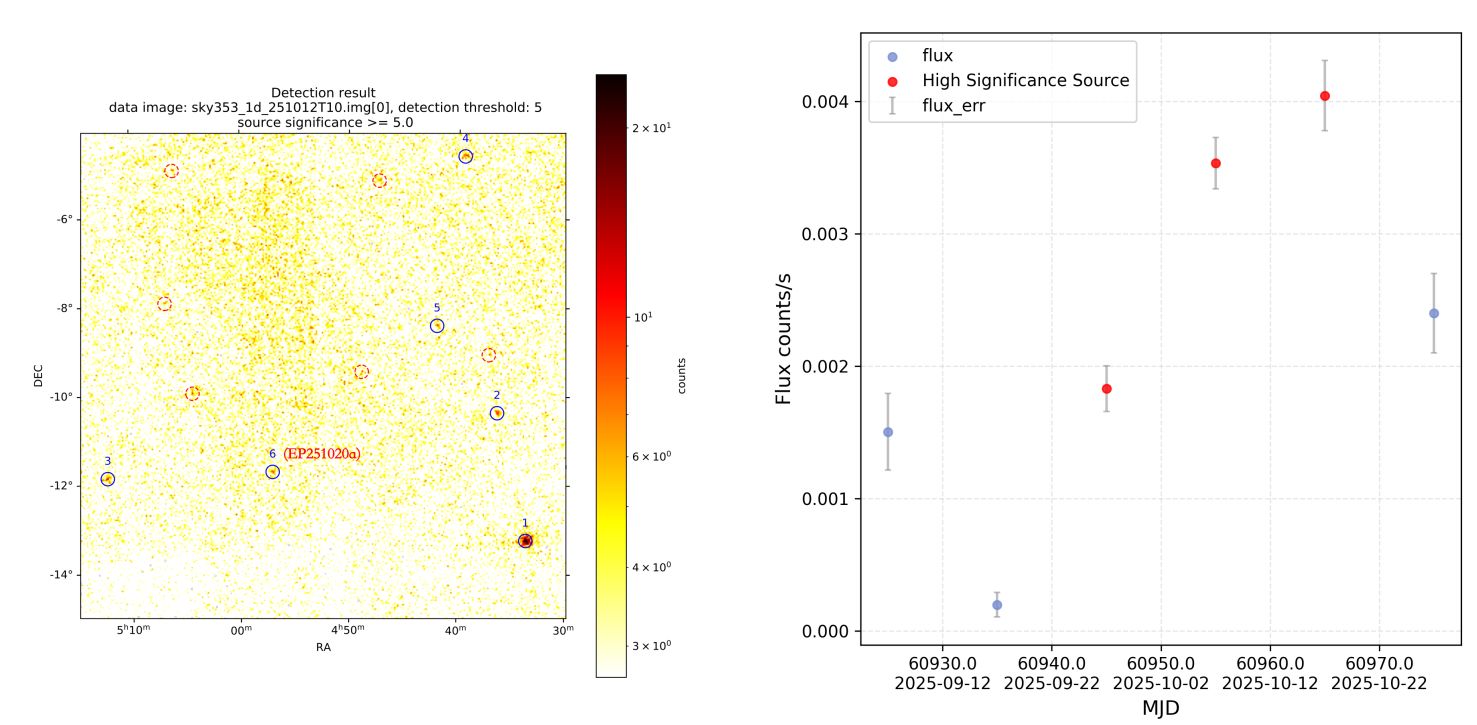
上图 (a)由 XPhotonBank 生成的 EP251020a 位置区域的叠加 X 射线图像,显示了该暂现源在单次观测触发前已出现。(b) EP251020a 的 10 天分段光变曲线,显示该暂现源在 2025 年 9 月下旬已开始活动。
EP J012607.7+121047
EP J012607.7+121047 是 XPhotonBank 发现的另一例暂现源,位于赤经 21.510 度、赤纬 12.186 度(J2000 历元),定位不确定度为 2.5 角分。根据 WXT 能谱推得的 0.5--4 keV 波段流量约为 3.5×10-¹² erg·s-¹·cm-²,低于 1000 秒曝光时长的灵敏度极限,因此未被标准单次观测流水线探测到。
而 XPhotonBank 的叠加分析在 2025 年 8 月探测到该源并触发了 FXT 的后续观测,确认其在空间位置上与候选激变变星 AT2023row(即 Gaia23cer)相符。这一发现与后续验证,充分体现了 XPhotonBank 在从叠加数据中挖掘微弱暂现源方面的有效性。如图中所示,XPhotonBank 完整记录了该暂现源从 2025 年 8 月至 12 月的爆发过程。
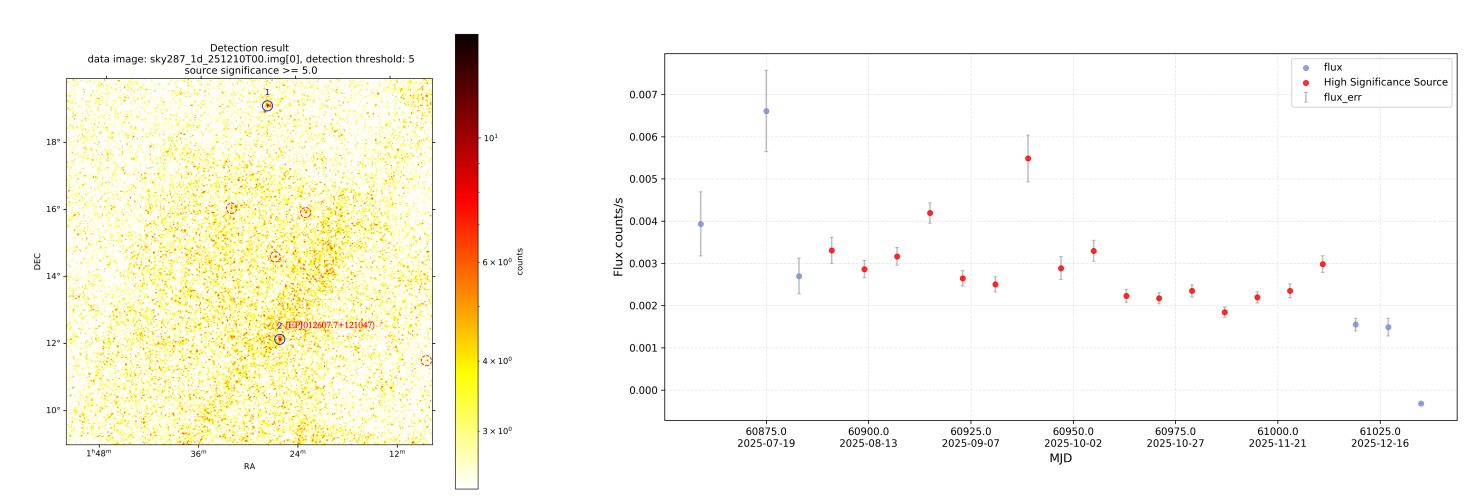
上图 (a) 由 XPhotonBank 生成的 EP J012607.7+121047 位置区域 1 天叠加 X 射线图像,显示该暂现源可在叠加数据中出现。(b) 8 天时间窗口的叠加光变曲线,表明 XPhotonBank 能够完整观测到该暂现源从 2025 年 8 月至 12 月的整个爆发过程。
关于 NADC
国家天文科学数据中心是由科技部、财政部认定的国家科技资源共享服务平台,属于基础支撑与条件保障类国家科技创新基地,负责汇交管理、整编、集成天文学科领域数据,制定相关标准规范,建设天文数据资源体系,优化完善天文数据开放共享服务平台,提供多元数据服务,建立数据挖掘分析与学科应用平台,促进天文学科领域科学数据的深度应用,开展科学传播和国际合作交流,努力把自身打造成为优秀的国家科学数据中心和国际知名的天文科学数据中心,成为引领天文学进入数据密集型科学发现新时代的重要资源平台和技术力量。