多模态大模型学习笔记(十四)------Transformer学习之Self-Attention
Self-Attention(自注意力机制)是Transformer架构的核心引擎,它解决了RNN类模型"长距离依赖建模困难"和"并行计算效率低"的痛点,让模型能同时捕捉序列中任意两个Token的语义关联。
本文将结合核心示意图,由浅入深地拆解Scaled Dot-Product Attention(缩放点积注意力)、Mask机制、Multi-Head Attention(多头注意力)的核心逻辑,配套修正后的数学原理与可运行代码实现,彻底吃透Self-Attention的工作机制。
1. 核心概念铺垫:Q、K、V的通俗隐喻与本质
在进入技术细节前,先理解Q、K、V的核心角色,这是掌握Self-Attention的关键。
1.1 通俗隐喻(地图-经纬度-物品)

| 概念 | 隐喻含义 | 核心作用 |
|---|---|---|
| Query(Q,查询) | 一张模糊的地图 | 代表当前Token想要"找什么",是发起检索的"需求向量" |
| Key(K,键) | 准确的经纬度地址 | 代表序列中每个Token"提供什么",是被检索的"特征向量" |
| Value(V,值) | 某空间内的贵重物品 | 代表序列中每个Token的"核心语义内容",是最终要提取的信息 |
1.2 技术本质
在Transformer中,Q、K、V并非天然存在,而是通过输入嵌入向量(Token Embedding + 位置编码) 经过3个独立的可学习线性层投影得到:
Q=X⋅WQ,K=X⋅WK,V=X⋅WV Q = X \cdot W_Q, \quad K = X \cdot W_K, \quad V = X \cdot W_V Q=X⋅WQ,K=X⋅WK,V=X⋅WV
其中:
- X∈RB×L×DmodelX \in \mathbb{R}^{B \times L \times D_{\text{model}}}X∈RB×L×Dmodel:输入嵌入向量(BBB为批次大小,LLL为序列长度,DmodelD_{\text{model}}Dmodel为模型隐藏层维度);
- WQ,WK,WV∈RDmodel×DkW_Q, W_K, W_V \in \mathbb{R}^{D_{\text{model}} \times D_k}WQ,WK,WV∈RDmodel×Dk:可学习的投影矩阵(DkD_kDk为单个注意力头的维度)。
2. Scaled Dot-Product Attention:自注意力的基础单元
Scaled Dot-Product Attention(缩放点积注意力)是Self-Attention的最小可执行单元。
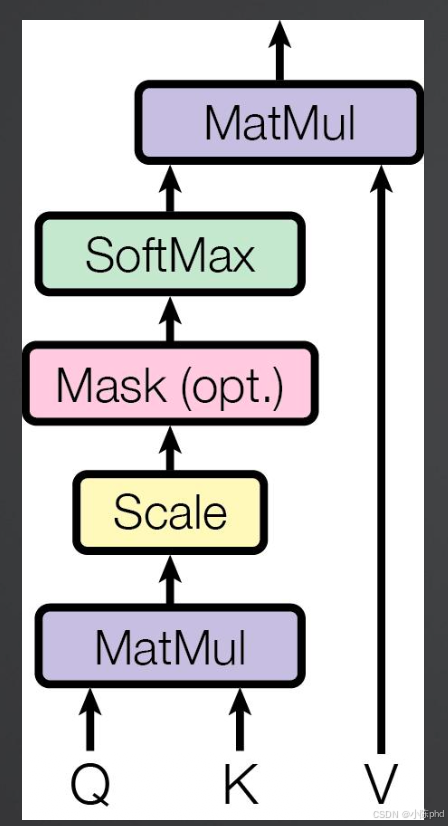
2.1 核心流程
按执行顺序拆解每一步的作用:
- MatMul(Q×Kᵀ) :计算Q与每个K的相似度(注意力分数),衡量当前Token与序列中其他Token的关联程度;
- Scale(缩放) :除以Dk\sqrt{D_k}Dk ,解决高维向量点积导致的"梯度消失"问题;
- Mask(可选,遮罩):对无效位置(如padding填充位、生成式任务的未来Token)赋值为负无穷,避免模型关注这些位置;
- SoftMax :将注意力分数归一化为0~1的概率分布,总和为1,代表对每个Token的"关注权重";
- MatMul(权重×V) :用归一化的注意力权重对V加权求和,得到融合了全局语义的当前Token表示。
2.2 数学原理

(1)核心公式
Scaled Dot-Product Attention的完整数学表达式为:
Attention(Q,K,V)=SoftMax(QKTDk+M)V \text{Attention}(Q, K, V) = \text{SoftMax}\left( \frac{QK^T}{\sqrt{D_k}} + M \right) V Attention(Q,K,V)=SoftMax(Dk QKT+M)V
各参数维度说明:
- Q∈RB×Lq×DkQ \in \mathbb{R}^{B \times L_q \times D_k}Q∈RB×Lq×Dk:查询序列矩阵(LqL_qLq为查询序列长度);
- K∈RB×Lk×DkK \in \mathbb{R}^{B \times L_k \times D_k}K∈RB×Lk×Dk:键序列矩阵(LkL_kLk为键序列长度,Self-Attention中Lq=LkL_q=L_kLq=Lk);
- V∈RB×Lk×DvV \in \mathbb{R}^{B \times L_k \times D_v}V∈RB×Lk×Dv:值序列矩阵(通常Dk=DvD_k=D_vDk=Dv);
- M∈RB×Lq×LkM \in \mathbb{R}^{B \times L_q \times L_k}M∈RB×Lq×Lk:Mask矩阵(无效位置为−∞-\infty−∞,有效位置为0);
- 输出:RB×Lq×Dv\mathbb{R}^{B \times L_q \times D_v}RB×Lq×Dv(融合全局语义的查询序列表示)。
(2)为什么要"缩放"?
当DkD_kDk较大时,QKTQK^TQKT的点积结果方差会随DkD_kDk线性增大,导致SoftMax输出极度趋近于0或1(梯度消失)。除以Dk\sqrt{D_k}Dk 可将方差归一化为1,保证梯度稳定:
Var(qi⋅kj)=Dk(假设 qi,kj∼N(0,1))qi⋅kjDk ⟹ Var(qi⋅kjDk)=1 \begin{align} \text{Var}(q_i \cdot k_j) &= D_k \quad (\text{假设} \ q_i,k_j \sim \mathcal{N}(0,1)) \\ \frac{q_i \cdot k_j}{\sqrt{D_k}} &\implies \text{Var}\left( \frac{q_i \cdot k_j}{\sqrt{D_k}} \right) = 1 \end{align} Var(qi⋅kj)Dk qi⋅kj=Dk(假设 qi,kj∼N(0,1))⟹Var(Dk qi⋅kj)=1
(3)Mask的两种类型
- Padding Mask :针对不等长序列,屏蔽padding填充位:
MPaddingb,i,j={−∞,若Tokenj是padding位0,其他 M_{\text{Padding}}b, i, j = \begin{cases} -\infty, & \text{若Token}_j \text{是padding位} \\ 0, & \text{其他} \end{cases} MPaddingb,i,j={−∞,0,若Tokenj是padding位其他 - Look-ahead Mask :针对生成式任务(如GPT),屏蔽"当前Token之后的所有位置":
MLook-aheadb,i,j={−∞,若j>i0,其他 M_{\text{Look-ahead}}b, i, j = \begin{cases} -\infty, & \text{若} j > i \\ 0, & \text{其他} \end{cases} MLook-aheadb,i,j={−∞,0,若j>i其他
2.3 代码实现(PyTorch版)
python
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: torch.Tensor = None
) -> tuple[torch.Tensor, torch.Tensor]:
"""
实现Scaled Dot-Product Attention,与数学公式严格对应
参数:
q: [batch_size, seq_len_q, d_k] 查询矩阵
k: [batch_size, seq_len_k, d_k] 键矩阵
v: [batch_size, seq_len_k, d_v] 值矩阵
mask: [batch_size, seq_len_q, seq_len_k] Mask矩阵(可选)
返回:
output: [batch_size, seq_len_q, d_v] 注意力输出
attn_weights: [batch_size, seq_len_q, seq_len_k] 注意力权重
"""
# 1. 计算Q×K^T(对应公式中的QK^T)
d_k = q.size(-1)
attn_scores = torch.matmul(q, k.transpose(-2, -1)) # [B, L_q, L_k]
# 2. 缩放(对应公式中的/√D_k)
attn_scores = attn_scores / torch.sqrt(torch.tensor(d_k, dtype=torch.float32))
# 3. 应用Mask(对应公式中的+M)
if mask is not None:
attn_scores = attn_scores.masked_fill(mask == 1, -1e9) # Mask位设为-∞
# 4. SoftMax归一化(对应公式中的SoftMax(·))
attn_weights = F.softmax(attn_scores, dim=-1) # [B, L_q, L_k]
# 5. 权重×V(对应公式中的SoftMax(·)V)
output = torch.matmul(attn_weights, v) # [B, L_q, D_v]
return output, attn_weights
# 测试代码
if __name__ == "__main__":
# 模拟输入:B=2, L=5, D_k=64
batch_size, seq_len, d_k = 2, 5, 64
q = torch.randn(batch_size, seq_len, d_k)
k = torch.randn(batch_size, seq_len, d_k)
v = torch.randn(batch_size, seq_len, d_k)
# 模拟Padding Mask:第2个样本的后2个Token是padding
mask = torch.zeros(batch_size, seq_len, seq_len)
mask[1, :, 3:] = 1 # [2,5,5]
# 执行注意力计算
output, attn_weights = scaled_dot_product_attention(q, k, v, mask)
print(f"Q/K/V形状: {q.shape}")
print(f"注意力权重形状: {attn_weights.shape}") # [2,5,5]
print(f"注意力输出形状: {output.shape}") # [2,5,64]3. Multi-Head Attention:多头注意力机制
Multi-Head Attention是Scaled Dot-Product Attention的升级版本,解决了"单一注意力头无法捕捉多维度语义"的问题。
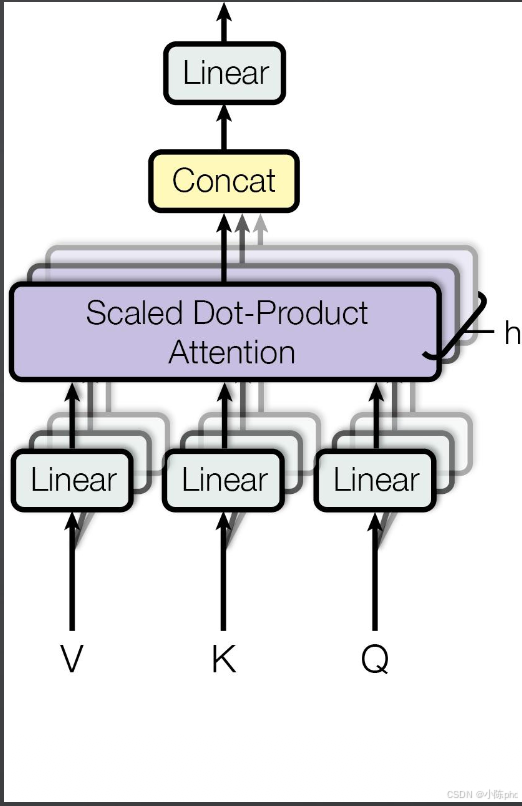
3.1 核心逻辑
多头注意力的核心思想是:将Q、K、V拆分为hhh个独立的"注意力头",每个头学习不同维度的语义关联,最后拼接并线性投影,融合所有头的信息。
执行步骤:
- Linear投影:输入Q、K、V分别经过独立线性层,映射到高维空间;
- 拆分多头 :将投影后的Q、K、V按维度拆分为hhh个头;
- 单头注意力计算:每个头独立执行Scaled Dot-Product Attention;
- 拼接多头输出 :将hhh个头的输出按维度拼接;
- 最终线性投影:融合多头语义信息,得到最终结果。
3.2 数学原理
(1)多头拆分与投影
假设模型隐藏层维度为DmodelD_{\text{model}}Dmodel,注意力头数为hhh,则每个头的维度Dk=Dmodel/hD_k = D_{\text{model}} / hDk=Dmodel/h(必须整除):
总维度: Dmodel=h×Dk单头投影: Qi=Q⋅WQi, Ki=K⋅WKi, Vi=V⋅WVi(i=1,2,...,h)其中: WQi,WKi,WVi∈RDmodel×Dk \begin{align} & \text{总维度:} \ D_{\text{model}} = h \times D_k \\ & \text{单头投影:} \ Q_i = Q \cdot W_{Q_i}, \ K_i = K \cdot W_{K_i}, \ V_i = V \cdot W_{V_i} \quad (i=1,2,...,h) \\ & \text{其中:} \ W_{Q_i}, W_{K_i}, W_{V_i} \in \mathbb{R}^{D_{\text{model}} \times D_k} \end{align} 总维度: Dmodel=h×Dk单头投影: Qi=Q⋅WQi, Ki=K⋅WKi, Vi=V⋅WVi(i=1,2,...,h)其中: WQi,WKi,WVi∈RDmodel×Dk
(2)单头注意力与拼接
headi=Attention(Qi,Ki,Vi)(i=1,2,...,h)MultiHead(Q,K,V)=Concat(head1,head2,...,headh)⋅WO其中: WO∈RDmodel×Dmodel,输出∈RB×L×Dmodel \begin{align} \text{head}_i &= \text{Attention}(Q_i, K_i, V_i) \quad (i=1,2,...,h) \\ \text{MultiHead}(Q,K,V) &= \text{Concat}(\text{head}1, \text{head}2, ..., \text{head}h) \cdot W_O \\ \text{其中:} & \ W_O \in \mathbb{R}^{D{\text{model}} \times D{\text{model}}}, \quad \text{输出} \in \mathbb{R}^{B \times L \times D{\text{model}}} \end{align} headiMultiHead(Q,K,V)其中:=Attention(Qi,Ki,Vi)(i=1,2,...,h)=Concat(head1,head2,...,headh)⋅WO WO∈RDmodel×Dmodel,输出∈RB×L×Dmodel
- headi∈RB×L×Dk\text{head}_i \in \mathbb{R}^{B \times L \times D_k}headi∈RB×L×Dk:第iii个头的注意力输出;
- Concat(⋅)\text{Concat}(\cdot)Concat(⋅):按最后一维拼接(将hhh个DkD_kDk维度拼接为DmodelD_{\text{model}}Dmodel);
- WOW_OWO:最终投影矩阵,融合多头语义信息。
3.3 代码实现(PyTorch版)
python
import torch
import torch.nn as nn
from typing import Optional
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int):
"""
实现Multi-Head Attention,与数学公式严格对应
参数:
d_model: 模型总维度(如768),需满足 d_model % num_heads == 0
num_heads: 注意力头数(如12)
"""
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads # 单头维度(对应公式中的D_k)
# 1. 线性投影层(对应公式中的W_Q/W_K/W_V)
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
# 5. 最终投影层(对应公式中的W_O)
self.w_o = nn.Linear(d_model, d_model)
def _split_heads(self, x: torch.Tensor) -> torch.Tensor:
"""
将投影后的向量拆分为多头(对应公式中的拆分步骤)
输入:x [B, L, D_model]
输出:x [B, num_heads, L, D_k]
"""
batch_size, seq_len, _ = x.shape
# 拆分:[B, L, num_heads, D_k] → 转置:[B, num_heads, L, D_k]
return x.view(batch_size, seq_len, self.num_heads, self.d_k).transpose(1, 2)
def _concat_heads(self, x: torch.Tensor) -> torch.Tensor:
"""
拼接多头输出(对应公式中的Concat步骤)
输入:x [B, num_heads, L, D_k]
输出:x [B, L, D_model]
"""
batch_size, _, seq_len, _ = x.shape
# 转置:[B, L, num_heads, D_k] → 拼接:[B, L, D_model]
return x.transpose(1, 2).contiguous().view(batch_size, seq_len, self.d_model)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask: Optional[torch.Tensor] = None
) -> torch.Tensor:
"""
前向传播(与数学公式严格对应)
参数:
q/k/v: [B, L, D_model] 输入矩阵
mask: [B, L, L] Mask矩阵(可选)
返回:
output: [B, L, D_model] 多头注意力输出
"""
batch_size = q.size(0)
# Step 1: 线性投影(对应公式中的Q·W_Q等)
q_proj = self.w_q(q) # [B, L, D_model]
k_proj = self.w_k(k) # [B, L, D_model]
v_proj = self.w_v(v) # [B, L, D_model]
# Step 2: 拆分多头(对应公式中的Q_i等)
q_heads = self._split_heads(q_proj) # [B, h, L, D_k]
k_heads = self._split_heads(k_proj) # [B, h, L, D_k]
v_heads = self._split_heads(v_proj) # [B, h, L, D_k]
# Step 3: 单头注意力计算(对应公式中的head_i)
# 扩展Mask维度以匹配多头:[B, L, L] → [B, 1, L, L]
mask_expanded = mask.unsqueeze(1) if mask is not None else None
attn_output, _ = scaled_dot_product_attention(q_heads, k_heads, v_heads, mask_expanded)
# attn_output: [B, h, L, D_k]
# Step 4: 拼接多头输出(对应公式中的Concat)
attn_concat = self._concat_heads(attn_output) # [B, L, D_model]
# Step 5: 最终线性投影(对应公式中的·W_O)
output = self.w_o(attn_concat) # [B, L, D_model]
return output
# 测试代码
if __name__ == "__main__":
# 初始化:D_model=768,h=12(BERT-base配置)
mha = MultiHeadAttention(d_model=768, num_heads=12)
# 模拟输入:B=2, L=10, D_model=768(Self-Attention中Q=K=V)
batch_size, seq_len, d_model = 2, 10, 768
x = torch.randn(batch_size, seq_len, d_model)
# 模拟Look-ahead Mask(生成式任务)
look_ahead_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1) # [10,10]
look_ahead_mask = look_ahead_mask.unsqueeze(0).repeat(batch_size, 1, 1) # [2,10,10]
# 执行多头注意力
output = mha(x, x, x, mask=look_ahead_mask)
print(f"输入形状: {x.shape}")
print(f"多头注意力输出形状: {output.shape}") # [2,10,768](与输入维度一致)4. Self-Attention vs 普通Attention:关键区别
Self-Attention是Attention机制的一个特例,其核心公式为:
Self-Attention(X)=MultiHead(XWQ,XWK,XWV) \text{Self-Attention}(X) = \text{MultiHead}(XW_Q, XW_K, XW_V) Self-Attention(X)=MultiHead(XWQ,XWK,XWV)
与普通Attention的区别:
- 普通Attention(如机器翻译的Encoder-Decoder Attention):Q来自Decoder,K、V来自Encoder,用于"目标序列对齐源序列";
- Self-Attention :Q=K=V,均来自同一序列(如Encoder的输入),用于"序列内部Token之间的语义关联建模"。
这也是为什么Self-Attention能高效捕捉长文本的上下文依赖------它能同时计算序列中任意两个Token的注意力权重,无需像RNN那样逐词遍历。
5. 总结
- 基础单元:Scaled Dot-Product Attention通过"Q×Kᵀ相似度计算→缩放→Mask→SoftMax归一化→加权求和V",实现单个Token的全局语义融合;
- 升级版本:Multi-Head Attention通过"拆分多头→独立注意力计算→拼接→线性投影",捕捉多维度语义关联,是Transformer的核心;
- 核心优势:并行计算效率高、长距离依赖建模能力强,是大模型处理文本、图像等序列数据的基础。