****论文题目:****FASTGCN: FAST LEARNING WITH GRAPH CONVOLUTIONAL NETWORKS VIA IMPORTANCE SAMPLING(通过重要性采样快速学习图卷积网络)
会议:ICLR2018
****摘要:****Kipf和Welling最近提出的图卷积网络(GCN)是一种有效的半监督学习图模型。然而,这个模型最初被设计为在训练和测试数据同时存在的情况下学习。此外,跨层的递归邻域扩展对于训练大型密集图会带来时间和内存方面的挑战。为了放宽对测试数据同时可用性的要求,我们将图卷积解释为嵌入函数在概率测度下的积分变换。这样的解释允许使用蒙特卡罗方法来一致地估计积分,这反过来又导致了我们在这项工作中提出的批量训练方案。通过重要性采样的增强,FastGCN不仅训练效率高,而且对推理也有很好的泛化能力。我们展示了一组全面的实验来证明它与GCN和相关模型的有效性。特别是,训练的效率提高了几个数量级,而预测仍然相当准确。
一句话概括就是,随机抽50个人,再从50个人抽25个人回答,而这50个人的关系网越大,抽到的概率就越大。
FastGCN:用重要性采样加速图卷积网络学习
图神经网络(GNN)已经成为处理图结构数据的重要工具,在社交网络分析、推荐系统、知识图谱等领域都有广泛应用。Kipf和Welling提出的图卷积网络(GCN)是其中的代表性工作,但它在实际应用中面临两个关键挑战:需要同时使用训练和测试数据 ,以及计算和内存开销巨大。今天要介绍的这篇发表在ICLR 2018的论文FastGCN,通过一个优雅的理论框架和巧妙的采样策略,同时解决了这两个问题。
问题背景:GCN的困境
挑战1:无法应对动态图
原始GCN的学习过程需要同时访问训练和测试数据,这种转导式学习方式在许多实际场景中不可行:
- 社交网络不断有新用户加入
- 推荐系统持续添加新商品
- 知识图谱随时扩展新实体
我们需要的是归纳式学习:仅从训练集学习模型,然后泛化到任意新节点。
挑战2:邻域爆炸问题
GCN的核心操作是邻域聚合,其架构可以简洁地表示为:
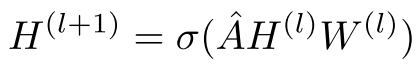
其中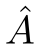 是归一化的邻接矩阵。看起来很简单,但问题在于递归邻域扩展:
是归一化的邻接矩阵。看起来很简单,但问题在于递归邻域扩展:
- 第1层:每个节点聚合其直接邻居
- 第2层:需要聚合邻居的邻居
- 第L层:需要L跳邻居的信息
对于稠密图或幂律图(如社交网络),一个节点的2-3跳邻域就可能覆盖大部分图!这导致:
- 内存爆炸:mini-batch训练仍需加载大量节点数据
- 计算低效:即使batch size很小,实际计算量也很大
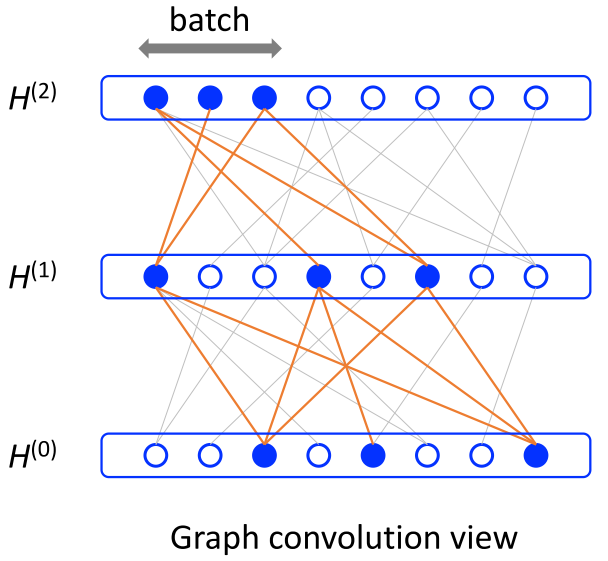
FastGCN的核心思想:从卷积到积分
理论创新:换个角度看图卷积
FastGCN的关键洞察是:我们可以将图卷积重新解释为概率测度下的积分变换。
假设 :图的节点是某个概率空间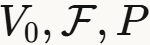 的i.i.d.采样。
的i.i.d.采样。
在这个框架下,GCN的每一层可以写成函数形式:
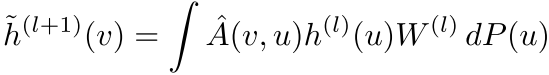
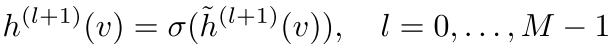
损失函数则是:
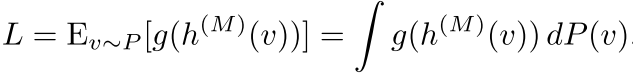
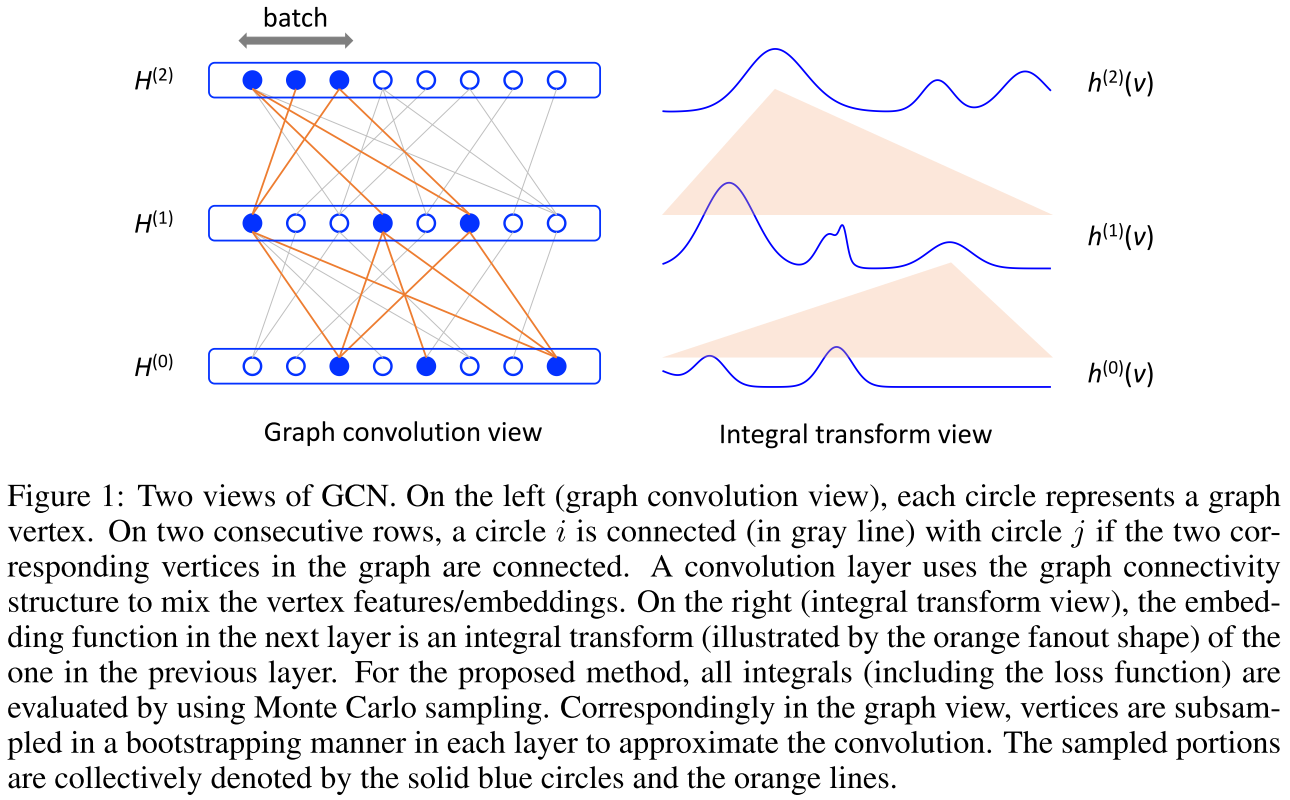
这个表述的美妙之处在于:积分可以用蒙特卡洛采样近似!
采样方案:逐层采样节点
对于第l层,我们采样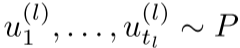 ,然后:
,然后:
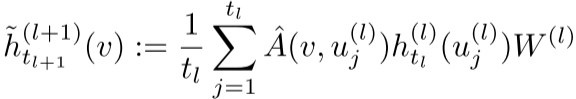
重要理论保证 (Theorem 1):如果激活函数σ和损失函数g连续,则当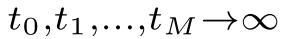 时,估计的损失几乎必然收敛到真实损失。
时,估计的损失几乎必然收敛到真实损失。
实际算法(Algorithm 1):
- 对每一层l,均匀采样t_l个节点
- 按照上述公式计算批次梯度
- 执行SGD更新

方差缩减:重要性采样的魔力
均匀采样虽然简单,但估计方差可能较大。论文深入分析了每一层的方差结构(Proposition 2),并提出了最优采样分布(Theorem 3)。
理论最优分布
最优采样分布应该正比于:
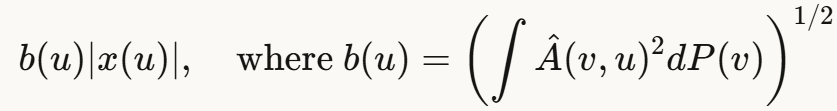
但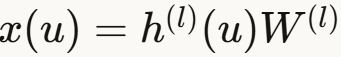 在训练中不断变化,计算成本太高。
在训练中不断变化,计算成本太高。
实用的次优方案
论文提出了一个巧妙的折中(Proposition 4):采样分布正比于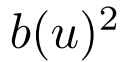 ,即:
,即:
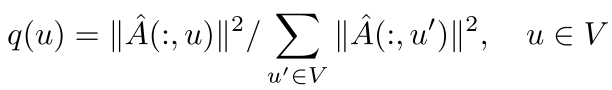
这个分布:
- ✅ 只依赖于图结构,所有层共享
- ✅ 可以预计算,开销很低
- ✅ 理论上保证了方差缩减
更新的算法(Algorithm 2):
- 预计算每个节点的采样概率q(u)
- 对每一层,按照q采样t_l个节点
- 计算梯度时加入重要性权重1/q(u)

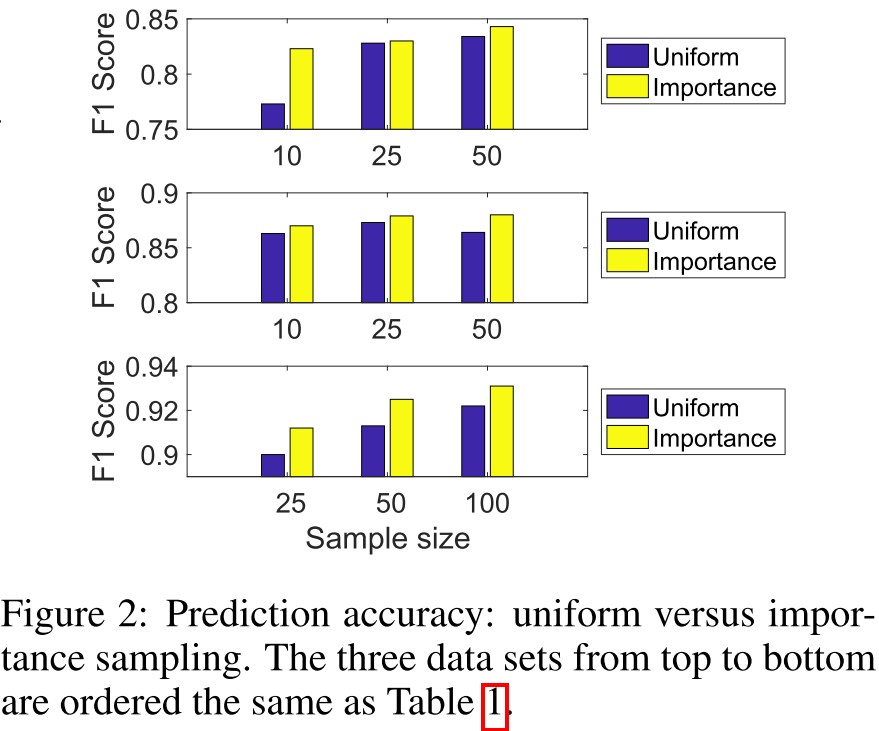
实验验证(Figure 2):在所有数据集上,重要性采样都显著优于均匀采样!
与GraphSAGE的关键区别
GraphSAGE也注意到了GCN的内存瓶颈,并提出通过采样限制邻域大小。但FastGCN的采样策略更加高效:
| 方法 | 采样对象 | 涉及节点总数方法 |
|---|---|---|
| GraphSAGE | 每个节点的邻居 | 乘积 |
| FastGCN | 每层的节点 | 求和 |
这是一个数量级的差异!例如,如果每层采样25个,2层网络中:
- GraphSAGE:涉及25 × 25 = 625个节点
- FastGCN:涉及25 + 25 = 50个节点
实验结果
数据集
论文在三个基准数据集上进行了实验:

这三个数据集规模递增,代表了从小型到大型稠密图的不同场景。
训练速度:数量级提升
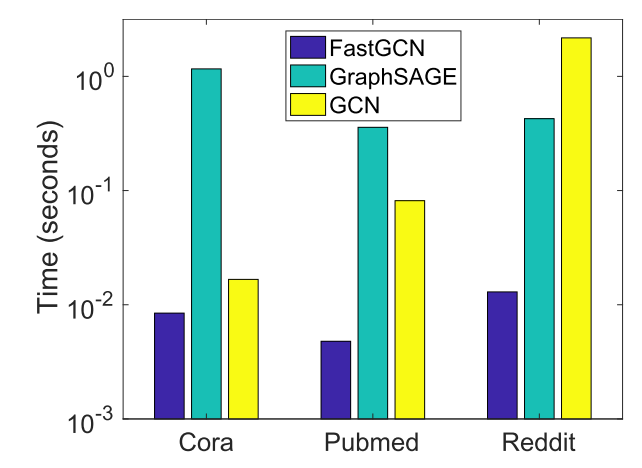
每批次训练时间(秒):
| 数据集 | FastGCN | GraphSAGE | GCN (batched) |
|---|---|---|---|
| Cora | 0.0084 | 1.1630 | 0.0166 |
| Pubmed | 0.0047 | 0.3579 | 0.0815 |
| 0.0129 | 0.4260 | 2.1731 |
关键发现:
- 在大图Reddit上,FastGCN比GCN快168倍 ,比GraphSAGE快33倍
- 即使在小图上,FastGCN也是最快的
- 原始GCN在Reddit上因内存不足无法运行
预测准确率:不降反升
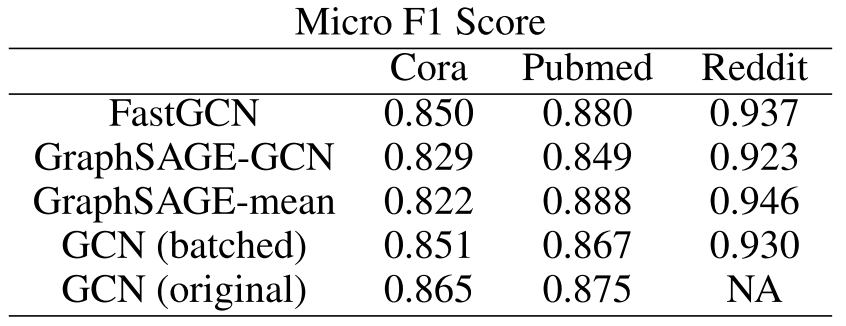
FastGCN的准确率与最佳baseline高度可比,在某些情况下甚至更好!
预计算优化
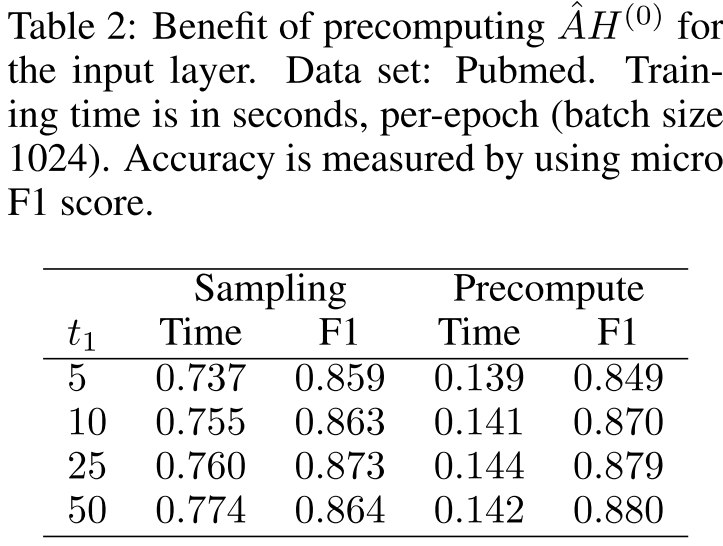
在Pubmed数据集上,预计算输入层的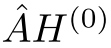 :
:
- 训练时间从0.760秒/epoch降至0.142秒/epoch(5.4倍加速)
- F1分数从0.873提升到0.880
这个优化基于一个简单观察:输入特征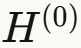 不变,所以
不变,所以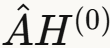 可以预计算并重用。
可以预计算并重用。
训练过程可视化
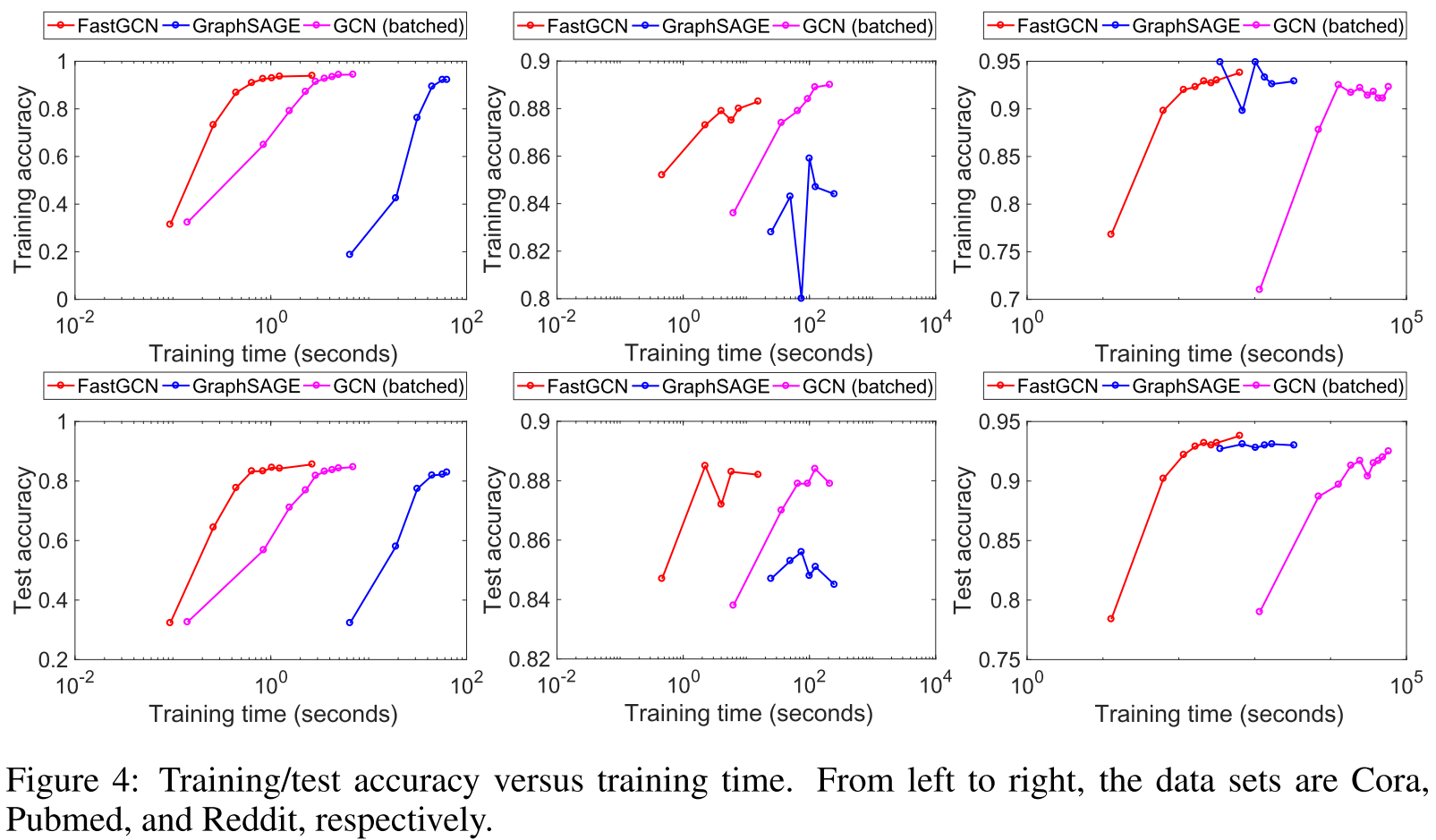
从训练曲线可以看出:
- FastGCN收敛速度最快
- 虽然per-batch时间短,总训练时间也显著更少
- 测试准确率稳定且高
技术细节与洞察
1. 一致性保证
Theorem 1保证了采样估计的一致性。证明巧妙地使用了:
- 大数定律(Law of Large Numbers)
- 连续映射定理(Continuous Mapping Theorem)
- 递归应用于每一层
2. 方差分析
论文对每一层的方差进行了详细分解(Proposition 2):
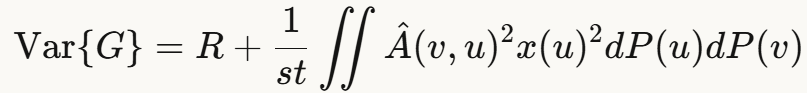
其中R部分难以优化(因为v的采样不在本层),但第二项可以通过改变u的采样分布来优化。
3. 归纳推理
FastGCN自然支持归纳学习:
- 训练:只使用训练节点,通过采样估计损失和梯度
- 推理:对新节点,使用完整GCN架构(或继续采样)
局限性与未来方向
论文也诚实地讨论了局限:
- 小图上的优势较小:当图很小时,采样开销可能抵消收益
- SGD理论:采样梯度是有偏的,虽然一致但不是标准SGD(附录D给出了收敛分析)
- 超参数:需要调节每层的采样数t_l
论文指出,这个框架可以推广到其他基于一阶邻域的图模型,如MoNet、消息传递神经网络等。
总结
FastGCN通过一个简洁优雅的理论框架------将图卷积重新解释为积分变换------解决了GCN的两大核心问题:
- ✅ 归纳学习:训练和测试数据分离,支持动态图
- ✅ 高效可扩展:逐层采样节点而非邻居,计算量从乘积降为求和
- ✅ 理论保证:一致性和方差缩减有严格的数学支撑
- ✅ 实验验证:1-2个数量级的加速,准确率不降反升
这篇论文的美妙之处在于,它不只是提出了一个工程技巧,而是通过改变视角(从离散图到连续概率空间)打开了新的设计空间。这种思维方式对图神经网络的后续发展产生了深远影响。
如果你正在处理大规模图数据,或者需要在动态变化的图上进行学习,FastGCN绝对值得一试!