⚡ 本文能帮你实现什么?
一套全自动的 TikTok 爆款发现系统,每天自动运行,无需人工干预
✅ 自动抓取 TikTok垂类内容(Bright Data API)
✅ 自动筛选突破性爆款
✅ 自动生成AI内容分析(DeepSeek)
✅ 自动同步至 Google Sheets,团队实时查阅
适合谁: 美妆/时尚品牌运营、MCN内容团队、社媒数据分析师
技术门槛: 会复制粘贴Python代码即可
所需工具: Bright Data(底下注册送$2)+ DeepSeek API + Google Cloud
免费注册试用,可联系客服延长试用期,用折扣码API30可再打7折
https://get.brightdata.com/yp8cjb
目录
- [⚡ 本文能帮你实现什么?](#⚡ 本文能帮你实现什么?)
- 前言
- 为什么手动监测已经失效?
- [解决方案:Bright Data TikTok 帖子抓取器的结构化优势](#解决方案:Bright Data TikTok 帖子抓取器的结构化优势)
- [代码实战:TikTok Dupes 爆款洞察自动化案例](#代码实战:TikTok Dupes 爆款洞察自动化案例)
-
- 1.找到Tiktok数据集
- 2.选择API
- [3.代码片段1:触发Bright Data API执行爬取任务](#3.代码片段1:触发Bright Data API执行爬取任务)
- [4.代码片段2:下载Bright Data爬取结果](#4.代码片段2:下载Bright Data爬取结果)
- 5.代码片段3:加载与清洗爬取数据
- 6.代码片段4:筛选突破性爆款内容
- 7.代码片段5:AI智能分析爆款逻辑
- [8.代码片段6:导出数据至Google Sheets](#8.代码片段6:导出数据至Google Sheets)
- 9.代码片段7:主流程执行函数
- 10.完整代码
- 结语
- [❓ 常见问题解答 (FAQ)](#❓ 常见问题解答 (FAQ))
前言
在 TikTok 这个以"速度"和"趋势"为王的战场上,晚一步意味着错失百万流量。当你的竞争对手还在手动浏览推荐页(For You Page)时,聪明的营销团队已经通过数据驱动的策略,提前锁定了下一个病毒式传播的题材。
想在对手之前发现有效内容,关键是建立一套可自动运行的抓取与分析系统。本文基于 Bright Data TikTok 抓取器,演示如何实现:自动抓取 → 统计筛选 → AI 洞察 → 写入 Google Sheets 的全流程。
为什么手动监测已经失效?
TikTok 拥有数十亿的用户生成内容。依靠人工去筛选创作者个人资料、记录帖子元数据、统计互动量(点赞、评论、分享)以及分析话题标签,不仅效率低下,而且极易遗漏那些处于萌芽阶段的"突破性内容"。
要真正跑赢算法,您需要收集以下核心数据维度:
创作者个人资料:粉丝增长轨迹、受众画像、过往爆款规律。
帖子元数据:发布时间、视频时长、背景音乐(BGM)、特效使用。
实时互动量:不仅是总数,更是互动速率(每小时增长量)。
话题标签生态:热门标签与长尾标签的组合策略。
发布频率:竞争对手在什么时间段、以何种频率发布内容效果最佳?
针对以上五大数据维度的手动监测痛点,Bright Data TikTok 帖子抓取器提供了一一对应的解决方案:
- 创作者资料 → 全字段Profile API,含粉丝增长轨迹
- 帖子元数据 → 结构化输出,BGM/特效等深层字段完整覆盖
- 实时互动量 → 支持轮询抓取,可构建互动速率曲线
- 话题标签生态 → hashtags字段结构化,支持长尾标签分析
- 发布频率 → Profile Posts API,还原创作者发布规律
不想手动整理数据?→ 试试 Bright Data 自动化方案,免费试用 →https://get.brightdata.com/yp8cjb
解决方案:Bright Data TikTok 帖子抓取器的结构化优势
面对 TikTok 复杂的反爬虫机制和动态变化的前端代码,通用的爬虫工具往往难以维持稳定的数据输出。这就是 Bright Data 脱颖而出的地方。与其他需要大量维护成本的自建脚本不同,Bright Data TikTok Web Scraper API(实时按关键词触发抓取)提供了一致且结构化的输出。如果你不需要实时数据,也可以直接购买 Bright Data TikTok Dataset(现成结构化数据,无需代码)。
主流TikTok抓取工具核心短板
-
开源爬虫脚本:需具备专业编程能力,适配门槛高;TikTok平台反爬机制严苛,易出现IP封禁、验证码拦截、数据采集中断问题;数据输出为零散的原始数据,无标准化格式,后期清洗整理耗时极长,无法满足快速分析、抢先决策的需求;且无合规保障,易触碰平台规则红线。
-
小型第三方爬虫工具:功能单一,仅能采集部分基础数据,无法覆盖创作者、帖子、互动、标签全维度;数据输出格式混乱,字段缺失严重,一致性极差,难以进行批量对比分析;稳定性不足,大规模采集时易卡顿、漏采,无法支撑常态化市场研究;部分工具暗藏数据泄露风险,安全性无保障。
-
通用型数据采集平台:针对TikTok的定制化能力弱,无法精准匹配平台页面结构,数据采集准确率低;虽能输出结构化数据,但定制流程繁琐,需手动配置字段,耗时耗力;收费模式不灵活,基础套餐难以满足高频抓取需求,升级套餐成本高昂;售后与技术支持薄弱,遇到反爬拦截、数据异常问题,无法快速解决。
| 特性 | 通用/自建爬虫 | Bright Data TikTok 抓取器 |
|---|---|---|
| 数据稳定性 | 低,网站更新即失效 | 高,由专业团队实时维护适配 |
| 输出格式 | 杂乱,需大量清洗 | JSON/CSV 标准化,开箱即用 |
| 反爬对抗 | 易被封禁,IP 管理复杂 | 内置代理网络,自动处理验证码与挑战 |
| 字段完整性 | 经常缺失关键元数据 | 全字段覆盖,包括隐藏的深度互动指标 |
| 合规性 | 风险不可控 | 符合 GDPR/CCPA,企业级合规保障 |
Bright Data 的核心价值在于它将非结构化的社交媒体噪音,转化为了您可以直接导入数据库进行分析的干净资产。您无需担心 IP 封锁或 HTML 结构变更,只需专注于数据背后的商业洞察。
代码实战:TikTok Dupes 爆款洞察自动化案例
本次实操代码围绕"Bright Data API触发爬取→结果下载→数据清洗→突破性内容筛选→AI智能分析→Google Sheets导出"打造全自动化闭环,全程无需人工频繁干预,适配每日常态化数据研究需求。核心逻辑是借助Bright Data API完成合规高效的TikTok数据抓取,通过Python完成数据清洗与爆款筛选,结合大模型AI提炼内容规律,最终同步至Google Sheets实现数据共享与复盘,完美落地"抢先对手发现有效内容"的核心目标,兼具自动化、精准性与实用性。
代码核心价值:解决手动抓取效率低、数据杂乱、分析滞后的痛点,实现从数据采集到决策输出的全链路自动化,缩短数据处理周期,助力运营者快速捕捉潜力爆款,抢占流量先机,同时适配美妆#dupe alternative等垂类精细化研究需求。
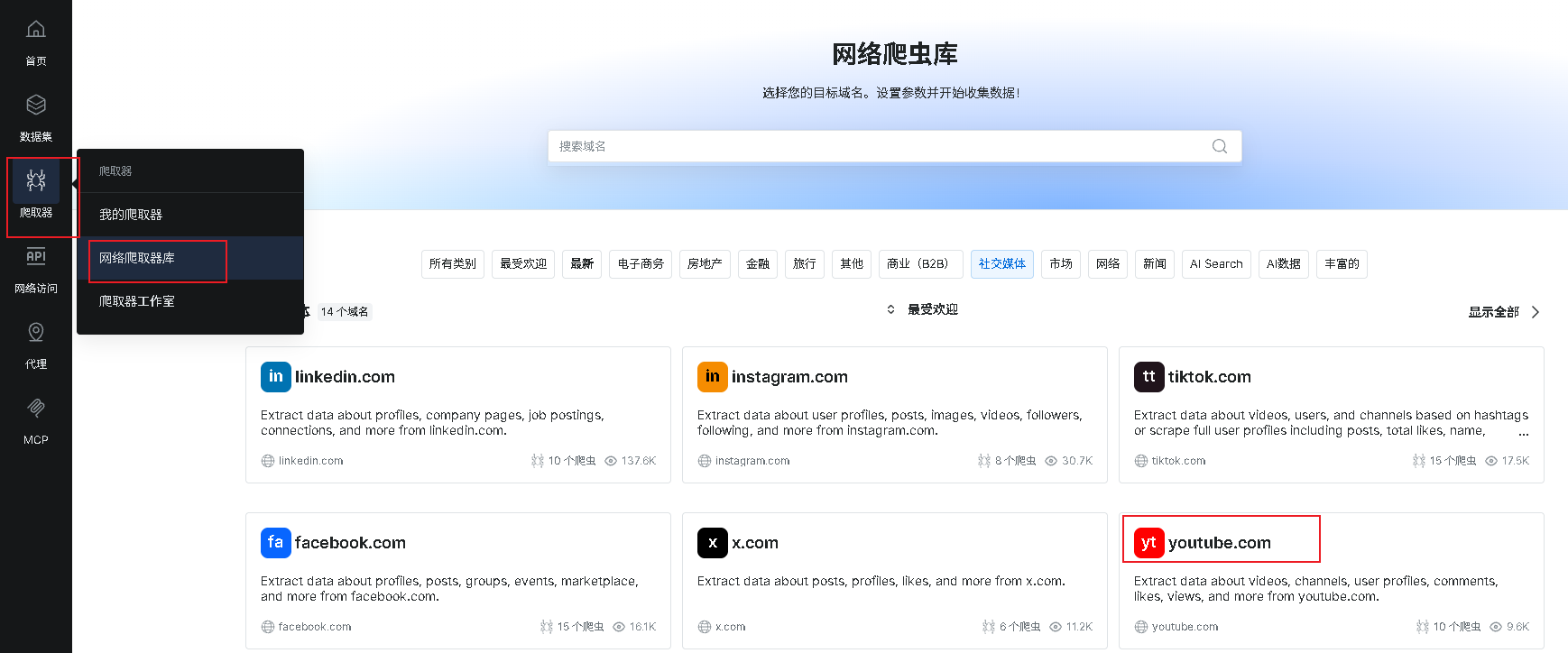
1.找到Tiktok数据集
没有账号的小伙伴可以在官网注册一下: 链接,初始有两美元的免费使用额度
进入爬虫市场,找到Tiktok
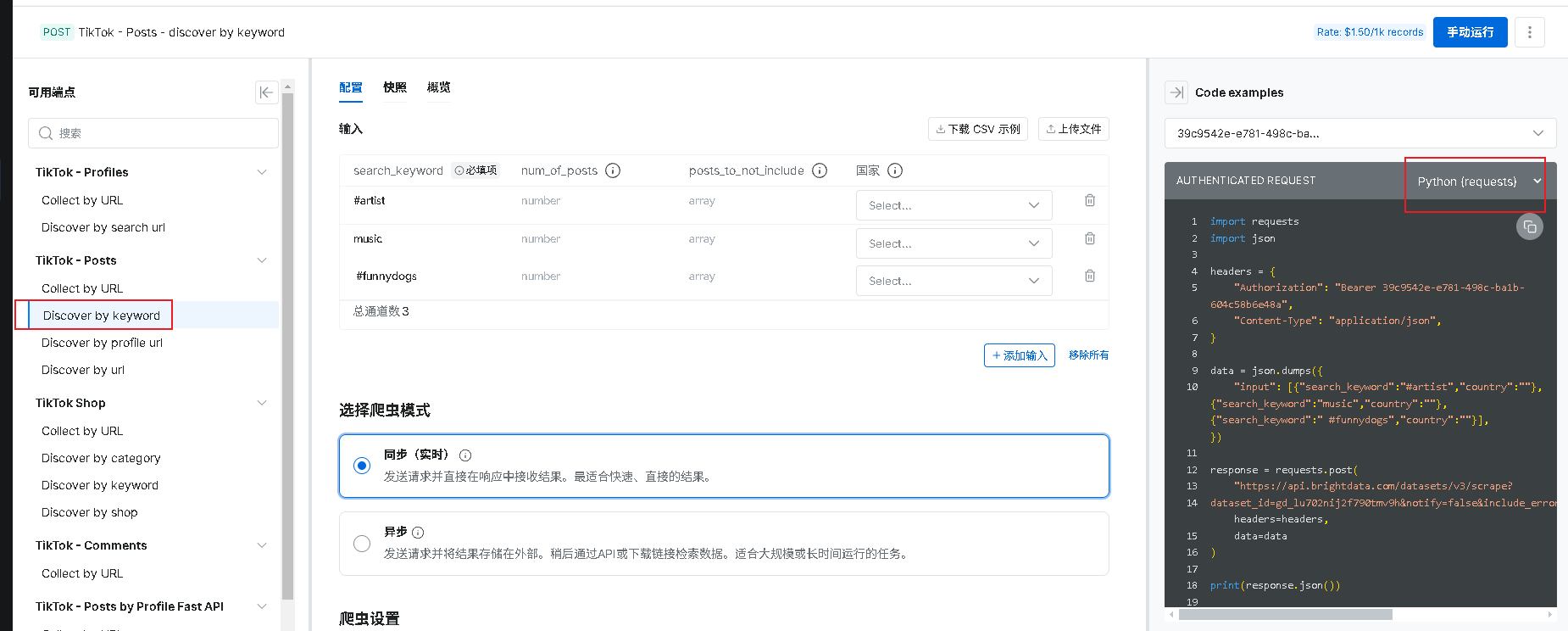
2.选择API
本案例采用 API 方式执行抓取(右侧提供多种语言的代码模板可直接复制),更便于自动化与流程整合。当然,你也可以在控制台页面直接运行任务并获取结果。
如上前置流程已准备完毕,下面进入实战环节。
3.代码片段1:触发Bright Data API执行爬取任务
python
import os
# 由于博主最后一步需要写入 Google Sheets,因此开启代理;
# DeepSeek和brightdata 接口不走代理,仅 Google Sheets 请求使用代理。
os.environ["HTTP_PROXY"] = "http://127.0.0.1:7897"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:7897"
os.environ["NO_PROXY"] = "api.deepseek.com"
os.environ["NO_PROXY"] = "api.brightdata.com"
import pandas as pd
import json
import time
import os
from openai import OpenAI
import gspread
from google.oauth2.service_account import Credentials
import requests
# ================= 配置区域 =================
Liang_KEY = 'Bright Data的key,可以在刚刚复制代码中找到'
API_KEY = "这里博主使用的是ds,放上对应的key"
MODEL_NAME = "deepseek-chat"
BASE_URL = "https://api.deepseek.com/v1"
# 文件路径配置
INPUT_JSON_FILE = "tiktok_data.jsonl" # 爬取的数据文件路径
CREDENTIALS_FILE = "credentials.json" # 凭证:Google Cloud 下载的 JSON
# Google Sheets 配置
SPREADSHEET_NAME = "TikTok爆款分析报告_2026"
WORKSHEET_NAME = "今日洞察"
# ✅ DeepSeek 兼容 OpenAI SDK
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# ================= 1. 触发Bright Data Api,进行爬取内容 =================
def trigger_brightdata_task(keyword, num_of_posts=500, country=""):
headers = {
"Authorization": f"Bearer {Liang_KEY}",
"Content-Type": "application/json.json",
}
data = json.dumps({
"input": [{"search_keyword": keyword, "num_of_posts": num_of_posts, "country": country}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_lu702nij2f790tmv9h¬ify=false&include_errors=true&type=discover_new&discover_by=keyword",
headers=headers,
data=data
)
snapshot_id = response.json().get("snapshot_id")
print("snapshot_id:", snapshot_id)
return snapshot_id功能解析:该片段为代码基础配置+Bright Data爬取任务触发模块,先完成环境代理、第三方库、密钥、文件路径等基础参数配置,再定义函数调用Bright Data官方API,传入关键词、爬取帖子数量、地域等参数,发起TikTok数据爬取请求,生成专属快照ID(snapshot_id),作为后续下载爬取数据的唯一标识。
复制上面的代码,3分钟内跑出第一批TikTok数据 → 注册获取API Token →https://get.brightdata.com/yp8cjb
4.代码片段2:下载Bright Data爬取结果
python
# ================= 2. 触发Bright Data Api,获取爬取结果 =================
def download_snapshot_result(snapshot_id, output_file="tiktok_data.jsonl", poll_interval=120):
url = f'https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}'
headers = {
"Authorization": f"Bearer {Liang_KEY}",
"Content-Type": "application/json.json",
}
# 定义期望的 Content-Type(支持部分匹配)
expected_content_type = "application/jsonl"
while True:
try:
response = requests.get(
url, headers=headers, stream=True,
proxies={"http": None, "https": None}
)
response.raise_for_status()
content_type = response.headers.get('Content-Type', '').lower()
if expected_content_type in content_type:
print("✅ 数据爬取成功!")
break
else:
print(f"⏳ 正在爬取,{poll_interval//60} 分钟后再试...")
time.sleep(poll_interval)
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
time.sleep(poll_interval)
with open(output_file, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"✅ Download completed: {output_file}")
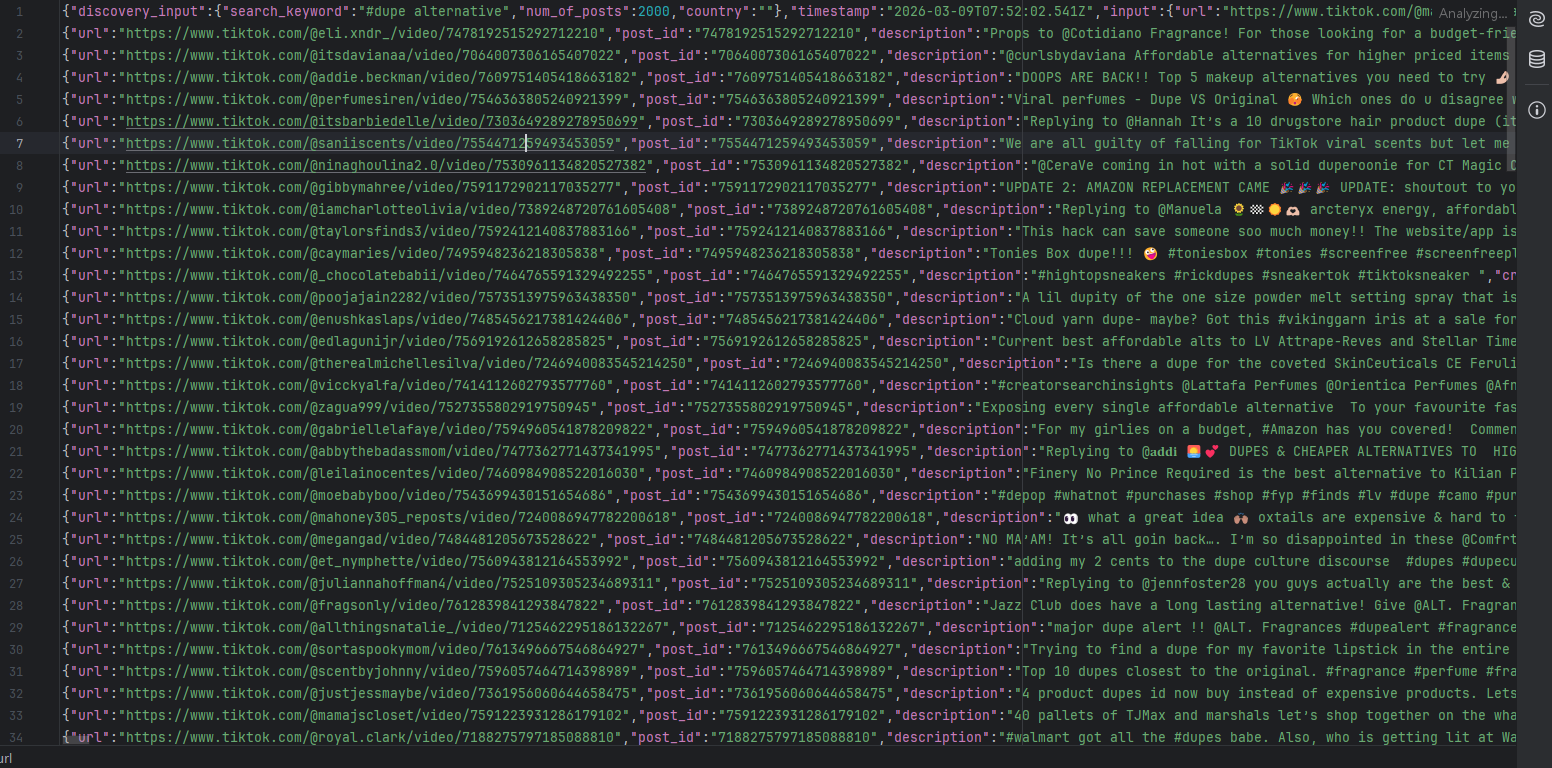
return output_file功能解析:该片段为爬取结果下载模块,定义函数通过快照ID轮询Bright Data服务器,检测爬取任务完成状态,待任务完成、数据生成JSONL格式文件后,自动将爬取数据下载至本地,保存为tiktok_data.jsonl文件。
运行截图:
5.代码片段3:加载与清洗爬取数据
python
# ================= 3. 加载数据 =================
def load_and_clean_data(file_path):
df = pd.read_json(file_path, lines=True) # 直接读 JSONL
df = df[~df["error"].notna()] if "error" in df.columns else df
df = df[df["digg_count"].notna() & df["description"].notna()]
print(f"✅ 数据加载完成:有效 {len(df)} 条")
return df功能解析:该片段为数据加载清洗模块,借助Pandas库读取本地JSONL格式的爬取数据,剔除含错误信息、无互动数据、无文案描述的无效数据,筛选出合规有效数据,生成标准化数据框(DataFrame),为后续分析筑牢基础。
6.代码片段4:筛选突破性爆款内容
python
# ================= 2. 统计分析与筛选逻辑 =================
def find_breakthroughs(df,keywords):
if df.empty:
return pd.DataFrame()
# 预处理:确保所有关键词都是小写字符串,去除空格
target_keywords = [str(k).lower().strip() for k in keywords]
df = df.copy()
# --- 1. 数据清洗:确保数值列是数字 ---
count_cols = ['digg_count', 'comment_count', 'share_count', 'collect_count']
for col in count_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
else:
df[col] = 0
df[count_cols] = df[count_cols].fillna(0)
# 计算综合互动分
df['score'] = (df['digg_count'] * 1) + \
(df['comment_count'] * 2) + \
(df['share_count'] * 3) + \
(df['collect_count'] * 4)
def check_topic(row,t_keywords):
# 1. 获取描述,确保是字符串并转小写
desc = str(row.get('description', '') or '').lower()
# 2. 获取标签列表
tags_raw = row.get('hashtags')
# 3. 如果 tags_raw 是 NaN (float) 或 None,则视为空列表;否则保持原样
if not isinstance(tags_raw, list):
tags_list = []
else:
tags_list = tags_raw
# 同时也把标签转成小写字符串,方便匹配
tags_list = [str(tag).lower() for tag in tags_raw]
# 4. 检查描述中是否包含【任意一个】目标关键词
# 遍历列表,只要有一个词在描述里,就为 True
has_keyword_in_desc = any(k in desc for k in t_keywords)
# 5. 检查标签中是否包含【任意一个】目标关键词
# 双重 any。外层遍历标签,内层遍历关键词列表
has_keyword_in_tags = any(
any(k in tag for k in t_keywords)
for tag in tags_list
)
return has_keyword_in_desc or has_keyword_in_tags
# 应用函数
# 使用 lambda 将 target_keywords 传递给 check_topic 函数
df['is_target_topic'] = df.apply(lambda row: check_topic(row, target_keywords), axis=1)
# ---------------------------------------
target_df = df[df['is_target_topic'] == True].copy()
if target_df.empty:
print(f"⚠️ 未找到与关键词 {target_keywords} 相关的内容。")
return pd.DataFrame()
print(f"✅ 关键词 [{', '.join(target_keywords)}] 筛选出 {len(target_df)} 条相关数据。")
# 计算统计指标
mean_score = target_df['score'].mean()
std_score = target_df['score'].std()
# 防止除以零或标准差为空
if std_score == 0 or std_score is None or pd.isna(std_score):
target_df['z_score'] = 0
else:
target_df['z_score'] = (target_df['score'] - mean_score) / std_score
# 防止除以零
if mean_score == 0 or pd.isna(mean_score):
target_df['breakthrough_ratio'] = 0
else:
target_df['breakthrough_ratio'] = target_df['score'] / mean_score
# 筛选策略
breakthroughs = target_df[(target_df['z_score'] > 0.5) | (target_df['breakthrough_ratio'] > 1.5)]
if not breakthroughs.empty:
print(breakthroughs.sort_values(by='z_score', ascending=False))
return breakthroughs.sort_values(by='z_score', ascending=False)功能解析:该片段为突破性内容核心筛选模块,先统一互动数据格式,结合点赞、评论、转发、收藏数据加权计算综合互动得分,再精准筛选目标垂类(dupe/alternative)内容,通过计算Z值、突破指数,筛选出远超行业平均水平的潜力爆款,最终按Z值降序排列,锁定高价值内容。
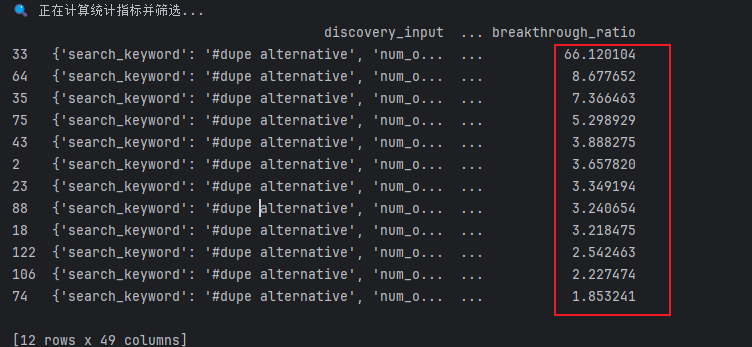
设计逻辑与好处:1. 加权计算综合互动分,贴合TikTok算法推荐逻辑,收藏、转发权重更高,更能精准判断内容有效性,避免单一点赞数误导分析;2. 智能校验标签与文案,精准定位垂类内容,解决非列表格式标签报错问题,适配各类数据格式,提升代码兼容性;3. 引入Z值与突破指数双重筛选标准,科学识别突破性内容,剔除普通流量内容,精准锁定可复制的爆款;4. 内置防除零、空值校验逻辑,避免代码运行报错,保障筛选流程顺畅;5. 按Z值降序排列,优先呈现优质爆款,便于运营者快速聚焦核心内容。
运行截图:
7.代码片段5:AI智能分析爆款逻辑
python
# ================= 3. LLM 分析函数 =================
def analyze_with_llm(row):
desc = row['description'][:150] # 截断过长描述
followers = row['profile_followers']
ratio = row['breakthrough_ratio']
plays = row['play_count']
size_label = "微型账号 (<1w)" if followers < 10000 else \
"小型账号 (1w-10w)" if followers < 100000 else \
"中型账号 (10w-100w)" if followers < 1000000 else \
"大型账号 (>100w)"
prompt = f"""
你是一位 TikTok 美妆赛道增长专家。
发现了一条在 "平价替代 (Dupes)" 赛道表现异常突出的视频。
【数据概览】
- 账号体量:{size_label} ({followers:,} 粉丝)
- 播放量:{plays:,}
- 突破指数:是同类平均水平的 {ratio:.2f} 倍
- 视频文案:"{desc}"
【任务】
请分析它为什么能跑赢平均水平?总结一个可复制的标题/内容公式。
【输出要求】
只输出一段简练的中文洞察 (80 字以内),直接给出结论。
"""
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100,
timeout=10
)
result = response.choices[0].message.content.strip()
print(f"\n✅ AI 返回结果 ({row['url']}):\n{result}\n")
return response.choices[0].message.content.strip()
except Exception as e:
return f"❌ AI Error: {str(e)}"功能解析:该片段为AI智能分析模块,调用DeepSeek大模型,传入爆款内容的账号体量、播放量、突破指数、视频文案等数据,通过定制化提示词(Prompt),让AI快速分析爆款成因,提炼可复制的内容公式,生成80字以内的精简洞察。
运行截图:

8.代码片段6:导出数据至Google Sheets
python
# ================= 4. 导出到 Google Sheets =================
def export_to_google_sheets(df, sheet_name, worksheet_name):
print(f"📡 正在连接 Google Sheets: '{sheet_name}'...")
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
if not os.path.exists(CREDENTIALS_FILE):
print(f"❌ 错误:找不到凭证文件 '{CREDENTIALS_FILE}'。")
return None
try:
creds = Credentials.from_service_account_file(CREDENTIALS_FILE, scopes=scopes)
gc = gspread.authorize(creds)
except Exception as e:
print(f"❌ Google 授权失败:{e}")
return None
try:
sh = gc.open(sheet_name)
print(f"📂 找到现有表格: {sheet_name}")
except gspread.exceptions.SpreadsheetNotFound:
sh = gc.create(sheet_name)
print(f"✨ 创建新表格: {sheet_name}")
try:
worksheet = sh.worksheet(worksheet_name)
worksheet.clear()
print(f"🧹 清空工作表: {worksheet_name}")
except gspread.exceptions.WorksheetNotFound:
worksheet = sh.add_worksheet(title=worksheet_name, rows=100, cols=20)
print(f"➕ 新建工作表: {worksheet_name}")
# 准备数据列
cols_to_export = ['profile_username', 'profile_followers', 'play_count', 'breakthrough_ratio', 'description',
'ai_insight', 'url']
available_cols = [c for c in cols_to_export if c in df.columns]
df_export = df[available_cols].copy()
df_export['分析时间'] = time.strftime("%Y-%m-%d %H:%M:%S")
data_values = [df_export.columns.tolist()] + df_export.values.tolist()
worksheet.update(values=data_values, range_name='A1')
worksheet.format('A1:Z1',
{'textFormat': {'bold': True}, 'backgroundColor': {'red': 0.9, 'green': 0.9, 'blue': 0.9}})
print(f"✅ 成功导出 {len(df_export)} 条数据到 Google Sheets!")
print(f"🔗 查看链接: {sh.url}")
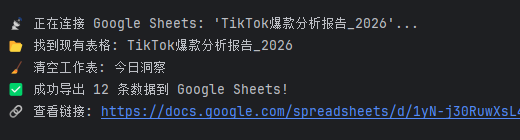
return sh.url功能解析:该片段为数据导出模块,通过Google Cloud凭证授权,连接Google Sheets,自动创建/清空指定表格,将筛选后的爆款数据、AI洞察、账号信息、视频链接等核心内容导入表格,格式化表头并生成表格链接。
运行截图:
Google Sheets详情页:
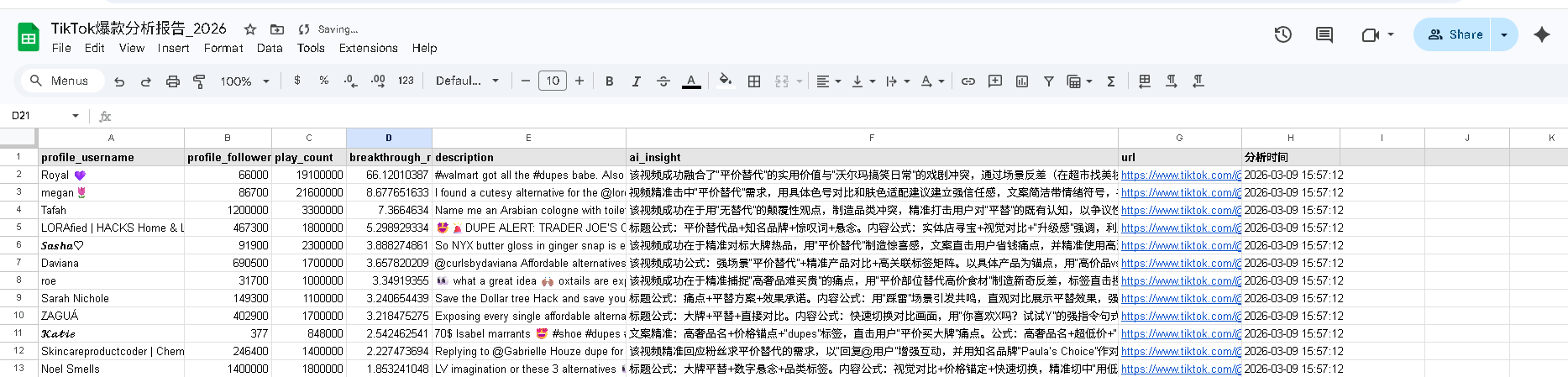
你的爆款分析报告长这样 → 点击注册,今天就建立你自己的数据系统 →https://get.brightdata.com/yp8cjb
实测结果数据
- 实测结果(关键词:#dupe alternative,抓取量:200条)
- 有效数据:195条(有效率97.5%)
- 筛选出突破性内容:12条
- AI分析耗时:约45秒
- 全流程总耗时:约8分钟
9.代码片段7:主流程执行函数
python
# ================= 5. 主流程执行 =================
def main():
#1. 触发爬虫api
snapshot_id = trigger_brightdata_task("#dupe alternative",2000)
# 2.下载爬取结果
download_snapshot_result(snapshot_id,INPUT_JSON_FILE)
# 3. 从文件加载数据
df = load_and_clean_data(INPUT_JSON_FILE)
if df.empty:
return
# beauty_dupe_keywords:在数据清洗阶段,快速剔除无关噪音。
# 只有标题或描述中包含以下"列表值"的视频,才能通过这第一道关卡,
# 进入后续的统计计算环节。这能大幅减少计算量并聚焦核心赛道。
beauty_dupe_keywords = [
'dupe', 'dupes',
'alternative', 'alternatives',
'swap', 'swaps'
]
# 4. 筛选突破性内容
print("🔍 正在计算统计指标并筛选...")
breakthroughs = find_breakthroughs(df, keywords=beauty_dupe_keywords)
if breakthroughs.empty:
print("未找到符合条件的突破性内容。")
return
print(f"🎯 识别出 {len(breakthroughs)} 条突破性内容。")
# 5. 熔断保护:最多只分析 Top 20
MAX_TO_ANALYZE = 2000
if len(breakthroughs) > MAX_TO_ANALYZE:
print(f"⚠️ 触发熔断:仅分析表现最好的 Top {MAX_TO_ANALYZE} 条。")
breakthroughs = breakthroughs.head(MAX_TO_ANALYZE)
# 6. 调用 AI
print("🤖 正在调用大模型进行深度归因...")
breakthroughs['ai_insight'] = breakthroughs.apply(analyze_with_llm, axis=1)
# 7. 导出到 Google Sheets
export_to_google_sheets(breakthroughs, SPREADSHEET_NAME, WORKSHEET_NAME)
if __name__ == "__main__":
main()
功能解析:该片段为主流程执行模块,按顺序调用上述所有函数,串联起"触发爬取→下载数据→清洗数据→筛选爆款→AI分析→导出表格"全流程,同时设置熔断保护,仅分析Top20优质爆款,避免资源浪费。
10.完整代码
python
import os
os.environ["HTTP_PROXY"] = "http://127.0.0.1:7897"
os.environ["HTTPS_PROXY"] = "http://127.0.0.1:7897"
os.environ["NO_PROXY"] = "api.deepseek.com"
os.environ["NO_PROXY"] = "api.brightdata.com"
import pandas as pd
import json
import time
import os
from openai import OpenAI
import gspread
from google.oauth2.service_account import Credentials
import requests
# ================= 配置区域 =================
Liang_KEY = '替换Bright Data的key'
API_KEY = "替换大模型的key"
MODEL_NAME = "deepseek-chat"
BASE_URL = "https://api.deepseek.com/v1"
# 文件路径配置
INPUT_JSON_FILE = "tiktok_data.jsonl" # 爬取的数据文件路径
CREDENTIALS_FILE = "credentials.json" # 凭证:Google Cloud 下载的 JSON
# Google Sheets 配置
SPREADSHEET_NAME = "TikTok爆款分析报告_2026"
WORKSHEET_NAME = "今日洞察"
# ✅ DeepSeek 兼容 OpenAI SDK
client = OpenAI(api_key=API_KEY, base_url=BASE_URL)
# ================= 1. 触发Bright Data Api,进行爬取内容 =================
def trigger_brightdata_task(keyword, num_of_posts=500, country=""):
headers = {
"Authorization": f"Bearer {Liang_KEY}",
"Content-Type": "application/json.json",
}
data = json.dumps({
"input": [{"search_keyword": keyword, "num_of_posts": num_of_posts, "country": country}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_lu702nij2f790tmv9h¬ify=false&include_errors=true&type=discover_new&discover_by=keyword",
headers=headers,
data=data
)
snapshot_id = response.json().get("snapshot_id")
print("snapshot_id:", snapshot_id)
return snapshot_id
# ================= 2. 触发Bright Data Api,获取爬取结果 =================
def download_snapshot_result(snapshot_id, output_file="tiktok_data.jsonl", poll_interval=120):
url = f'https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}'
headers = {
"Authorization": f"Bearer {Liang_KEY}",
"Content-Type": "application/json.json",
}
# 定义期望的 Content-Type(支持部分匹配)
expected_content_type = "application/jsonl"
while True:
try:
response = requests.get(
url, headers=headers, stream=True,
proxies={"http": None, "https": None}
)
response.raise_for_status()
content_type = response.headers.get('Content-Type', '').lower()
if expected_content_type in content_type:
print("✅ 数据爬取成功!")
break
else:
print(f"正在爬取,{poll_interval//60} 分钟后尝试获取爬取结果...")
time.sleep(poll_interval)
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
time.sleep(poll_interval)
with open(output_file, 'wb') as file:
for chunk in response.iter_content(chunk_size=8192):
file.write(chunk)
print(f"✅ Download completed: {output_file}")
return output_file
# ================= 3. 加载数据 =================
def load_and_clean_data(file_path):
df = pd.read_json(file_path, lines=True) # 直接读 JSONL
df = df[~df["error"].notna()] if "error" in df else df
df = df[df["digg_count"].notna() & df["description"].notna()]
print(f"✅ 数据加载完成:有效 {len(df)} 条")
return df
# ================= 2. 统计分析与筛选逻辑 =================
def find_breakthroughs(df,keywords):
if df.empty:
return pd.DataFrame()
# 预处理:确保所有关键词都是小写字符串,去除空格
target_keywords = [str(k).lower().strip() for k in keywords]
df = df.copy()
# --- 1. 数据清洗:确保数值列是数字 ---
count_cols = ['digg_count', 'comment_count', 'share_count', 'collect_count']
for col in count_cols:
if col in df.columns:
df[col] = pd.to_numeric(df[col], errors='coerce')
else:
df[col] = 0
df[count_cols] = df[count_cols].fillna(0)
# 计算综合互动分
df['score'] = (df['digg_count'] * 1) + \
(df['comment_count'] * 2) + \
(df['share_count'] * 3) + \
(df['collect_count'] * 4)
def check_topic(row,t_keywords):
# 1. 获取描述,确保是字符串并转小写
desc = str(row.get('description', '') or '').lower()
# 2. 获取标签列表
tags_raw = row.get('hashtags')
# 3. 如果 tags_raw 是 NaN (float) 或 None,则视为空列表;否则保持原样
if not isinstance(tags_raw, list):
tags_list = []
else:
tags_list = tags_raw
# 同时也把标签转成小写字符串,方便匹配
tags_list = [str(tag).lower() for tag in tags_raw]
# 4. 检查描述中是否包含【任意一个】目标关键词
# 遍历列表,只要有一个词在描述里,就为 True
has_keyword_in_desc = any(k in desc for k in t_keywords)
# 5. 检查标签中是否包含【任意一个】目标关键词
# 双重 any。外层遍历标签,内层遍历关键词列表
has_keyword_in_tags = any(
any(k in tag for k in t_keywords)
for tag in tags_list
)
return has_keyword_in_desc or has_keyword_in_tags
# 应用函数
# 使用 lambda 将 target_keywords 传递给 check_topic 函数
df['is_target_topic'] = df.apply(lambda row: check_topic(row, target_keywords), axis=1)
# ---------------------------------------
target_df = df[df['is_target_topic'] == True].copy()
if target_df.empty:
print(f"⚠️ 未找到与关键词 {target_keywords} 相关的内容。")
return pd.DataFrame()
print(f"✅ 关键词 [{', '.join(target_keywords)}] 筛选出 {len(target_df)} 条相关数据。")
# 计算统计指标
mean_score = target_df['score'].mean()
std_score = target_df['score'].std()
# 防止除以零或标准差为空
if std_score == 0 or std_score is None or pd.isna(std_score):
target_df['z_score'] = 0
else:
target_df['z_score'] = (target_df['score'] - mean_score) / std_score
# 防止除以零
if mean_score == 0 or pd.isna(mean_score):
target_df['breakthrough_ratio'] = 0
else:
target_df['breakthrough_ratio'] = target_df['score'] / mean_score
# 筛选策略
breakthroughs = target_df[(target_df['z_score'] > 0.5) | (target_df['breakthrough_ratio'] > 1.5)]
if not breakthroughs.empty:
print(breakthroughs.sort_values(by='z_score', ascending=False))
return breakthroughs.sort_values(by='z_score', ascending=False)
# ================= 3. LLM 分析函数 =================
def analyze_with_llm(row):
desc = row['description'][:150] # 截断过长描述
followers = row['profile_followers']
ratio = row['breakthrough_ratio']
plays = row['play_count']
size_label = "微型账号 (<1w)" if followers < 10000 else \
"小型账号 (1w-10w)" if followers < 100000 else \
"中型账号 (10w-100w)" if followers < 1000000 else \
"大型账号 (>100w)"
prompt = f"""
你是一位 TikTok 美妆赛道增长专家。
发现了一条在 "平价替代 (Dupes)" 赛道表现异常突出的视频。
【数据概览】
- 账号体量:{size_label} ({followers:,} 粉丝)
- 播放量:{plays:,}
- 突破指数:是同类平均水平的 {ratio:.2f} 倍
- 视频文案:"{desc}"
【任务】
请分析它为什么能跑赢平均水平?总结一个可复制的标题/内容公式。
【输出要求】
只输出一段简练的中文洞察 (80 字以内),直接给出结论。
"""
try:
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=100,
timeout=10
)
result = response.choices[0].message.content.strip()
print(f"\n✅ AI 返回结果 ({row['url']}):\n{result}\n")
return response.choices[0].message.content.strip()
except Exception as e:
return f"❌ AI Error: {str(e)}"
# ================= 4. 导出到 Google Sheets =================
def export_to_google_sheets(df, sheet_name, worksheet_name):
print(f"📡 正在连接 Google Sheets: '{sheet_name}'...")
scopes = [
'https://www.googleapis.com/auth/spreadsheets',
'https://www.googleapis.com/auth/drive'
]
if not os.path.exists(CREDENTIALS_FILE):
print(f"❌ 错误:找不到凭证文件 '{CREDENTIALS_FILE}'。")
return None
try:
creds = Credentials.from_service_account_file(CREDENTIALS_FILE, scopes=scopes)
gc = gspread.authorize(creds)
except Exception as e:
print(f"❌ Google 授权失败:{e}")
return None
try:
sh = gc.open(sheet_name)
print(f"📂 找到现有表格: {sheet_name}")
except gspread.exceptions.SpreadsheetNotFound:
sh = gc.create(sheet_name)
print(f"✨ 创建新表格: {sheet_name}")
try:
worksheet = sh.worksheet(worksheet_name)
worksheet.clear()
print(f"🧹 清空工作表: {worksheet_name}")
except gspread.exceptions.WorksheetNotFound:
worksheet = sh.add_worksheet(title=worksheet_name, rows=100, cols=20)
print(f"➕ 新建工作表: {worksheet_name}")
# 准备数据列
cols_to_export = ['profile_username', 'profile_followers', 'play_count', 'breakthrough_ratio', 'description',
'ai_insight', 'url']
available_cols = [c for c in cols_to_export if c in df.columns]
df_export = df[available_cols].copy()
df_export['分析时间'] = time.strftime("%Y-%m-%d %H:%M:%S")
data_values = [df_export.columns.tolist()] + df_export.values.tolist()
worksheet.update(values=data_values, range_name='A1')
worksheet.format('A1:Z1',
{'textFormat': {'bold': True}, 'backgroundColor': {'red': 0.9, 'green': 0.9, 'blue': 0.9}})
print(f"✅ 成功导出 {len(df_export)} 条数据到 Google Sheets!")
print(f"🔗 查看链接: {sh.url}")
return sh.url
# ================= 5. 主流程执行 =================
def main():
#1. 触发爬虫api
snapshot_id = trigger_brightdata_task("#dupe alternative",2000)
# 2.下载爬取结果
download_snapshot_result(snapshot_id,INPUT_JSON_FILE)
# 3. 从文件加载数据
df = load_and_clean_data(INPUT_JSON_FILE)
if df.empty:
return
# beauty_dupe_keywords:在数据清洗阶段,快速剔除无关噪音。
# 只有标题或描述中包含以下"列表值"的视频,才能通过这第一道关卡,
# 进入后续的统计计算环节。这能大幅减少计算量并聚焦核心赛道。
beauty_dupe_keywords = [
'dupe', 'dupes',
'alternative', 'alternatives',
'swap', 'swaps'
]
# 4. 筛选突破性内容
print("🔍 正在计算统计指标并筛选...")
breakthroughs = find_breakthroughs(df, keywords=beauty_dupe_keywords)
if breakthroughs.empty:
print("未找到符合条件的突破性内容。")
return
print(f"🎯 识别出 {len(breakthroughs)} 条突破性内容。")
# 5. 熔断保护:最多只分析 Top 20
MAX_TO_ANALYZE = 2000
if len(breakthroughs) > MAX_TO_ANALYZE:
print(f"⚠️ 触发熔断:仅分析表现最好的 Top {MAX_TO_ANALYZE} 条。")
breakthroughs = breakthroughs.head(MAX_TO_ANALYZE)
# 6. 调用 AI
print("🤖 正在调用大模型进行深度归因...")
breakthroughs['ai_insight'] = breakthroughs.apply(analyze_with_llm, axis=1)
# 7. 导出到 Google Sheets
export_to_google_sheets(breakthroughs, SPREADSHEET_NAME, WORKSHEET_NAME)
if __name__ == "__main__":
main()到这里我们的实战就结束了,本文所展示的只是Bright Data平台的冰山一角,无论你是创业者、内容运营者,还是技术团队,Bright Data TikTok Web Scraper API 都能帮你省下数周开发时间,降低90%维护成本,快速验证商业模式,抢占垂直内容赛道先机。👉 立即免费试用
结语
爬虫不是目的,数据才是资产;自动化不是终点,创造才是意义。希望这篇文章能为你打开一扇门!
❓ 常见问题解答 (FAQ)
Q: 这套系统每天运行成本大概是多少?
A: 成本主要取决于抓取量。Bright Data 按成功抓取的数据量计费,通常几百条数据的成本仅为几美分。加上 DeepSeek API(极低廉)和 Google Sheets(免费额度内),每日运行成本可控制在 1 美元以内。
Q: 没有 Python 基础能用吗?A: 完全没有问题。 虽然本文提供了 Python 代码以实现全自动化流程,但非技术用户可以直接在 Bright Data 控制台使用可视化模式运行同款 TikTok 抓取器。你无需写一行代码,只需在界面配置关键词,结果同样可以一键导出为 CSV/JSON,轻松完成数据分析。
Q: Bright Data TikTok API 和直接买数据集有什么区别?A: API 适合需要实时监控、按特定关键词即时抓取最新内容的场景;而 Dataset 是预先抓取好的历史静态数据包。若需追踪实时热点,请选择 Web Scraper API。
Q: 抓取 TikTok 数据合规吗?会封号吗?A: Bright Data 是企业级合规服务商,严格遵循 GDPR/CCPA 法规。其内置的代理网络和反指纹技术模拟真实用户行为,无需登录个人账号即可抓取公开数据,因此不会导致您的个人账号被封禁。
Q: 这套流程能换成其他垂类关键词吗?A: 完全可以。只需在主函数 trigger_brightdata_task 中修改 keyword 参数(例如改为 "#skincare routine" 或 "#tech gadgets"),系统即可自动适配新的垂类进行爆款挖掘。