预制链
LangChain已经事先做好了很多LCEL链,我们在之前的 基于Web网页的RAG实战 中已经接触过三种链:
- create_stuff_documents_chain
- create_retrieval_chain
- load_summarize_chain
更多内置LCEL链可见 LangChain官方 查询。
但是注意:在"Deprecated classes"和"Deprecated functions"中的属于被声明废弃,不建议使用。🌰:MapReduceDocumentsChain
今天,我们就简单看看几个常用的预置链及其使用。
create_stuff_documents_chain
专注于处理和管理文档上下文,是构建RAG(检索增强生成)系统的基石。它将所有检索到的文档内容拼接成一个长字符串,作为上下文注入Prompt。优点 是简单、只需一次LLM调用;缺点是受限于模型的上下文窗口长度。
ini
chain = create_stuff_documents_chain(client, prompt)
res = chain.invoke({"input": "会议具体说了哪些内容?", "context": documents})
print(res)create_retrieval_chain
是RAG(检索增强生成)流程的完整封装链,它标准化了检索增强生成的工作流程:
- 输入处理:接收用户问题
- 文档检索:调用检索器(通常是向量数据库)获取相关文档
- 上下文装配:将检索到的文档与原始问题组合
- 答案生成:将组合后的上下文发送给LLM生成答案
- 输出标准化:返回包含答案、原始问题和检索上下文的统一格式
通常与create_stuff_documents_chain结合使用。
python
# 6. 创建文档处理链
print("步骤4: 创建文档处理链...")
document_chain = create_stuff_documents_chain(llm, prompt)
# 7. 创建完整的检索链
print("步骤5: 创建检索链...")
rag_chain = create_retrieval_chain(retriever, document_chain)
# 测试
for i, question in enumerate(test_questions, 1):
print(f"\n问题 {i}: {question}")
print("-" * 30)
# 执行RAG流程
result = rag_chain.invoke({"input": question})
print(f"答案: {result['answer']}")
print(f"\n检索到的文档数量: {len(result['context'])}")
load_summarize_chain
用于文档摘要的预构建解决方案,能够自动处理超出模型上下文长度的长文档。核心价值在于自动处理长文档分块、摘要策略选择和迭代优化,避免用户手动实现复杂的摘要流水线。
核心
-
策略选择指南:
stuff:文档总长度小于模型上下文窗口的80%时使用,最简单快速map_reduce:处理超长文档(如书籍、长报告),支持并行处理refine:需要最高质量摘要的场景,可生成最连贯的结果map_rerank:为每个分块评分并选择最佳摘要,适用于多文档汇总
-
性能优化建议:
- 对于
map_reduce策略,可设置max_concurrency参数控制并行度 - 使用
return_intermediate_steps=True调试复杂文档的摘要过程 - 长文档摘要时考虑使用GPT-4等更大上下文模型
- 对于
-
生产环境注意事项:
- 添加超时和重试机制,特别是处理长文档时
- 监控token使用量,避免意外的高成本
- 缓存常见文档的摘要结果,提高响应速度
- 考虑实现增量摘要,只处理文档变化部分
代码
准备工作
python
# 1. 加载文档(这里以文本文件为例)
loader = TextLoader("./data/deepseek百度百科.txt") # 请替换为你的文档路径
documents = loader.load()
# 2. 初始化大语言模型
llm = get_ali_model_client()摘要代码
ini
# 3. 定义明确要求中文摘要的提示词模板
# 注意:{text} 是占位符,链会自动将文档内容填充到这里
prompt\_template = """请用中文,简洁地总结以下文本的主要内容:
{text}
请确保摘要完全使用中文,并涵盖核心要点。
中文摘要:"""
prompt = PromptTemplate(template=prompt\_template, input\_variables=\["text"])
# 3. 创建摘要链 - 最简单的调用方式
# **`stuff`**:文档总长度小于模型上下文窗口的80%时使用,最简单快速
# **`map_reduce`**:处理超长文档(如书籍、长报告),支持并行处理
# **`refine`**:需要最高质量摘要的场景,可生成最连贯的结果
# **`map_rerank`**:为每个分块评分并选择最佳摘要,适用于多文档汇总
chain = load\_summarize\_chain(
llm=llm,
chain\_type="stuff", # 使用stuff策略
prompt=prompt # 关键:覆盖默认prompt
)
# 4. 执行摘要
summary = chain.invoke(documents)注意事项
create_history_aware_retriever
是一个对话式RAG(Conversational RAG)的核心组件------查询重写器,其工作原理如下:
- 问题诊断:分析当前用户问题,判断是否需要对话历史来完整理解意图
- 上下文感知重写:当需要时,将对话历史与当前问题结合,生成一个独立、完整的搜索查询
- 智能检索:使用重写后的查询进行向量搜索,而非原始问题
准备工作
ini
# 2. 创建向量存储和基础检索器
print("创建向量数据库和基础检索器...")
embeddings = get_ali_embeddings
vectorstore = Chroma.from_documents(documents, embeddings)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 3})LLM初始化
ini
# 3. 初始化LLM
llm = get_ali_model_client()
# 4. 创建历史感知检索器
print("\n创建历史感知检索器...")
contextualize_q_system_prompt = """
你是一个查询重写助手。基于对话历史和最新的用户问题,创建一个独立的问题。
这个独立的问题应该包含理解用户意图所需的所有上下文。
如果对话历史是相关的,将其整合到新问题中。
如果对话历史不相关或为空,直接返回原始问题。
对话历史:
{chat_history}
用户问题:{input}
独立的问题:
"""
contextualize_q_prompt = ChatPromptTemplate.from_messages([
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
])history_aware_retriever
ini
history_aware_retriever = create_history_aware_retriever(
llm=llm,
retriever=base_retriever, # 基础检索器
prompt=contextualize_q_prompt
)
# 5. 创建对话记忆
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True,
output_key="answer"
)链整合
ini
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# 7. 创建完整的对话式RAG链
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)create_sql_query_chain
用于将自然语言问题转换为SQL查询并获取结果。它把大语言模型的理解能力、数据库的模式信息以及SQL的执行能力串联了起来,是构建"用自然语言对话数据库"应用的核心工具。
工作流程
-
输入与上下文 :接收用户自然语言问题。同时,它会自动获取你提供的数据库的模式信息(如表名、列名、列类型),作为关键上下文喂给模型。
-
模型推理:将一个组装好的提示词(包含系统指令、数据库模式、用户问题)发送给大语言模型(如GPT-4, Claude, 或本地模型)。模型的任务是根据这些信息,生成一句语法正确的SQL。
-
输出解析:对模型生成的文本进行清洗和校验,提取出纯SQL语句。
-
查询执行:使用你配置的数据库连接,执行上一步得到的SQL,并将结果返回。
代码
准备工作
python
# 1. 连接到数据库 (这里创建一个内存SQLite数据库并添加样例数据)
from sqlalchemy import create_engine, text
import pandas as pd
# 创建内存数据库引擎
engine = create_engine("sqlite:///../test_sql.db")
# 创建样例数据
with engine.connect() as conn:
# 使用此连接执行建表操作
df = pd.DataFrame({
'employee_id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'department': ['Sales', 'Engineering', 'Sales'],
'salary': [70000, 85000, 72000]
})
# 将DataFrame写入数据库
df.to_sql('employees', conn, index=False, if_exists='replace')
# 对于SQLite,最好显式提交
conn.commit()
# 使用同一个连接对象来创建LangChain的SQLDatabase对象
# db = SQLDatabase(engine=engine, engine_connection=conn)
db = SQLDatabase(engine=engine)查询链
ini
# 3. 初始化大语言模型 (此处以OpenAI为例,你需要设置自己的API_KEY)
# 实践中,完全可以用DeepSeek-V2等高性能开源模型替代
llm = get_lc_model_client()
# 4. 创建查询链!
chain = create_sql_query_chain(llm, db)
# 5. 使用链进行查询
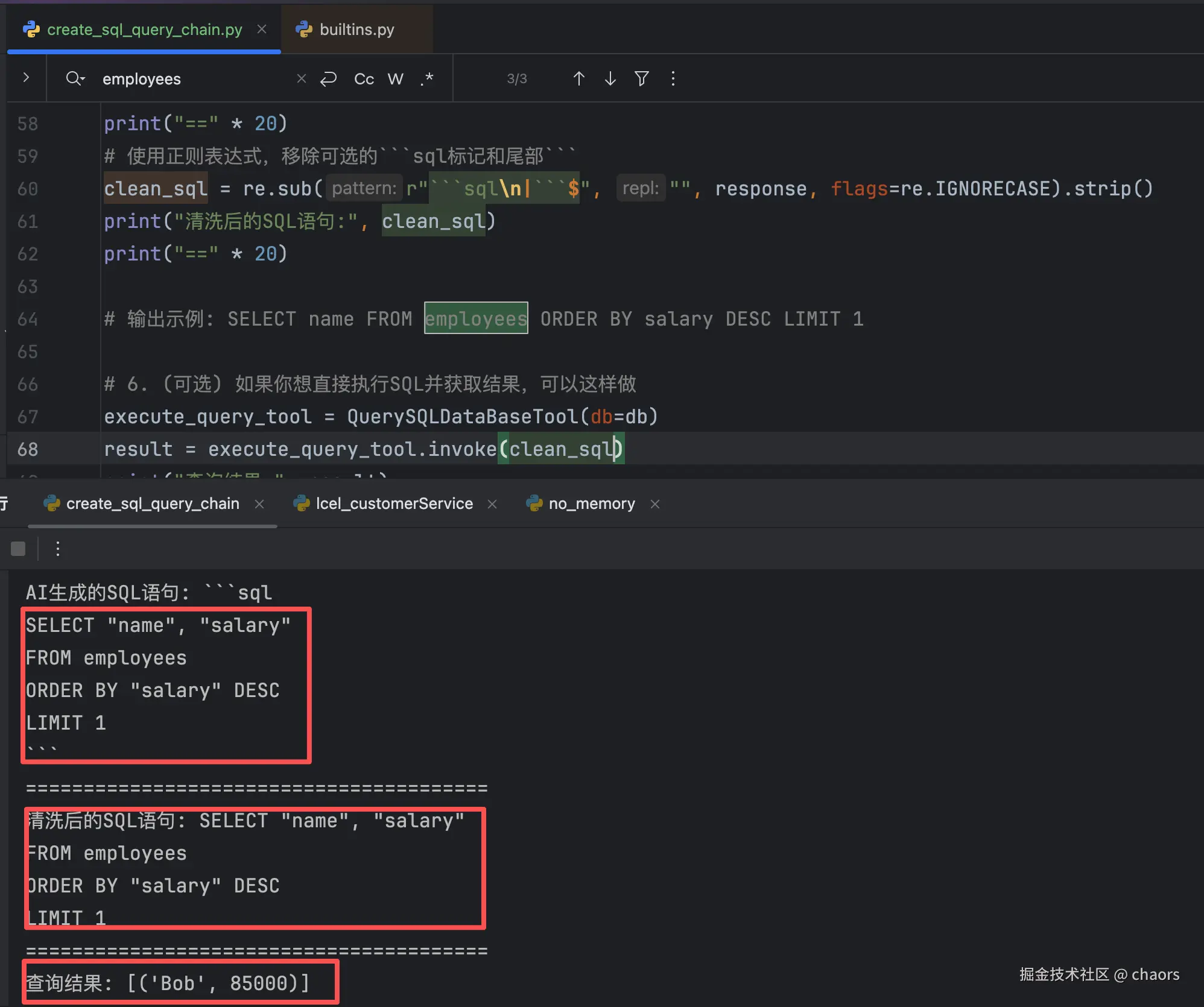
response = chain.invoke({"question": "薪资最高的员工是谁?"})
print("生成的SQL语句:", response)
# 输出示例: SELECT name FROM employees ORDER BY salary DESC LIMIT 1结果
APIChain
APIChain是 LangChain 框架中的一个高级抽象,它将大语言模型的自然语言理解能力与外部API的调用能力无缝衔接,让AI能够像使用自己的"记忆"一样,实时查询和使用外部服务与数据。
核心流程
-
理解意图:解析用户的自然语言问题,判断是否需要调用API以及调用哪个API。
-
结构化请求:将模糊的需求转化为具体的API调用参数(URL、查询参数、请求体等)。
-
处理响应:解析API返回的原始数据(通常是JSON/XML),提取关键信息。
-
整合回答:将API返回的信息组织成自然流畅的最终答案。
代码
ini
# 3. 创建APIChain
chain = APIChain.from_llm_and_api_docs(
llm=llm,
api_docs=api_docs,
limit_to_domains=["https://api.open-meteo.com"], # 只允许调用这个域名
verbose=True # 显示详细过程
)
# 4. 使用链进行查询
question = "查询北京现在的温度"
result = chain.run(question)
print(f"问题: {question}")
print(f"回答: {result}")源码