在游戏开发和实时渲染领域,Draw Call 是一个被反复提及、甚至有些被"神话"的概念。无论是经验丰富的老兵,还是刚入行的萌新,几乎都听过一句话:"Draw Call 太高了,帧率得掉。"
但你是否真正思考过:为什么几条简单的指令,就能让价值万元的显卡"原地踏步",让性能强劲的 CPU"满头大汗"? 本文将带你穿越抽象的 API,直达硬件底层,彻底看清 Draw Call 的真面目。
什么是 Draw Call?(底层视角)
从直观定义上讲,Draw Call 是 CPU 调用图形 API(如 OpenGL, DirectX, Vulkan, Metal)发出的绘制指令。
当 CPU 执行到类似 glDrawElements 或 CmdDrawIndexed 的代码时,它实际上是在对 GPU 说:"嘿,兄弟,用我刚才传给你的那堆顶点数据,配合现在挂载的这套纹理和 Shader,在屏幕的这个位置画出物体。"
渲染状态(Render State)
一个 Draw Call 绝不仅仅是一条指令,它背后挂载了庞大的状态机。在发起调用前,CPU 必须准备好:
-
着色器(Shader): 顶点着色器、片元着色器等。
-
资源(Resources): 纹理(Textures)、常量缓冲区(Constant Buffers)。
-
管线状态(Pipeline State): 混合模式、深度测试、剔除模式、拓扑结构。
核心矛盾:为什么 Draw Call 会成为瓶颈?
很多人误以为 Draw Call 耗时是因为 GPU 渲染太慢。事实恰恰相反:Draw Call 的压力几乎全部集中在 CPU 和总线通信上。
用户态到内核态的切换(Context Switch)
图形 API 通常运行在用户态,而驱动程序需要与硬件交互,必须切换到内核态。这种上下文切换在底层涉及大量的寄存器状态保存和恢复,开销极大。
驱动程序的指令翻译(Translation)
CPU 发出的 API 指令(如 DirectX 指令)并不是 GPU 硬件能直接读懂的。显卡驱动程序需要将这些高级指令"翻译"成特定显卡架构(如 NVIDIA Ada Lovelace 或 AMD RDNA 3)的机器码。如果一帧有几千个 Draw Call,驱动程序就会占用大量的 CPU 时间片进行这种重复的翻译工作。
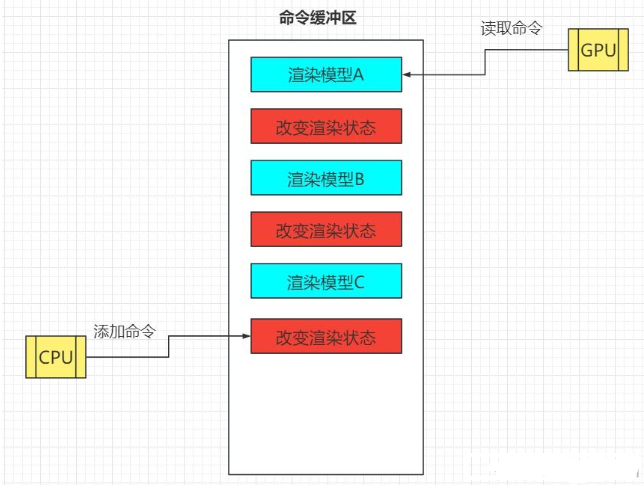
命令缓冲区(Command Buffer)的阻塞
CPU 将翻译好的指令放入命令缓冲区,GPU 异步从中读取。如果 Draw Call 过多且细碎,CPU 填充缓冲区的速度可能跟不上 GPU 消耗的速度,或者由于频繁切换状态导致 GPU 流水线(Pipeline)频繁起停(Stall),造成巨大的资源浪费。
性能损耗的数学模型
我们可以将一帧的耗时简写为:
-
:Draw Call 数量。
-
-
当 达到数千时,即便 GPU 执行速度(
)极快,前面的累加项也会迅速填满
(60帧的极限),导致 CPU 成为所谓的 CPU Bound(CPU 受限)。
工业界的"降维打击":优化策略
为了解决这个问题,图形工程师们进化出了多套组合拳:
合批(Batching):化零为整
这是最常用的手段,核心思想是减少状态切换。
-
静态合批(Static Batching): 在场景构建时,将使用相同材质的静态物体(如远处的山脉、房屋)合并成一个巨大的 Mesh。这样 CPU 只需要发一次指令,就能画出一片建筑。
-
动态合批(Dynamic Batching): 引擎在运行时,自动将一些顶点数较小的、材质相同的物体(如子弹、粒子)在内存中合并后再提交。
实例化(GPU Instancing):复制的艺术
如果你要渲染一万棵树,合批会占用海量内存。GPU Instancing 允许你只上传一份模型数据和材质,然后通过一个包含一万个位置/缩放信息的数组,一条指令完成绘制。
- 优点: 内存占用极低,CPU 压力极小。
纹理图集(Texture Atlas)
如果两个物体 Shader 一样,但贴图不同,它们依然无法合批。美术同学会将多张小图合成为一张大图。通过偏移 UV 坐标,不同的物体可以共用同一张大贴图,从而满足合批的先决条件。
现代 API 的革新(Vulkan/DX12/Metal)
传统的 DX11 或 OpenGL 像是一个"单窗口办事处",所有 Draw Call 必须排队经过一个 CPU 核心。
现代 API 引入了并行指令录制(Multi-threaded Command Buffers)。它允许 CPU 的多个核心同时录制绘制指令,大幅缓解了单核性能瓶颈。
五、 结语:性能优化的哲学
Draw Call 的优化本质上是一场关于"懒惰"的艺术。
我们并不是要减少画面的复杂程度,而是要通过算法和架构,尽量减少 CPU 与 GPU 之间那次昂贵的"握手"。
记住:最好的 Draw Call 是那个被剔除(Culling)掉的指令,其次是那个被合并(Batching)掉的指令。