2026年广东省职业院校技能大赛中职组"大数据应用与服务"赛项任务书(三)
文章目录
- 2026年广东省职业院校技能大赛中职组"大数据应用与服务"赛项任务书(三)
-
- 项目一:平台搭建与运维
- 项目二:数据获取与处理
- 项目三:业务分析与可视化
- [项目四:AI 大模型应用开发综合实践](#项目四:AI 大模型应用开发综合实践)
-
- [(一)任务一:AI 大模型服务综合部署](#(一)任务一:AI 大模型服务综合部署)
- [(二)任务二:AI 大模型综合应用开发](#(二)任务二:AI 大模型综合应用开发)
- 需要题目答案可联系博主!
需要竞赛样题答案可联系博主!!
项目一:平台搭建与运维
(一)任务一:大数据平台搭建
1.子任务一:基础环境准备
本任务需要使用 root 用户完成相关配置,安装 Hadoop 需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
(1)配置三个节点的主机名,分别为 master、slave1、slave2,然后修改三个节点的 hosts 文件,使得三个节点之间可以通过主机名访问,在 master 上将执行命令 cat /etc/hosts 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;
(2)将 /opt/software 目录下将文件 jdk-8u391-linux-x64.tar.gz 安装包解压到 /opt/module 路径中,将 JDK 解压命令复制并粘贴至【提交结
果.docx】中对应的任务序号下;
(3)在 /etc/profile 文件中配置 JDK 环境变量 JAVA_HOME 和 PATH 的值,并让配置文件立即生效,将在 master 上 /etc/profile 中新增的内容复制并 粘贴至【提交结果.docx】中对应的任务序号下;
(4)查看 JDK 版本,检测 JDK 是否安装成功,在 master 上将执行命令 java
-version 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;
(5)创建 hadoop 用户并设置密码,为 hadoop 用户添加管理员权限。在
master 上将执行命令 grep 'hadoop' /etc/sudoers 的结果复制并粘贴至
【提交结果.docx】中对应的任务序号下;
(6)关闭防火墙,设置开机不自动启动防火墙,在 master 上将执行命令 systemctl status firewalld 的结果复制并粘贴至【提交结果.docx】中对应的任务序号下;
(7)配置三个节点的 SSH 免密登录,在 master 上通过 SSH 连接 slave1 和
slave2 来验证。
2.子任务二:Hadoop 完全分布式安装配置
本任务需要使用 root 用户和 hadoop 用户完成相关配置,使用三个节点完成
Hadoop 完全分布式安装配置。命令中要求使用绝对路径,具体要求如下:
(1)在 master 节点中的 /opt/software 目录下将文件
hadoop-3.1.3.tar.gz 安装包解压到 /opt/module 路径中,将 hadoop 安装包解压命令复制并粘贴至【提交结果.docx】中对应的任务序号下;
(2)在 master 节点中将解压的 Hadoop 安装目录重命名为 hadoop,并修改该目录下的所有文件的所属者为 hadoop,所属组为 hadoop,将修改所属者的完整命令复制并粘贴至【提交结果.docx】中对应的任务序号下;
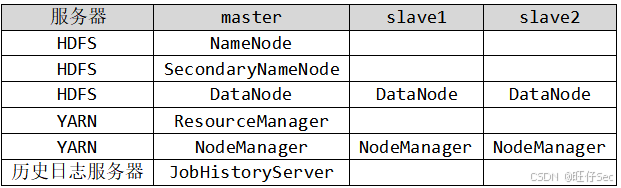
(3)在 master 节点中使用 hadoop 用户依次配置 hadoop-env.sh、 core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、 masters 和 workers 配置文件,Hadoop 集群部署规划如下表,将
yarn-site.xml 文件内容复制并粘贴至【提交结果.docx】中对应的任务序号下;
(二)任务二:数据库服务器的安装与运维
1.子任务一:MySQL 安装配置
本任务需要使用 rpm 工具安装 MySQL 并初始化,具体要求如下:
(1)在 master 节点中的 /opt/software 目录下将
mysql-5.7.25-1.el7.x86_64.rpm-bundle.tar 安装包解压到
/opt/module 目录下;
(2)在 master 节点中使用 rpm -ivh 依次安装 mysql-community-common、 mysql-community-libs、mysql-community-libs-compat、
mysql-community-client 和 mysql-community-server 包,将所有命令复制粘贴至【提交结果.docx】中对应的任务序号下;
(3)在 master 节点中启动数据库系统并初始化 MySQL 数据库系统,将完整命令复制粘贴至【提交结果.docx】中对应的任务序号下。
2.子任务二:MySQL 运维
本任务需要在成功安装 MySQL 的前提下,对 MySQL 进行运维操作,具体要求如下:
(1)配置服务端 MySQL 数据库的远程连接,将新增的配置内容复制粘贴至【提交结果.docx】中对应的任务序号下;
(2)配置 root 用户允许任意 IP 连接,将完整命令复制粘贴至【提交结果.docx】中对应的任务序号下;
(3)通过 root 用户登录 MySQL 数据库系统,查看 mysql 库下的所有表,将完整命令及执行命令后的结果复制粘贴至【提交结果.docx】中对应的任务序号下;
(4)创建 hadoop 用户,设置密码为 qwER12#$,并允许任意 IP 进行连接,将命令和完整结果截图至【提交结果.docx】中对应的任务序号下;
(5)授予 hadoop 用户拥有对所有数据库的插入数据,查询数据,删除数据权限,将命令和完整结果截图至【提交结果.docx】中对应的任务序号下;
(6)在 MySQL 数据库中创建一个名为 hddb 的数据库,并指定 utf8mb4 的字符集和 utf8mb4_unicode_ci 的排序规则,将命令和完整结果截图至【提交结 果.docx】中对应的任务序号下;
(7)创建名为hdadmin 的新用户,并授予 hdadmin 对hddb 数据库的全部权限,将创建用户及授予权限的命令截图至【提交结果.docx】中对应的任务序号下;
(8)刷新权限,并查看 hdadmin 用户的权限信息,将显示权限信息的命令和结果截图至【提交结果.docx】中对应的任务序号下;
(9)查看 MySQL 数据库的全局的默认字符集,将命令和结果截图至【提交结果.docx】中对应的任务序号下;
3.子任务三:数据表的创建及维护
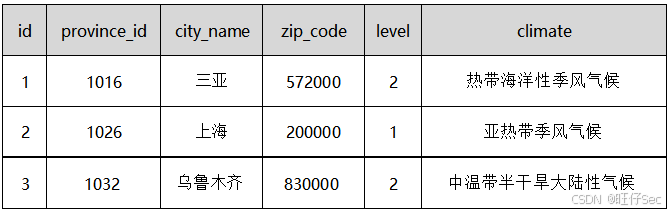
根据以下数据字段在 hddb 数据库中创建天气表(new_weather)。天气表字段如下:
| 字段 | 类型 | 列注释 | 约束 |
|---|---|---|---|
| id | INT | 城市 ID | 主键自增 |
| province_id | INT | 省份 ID | 非空 |
| city_name | VARCHAR(255) | 城市名称 | 非空 |
| zip_code | INT | 邮编 | |
| levels | INT | 城市等级 | |
| climate | VARCHAR(255) | 气候条件 |
将天气表(new_weather)的建表语句截图至【提交结果.docx】中对应的任务序号下;
向 hddb 数据库中的天气表(new_weather)中插入以下记录,并查看天气表的全部记录。将 SQL 语句和执行结果截图至【提交结果.docx】中对应的任务序号下;
为天气表添加气候介绍字段(comment),并查询天气表的结构,将 SQL 语句和结果截图至【提交结果.docx】中对应的任务序号下;
根据/opt/software/mysql 路径下的三份数据库文件(city_info.sql、 province_info.sql、weather.sql),将其导入到数据库 hddb 中。将导入命令和结果截图至【提交结果.docx】中对应的任务序号下;
对导入的三份数据进行以下操作:
(1)编写一个 SQL 查询,查询最高气温超过 30 且天气为多云的所有记录。将
SQL 语句和执行结果截图至【提交结果.docx】中对应的任务序号下;
(2)编写一个 SQL 查询,统计城市阿克苏最高气温超过 17 度的记录,并按照降序排列。将 SQL 语句和执行结果截图至【提交结果.docx】中对应的任务序号下;
(3)编写一个 SQL 查询,统计每个城市当日天气状况为多云的天数,并按照降序排列。将 SQL 语句和执行结果截图至【提交结果.docx】中对应的任务序号下;
(4)查询属于亚热带季风气候,最高气温大于 30 度且风力大于 2 级的城市名称和最高气温。将 SQL 语句和执行结果截图至【提交结果.docx】中对应的任务序号下;
项目二:数据获取与处理
(一)任务一:数据获取与清洗
1.子任务一:数据获取
现有一份气象观测数据集,包含以下字段:记录 ID、观测站 ID、观测日期、观测时间、气温(℃)、相对湿度(%)、降水量(mm)、风速(m/s)、风向、气压(hPa)、天气现象(如晴、雨、雪等)。
数据已存入 weather_observations.csv 文件中,请使用 pandas 读取该文件,并将数据集的前 10 行打印在 IDE 终端的截图复制粘贴至【提交结果.docx】中对应的任务序号下。
2.子任务二:使用 Python 进行数据清洗
从气象数据中心获取的原始数据集,已对观测站 ID 等敏感信息进行了脱敏处理。请使用 pandas 库,按照以下要求对数据进行清洗和整理:
(1)删除"降水量"为空值且"天气现象"不为"雨"或"雪"的无效记录(即疑似缺失的记录),并将结果存储为 cleaned_weather_c1_N.csv,N 为删除的数据条数;
(2)识别并删除物理上不可能的异常记录(如:气温低于-50℃或高于 50℃,气压低于 800hPa 或高于 1100hPa),将结果存储为 cleaned_weather_c2_N.csv,N 为删除的数据条数;
(3)将"观测日期"和"观测时间"两列合并为标准的 YYYY-MM-DD HH:MM:SS格式的"观测时间戳"列,并删除原两列,将结果存储为 cleaned_weather_c3_N.csv,N 为总记录条数(此项无需统计修改量,N 为处理后数据总行数);
(4)删除所有字段完全相同的重复观测记录,并将结果存储为
cleaned_weather_c5_N.csv,N 为删除的数据条数;
请将该 4 个文件名截图,复制粘贴至【提交结果.docx】中对应的任务序号下。
(二)任务二:数据标注
1.子任务一:骑行距离分类标注
使用 Python 编写脚本,根据日最高气温将每日天气情况分为"寒冷"、"凉爽"、"舒适"、"炎热"四类。具体的分类要求如下:
(1)寒冷:日最高气温 < 10℃;
(2)凉爽:10℃ ≤ 日最高气温 < 20℃;
(3)舒适:20℃ ≤ 日最高气温 < 28℃;
(4)炎热:日最高气温 ≥ 28℃。
在数据集中新增一列"气温等级",根据上述标准对每日的天气记录进行标注(需先按"观测日期"和"观测站 ID"分组计算日最高气温),存入 temperature_level.csv 文件中。具体格式如下:
| 观测日期 | 观测站 ID | 日最高气温 | 气温等级 |
|---|---|---|---|
| 2025-01-01 | STATION_001 | 8.5 | 寒冷 |
将 temperature_level.csv 打开后的前若干行直接截图,复制粘贴至【提交结果.docx】中对应的任务序号下。
2.子任务二:时段热度标注
使用 Python 编写脚本,基于"天气现象"和"降水量"字段,对降水类天气的强度进行标注。具体的分类要求如下:
(1)小雨/小雪:天气现象为"雨"或"雪",且降水量 < 10mm;
(2)中雨/中雪:天气现象为"雨"或"雪",且 10mm ≤ 降水量 < 25mm;
(3)大雨/大雪:天气现象为"雨"或"雪",且降水量 ≥ 25mm;
(4)非降水:天气现象为"晴"、"多云"、"阴"等。
在数据集中新增一列"降水强度",根据上述标准对每条观测记录进行标注,存入 precipitation_intensity.csv 文件中。具体格式如下:
| 记录 ID | 观测时间 | 天气现象 | 降水量 **(mm)** 降水强度 |
|---|---|---|---|
| 1001 | 2025-01-01 | 雨 | 15.2 中雨/中雪 |
将 precipitation_intensity.csv 打开后的前若干行直接截图,复制粘贴至
【提交结果.docx】中对应的任务序号下。
(三)任务三:数据统计
1.子任务一:HDFS 文件操作
本任务需要使用 Hadoop、HDFS 命令,具体要求如下:
(1)在 HDFS 根目录下新建目录 /weather_data/input;
(2)修改该目录权限,赋予其 755 权限;
(3)将本地清洗后的最终数据文件 cleaned_weather_c5_N.csv 上传至
HDFS 的该目录下。
请将以上三条操作的完整命令粘贴至【提交结果.docx】中对应的任务序号下。
2.子任务二:计算输入文件中的单词数
有一份从气象报告中提取的关键词文本文件 weather_keywords.txt,每行一个词。本任务要求使用 Hadoop MapReduce 完成词频统计,具体要求如下:
(1)将该文本文件上传至 HDFS 的 /weather_data/keywords 目录下;
(2)使用 Hadoop 提供的 wordcount 示例程序对该文件进行词频统计;
(3)将统计结果输出到 HDFS 的 /weather_data/keyword_count 目录下;
(4)将最终词频统计结果的前十行内容截图粘贴至【提交结果.docx】中对应的任务序号下。
3.子任务三:计算区域平均骑行时长
本任务要求使用 MapReduce 框架,计算每个观测站所在区域(根据观测站 ID
前缀划分,如 STATION_BJ_001 前缀为 BJ)的月平均气温。
(1)编写 MapReduce 程序,输入数据格式为:观测站 ID, 观测时间戳, 气温 STATION_BJ_001,2025-01-01 08:00:00, -2.5
STATION_SH_002,2025-01-01 08:05:00, 5.0
...
(2)Map 函数需要从每条记录中提取 (区域-月份) 作为键(如 BJ-202501),气温作为值;
(3)Reduce 函数需要计算每个 (区域-月份) 组合下的所有气温值的平均值;
(4)将计算结果输出到 HDFS 的 /weather_data/avg_temperature 目录下,输出格式为:
区域-月份 平均气温
BJ-202501 1.2
SH-202501 6.8
...
(5)将程序运行结果的前十行截图粘贴至【提交结果.docx】中对应的任务序号下。
项目三:业务分析与可视化
(一)任务一:数据分析与可视化
1.子任务一:数据分析
气象数据分析是理解气候变化规律、评估观测质量和服务效果的重要手段。在本任务中,您将运用 Python 对气象观测数据进行多维度分析,以获取关键洞察。参赛者需要运用 Pandas 等数据处理和分析库来完成以下任务:
(1)按观测时间统计一天中每个小时的平均温度、最高温度和最低温度,并找出日温差最大的三个时段;
(2)计算不同天气现象(如晴、雨、雪、阴、多云)下的平均温度、平均降水量和平均风速;
(3)分析不同季节(春季:3-5 月,夏季:6-8 月,秋季:9-11 月,冬季:12-2月)的温度与降水量模式差异,计算各季节的平均温度、总降水量;
(4)统计各观测站的日最高气温极值和日最低气温极值,识别出高温区域和低温区域;
(5)分析降水量等级(无降水:0mm,小雨:0-10mm,中雨:10-25mm,大雨:>25mm)与平均相对湿度、平均风速之间的关系;
请将该 5 项统计结果在 IDE 的控制台中格式化打印,并分别截图复制粘贴至
【提交结果.docx】中对应的任务序号下。
2.子任务二:数据可视化
在本任务中,参赛者将使用 pyecharts 库创建直观、互动的图表,以揭示气象数据中的时空模式和关联关系。具体要求如下:
(1)创建时间热力图展示一周内各时段(小时)的温度分布,横轴为星期(周一至周日),纵轴为小时(0-23 时),颜色冷暖表示温度高低;
(2)使用多系列折线图展示一年中(按月份)的温度变化趋势,图中需要包含平均气温、历史同期最高气温和最低气温三条折线,以便进行对比;
(3)制作风向玫瑰图,展示特定区域(如某城市)在特定时期内(如一个季度)的风向频率分布,使用扇区表示风向,半径长度表示该风向出现的频率;
(4)创建散点图分析温度与相对湿度的关系,横轴为温度(℃),纵轴为相对湿度(%),每个点的大小可表示观测时的风速,颜色表示天气现象(晴、雨等);
请将该 4 个可视化图表分别截图复制粘贴至【提交结果.docx】中对应的任务序号下。
(二)任务二:业务分析
在气象服务中,准确评估数据质量、理解气候规律并优化预报服务至关重要。通过分析历史观测数据,可以诊断观测网络效能、验证模型准确性并为服务改进提供依据。本任务要求使用 Python 对气象数据进行深入的业务分析,目的是识别关键指标,并提出基于数据的优化建议。
使用提供的气象数据集,计算以下指标:
(1)气象数据质量评估
•数据完整性:按观测站统计各主要要素(气温、降水量、风速)的有效记录条数占总应记录条数的百分比。
•数据稳定性:计算各观测站日最高气温与日最低气温的月平均差值(日温差),分析其月际波动情况。
•异常值检出率:识别并统计超出历史同期(近五年)平均值±3 倍标准差范围
的记录数量及其占比。
(2)预报准确性对比分析
•温度预报误差:将实际观测温度与前一天发布的预报温度进行对比,计算平均绝对误差(MAE)。
•降水预报准确率:评估对于"有降水"(降水量>0)和"无降水"事件的预报准确率(命中率)。
•趋势一致性:分析预报的温度变化趋势(如升温、降温)与实际观测趋势的一
致天数占比。
(3)服务需求分析
•高温服务需求:统计日最高气温超过 35℃的天数,并分析这些高温日中不同时段(如午后)的平均湿度与风速(用于评估体感热度)。
•降水服务需求:统计中雨及以上降水事件(降水量≥10mm)的持续时长、发生时段(白天/夜间)及伴随的平均风速。
•舒适度区间分析:根据温度(18-26℃)和湿度(40%-70%)定义"人体舒适度区间",统计全年处于该区间的天数比例。
根据上述分析结果,请撰写一份简短的分析报告(300 字以内),内容应包括:
•对当前气象观测数据质量和预报准确性的核心评估结论;
•在数据收集或服务中存在的关键薄弱环节;
•至少三条基于数据分析的具体优化建议(如针对观测网络、预报模型或公众服务),并简述其预期价值。
将分析报告内容复制粘贴至【提交结果.docx】中对应的任务序号下。
项目四:AI 大模型应用开发综合实践
随着人工智能技术的快速发展,越来越多的企业和开发者希望能够使用强大的 AI 模型来处理各类任务,如自然语言处理、文本生成、自动化客服、智能推荐等。在此背景下,利用 Ollama 和 Dify 搭建一个可定制的 AI 系统成为了提升智能应用的重要途径。
通过 在 openEuler 系统上搭建一个基于 Ollama 和 Docker 的 AI 大模型平台,可以通过 Dify 平台将 Ollama 注册为模型供应商,从而实现不同服务应用效果。Dify 是一个轻量级的 AI 平台,能够快速整合模型和应用,允许用户通过简单的配置和管理,调用不同的 AI 模型提供服务。
(一)任务一:AI 大模型服务综合部署
1.子任务一:基本配置
本任务需要使用 root 用户完成相关配置,已提供操作系统镜像及需要配置前置环境,所需软件安装包均在/root/目录下。命令中要求使用绝对路径,具体要求如下:
(1)在 AI-SRV 中将操作系统镜像挂载至/media/cdrom,并实现开机自启。
(2)在 AI-SRV 中完成软件源配置文件的编写,禁用 GPG 校验,并为源数据建立缓存。
2.子任务二:环境搭建
本任务需要使用 root 用户完成相关配置,已提供 ollama 安装包及需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
(1)在 AI-SRV 中为 ollama 配置用户/组,该用户仅用于运行服务,禁止其登录系统,家目录位于/usrlshare/ollama。
(2)在 AI-SRV 中为 root 用户加入附加组 ollama。
(3)在 AI-SRV 中将文件 ollama-linux-amd64.tgz 解压安装至/usr 目录下。
(4)在 AI-SRV 中编写 SystemD 服务配置,使用服务运行专用用户完成启动,无论发生任何意外情况,服务都会进行自动重启(冷却 3 秒),以保证服务可靠运行,服务需要监听所有地址。
(5)在 AI-SRV 中启动 ollama 服务,并完成开机启动配置,最终启动 ollama服务。
(6)在 AI-SRV 中导入 1.5b.tgz 压缩文件模型至 ollama。
(二)任务二:AI 大模型综合应用开发
1.子任务一:Dify 运行环境搭建
本任务需要使用root 用户完成相关配置,已提供安装dify 及需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
(1)在 AI-SRV 中完成 Docker 环境的安装,并查看 Docker 版本信息。
(2)在 AlI-SRV 中将文件 dify-0.14.2.tar.gz 解压至/opt 路径中。
(3)在 AI-SRV 中完成 dify 镜像的导入,相关文件位于 dify-images 目录中,完成后检查镜像列表。
(4)在 AI-SRV 中完成 dify 的启动,并在客户机中访问 AI-SRV 中的 dify web服务。
(5)在客户机中访问 dify,完成用户注册,邮箱为 admin@dify.ai,用户名为 admin,密码为 Qwer1234,注册后登录 dify 管理页面。
(6)在客户机中访问 dify,完成对 ollama 模型提供商的注册。 2.子任务二:气象数据智能助手构建
本任务需要基于前置环境完成,选手须先自行完成配置,具体要求如下:
(1)根据气象数据分析场景需要, 创建空白应用 "Meteorological Data Assistant"。
(2)为用户提供气象数据智能查询功能,其中参数包含:Query(查询内容),支持以下类型的查询:
城市气候查询(如:"查询'广州'的历史平均温度、年降水量")
极端天气统计(如:"查询 2025 年广东省最高气温超过 35℃的天数")天气现象分析(如:"查询'暴雨'事件的发生频率和平均持续时间")区域对比分析(如:"对比珠三角和粤北地区的年平均风速")
气象趋势预测建议(基于历史数据的简单推演)
(3)为确保结果准确性,需要从以下多个维度提供数据支持:
基于 MySQL 数据库中的结构化气象数据( 如 hddb 数据库中的 weather、 city_info 等表)
基于清洗后的 CSV 文件(如 cleaned_weather_c5_N.csv 及相关处理结果)基于大模型的智能解析和推理能力
(4)配置提示词要求:
系统角色设定为 "气象数据分析专家"支持 SQL 查询语句的自动生成和解释
支持自然语言到气象数据分析需求的转换
输出结果需包含数据来源说明(如数据库表、CSV 文件等)
(5)运行应用,测试以下查询场景:
"查询 2025 年广州市每月平均气温和降水量"
"广东省哪个城市在 2025 年出现暴雨次数最多?" "对比深圳和珠海的风向频率分布"
"预测未来一周深圳的天气趋势(基于历史同期数据)"
"查询 2025 年广东省极端高温事件的持续时间和影响范围"
需要题目答案可联系博主!
需要竞赛样题答案可联系博主!!