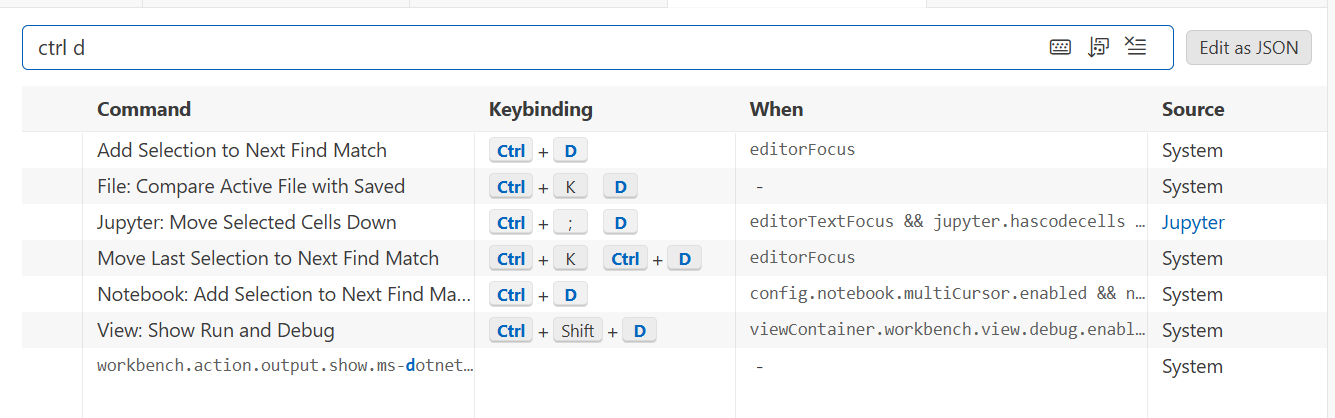
add selection to next find match,
作用是定位之后的整体光标移动,比如重点是加光标了,其实还是没什么用的感觉
alt f在当前文件找层次已经可以
-
Ctrl + Click(鼠标点击)
默认行为是 Go to Definition(跳转到定义) 。
效果:直接打开定义所在文件并跳转过去。
等价快捷键:
F12。 -
Alt + F12
这是 Peek Definition(查看定义) 。
效果:在当前编辑器里弹出一个小窗口显示定义,不离开当前文件。
- 更多有效源码 是好事
- 更多缓存、生成物、编译产物 通常不是好事
真正有价值被扫描的,通常是:
- Source
- 你自己会改的 Plugins 源码
- Config
- 少量必要脚本
- 某些你确实会读的引擎接口头文件
而"全扫"带来的坏处常常大于收益的目录是:
- Intermediate
- Binaries
- DerivedDataCache
- Saved
- .vs
原因是这些目录虽然也属于项目,但它们大多是:
- 自动生成
- 变化频繁
- 数量巨大
- 搜索噪音很多
- 对理解业务逻辑帮助很小
clangd 是 LLVM/Clang 项目的 C++ 语言服务器(Language Server) 。
简单理解:它是一个负责 代码补全、跳转定义、诊断、重构等 IDE 功能的后台服务,VSCode 只是前端 UI。
所以结构其实是:
VSCode
→ 语言服务器插件
→ 语言服务器(clangd / cpptools)
VSCode 本身并不真正理解 C++,它只是调用这些语言服务器。
微软的 C/C++ (cpptools) 更像 通用型解决方案:
-
为 VSCode 提供 IntelliSense
-
适配 Windows / Linux / Mac
-
不依赖特定编译系统
-
自动扫描 workspace 推测 include path
所以它的策略通常是:
扫描 workspace
→ 尝试推断编译环境
→ 构建索引
优点是:
开箱即用
小项目体验很好
缺点是:
大型工程容易爆炸。
UE、Chromium、LLVM 这种项目动辄:
-
十几万文件
-
巨型 include tree
-
大量宏
cpptools 就会开始:
overflow-visible!
Enumerating files
Indexing
Building IntelliSense database
于是你刚才看到:
overflow-visible!
289k files
185k C++ files
clangd 的思路完全不同
clangd 不猜工程结构,而是 直接使用真实编译信息。
它依赖一个文件:
overflow-visible!
compile_commands.json
这个文件来自编译系统(UBT / CMake / Bazel 等),里面记录:
-
每个 cpp 的编译命令
-
include path
-
宏定义
-
编译选项
例如:
overflow-visible!
clang++ -IEngine/... -DUE_BUILD ...
clangd 只会解析:
overflow-visible!
真正参与编译的文件
而不会扫描整个 workspace。
所以流程变成:
compile_commands.json
→ clangd
→ 精确语义分析
这也是为什么它在大型项目上更稳定。
为什么 UE 不默认生成?
因为 UE 默认开发工具是:
-
Visual Studio
-
Rider
-
Xcode
这些 IDE 不需要 compile_commands.json。
而 clangd / clang-based IDE 才需要。
所以 UE 只在你请求时生成。
workspace
-
myOne/ (项目)
-
UE5/ (引擎源码目录)
这是典型的 源码版 UE + 项目同级目录 的布局。
UE5/** 整体排除,会出现几个实际问题:
-
F12 无法跳转到引擎代码
-
IntelliSense / clangd 类型解析变弱
-
UE 宏、模板、容器(TArray、TObjectPtr 等)提示变差
-
编译错误定位只停留在项目层
对于 C++ UE 开发,这通常是不可接受的。
Refresh VS Code Project 是 Unreal Editor 用来 重新生成 VS Code 的工程配置文件 的操作。本质上是调用 UnrealBuildTool (UBT) 重新生成 IDE 支持文件,使 VS Code 能正确解析 UE 项目结构。
它主要做的事情可以分成四类。
第一类:重新生成 VS Code 工作区配置。
UE 会重新生成 .vscode 目录下的文件,例如:
-
tasks.json -
launch.json -
c_cpp_properties.json -
compileCommands.json(如果启用)

这在 VS Code 里叫多根工作区。
每个根目录都可以各自有自己的 .vscode。
你可以粗暴理解成:
- myOne/.vscode 管你项目
- UE5/.vscode 管引擎源码
这也解释了为什么你会看到两个。
如果你主要只是写项目代码,通常更应该关心的是:
- myOne/.vscode
而 UE5/.vscode 只有在你也打算直接读/改引擎源码时才更重要。
另外,这也意味着一件事:
- 你现在的工作区负担会比"只开 myOne"更重
- 因为你把整个 UE5 根目录也一起放进 workspace 了
是因为 "Unity 不开源" 本身直接导致只显示一个 .vscode,而是因为你通常不会把 Unity 引擎源码目录也作为一个工作区根一起打开。
所以常见情况是:
- Unity 项目里,你只打开项目目录
- 于是通常只看到项目自己的 .vscode
而 UE 这边你现在是:
- 同时打开了 myOne
- 又打开了 UE5
所以会看到两个 .vscode:
- 项目的
- 引擎目录的
Unity 和 UE 的差别更准确地说是:
- Unity 引擎源码通常不是你本地项目工作区的一部分
- UE 引擎源码/引擎目录经常会被直接放进工作区一起看
Unity 里你日常更常面对的是:
- Assets
- Packages
- Unity 提供的托管 API
你确实也会看文档、反编译、看 package 源码,但一般不会像 UE 那样长期把"整个引擎源码根目录"放在工作区里一起工作。
所以差别本质上是:
- UE:看引擎源码是高频行为
- Unity:看项目代码和包代码更常见,看整个引擎源码不是日常默认动作
换句话说:
- UE 开发常常是"项目 + 引擎一起读"
- Unity 开发更多是"项目为主,必要时查包或 API"
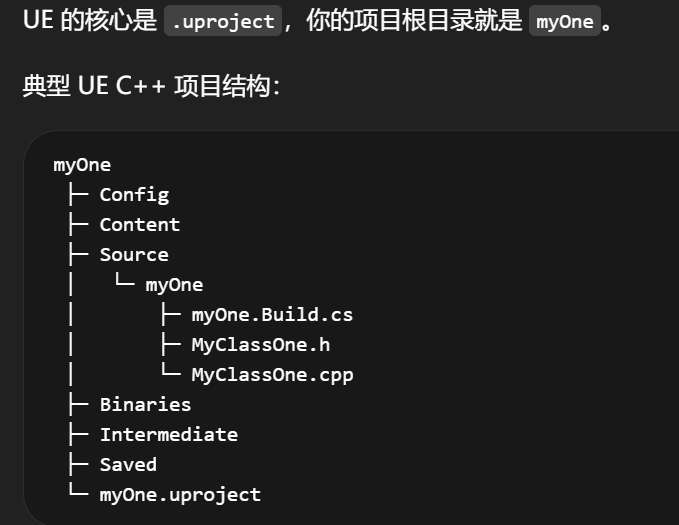
overflow-visible!
myOne.sln
.vscode
myOne.code-workspace
全部是 IDE层文件。
你截图里特殊的目录
截图里还有:
overflow-visible!
Backup
UE5
UpgradeLog.htm
这通常来自:
UE 项目升级
例如:
overflow-visible!
UE4 → UE5
UE 会自动生成:
overflow-visible!
Backup/
UpgradeLog.htm
用于记录迁移日志。
VSCode Workspace 为什么叫 workspace
workspace 只是:
overflow-visible!
IDE 的工作区
例如可以同时打开:
overflow-visible!
Engine
Project
Plugin
例如很多 UE 开发者会这样:
overflow-visible!
workspace
├─ UnrealEngine
└─ MyGame
这样可以:
-
跳转 Engine 源码
-
Debug 引擎
-
修改插件
但实际上:
overflow-visible!
UE 编译完全不依赖 workspace
UE 项目最小结构
理论最小 UE C++ 项目:
overflow-visible!
MyGame
├─ Source
│ └─ MyGame
│ ├─ MyGame.Build.cs
│ ├─ MyGame.cpp
│ └─ MyGame.h
├─ Config
├─ Content
└─ MyGame.uproject
其他:
overflow-visible!
Binaries
Intermediate
Saved
全部可以删。
UE 会自动重新生成。
我先看一下当前 myOne.code-workspace 怎么组织这两个根,这样能准确判断:把 UE5 加到哪一级的排除里,会不会把引擎源码整个隐藏掉。
Ran Get-Content .vscode/settings.json for 1s
Ran Get-Content myOne.code-workspace for 1s
Worked for 28s
不会。
按你现在这个结构,myOne/.vscode/settings.json 里的排除规则只作用在 myOne 这个根上,不会把另一个根 UE5 整个隐藏掉。
原因是你这个工作区是双根的,在 myOne.code-workspace 里明确分成了:
- myOne,路径是 .
- UE5,路径是 E:\UE_5.5
而你现在编辑的 settings.json 是 myOne 这个根自己的文件夹设置。它能排除的是:
- myOne 根下面的目录
- 比如 Binaries、Intermediate 这种
它不能跨去把同级的另一个工作区根 UE5 整个弄消失。
你可以这样记:
-
myOne/.vscode/settings.json
只管 myOne
-
UE5/.vscode/settings.json
只管 UE5
-
myOne.code-workspace 里的 "settings"
才是整个多根工作区都可能一起吃到的设置
所以如果你在当前这个 settings.json 里加类似 UE5 的排除:
- 大概率没效果
- 因为 UE5 不是 myOne 目录下的子目录
真要让引擎源码在资源管理器里整体消失,通常要么:
- 在 myOne.code-workspace 的工作区级 settings 里配排除
- 要么直接把 UE5 这个根从 workspace 里移除
所以结论是:
- 加在你当前这个 myOne/.vscode/settings.json 里,不会把引擎源码整个隐藏掉
- 真正能影响两个根的是 .code-workspace

一个实用经验是:
引擎源码只保留两类目录
Engine/Source
Engine/Shaders
其余绝大部分目录对 C++ 索引价值很低。
件事本质上属于 VSCode 的文件系统与工作区机制 ,与是否使用 clangd 并没有直接关系。
settings.json 里的这些配置:
overflow-visible!
files.exclude
search.exclude
files.watcherExclude
都是 VSCode Core 层在处理,而不是语言服务器。
它们作用在三个地方:
-
Explorer 文件树
-
全局搜索 (ripgrep)
-
文件系统 watcher
也就是说,即使没有安装任何 C++ 插件,这些规则依然生效。
需要区分一点:语言服务器是否会读取这些规则。
不同 LSP 的行为不同。
clangd
clangd 不依赖 VSCode 的 exclude。
它主要根据:
overflow-visible!
compile_commands.json
compile_flags.txt
来确定索引哪些 translation unit。
即使 VSCode Explorer 隐藏了某些目录:
overflow-visible!
Engine/Binaries
Engine/Intermediate
如果这些文件被 compile_commands.json 引用,clangd 仍然可能解析。
不过 UE 的 compile_commands.json 通常只包含:
overflow-visible!
Engine/Source
Project/Source
Plugins/Source
因此缓存目录本身不会进入 clangd 的 TU 集。
UE 编辑器启动后打开哪个关卡由 Editor Startup Map 控制,而不是自动记住上次关闭时的关卡。因此如果不配置,它通常会回到模板项目的默认关卡。
要让 UE 启动时直接进入你想继续工作的关卡,需要修改编辑器启动地图。
步骤:
-
打开
Edit → Project Settings -
找到
Project → Maps & Modes -
里面有两个关键设置:
Editor Startup Map
Game Default Map
含义:
Editor Startup Map
控制 UE编辑器启动时加载的关卡
Game Default Map
控制 游戏运行(Play/Package)时加载的关卡
- 把 Editor Startup Map 改成你常用的关卡,例如:
overflow-visible!
/Game/Maps/MainLevel
保存后,下次打开项目就会直接进入这个关卡。
如果你的需求是 "始终打开上一次关闭时的关卡"(而不是固定某个关卡),UE 默认其实有一个相关选项。
打开:
overflow-visible!
Edit
→ Editor Preferences
→ Loading & Saving
找到:
overflow-visible!
Load Level at Startup
设置为:
overflow-visible!
Last Opened
可选值通常是:
overflow-visible!
Project Default
Last Opened
设置为 Last Opened 后:
UE 会在退出时记录当前关卡,下次启动时直接恢复。
iagara (拼写:N-i-a-g-a-r-a),不是 Nigara。UE5 中 Cascade 基本已经进入维护状态,所有新特效体系都围绕 Niagara。
可编程粒子与视觉效果系统(data-driven VFX framework)
类似于:
-
Unity:VFX Graph + Particle System
-
Houdini:POP / VEX 系统
-
Frostbite:Data-driven particle graph
性能优化基本围绕三个层面:Simulation 成本、Renderer 成本、以及数据交互成本 。如果从引擎层或图形工程角度看,优化重点通常不是单一节点,而是 粒子数量、更新频率、以及 GPU/CPU 执行路径选择。下面按实际工程中最影响性能的几个方向说明。Niagara 最大的性能差异来自是否使用 GPU simulation。
CPU Niagara:
-
粒子更新在游戏线程 / worker thread
-
每个粒子逐个执行模块
-
通常粒子数量建议 < 1000--3000
GPU Niagara:
-
通过 compute shader 执行
-
可支持 10万级粒子
典型优化策略是:
小规模、需要 Gameplay 交互的特效:
overflow-visible!
CPU Niagara
大规模视觉粒子:
overflow-visible!
GPU Niagara
例如:
烟雾
火焰
魔法粒子
雪雨
几乎都应该 GPU 化。
UE 的 profiler 中可以看到:
overflow-visible!
stat Niagara
如果看到:
overflow-visible!
Niagara CPU Sim
占用明显,就说明 emitter 应该迁移到 GPU。
Niagara 确实能做出"很多粒子同时受力、碰撞、反弹、流动"这类效果,但这通常不是你脑子里那种 Chaos 刚体物理 ,而更接近 大规模并行粒子模拟 。Niagara 的核心是 System / Emitter / Module 这套粒子框架,并且支持 GPU 仿真与碰撞模块,所以它能在一个系统里同时驱动大量粒子。它大多数时候跑的不是"刚体世界",而是简化粒子动力学 。
Niagara 粒子通常只维护很少的状态:位置、速度、年龄、颜色、尺寸、朝向,再加上少量自定义属性。每帧做的常见更新也只是积分这类简单步骤:
v += a * dt,x += v * dt,外加阻尼、噪声、碰撞修正。
这和 Chaos 里每个物体都要做碰撞体管理、接触约束求解、睡眠、岛屿分解、刚体堆叠稳定化,不是一个量级。也就是说,很多 Niagara "看起来像物理"的效果,本质上只是廉价得多的粒子更新。Niagara 的碰撞能力也是通过专门的 Collision 模块提供,而不是默认进入完整刚体求解。GPU Ray Tracing Collisions 这类面向 GPU simulation 的能力;同时 Niagara 还支持 Simulation Stages / GPU 计算路径来做更复杂的迭代更新。
烟雾如果从严格 CFD 看,应该是:
-
速度场
-
压力场
-
密度场
-
温度场
这是欧拉网格表示。
但在实时 VFX 里,通常没必要完全求解。
只要让很多粒子:
-
从某区域生成
-
向上漂
-
带噪声扰动
-
生命周期渐隐
人眼就会把它识别成烟。
烟雾的感知阈值很低,粒子近似已经够骗过视觉系统。
Emitter 正好就是这个模型:
-
Spawn Rate
-
Burst
-
Shape Location
-
Initial Velocity
所以一个烟源只要配:
-
圆环 / 球 / 盒 的发射区域
-
合适 spawn rate
-
初速度
-
噪声力
烟雾主要靠统计外观,不靠单个粒子精度。
做火花时,你会很在意每个粒子的轨迹。
这些 UI 词看起来像"普通界面标签",但其实每一个都直接对应 粒子模拟管线中的一个阶段(simulation stage) 。Niagara 的 UI 本质上是在可视化一条 粒子生命周期执行图 Emitter → Spawn → Update → Render一个 Niagara System 可以包含多个 emitter。System OverviewEmitter Settings / Emitter PropertiesEmitter 是 粒子生成器实例。
一个 emitter 负责:
-
产生粒子
-
管理粒子生命周期
-
更新粒子状态
Emitter Spawnemitter 创建时执行一次。
因为"重力"这件事对粒子来说,在数值上极其便宜,而且天然适合 GPU 的数据并行模型 。
真正贵的通常不是"重力",而是:
-
碰撞
-
邻域搜索
-
约束求解
-
排序
-
透明混合 overdraw
-
CPU↔GPU 同步
-
BVH / 网格 / 场采样
对单个粒子,一帧的最基础更新通常只有这几步:
overflow-visible!
Plain text
v = v + g * dt
x = x + v * dt
如果更完整一点,再带上阻尼:
overflow-visible!
Plain text
v = (v + g * dt) * damping
x = x + v * dt
这本质上只是少量向量加法和乘法。
假设位置、速度都是 float3,每个粒子一帧也就十几个到几十个 FLOPs 量级,远远算不上复杂物理。
把同一个 kernel 扔给海量线程执行即可。
非常理想的 SIMT 负载:
-
指令一致
-
内存访问模式规则
-
很少分支
-
粒子之间独立
-
容易批量调度
这五条几乎就是"GPU 友好型算法"的教科书条件。
体地说,为什么"重力"特别便宜?
第一,它是常量场。
重力通常就是:
overflow-visible!
Plain text
g = (0, 0, -980)
所有粒子读的是同一个常量,甚至可以直接放在常量缓存里。
所以每个线程根本不需要复杂查询,也不需要随机访存。
十万独立粒子受重力 很轻,
但 十万个粒子互相碰撞 会立刻变成另一回事。
100 万粒子,每粒子每帧做 20 FLOPs,
那么一帧总共也就 2000 万 FLOPs。
对现代桌面 GPU 而言,这根本不算大。
kernel 的特点是:
-
ALU 很轻
-
控制流很平
-
occupancy 往往不错
-
dispatch 非常直接
GPU 很擅长把这种任务铺满执行单元。
粒子数很大时,GPU 反而更容易保持高利用率,因为有足够多的线程去隐藏访存延迟。
所以大量粒子的"便宜",并不只是单粒子便宜,还是因为:
总任务形状非常符合 GPU 的吞吐式架构。
每个粒子都要和场景做碰撞,可能要:
-
采样 depth
-
采样 SDF
-
射线检测
-
查询 voxel/grid
这已经比重力贵很多。
百万粒子哪怕模拟很轻,画出来也可能很贵。
尤其烟雾、火焰、雾状体这种 overdraw 很容易成为瓶颈。粒子更新轻,前提是它们作为 simulation element 彼此独立;
粒子绘制重,前提是它们作为 translucent surface sample 会在屏幕空间大量重叠。
成本基本按"粒子数"线性增长,接近:
overflow-visible!
Plain text
O(N)
因为每个粒子独立更新,不关心它最终投到屏幕上是否重叠。
GPU 的 early-z / depth test 机制。后面的被 depth reject很多 fragment 根本不会进完整 pixel shader
对 translucent particle:
- 通常不能像 opaque 那样先写深度再把后面全干掉
但对 translucent particle:后面的颜色还要参与混合所以前后层都得算、都得 blend都得 blend
如果一团烟在屏幕中心叠了 30 层,哪怕它看起来只是"一朵烟",GPU 可能真的是把那 30 层对应的 fragment 都跑了一遍。
这就是为什么 overdraw 会成为大头。

天灵盖开了的感觉,这个区别现在才意识到
最理想的实时图形状态,确实是"每个屏幕像素只被稳定地着色一次" 。
也就是你说的那种:结果在逻辑侧尽量收敛,最后映射到屏幕时,接近"分辨率级别的一次性落图"。
这是对的,而且整个现代图形优化几乎都在朝这个方向逼近。
从信息论角度看,最终输出带宽是有限的,而场景内部中间表示往往是远大于输出分辨率的。于是整个图形系统天然会出现一个问题:
哪些中间复杂度是必须保留到最后的,哪些应该尽早消掉?
Pixel shading,如果按 GPU pipeline 的语义讲,确实就是:
某个 rasterized fragment 已经通过到达 fragment/pixel stage,GPU 开始执行对应的 pixel shader,用来求这个 sample/fragment 的颜色、透明度或其他输出。
所以你说"每个都不可避免要写 pixel shader",这个说法在很多具体路径里要分情况:
不是"所有进入 raster 的东西都一定完整执行 pixel shader",而是:
凡是最终没能在 pixel stage 之前被拒绝、合并、替代或降级的贡献,都会在那里付账。
这才是更准确的说法。
这个 primitive / particle / volume contribution 要不要参与当前视图?
这里会发生:
-
culling
-
LOD
-
clustering / binning
-
coarse visibility
-
bounds reject
-
instance reject
第二道门:
它投影后形成的这些 fragments,哪些 actually 值得着色?
这里会发生:
-
early-z
-
hierarchical-z
-
coarse coverage reject
-
stencil/depth reject
-
alpha/mask 的一部分优化
-
coarse test / tile test
第三道门:
真正执行 pixel shader,为 surviving fragment/sample 生成颜色。
你说的 pixel shading 就是第三门。
而我说"最好在 pixel shading 之前收敛",意思是尽量在前两门多解决问题。
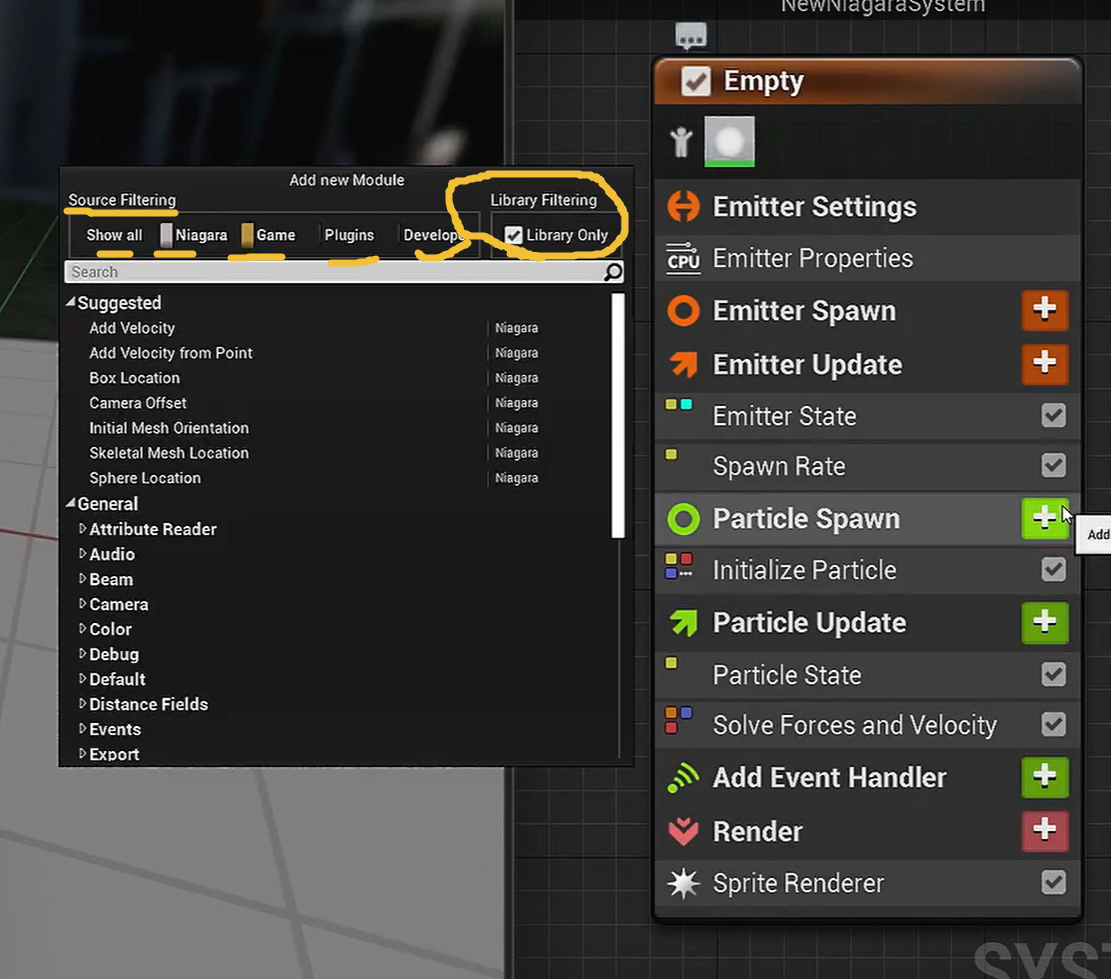
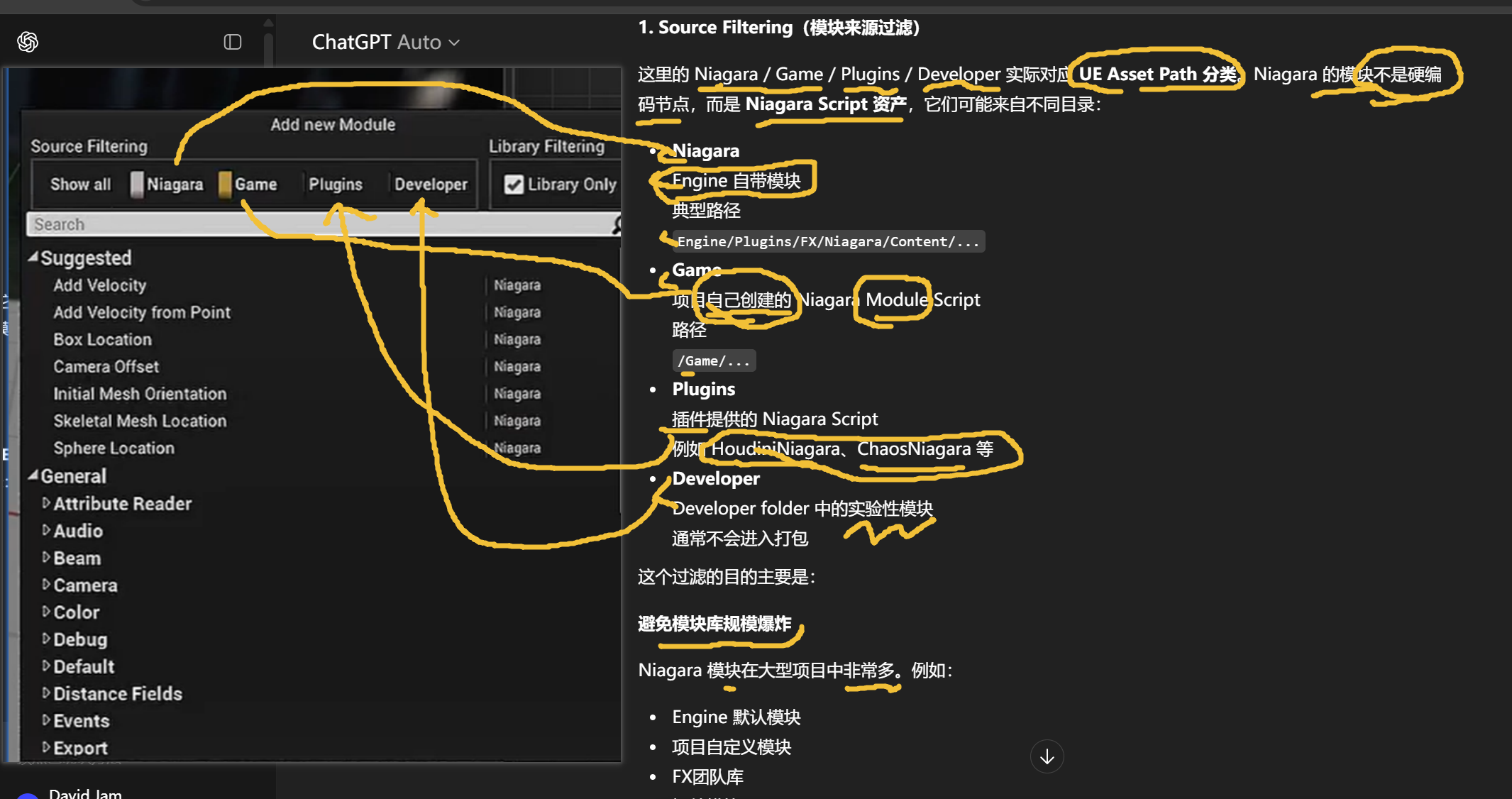
Niagara Module Add(模块添加窗口) 的过滤 UI。Niagara 模块资产体系(Script Asset System) 下解决三个问题:模块来源、资产规模和可维护性。

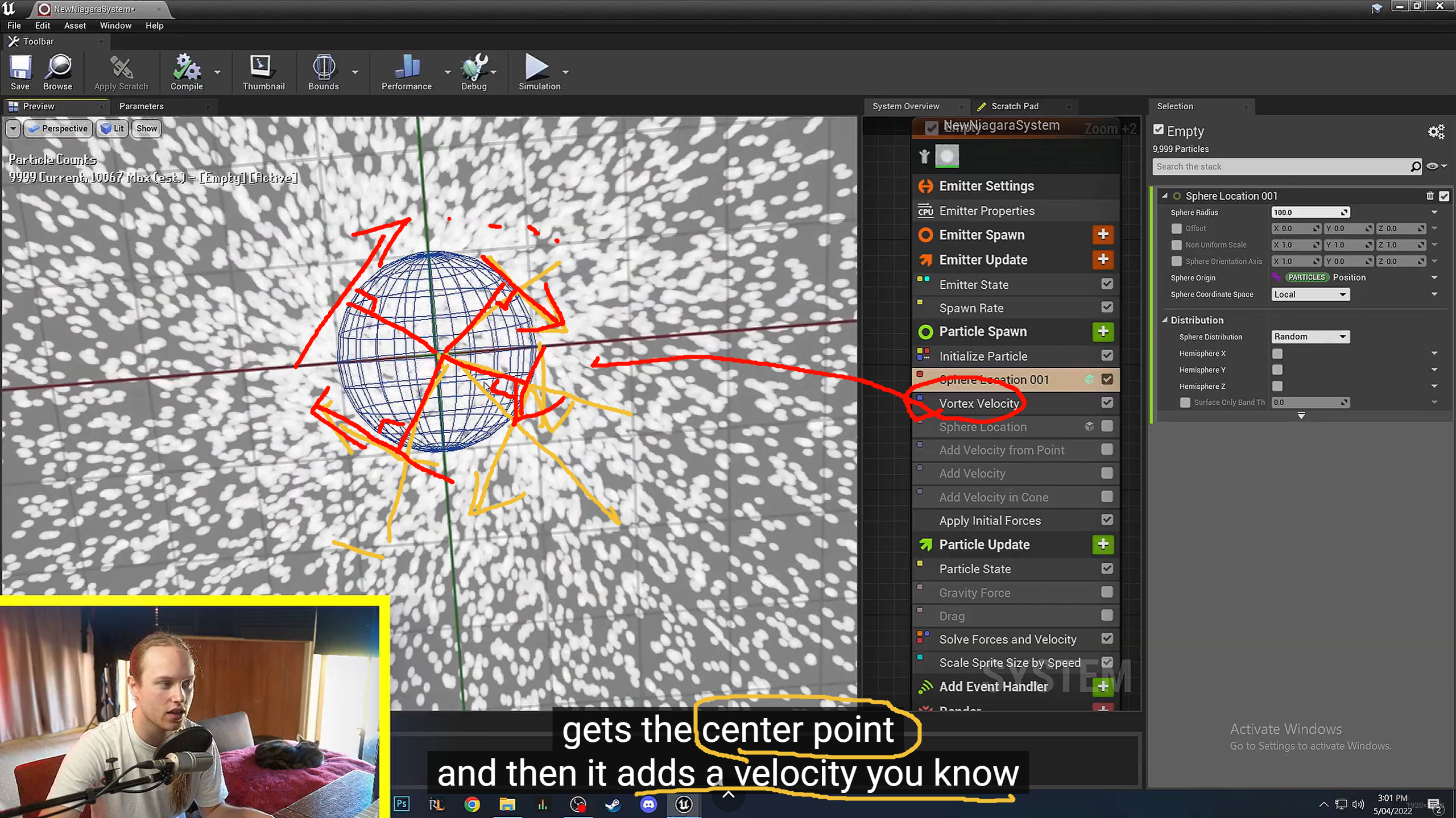
都是属于逻辑端的计算,重点在?我已经理解?
ue 全蓝图节点介绍,了解每个部分的计算占用多少,或者说建立直觉
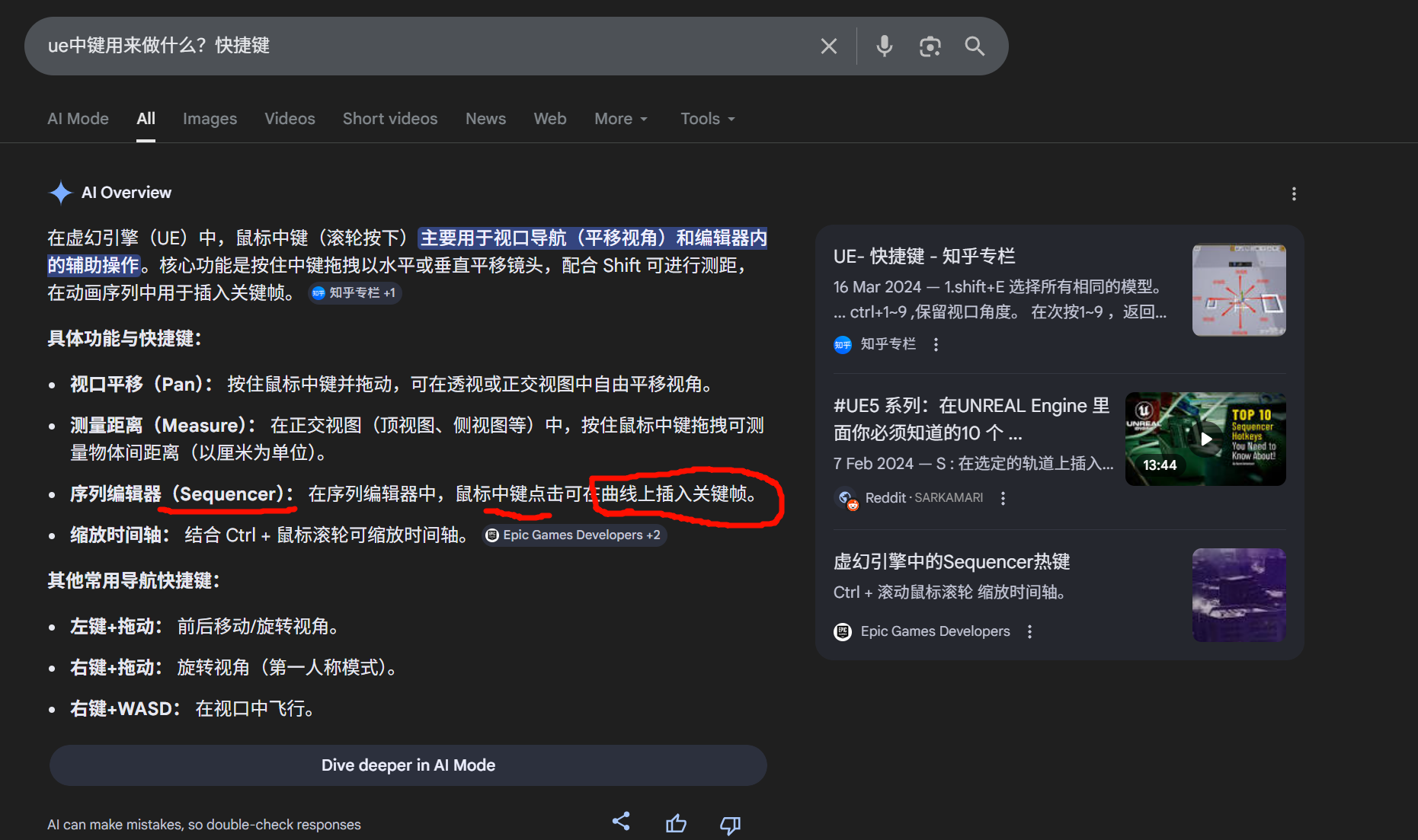
Render Graph / Frame Graph 系统。
Renderer 主调度流程 。Scene representation(场景数据结构) 。Scene representation(场景数据结构)。GPU driven pipeline
MeshDrawCommand 体系就是为了减少:
overflow-visible!
PSO switch
Root signature change
Descriptor binding
这部分本质是 CPU → GPU 提交架构。
做 DX12 / Vulkan / GPU-driven rendering,这一层非常关键。
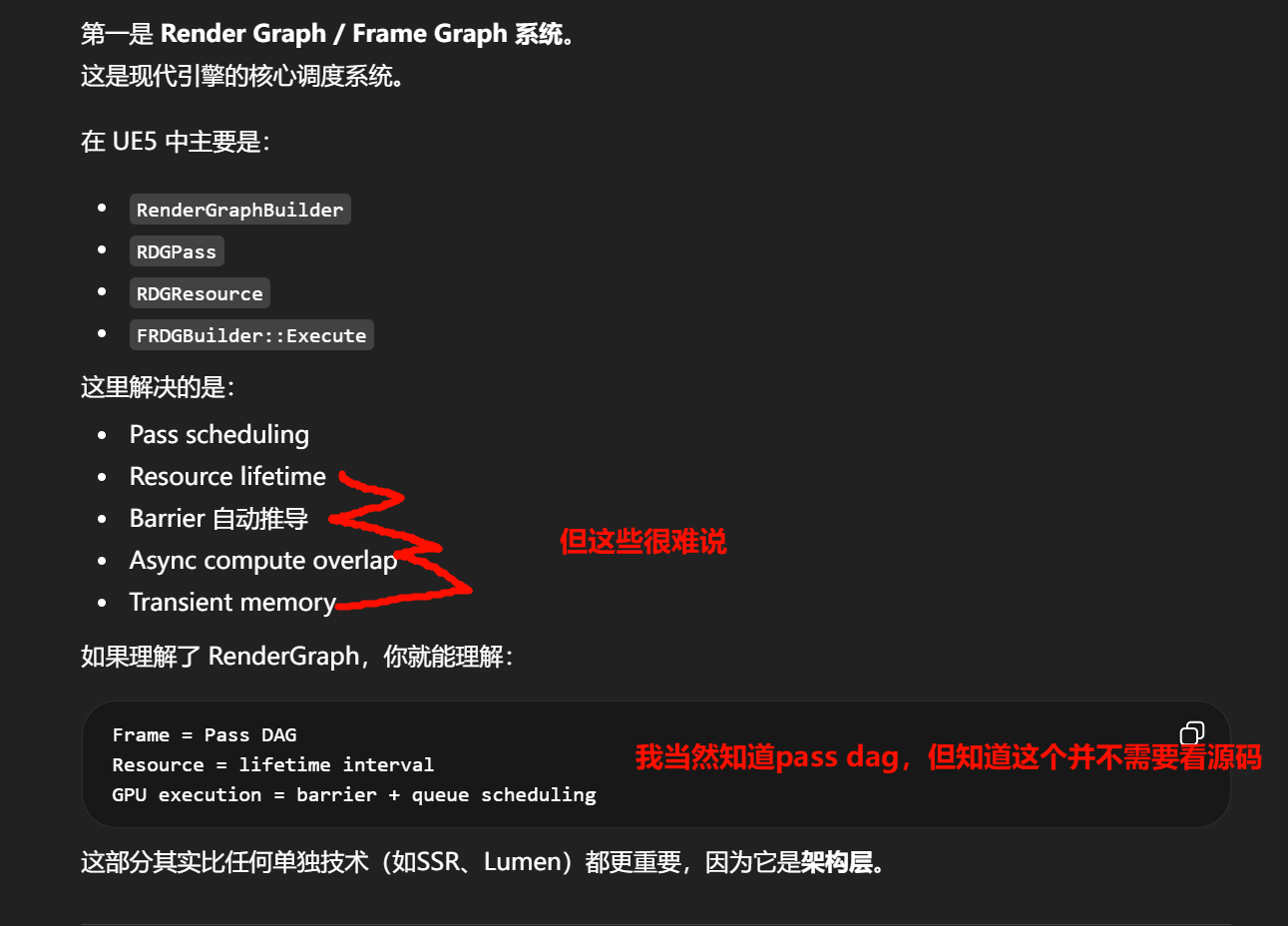
资深者的角度,--为什么需要编程语言?
人类无法直接规模化编写机器指令
CPU只理解极少量形式的指令,例如:
-
x86 / ARM 指令
-
Load / Store / Branch
-
SIMD / Vector 操作
理论上所有软件都可以直接写机器码或汇编。但问题是:
-
指令粒度极低(单条指令只做极小操作)
-
没有结构化表达
-
无类型系统
-
无模块化
抽象层:把"计算模型"表达为可组合结构
现代语言实际上在表达三类抽象:
控制流抽象
if / for / coroutine / async
对应底层
branch / jump / stack
数据抽象
struct / class / ECS / SoA
对应底层
memory layout + pointer arithmetic
计算抽象
lambda / template / generics / shader graph
对应底层
function pointer + code generation
语言把这些模式固化,使得复杂系统可以通过组合构建。
例如:
Unity DOTS 的 ECS
Component
System
Entity
本质上只是:
SoA memory + iteration
但语言级表达极大降低理解成本。
为什么 ECS 运行更快?
- 缓存命中率 (Cache Locality) :传统 OOP 对象散落在内存各处,而 ECS 将相同类型的组件数据连续存储在内存块(Chunks)中,CPU 访问时能极大地减少 Cache Miss。
- 并行计算 :由于数据组织规整且逻辑解耦,ECS 天然适合配合 C# Job System 实现多线程并行处理。
- SIMD 优化 :配合 Burst Compiler,ECS 代码可以被转换为高度优化的机器码,充分利用 CPU 的向量化计算指令。

ECS 在 2026 年的定位更像是一个 "高性能增强包":
- 特定场景必备:在 RTS、大规模割草游戏或复杂物理仿真中,ECS 是唯一的性能解决方案。
- 核心包化:到 2026 年,Entities、Collections 等包已成为 Unity 的"核心包"(Core Packages)
++SoA (Structure of Arrays) 的内存布局 加上 高度优化的线性迭代。++
如果用一句话概括 ECS 的底层逻辑,它确实就是
SoA (Structure of Arrays) 的内存布局 加上 高度优化的线性迭代。
内存布局: 从 AoS 到 SoA
在传统的 MonoBehaviour (AoS - Array of Structures) 模式下,对象在内存中是这样排布的:
- 实体A (位置, 旋转, 血量) ------ 实体B (位置, 旋转, 血量)
- 当你只想更新"位置"时,CPU 必须把包含"旋转"和"血量"的整块数据加载进缓存(Cache Line),这造成了大量的带宽浪费 和 Cache Miss。
在 ECS (SoA - Structure of Arrays) 模式下,数据是按组件类型分组存储的:
- 位置A, 位置B, 位置C...
- 旋转A, 旋转B, 旋转C...
- Iteration 的优势 :系统(System)在迭代时,CPU 缓存里全是紧凑的"位置"数据。这种线性访问让 CPU 预取器(Prefetcher)工作效率极高,几乎实现了理论上的最大吞吐量。