当我们谈论 AI 时,我们在谈论什么?是冷冰冰的算法,还是改变世界的新质生产力?
在同元软控,我们选择了一种更纯粹的方式:原生拥抱,深度进化。
【AI-ing 同元】系列专题,记录这场由内而外的重塑之旅。AI 不仅是工具,也正成为同元的"基因"------淬炼出全新的同元人才,让创造力在数智世界里自由生长。
AI-ing,是"正在进行"的状态,是同元永不止步的生命力。
进化的同元,邀你同行。
一个失败的故事
最近,小宁在尝试用 AI Agent 为一个中等规模的代码库完整添加国际化(i18n)支持。
理论上,这是一类非常适合 AI 处理的任务:规则明确,需要识别所有硬编码字符串并替换为t('KEY')的形式,同时在语言文件中补充对应键值;任务重复性高,几乎不需要创造性。
一开始进展顺利。Agent 像一台推土机一样,一个文件接一个文件地处理代码。但几个小时后,情况开始失控。对话历史、数百行代码搜索结果、工具调用日志、Linter 报错、人工补充指令......所有信息都被不断塞进同一个上下文窗口。Agent 的响应速度从秒级下降到分钟级,随后开始"胡言乱语"。它会突然忘记之前已经处理过的文件,在一个无关的函数里问我"这个变量是什么意思",甚至开始修改一些完全不相关的业务逻辑。
最终,当一个简单的 JSON 配置文件也被改得面目全非时,小宁只能选择终止任务。原本寄予厚望的 AI 助手,变成了一个堆满草稿、废弃代码和错误日志的"垃圾场"。
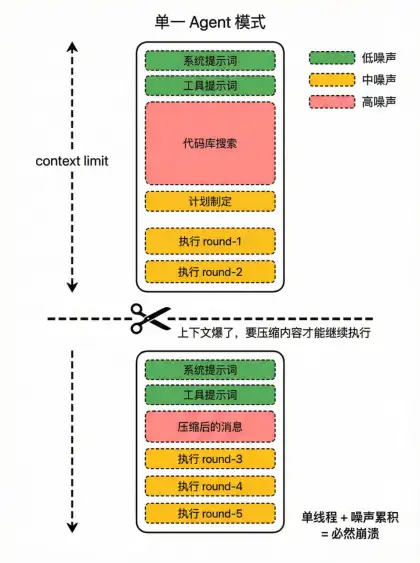
单一 Agent 模式中,上下文不断堆积,噪声与历史信息会持续侵蚀主流程
这次失败揭示了一个关键问题:当任务复杂度超过一定阈值时,单一 Agent 模式极易因为上下文污染而失控。
1. 上下文灾难:单一 Agent 的死胡同
回顾这一失败案例,可以将单一 Agent 的问题归纳为三个典型的"上下文灾难"。
1)上下文干扰
在长周期任务中,代码库、知识库、网页搜索结果等高噪声信息会不断进入上下文。
这些信息就像未经处理的原材料,被堆在同一张工作台上。Agent 必须持续判断哪些是当前任务所需信息,哪些只是历史残留数据。
随着信息不断积累,上下文信噪比持续下降,模型行为也会逐渐变得不稳定。
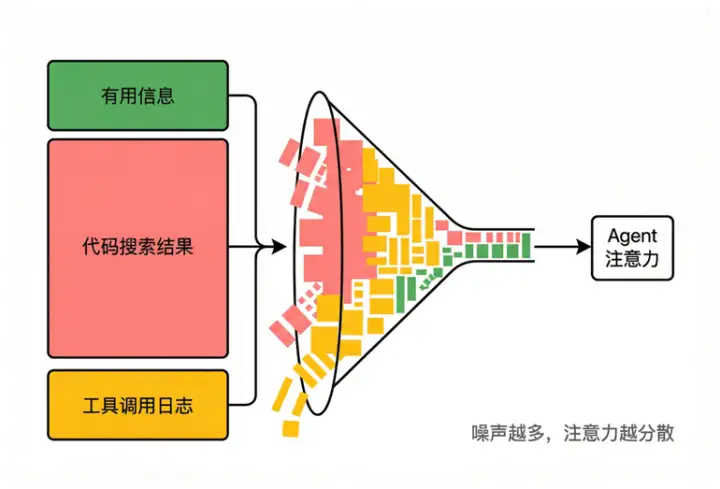
当噪声信息不断涌入,真正有价值的内容会在注意力分配中被稀释
2)上下文溢出
很多人认为,只要上下文窗口足够大,就可以解决问题。
从 4K 到 200K,再到百万级窗口,看似"大力出奇迹"。但斯坦福大学《Lost in the Middle》研究已经指出:即使是先进模型,在长上下文中也更容易记住开头和结尾的信息,而忽略中间的关键内容。
这意味着,即使没有真正达到窗口上限,认知层面的信息丢失仍然会发生。
把所有信息塞进一个巨大窗口,本质上就像拥有一本永远读不完的厚书------最终什么也记不住。
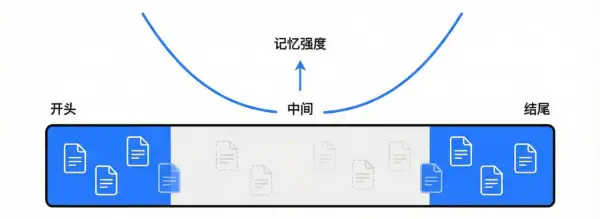
长上下文并不等于高质量记忆,中段信息往往最容易被忽略
3)串行效率瓶颈
单一 Agent 的工作流程通常是:
思考 → 执行 → 观察
这一循环本质上是单线程串行机制。无论模型推理能力多强,一次只能处理一件任务。在需要并行探索多个方向的复杂任务中,这种模式的效率瓶颈会迅速显现。
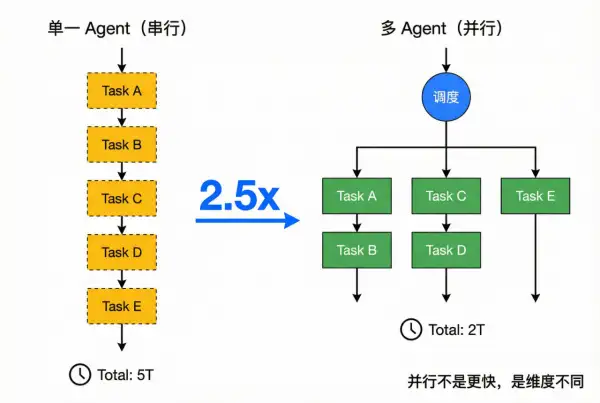
单一 Agent 是串行执行,而多 Agent 的优势在于将任务拆解并并行推进
2. 分而治之:Multi-Agent 的架构启示
解决思路并不在于寻找更强大的单一模型,而在于重新组织 Agent 的协作方式。
Multi-Agent 的核心思想就是:分而治之。
与单一 Agent 在拥挤上下文中处理所有任务不同,Multi-Agent 会将任务拆解,并交给多个拥有独立上下文的 Agent 执行。这种架构带来了几个关键优势:
1)上下文隔离
以 i18n 项目为例,Multi-Agent 的流程可以这样设计:
•Planner Agent(规划者)
负责分析代码库结构并生成任务列表。
•Explorer Agents(探索者)
为每个模块或目录启动独立 Agent,扫描文件并识别需要国际化的字符串。
每个 Explorer 都在自己的上下文中运行。无论探索过程中产生多少日志和中间信息,最终提交给 Planner 的只有一份结构化报告。
这样,核心工作流始终保持干净,不会被探索阶段的噪声污染。
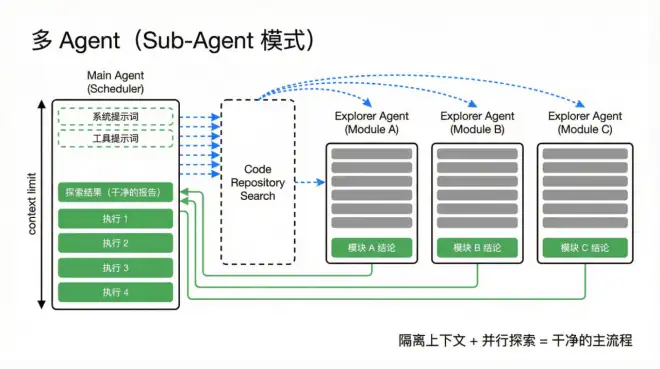
Sub-Agent 模式的价值,不在于角色变多,而在于上下文隔离与并行探索
2)模型经济学
不同任务对模型能力的需求并不相同。
•探索任务:信息量大、重复性强,可使用更快、更便宜的小模型
•规划决策:需要更强推理能力,可使用高性能模型
这种分层策略类似技术团队中的资源配置:把最昂贵的计算资源用于最关键的决策环节。
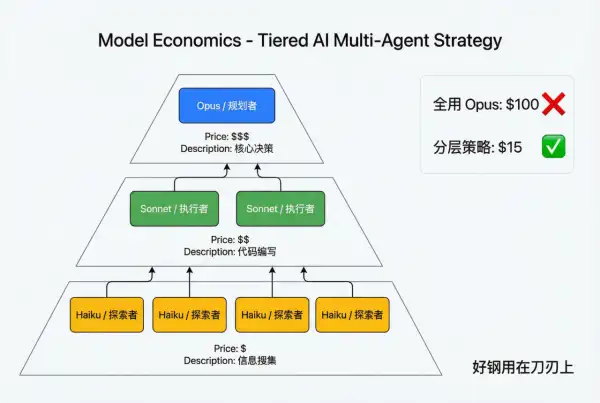
让不同能力、不同成本的模型承担不同任务,才是更合理的系统经济学
3)系统智能 > 个体智能
实践经验表明:
一个设计良好的 Multi-Agent 系统,往往优于一个单独的顶级 Agent。
真正的智能,不只是模型能力,更体现在系统架构和协作设计上。
3. 工程师的现实主义:警惕过度工程化
Multi-Agent 也并非万能方案。在实践中,很容易走向另一个极端:过度工程化。
如果沉迷于构建一个角色极其精细的 Agent 系统,有"产品经理""架构师""程序员""测试工程师"......这个系统看起来像完整的软件团队,但在真实工程实践中,复杂编排往往带来新的问题,如Agent 协作逻辑难以调试、系统运行成本增加等等,最终的产出,往往还不如一个简单的 "Planner + 并行 Explorers"架构来得直接有效。
系统瓶颈往往不在架构,而在需求本身。如果需求不清晰,再复杂的 Agent 系统也只是在更高效地执行错误指令。
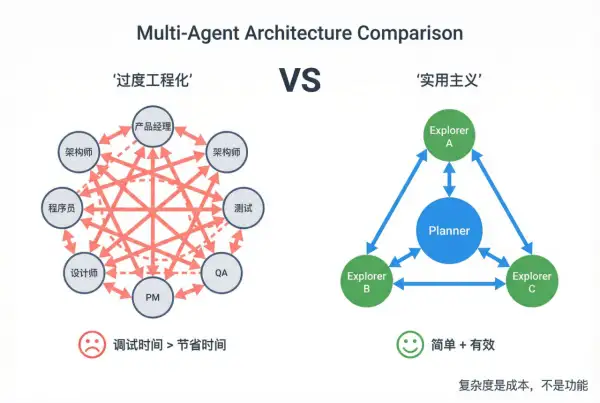
Multi-Agent 不是角色越多越强,关键在于结构是否简单、清晰、可维护
4. 一份更务实的实践清单
结合实际工程经验,可以总结出几条更现实的实践原则。
1)优先使用现成的 Sub-agent 方案
许多工具已经内置成熟方案,例如:
• Cursor
• Claude Code
• OpenCode
这些工具提供的 @Explorer 、@Planner 等子 Agent,已经解决了上下文隔离和状态管理问题。优先使用成熟工具,通常比自行构建系统更可靠。
2)只读先行
在绝大多数场景下,子 Agent 只负责读取与分析任务:
• 代码探索
• 文档分析
• API 设计评审
写操作只在最终阶段由专门 Agent 执行。这种策略既能获得并行效率,也能避免文件冲突和状态混乱。
3)明确 Multi-Agent 的使用场景
Multi-Agent 适用于两类典型问题:
① 可拆分的并行任务
例如:对大量 API 端点进行独立测试、批量代码扫描。
② 上下文需要严格保护的核心流程
例如:长期维护的系统设计文档、关键架构决策过程。
结语
从单一 Agent 到 Multi-Agent 的演进,不只是技术架构的变化。更重要的是,它改变了人与 AI 的协作方式。
过去,AI 更多被视为一个"回答问题的模型";而现在,它正在成为可以被编排、协作和管理的系统组件。
开发者的角色也随之发生转变:从单纯的模型使用者,逐渐走向 AI 系统设计者。