1. 什么是kafka
-
kafka的来源
-
kafka的外在表现
-
kafka的作者和市场情况
2. kafka的基本概念
- 消息和批次
消息:相当于数据表中的一条记录,只接受字节数组,send:message{key(负责路由分配),value(byte [])}
批次:kafka发送消息是批次发送,后期调优是批量的大小和延迟,即批次和吞吐量
- 主题和分区
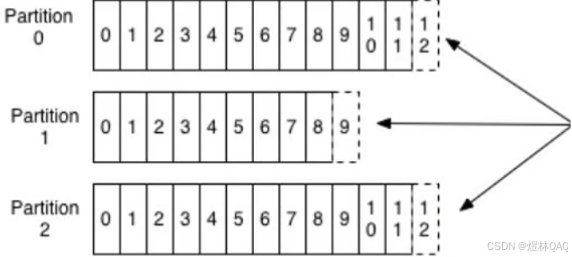
主题:是kafka的逻辑分配单元,比如数据库的表单,即kafka的数据发送到相应的主题中
分区:一个主题中包含多个分区(Parttion),分区是kafka物理存储单位,可以保证顺序存储,先进先出
注意:分区级别可以确保顺序,但是主题级别是无顺序,因为数据可以存在不一定哪个分区
- 生产者和消费者
生产者:可以将消息负载均衡的发送到一个主题中的不同分区,但是如何想叫消息有顺序的话可以将消息发送到一个主题中的固定分区中
消费者:消费者在一个分区中消息也具备顺序性
- 偏移量和消费者群组
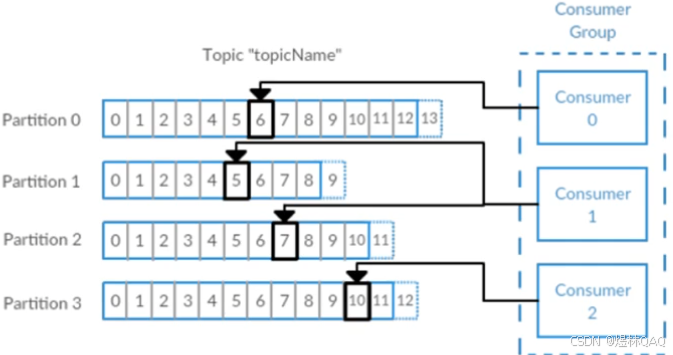
偏移量:消息在发送的时候分区里边的消息比如十条消息偏移量是九,在消费的时候消费偏移量是消费者在分区消费消息时消费到的位置,因为消息是持久化的,这样就可以防止消息重复消费
消费者群组:多个消费者可以组成一个消费者群组,一个消费者群组里一个分区只能匹配群组里边的一个消费者,但是一个消费者可以消费多个分区
疑问:消费者组每一个消费者绑定分区是绑定死的还是每次绑定都是不一样的
- Broker和集群
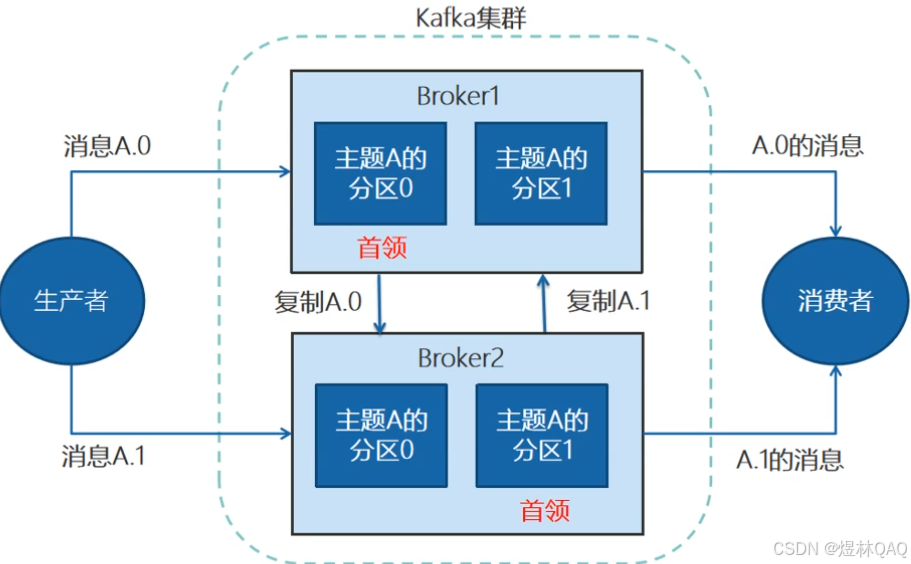
Broker:一台独立的kafka服务
集群:把多台Broker集合在一起构建成集群
- 复制与首领
复制:为了保证数据不丢失创建副本,但是不知道主次关系,所以有首领概念
首领:每个分区选择不同Broker当作首领这样的话可以保证数据最大化保护,生产和消费都是通过首领进行操作,副本是保存数据,不会丢失数据,提高容错
- 副本机制
只是走首领副本保存数据
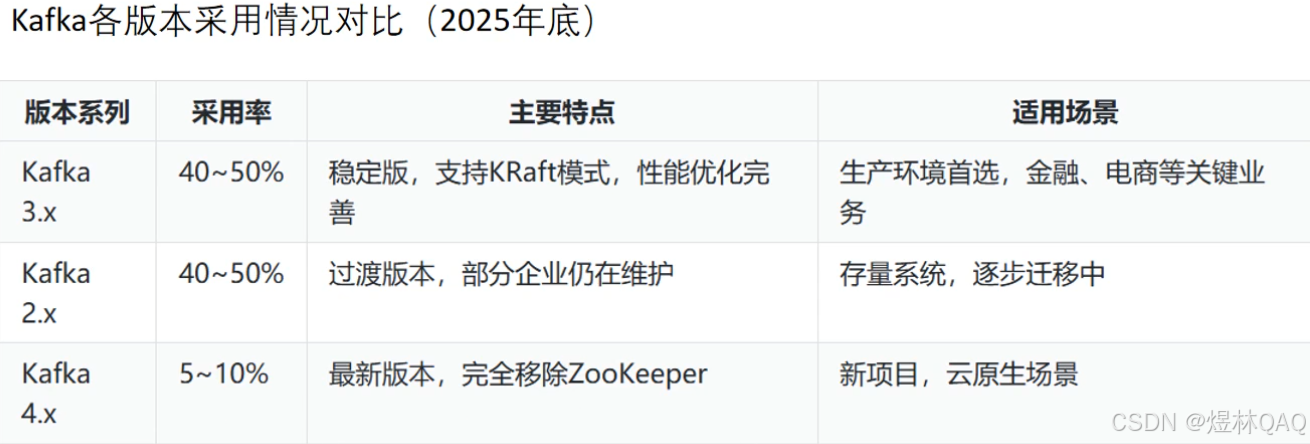
3. kafka版本
4. kafka安装
前提:安装响应版本的jdk
4.1 2.x的安装、管理和配置
- 下载
- windows安装
bash
#打开kafka安装的目录cmd首先启动zookeeper要配置响应的配置文件
kafka_2.12-2.8.1\kafka_2.12-2.8.1\bin\windows>zookeeper-server-start.bat ..\..\config/zookeeper.properties
bash
#启动kafka-server的启动文件,也是启动程序和相应的配置文件
kafka_2.12-2.8.1\kafka_2.12-2.8.1\bin\windows>kafka-server-start.bat ..\..\config/server.properties- linux安装
bash
#后台启动 zookeeper(默认端口2181)
nohup bin/zookeeper-server-start.sh config/zookeeper.properties 1>zookeeper_stdout.log 2>zookeeper_stderr.log &
bash
# 后台启动 kafka-server
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &- kafka基本操作和管理
bash
# 主题相关
./kafka-topics.sh --bootstrap-server localhost:9092 --list
./kafka-topics.sh --bootstrap-server localhost:9092 --describe
# 创建三个分区、副本数为1、主题名称为new-topic
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic new-topic --partitions 3 --replication-factor 1
bash
# 查看消费者偏移量详情
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-group --describe
bash
# 使用bootstrap-server
./kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic my-topic
bash
#创建生产者
./kafka-console-producer.sh --broker-list localhost:9092 --topic my-topic
bash
# 查看最新消息
./kafka-console-consumer.sh --bootstrap-sever localhost:9092 --topic my-topic
bash
# 从头消费
./kafka-console-consumer.sh --bootstrap-sever localhost:9092 --topic my-topic --from -beginning
bash
# 消费特定分区
./kafka-console-consummer.sh --bootstrap-server localhsot:9092 --topic my-topic --partition 0
bash
# 消费特定偏移量
./kafka-console-consummer.sh --bootstrap-server localhsot:9092 --topic my-topic --offset 100 --partition 0
bash
#查看主题配置
./kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name new-topic --describe
bash
# 修改主题配置(如修改保留时间)
./kafka-configs.sh --zookeeper localhost:2181 --entity-type topics --entity-name new-topic --alter --add -config retention,- Broker配置项
properties
############################# Server Basics #############################
# broker id 如何是集群的话要是不唯一的正数
broker.id=0
############################# Log Basics #############################
# 持久化文件存放位置
log.dirs=/tmp/kafka-logs
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
# zookeeper的地址
zookeeper.connect=localhost:21814.2 3.x的安装、管理和配置
- 下载(对比2.x多一个KRaft模式)
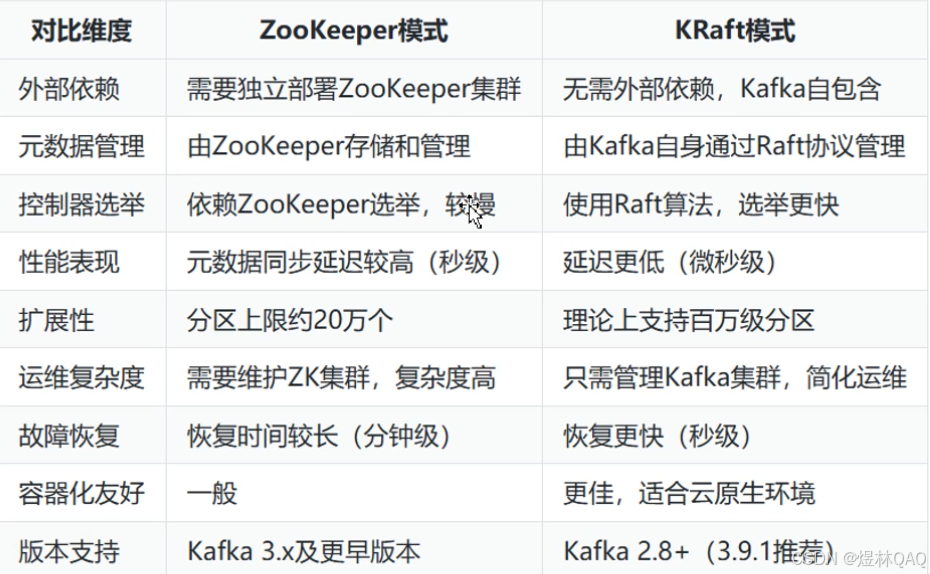
kafka 3.9.1,
推荐jdk版本17
- windows安装
和上边2.x启动一致,启动zookeeper和kafka
bash
#KRaft模式启动
# 会生成一个唯一的id区别不同的kafka集群
kafka-storage.bat random-uuid
kafka-storage.bat format --config ..\..\config\kraft\server.properties --cluster-id 上一步生成的uuid
#启动kafka 就不用在启动zookeeper
kafka-server-start.bat ..\..\config/server.properties- linux安装
和上边2.x启动一致,启动zookeeper和kafka
bash
#KRaft模式启动
# 会生成一个唯一的id区别不同的kafka集群
kafka-storage.bat random-uuid
kafka-storage.bat format --config ..\..\config\kraft\server.properties --cluster-id 上一步生成的uuid
#启动kafka 就不用在启动zookeeper
kafka-server-start.bat ..\..\config\kraft\server.properties- kafka基本的操作和管理(单机非集群)
和2.x一致命令
- Broker配置项
和2.x差不多但是使用kraft模式需要注意一下:
\kafka_2.12-3.9.1\config\kraft\server.properties
properties
############################# Server Basics #############################
# 定义节点角色
# broker:消息代理,生产/消费 请求
# controller:集群控制器,管理元数据和领导选举
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# The connect string for the controller quorum
controller.quorum.voters=1@localhost:9093
############################# Log Basics #############################
# 日志文件存储位置
log.dirs=/tmp/kraft-combined-logs4.3 4.x的安装、管理和配置
- 下载(完全去除zookeeper使用kraft)
kafka 4.1.1,
推荐jdk版本17
- windows安装
bash
#KRaft模式启动
# 会生成一个唯一的id区别不同的kafka集群
kafka-storage.bat random-uuid
kafka-storage.bat format --standalone -t 上一步生成的uuid -c ..\..\config\server.properties
#启动kafka 就不用在启动zookeeper
kafka-server-start.bat ..\..\config\server.properties- linux安装
bash
#KRaft模式启动
# 会生成一个唯一的id区别不同的kafka集群
kafka-storage.sh random-uuid
kafka-storage.sh format --standalone -t 上一步生成的uuid -c ..\..\config\server.properties
#启动kafka 就不用在启动zookeeper
kafka-server-start.sh ..\..\config/server.properties- kafka基本的操作和管理(单机非集群)
和2.x一致命令
- Broker配置项
properties
############################# Server Basics #############################
# The role of this server. Setting this puts us in KRaft mode
process.roles=broker,controller
# The node id associated with this instance's roles
node.id=1
# List of controller endpoints used connect to the controller cluster
controller.quorum.bootstrap.servers=localhost:9093
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/tmp/kraft-combined-logs5. kafka clients 版本兼容性
- Apache kafka 官方有明确的
向后兼容性保证 - 生产者/消费者客户端 可以
连接版本相同或更高的Broker - 但
不能保证新版客户端能连接旧版本的Broker
6. Hello kafka
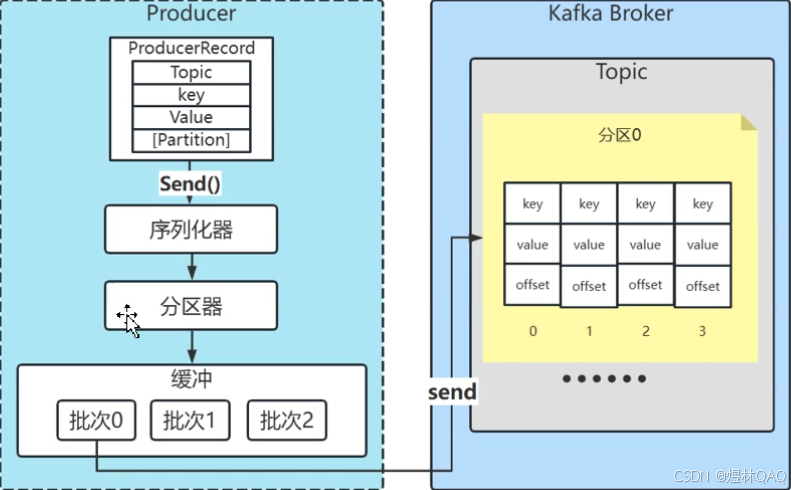
6.1 创建主题
bash
# 启动的时候含有下边的意思是可以自动创建主题,也可以根据前边的指令进行创建
auto.create.topics.enable = true6.2 生产者发送消息(三种方式)
pom包依赖,我使用的版本
3.9.1
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.x</groupId>
<artifactId>demo_01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo_01</name>
<description>demo_01</description>
<properties>
<java.version>17</java.version>
<junit-jupiter.version>5.10.2</junit-jupiter.version>
</properties>
<dependencies>
<!-- ✅ 正确的 starter 名称是 spring-boot-starter-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- ✅ 正确的测试 starter 名称是 spring-boot-starter-test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>代码展示
java
/**
* TODO 生产者发送消息
* */
@Test
void producer1() {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 配置多台的服务,用,分割 其中一个宕机,生产者依然可以脸上(集群)
// 配置string 的序列化(对象 -> 二进制字节数组:能够在网络上传输)
properties.put("key.serializer",StringSerializer.class);
properties.put("value.serializer",StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
ProducerRecord<String,String> record ;
try {
// 构建消息
record = new ProducerRecord<>("iuit", "name", "小明");
// 发送消息,不知道是否发送成功
producer.send(record);
System.out.println("消息已经发送");
}catch (Exception e){
e.printStackTrace();
}
}finally {
// 释放连接
producer.close();
}
}
@Test
void producer2() {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 配置多台的服务,用,分割 其中一个宕机,生产者依然可以脸上(集群)
// 配置string 的序列化(对象 -> 二进制字节数组:能够在网络上传输)
properties.put("key.serializer",StringSerializer.class);
properties.put("value.serializer",StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
ProducerRecord<String,String> record ;
try {
// 构建消息
record = new ProducerRecord<>("iuit", "name", "小王");
// 发送消息,不知道是否发送成功
Future<RecordMetadata> send = producer.send(record);
RecordMetadata recordMetadata = send.get();
if (null != recordMetadata){
System.out.println("offset(偏移量):" + recordMetadata.offset() + ","
+ "partition(分区):" + recordMetadata.partition()
);
}
System.out.println("消息已经发送");
}catch (Exception e){
e.printStackTrace();
}
}finally {
// 释放连接
producer.close();
}
}
@Test
void producer3() {
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 配置多台的服务,用,分割 其中一个宕机,生产者依然可以脸上(集群)
// 配置string 的序列化(对象 -> 二进制字节数组:能够在网络上传输)
properties.put("key.serializer",StringSerializer.class);
properties.put("value.serializer",StringSerializer.class);
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
ProducerRecord<String,String> record ;
try {
// 构建消息
record = new ProducerRecord<>("iuit", "name", "小王");
// 发送消息,不知道是否发送成功
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if (e == null){
System.out.println("没有异常," + "offset:" + recordMetadata.offset() + ","
+ "partition:" + recordMetadata.partition());
}else{
// 异常打印
e.printStackTrace();
}
}
});
System.out.println("消息已经发送");
}catch (Exception e){
e.printStackTrace();
}
}finally {
// 释放连接
producer.close();
}
}6.3 顺序保障
kafka消息发送的顺序保障
- 一个主题一个发呢去。主题就具备顺序性
- 就算一个主题多个分区,在一个分区内,消息也会具备顺序的
6.4 生产和消费序列化器
java
// 配置string 的序列化(对象 -> 二进制字节数组:能够在网络上传输)
properties.put("key.serializer",StringSerializer.class);
properties.put("value.serializer",StringSerializer.class);
kafka的序列化:
Avro:语言无关,序列化后体积小
案例:
- LinkedIN:Avro
- 国内大厂:Avro、Protobuf、自定义、json序列化
6.5 分区器
分局上边配置新增
- 默认分区器会根据key的值进行分区匹配
- 轮询:将消息平均分配
- 统一粘性分区器:不管有没有key都会进行分区匹配1
- 可以直接在发送中指定
- 自定义分区
java
// 设置属性
Properties properties = new Properties();
// 指定连接的kafka服务器地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 配置多台的服务,用,分割 其中一个宕机,生产者依然可以脸上(集群)
// 配置string 的序列化(对象 -> 二进制字节数组:能够在网络上传输)
properties.put("key.serializer",StringSerializer.class);
properties.put("value.serializer",StringSerializer.class);
// 默认分区
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, DefaultPartitioner.class);
// 轮询分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,RoundRobinPartitioner.class);
// 统一粘性分区器
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,UniformStickyPartitioner.class);
// 构建kafka生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
try {
ProducerRecord<String,String> record ;
try {
// 构建消息
// record = new ProducerRecord<>("iuit", "name", "小明");
// 直接指定放在分区1上边
record = new ProducerRecord<>("iuit", 1,"name", "小明");
// 发送消息,不知道是否发送成功
producer.send(record);
System.out.println("消息已经发送");
}catch (Exception e){
e.printStackTrace();
}
}finally {
// 释放连接
producer.close();
}
}- 自定义分区实现
Partitioner
java
public class SelfPartitioner implements Partitioner {
@Override
public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {
// 根据value值进行分区
List<PartitionInfo> partitionInfos = cluster.partitionsForTopic(s);
int num = partitionInfos.size();
int partId = Utils.toPositive(Utils.murmur2(bytes)) % num;
return partId;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> map) {
}
}6.6 缓冲\批次
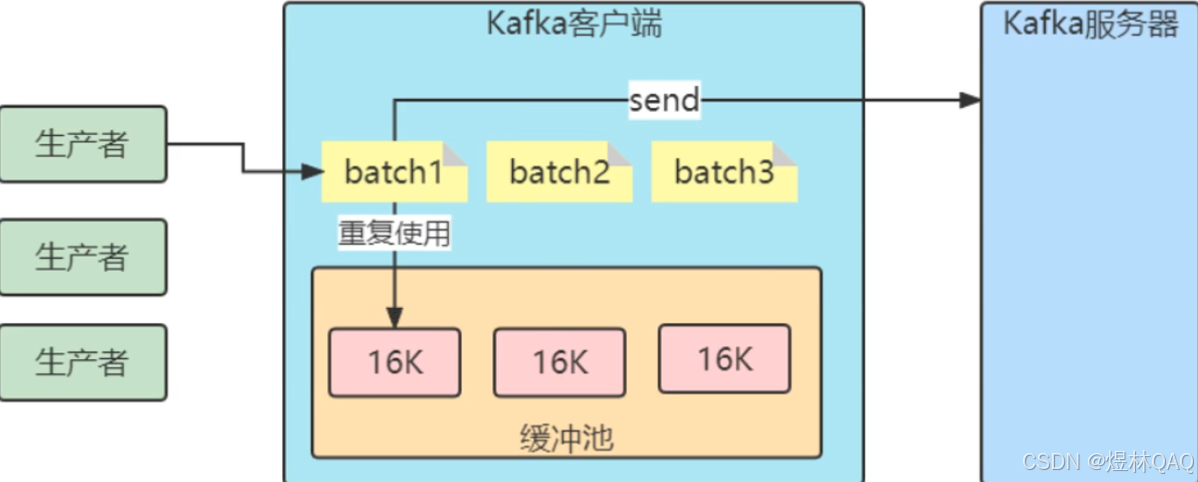
- buffer.memory
- batch.size
- linger.ms
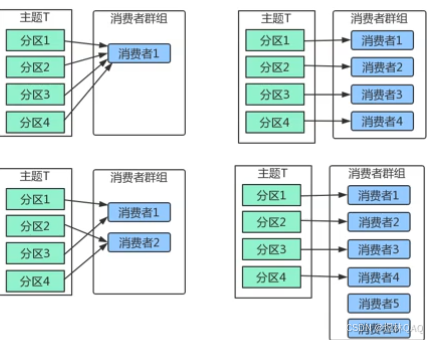
7 消费者接受消息的基本流程
7.1 消费这个和消费者组
核心规则:
- 一个分区只能被同一消费者组内的一个消费者独占消费
- 消费者数量 <= 分区数:每个消费者分配一个或者多个分区
- 消费者数量> 分区数:多个消费者处于空闲状态
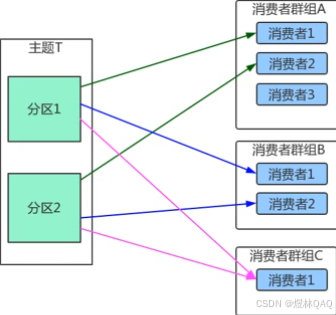
- 不同消费者组可独立消费同一主题,互不影响
7.2 消费者配置
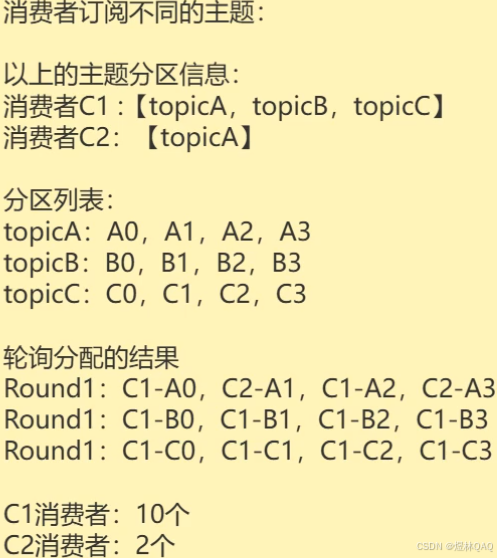
- partition.assignment.strategy
分配分区策略
range:按照主题逐个分配,将连续的分区范围分配和消费者,可能导致负载不均衡,过载的问题
RoundRobinAssignor:跨所有主题轮询分配,实现全局负载均衡,但是在消费订阅不同的主题会出现严重的负载不均衡的问题
StickyAssignor机制:
- 首次分配:尽可能负载均衡
- 重平衡时:尽量保证原有分配,减少分区迁移
- 解决上面Range,RoundRobin在重平衡时的"颠簸"问题
CooperativeStickyAssignor:增强版,粘性分析器
- kafka2.4后引入,Sticky的增强版本








- max.partition.fetch.bytes
指定服务器给每消费者每个分区的最大字节数
- auto.offset.reset
首次消费的时候决定在哪里偏移量进行消费
消费者消费kafka的时候确认是否存活
- enable.auto.commit
默认为true,自动提交,默认程序运行的时候
消费者名字
- max.poll.records
控制每次拉取的最大消息,默认是500
- fetch.min.bytes
配合
fetch.wait.max.bytes,协同等待策略,等待最少多少字节消费
- receive.buffer.bytes
tcp发送缓冲区大小
配合
fetch.min.bytes,协同等待策略
- send.buffer.bytes
tcp接收缓冲区大小
- 代码演示
java
/**
* TODO 消费者 为什么之前的没有消费的消息没有消费?
* */
@Test
void consumer01() {
// 设置属性
Properties properties = new Properties();
// 指定kafka服务器地址
properties.put("bootstrap.servers","127.0.0.1:9092");
// 设置string反序列化
properties.put("key.deserializer", StringDeserializer.class);
properties.put("value.deserializer",StringDeserializer.class);
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"groupB");
// RangeAssignor(默认策略):按主题逐个分配,将连续的分区范围分配给消费者
// properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RangeAssignor");
// RoundRobinAssignor:跨所有主题轮询,实现全局负载均衡
// properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.RoundRobinAssignor");
// StickyAssignor(推荐):初始分配均衡,重平衡时保留原有分配,仅调整必要分区
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");
// CooperativeStickyAssignor 上一个增强版 粘性分配器
// properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.CooperativeStickyAssignor");
// 默认值latest:消息启动后接收到的消息;earliest:从头开始消费所有的
properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
/* 取消自动提交*/
properties.put("enable.auto.commit",false);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
try {
consumer.subscribe(Collections.singletonList("iuit"));
// 使用消费者拉去消息
while (true){
// 每隔1秒拉取一次消息
ConsumerRecords<String, String> poll = consumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : poll) {
String key = record.key();
String value = record.value();
System.out.println("接收到的消息,key为:" + key + ";value为:" + value);
}
// 取消自动提交
consumer.commitAsync();// 异步提交:不阻塞我们的应用程序的线程,不会重试(有可能失败)
}
}finally {
try {
consumer.commitSync();// 同步提交:会阻塞我们的应用线程,会重试(一定会成功)
}finally {
// 释放连接
consumer.close();
}
}
}8. kafka的SpringBoot实战
- maven依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.3</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.x</groupId>
<artifactId>demo_01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo_01</name>
<description>demo_01</description>
<properties>
<java.version>17</java.version>
<junit-jupiter.version>5.10.2</junit-jupiter.version>
</properties>
<dependencies>
<!-- ✅ 正确的 starter 名称是 spring-boot-starter-web -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- ✅ 正确的测试 starter 名称是 spring-boot-starter-test -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- Kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.9.1</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>3.3.11</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<version>3.3.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>- 配置文件
yaml
spring:
application:
name: demo_01
kafka:
bootstrap-servers: localhost:9092 # kafka服务器地址
# 生产者配置
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 消息确认机制:0-不确认 1-leader确认 all-所有副本确认
acks: all
# 发送失败重试次数
retries: 3
# 批量发送大小
batch-size: 16384
# 发送缓冲区大小
buffer-memory: 33554432
# 消费者配置
consumer:
group-id: iuit-group
key-deserializer: org.apache.kafka.common.serialization.StringSerializer
value-deserializer: org.apache.kafka.common.serialization.StringSerializer
# 自动提交offset 偏移量
enable-auto-commit: true
auto-commit-interval: 1000
# 自动配置offset:earliest-从最早开始 latest-从最新开始
auto-offset-reset: earliest
# 监听器配置
listener:
# 批量消费模式
type: single # batch
# 手动提交ack
ack-mode: manual_immediate- 配置文件
KafkaConsumerConfig
java
@Configuration
public class KafkaConsumerConfig {
@Bean
public ConsumerFactory<String,String> consumerFactory(){
HashMap<String, Object> map = new HashMap<>();
map.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
map.put(ConsumerConfig.GROUP_ID_CONFIG,"iuit1-group");
map.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
map.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 可选 自定义配置
map.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest");
map.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
map.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,10);
return new DefaultKafkaConsumerFactory<>(map);
}
@Bean("batchFactory")
public ConcurrentKafkaListenerContainerFactory<String,String> consumerBatchFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.setBatchListener(true);
factory.getContainerProperties().setPollTimeout(3000);
// 配置手动提交
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String,String> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
// 配置手动提交
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
// 设置并发消费者数量
factory.setConcurrency(3);
return factory;
}
}KafkaProducerConfig
java
@Configuration
public class KafkaProducerConfig {
@Bean
public ProducerFactory<String,String> producerFactory(){
HashMap<String, Object> map = new HashMap<>();
map.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
map.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
map.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class);
// 可选 自定义配置
map.put(ProducerConfig.ACKS_CONFIG,"all");
map.put(ProducerConfig.RETRIES_CONFIG,3);
map.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
map.put(ProducerConfig.LINGER_MS_CONFIG,1);
map.put(ProducerConfig.BUFFER_MEMORY_CONFIG,3354432);
return new DefaultKafkaProducerFactory<>(map);
}
@Bean
public KafkaTemplate<String,String> kafkaTemplate(){
return new KafkaTemplate<>(producerFactory());
}
}- 生产者
java
@Service
public class KafkaProducerService {
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
// 1.同步发送
public void sendMessageSync(String topic,String message){
try {
SendResult<String, String> result = kafkaTemplate.send(topic, message).get();
System.out.println("发送成功:" + result.getRecordMetadata().topic() +
";partition:" + result.getRecordMetadata().partition() +
";offset:" + result.getRecordMetadata().offset()
);
}catch (Exception e){
System.out.println("发送失败:" + e.getMessage());
}
}
// 2.异步发送
public void senfMessageAsync(String topic,String message){
CompletableFuture<SendResult<String, String>> send = kafkaTemplate.send(topic, message);
send.whenComplete((result,ex)->{
if (ex == null){
System.out.println("异步发送成功:" + result.getRecordMetadata().toString());
}else {
System.err.println("异步发送失败:" + ex.getMessage());
}
});
}
// 3.带key的发送
public void senfMessageWithKey(String topic,String key,String value){
kafkaTemplate.send(topic,key,value);
}
// 发送指定分区
public void sendToPartition(String topic,Integer partition, String key,String value){
kafkaTemplate.send(topic,partition,key,value);
}
}- 消费者
java
@Component
public class KafkaConsumerService {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class);
/**
* TODO 基础消费
* */
@KafkaListener(topics = "iuit-topic",groupId = "iuit-group")
public void consumerMessage(String message){
logger.info("接受到消息:{}",message);
}
/**
* TODO 获取完整消息的消息
* */
@KafkaListener(topics = "iuit-topic",groupId = "iuit1-group")
public void consumerFullMessage(ConsumerRecord<String,String> record){
logger.info("接收到的完整消息:topic={},partition={},offset={},key={},value={}",
record.topic(),
record.partition(),
record.offset(),
record.key(),
record.value()
);
}
/**
* TODO 批量消费
* */
@KafkaListener(topics = "batch-topic",groupId = "batch-group",containerFactory = "batchFactory")
public void consumerBatchMessages(List<ConsumerRecord<String,String>> records){
logger.info("批量接收到{}条消息",records.size());
for (ConsumerRecord<String, String> record : records) {
logger.info("批量消息:{}",record.value());
}
}
/**
* TODO 监听多个topic
* */
@KafkaListener(topics = {"topic1","topic2","topic3"},groupId = "multi-group")
public void consumerMultipleTopics(String message){
logger.info("收到多个主题消息:{}",message);
}
/**
* TODO 收到提交offest
* */
@KafkaListener(topics = "manual-topic",groupId = "manual-group")
public void consumerWithManualCommit(ConsumerRecord<String,String> record, Acknowledgment acknowledgment){
try {
logger.info("处理消息:{}",record.value());
System.out.println("处理业务。。。。");
// 手动提交offset
acknowledgment.acknowledge();
}catch (Exception e){
logger.error("处理消息失败:" + e);
}
}
}- api 接口调用
java
@RestController
@RequestMapping("/kafka")
public class KafkaController {
@Autowired
private KafkaProducerService kafkaProducerService;
@PostMapping("/send")
public String senfMessage(@RequestParam String topic,@RequestParam String message){
kafkaProducerService.senfMessageAsync(topic,message);
return "消息发送成功";
}
@PostMapping("/sendAsync")
public String sendMessageAsync(@RequestParam String topic,
@RequestParam String meaasge){
kafkaProducerService.senfMessageAsync(topic,meaasge);
return "异步消息发送中";
}
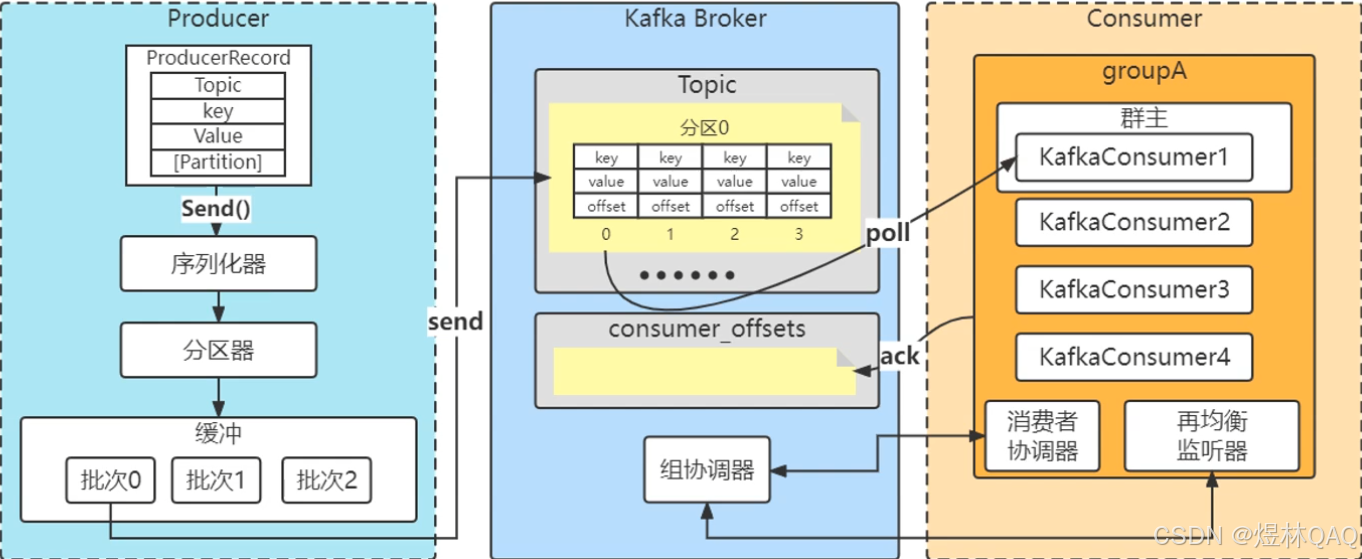
}9 kafka消息发送和消费的过程
10. kafka集群原理
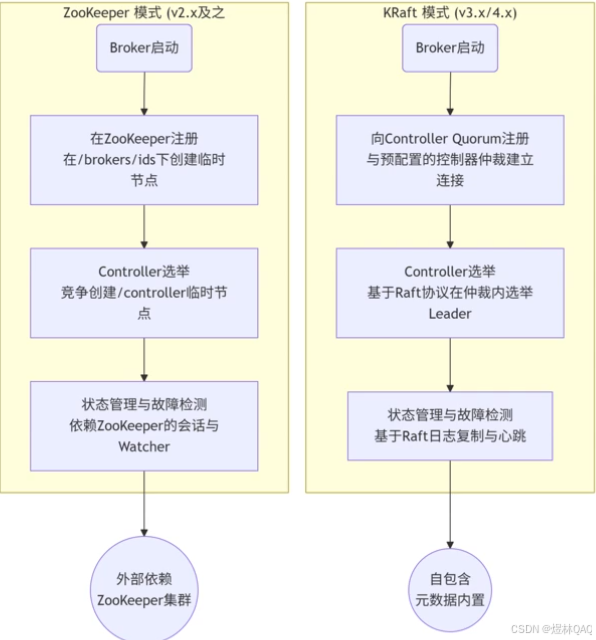
-
Controller选举和Broker注册
-
kafka的副本机制
- Leader副本(首领副本)
- Follower副本(跟随者副本)
-
集群中的核心概念和参数
- 复制系数:主题级别 default.replication.factor (默值3)
- 不完全首领选举:分区首领不可用切没有同步副本 unclean.leader.election.enable
- 最少同步副本
- 副本分布策略




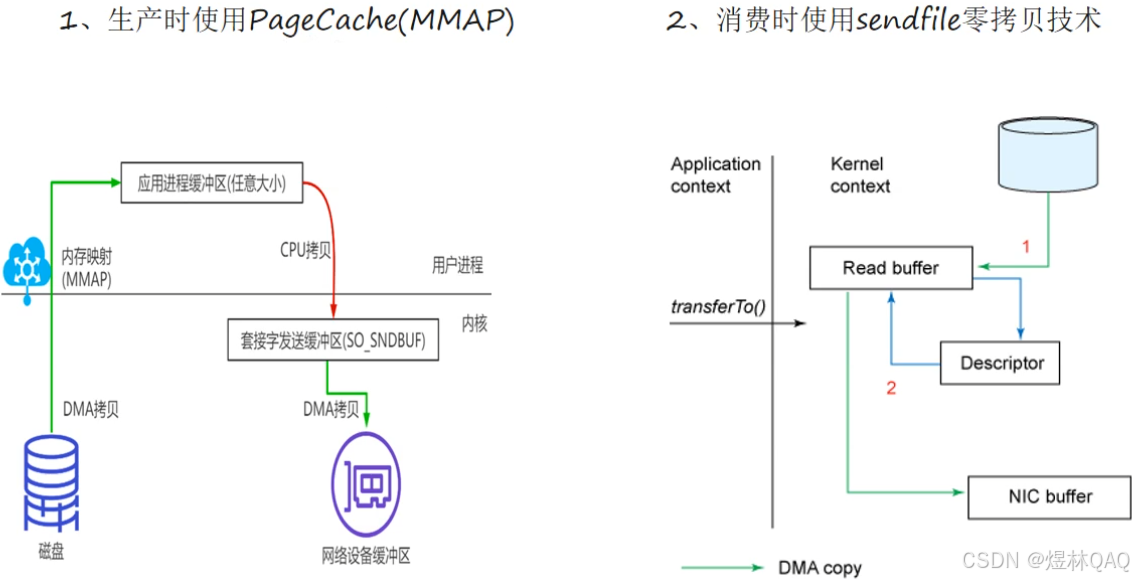
11. kafka的零拷贝
四次交换
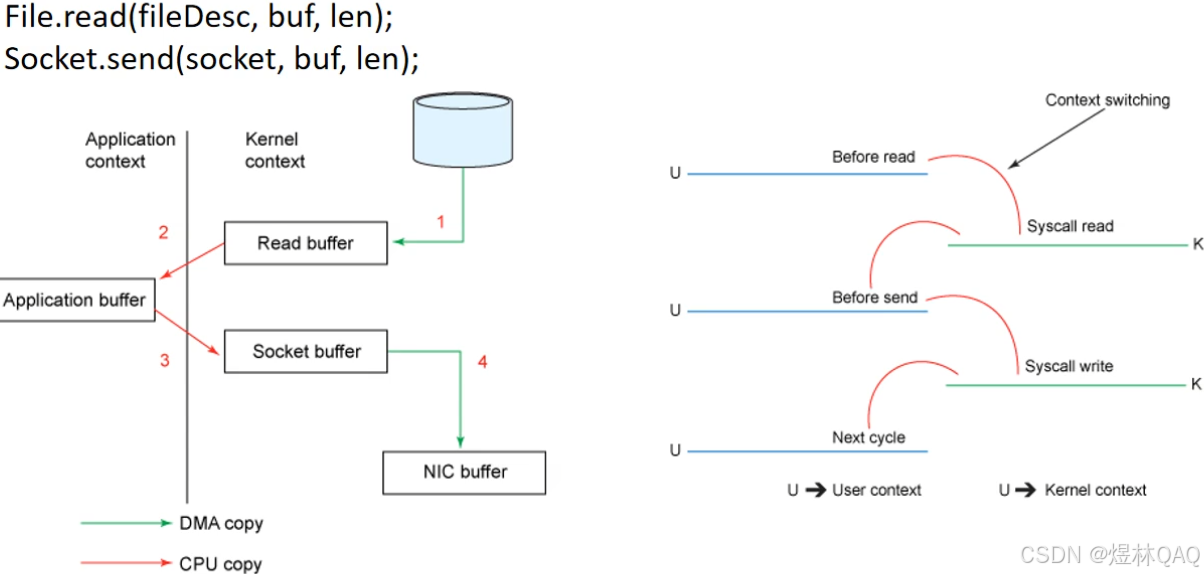
kafka的transferTo
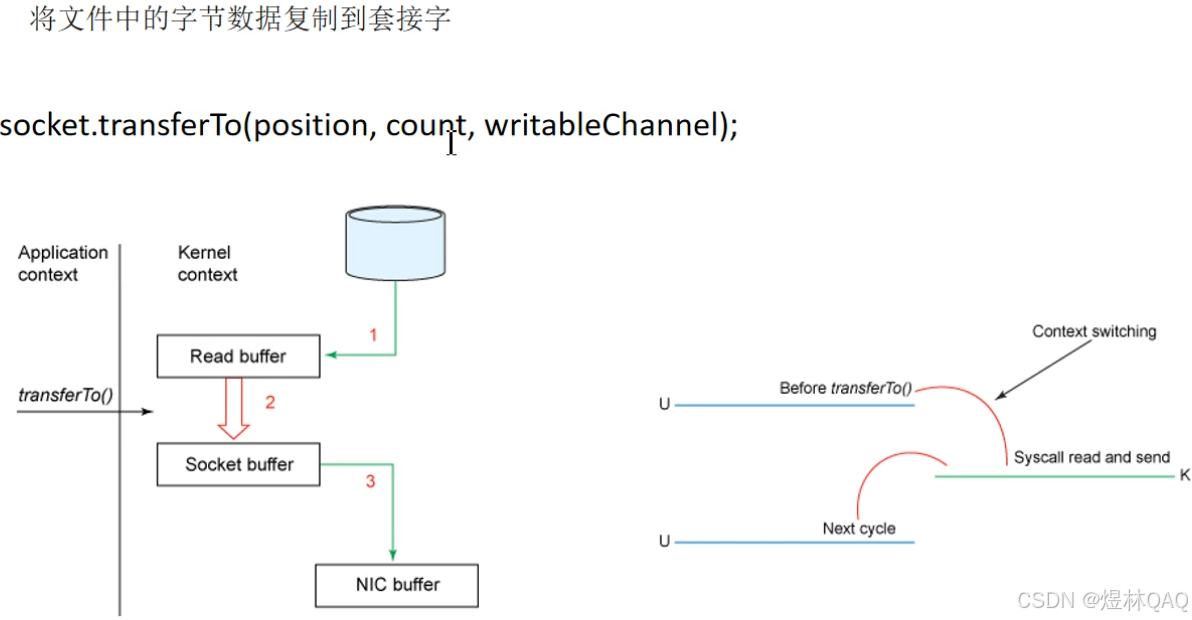
linux系统的改进
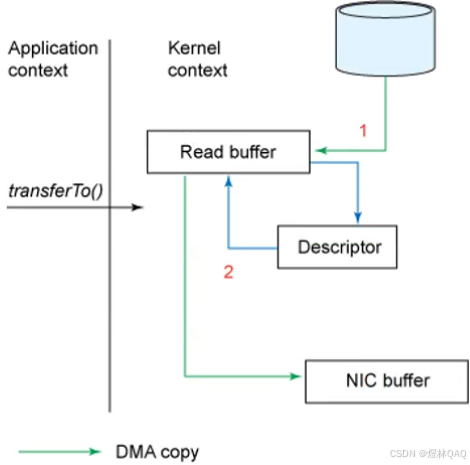
kafka的零拷贝运用
12. 流式处理
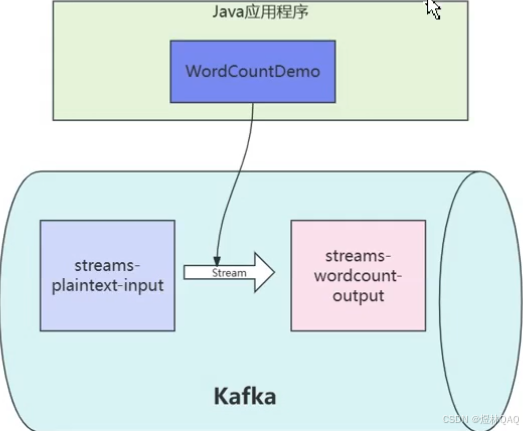
- 流式处理命令
bash
# 创建输入Topic'streams-plaintext-input' 和输出Topic 'streams-wordcount-output'
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic streams-plaintext-input --partitions 1 --replication-factor 1
./kafka-topics.sh --bootstrap-server localhost:9092 --create --topic streams-wordcount --partitions 1 --replication-factor 1
# 启动WordCount应用
./kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
# 启动生产者和消费者
./kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input
--form-beginning --property print.ket=true --property print.value=true --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer