在熙瑾会悟产品研发的时候,有以下能力:说话人识别(Speaker Identification) 。
简单说就是:
系统不仅要把语音转成文字,还要知道 "是谁在说话" 。
这个能力在很多场景都会用到,比如:
- 会议纪要
- 电话质检
- 多人访谈记录
- 语音客服分析
- AI语音助手
但在实际落地过程中,一个非常常见的问题就是:
角色识别会"漂移"。
简单说就是:
识别一开始是对的,但说着说着,人物身份突然变了。
比如:
张三:今天这个项目需要尽快推进
张三:后面资源可能不太够
李四:我们可以再评估一下结果系统识别成:
张三:今天这个项目需要尽快推进
李四:后面资源可能不太够
李四:我们可以再评估一下第二句话 被错误识别成李四 ,这就是典型的 角色漂移问题 。
在长会议(30分钟以上)或者多人会议中,这种情况尤其明显。
在工程中我们是怎么解决这个问题的:
核心方案:
陌生人机制 + 稳定性规则
一、为什么会出现角色漂移
在理解解决方案之前,我们先看看问题产生的原因。
语音角色识别通常依赖 声纹(Speaker Embedding) 技术。
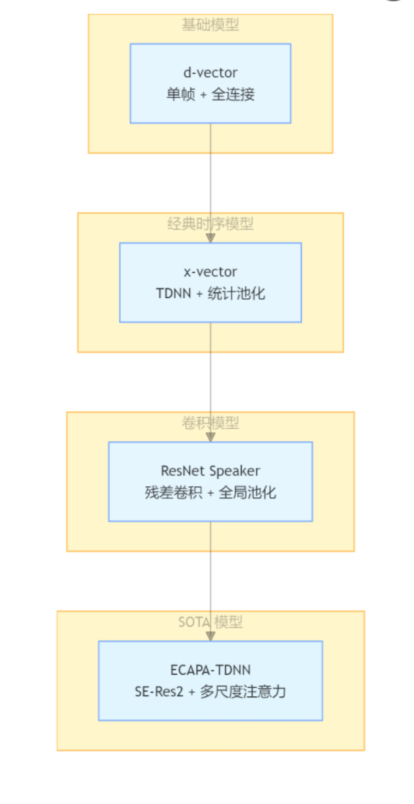
常见模型包括:
- d-vector:最简单
- x-vector:时序建模基准
- ResNet:卷积全局特征
- ECAPA-TDNN:当前最优
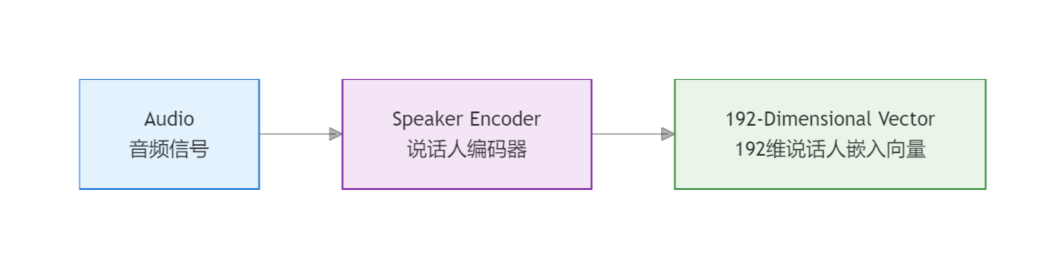
这些模型的核心能力是:
把一段语音映射成一个向量。
例如:
然后通过 余弦相似度(Cosine Similarity) 判断是否同一个人。
如果相似度高于阈值,比如:
cosine > 0.75就认为是同一个人。
但问题是:
语音是 非常不稳定的数据 。
影响因素很多:
- 麦克风距离变化
- 环境噪声
- 情绪变化
- 说话速度变化
- ASR分段误差
这些都会导致 embedding 向量产生波动 。
所以会出现一种情况:
张三A句 → embedding1
张三B句 → embedding2结果:
cosine(embedding1, embedding2) < 阈值系统就会认为:
这是另一个人。
于是就发生了角色漂移。
二、工程实践中的典型问题
在真实项目中,常见问题主要有三类:
1 误识别
两个人声音相似。
系统会把:
张三 → 李四识别错。
2 角色漂移
长时间会议中:

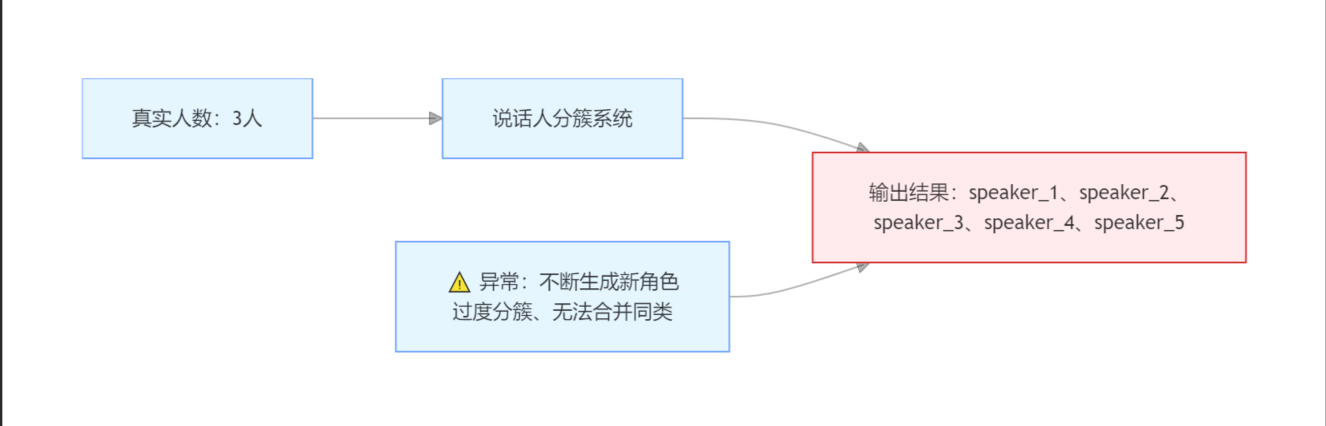
3 角色数量膨胀
系统不断生成新角色:
三、解决方案一:陌生人机制
为了解决误识别问题,我们引入一个机制:
陌生人检测(Unknown Speaker Detection)
核心思路是:
不要强行匹配已有角色。
如果相似度不足,就判定为 未知角色 。
逻辑大概是:
if similarity > speaker_threshold:
match speaker
else:
new speaker流程大致如下:
例如:
已有角色:
张三 embedding
李四 embedding新语音进来:
similarity(张三) = 0.61
similarity(李四) = 0.58阈值:
0.72
那么系统不会强行匹配。
而是创建:
speaker_3
这样就避免了 误识别问题 。
四、解决方案二:稳定性规则
仅靠陌生人机制还不够。
因为还有一个问题:
短时间漂移。
例如:
张三
张三
李四 ← 错误
张三我们观察真实会议数据发现:
同一个人往往会连续说几句话。
所以可以引入一个 稳定性规则(Stability Rule) 。
核心思想:
不要轻易切换角色。
例如:
最近N句都是张三
如果突然出现:
李四
但相似度并不明显更高。
系统就 拒绝切换角色 。
简单规则:
if last_speaker == current_speaker:
keep speaker或者:
连续3句才确认新角色
例如:
张三
张三
李四 (候选)
张三系统会自动修正为:
张三
张三
张三
张三这一步可以极大减少 角色漂移 。
五、进一步优化:Embedding 复用
在工程中还有一个重要优化:
说话人表征更新(Speaker Embedding Update)
问题是:
如果只保存 第一句 embedding 。
那后面的匹配会越来越不准。
更好的做法是:
动态更新角色 embedding。
例如:
speaker_embedding =
average(last_k_embeddings)示意图如下:
这样角色向量会逐渐稳定。
优点:
- 抗噪声能力更强
- 长会议更稳定
- 减少漂移
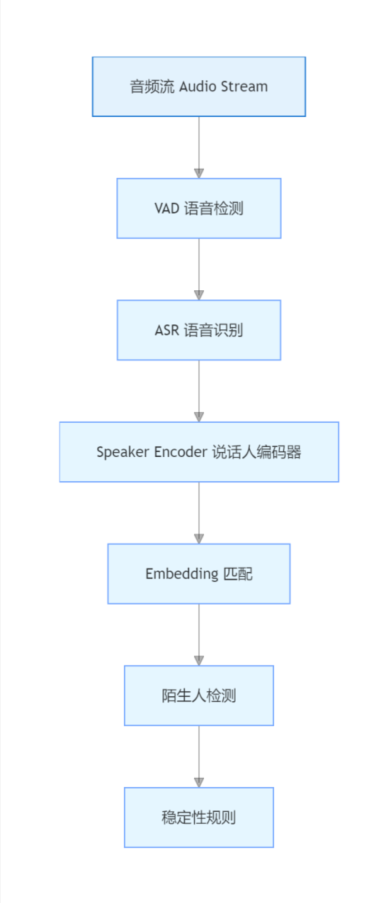
六、整体识别架构
完整系统通常是这样的:
角色输出如果用简单结构表示:

七、效果对比
在实际项目测试中(30分钟会议数据):
优化前:
角色错误率:18%+
角色数量膨胀:严重
频繁漂移优化后:
角色错误率:5%以内
漂移基本消失
角色数量稳定在真实会议纪要系统中,可读性提升非常明显 。
在长时间会议场景中,语音角色识别往往容易出现误识别和角色漂移的问题。通过在声纹识别体系中引入陌生人机制 与稳定性规则 ,可以有效提升多角色识别的稳定性与准确率,使长会场景下的角色归属更加可靠。基于这一技术能力构建的离线AI会议秘书 ,支持私有化部署,保障数据安全与高保密需求,同时提供98.6%准确率的语音转文字、多语言识别、声纹识别、AI会议纪要与知识问答 等能力。系统支持服务器版、单机版及SDK/API接入 等多种服务模式,并可配合AI录音卡、AI电子工牌等移动录音设备 使用,满足政企会议记录、访谈纪要与知识沉淀等多场景需求。