文章目录
以如下二叉树为例:
python
1
/ \
2 3
/ \
4 5
94.二叉树的中序遍历
给你二叉树的根节点 root ,返回它节点值的 中序 遍历。
示例 1 :
输入 :root = 1,null,2,3
输出 :1,3,2
解释 :
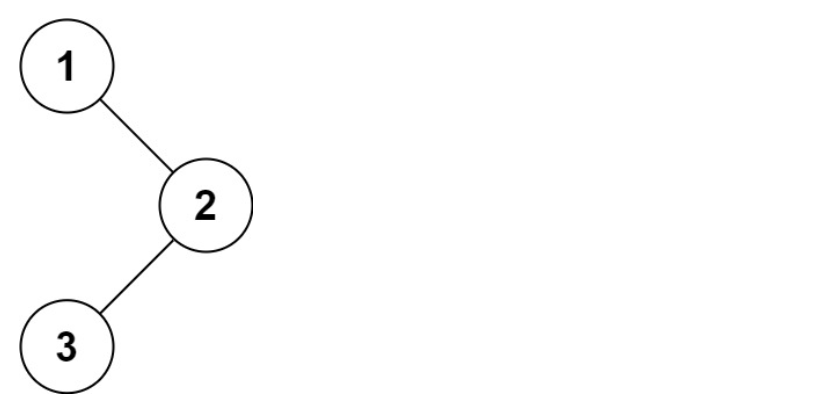
示例 2 :
输入 :root = \[\]
输出:\[\]
示例 2 :
输入 :root = 1
输出:1
提示 :
树中节点数目在范围 0, 100 内
-100 <= Node.val <= 100
进阶:递归算法很简单,你可以通过迭代算法完成吗?
中序遍历顺序:左 → 根 → 右
递归
思路
二叉树递归遍历是最自然的方式,因为树结构本身就是递归结构。
中序遍历的规则是:
遍历左子树 -> 访问当前节点 -> 遍历右子树
因此递归函数的逻辑就是:
如果节点为空 → 返回否则:
递归遍历
左子树记录
当前节点值递归遍历
右子树
整个遍历过程实际上依赖 函数调用栈 来保存遍历状态。
代码实现(Go)
go
package main
import "fmt"
// 定义二叉树结构
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// 中序遍历(递归)
func inorderTraversal(root *TreeNode) []int {
res := []int{} // 用于存储遍历结果
// --------------------------
// 定义递归函数 dfs
// --------------------------
// 注意这里分两步:
// 1. var dfs func(node *TreeNode)
// - 声明一个函数变量 dfs,类型是 "接受 *TreeNode 参数、返回 void" 的函数
// - 先声明是因为 Go 不允许在函数体内部直接递归调用匿名函数,如果直接写:
// func(node *TreeNode){ dfs(node.Left) ... }
// Go 会报错,因为 dfs 还不存在
// 2. dfs = func(node *TreeNode) { ... }
// - 给 dfs 赋值一个匿名函数(闭包)
// - 闭包的好处:
// a. 可以访问外部变量 res(这里就是捕获了 res)
// b. 可以在函数内部递归调用自己 dfs
var dfs func(node *TreeNode)
dfs = func(node *TreeNode) {
// 递归终止条件
if node == nil {
return
}
// 递归遍历左子树
dfs(node.Left)
// 访问当前节点(根)
res = append(res, node.Val) // 这里闭包捕获了外部的 res
// 递归遍历右子树
dfs(node.Right)
}
// 从根节点开始递归
dfs(root)
return res
}
func main() {
// 构造示例二叉树:
// 1
// \
// 2
// /
// 3
root := &TreeNode{Val: 1}
root.Right = &TreeNode{Val: 2}
root.Right.Left = &TreeNode{Val: 3}
result := inorderTraversal(root)
fmt.Println(result) // 输出: [1 3 2]
}-
时间复杂度 :O(n) 每个节点只访问一次。
-
空间复杂度 :O(h) h 为树高度(递归调用栈深度)。
- 最坏情况(链状树):O(n)
迭代(进阶)
思路
中序遍历顺序:
左 → 根 → 右
迭代版(统一模板思路):
- 从根节点开始 ,准备一个空栈 、一个空结果数组。
- 只要 当前节点不为空 或者 栈里还有节点,就继续循环。
- 内层循环:一路向左走到最深处
- 只要当前节点不是空 :
- 把这个节点压入栈(保存起来,因为左边走完后,还要回来访问根、处理右子树)
- 当前节点移动到它的左孩子(继续往左走)
- 只要当前节点不是空 :
- 内层循环结束 = 左边已经彻底走到底了
- 现在必须回头 :
- 从栈里取出最后压入的节点(这是最近一次经过的根)
- 把这个节点从栈里删除
- 访问这个节点(中序:左子树全部遍历完,才能访问根)
- 当前节点移动到它的右孩子(去处理右子树)
- 回到第2步,重复执行
- 直到当前节点为空 + 栈也为空,遍历结束
代码实现(Go)
go
package main
import "fmt"
// 二叉树节点定义
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// 中序遍历 迭代法(左 -> 根 -> 右)
func inorderTraversal(root *TreeNode) []int {
// 结果集合
res := []int{}
// 创建栈并初始化,将根节点 root 放入栈中
// 栈用来模拟递归的调用顺序,LIFO(后进先出)
// 这里类型是 []*TreeNode,表示栈里存放的是指向 TreeNode 的指针
// 用切片模拟栈,存储待处理的节点
stack := []*TreeNode{}
// 只要 当前节点不为空 或 栈里还有东西,就继续
for root != nil || len(stack) > 0 {
// ----------------------
// 第一步:一路向左,只入栈不访问
// ----------------------
for root != nil {
stack = append(stack, root) // 把自己存进栈
root = root.Left // 继续往左
}
// ----------------------
// 第二步:左边走到底了,回头
// ----------------------
root = stack[len(stack)-1] // 拿出最后存的节点
stack = stack[:len(stack)-1]// 删掉它(出栈)
// ----------------------
// 第三步:访问当前节点
// ----------------------
res = append(res, root.Val)
// ----------------------
// 第四步:去右边 继续重复
// ----------------------
root = root.Right
}
return res
}
func main() {
// ======================
// 构造输入二叉树
// 1
// \
// 2
// /
// 3
// ======================
root := &TreeNode{Val: 1}
root.Right = &TreeNode{Val: 2}
root.Right.Left = &TreeNode{Val: 3}
// 执行遍历
result := inorderTraversal(root)
// 输出结果
fmt.Println("中序遍历结果:", result) // 预期输出 [1 3 2]
}时间复杂度 :O(n)
- 每个节点访问一次
- 没有重复/多余操作
空间复杂度 :O(h)
- h = 二叉树高度
- 栈只保存一条路径上的节点
- 最坏:树是一条链 → O(n)
- 平均:平衡树 → O(log n)
思路
递归本质上依赖 函数调用栈 ,因此可以使用 显式栈(stack) 来模拟递归过程。
中序遍历的规则是:
遍历左子树 -> 访问当前节点 -> 遍历右子树
遍历步骤:
1 创建栈,定义当前节点指针指向根节点
2 循环:
若当前节点
不为空→ 入栈,当前节点指向左子节点若当前节点
为空→ 弹出栈顶节点,记录节点值 ,当前节点指向右子节点3 栈为空且当前节点为空时结束遍历
核心逻辑:一路向左走到尽头,再回溯访问根节点,最后处理右子树
代码实现(Go)
go
package main
import "fmt"
// 定义二叉树结构
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
// 中序遍历(迭代)
func inorderTraversal(root *TreeNode) []int {
res := []int{}
// 创建栈并初始化,将根节点 root 放入栈中
// 栈用来模拟递归的调用顺序,LIFO(后进先出)
// 这里类型是 []*TreeNode,表示栈里存放的是指向 TreeNode 的指针
stack := []*TreeNode{}
// 用切片模拟栈,保存访问过但右子树未处理的节点
// cur 指向当前遍历的节点,一路向左推进
// 当前遍历的节点
cur := root
// 栈不为空 或 当前节点不为空 就继续循环
for len(stack) > 0 || cur != nil {
// 一路向左,把所有左节点入栈
if cur != nil {
stack = append(stack, cur)
cur = cur.Left
} else {
// 左节点走到头,弹出栈顶(最左节点)
cur = stack[len(stack)-1]
stack = stack[:len(stack)-1]
// 访问当前节点
res = append(res, cur.Val)
// 处理右子树
cur = cur.Right
}
}
return res
}
func main() {
// 构造示例二叉树:
// 1
// \
// 2
// /
// 3
root := &TreeNode{Val: 1}
root.Right = &TreeNode{Val: 2}
root.Right.Left = &TreeNode{Val: 3}
result := inorderTraversal(root)
fmt.Println(result) // 输出: [1 3 2]
}
/*
迭代核心逻辑:
1. 先把所有左孩子压入栈,直到最左侧叶子节点
2. 出栈并访问节点,再处理该节点的右子树
3. 重复上述步骤,完成中序遍历
*/-
时间复杂度:O(n) 每个节点访问一次。
-
空间复杂度 :O(n)
最坏情况下(树退化成链表),栈需要存储 n 个节点。
-
一路向左推进
cur = cur.Left,每走一个节点都入栈- 栈里保存的是还没访问的父节点
- 你走到最左边的叶子节点 → 它左右都是空 → cur=nil
-
回溯访问左子树
- cur=nil → 出栈栈顶节点
- 弹出的就是
最左的节点→ 访问它(左子树访问完毕) - 然后 cur 指向它的
右子节点(如果有)
-
继续回溯访问父节点
- 如果右子树为空 → cur=nil →
继续出栈父节点 - 访问父节点 → 对应中序遍历中的"根"
- 然后把 cur 指向它的右子树 → 如果右子树不为空 ,沿右子树
重复"向左推进"的步骤这个时候这个右子树的结点就是根,会先加入栈,之后先弹出。
- 如果右子树为空 → cur=nil →
-
处理右子树
- 右子树非空 → cur 指向右子树 → 重复整个流程
- 右子树为空 → cur=nil → 回到上一层父节点 → 出栈访问
假设树是:
bash
1
/ \
2 3
/ \
4 5- 栈变化:
Bash
初始:stack=[], cur=1
1. cur=1 → 入栈(stack=[1]) → cur=2
2. cur=2 → 入栈(stack=[1,2]) → cur=4
3. cur=4 → 入栈(stack=[1,2,4]) → cur=nil
4. cur=nil → 出栈4,访问4 → cur=4.Right=nil
5. cur=nil → 出栈2,访问2 → cur=2.Right=5
6. cur=5 → 入栈(stack=[1,5]) → cur=nil
7. cur=nil → 出栈5,访问5 → cur=5.Right=nil
8. cur=nil → 出栈1,访问1 → cur=1.Right=3
9. cur=3 → 入栈(stack=[3]) → cur=nil
10. cur=nil → 出栈3,访问3 → cur=3.Right=nil- 输出顺序:4,2,5,1,3 中序遍历
递归实现更直观,但在工程实践中迭代版本可以避免递归栈过深导致的栈溢出问题,因此在某些场景下会优先选择迭代实现。