前言
在 Langchain-RAG中学习了RAG的整个流程。今天简单实现一个基于Langchain-RAG的Web网页摘要检索。
需求背景
我们在日常可能需要获取某个网页的核心信息,但是该网页信息又过多,我们无暇一一阅读。如果有个工具能将网页正文信息的摘要总结一下,这样我们在看的时候就大大提高了效率。ok,今天我们就用 Langchain 实现这样一个功能。
项目代码
WebBaseLoader
WebBaseLoader 是LangChain社区(langchain_community.document_loaders)提供的一个文档加载器(Document Loader) ,其核心功能是从指定的网页URL抓取内容,并将其解析、清洗、封装成LangChain标准的Document对象。
核心流程:
- 发起请求 :内部使用
requests库向目标URL发送HTTP GET请求,获取原始的HTML源码。 - 解析与清洗 :利用
BeautifulSoup4库解析HTML,智能地剥离脚本、样式表、导航栏、页脚等无关的HTML标签,提取出核心的正文文本内容。 - 标准化输出 :将提取的文本和元数据(如来源URL、标题)打包成一个或多个
Document对象。每个Document对象主要包含page_content(文本内容)和metadata(元数据)。
网页 -> 文档
-
web_path:网页地址
-
bs_kwargs:解析指南
- bs4.SoupStrainer(id="UCAP-CONTENT") 表示解析内容为
UCAP-CONTENT段
- bs4.SoupStrainer(id="UCAP-CONTENT") 表示解析内容为
我们打开 网页 ,我们需要的是 正文 ,页头、页脚等都不需要。查看网页源码不难发现,detailContent段正是我们想要的。
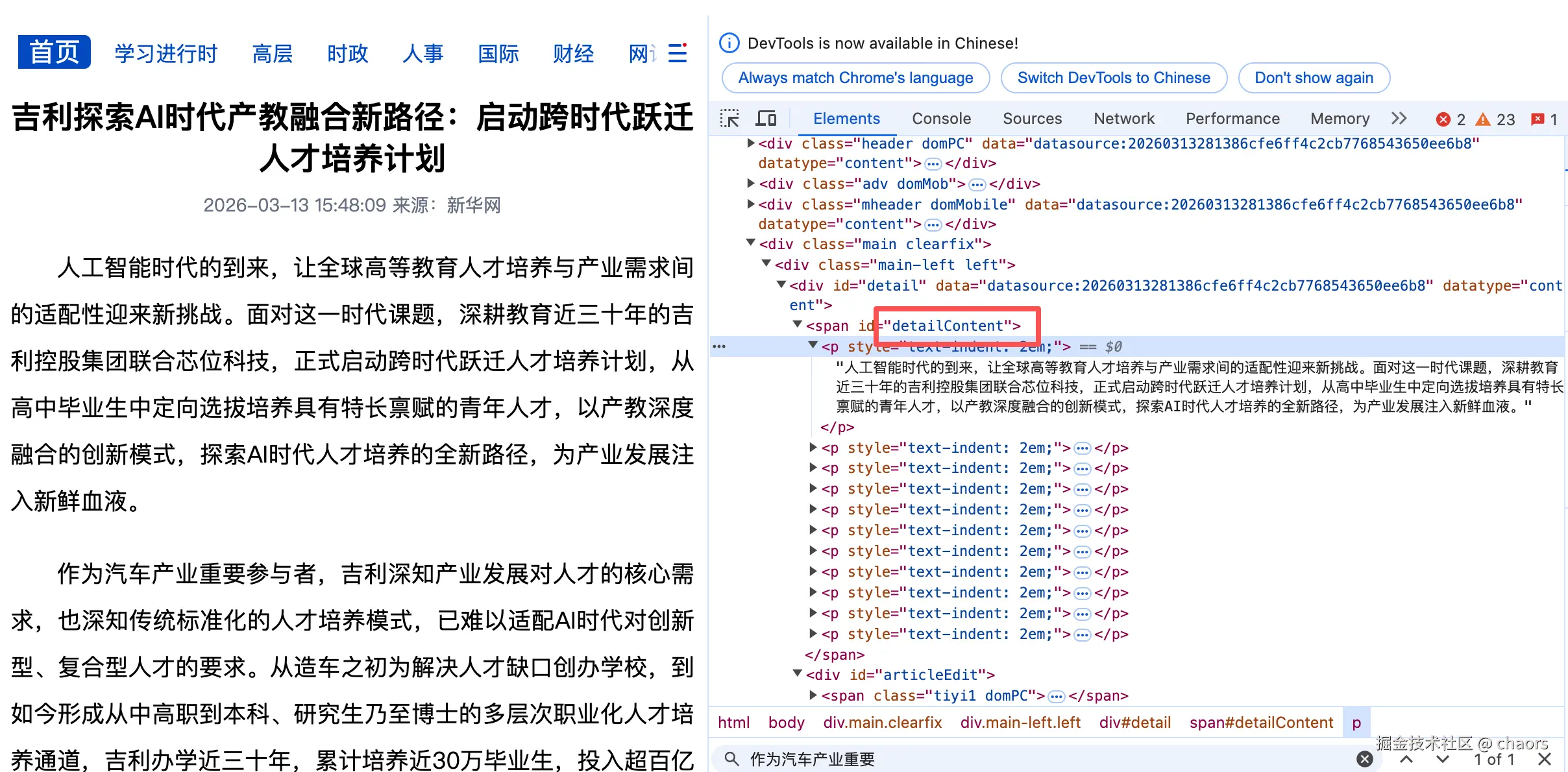
python
loader = WebBaseLoader(
web_path="https://www.gov.cn/yaowen/liebiao/202603/content_7061810.htm",
# bs_kwargs=dict(parse_only=bs4.SoupStrainer(id="UCAP-CONTENT"))
# 分割,将网页中目标内容进行分割
bs_kwargs={"parse_only":bs4.SoupStrainer(id="UCAP-CONTENT")}
)
docs = loader.load()准备工作
ini
#文本的切割
splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=100)
documents = splitter.split_documents(docs)
# for s in documents:
# print(s,end="**\n")
# 实例化向量空间
vector_store = Chroma.from_documents(documents=documents,embedding=llm_embeddings)
#检索器
retriever = vector_store.as_retriever()
# 注意这里的prompt模板中包含 {context} 和 {input} 的模板
#需要使用{context},这个变量,来表示上下文,这个变量,会自动从retriever中获取。
#而human中也限定了变量{input},链的必须使用这个变量。
system_prompt = """
您是问答任务的助理。使用以下的上下文来回答问题,
上下文:<{context}>
如果你不知道答案,不要其他渠道去获得答案,就说你不知道。
"""
prompt_template = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
("human", "{input}")
]
)摘要
方法一:内置检索链
- retrieval_chain + documents_chain
ini
# ====================== 方式1:retrieval_chain + documents_chain ======================
#创建链,预定义链 create_stuff_documents_chain 文档链
documents_chain = create_stuff_documents_chain(client,prompt_template)
# 参数1:是检索器 参数2:是文档链
retrieval_chain = create_retrieval_chain(retriever, documents_chain)
# 用大模型生成答案
resp = retrieval_chain.invoke({"input":"会议说了什么?"})
print("=========方式1:retrieval_chain + documents_chain==========")
print(resp["answer"])方法二:内置摘要链
- load_summarize_chain
代码
ini
# 定义明确要求中文摘要的提示词模板
# 注意:{text} 是占位符,链会自动将文档内容填充到这里
prompt_template = """请用中文,简洁地总结以下文本的主要内容:
{text}
请确保摘要完全使用中文,并涵盖核心要点。
中文摘要:"""
prompt = PromptTemplate(template=prompt_template, input_variables=["text"])
summarize_chain = load_summarize_chain(
llm=client,
chain_type="stuff", # 使用stuff策略
prompt=prompt
)
# 4. 执行摘要
summary = summarize_chain.invoke(docs)注意事项
- invoke入参是 loader.load() 加载好的Document对象,而不是方法一经过切割处理的Document。这里是二者的不同,一定要注意。
ini
summary = summarize_chain.invoke(docs)- 当我们直接调用,不指定任何约束的时候会发现:输出的摘要是英文。
ini
summarize_chain = load_summarize_chain(
llm=client,
chain_type="stuff" # 使用stuff策略
)
# 执行摘要
summary = summarize_chain.invoke(docs)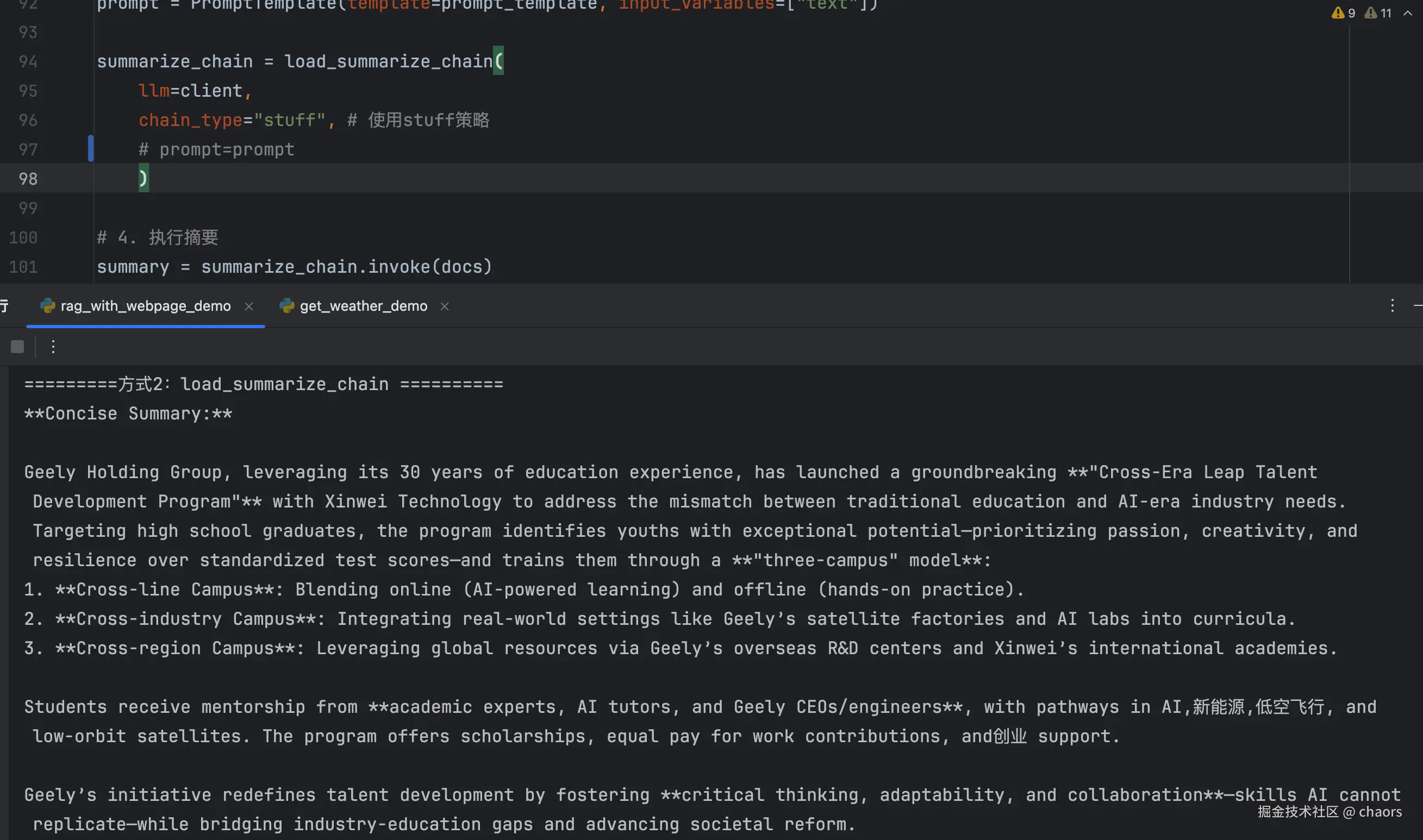
-
那么问题来了:输入纯中文文档,但通过LangChain的
load_summarize_chain函数处理后,摘要输出却变成了英文。这是为什么捏?- 这个问题本质上不是代码或框架的Bug,而是对大模型(LLM)工作模式 和LangChain默认配置 的理解偏差。它触及了当前AI应用开发中一个非常典型且关键的"黑箱"问题:我们如何精确地控制大模型的输出行为? 其实就是提示词工程的范畴。
- 原因当然那很简单:load_summarize_chain内部实现默认了一个 Prompt Template,这个模版里要求输入英文。
- 经验之谈: "隐式"不如"显式" 。在AI工程实践中,所有关键要求(如输出格式、语言、风格、长度)都必须通过提示词显式、无歧义地传递。依赖模型的"隐式推断"是系统不稳定和结果不可控的主要根源。
方案对比


两个方式总结的摘要都差不多,不过方式1比较谨慎还对摘要做出了声明仅基于给定上下文得出。
扩展思考
至此,就实现了一个网页的内容摘要提取。那么,当我们需要提取大量网页内容的时候,无非是基于这个去做拓展。比如,当数量级上去以后,我们可以限定摘要的字数,然后将网页分类,同类信息搜集到一个表格。后续就可以基于这些信息做数据分析和处理。