近年来,大型语言模型(LLM)已经能根据指令生成各种文本,但你是否遇到过这样的尴尬:问"什么是LLM?",模型只回答"它是一个LLM",然后戛然而止。虽然从字面上看它没答错,但显然我们更希望得到一个详细的、有深度的解释。这种差异揭示了当前模型的短板------它们擅长"完成任务",但不一定理解什么是对人类更有用、更可接受 的回答。为了让模型真正与人类的期望对齐,研究者引入了一项关键训练:偏好调优(Preference Tuning)。本文将用最通俗的语言,带你深入理解这个让AI变得更"贴心"的技术。
1. 从"能回答"到"会回答"
传统的语言模型训练主要关注语言建模------预测下一个词的概率。经过指令微调后,模型可以按照指令生成答案。但指令微调只能让模型学会"照办",却无法区分哪种答案质量更好。例如,同样是解释"LLM":
-
答案A:"LLM是大语言模型。"
-
答案B:"LLM是Large Language Model的缩写,指基于海量文本训练的大型神经网络,能够理解和生成人类语言,广泛应用于对话、写作、代码生成等领域。"
显然,答案B更符合我们的偏好。但如何让模型学会自动输出B而不是A呢?这就是偏好调优要解决的问题。
2. 偏好调优的核心思想:用反馈引导模型
想象一下,我们有一个学生(LLM),每次做题(生成答案)后,老师(人类评估者)都会打分。如果得分高,就鼓励学生继续这样做;得分低,就提醒他避免类似错误。经过大量练习,学生自然学会输出高分答案。
偏好调优正是这种思路:让模型从人类的偏好反馈中学习。具体流程如下:
-
输入提示词:给模型一个任务或问题(例如"什么是LLM?")。
-
生成回答:模型产生多个候选答案。
-
评估质量:由人类评估者对每个答案打分(例如1-5分)。
-
更新模型:如果分数高,就通过优化算法让模型更倾向于生成这类答案;如果分数低,则抑制这类生成模式。
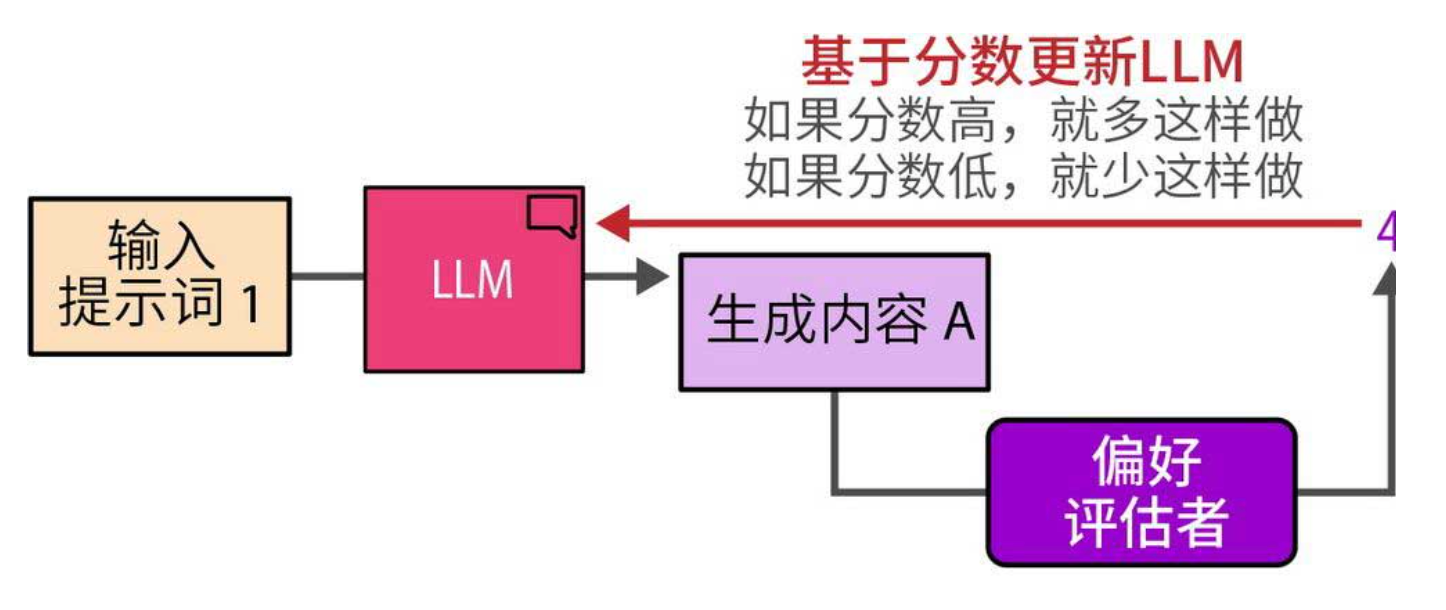
这个过程在图中被形象地展示:人类给出分数后,模型参数朝鼓励高分生成的方向更新(下图)。通过成千上万个样本,模型逐渐学会模仿人类偏好的输出风格、详细程度、准确性等。
3. 自动化的关键:奖励模型(Reward Model)
人工评估虽然准确,但成本高、速度慢,无法规模化。那么有没有办法让评估过程自动化呢?答案是训练一个奖励模型。
奖励模型本质上也是一个神经网络,它的任务是:给定输入提示词和模型生成的答案,预测人类会给这个答案打多少分。训练奖励模型的数据来自于人类标注的(提示词,答案,分数)三元组。一旦训练好,它就可以代替人类给新生成的答案打分。
奖励模型如何与LLM结合?
有了奖励模型,我们就可以构建一个闭环的优化系统:
-
策略模型:即我们想要优化的LLM,负责生成答案。
-
奖励模型:对生成的答案评分。
-
优化算法(如PPO,即近端策略优化):根据奖励分数调整策略模型的参数,使未来的生成能获得更高奖励。
这一整套流程被称为基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback)。著名的ChatGPT、Claude等模型都采用了类似技术,从而变得能言善辩、善解人意。
4. 偏好调优的深层意义:对齐人类价值观
偏好调优不仅让模型回答更详细、更准确,更重要的是,它让模型的行为与人类的伦理、价值观对齐。例如:
-
当用户提出有害请求时,模型学会拒绝而不是迎合;
-
当讨论敏感话题时,模型保持中立、客观;
-
当用户表达情感时,模型能以同理心回应。
这些微妙的行为无法通过简单的指令微调习得,必须依靠大量的偏好数据来引导。这正是当前大模型安全性和可用性的核心保障。
5. 实践中的挑战与未来
尽管偏好调优效果显著,但实现起来并非易事:
-
数据收集困难:高质量的偏好数据需要大量人工标注,成本高昂。
-
奖励模型的偏差:如果奖励模型本身有偏见(例如偏爱冗长答案),就会放大到LLM中。
-
多目标权衡:有时详细和简洁、创造性和准确性之间存在矛盾,如何平衡仍需探索。
未来,研究者正尝试引入更多自动化方法(如AI自我评判、宪法AI等)来降低对人工的依赖,同时确保模型更稳健、更安全。
总结
偏好调优是让大语言模型从"能回答问题"进化为"会回答问题"的关键一步。它通过引入人类反馈(或奖励模型模拟的反馈)来引导模型生成更符合期望的内容。这一过程不仅提升了回答质量,更使模型与人类的价值观对齐,成为安全、可信赖的智能助手。理解偏好调优,就等于掌握了大模型最后、也是最人性化的一道训练关卡。未来,随着技术的演进,我们有望看到更智能、更贴心的AI融入生活,真正成为人类的伙伴。
本文参考:图解大模型:生成式AI原理与实战
书籍pdf免费下载地址:https://pan.baidu.com/s/1mTaUQ5czcfGpBM8KvJuS2g?pwd=un44