了解更多银河麒麟操作系统全新产品,请点击访问:
麒麟软件产品专区:https://www.kylinos.cn/productPc/
开发者专区:https://developer.kylinos.cn/
文档中心:https://document.kylinos.cn/document/center
目录
[一、I/O 流程概述](#一、I/O 流程概述)
[1.1、读 I/O 概述](#1.1、读 I/O 概述)
[1.2、写 I/O 概述](#1.2、写 I/O 概述)
[1.3、裸设备 IO 读写机制](#1.3、裸设备 IO 读写机制)
[1.3.1 裸设备 IO 的定义与特性](#1.3.1 裸设备 IO 的定义与特性)
[1.3.2 裸设备 IO 读概述](#1.3.2 裸设备 IO 读概述)
[1.3.3 裸设备 IO 写概述](#1.3.3 裸设备 IO 写概述)
一、I/O 流程概述
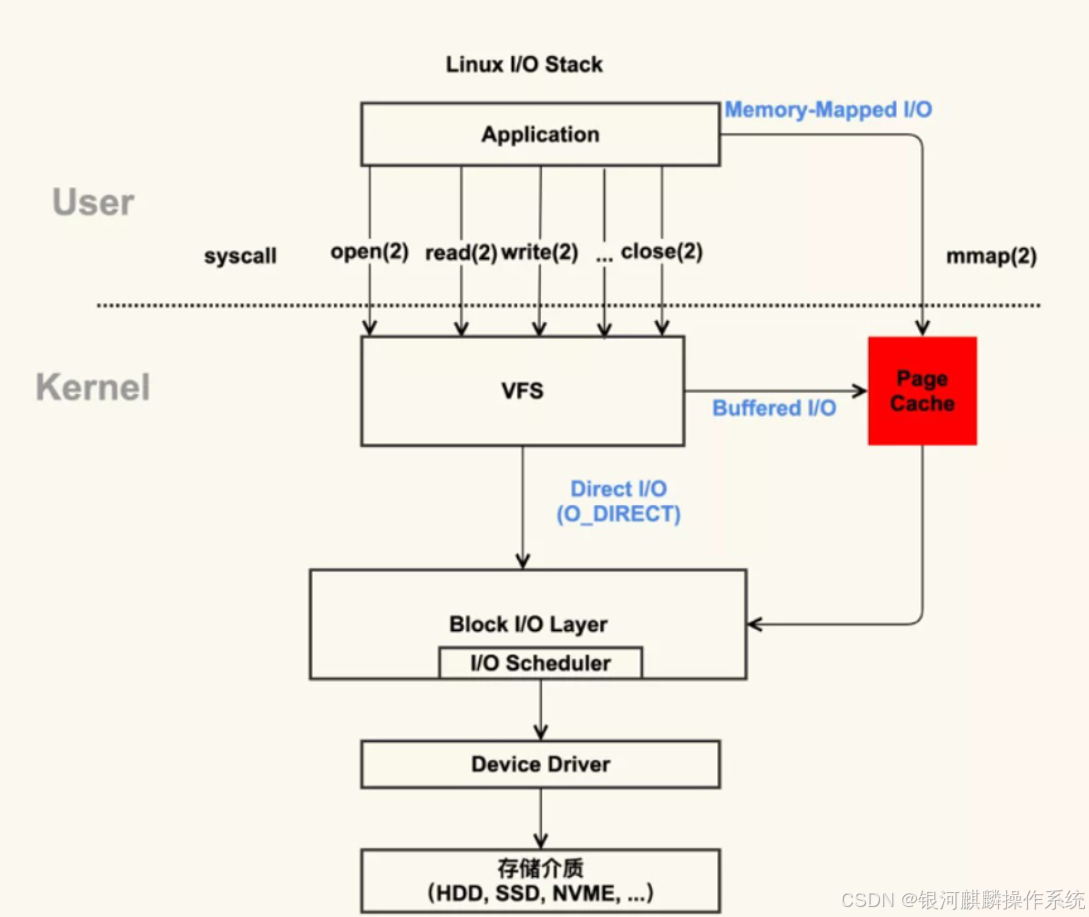
在 Linux 系统中,传统的访问方式是通过 write() 和 read() 两个系统调用实现的,通过 read() 函数读取文件到到缓存区中,然后通过 write() 方法把缓存中的数据输出到文件。
1.1、读 I/O 概述
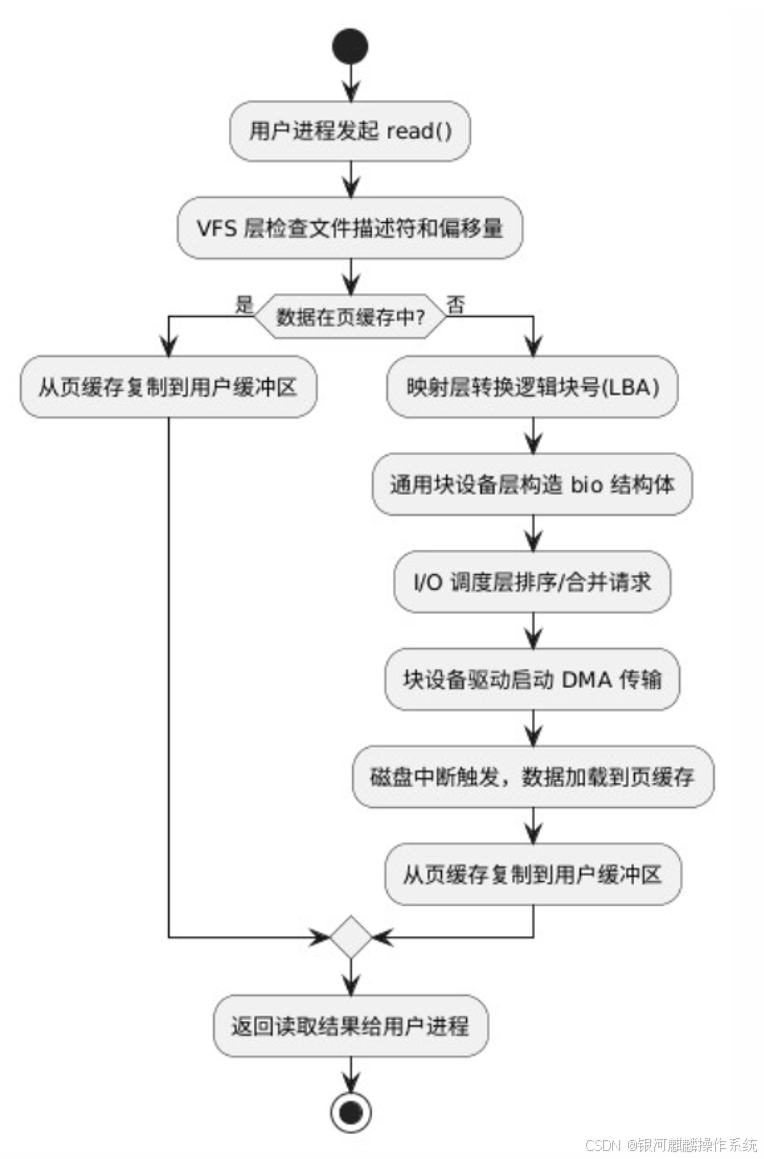
以 BufferIO 为例(与之对应的是 DirectIO,不读写 PageCache),当应用程序执行 read 系统调用读取一块数据的时候,如果这块数据已经存在于用户进程的页内存中,就直接从内存中读取数据。如果数据不存在,则先将数据从磁盘加载数据到内核空间的读缓存(Read Buffer)中,再从读缓存拷贝到用户进程的页内存中,过程如下:
a、用户进程(用户态)发起读请求,并从用户态通过 read() 函数向 Kernel 发起 System Call,上下文从 user space 切换为 kernel space。
b、系统调用 read() 会触发相应的 VFS(Virtual Filesystem Switch) 函数,传递的参数有文件描述符和文件偏移量。通过文件描述符 fd 找到对应的 inode,检查文件可读性。
c、VFS 确定请求的数据是否已经在内存缓冲区中,若在,数据从内核复制至用户态 buffer,然后应用程序读取,若数据不在内存中,将文件偏移量转换为逻辑块号(LBA)。
d、假设内核必须从块设备上读取数据,这样内核就必须确定数据在物理设备上的位置。这由映射层(Mapping Layer)来完成。
e、内核通过通用块设备层(Generic Block Layer)在块设备上执行读操作,构造 bio 结构体,包含目标设备、LBA 范围、数据方向(读),启动 I/O 操作。传输请求的数据。
f、在通用块设备层之下是 I/O 调度层(I/O Scheduler Layer),根据内核的调度策略,对等待的 I/O 等待队列排序和合并。
g、块设备驱动(Block Device Driver)驱动将逻辑块号转换为物理扇区地址,启动 DMA 传输,数据流向为:磁盘 → 控制器缓存 → Page Cache(由 DMA 完成),若为同步读,进程阻塞等待数据就绪。
h、最后,磁盘中断触发后,将 Page Cache 数据复制到用户缓冲区,唤醒进程,返回读取结果。
1.2、写 I/O 概述
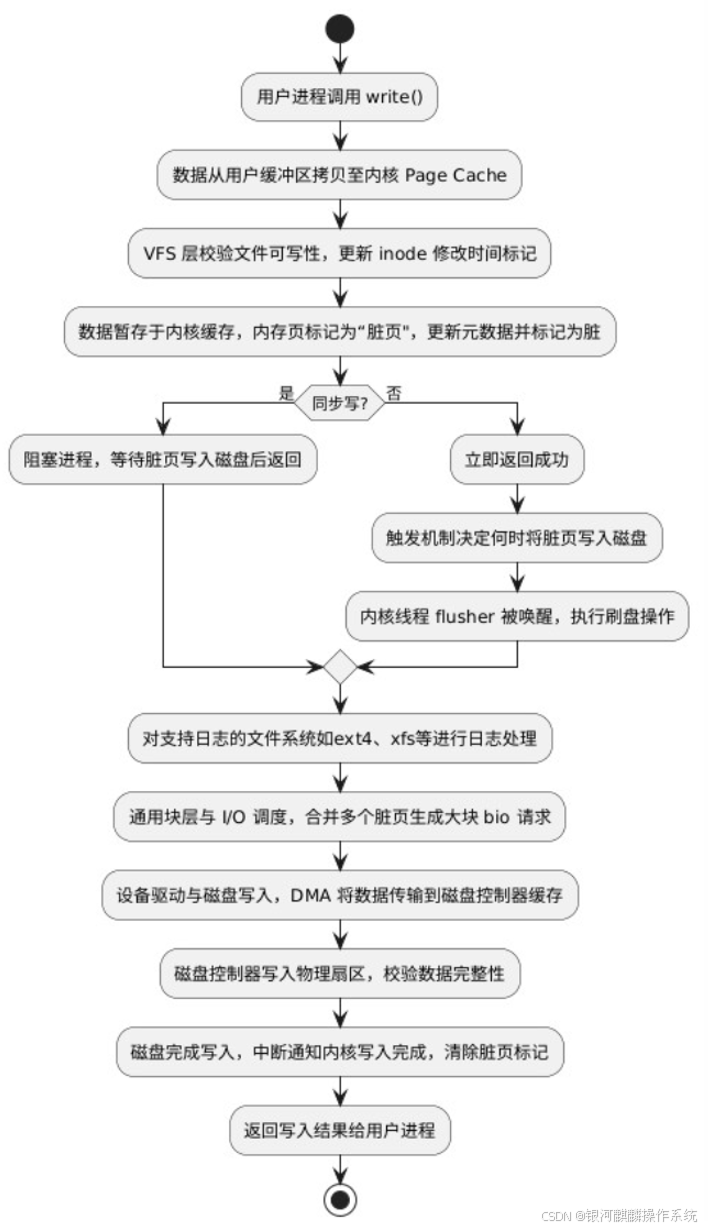
a、用户进程调用 write() 将数据从用户缓冲区拷贝至内核 Page Cache(除非使用 mmap)。
b、VFS 层校验文件可写性,更新 inode 的修改时间标记。
c、数据暂存于内核缓存,对应的内存页标记为"脏页"(Dirty Page)并做元数据更新,比如文件大小、修改时间等元数据标记为脏。
d、此时如果是异步写,立即返回成功。
e、系统根据脏页留存时间、占用比例、系统内存压力等触发机制决定何时将脏页写入磁盘。当触发条件满足时,内核线程 flusher 被唤醒执行刷盘操作。
f、同步写则会阻塞进程,等待脏页写入磁盘后才返回。
g、对支持日志的文件系统如 ext4、xfs 等进行日志处理。
h、通用块层与 I/O 调度,合并多个脏页对应的写请求,生成大块 bio 请求。
i、设备驱动与磁盘写入,DMA 将数据从 Page Cache 传输到磁盘控制器缓存。磁盘控制器写入物理扇区,校验数据完整性(如 CRC)。
j、磁盘中断通知内核写入完成。除脏页标记,释放 Page Cache 空间(若需回收内存)。返回写入结果给用户进程。
1.3、裸设备 IO 读写机制
1.3.1 裸设备 IO 的定义与特性
裸设备(Raw Device)IO 是一种直接访问块设备的方式,允许应用程序绕过文件系统层,直接对底层存储设备进行读写操作。裸设备通常用于需要高性能、低延迟的应用场景,例如数据库管理系统(如 Oracle、MySQL 等)。
其与普通文件 I/O 的区别如下:
| 特性 | 裸设备 IO | 普通文件 I/O |
|---|---|---|
| 是否依赖文件系统 | 不依赖文件系统,直接访问块设备 | 依赖文件系统,通过文件路径访问 |
| 缓存机制 | 无缓存,数据直接从用户缓冲区传输到磁盘或从磁盘传输到用户缓冲区 | 数据会经过 Page Cache,操作系统负责缓存管理和同步 |
| 性能 | 更高效,适合低延迟、高吞吐量的场景 | 性能稍低,但借助文件系统缓存可提高重复读取的效率 |
| 元数据管理 | 无元数据管理,应用程序需手动维护数据一致性 | 文件系统自动管理元数据(如 inode、文件大小、权限等) |
| 开发复杂度 | 开发复杂度高,需手动管理数据布局、一致性及错误恢复 | 开发简单,文件系统提供高级抽象,开发者无需关注底层细节 |
| 适用场景 | 数据库事务日志、高性能计算、实时性要求高的应用 | 普通文件读写、日常应用程序 |
| 数据一致性 | 应用程序需自行保证数据一致性 | 文件系统提供一致性保障,崩溃后可通过日志恢复 |
| 块大小限制 | 需遵循设备的块大小(如 512 字节或 4KB),对齐要求严格 | 文件系统屏蔽了块大小限制,开发者无需关心 |
| 错误处理 | 错误处理由应用程序负责 | 文件系统和操作系统提供错误处理机制 |
1.3.2 裸设备 IO 读概述
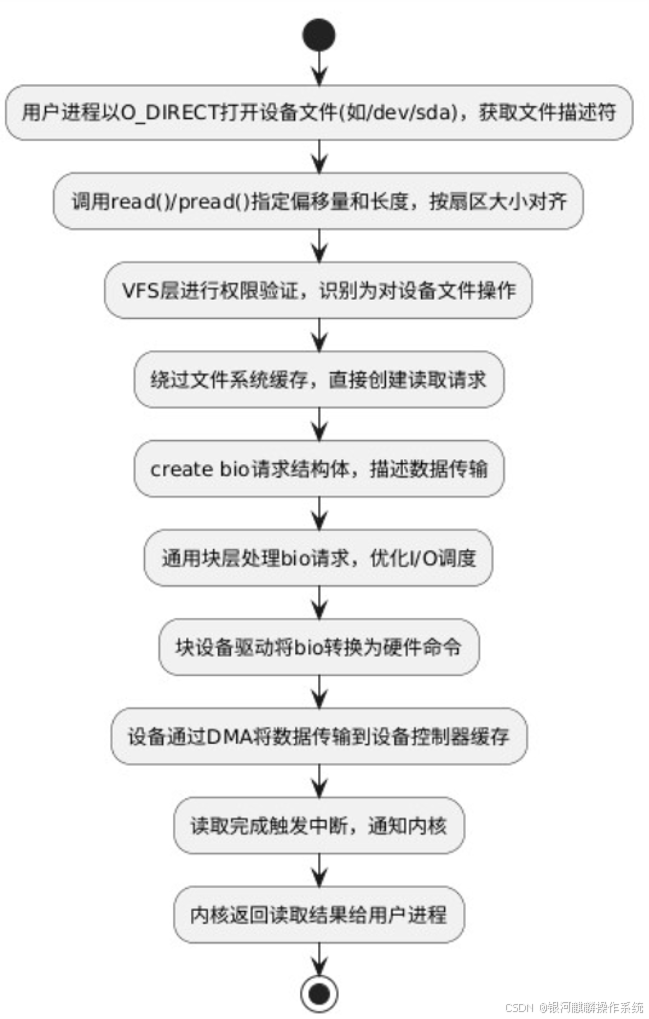
a、用户进程通过 open() 以 O_DIRECT 标志打开设备文件,获取文件描述符。
b、用户进程调用 read()/pread() 函数,指定要读取的设备偏移量和长度。读取请求必须按设备扇区大小对齐。
c、VFS 层验证文件描述符权限,识别这是对设备文件的操作,并绕过常规文件系统处理路径。
d、绕过文件系统缓存,直接创建读取请求。
e、创建 bio 请求结构体,描述数据传输的来源(设备扇区)和目标(用户空间缓冲区)。
f、通用块层处理 bio 请求,应用 I/O 调度策略优化访问顺序。
g、块设备驱动将 bio 请求转换为设备特定的命令。
h、设备读取指定扇区的数据,通过 DMA 直接传输到存储设备控制器缓存。
i、读取完成后设备触发中断,中断处理程序通知内核操作已完成。
j、内核向用户进程返回读取的字节数或错误码。
1.3.3 裸设备 IO 写概述
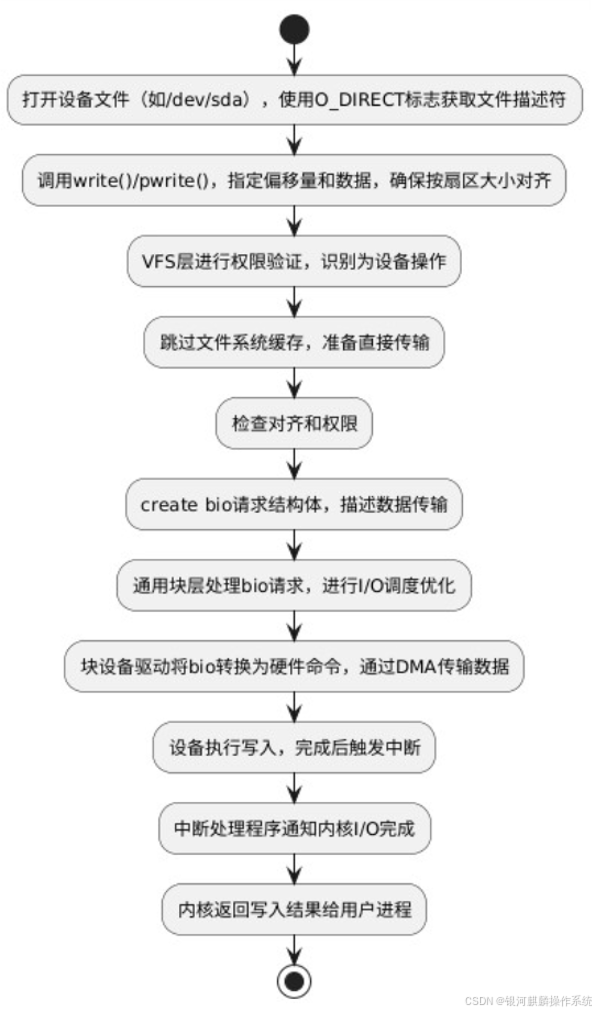
a、用户进程通过 open() 以 O_DIRECT 标志打开设备文件(如 /dev/sda),获取文件描述符。与常规 IO 不同,这里打开的是设备节点而非普通文件。
b、用户进程调用 write()/pwrite()函数,指定写入设备的偏移量和数据。由于是裸设备访问,数据必须按照设备扇区大小对齐(通常为 512 字节或 4KB)。
c、VFS 层验证文件描述符权限,识别这是对设备文件的操作,并绕过常规文件系统处理路径。
d、跳过了文件系统层,不存在 Page Cache 和脏页的概念,数据直接从用户空间准备传输到设备。
e、系统检查对齐要求和访问权限,确保写入操作合法。裸设备访问通常需要 root 权限或特定的设备访问权限。
f、调用块设备驱动的请求函数,创建 bio(Block I/O)请求结构体,描述数据传输信息。
g、通用块层接收 bio 请求,根据设备队列策略进行 I/O 调度,可能合并相邻请求以提高效率。
h、块设备驱动将 bio 请求转换为具体硬件操作,通常通过 DMA 直接将数据从用户空间传输到设备控制器。
i、设备执行物理写入操作,将数据写入指定扇区。完成后触发中断。
j、中断处理程序接收完成信号,通知内核 I/O 操作已完成。
k、内核通知用户进程写入完成,返回写入的字节数或错误码。
1.4、IO超时及重试机制
IO栈整体架构如下图:
- 工作流程
I/O 发起 :用户调用 read() → VFS → 文件系统 → Block 层提交请求。
超时触发:Block 层检测到请求超时 → 调用设备驱动的错误处理。
设备恢复:驱动尝试重置设备/重试命令 → 成功则继续,失败则标记错误。
错误 上报 :Block 层清理请求 → 文件系统处理错误(如 ext4 记录日志错误)→ VFS 返回用户态 -ETIMEDOUT 或 -EIO。
- VFS层
VFS 之上的系统调用 read/write 通常是阻塞的,无超时配置。VFS 层是虚拟文件系统层,主要职责是抽象和路由请求到对应的文件系统,VFS 本身不处理超时和重试,如果设备一直无响应,可能体现为 IO hung 住。一些文件系统可能自行实现超时重传,如 NFS 客户端可以通过设置 mount -o timeo,retrans 来设置超时和重试时间。
- 块设备层
块设备层负责管理请求队列、合并请求、调度策略等。每个 IO 关联一个默认 30 秒的定时器。超时后触发回调;块设备层一般不重试,由驱动或者上层应用重试。
scsi 设备存在 IO 处理超时时间,用户空间可以查看并修改:
cat /sys/block/sdx/device/timeout,默认为 90s
echo -n 60 > /sys/block/sdc/device/timeout
- 驱动层
驱动层负责与物理硬件交互,处理协议级超时。驱动层存在一些如 SCSI/NVME 命令超时配置,默认为 30s,命令超时会触发驱动的 error handler。
其中,nvme 设备超时时间可以被查看和修改:
cat /sy s/module/nvme_core/parameters/io_timeout,默认为 30s
echo -n 30 > /sys/module/nvme_core/parameters/io_timeout