@TOC 在企业级业务系统的实际应用中,SQL语句早已脱离了教科书式的简洁形态。随着业务逻辑的层层叠加,CTE、多层嵌套子查询、窗口函数与聚集计算成为构建复杂查询的常用手段,虽提升了代码的可读性与逻辑组织性,却也给数据库查询优化器带来了严峻挑战。其中,JOIN条件无法有效下推至子查询,导致过滤操作滞后引发的性能瓶颈,成为众多业务场景中的共性问题。本文结合真实客户的业务痛点,深入探讨基于代价模型的连接条件下推优化方案的设计思路、实现逻辑与实际效果,为复杂SQL查询的性能优化提供可行思路。
一、复杂查询的性能痛点与优化难点
1.1 业务场景中的典型性能问题
在实际业务开发中,技术人员常采用"子查询/CTE完成复杂计算+外层JOIN关联表并过滤"的SQL编写模式,这类语句在语义上完全符合业务需求,却隐藏着严重的执行性能隐患。典型示例为在子查询中对表进行去重、聚集等操作,外层通过JOIN关联其他表并施加高选择性过滤条件,从执行层面来看,子查询会对基表进行全量扫描与复杂计算,外层的高选择性过滤条件无法反向约束子查询的扫描范围,最终导致子查询输出海量中间结果集,后续的JOIN、聚集等操作均基于大数据量开展,查询性能急剧下降。
下面是一个典型的性能瓶颈 SQL:外层 JOIN 条件无法约束子查询,导致子查询全量扫描 + 去重。 
追本溯源,这类问题的核心并非JOIN操作本身,而是过滤条件生效时机过晚,未能在数据扫描与初步计算阶段发挥作用,造成了大量无效的数据处理与传输。
1.2 连接条件下推的两大核心难点
将外层JOIN条件下推至子查询内部,是解决上述问题的直观思路,但在数据库内核层面,这一优化并非简单的规则改写,而是面临着语义与性能的双重考验,也是业界普遍面临的技术难点。
(1)语义安全性的等价性判定
连接条件下推的本质是改变谓词的生效位置,若处理不当,极易破坏SQL的原始语义,导致查询结果出错。尤其是在包含聚集计算、窗口函数、DISTINCT/UNION去重合并,以及含有副作用、非确定性函数的表达式的场景中,谓词位置的变更可能直接改变数据的计算逻辑与结果集范围。因此,连接条件下推的首要前提是完成严格的等价性判定,明确哪些JOIN条件可以安全下推,哪些场景下的下推会导致语义失真。
(2)执行代价的合理性评估
即便某一JOIN条件在语义上满足下推的等价性要求,也不代表下推操作一定能带来性能提升,甚至可能适得其反。例如,条件下推后可能触发参数化执行,若外层查询基数较大,会导致子查询被重复执行多次;部分场景下,下推带来的过滤收益远无法抵消重复计算的成本,最终造成查询性能的灾难性下降。这意味着,连接条件下推不仅要解决"能不能推"的问题,更要精准判断"值不值得推"。
二、传统优化方案的执行局限
面对包含复杂子查询与外层JOIN的SQL语句,传统数据库查询优化器的执行策略存在明显的局限性,其核心问题在于无法实现外层条件对内部子查询的反向约束,具体执行流程可分为三步:
- 完整执行子查询:对基表进行全量扫描,依次完成DISTINCT、UNION、窗口函数等复杂计算操作,无任何提前过滤;
- 生成海量中间结果:子查询因缺乏过滤条件,会输出包含全量计算结果的中间数据集,数据规模通常较大;
- 外层执行JOIN与过滤:将子查询的中间结果与外层表进行JOIN关联,再施加过滤条件。
当子查询本身涉及复杂计算、基表数据量庞大时,这种"先全量计算、后关联过滤"的策略会让中间结果集的处理成为整个查询的性能瓶颈,大幅增加数据库的CPU、IO与内存开销。
三、基于"等价性+代价模型"的连接条件下推设计
针对传统方案的弊端,金仓数据库在V009R002C014版本中,设计并实现了一套双重约束的连接条件下推机制,将等价性判定作为安全前提,以代价模型作为决策依据,实现连接条件的智能、高效下推。整体优化思路分为"能不能推"与"值不值推"两个核心阶段,确保下推操作既不破坏SQL语义,又能切实提升查询性能。
优化器会遵循「谓词识别 - 安全校验 - 代价决策」的完整流程: 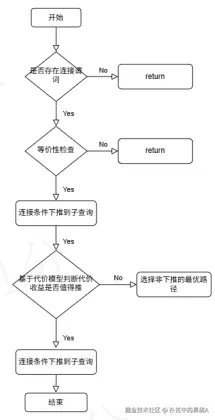
3.1 等价性判定:解决"能不能推"的安全问题
本阶段的核心目标是识别绝对安全的连接条件下推机会,而非追求下推的数量,优化器会通过多维度分析完成严格的等价性校验:
- 解析子查询的整体结构,判断其语法与计算逻辑是否满足条件下推的语义等价要求;
- 针对包含聚集、窗口函数、UNION等复杂操作的子查询,进行专项约束性判定,明确条件下推的边界;
- 对JOIN条件进行拆分,分离出依赖外层列的可参数化部分 与子查询内部列的独立部分。
对于通过所有等价性校验的JOIN谓词,优化器会将其改写为参数化过滤条件,注入到子查询的数据扫描或初步过滤阶段,从源头实现数据裁剪。这一阶段的核心价值,是确保"推下去之后,查询结果与原始SQL完全一致"。
3.2 代价模型评估:解决"值不值推"的性能问题
通过等价性判定仅代表连接条件具备下推的可能性,优化器并不会立即执行下推操作,而是进入代价评估阶段,通过量化分析选择整体执行代价最低的查询计划:
- 分别评估下推前后的两条执行路径,计算各自的总执行代价;
- 对比核心指标:子查询的基表扫描行数、中间结果集的规模、IO与CPU的开销;
- 重点评估参数化执行带来的重复计算成本,量化分析下推的收益与成本;
- 若代价模型判定下推操作的收益显著,即过滤带来的性能提升远大于额外产生的计算成本,则执行下推;若判定收益不足或可能导致性能回退,则自动放弃下推,选择传统执行路径。
这一阶段的核心价值,是确保"推下去之后,查询性能能得到切实提升"。
整体而言,优化器会先判断是否存在可下推的连接谓词,再通过等价性检查筛选出安全的下推条件,最后经代价模型评估后,决定是否执行下推并生成最优执行计划,形成"谓词识别-安全校验-代价决策"的完整优化链路。
四、多场景测试验证:下推优化的性能提升效果
为验证基于代价模型的连接条件下推机制的实际效果,我们设计了最小化用例 与复杂场景用例两组测试,对比条件下推开启与关闭状态下的执行时间、扫描方式、中间结果规模,同时与不支持该优化的主流数据库厂商进行性能对比。
4.1 最小化用例测试:基础场景的性能飞跃
测试SQL为包含DISTINCT子查询与JOIN关联的基础语句,核心验证简单场景下条件下推对扫描方式与执行效率的优化效果。
- 未下推状态:子查询对基表进行全表扫描+去重操作,无任何提前过滤,最终执行时间约84ms;
- 下推状态:JOIN条件被注入子查询扫描阶段,利用索引实现选择性扫描,数据在源头被裁剪,中间结果规模大幅下降,执行时间仅约0.14ms;
- 竞品对比:不支持连接条件下推的D厂商,该语句执行时间约1.62ms,远高于金仓数据库开启下推后的性能表现。
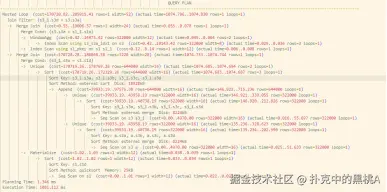
未开启下推优化时:子查询对 s3 全表扫描(Seq Scan),去重后生成 32200 行中间结果,执行时间为 84.788ms。 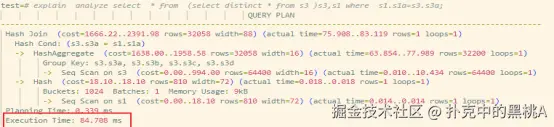 开启下推优化后:连接条件被下推至子查询,s3 利用索引扫描(Index Scan)仅处理 2 行数据,执行时间骤降至 0.143ms,性能提升约 600 倍。
开启下推优化后:连接条件被下推至子查询,s3 利用索引扫描(Index Scan)仅处理 2 行数据,执行时间骤降至 0.143ms,性能提升约 600 倍。 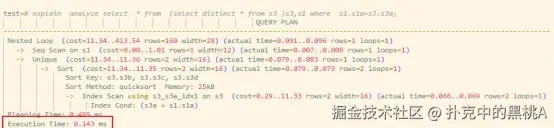 从执行计划树可以清晰看到,连接条件 S1.S1A = S3.S3A 已被下推到子查询内部,直接作用于 s3 的索引扫描:
从执行计划树可以清晰看到,连接条件 S1.S1A = S3.S3A 已被下推到子查询内部,直接作用于 s3 的索引扫描: 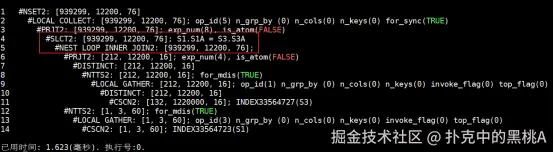
从测试结果来看,连接条件下推让基础场景的查询性能实现了数量级的提升,核心原因是将"全量扫描"转为"选择性扫描",从源头减少了无效数据的处理。
4.2 复杂场景测试:多操作嵌套的性能突破
测试SQL为包含UNION合并、DISTINCT去重、窗口函数、三层嵌套子查询与多表JOIN的复杂语句,贴合企业实际业务中的复杂查询场景,核心验证下推机制在多操作叠加场景下的适配性与优化效果。
- 未下推状态:多个子查询对基表进行全量扫描,依次完成UNION、DISTINCT、窗口函数计算,生成多个海量中间结果集,后续多轮JOIN均基于大数据量开展,成为性能瓶颈,整体执行时间约1081ms;
- 下推状态 :外层JOIN条件被逐层下推至各子查询的扫描阶段,所有子查询均由"全量扫描"转为"选择性扫描",数据在扫描阶段即被精准裁剪,中间结果集规模骤降,后续JOIN操作的开销大幅减少,整体执行时间仅约0.23ms。
复杂场景的测试结果表明,基于代价模型的连接条件下推机制,能够有效适配包含多种复杂操作的嵌套查询,通过提前过滤实现全链路的性能优化,即便在多操作叠加的场景下,仍能实现数量级的性能提升。
五、优化方案的核心价值与未来展望
复杂查询中的连接条件下推,并非简单的数据库规则改写,而是典型的成本驱动型优化问题:仅依靠规则判断下推可能性,忽略执行代价,可能导致查询性能的灾难性回退;仅关注执行代价,未做好语义等价性保障,则会直接破坏SQL语义,导致查询结果错误。
金仓数据库设计的"等价性保障+基于代价的决策"组合优化方案,实现了两大核心目标:一是在严格的语义等价前提下,最大化发挥JOIN条件的提前过滤能力,从源头减少数据扫描与中间结果规模;二是通过代价模型的量化分析,确保下推操作的收益大于成本,避免无效优化。从实际测试效果来看,该方案在基础与复杂查询场景中均能实现数量级的性能提升,有效解决了复杂SQL因过滤滞后引发的性能瓶颈。
从数据库技术的演进方向来看,这类基于代价模型的精细化查询优化,对于OLAP分析、混合负载处理以及复杂报表型查询具有至关重要的意义。未来,查询优化器的发展将更注重语义理解的深度 与代价评估的精度,结合人工智能、机器学习等技术,实现更智能的谓词优化、执行计划选择,让复杂SQL的性能优化更贴合业务实际需求,为企业级业务系统的高效运行提供更坚实的数据库内核支撑。