进阶10 分解质因数
求出区间a,b中所有整数的质因数分解。
输入两个整数a,b。
2<=a<=b<=10000
每行输出一个数的分解,形如k=a1*a2*a3...(a1<=a2<=a3...,k也是从小到大的)(具体可看范例)
cpp
3=3
4=2*2
5=5
6=2*3
7=7
8=2*2*2
9=3*3
10=2*5代码
cpp
#include <iostream>
#include <vector>
using namespace std;
int main() {
int a, b;
cin >> a >> b;
for (int k = a; k <= b; k++) {
cout << k << "=";
int n = k;
bool first = true; // 控制是否输出 '*'
// 从 2 开始试除
for (int i = 2; i * i <= n; i++) {
while (n % i == 0) {
if (!first) {
cout << "*";
}
cout << i;
first = false;
n /= i;
}
}
// 如果最后 n > 1,说明它本身是一个质因数
if (n > 1) {
if (!first) {
cout << "*";
}
cout << n;
}
cout << endl;
}
return 0;
}总结
从2开始不断试除,由于允许除数相同,并且都是从小的开始,所以设置了while,使得每次出现的都是最小的那个质因数
注意输出格式 除了第一个之外,后边都要先输出*,再输出质因数。与那种不是第一组,就先输出一个空行,是同一种思路
基础38 树
问题描述
明明是一家地铁建设公司的职员,他负责地铁线路的规划和设计。一次,明明要在一条长L的马路上建造若干个地铁车站。
这条马路有一个特点,马路上种了一排树,每两棵相邻的树之间的间隔都是一米。
如果把马路看成一个数轴,马路的一端在数轴0的位置,马路的另一端在L的位置,那么这些树都种在数轴的整数点上,即0,1,2,...,L上都种有一棵树。
由于要设计建造地铁站的缘故,所以需要把一些树移走,明明为了移树的方便,把地铁站的区域也建在了数轴上两个整数点之间,由于有多条地铁线路,地铁车站的区域可能会有部分的重合(重合的区域明明将来会设计成一个大型的车站,移树的时候不必考虑地铁站重合区域的问题)。
现在明明想请你帮一个忙,他把车站区域的位置告诉你,即告诉你数轴上的两个整数点,在这两个整数点之间是车站的区域,请你写一个程序,计算出把所有车站区域两点之间的树移走以后,这条马路上还剩多少棵树。
例如:马路长为10,要建造2个地铁车站,车站的区域分别是2到5和3到6,原先的马路上一共有11棵树,在2到5的位置上建车站后,需要移走4棵树,在3到6的位置上建车站后,也需要移走4棵树,但是3到6这个区域和2到5这个区域有部分重合,所以只需移走1棵树即可,这样总共移走的树是5棵,剩下的树就是6棵。
明明的问题可以归结为:给你一条马路的长度和若干个车站的位置,请你用程序计算出把树移走后,马路上还剩多少棵树。
输入说明
你写的程序要求从标准输入设备中读入测试数据作为你所写程序的输入数据。标准输入设备中有多组测试数据,每组测试数据有多行,每组测试数据的第一行有两个整数L(1≤L≤10000)和M(0≤M≤100),分别表示马路的长度和地铁车站区域的个数。接下来有M行,每行有2个整数,分别表示每一座地铁车站区域的两个坐标的。每组测试数据与其后一组测试数据之间没有任何空行,第一组测试数据前面以及最后一组测试数据后面也都没有任何空行。
输出说明
对于每一组测试数据,你写的程序要求计算出一组相应的运算结果,并将每组运算结果作为你所写程序的输出数据依次写入到标准输出设备中。每组运算结果为一个整数,即把树移走后,马路上还剩下多少棵树。每组运算结果单独占一行,其行首和行尾都没有任何空格或其他任何字符,每组运算结果与其后一组运算结果之间没有任何空行或其他任何字符,第一组运算结果前面以及最后一组运算结果后面也都没有任何空行或其他任何字符。 注:通常,显示屏为标准输出设备。
cpp
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct Station {
int s, e;
};
bool cmp(const Station& a, const Station& b) {
return a.s < b.s;
}
int main() {
int L, M;
while (cin >> L >> M) {
if (M == 0) {
cout << L + 1 << endl;
continue;
}
vector<Station> stations(M);
for (int i = 0; i < M; i++) {
cin >> stations[i].s >> stations[i].e;
}
// 按起点排序
sort(stations.begin(), stations.end(), cmp);
// 合并区间
int totalRemoved = 0;
int curStart = stations[0].s;
int curEnd = stations[0].e;
for (int i = 1; i < M; i++) {
if (stations[i].s <= curEnd) {
// 重叠或相邻,合并
curEnd = max(curEnd, stations[i].e);
} else {
// 不重叠,结算当前区间
totalRemoved += (curEnd - curStart + 1);
curStart = stations[i].s;
curEnd = stations[i].e;
}
}
// 结算最后一个区间
totalRemoved += (curEnd - curStart + 1);
cout << (L + 1 - totalRemoved) << endl;
}
return 0;
}区间合并问题:重叠或相邻,合并;不重叠,结算当前区间;最后记得加上最后一段。这基本上是固定思路
基础47 最大值
问题描述
为了培养明明对数学的热爱,明明的爸爸经常想出一些简单有趣且富有数学思想的游戏给明明玩。有一次,明明的爸爸在纸上写了N个数字,有正整数、负整数和0。明明的爸爸给明明一个范围,他可以选大于等于L1个且小于等于L2个的数字(L1≤L2),且这些数字必须是连续的。但是要求明明选出的数的和最大,这样说明明可能不太明白,于是明明爸爸就举了一个简单的例子。 例如有5个数字为"1"、"2"、"3"、"4"、"5",明明可以选择大于等于1个且小于等于2个的数字,也就是说明明可以选择1个数字,或者连续的2个数字。通过观察数字串,最后我们会选2个数字,4和5,他们的和最大,为9。 明明明白爸爸的意思后,就开始玩起游戏来。但是他发现,这个游戏看似简单,其实还是有相当的难度,因为数字越多,选择数字个数范围越大,则题目越难,到后面明明有些不想玩了。于是明明就求助于你,请你帮他写一个程序,来求出和的最大值。 明明的问题可以归结为:有N个数字,从中选择出连续的M(L1≤M≤L2)个数,求出它们之和的最大值。
输入说明
你写的程序要求从标准输入设备中读入测试数据作为你所写程序的输入数据。标准输入设备中有多组测试数据,每组测试数据有两行,每组测试数据的第一行有三个整数N(0<N≤20)、L1、L2(0<L1≤L2≤N),N表示数字串中有多少个整数,L1、L2表示可选数字个数的范围,每组测试数据的第二行有N个整数,整数大小的绝对值都小于等于100,整数之间用一个空格隔开。每组测试数据与其后一组测试数据之间没有任何空行,第一组测试数据前面以及最后一组测试数据后面也都没有任何空行。
输出说明
对于每一组测试数据,你写的程序要求计算出一组相应的运算结果,并将每组运算结果作为你所写程序的输出数据依次写入到标准输出设备中。每组运算结果为一个整数,即所求的最大值。每组运算结果单独形成一行数据,其行首和行尾都没有任何空格,每组运算结果与其后一组运算结果之间没有任何空行,第一组运算结果前面以及最后一组运算结果后面也都没有任何空行。 注:通常,显示屏为标准输出设备。
cpp
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
int N, L1, L2;
while (cin >> N >> L1 >> L2) {
vector<int> a(N);
for (int i = 0; i < N; i++) {
cin >> a[i];
}
int maxSum = INT_MIN; // 初始化为最小值,防止全负数出错
// 枚举所有起始位置
for (int i = 0; i < N; i++) {
int currentSum = 0;
// 枚举从 i 开始,长度从 1 到 L2(但不超过 N-i)
for (int len = 1; len <= L2 && i + len <= N; len++) {
currentSum += a[i + len - 1]; // 累加新元素
// 如果当前长度 >= L1,更新答案
if (len >= L1) {
if (currentSum > maxSum) {
maxSum = currentSum;
}
}
}
}
cout << maxSum << endl;
}
return 0;
}外循环是起始位置,内循环是长度(防溢出条件),当长度满足要求时,可以存下数字和,加上长度更新条件。
基础84 删除字符
问题描述
从键盘输入一个字符串和一个字符,将输入字符从字符串中删除,输出新的字符串。如果字符串中没有此字符,则原样输出字符串。
输入说明
输入两行,第一行输入一个字符串,第二行输入一个字符。
字符串最多允许输入20个任意字符。
输出说明
输出删除字符后的字符串。
char不能用getline读,string又不能用于字符比较,如何解决?
cpp
string line;
getline(cin, line); // 第一行字符串
string charLine;
getline(cin, charLine); // 第二行(可能是一个空格)
char c = charLine[0]; // 取第一个字符
cpp
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
int main()
{
string old;
//整行读入要用getline
getline(cin,old);
char del=cin.get();
string s;
for(size_t i=0;i<old.length();i++){
if(old[i]!=del){
s+=old[i];
}
}
cout<<s<<endl;
return 0;
}上边是用cin.get,什么都不跳过,包括换行符和空格
更保险的办法:
cpp
#include <iostream>
#include <string>
using namespace std;
int main() {
string line;
getline(cin, line); // 读字符串(可能含空格)
string charLine;
getline(cin, charLine); // 读第二行(一个字符,可能为空格)
char c = charLine[0];
string result = "";
for (size_t i = 0; i < line.length(); i++) {
if (line[i] != c) {
result += line[i];
}
}
cout << result << endl;
return 0;
}string不能直接比字符,但是如果string只有一个字符,则我的s【0】就是那个char,可以换个方法去比,还方便输入,包括空格。
基础100 纯粹合数
问题描述
明明的爸爸是一位数学家,明明受他爸爸的影响从小就喜欢数学,经常向他爸爸学习或请教数学问题。
一天,明明问他爸爸什么是合数,明明的爸爸回答说:"首先,合数都是大于1的整数,其次合数是除了1和其本身外,还能被至少一个其他自然数整除的数,例如'4'这个数,它除了能被1和4整除外,还能被2整除,因此'4'就是合数;但是'3'就不是合数,因为3只能被1和3这两个数整除,因此'3'不是合数。"
聪明的明明很快就理解了他爸爸的意思,于是又接着问他爸爸:"那什么又是纯粹合数呢?"明明的爸爸接着回答说:"一个合数,去掉最高位,剩下的数是0或仍是合数;再去掉剩下的数的最高位,剩下的数还是0或合数;这样反复,一直到最后剩下的一位数仍为0或合数;我们把这样的数称为纯粹合数。
例如'100'这个数,它能被1、2、4、5、10、20、50、100整除,因此100是个合数,我们去掉它的最高位,剩下的数是0(其实剩下的应该是00,但是前置0对一个整数来说没有意义,因此前置0被舍去,就剩下个位数上的0),因此'100'是一个纯粹合数。有趣的是,100是最小的一个三位纯粹合数。
再例如'104'这个数,104能被1、2、8、13、26、52、104整除,所以104是个合数;我们去掉它的最高位后剩下4,4能被1、2、4整除,所以4也是合数,所以'104'是一个纯粹合数。
但是'101'就不是纯粹合数,因为'101'只能被1和101这两个数整除。"
明明对他爸爸的回答很满意,于是自己动手从100开始寻找纯粹合数,他一共找到了100个纯粹合数,调皮的明明开始反过来考爸爸了,问他爸爸能否告诉他第2个大于等于100的纯粹合数是哪个?第3个大于等于100的纯粹合数又是哪个?......明明的爸爸被这个突如其来的问题给难住了,他无法立刻回答出来,于是请求你的帮助,帮助他回答明明的这个问题。
明明的问题可以归结为:根据一个正整数n,求出从100开始从小到大的第n个纯粹合数。
输入说明
你写的程序需要从标准输入设备(通常为键盘)中读入多组测试数据,每组测试数据仅占一行,每行仅包括一个正整数n(1 ≤ n ≤ 100)。每组测试数据与其后一组测试数据之间没有任何空行,第一组测试数据前面以及最后一组测试数据后面也都没有任何空行。
输出说明
对于每一组测试数据,你写的程序需要计算出一组相应的运算结果,并将每组运算结果依次写入到标准输出设备(通常为启动该程序的文本终端,例如Windows中的命令行终端)中。每组运算结果为一个整数,即从100开始从小到大的第n个纯粹合数。每组运算结果单独形成一行数据,其行首和行尾都没有任何空格,每组运算结果与其后一组运算结果之间没有任何空行,第一组运算结果前面以及最后一组运算结果后面也都没有任何空行。
cpp
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
//判断是否合数
bool isHeshu(int n){
if(n<=2) return false;
//注意 被2整除 也就是>2的偶数 肯定都是合数
//所以 虽然2不是合数,但是i依然要从2开始取,否则就会漏掉很多偶数
for(int i=2;i*i<=n;i++){
if(n%i==0){
return true;
}
}
return false;
}
//判断是否是纯粹合数
bool ispureHeshu(int n){
if(!isHeshu(n)) return false;
string n_str=to_string(n);
//去掉最高位
for(int i=1;i<n_str.size();i++){
string new_str=n_str.substr(i);
int num=stoi(new_str);//转为数字
if(num!=0&&!isHeshu(num)){
return false;
}
}
return true;
}
/*
int转string类型用to_string,而string转int型用stoi,没有itos函数
*/
int main()
{
int n;
//100不算小 把握不住i的上限,那就预存
vector<int> ans;
for(int i=100;ans.size()<100;i++){
if(ispureHeshu(i)){
ans.push_back(i);
}
}
while(cin>>n){
cout<<ans[n-1]<<endl;
}
return 0;
}基础120 顺序的分数
问题描述
输入一个自然数N,请写一个程序来增序输出分母小于等于N的既约真分数(即无法再进行约分的小于1的分数)
输入说明
单独的一行,一个自然数N(1..20)
输出说明
每个分数单独占一行
按照分数大小升序排列
对于分子为0的分数,仅输出0/1,不输出其它分母的分数,比如0/2, 0/3。
cpp
#include <iostream>
#include <bits/stdc++.h>
using namespace std;
//自定义排序 结构体
struct fru{
double fz;
double fm;
};
//增序排列
bool comparefru(const fru& a,const fru& b){
return a.fz*b.fm<b.fz*a.fm;
}
//最大公约数 关于分数 要有最简分数的判断
int gcd(int a,int b){
//a b---b a%b
while(b!=0){
int temp=b;
b=a%b;
a=temp;
}
return a;
}
int main()
{
int N;
cin>>N;
vector<fru> f;
//分母1-N
for(double i=1;i<=N;i++){
//分子
for(double j=0;j<i;j++){
if(j==0){
if(i==1){
f.push_back({0,1});
continue;
}else{
continue;
}
}else{
if(gcd(j,i)==1){
f.push_back({j,i});
}
}
}
}
sort(f.begin(),f.end(),comparefru);
for(int i=0;i<f.size();i++){
cout<<f[i].fz<<"/"<<f[i].fm<<endl;
}
return 0;
}记住最大公约数 如何判断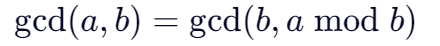
翻译
恶意软件变体的指数级增长对网络安全构成了严重威胁,使得传统的基于签名的检测方法日益失效。虽然启发式和行为分析提供了一些改进,但它们往往受限于高误报率,且无法检测零日攻击。最近,深度学习 (DL) 已成为一种强大的恶意软件检测范式,能够无需人工特征工程,直接从原始数据中自动学习复杂特征。本综述全面概述了应用于恶意软件检测的深度学习技术。我们根据输入数据表示(如操作码序列、二进制图像、API 调用图)和所使用的神经网络架构(如 CNN、RNN、自编码器、GAN),对现有方法进行了系统分类。此外,我们讨论了关键挑战,如对抗性攻击、类别不平衡以及大规模标注数据集的缺乏。最后,我们概述了未来的研究方向,包括用于安全的可解释人工智能 (XAI) 以及针对逃避技术的鲁棒防御机制。
恶意软件(Malware)是恶意软件的简称,包括病毒、蠕虫、木马、勒索软件和间谍软件,旨在破坏操作或窃取敏感信息。恶意软件的格局正在迅速演变;攻击者现在使用多态和变形技术不断改变代码结构,从而逃避静态签名检测。因此,迫切需要能够泛化到未见变体的智能检测系统。
传统的机器学习 (ML) 方法,如支持向量机 (SVM) 和随机森林,已被广泛使用。然而,它们的性能严重依赖于手工特征的质量,这需要领域专业知识且耗时。相比之下,深度学习 (DL) 模型擅长表示学习,能够自动从原始二进制文件或反汇编代码中提取层次化特征。例如,卷积神经网络 (CNN) 可以将恶意软件二进制文件视为图像以捕捉空间模式,而循环神经网络 (RNN) 可以建模指令流中的序列依赖关系。
尽管结果令人鼓舞,但在网络安全中部署深度学习仍面临独特的障碍。一个主要担忧是对抗鲁棒性:攻击者可以注入良性字节或修改指令以欺骗分类器,而不改变恶意软件的功能。此外,深度学习模型的"黑盒"性质使得安全分析师难以信任检测结果,凸显了可解释性的需求。本综述旨在通过提供当前方法的结构化分类并识别开放性挑战,弥合深度学习和安全社区之间的差距。
单词